Tabla de contenido
1. yum: herramienta de gestión de paquetes de software
1.3 actualización de la fuente yum
2.2 Operaciones básicas de vim
2.3 conjunto de comandos de modo normal de vim
2.4 conjunto de comandos del modo de final de línea de vim
Tres formas de crear archivos en extra2
extra3 vim admite el trabajo en múltiples ventanas
Configuración simple de extra4 vim
3.1 Demostración de uso de gcc/g++
3.3 Concepto y comprensión de bibliotecas dinámicas y estáticas.
4. make/Makefile: herramienta de compilación automatizada
4.1 Demostración del uso de make/makefile
4.2 Comprender los principios básicos de make/makefile
suplemento adicional make/makefile
5. Escribe un pequeño programa: barra de progreso.
5.0 Búfer, retorno de carro y avance de línea
5.1 Versión de principio simple
5.2 Versión práctica de ingeniería
5.3 Extensión del lenguaje C (embellecimiento de estilo)
7.1 ¿Qué es la depuración y la liberación?
Prefacio
Espero que lea este blog después de que tenga una comprensión básica de los comandos y permisos comunes de Linux y otras cuestiones básicas.
Cuando utilizamos el sistema operativo Windows o el sistema Android de nuestros teléfonos móviles, no siempre podemos utilizar algunas de las herramientas de software predeterminadas del sistema, ¿verdad? Es posible que queramos agregar algunas herramientas de desarrollo básicas como Word, Excel y PPT. A medida que seamos más competentes en su uso, es posible que también necesitemos algunas herramientas de desarrollo más potentes como PS, devC++ y Python. Incluso podemos descargar e instalar algunas. Juegos para enriquecer nuestra experiencia, nuestra vida online. Entonces echemos un vistazo a las herramientas básicas de desarrollo de Linux y cómo usarlas.
1. yum: herramienta de gestión de paquetes de software
1.1 Introducción a yum
Al instalar software en Linux, un método común es descargar el código fuente del programa y compilarlo para obtener un programa ejecutable. Pero esto es demasiado problemático (el código fuente en sí puede tener errores, compilar el código fuente es muy difícil para nosotros que estamos actualmente en la etapa de aprendizaje y el programa en sí puede depender de otros programas o bibliotecas de terceros), por lo que algunos personas Algunos software de uso común se compilan de antemano y se convierten en un paquete de software (que puede entenderse como un programa de instalación en Windows) y se colocan en un servidor. El paquete de software compilado se puede obtener fácilmente a través del administrador de paquetes de software e instalarlo directamente ( La esencia de la instalación es copiar el programa ejecutable a la ruta especificada). Algunos lectores pueden pensar inmediatamente: ¿no es esto como la tienda de aplicaciones u otro software de nuestros teléfonos móviles? El hecho es que los paquetes de software y los administradores de paquetes son como la relación entre "App" y "App Store".
yum (Yellow dog Updater, modificado) es un administrador de paquetes muy utilizado en Linux. Utilizado principalmente en Fedora, RedHat, Centos y otras distribuciones. Podemos obtener una descripción general de yum y la ecología de yum a través de la siguiente imagen.Sin embargo, dado que el servidor Linux está construido por extranjeros y la mayoría de los recursos que contiene también son proporcionados y compartidos por extranjeros, puede que no sea tan fácil para nosotros. obtener directamente estos recursos.(? Implica problemas de seguridad de la red). Por lo tanto, también se proporcionan algunas fuentes espejo en China. Generalmente utilizamos el comando yum para obtener enlaces de paquetes de software de fuentes espejo nacionales.
1.2 Uso de yum
Ahora podemos hacerlo en la práctica y descargar algunas instrucciones de software interesantes a través de yum.
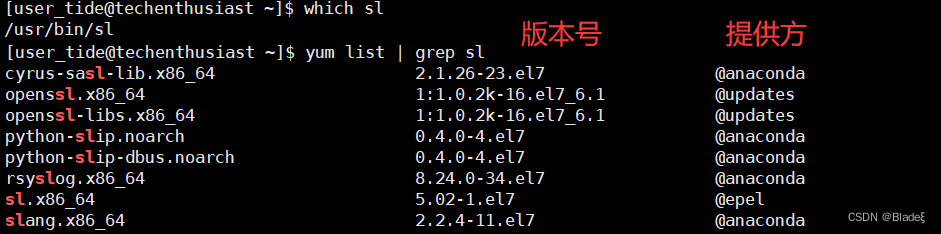
安装软件需要较高的权限,可以通过sudo或切换到root账号执行命令 安装指令:yum install -y sl 卸载指令:yum remove sl sl #此命令可以在屏幕上驶过一辆小火车 sl -c #显示有故障的小火车 sl -F #小火车驶过的过程中缓缓上升 读者可以自行搜索更多有趣的指令... 如果发现这些指令无法执行,可以先安装一个yum源插件 yum install -y epel-releaseComo se muestra en la imagen, si accidentalmente escribe el comando "ls" como "sl", un pequeño tren interrumpirá su trabajo.
El comando "yum list" puede enumerar qué paquetes de software están disponibles actualmente. Dado que la cantidad de paquetes de software puede ser muy grande, aquí podemos usar el comando grep para filtrar
1.3 actualización de la fuente yum
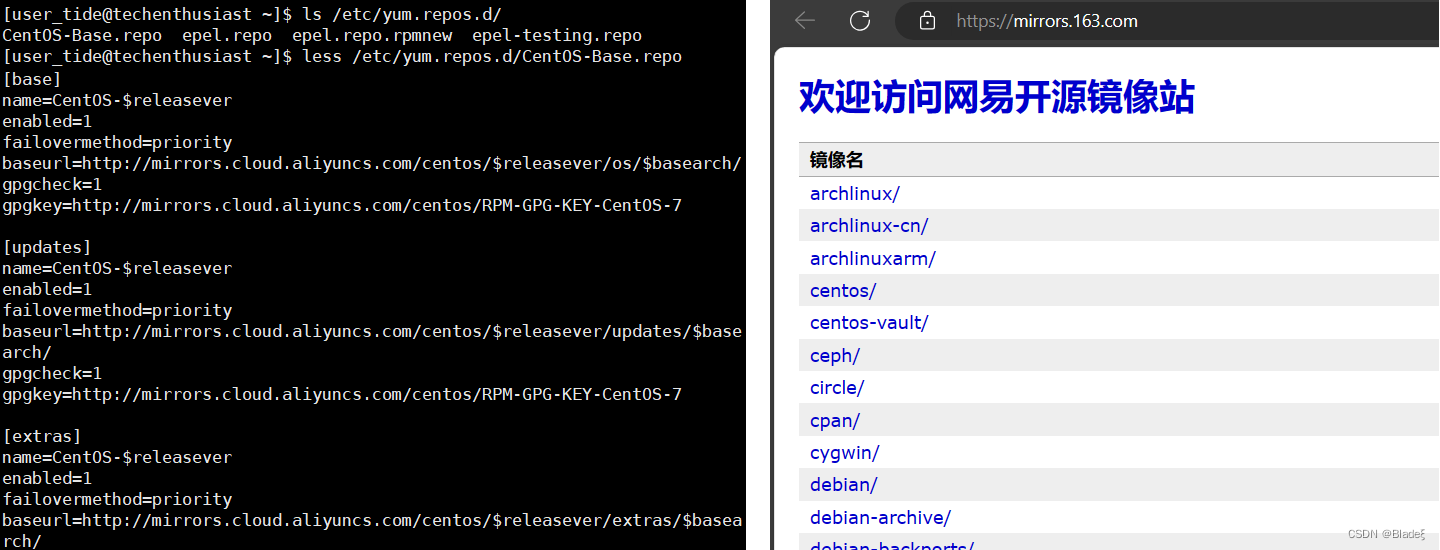
Si actualmente está utilizando un servidor en la nube, la fuente yum que está utilizando probablemente ya esté configurada. Si actualmente está utilizando una máquina virtual, la fuente de yum que puede estar utilizando no es nacional. Usamos CentOS7 como ejemplo para actualizar la fuente de yum. Si los lectores tienen otras confusiones, pueden buscar y leer información más profesional y detallada por sí mismos.
⭐进入yum源配置文件夹 cd /etc/yum.repos.d/ ⭐做好备份,以绝后患 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup ⭐获取国内的yum源 wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo (如果wget命令没有生效,输入yum -y install wget 安装wget工具) http://mirrors.aliyun.com 阿里镜像源域名 ⭐把国内的yum源,移动到对应的目录下 mv CentOS-Base.repo /etc/yum.repos.d/
2. vim - editor de texto
IDE (Entorno de desarrollo integrado) es un entorno de desarrollo integrado que se utiliza para proporcionar aplicaciones con un entorno de desarrollo de programas y que generalmente incluye herramientas como editores de código, compiladores, depuradores e interfaces gráficas de usuario. Generalmente escribimos código en el entorno de desarrollo integrado bajo el sistema operativo Windows. En el sistema operativo Linux, cada paso, desde escribir código, compilar código hasta ejecutar código, puede ser independiente, lo que significa que podemos usar varios programas para ayudarnos a completar cada paso del proceso.
2.1 Conceptos básicos de vim
Primero echemos un vistazo a los tres modos más utilizados de vim, que son el modo comando, el
modo inserción y el modo última línea. Las funciones de cada modo se distinguen de la siguiente manera:
modo normal (modo normal)
, también llamado modo comando, controles el movimiento del cursor de la pantalla, o ingresa a otros modos de vim. En cualquier otro modo, presione la tecla "ESC" para regresar al modo de línea de comando (modo
Insertar)
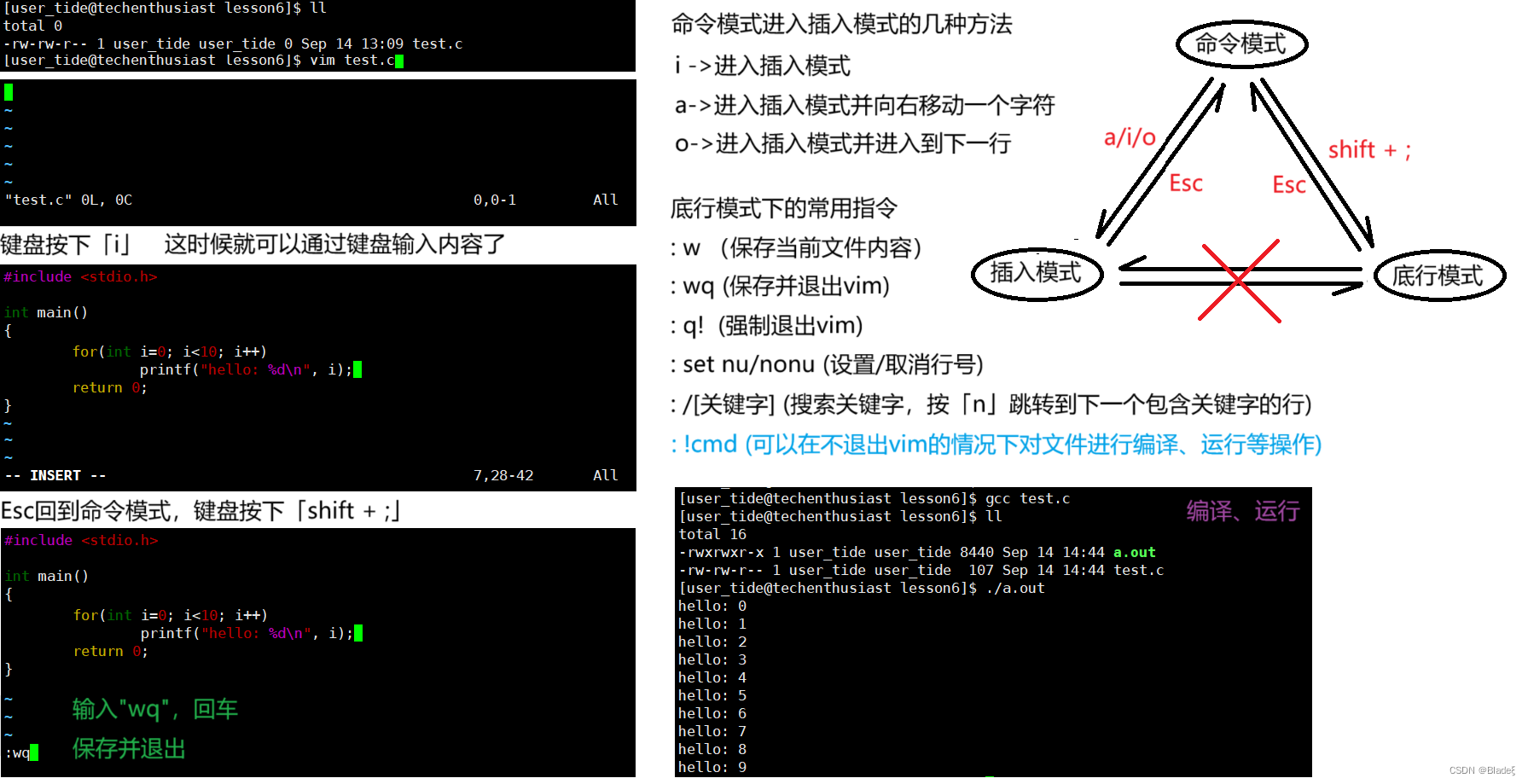
. En el modo de comando, presione la tecla "i" para ingresar a este modo. Solo en este modo puede ingresar contenido al archivo a través del teclado.
El modo de última línea (modo de última línea)
también se llama modo de línea inferior. En el modo de comando, presione las teclas "shift" + ";" para ingresar a este modo. En este modo, puede guardar o salir de archivos, reemplazar archivos, buscar cadenas, enumerar números de línea, etc.Vea todos sus modos: abra vim, ingrese directamente al modo final: ayuda vim-modes
2.2 Operaciones básicas de vim
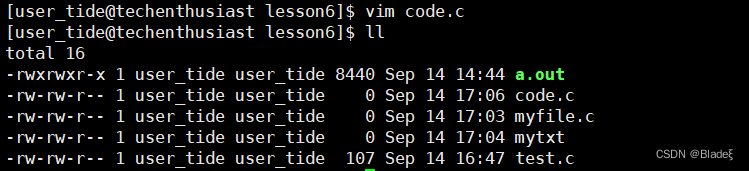
Ingrese el comando $vim test.c para editar el archivo test.c a través de la herramienta vim. Generalmente, después de ingresar a vim, estas operaciones breves modo normalen
De hecho, en los primeros años, las computadoras no tenían mouse, solo podíamos editar texto ingresando comandos en el teclado, y nació vim. Si solo escribe código, vim definitivamente no es tan bueno como algunos de los programas que usamos habitualmente, pero vim también tiene sus propias ventajas.2.3 conjunto de comandos de modo normal de vim
⭐插入模式 按「i」切换进入插入模式「insert mode」,从光标当前位置开始编辑 按「a」进入插入模式后,从光标所在位置的后一个位置开始编辑 按「o」进入插入模式后,在光标所在位置的下面插入新的一行,并从行首开始编辑 从插入模式切换到命令模式 按「ESC」键 ⭐移动光标 vim可以直接用键盘上的光标来上下左右移动, 但标准情况下vim使用的是小写英文字母「h」-> "←"「j」-> "↓"「k」-> "↑"「l」-> "→" 按[gg]:进入到文本的开始位置 按[shift+g]/「G」:移动到文本的结尾位置 按[n+shift+g]/「G」:移动到文本的第n行 按「$」:移动到光标所在行的“行尾” 按「^」:移动到光标所在行的“行首” 按「#l」:光标移到该行的第#个位置,如:5l,56l 按「w」:光标跳到下个word的开头 按「b」:光标回到上个word的开头 按「e」:光标跳到下个word的末尾 按「ctrl」+「b」:屏幕往“后”移动一页 按「ctrl」+「f」:屏幕往“前”移动一页 按「ctrl」+「u」:屏幕往“后”移动半页 按「ctrl」+「d」:屏幕往“前”移动半页 ⭐复制粘贴 「yy」: 复制 光标所在行 「#yy」:复制 从光标所在行开始的共#行文本 「yw」: 复制 从光标所在位置开始到字尾 「#yw」:复制 从光标所在位置开始的共#个字 「dd」: 剪切 光标所在行 「#dd」:剪切 从光标所在行开始的共#行文本 「p」: 粘贴 缓冲区里的文本到光标所在位置 「#p」:粘贴 重复进行粘贴操作#次 注意:所有与“y”有关的复制命令都必须与“p”配合才能完成复制与粘贴功能。 ⭐撤销上一次操作 「u」:撤销上一次操作 「ctrl + r」: 取消上一次的撤销操作 ⭐删除文字 「x」: 删除 光标所在位置的一个字符 「#x」:删除 从光标所在位置开始的共#个字符 「X」: 删除 光标所在位置的前一个字符(大写的X) 「#X」:删除 从光标所在位置开始(向前数)的共#个字符 ⭐替换 「r」: 替换 光标所在位置的字符 「#r」:替换 从光标所在位置开始的共#个字符 「R」:进入替换模式(替换光标所在位置的字符),「ESC」键回到命令模式 ⭐更改 「cw」: 更改 光标所在位置的字到字尾 「c#w」:更改 从光标所在位置开始的共#个字到字尾 「shift + ~」:大小写互换(长按shift,点按~,光标右移并把光标选中的字符大小写互换)2.4 conjunto de comandos del modo de final de línea de vim
Antes de usar el modo de última línea, recuerde presionar la tecla "ESC" para asegurarse de que está en el modo normal y luego presione los dos puntos ":" para ingresar al modo de última línea.
⭐列出行号 「set nu」: 输入「set nu」后,会在文件中的每一行前面列出行号 ⭐跳到文件中的某一行 「#」:「#」表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了 如输入数字15,再回车,就会跳到文章的第15行 ⭐查找字符 「/关键字」: 先按「/」键,再输入想寻找的字符串,如果第一次找的关键字不是想要的, 可以一直按「n」会往后寻找到您要的关键字为止。 「?关键字」:先按「?」键,再输入想寻找的字符串,如果第一次找的关键字不是想要的, 可以一直按「n」会往前寻找到您要的关键字为止。 ⭐保存文件 「w」: 在冒号后输入字母「w」就可以将文件保存起来 ⭐离开vim 「q」:按「q」就是退出,如果无法离开vim,可以在「q」后跟一个「!」强制离开vim 「wq」:一般建议离开时,搭配「w」一起使用,这样在退出的时候还可以保存文件Mapa de teclas vi/vim (la imagen proviene de una búsqueda en Internet)
suplemento de vitalidad extra
comentarios de lote extra1
En el modo de comando, presione "Ctrl + v" para ingresar al modo de visualización.- -BLOQUEO VISUAL-- aparece en la esquina inferior izquierda , indicando que actualmente se encuentra en el modo de visualización .
1. "Ctrl + v" para ingresar al modo de visualización
2. "j", "k" selecciona el área arriba y abajo
3.「mayús + i」
4. // Comentario de doble barra
5. Esc para completar el procesamiento por lotes
Eliminar comentarios en lotes:
1. "Ctrl + v" para ingresar al modo de visualización
2. "h, j, k, l" selecciona el área arriba, abajo, izquierda y derecha
3. "d" eliminar comentario
Tres formas de crear archivos en extra2
1. toque el nombre del archivo
2. Ingrese redirección>miarchivo.c
3. código vim.c
Utilice vim para abrir un archivo inexistente, luego guárdelo y salga para crear un archivo nuevo.
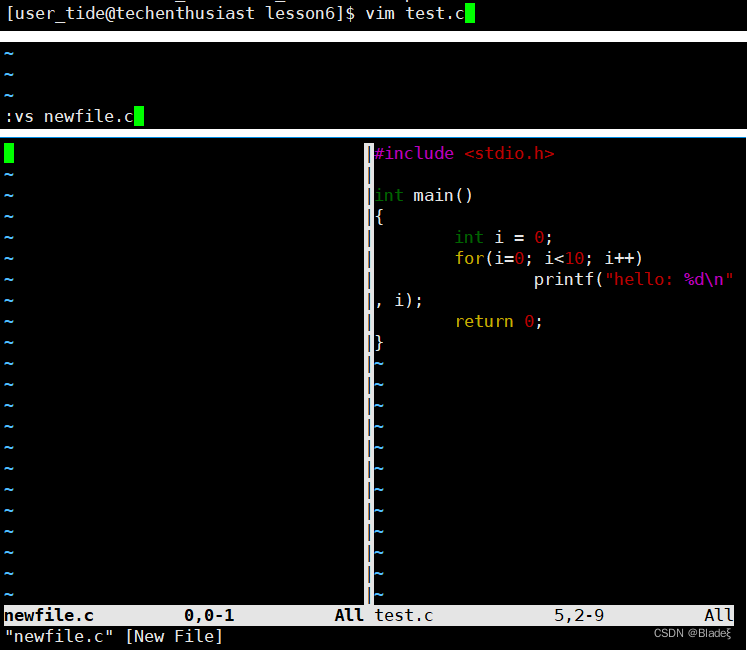
extra3 vim admite el trabajo en múltiples ventanas
En el modo de línea inferior, ingrese: vs + nombre de archivo para agregar una ventana. El área donde está el cursor indica en qué archivo está trabajando actualmente. "Ctrl + w + w" puede cambiar entre varias ventanas.
Configuración simple de extra4 vim
1. Configuración básica
Primero tengamos una comprensión preliminar del principio de configuración de vim: cuando vim se inicia, escaneará automáticamente el archivo .vimrc en el directorio /home del usuario actual (crea uno si no existe) para crear las opciones dentro del archivo . el archivo vimrc surta efecto. De hecho, el núcleo de la configuración de vim es agregar más opciones de configuración al archivo .vimrc (los lectores pueden buscar en línea qué opciones de configuración de vim están disponibles y agregarlas personalmente).
2. Instale el complemento
Si existen requisitos más altos, es posible que la configuración nativa no sea completamente funcional y puede optar por instalar complementos para completar la configuración. De manera similar, primero debemos crear un directorio .vim para almacenar los complementos de vim.
El principio de instalación de complementos es similar a la configuración básica, pero la operación es más complicada y diversa, y los posibles problemas son infinitos. El artículo tiene una extensión limitada y no se presentará en detalle. Si los lectores están interesados, pueden Busque algunos tutoriales relacionados en Internet.



3. gcc/g++ - compilador
A través del aprendizaje anterior, ya podemos usar vim para escribir código (puedes configurar tu vim para que escribir código sea más cómodo). A continuación, les presentaré el compilador gcc/g++ comúnmente utilizado en Linux (gcc/g++ se puede usar para compilar el lenguaje C, y solo g++ se puede usar para compilar C++)
3.1 Demostración de uso de gcc/g++
Primero, demostrémoslo a través del funcionamiento real (si su Linux actualmente no tiene gcc/g++ instalado, instálelo con yum install gcc o yum install gcc-c++. Una vez completada la instalación, gcc/g++ verifica si la instalación se realizó correctamente)
Nota: En los sistemas Linux, los sufijos de archivos no tienen sentido, pero eso no significa que a gcc/g++ no le importen los sufijos de archivos. Un sufijo de archivo incorrecto hará que falle la compilación de gcc/g++
3.2 Traducción de programas
Archivo fuente->Preprocesamiento->Compilar->Ensamblaje->Enlace->Programa ejecutable
Nota: ¡El siguiente contenido es sólo para comprensión! Comprender este proceso puede ayudarnos a comprender mejor la traducción de programas.
⭐Preprocesamiento _
Primero llevamos a los lectores a través de las operaciones reales para aprender las instrucciones requeridas para las operaciones correspondientes y comparar los códigos antes y después del preprocesamiento.
Echemos un vistazo al efecto de preprocesamiento de un fragmento de código.
Mediante la compilación condicional, se puede lograr una adaptación dinámica del código.
En la vida real existen muchos softwares que abren diferentes funciones según la identidad del usuario, como por ejemplo: Visual Studio, idea, Xshell, VMware... Muchos softwares tienen ediciones personales/gratuitas/comunitarias y ediciones profesionales. La versión tiene funciones completas y es suficiente para nuestro aprendizaje y uso general; la versión profesional tiene funciones muy ricas, pero se cobrará una cierta tarifa. Si abre una empresa y desarrolla un software similar, ¿cree que el código fuente detrás de este software debe mantenerse en dos copias (un código fuente para la versión gratuita y un código fuente para la versión profesional)? Obviamente es un código. Podemos usar la compilación condicional para hacer que un código desempeñe dos funciones diferentes (versión gratuita y versión profesional) al mismo tiempo, lo que puede ahorrar más costos de recursos.
⭐Compilar
⭐Recopilación _
⭐Resumen _
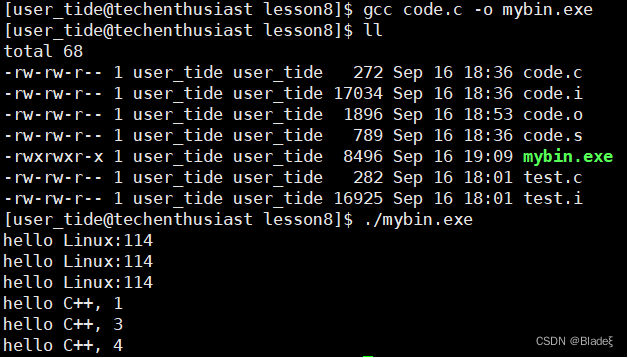
Es posible que tenga muchas dudas después de leer la introducción y el análisis anteriores, pero solo hay una instrucción que debemos aprender:
gcc code.c -o mybin.exeConsejos: si no recuerda las opciones de comando correspondientes al preprocesamiento, compilación y ensamblaje, puede mirar "Esc" en la esquina superior izquierda del teclado.
3.3 Concepto y comprensión de bibliotecas dinámicas y estáticas.
En 3.2, solo introdujimos el preprocesamiento, la compilación y el ensamblaje en la traducción del programa. A continuación, presentaremos los enlaces en detalle . De hecho, todo el código que hemos escrito hasta ahora está sobre los hombros de gigantes (alguien ya ha escrito una interfaz funcional para nosotros que se puede usar directamente), solo necesitamos incluir un archivo de encabezado y no requiere ningún esfuerzo Utilice las funciones internas. Por supuesto, estos archivos de encabezado han sido preinstalados en un directorio bajo nuestro Linux.
Antes de explicar qué es un enlace, primero debemos comprender un nuevo concepto: biblioteca de funciones.
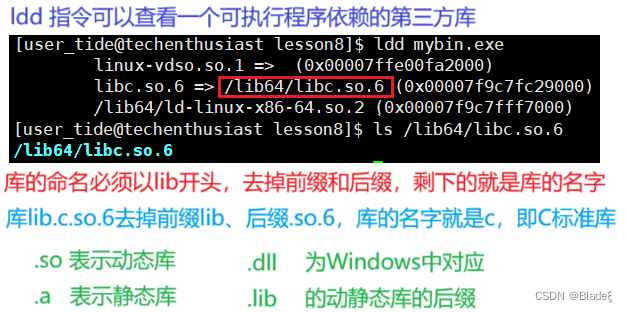
En nuestro programa C, la implementación de la función "printf" no está definida, y el "stdio.h" incluido en la precompilación solo tiene la declaración de la función y no está definida la implementación de la función. Entonces, ¿dónde está la implementación de "printf" "¿Qué pasa con las funciones?
El sistema coloca la implementación de estas funciones en un archivo de biblioteca llamado libc.so.6. Si no se especifica, gcc buscará
en la ruta de búsqueda predeterminada del sistema "/usr/lib", es decir, vincular a la función de biblioteca libc.so.6, de modo que se pueda usar la función "printf", y esta es la función del enlace .El programa ejecutable que obtenemos = el código que escribimos + archivos de encabezado + bibliotecas
Los archivos de encabezado y las bibliotecas son esencialmente archivos. La llamada creación de un entorno de desarrollo significa esencialmente descargar, instalar y copiar los archivos de encabezado y las bibliotecas en una ruta específica en el entorno de desarrollo (debe ser encontrada por el propio compilador).
Echemos un vistazo más de cerca al concepto de bibliotecas dinámicas y estáticas.
Biblioteca dinámica (enlace dinámico) : es una colección de todos los métodos proporcionados por C/C++ u otros terceros, que están vinculados por todos los programas ( todas las funciones de la biblioteca tienen direcciones de entrada. El llamado enlace dinámico es en realidad La función La dirección de la biblioteca que se va a vincular se copia en una ubicación específica de nuestro programa ejecutable)
Biblioteca estática (enlace estático) : es una colección de todos los métodos proporcionados por C/C++ u otros terceros y todos los programas la copian para copiar el código requerido en sus propios programas ejecutables .
Ventajas y desventajas de la vinculación dinámica y estática :
El programa ejecutable formado por enlaces dinámicos ocupa menos espacio y ahorra recursos. Sin embargo, una vez que la biblioteca dinámica desaparece, todos los programas que dependen de esta biblioteca no podrán ejecutarse. Los enlaces estáticos se pueden ejecutar de forma independiente y no dependen de la biblioteca. , pero ocupa más espacio Grande, relativamente desperdiciador de recursos.
Consejos: Si está utilizando un servidor en la nube, generalmente el sistema no tiene enlaces estáticos instalados, si es necesario, consulte las instrucciones a continuación.
sudo yum install -y glibc-static # 安装C静态库 sudo yum install -y libstdc++-static # 安装C++静态库



4. make/Makefile: herramienta de compilación automatizada
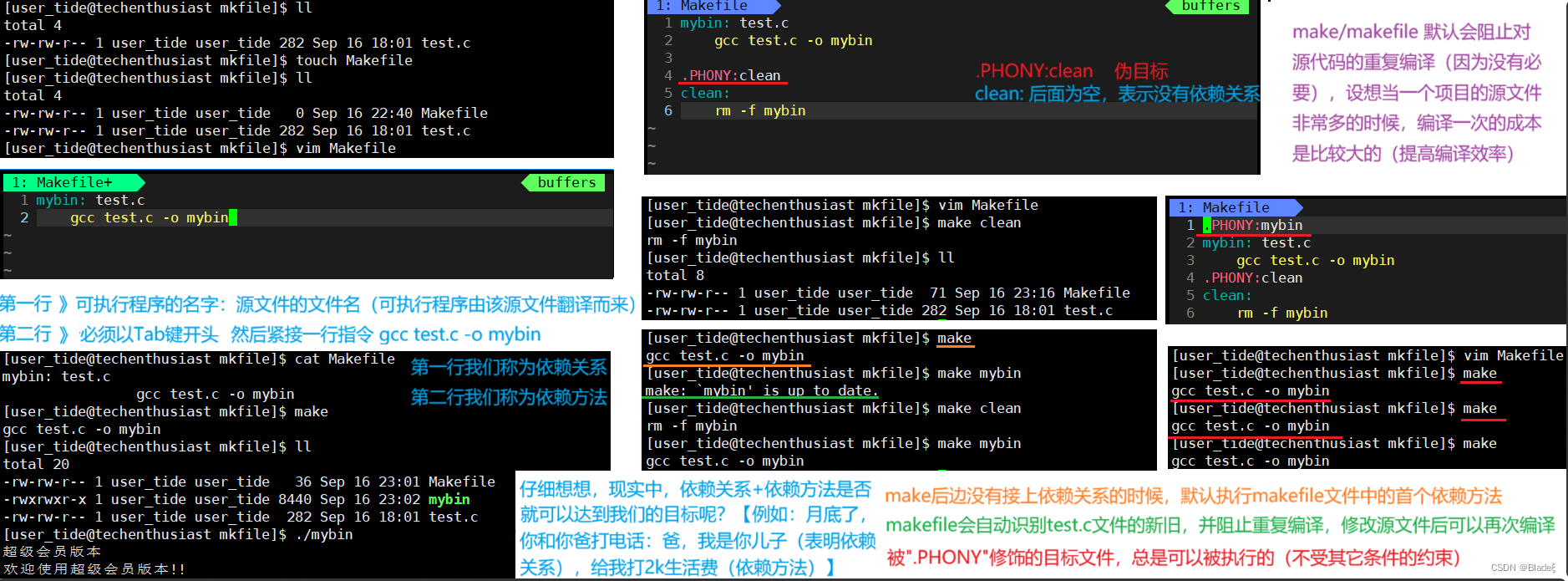
Make es un comando y makefile es un archivo de texto con un formato específico que existe en el directorio actual. Utilice los dos juntos para completar la construcción automatizada del proyecto (los archivos fuente de un proyecto no se cuentan y se dividen en tipos, funciones y módulos . Ubicados en varios directorios respectivamente, los archivos MAKE definen una serie de reglas para especificar qué archivos deben compilarse primero, qué archivos deben compilarse más tarde, qué archivos deben compilarse nuevamente y funciones aún más complejas. operaciones La llamada compilación automatizada, es decir, solo se necesita un comando de creación y todo el proyecto se compila de forma completamente automática, lo que mejora enormemente la eficiencia del desarrollo de software)
4.1 Demostración del uso de make/makefile
Primero, llevemos a los lectores a través de operaciones prácticas para comprender los puntos de conocimiento detallados.
4.2 Comprender los principios básicos de make/makefile
A continuación, echemos un vistazo a los principios básicos de make/makefile.
⭐ ¿ Cómo identifica make/makefile los archivos nuevos y antiguos ? ¿Cómo entender el significado de la frase que dice que los archivos de destino modificados con "PHONY" siempre se pueden ejecutar ?
⭐ make/makefile es capaz de derivar dependencias
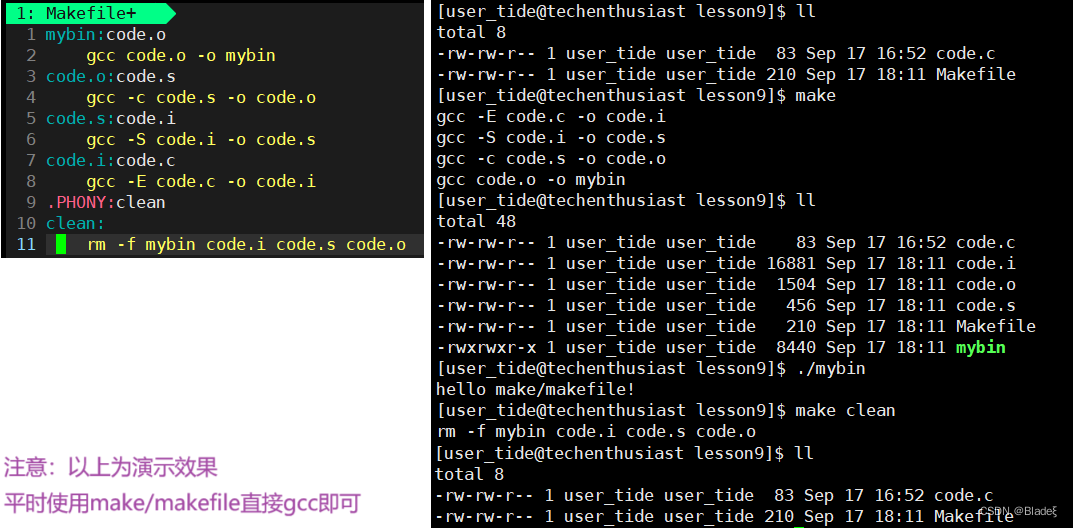
Cuando ejecutamos el comando make, make buscará un archivo llamado "Makefile" o "makefile" en el directorio actual. Si se encuentra un archivo MAKE, busca el primer archivo de destino (mybin) en el archivo de arriba a abajo. Si el archivo no existe, o la hora de modificación del archivo code.o del que depende mybin es más reciente que el archivo de destino (puede usar touch para probar), el comando definido más adelante se ejecutará para generar el archivo mybin. Por analogía, si el archivo code.o del que depende mybin no existe, entonces make continuará buscando dependencias dirigidas al archivo code.o en el archivo actual. Si lo encuentra (code.s), lo implementará gradualmente. atrás de acuerdo con la relación de dependencia., hasta que se genere el archivo mybin. Esta es la capacidad de derivación de las dependencias make/makefile . Make buscará las dependencias de archivos capa por capa hasta que finalmente se compile el primer archivo de destino. Nota: Durante el proceso de búsqueda de archivos, si ocurre un error (por ejemplo, no se puede encontrar el último archivo dependiente), make finalizará directamente la búsqueda y repetirá el mensaje de error. make solo tiene la capacidad de deducir dependencias de archivos. Si el archivo después de los dos puntos no existe después de encontrar las dependencias, make no hará nada.
suplemento adicional make/makefile

5. Escribe un pequeño programa: barra de progreso.
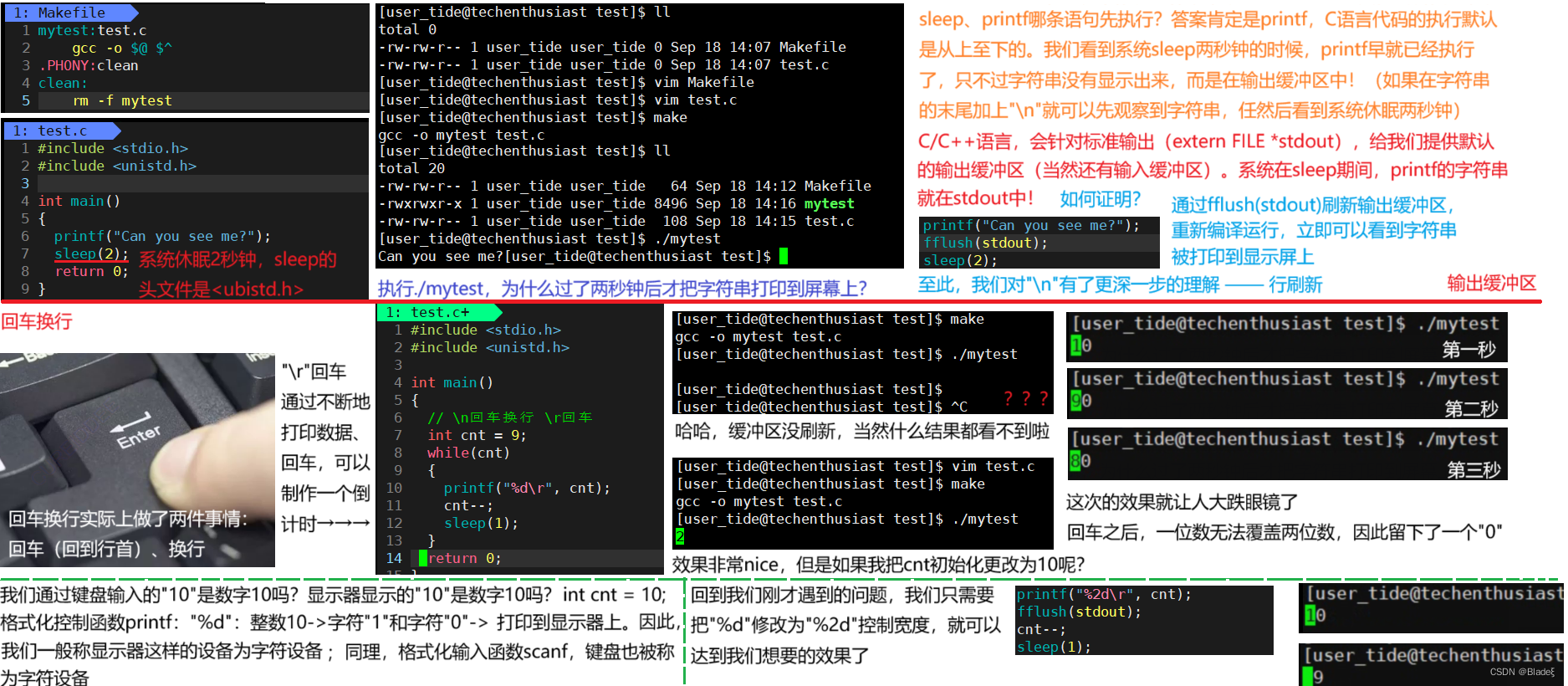
5.0 Búfer, retorno de carro y avance de línea
5.1 Versión de principio simple
Primero tengamos una breve descripción general de la estructura del código.
A continuación, lo guiaré paso a paso para implementar una versión simple de la barra de progreso.
Por supuesto, esto es solo una barra de progreso y realmente no cumple su función (mostrar el progreso de las tareas de descarga e instalación en tiempo real). Si está interesado en el código fuente, lo he compartido a continuación, pero no se vaya. , la versión de práctica de ingeniería La barra de progreso tiene un significado más práctico y es más digna de nuestro estudio.
FILE->main.c #include "process.h" int main() { process(); return 0; } /// FILE->process.h #pragma once #include <stdio.h> void process(); /// FILE->process.c #include "process.h" #include <string.h> #include <unistd.h> #define SIZE 101 #define MAX_RATE 100 #define STYLE '#' #define SLEEPTIME 1000*200 const char *str="|/-\\"; void process() { // version 1 int rate=0; //char bar[SIZE] = {0}; char bar[SIZE]; memset(bar, '\0', sizeof(bar)); int len = strlen(str); while(rate <= MAX_RATE) { printf("[%-100s][%d%%][%c]\r", bar, rate, str[rate%len]); fflush(stdout); usleep(SLEEPTIME); bar[rate++] = STYLE; } printf("\n"); }
5.2 Versión práctica de ingeniería
Si necesita que la barra de progreso coincida con la tarea de descarga e instalación real, no puede imprimir la barra de progreso de una vez, sino que debe actualizar la barra de progreso en tiempo real según el progreso de la tarea.
código fuente:
FILE->main.c #include "process.h" #define TARGET_SIZE 1024*1024 // 1M #define DSIZE 1024*10 // 10kb // 模拟下载 void download(callback_t cb) { int target = TARGET_SIZE; int total = 0; while(total < target) { // 休眠模拟下载花费的时间 usleep(SLEEPTIME); total += DSIZE; int rate = total*100/target; cb(rate); // 回调函数 } printf("\n"); } int main() { download(process_v2); return 0; } /// FILE->process.h #pragma once #include <stdio.h> #include <string.h> #include <unistd.h> #define MAX_RATE 100 #define SIZE 101 #define STYLE '#' #define SLEEPTIME 1000*200 typedef void (*callback_t)(int); void process_v1(); void process_v2(int rate); /// FILE->process.c #include "process.h" const char *str="|/-\\"; void process_v2(int rate) { // version 2 static char bar[SIZE] = {0}; int len = strlen(str); if(rate <= MAX_RATE && rate >= 0) { printf("[%-100s][%d%%][%c]\r", bar, rate, str[rate%len]); fflush(stdout); bar[rate] = STYLE; } if(rate == MAX_RATE) memset(bar, '\0', sizeof(bar)); }
5.3 Extensión del lenguaje C (embellecimiento de estilo)
El código es liviano y solo sirve como referencia. Si es necesario, se recomienda a los lectores que busquen un código mejor en línea.
FILE->main.c #include "process.h" #define TARGET_SIZE 1024*1024 // 1M #define DSIZE 1024*10 // 10kb // 模拟下载 void download(callback_d cb) { int testcnt = 80; int target = TARGET_SIZE; int total = 0; while(total <= target) { usleep(SLEEPTIME); total += DSIZE; double rate = total*100.0/target; // 测试进度条停滞的情况,稍等几秒 if(rate > 50.0 && testcnt) { total = target/2; testcnt--; } cb(rate); // 回调函数 } cb(MAX_RATE); printf("\n"); } int main() { download(process_v3); return 0; } /// FILE->process.h #pragma once #include <stdio.h> #include <string.h> #include <unistd.h> #define MAX_RATE 100 #define SIZE 101 #define STYLE '#' #define STYLE_BODY '=' #define STYLE_HEADER '>' #define SLEEPTIME 1000*60 typedef void (*callback_t)(int); typedef void (*callback_d)(double); void process_v1(); void process_v2(int); void process_v3(double); /// FILE->process.c #include "process.h" const char *str="|/-\\"; void process_v3(double rate) { // version 3 static char bar[SIZE] = {0}; static int cnt = 0; int len = strlen(str); if(rate <= MAX_RATE && rate >= 0) { cnt++; cnt %= len; printf("加载中...\033[44m%-100s\033[0m[%.1f%%][%c]\r", bar, rate, str[cnt]); fflush(stdout); if(rate < MAX_RATE) { bar[(int)rate] = STYLE_BODY; bar[(int)rate+1] = STYLE_HEADER; } else { bar[(int)rate] = STYLE_BODY; } } if(rate == MAX_RATE) memset(bar, '\0', sizeof(bar)); } // v3 优化了旋转光标,v2旋转光标依赖于rate,故进度条停滞会导致光标停止旋转 // 优化了rate的数据类型<double> // 解释printf中的"\033[44m%-100s\033[0m" \033[44m到\033[0之间的区域染为蓝色Resultados de la prueba:

6. Conozca git/gitee/github
Debido a la extensión limitada del artículo, el autor solo presenta las instrucciones básicas más utilizadas y ayuda a los lectores a comprender los principios básicos de git.
6.1 ¿Qué es git?
Git (El rastreador de contenido estúpido, rastreador de contenido estúpido . Así es como Linus Torvalds nos presentó Git.) es un sistema de control de versiones distribuido de código abierto que puede manejar la gestión de versiones de proyectos desde proyectos muy pequeños hasta proyectos muy grandes de manera efectiva y a alta velocidad . [1] También es un software de control de versiones de código abierto desarrollado por Linus Torvalds para ayudar a gestionar el desarrollo del kernel de Linux .
——Extraído de la Enciclopedia Baidu
Entonces, ¿ qué es un controlador de versiones ? Por poner un ejemplo popular, ahora que has escrito un blog y lo has publicado, unos días después le pides a tu profesor que te ayude a ver qué áreas se pueden mejorar. Después de escucharlo, sentiste que tenía sentido, así que fuiste a hacer algunos cambios importantes y luego le pediste consejo al maestro. Después de escuchar las sugerencias del maestro, hiciste algunos cambios más, pero al final el maestro dijo: Olvídate. La primera versión es más concisa y clara. ¿Qué debes hacer en este momento? Si guarda y registra cada versión de su blog, no tendrá que preocuparse por eso. Este método de guardar cada versión se puede llamar control de versiones manual, y el espacio utilizado para almacenar cada versión guardada se llama almacén . Git es un software que logra esta función a través de la automatización de la programación (administra el contenido guardado según los cambios y, en última instancia, proporciona varias versiones durante el proceso de cambio). Además, también necesita su propio sitio web: gitee/github.
6.2 Características de git
1. git es un software que es a la vez cliente y servidor
2. git solo registrará cambios en el contenido (no guardará todo el contenido en cada versión)
3. git es software distribuido y descentralizado
gitee/github es un sitio web creado en base al software git para visualizar versiones (reducir los costos de aprendizaje)
6.3 Uso de git
URL de casa rural/github:
Gitee: la plataforma de rendimiento de I+D de DevOps a nivel empresarial proporciona a las empresas soluciones integrales de gestión de I+D, que incluyen gestión de códigos, gestión de proyectos, colaboración de documentos, gestión de pruebas, CICD, medición del rendimiento y otros módulos, y admite SaaS, privatización y otras implementaciones. El método ayuda a las empresas a planificar y gestionar el proceso de I+D de forma ordenada y a mejorar la eficiencia y la calidad de la I+D.
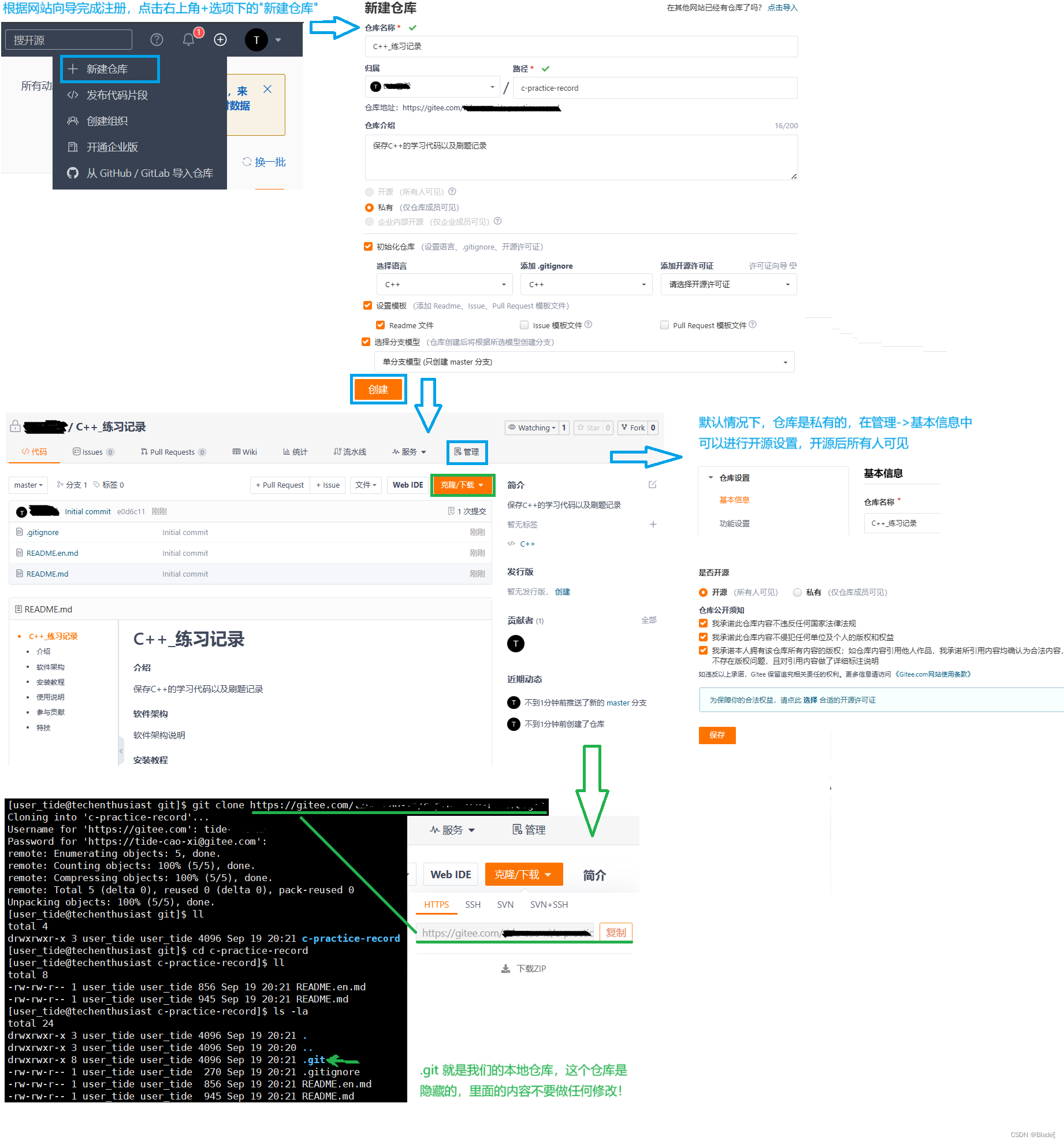
https://gitee.com/Tutorial ilustrado para crear un nuevo almacén y un enlace de código abierto para usuarios de Linux
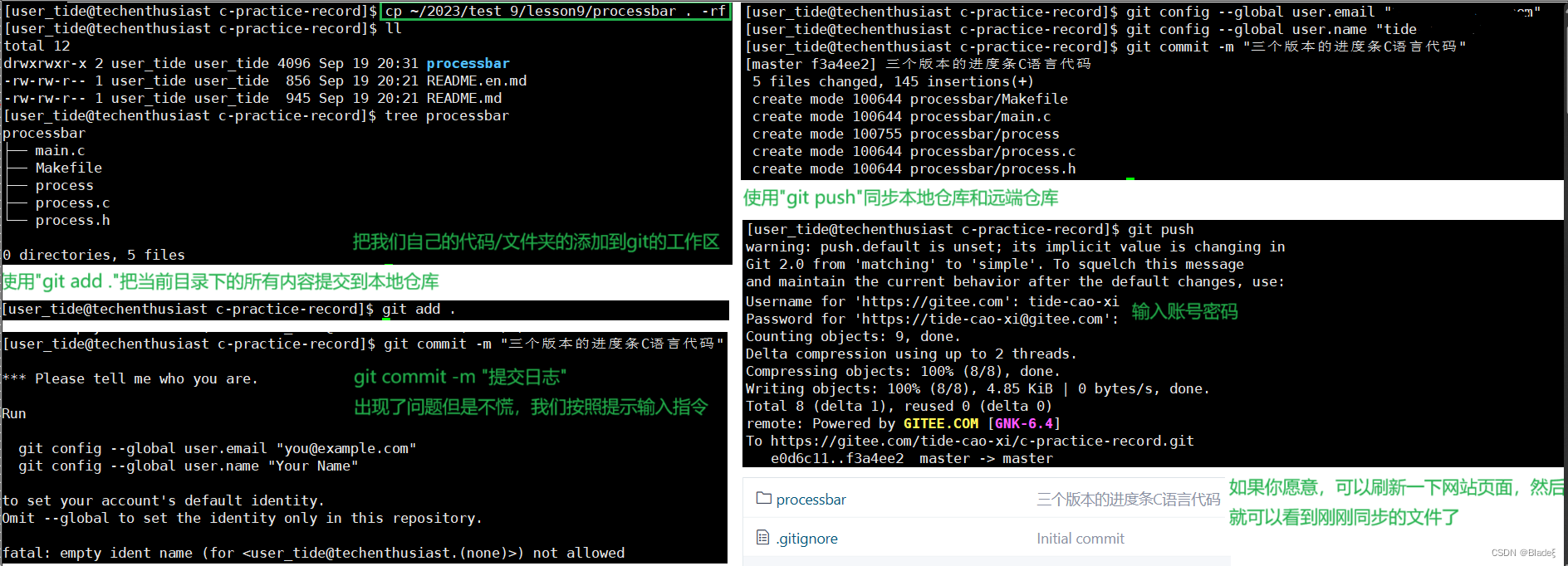
Después de completar las operaciones anteriores, introduzcamos los tres ejes de git.
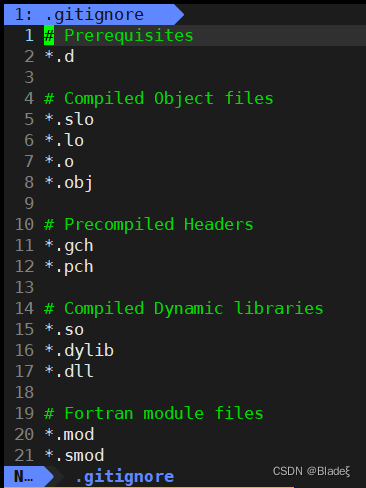
archivo .gitignore adicional
vim .gitignore puede abrir y editar archivos .gitignore. Cualquier tipo de archivo (en forma de sufijo) registrado en .gitignore no se enviará al almacén.

7. gdb - depurador
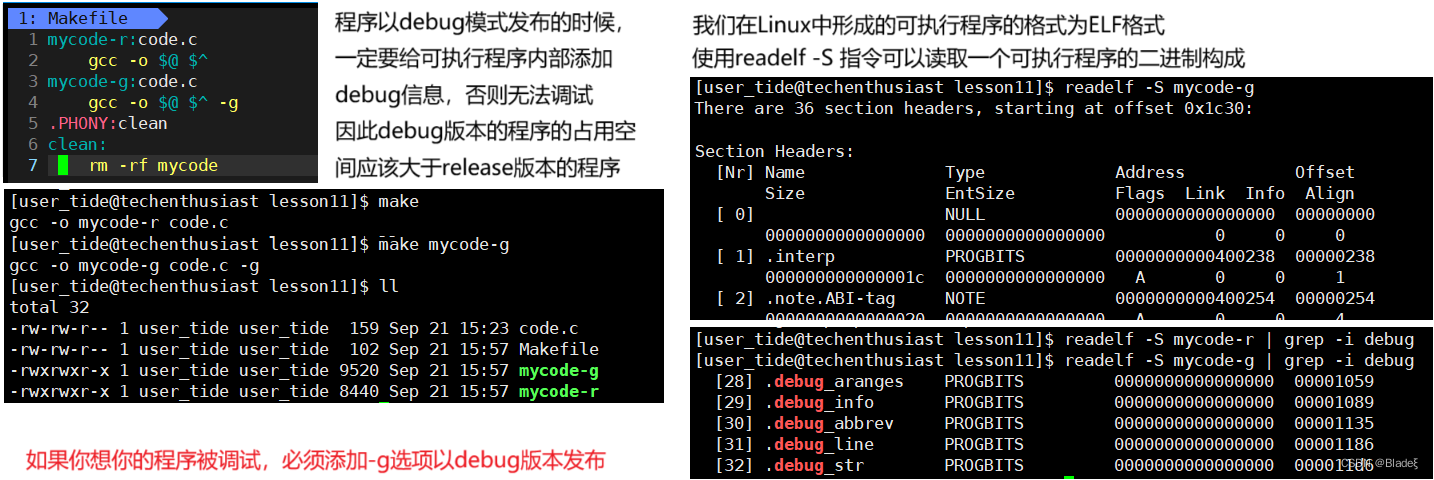
7.1 ¿Qué es la depuración y la liberación?
Hay dos formas de publicar un programa, modo de depuración y modo de publicación. Los programas ejecutables compilados por Linux gcc/g++ están en modo de lanzamiento de forma predeterminada. Si desea utilizar gdb para depurar, debe agregar la opción -g al modo de depuración al generar el programa ejecutable a partir del código fuente.
Observemos y demostremos más a fondo que existe una diferencia entre el modo de depuración y el modo de lanzamiento.
A algunas personas les puede parecer extraño, ¿por qué se necesitan dos versiones? ¿No es bueno que todos usen la versión de depuración? De hecho, los programas utilizados por los usuarios son todos versiones de lanzamiento, y la versión de lanzamiento ha realizado algunas optimizaciones en el código.
7.2 Usando gdb
Lista de comandos básicos comunes de gdb
gdb mybin # base ctrl d 或 quit:退出 list(l) 行号/函数名: 显示mybin的源代码,每次展示10行(或列出此函数的源代码) run(r): 运行程序/开始调试 next(n): 逐过程(会一步完成整个函数调用 step(s): 逐语句(会进入函数的内部 set var 变量名: 修改变量的值 (print)p 变量名: 打印变量的值 # 断点 break(b) 行号/函数名: 在此行(或此函数的第一条语句处)设置断点 info(i) n: 查看序号为n的断点的信息 delete(d) n: 删除序号为n的断点 disable n: 禁用序号为n的断点 enable n: 启用序号为n的断点 i/d b: 查看/删除所有断点 # 监视 display 变量名: 跟踪查看一个变量,每次停下来都显示它的值 undisplay 序号: 取消对序号指代的变量的跟踪 # 代码块定位 until 行号: 跳至该行 finish: 运行到当前函数的结尾 continue(c): 运行到下一断点处 # 堆栈 breaktrace(bt): 查看调用堆栈 info(i) locals: 查看当前栈帧局部变量的值 @0. | number 查看代码 @1. gdb会记录上一次使用的指令,可以通过Enter快捷使用上一次使用的指令 @2. 每次调试过程中,断点序号是递增的,一旦退出调试,所有断点都将被清除