Prueba de implementación del entorno Spark On Yarn (usando pseudodistribución)
1. Trabajo previo
- La pseudodistribución de Hadoop está instalada, puede consultar: Pseudodistribución de construcción del entorno Hadoop2.7.3
- Para instalar la pseudodistribución de Spark, consulte: Construcción del entorno de modo autónomo Spark Standalone
2. Configurar Spark On Yarn
-
Modifique Yarn-site.xml y agregue la siguiente información
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> -
Reasigne el directorio de registro del servicio histórico de Spark a HDFS:
1) Cree el directorio del historial de registro del servicio histórico de Spark en HDFS y ejecute:
hdfs dfs -mkdir -p /training/spark-2.4.8-bin-hadoop2.7/history -
Modifique spark-env.sh al siguiente contenido:
export JAVA_HOME=/training/jdk1.8.0_171 # 改成你自己的主机名称 export SPARK_MASTER_HOST=niit-master export SPARK_MASTER_PORT=7077 #history 配置历史服务 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://niit-master:9000/training/spark-2.4.8-bin-hadoop2.7/history" # yarn YARN_CONF_DIR=/training/hadoop-2.7.3/etc/hadoopAviso:
spark.history.fs.logDirectory路径改成hdfs上的路径,即hdfs://niit-master:9000/training/spark-2.4.8-bin-hadoop2.7/history -
Modifique spark-defaults.conf al siguiente contenido:
spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop001:9000/training/spark-2.4.8-bin-hadoop2.7/historyAviso:
spark.eventLog.dir路径改成HDFS上的history路径,即hdfs://hadoop001:9000/training/spark-2.4.8-bin-hadoop2.7/history -
Reinicie el clúster de Hadoop (si Spark se inició antes, no necesita iniciar Spark)
1) Primero verifique si se ha iniciado Hadoop . Si es así, primero debe detenerlo y ejecutarlo:stop-all.sh
2) Reinicie o inicie Hadoop y ejecute :start-all.sh -
Inicie el servicio de historial de Spark (si ya inició Spark antes, no es necesario que lo inicie),
vaya al directorio de instalación de Spark, inicie el servicio de historial de Spark y ejecute:sbin/start-history-server.sh
3. Ejecute el caso Spark Pi
-
Ingrese al directorio de instalación de Spark y ejecute el siguiente comando para enviar el programa al clúster de Spark:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.4.8.jar 100 -
Consulte los resultados experimentales: puede ver el programa Spark en la interfaz de administración web de YARN.
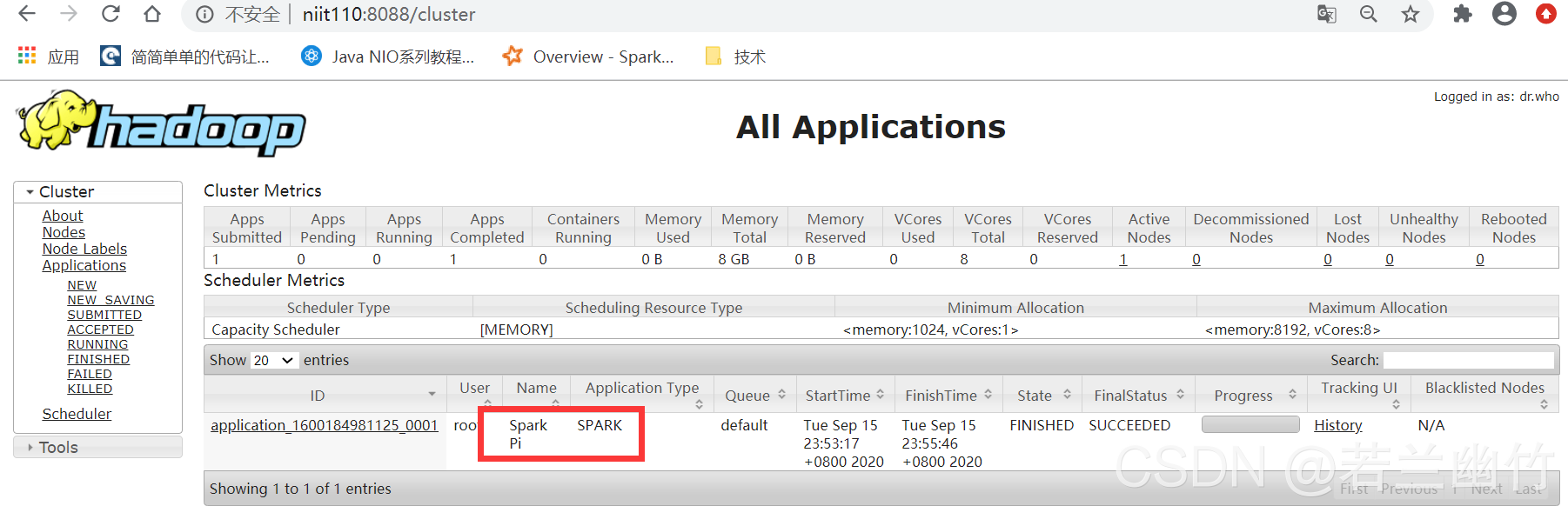
-
Ver el resultado del experimento 2 : verá la siguiente información en la interfaz web del servicio de historial de Spark:
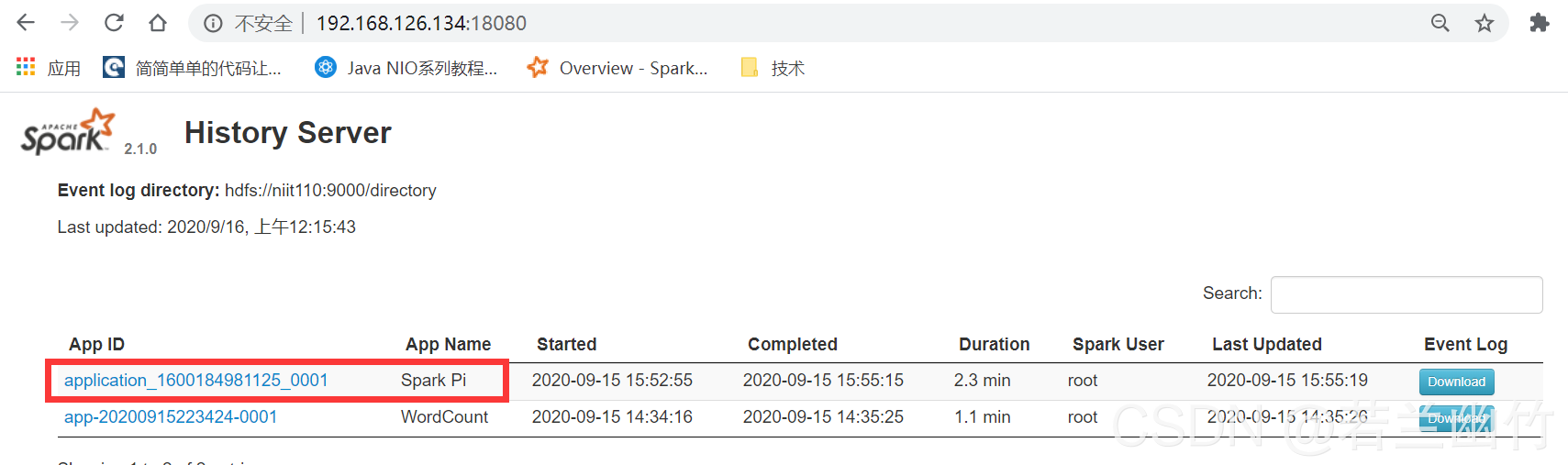
Prueba de implementación del entorno Spark On Yarn (usando pseudodistribución)
1. Trabajo previo
- La pseudodistribución de Hadoop está instalada, puede consultar: Pseudodistribución de construcción del entorno Hadoop2.7.3
- Para instalar la pseudodistribución de Spark, consulte: Construcción del entorno de modo autónomo Spark Standalone
2. Configurar Spark On Yarn
-
Modifique Yarn-site.xml y agregue la siguiente información
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> -
Reasigne el directorio de registro del servicio histórico de Spark a HDFS:
1) Cree el directorio del historial de registro del servicio histórico de Spark en HDFS y ejecute:
hdfs dfs -mkdir -p /training/spark-2.4.8-bin-hadoop2.7/history -
Modifique spark-env.sh al siguiente contenido:
export JAVA_HOME=/training/jdk1.8.0_171 # 改成你自己的主机名称 export SPARK_MASTER_HOST=niit-master export SPARK_MASTER_PORT=7077 #history 配置历史服务 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://niit-master:9000/training/spark-2.4.8-bin-hadoop2.7/history" # yarn YARN_CONF_DIR=/training/hadoop-2.7.3/etc/hadoopAviso:
spark.history.fs.logDirectory路径改成hdfs上的路径,即hdfs://niit-master:9000/training/spark-2.4.8-bin-hadoop2.7/history -
Modifique spark-defaults.conf al siguiente contenido:
spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop001:9000/training/spark-2.4.8-bin-hadoop2.7/historyAviso:
spark.eventLog.dir路径改成HDFS上的history路径,即hdfs://hadoop001:9000/training/spark-2.4.8-bin-hadoop2.7/history -
Reinicie el clúster de Hadoop (si Spark se inició antes, no necesita iniciar Spark)
1) Primero verifique si se ha iniciado Hadoop . Si es así, primero debe detenerlo y ejecutarlo:stop-all.sh
2) Reinicie o inicie Hadoop y ejecute :start-all.sh -
Inicie el servicio de historial de Spark (si ya inició Spark antes, no es necesario que lo inicie),
vaya al directorio de instalación de Spark, inicie el servicio de historial de Spark y ejecute:sbin/start-history-server.sh
3. Ejecute el caso Spark Pi
-
Ingrese al directorio de instalación de Spark y ejecute el siguiente comando para enviar el programa al clúster de Spark:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.4.8.jar 100 -
Consulte los resultados experimentales: puede ver el programa Spark en la interfaz de administración web de YARN.
-
Ver el resultado del experimento 2 : verá la siguiente información en la interfaz web del servicio de historial de Spark: