Tabla de contenido
Métodos de procesamiento de texto proporcionados en sklearn
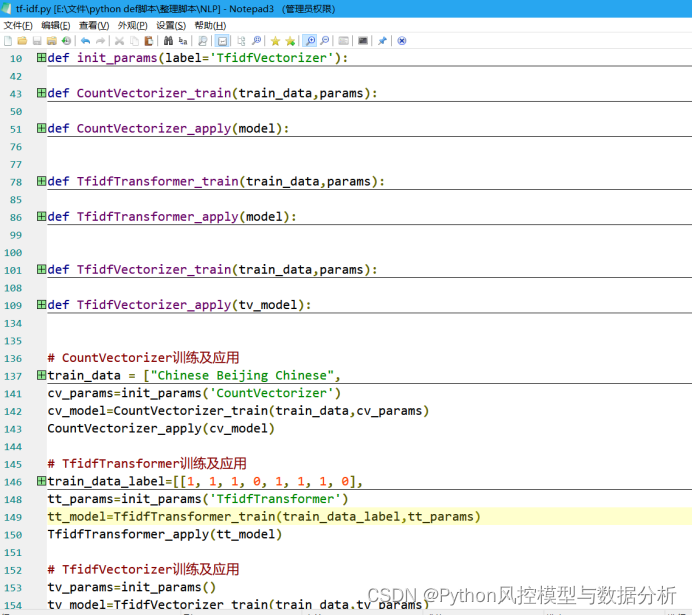
2. Inicialice los parámetros de entrenamiento del vector de frecuencia de palabras/tf_idf
3. Funciones de aplicación y entrenamiento de CountVectorizer
4. Utilice el vectorizador de conteo
5. Funciones de aplicación y entrenamiento de TfidfTransformer
6. Funciones de aplicación y entrenamiento de TfidfTransformer
Como uno de los métodos estadísticos comúnmente utilizados para la extracción de características estilísticas, tf-idf es adecuado para tareas de clasificación de texto. Este artículo explica tf-idf en detalle desde los principios, explicaciones detalladas de los parámetros y la implementación práctica. Después de dominar este artículo, podrá comience fácilmente y utilícelo para la clasificación de datos de texto.
1. Principio
tf representa la frecuencia de palabras (el número de veces que aparece una palabra en un determinado texto/el número de todas las palabras del texto), idf representa la frecuencia inversa del texto (el recíproco del número de textos que contienen una determinada palabra en el corpus, tomando el registro), tf-idf representa la frecuencia de palabras * frecuencia inversa del documento . tf-idf cree que la importancia de una palabra aumenta directamente con la cantidad de veces que aparece en el texto, pero al mismo tiempo disminuye inversamente con la frecuencia de su aparición en todo el corpus.
La expresión idf es la siguiente, donde k es el número de textos que contienen una determinada palabra y n es el número de textos en todo el corpus.
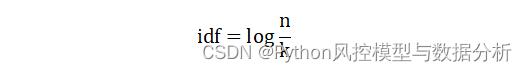
Suavizar idf para evitar valores máximos/mínimos (smooth_idf=True)
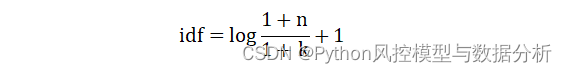
2. Combate real
Métodos de procesamiento de texto proporcionados en sklearn
(1) CountVectorizer : convierte una colección de documentos de texto en una matriz de frecuencia de palabras/frecuencia de caracteres e implementa tokenización (segmentación a nivel de caracteres + nivel de palabras), n-gramas, eliminación de palabras vacías, filtrado de palabras de alta frecuencia, y recuento de ocurrencias (estadísticas de frecuencia)
(2) TfidfTransformer : convierte la matriz de frecuencia de palabras / frecuencia de caracteres en una matriz tf o tf-idf estandarizada. Tf representa la frecuencia de palabras y tf-idf representa la frecuencia de palabras multiplicada por la frecuencia inversa del documento. A menudo se usa para la clasificación de texto.
(3) TfidfVectorizer: convierte directamente la colección de documentos originales en una matriz de características tf-idf, combinando todas las funciones de CountVectorizer y TfidfTransformer en un solo modelo.
Los resultados reales de la aplicación son los siguientes (1 gramo + 2 gramos):
Este artículo utiliza ejemplos prácticos para demostrar los métodos de uso y funciones de estas categorías, así como explicaciones detalladas de los parámetros para facilitar el uso propio bajo diferentes necesidades.

1. Paquete de guía
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer,TfidfVectorizer2. Inicialice los parámetros de entrenamiento del vector de frecuencia de palabras/tf_idf
Debido al problema de la combinación de funciones, el parámetro TfidfVectorizer = parámetro CountVectorizer + parámetro TfidfTransformer, la función del parámetro de inicialización resume las tres partes de los parámetros y establece la etiqueta del parámetro para determinar el diccionario de parámetros que debe devolverse.
def init_params(label='TfidfVectorizer'):
params_count={
'analyzer': 'word', # 取值'word'-分词结果为词级、'char'-字符级(结果会出现he is,空格在中间的情况)、'char_wb'-字符级(以单词为边界),默认值为'word'
'binary': False, # boolean类型,设置为True,则所有非零计数都设置为1.(即,tf的值只有0和1,表示出现和不出现)
'decode_error': 'strict',
'dtype': np.float64, # 输出矩阵的数值类型
'encoding': 'utf-8',
'input': 'content', # 取值filename,文本内容所在的文件名;file,序列项必须有一个'read'方法,被调用来获取内存中的字节;content,直接输入文本字符串
'lowercase': True, # boolean类型,计算之前是否将所有字符转换为小写。
'max_df': 1.0, # 词汇表中忽略文档频率高于该值的词;取值在[0,1]之间的小数时表示文档频率的阈值,取值为整数时(>1)表示文档频数的阈值;如果设置了vocabulary,则忽略此参数。
'min_df': 1, # 词汇表中忽略文档频率低于该值的词;取值在[0,1]之间的小数时表示文档频率的阈值,取值为整数时(>1)表示文档频数的阈值;如果设置了vocabulary,则忽略此参数。
'max_features': None, # int或 None(默认值).设置int值时建立一个词汇表,仅用词频排序的前max_features个词创建语料库;如果设置了vocabulary,则忽略此参数。
'ngram_range': (1, 2), # 要提取的n-grams中n值范围的下限和上限,min_n <= n <= max_n。
'preprocessor': None, # 覆盖预处理(字符串转换)阶段,同时保留标记化和 n-gram 生成步骤。仅适用于analyzer不可调用的情况。
'stop_words': 'english', # 仅适用于analyzer='word'。取值english,使用内置的英语停用词表;list,自行设置停停用词列表;默认值None,不会处理停用词
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b', # 分词方式、正则表达式,默认筛选长度>=2的字母和数字混合字符(标点符号被当作分隔符)。仅在analyzer='word'时使用。
'tokenizer': None, # 覆盖字符串标记化步骤,同时保留预处理和 n-gram 生成步骤。仅适用于analyzer='word'
'vocabulary': None, # 自行设置词汇表(可设置字典),如果没有给出,则从输入文件/文本中确定词汇表
}
params_tfidf={
'norm': None, # 输出结果是否标准化/归一化。l2:向量元素的平方和为1,当应用l2范数时,两个向量之间的余弦相似度是它们的点积;l1:向量元素的绝对值之和为1
'smooth_idf': True, # 在文档频率上加1来平滑 idf ,避免分母为0
'sublinear_tf': False, # 应用次线性 tf 缩放,即将 tf 替换为 1 + log(tf)
'use_idf': True, # 是否计算idf,布尔值,False时idf=1。
}
if label=='CountVectorizer':
return params_count
elif label=='TfidfTransformer':
return params_tfidf
elif label=='TfidfVectorizer':
params_count.update(params_tfidf)
return params_count3. Funciones de aplicación y entrenamiento de CountVectorizer
def CountVectorizer_train(train_data,params):
cv = CountVectorizer(**params)
# 输入训练集矩阵,每行表示一个文本
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式
cv_fit = cv.fit_transform(train_data)
return cv
def CountVectorizer_apply(model):
print('词汇表')
print(model.vocabulary_)
print('------------------------------')
print('特证名/词汇列表')
print(model.get_feature_names())
print('------------------------------')
print('idf_列表')
print(model.idf_)
print('------------------------------')
data=['Tokyo Japan Chinese']
print('{} 文本转化VSM矩阵'.format(data))
print(model.transform(data).toarray())
print('------------------------------')
print('转化结果输出为dataframe')
print(pd.DataFrame(model.transform(data).toarray(),columns=model.get_feature_names()))
print('------------------------------')
print('model参数查看')
print(model.get_params())
print('------------------------------')4. Utilice el vectorizador de conteo
train_data = ["Chinese Beijing Chinese",
"Chinese Chinese Shanghai",
"Chinese Macao",
"Tokyo Japan Chinese"]
params=init_params('CountVectorizer')
cv_model=CountVectorizer_train(train_data,params)
CountVectorizer_apply(cv_model)
Al observar los resultados, puede encontrar que la matriz VSM no es una estadística de frecuencia de palabras, sino que en realidad es el resultado de tf-idf.

5. Funciones de aplicación y entrenamiento de TfidfTransformer
def TfidfTransformer_train(train_data,params):
tt = TfidfTransformer(**params)
tt_fit = tt.fit_transform(train_data)
return tt
def TfidfTransformer_apply(model):
print('idf_列表')
print(model.idf_)
print('------------------------------')
data=[[1, 1, 0, 2, 1, 1, 0, 1]]
print('词频列表{} 转化VSM矩阵'.format(data))
print(model.transform(data).toarray())
print('------------------------------')
print('model参数查看')
print(model.get_params())
print('------------------------------')
train_data=[[1, 1, 1, 0, 1, 1, 1, 0],
[1, 1, 0, 1, 1, 1, 0, 1]]
params=init_params('TfidfTransformer')
tt_model=TfidfTransformer_train(train_data,params)
TfidfTransformer_apply(tt_model)6. Funciones de aplicación y entrenamiento de TfidfTransformer
def TfidfVectorizer_train(train_data,params):
tv = TfidfVectorizer(**params)
# 输入训练集矩阵,每行表示一个文本
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式
tv_fit = tv.fit_transform(train_data)
return tv
def TfidfVectorizer_apply(tv_model):
print('tv_model词汇表')
print(tv_model.vocabulary_)
print('------------------------------')
print('tv_model特证名/词汇列表')
print(tv_model.get_feature_names())
print('------------------------------')
print('idf_列表')
print(tv_model.idf_)
print('------------------------------')
data=['Tokyo Japan Chinese']
print('{} 文本转化VSM矩阵'.format(data))
print(tv_model.transform(data).toarray())
print('------------------------------')
print('转化结果输出为dataframe')
print(pd.DataFrame(tv_model.transform(data).toarray(),columns=tv_model.get_feature_names()))
print('------------------------------')
print('tv_model参数查看')
print(tv_model.get_params())
print('------------------------------')
train_data = ["Chinese Beijing Chinese",
"Chinese Chinese Shanghai",
"Chinese Macao",
"Tokyo Japan Chinese"]
params=init_params('TfidfVectorizer')
tv_model=TfidfVectorizer_train(train_data,params)
TfidfVectorizer_apply(tv_model)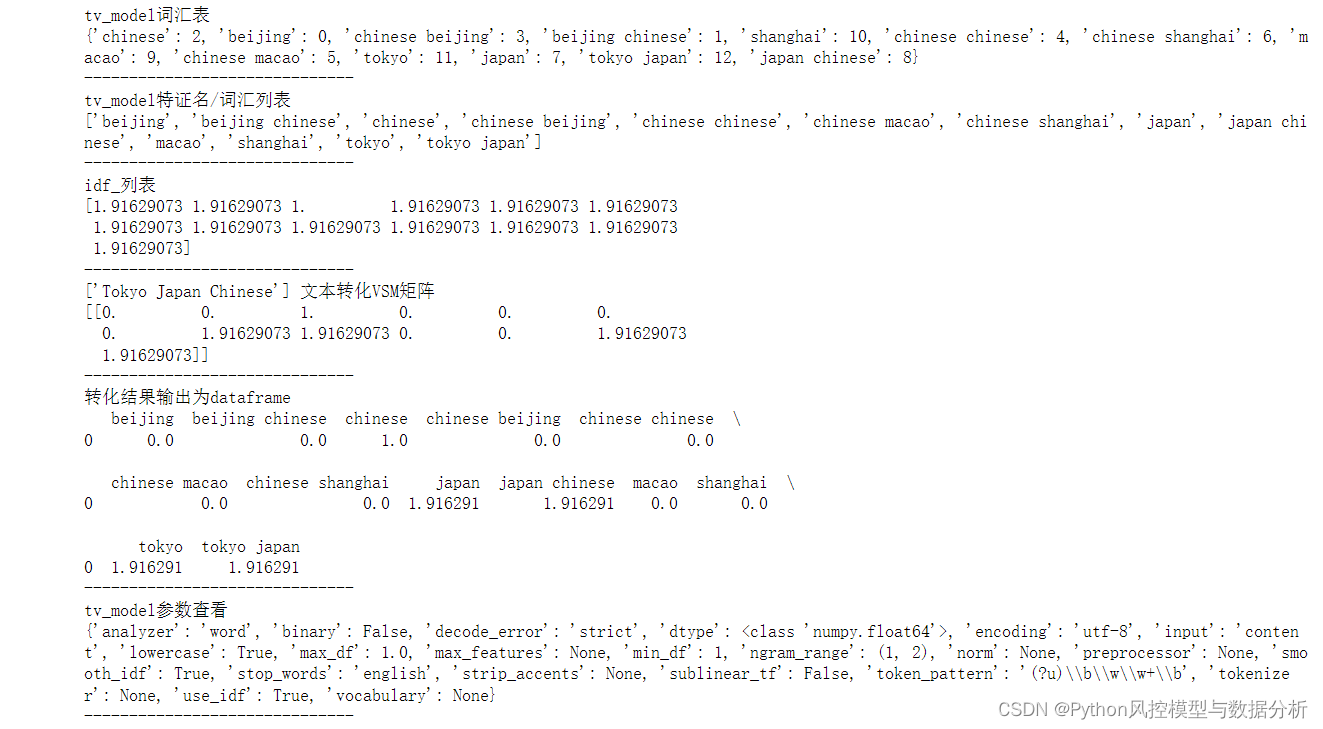
Convierta la matriz tf-idf de train_data en el resultado del marco de datos
pd.DataFrame(tv_model.transform(train_data).toarray(),
columns=tv_model.get_feature_names())
3. Concéntrate en
Evite 10 años de desvíos
Preste atención al modelo de control de riesgos y análisis de datos de Python de la cuenta pública, responda al combate real de tfidf para obtener el código .py de este artículo y llámelo directamente sin tener que hacerlo, ¿no es delicioso?
¿Hay más teorías, códigos compartidos y resultados sin reservas que no merezcan atención?