Tabla de contenido
1 ¿Por qué el rendimiento de count (*) es deficiente?
2 Optimizar el rendimiento del recuento (*)
Comparación de rendimiento de varios usos de 3 recuentos
Base de datos: Mysql8、el motor de almacenamiento es Innodb.
Normalmente, la interfaz de paginación consultará la base de datos dos veces: la primera vez es para obtener datos específicos, la segunda vez es para obtener el número total de filas de registros y luego los resultados se integran antes de regresar.
SQL para consultar datos específicos, como este, no tiene problemas de rendimiento.
select id,name from user limit 1,20;Pero otro SQL que usa count (*) para consultar el número total de filas de registros tiene un rendimiento deficiente. Por ejemplo:
select count(*) from user;¿Por qué pasó esto?
1 ¿Por qué el rendimiento de count (*) es deficiente?
En Mysql, count(*)la función es contar el número total de filas registradas en la tabla. El count(*)rendimiento está directamente relacionado con el motor de almacenamiento, pero no todos los motores de almacenamiento tienen count(*)un rendimiento deficiente.
Los motores de almacenamiento más utilizados en Mysql son: innodby myisam.
En myisam, el número total de filas se guardará en el disco. Cuando se usa count (*), solo necesita devolver esos datos sin cálculos adicionales, por lo que la eficiencia de ejecución es muy alta.
InnoDB es diferente: dado que admite transacciones y tiene MVCCla existencia de control de concurrencia de múltiples versiones, en diferentes transacciones en el mismo momento, el número de filas de registros devueltas por la misma consulta SQL puede ser incierto. Cuando se usa count (*) en innodb, los datos deben leerse fila por fila desde el motor de almacenamiento y luego acumularse, por lo que la eficiencia de ejecución es muy baja. Está bien si la cantidad de datos en la tabla es pequeña. Una vez que la cantidad de datos en la tabla es grande, el rendimiento será muy pobre cuando el motor de almacenamiento innodb use estadísticas de recuento (*).
2 Optimizar el rendimiento del recuento (*)
2.1 Agregar caché de Redis
Para un recuento simple (*), como contar el número total de vistas o el número total de visitantes, podemos almacenar en caché directamente la interfaz usando redis y no es necesario contar en tiempo real.
Cuando el usuario abre la página especificada, establezca count = count+1 en el caché cada vez. Cuando el usuario visita la página por primera vez, el valor de recuento en redis se establece en 1. Cada vez que el usuario visite la página en el futuro, el recuento se incrementará en 1 y finalmente se restablecerá a redis.
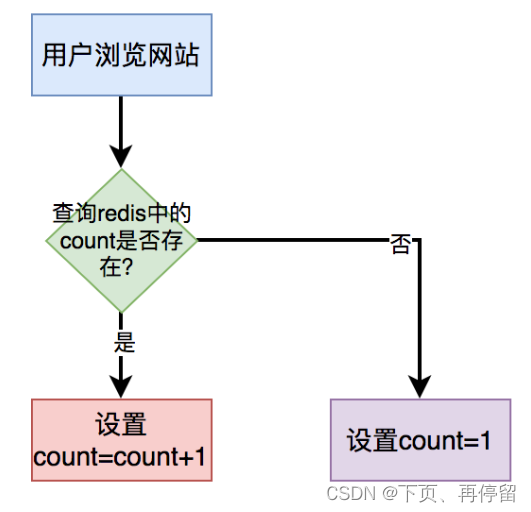
De esta manera, cuando es necesario mostrar la cantidad, el valor del recuento se puede encontrar en redis y devolverlo.
En este escenario, no es necesario utilizar estadísticas de recuento (*) en tiempo real de la tabla de puntos de datos y el rendimiento mejorará enormemente. Sin embargo, en situaciones de alta concurrencia, puede haber inconsistencias de datos entre el caché y la base de datos. Sin embargo, para escenarios comerciales como contar el número total de vistas o el número total de espectadores, la precisión de los datos no es alta y se toleran las inconsistencias de los datos.
2.2 Ejecución multiproceso
Por ejemplo, es necesario: contar cuántos pedidos válidos hay y cuántos pedidos no válidos.
En este caso, generalmente es necesario escribir dos SQL. Los SQL utilizados para contar los pedidos válidos son los siguientes:
select count(*) from order where status=1;El SQL para contar pedidos no válidos es el siguiente:
select count(*) from order where status=0;Pero si está en una interfaz, la eficiencia de ejecutar estos dos SQL sincrónicamente será muy baja. En este momento, puedes cambiarlo a sql:
select count(*),status from order
group by status;El uso de group byla agrupación de palabras clave para contar el número del mismo estado solo generará dos registros, un registro es el número de pedidos válidos y el otro registro es el número de pedidos no válidos. Pero hay un problema: el campo de estado solo tiene dos valores 1 y 0, el grado de repetición es muy alto, la discriminación es muy baja, no se puede indexar y se escaneará toda la tabla, que es no muy eficiente.
¿Hay otras soluciones? Respuesta: Utilice subprocesos múltiples.
Podemos usar CompleteFuturedos 线程llamadas asincrónicas a SQL para contar pedidos válidos y SQL para contar pedidos no válidos y, finalmente, resumir los datos, lo que puede mejorar el rendimiento de la interfaz de consulta.
2.3 Reducir tablas de unión
En la mayoría de los casos, count (*) se utiliza para contar la cantidad total en tiempo real. Sin embargo, si la cantidad de datos en la tabla en sí es pequeña, pero hay demasiadas tablas unidas, la eficiencia del recuento (*) también puede verse afectada. Por ejemplo, al consultar información del producto, debe consultar datos según el nombre del producto, unidad, marca, clasificación y otra información. En este momento, escriba un SQL para encontrar los datos deseados, como los siguientes:
select count(*)
from product p
inner join unit u on p.unit_id = u.id
inner join brand b on p.brand_id = b.id
inner join category c on p.category_id = c.id
where p.name='测试商品' and u.id=123 and b.id=124 and c.id=125;Utilice la tabla de productos para ir a joinlas tres tablas de unidad, marca y categoría. De hecho, estas condiciones de consulta pueden consultar datos en la tabla de productos y no es necesario unir tablas adicionales.
Podemos cambiar el sql a esto:
select count(*)
from product
where name='测试商品' and unit_id=123 and brand_id=124 and category_id=125;Al contar (*), consulte solo la tabla de productos y elimine las uniones de tablas redundantes, para que la eficiencia de la consulta pueda mejorar considerablemente.
Comparación de rendimiento de varios usos de 3 recuentos
-
count (*): obtendrá los datos de todas las filas sin realizar ningún procesamiento y agregará 1 al número de filas.
-
count(1): Obtendrá los datos de todas las filas, con un valor fijo de 1 para cada fila, que también es el número de filas más 1.
-
count(id): id representa la clave principal. Necesita analizar el campo de id de todas las filas de datos. La identificación no debe ser NULL y el número de filas se incrementa en 1.
-
recuento (columna de índice ordinaria): necesita analizar la columna de índice ordinaria a partir de los datos de todas las filas y luego determinar si es NULL. Si no es NULL, el número de filas aumenta en 1.
-
recuento (columna no indexada): escanea toda la tabla para obtener todos los datos, analiza la columna no indexada y luego determina si es NULL. Si no es NULL, el número de filas aumenta en 1.
A partir de esto, el rendimiento del conteo final de mayor a menor es:
recuento(*) ≈ recuento(1) > recuento(id) > recuento (columna de índice ordinaria) > recuento (columna no indexada)
Entonces, count(*)en realidad es el más rápido.