arquitectura cliente/servidor
Antes de mirar HTTP, presentaremos brevemente las propiedades del entorno en el que operan. A esto se le suele denominar entorno cliente/servidor.
Un sistema cliente/servidor simple tiene uno o más procesos cliente y un proceso servidor, como se muestra en la siguiente figura:

Aunque esto parece simple, hay varias propiedades que lo hacen más complejo de lo esperado. Los clientes son entidades independientes que se ejecutan en muchos sistemas informáticos diferentes. este
Esto significa que debemos considerar lo siguiente:
1. El proceso del cliente debe ser compatible con el sistema operativo del cliente. Cosas como la compatibilidad con idiomas y protocolos de comunicación de datos deben estar disponibles y ser compatibles.
2. La seguridad es un problema porque los clientes remotos deben autenticarse antes de que se les permita acceder a la información del servidor.
3. Muchas computadoras cliente diferentes significan que eventualmente una o más se interrumpirán durante alguna comunicación cliente/servidor. Esto requiere que la instalación se recupere de la situación.
4. Si muchos clientes pueden acceder al servidor, es necesario respaldar la disponibilidad del servidor y la recuperación de errores, especialmente si la relación cliente/servidor es una relación comercial cliente/proveedor.
5. Los tiempos de respuesta para las interacciones cliente/servidor deben ser aceptables y manejables.
6. En la escala de redes de Internet, también debemos considerar cómo los clientes encuentran servidores entre los millones de servidores a los que pueden acceder.
También debemos darnos cuenta de que la arquitectura simple cliente/servidor que se muestra arriba no significa que todos los clientes estén en máquinas diferentes. En una arquitectura cliente/servidor está perfectamente permitido que uno o más procesos cliente y servidor estén en el mismo sistema informático.
Los sistemas cliente/servidor modernos son aún más complejos. El siguiente diagrama ilustra cómo interactuamos con cualquier combinación de clientes y servidores en un sistema informático. Múltiples clientes coexisten con múltiples servidores en cualquier sistema informático. Además, los procesos del cliente pueden acceder a múltiples servidores para lograr sus objetivos y los servidores pueden actuar como clientes para satisfacer las necesidades de sus propios clientes.
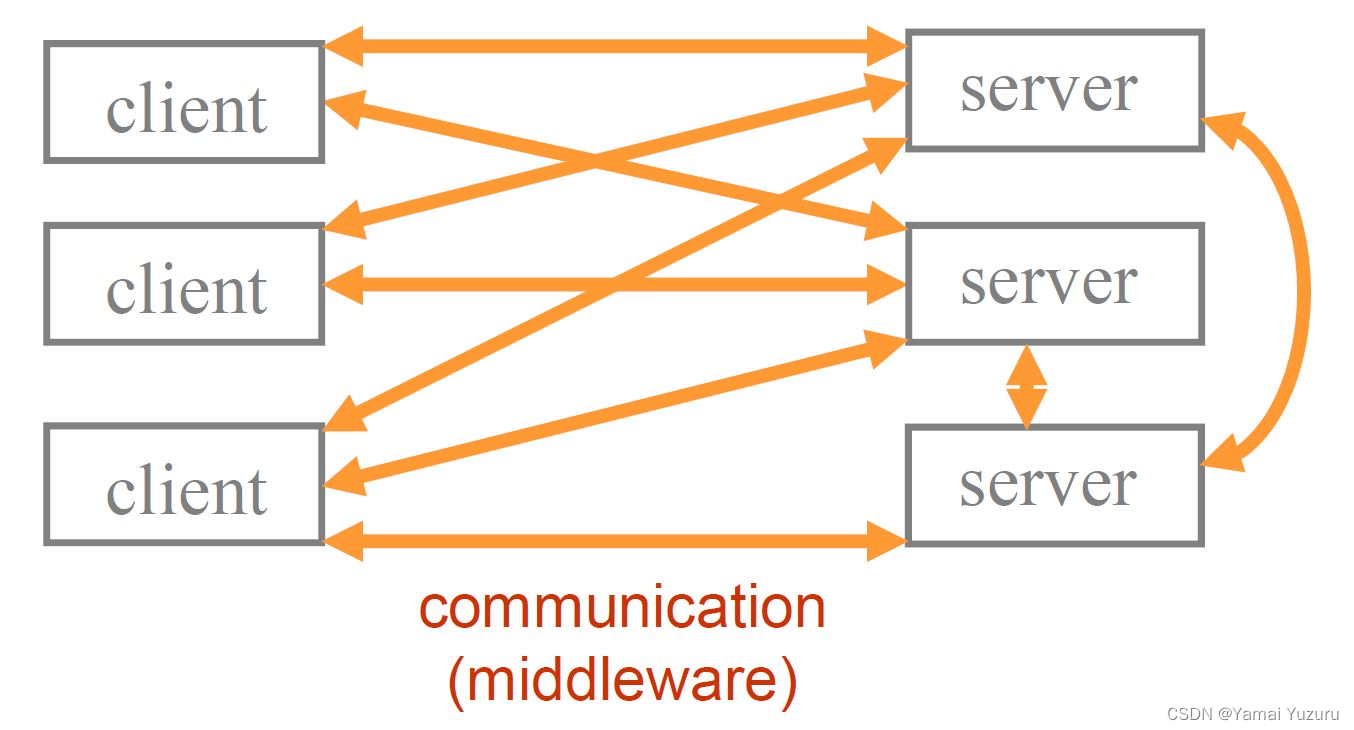
Ahora notará que en los dos diagramas anteriores, el término middleware debajo de la flecha representa la interacción cliente/servidor. El middleware es el componente de software requerido por un sistema cliente/servidor para lograr los objetivos anteriores. Es el software entre el programa cliente y el sistema operativo y el programa servidor y el sistema operativo. Aísla a los programadores de clientes y servidores de las complejidades relacionadas con la compatibilidad, la seguridad, el posicionamiento mutuo, etc. al proporcionar una interfaz estandarizada.
El middleware que cubriremos es el Protocolo de transferencia de hipertexto (HTTP) y la infraestructura utilizada para respaldarlo. Debido a la naturaleza de esta unidad (sistema móvil) estaremos interesados principalmente en el lado del cliente de la infraestructura. Sin embargo, comprender lo que sucede en el lado del servidor es crucial para comprender mejor las limitaciones y ventajas de esta tecnología.
Servidor de red
Un servidor web es el lado del servidor de un sistema cliente/servidor basado en HTTP. Actualmente son la tecnología de servidor dominante en Internet, debido principalmente a la popularidad de la Web y a los avances en el diseño de software de red. Aunque el "hipertexto" en HTTP era originalmente un documento HTML, ahora se utilizan muchos más formatos de datos en HTTP, algunos de los cuales examinaremos en esta unidad. En esta sección, cubrimos las operaciones básicas del servidor web. En las siguientes secciones, modificamos HTML para convertirlo en un lenguaje de marcado de documentos y analizamos cómo los enlaces HTML forman la interacción básica con un servidor web. Luego veremos la etiqueta <form> porque proporciona una manera para que el cliente envíe datos al servidor web, permitiendo al servidor web construir una página única para enviarla al cliente. Luego, veremos un sistema CGI simple que permite a un servidor web ejecutar programas que crean páginas para clientes. Se examinarán algunas otras tecnologías modernas que han reemplazado a CGI para servidores web de gran volumen, PHP y ASP.
El servidor web es la parte del servidor del cliente/servidor que interactúa con las páginas HTML. En su forma más simple, simplemente acepta una solicitud de una página HTML y envía una copia almacenada de la página al cliente solicitante. Sin embargo, los servidores web modernos son mucho más complejos de lo que sugiere esta simple interacción.
Los pasos involucrados en una interacción típica con un servidor web son los siguientes:
1. Un cliente web (normalmente un navegador web) envía una solicitud de página web a través de Internet.
2. El servidor valida la solicitud para garantizar que la página exista, que esté instalado el software necesario y que se cumplan las restricciones de seguridad.
3. Cualquier software requerido por el servidor para ejecutar las solicitudes de los clientes.
4. El servidor recopila la página HTML del sistema de archivos del servidor o como salida del programa.
5. El servidor envía el documento HTML al cliente a través de Internet.
Los pasos 1 y 2 utilizan el protocolo HTTP para enviar solicitudes al servidor y páginas HTML al cliente. HTTP es un protocolo muy simple que utiliza mensajes de SOLICITUD y RESPUESTA para interactuar entre clientes y servidores. Si bien no necesitamos conocer los detalles de HTTP, es útil ver el formato general de estos mensajes. La siguiente tabla muestra la forma general de los mensajes de solicitud HTTP y mensajes de muestra.
| Forma general de solicitud HTTP | Solicitud de muestra |
|
método id_recurso HTTP_version
encabezado: valor
…
encabezado: valor
linea en blanco
cuerpo_mensaje y
|
OBTENER /jdk1.3/docs/index.html HTTP/1.0 Aceptar: texto/html Agente de usuario: MacWeb |
En este ejemplo, el método "GET" es uno de los posibles métodos HTTP. La versión HTTP es 1.0, en este caso no hay cuerpo del mensaje. Tenga en cuenta que el identificador del recurso es simplemente el nombre del archivo del recurso en el servidor. El nombre de la computadora del servidor no es necesario porque para enviar un mensaje, el cliente ya debe encontrar el nombre del servidor para saber dónde enviar el mensaje.
La siguiente tabla muestra la forma general de una respuesta HTTP y un ejemplo de respuesta real que contiene una página HTML.
| Forma general de respuesta HTTP | Respuesta de muestra |
| Versión_HTTP código_resultado resultado_comentario encabezado: valor … encabezado: valor linea en blanco Cuerpo del mensaje |
HTTP/1.0 200 correcto Servidor: Apache/1.3 Versión_mime: 1.0 Tipo de contenido: texto/html <html>…</html> |
Esta respuesta HTTP utiliza la versión 1.0 del protocolo y devuelve el código de resultado 200. Sus pares encabezado/valor indican que el servidor es un servidor Apache versión 1.3 y se envía una página HTML en el cuerpo del mensaje.
Ahora ha encontrado localizadores universales de recursos (URL). Por ejemplo, la siguiente URL identifica una página web denominada Spike.scu.edu.au ubicada en un servidor web en /jdk1.3/docs/index.html, al que se puede acceder a través del protocolo HTTP.
http://spike.scu.edu.au/jdk1.3/docs/index.html
El mensaje de solicitud HTTP solo requiere la ubicación del archivo en el servidor web porque el protocolo (HTTP) se selecciona en la primera parte de la URL y el servidor se encontró usando el nombre de la computadora en la URL, en este caso Spike.scu.edu. .au. Es posible que haya visto otros protocolos como HTTPS y FTP (https: y ftp:) utilizados en las URL.
Programación del lado del servidor
La programación del lado del servidor se refiere al proceso de desarrollo o programación directamente dentro del servidor.
El beneficio de utilizar la programación del lado del servidor es que se puede acceder a los datos subyacentes localmente; no se requiere conexión de red ni recursos externos para acceder a los datos. Además, el código integrado que se ejecuta en el servidor suele ser más rápido que el código del lado del cliente, lo que requiere que el usuario acceda a la base de datos para acceder a los datos. Estudiaremos el acceso a bases de datos usando NodeJS en el módulo de la Semana 4.
Además, la programación del lado del servidor permite incorporar código directamente a la base de datos. El código se puede administrar y restaurar utilizando herramientas de respaldo de bases de datos estándar, como cualquier otro objeto de base de datos.
En esta sección, analizaremos NodeJS en el contexto de un lenguaje de programación del lado del servidor y exploraremos los conceptos necesarios para crear nuestra primera aplicación de servidor utilizando NodeJS. Pero antes de eso, revisaremos algunos temas importantes como HTTP, la API necesaria para crear nuestra primera aplicación de servidor.
Protocolo de transferencia de hipertexto (HTTP)
Como parte de este módulo, deberá comprender el Protocolo de transferencia de hipertexto (HTTP), un protocolo utilizado por las redes informáticas. Existen otros protocolos como SMTP (Protocolo simple de transferencia de correo), FTP (Protocolo de transferencia de archivos), POP3 (Protocolo de oficina de correos 3), etc.
Los protocolos proporcionan formatos de mensajes, reglas, sintaxis, semántica, etc. bien definidos, lo que permite que dispositivos con diferente hardware y software interactúen entre sí. Cualquier dispositivo que sea compatible con un protocolo específico puede comunicarse con cualquier otro dispositivo de la red.
El Protocolo de transferencia de hipertexto (HTTP) es posiblemente uno de los protocolos de aplicaciones de Internet más adoptados en la historia. Es el método mediante el cual los clientes y servidores se comunican a través de Internet. Aparte de los navegadores, HTTP es el protocolo elegido para casi todas las aplicaciones que se conectan a Internet.
El hecho de que la mayoría de sistemas operativos incluyan protocolos de red como HTTP por defecto hace que no tengamos que instalar ningún software adicional para acceder a Internet.
El protocolo HTTP que impulsa la Web se denomina protocolo sin conexión. Es el protocolo utilizado por los navegadores web para comunicarse con los servidores web. Cada vez que se hace clic en un enlace, se envía un formulario o se realiza una búsqueda, se envía una solicitud desde el navegador al servidor de destino. Después de solicitar imágenes, vídeos y texto del servidor, el navegador y el servidor ya no están conectados. Esto se debe a que opera según un modelo de solicitud/respuesta.
Al enviar una solicitud, debe incluir la URL que identifica el recurso y el método que se aplicará (como recuperar, eliminar o publicar). Se puede incluir información adicional en forma de parámetros de URL (pares de valor de campo), datos POST o cookies.
El protocolo HTTP establece pautas claras para la comunicación entre clientes y servidores.
- Normalmente, las solicitudes HTTP las envía únicamente el cliente al servidor. El servidor responde a las solicitudes HTTP de los clientes. Al utilizar una tecnología llamada server push, el servidor también puede llenar el caché del cliente con información antes de solicitarla.
- Al solicitar un archivo a través de HTTP, el cliente debe proporcionar la URL del archivo.
- El servidor web debe responder a cada solicitud HTTP, al menos con un mensaje de error.
HTML y etiquetas de formulario <form>
Has visto la etiqueta HTML <form> en la unidad anterior. Lo que no hemos discutido hasta ahora es cómo debemos enviar datos a un servidor remoto y gestionar los retrasos y errores que ocurren en la transferencia de datos. Entonces, como revisión, revisaremos la etiqueta HTML <form> normal aquí.
Un ejemplo de la etiqueta HTML <form> tomada del sitio web de Java (java.sun.com) es el siguiente:
<form action="/cgi-bin/coffee" method="post">
Would you care for a cup of coffee?<BR>
<INPUT type="radio" name="coffee" value="Y" CHECKED="checked"/>Yes
<INPUT type="radio" name="coffee" value="N"/>No<P>
If yes:<BR/>
What flavor?
<SELECT name="flavor" size="1">
<OPTION value="French Roast"/>French Roast
<OPTION value="Vienna Roast"/>Vienna Roast
<OPTION value="Almond Mocha"/>Almond Mocha
</SELECT><BR/>
<INPUT type="checkbox" name="cream" value="Y"/>Include Cream
<INPUT type="checkbox" name="sugar" value="Y"/>Include Sugar<br/>
<INPUT type="submit" value="Brew It"/>
</form>El atributo de acción de esta etiqueta <form> especifica un programa para manejar los datos que se enviarán al servidor (en este caso, /cgi-bin/coffee). El servidor web utiliza esta información para iniciar programas para procesar los datos. El atributo de método usa su valor de publicación para especificar que el método HTTP POST debe usarse en solicitudes HTTP para enviar datos al servidor.
Esta etiqueta también construye un conjunto de controles visuales que permiten al usuario cliente seleccionar valores para enviar al servidor web interpretando etiquetas separadas por <form> y </form>. El navegador mostrará algo similar a la imagen a continuación.
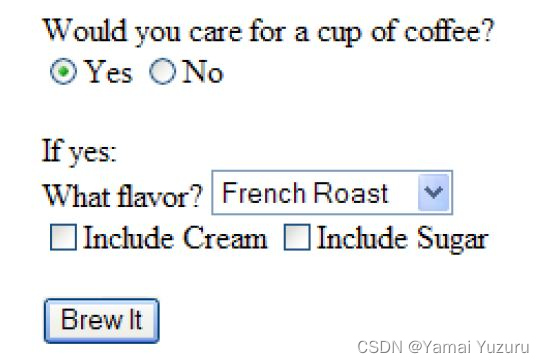
En este ejemplo, la etiqueta <input> se utiliza para construir botones de opción, casillas de verificación y el botón "Prepararlo" en la parte inferior del formulario. La etiqueta <select> se utiliza para crear un menú desplegable que permite al usuario seleccionar el tipo de café.
Interfaz de puerta de enlace común (CGI)
En la sección anterior, vimos cómo usar la etiqueta <form> para recopilar datos del usuario y enviarlos al servidor para su procesamiento. El primer sistema del lado del servidor que utilizó estos datos fue Common Gateway Interface, siempre denominado simplemente CGI.
CGI es un sistema simple en el que el servidor web inicia un programa llamado programa CGI para procesar datos de formulario. Luego, el programa CGI genera una página web HTML, que el servidor envía de vuelta al cliente. El siguiente diagrama muestra la interacción completa entre cliente y servidor.
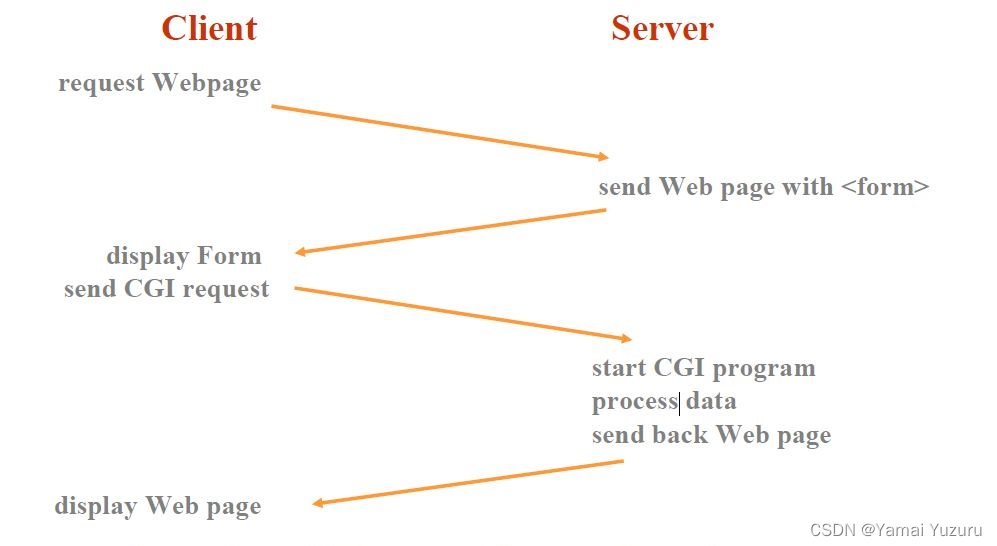
Este diagrama muestra cómo se carga por primera vez el formulario desde el servidor web, posiblemente a través de una solicitud CGI previa. Luego, el usuario cliente opera el formulario y envía los datos del formulario al servidor para su procesamiento. Luego, el servidor comienza a procesar el programa CGI especificado por el atributo de acción en la etiqueta <form>, que lee los datos del cliente y genera una página HTML para que el servidor la envíe al cliente. Finalmente, el cliente muestra la página web generada.
El navegador web recopila los datos cuando el usuario hace clic en el botón de envío o anula la interacción de envío, como por ejemplo ejecutando una función JavaScript adecuada. Los datos se ensamblan en pares etiqueta/valor antes de transmitirse al servidor. Los pares están organizados en el formato etiqueta=valor, con pares individuales separados por el carácter "&". El navegador también reemplaza los caracteres especiales con caracteres que pueden transmitirse a través de HTTP; por ejemplo, los espacios se reemplazan por "+".
El programa CGI obtiene datos del cliente en los mismos pares de etiqueta/valor del servidor web. Por ejemplo, digamos que seleccionamos los controles para el ejemplo del café de la sección anterior, como se muestra a continuación.
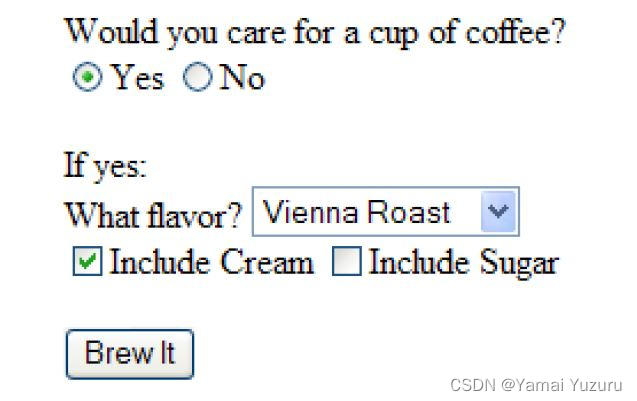
El navegador construirá la siguiente cadena para enviarla al programa CGI y utilizará el método HTTP POST para enviar los datos al programa CGI:
flavor=Vienna+Roast&cream=Y&coffee=YAhora debes compararlo cuidadosamente con el código HTML proporcionado anteriormente. Tenga en cuenta que el orden de las etiquetas es diferente del orden declarado en la etiqueta HTML <form>. En términos generales, este es el caso, los programas CGI no pueden depender de ningún orden de etiquetas. Además, observe cómo la casilla de verificación etiquetada como azúcar no está representada en esta cadena. Normalmente, esto también es cierto cuando la casilla de verificación no está marcada, es decir, solo las casillas marcadas devuelven pares de etiqueta/valor.
El siguiente paso en la interacción cliente/servidor es que el servidor web reciba la solicitud HTTP POST y pase los detalles del mensaje HTTP al programa CGI designado utilizando variables de entorno. Luego, el programa CGI recupera las variables de entorno para determinar el patrón de la solicitud HTTP. Tenga en cuenta que es posible que haya visto variables de entorno antes, como PATH o CLASSPATH. Los sistemas CGI utilizan diferentes variables, que pueden ser recuperadas mediante programas CGI.
En este ejemplo, el programa CGI descubrirá que la solicitud CGI está utilizando el modo POST para poder leer los pares etiqueta/valor de la entrada estándar del programa. El programa debe interpretar la cadena pasada para eliminar varios caracteres insertados ("=", "?", "+", etc.). El programa construirá una estructura de datos interna para contener las etiquetas y sus valores asociados.
Luego, los programas CGI pueden procesar los datos accediendo a bases de datos, archivos y otros programas. Finalmente, el programa CGI escribe la página HTML directamente en el flujo de salida estándar del programa. Esto se puede hacer en un programa CGI de Java, por ejemplo, utilizando la función System.out.println().
Cuando un programa CGI cierra su salida estándar o sale, el servidor web envía la página HTML al cliente. Si el cliente es un navegador web, muestra la página web.
CGI tiene varios problemas que lo hacen inadecuado para servidores web de gran volumen:
1. El sistema CGI es lento. Esto se debe a que el servidor web debe iniciar un nuevo programa para cada solicitud CGI. Iniciar un programa CGI requiere reunir muchos recursos del sistema y cargar el programa desde el sistema de archivos. Los mejores sistemas evitan estos problemas utilizando programas que permanecen ejecutándose en la memoria de la computadora.
2.CGI no tiene estado. Sin estado significa que el programa CGI no recuerda qué cliente envió la última solicitud CGI, por lo que no recuerda qué hizo el cliente en la última solicitud. Esto significa que las interacciones CGI suelen ser aplicaciones de una pantalla, una respuesta, y se han introducido cookies y otros dispositivos de ahorro de estado para resolver este problema.
3.La programación CGI es difícil. La solución al problema 2 complica bastante la programación CGI. Se han desarrollado mejores sistemas para facilitar la programación.
Transferencia de estado representacional (REST)
La transferencia de estado representacional (REST) se ha convertido en un método común para organizar aplicaciones basadas en el protocolo HTTP. Utiliza encabezados de mensajes HHTP y atributos de protocolo de forma natural y muy relevante. En esta sección, describiremos las principales características implementadas por los servicios web RESTful (como se los conoce comúnmente).
Hay cuatro aspectos principales de los servicios web REST:
1. Con HTTP, los tipos de mensajes (GET, POST, PUT, etc.) tienen significados claros;
2. La comunicación es apátrida;
3. La estructura de directorios de los datos está expuesta al cliente y al servidor, y
4. Los datos se transfieren en XML u otro tipo MIME especificado en el encabezado HTTP.
Utilice NodeJS para crear un servidor web y cargar archivos HTML
- Asegúrese de que Node.js esté instalado en su computadora
- Ha aprendido los conceptos básicos necesarios para crear un servidor web.
- Cree una nueva carpeta llamada "Mi servidor"
- Cree un nuevo archivo llamado "web-server.js" en la carpeta recién creada my-server
- Agregue el siguiente código al archivo "web-server.js".
const http = require("http");A continuación definiremos dos constantes, el host y el puerto que se asignará al servidor:
const host = 'localhost';
const port = 8080Los servidores web manejan solicitudes de navegadores y otros clientes, como comentamos en la sección anterior. Al utilizar nombres de dominio, puede interactuar con servidores web, que un servidor DNS traduce en direcciones IP. localhost es el nombre de la dirección proporcionada cuando la computadora se conecta a la red, también conocida como dirección de loopback. También conocida como "Dirección IP interna 127.0.0.1", solo está disponible en la computadora local y no en ninguna red o Internet de la que formemos parte.
Todos los dispositivos conectados a la red tienen puertos estandarizados, cada uno con un número único. Hay muchos puertos reservados para protocolos específicos. Por ejemplo, el puerto 80 es el puerto predeterminado asignado para los mensajes del Protocolo de transferencia de hipertexto (HTTP).
Una dirección IP permite la transmisión de mensajes hacia y desde un dispositivo específico. Un número de puerto, por otro lado, permite que un servicio o aplicación específica se dirija a un dispositivo específico y actúe como puerta de enlace. Aquí usamos 8080 como nuestro número de puerto. Si el servidor se configuró correctamente, deberíamos poder acceder a él a través de http en http://localhost:8080 .
Luego de acceder al servidor, el siguiente paso será mostrar el mensaje. Para hacer esto necesitamos crear una función.
const requestLis = function (req, res) {
res.end("Hello world, this is my first web server using NodeJS");
};En Node.js, todas las funciones de escucha de solicitudes aceptan dos parámetros, req y res. La solicitud HTTP del usuario se captura en el objeto de solicitud, que corresponde al primer parámetro req. El objeto de respuesta en el segundo parámetro res (res) se utiliza para generar la respuesta HTTP devuelta al usuario. La función res.end() devuelve la respuesta HTTP al cliente.
const server = http.createServer(requestLis);
server.listen(port, host, () => {
console.log(`Server is up and running on http://${host}:${port}`);
});Ahora, guarde el archivo y vaya a Powershell o Terminal y ejecute el siguiente comando
node web-server.jsAhora debería poder ver la siguiente información en PowerShell/Terminal.
Server is up and running on http://localhost:8080Cargue archivos HTML usando NodeJS:
Usando el módulo fs que discutimos en la sección anterior, podemos cargar archivos HTML y usar sus datos al escribir respuestas HTTP.
Cree un documento HTML que será devuelto por el servidor web.
index.htmlAgregue algo de código al archivo html para que la página web sea atractiva.
Importe fs-module.js escribiendo el siguiente código en su servidor web para utilizar la función readFile() necesaria para cargar archivos HTML.
const fs = require('fs').promises;Para cumplir con las mejores prácticas modernas de Javascript, utilizamos una variante de promesas, de ahí .promises.
Finalmente agregue el siguiente código a webserver.js.
Cree un servidor HTTP usando Express (marco Node.js)
Hay varios marcos, como Express.js y Koa.js, disponibles para Node.js. Estos marcos proporcionan una variedad de capacidades de middleware útiles, así como muchas otras características útiles que los desarrolladores pueden aprovechar en lugar de desarrollar ellos mismos. En este curso, exploraremos el marco Express.js y crearemos un servidor HTTP.
Para utilizar el marco Express, primero debe instalar Express. Para hacer esto, debe ir a Powershell/Terminal e ingresar el siguiente comando.
npm install expressLuego use la función require() para importar el esquema llamado express. Para utilizar el marco Express, primero debe importar un esquema llamado express usando la función require(). A continuación se muestra un ejemplo de cómo importar un módulo usando el marco Express.
const express = require('express');
const app = express();La función require() se llama inicialmente especificando el nombre del módulo como una cadena ('express') y luego se llama al objeto devuelto para crear la aplicación Express. Luego puede acceder a las propiedades y funciones del objeto de la aplicación.
Cree un nuevo archivo llamado app.js y use el siguiente código.
const express = require('express');
const app = express();
const port = 8000;
app.get('/', function(req, res) {
res.send('Hello World!')
});
app.listen(port, function() {
console.log(`Example app listening on port ${port}!`)
});Vaya a Powershell o Terminal y ejecute el código
node ./app.js