Análisis de la implementación de STL HashTable
Contenedores comunes
- mapa_desordenado
- mapa_multimapa desordenado
- conjunto_desordenado
- conjunto_multiconjunto desordenado
capa de interfaz
// gnu 实现
template<typename _Key, typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = equal_to<_Key>,
typename _Alloc = allocator<std::pair<const _Key, _Tp>>>
class unordered_map
{
typedef __umap_hashtable<_Key, _Tp, _Hash, _Pred, _Alloc> _Hashtable;
_Hashtable _M_h; // 内部的唯一成员变量: hashtable
};
/// Base types for unordered_map.
template<bool _Cache>
using __umap_traits = __detail::_Hashtable_traits<_Cache, false, true>;
template<typename _Key,
typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = std::equal_to<_Key>,
typename _Alloc = std::allocator<std::pair<const _Key, _Tp> >,
typename _Tr = __umap_traits<__cache_default<_Key, _Hash>::value>>
using __umap_hashtable = _Hashtable<_Key, std::pair<const _Key, _Tp>,
_Alloc, __detail::_Select1st,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
template<typename _Key, typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = equal_to<_Key>,
typename _Alloc = allocator<std::pair<const _Key, _Tp>>>
class unordered_multimap
{
typedef __ummap_hashtable<_Key, _Tp, _Hash, _Pred, _Alloc> _Hashtable;
_Hashtable _M_h;
};
/// Base types for unordered_multimap.
template<bool _Cache>
using __ummap_traits = __detail::_Hashtable_traits<_Cache, false, false>;
template<typename _Key,
typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = std::equal_to<_Key>,
typename _Alloc = std::allocator<std::pair<const _Key, _Tp> >,
typename _Tr = __ummap_traits<__cache_default<_Key, _Hash>::value>>
using __ummap_hashtable = _Hashtable<_Key, std::pair<const _Key, _Tp>,
_Alloc, __detail::_Select1st,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
/// Base types for unordered_set.
template <bool _Cache>
using __uset_traits = __detail::_Hashtable_traits<_Cache, true, true>;
template <typename _Value,
typename _Hash = hash<_Value>,
typename _Pred = std::equal_to<_Value>,
typename _Alloc = std::allocator<_Value>,
typename _Tr = __uset_traits<__cache_default<_Value, _Hash>::value>>
using __uset_hashtable = _Hashtable<_Value, _Value, _Alloc,
__detail::_Identity, _Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
/// Base types for unordered_multiset.
template <bool _Cache>
using __umset_traits = __detail::_Hashtable_traits<_Cache, true, false>;
template <typename _Value,
typename _Hash = hash<_Value>,
typename _Pred = std::equal_to<_Value>,
typename _Alloc = std::allocator<_Value>,
typename _Tr = __umset_traits<__cache_default<_Value, _Hash>::value>>
using __umset_hashtable = _Hashtable<_Value, _Value, _Alloc,
__detail::_Identity,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
Corresponde a la clase _Hashtable:
template <typename _Key, typename _Value, typename _Alloc,
typename _ExtractKey, typename _Equal,
typename _Hash, typename _RangeHash, typename _Unused,
typename _RehashPolicy, typename _Traits>
class _Hashtable
: public __detail::_Hashtable_base<_Key, _Value, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused, _Traits>,
public __detail::_Map_base<_Key, _Value, _Alloc, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused,
_RehashPolicy, _Traits>,
public __detail::_Insert<_Key, _Value, _Alloc, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused,
_RehashPolicy, _Traits>,
public __detail::_Rehash_base<_Key, _Value, _Alloc, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused,
_RehashPolicy, _Traits>,
public __detail::_Equality<_Key, _Value, _Alloc, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused,
_RehashPolicy, _Traits>,
private __detail::_Hashtable_alloc<
__alloc_rebind<_Alloc,
__detail::_Hash_node<_Value,
_Traits::__hash_cached::value>>>,
private _Hashtable_enable_default_ctor<_Equal, _Hash, _Alloc>
{
using __traits_type = _Traits;
using __hash_cached = typename __traits_type::__hash_cached;
using __constant_iterators = typename __traits_type::__constant_iterators;
// hash表中节点类型
using __node_type = __detail::_Hash_node<_Value, __hash_cached::value>;
using __node_alloc_type = __alloc_rebind<_Alloc, __node_type>;
using __hashtable_alloc = __detail::_Hashtable_alloc<__node_alloc_type>;
// hash表中节值类型
using __node_value_type =
__detail::_Hash_node_value<_Value, __hash_cached::value>;
using __node_ptr = typename __hashtable_alloc::__node_ptr;
using __value_alloc_traits =
typename __hashtable_alloc::__value_alloc_traits;
using __node_alloc_traits =
typename __hashtable_alloc::__node_alloc_traits;
// __node_base的定义
using __node_base = typename __hashtable_alloc::__node_base;
using __node_base_ptr = typename __hashtable_alloc::__node_base_ptr;
// __bucket_type的定义如下,实际上就是指向__node_base的指针
using __buckets_ptr = typename __hashtable_alloc::__buckets_ptr;
using __insert_base = __detail::_Insert<_Key, _Value, _Alloc, _ExtractKey,
_Equal, _Hash,
_RangeHash, _Unused,
_RehashPolicy, _Traits>;
using __enable_default_ctor = _Hashtable_enable_default_ctor<_Equal, _Hash, _Alloc>;
private:
// buckets的定义,是一个二级指针,可以理解为类型为__node_base*的数组
__buckets_ptr _M_buckets = &_M_single_bucket;
size_type _M_bucket_count = 1; // bucket 节点个数
__node_base _M_before_begin;
size_type _M_element_count = 0; //hashtable中list节点个数
_RehashPolicy _M_rehash_policy; // rehash策略
__node_base_ptr _M_single_bucket = nullptr; // 只需要一个桶用
}
__detail::_Hash_node y __detail::_Hashtable_alloc son en realidad las estructuras de datos centrales. Estas dos clases también están estrechamente relacionadas:
/**
* Primary template struct _Hash_node.
*/
// _Hash_node为value+next
template <typename _Value, bool _Cache_hash_code>
struct _Hash_node
: _Hash_node_base,
_Hash_node_value<_Value, _Cache_hash_code>
{
_Hash_node *
_M_next() const noexcept
{
return static_cast<_Hash_node *>(this->_M_nxt);
}
};
// _Hash_node_base仅持有指向下一个节点的指针
struct _Hash_node_base
{
_Hash_node_base *_M_nxt;
_Hash_node_base() noexcept : _M_nxt() {}
_Hash_node_base(_Hash_node_base *__next) noexcept : _M_nxt(__next) {}
};
template <typename _Value, bool _Cache_hash_code>
struct _Hash_node_value
: _Hash_node_value_base<_Value>,
_Hash_node_code_cache<_Cache_hash_code>
{
};
/**
* struct _Hash_node_value_base
*
* Node type with the value to store.
*/
// _Hash_node_value_base持有value
template <typename _Value>
struct _Hash_node_value_base
{
typedef _Value value_type;
__gnu_cxx::__aligned_buffer<_Value> _M_storage;
_Value *
_M_valptr() noexcept
{
return _M_storage._M_ptr();
}
const _Value *
_M_valptr() const noexcept
{
return _M_storage._M_ptr();
}
_Value &
_M_v() noexcept
{
return *_M_valptr();
}
const _Value &
_M_v() const noexcept
{
return *_M_valptr();
}
};
En resumen, en comparación con los depósitos clásicos de vector + lista vinculada, los depósitos de la clase _Hashtable en STL se implementan como una matriz _Hash_node_base* con un tipo de elemento.
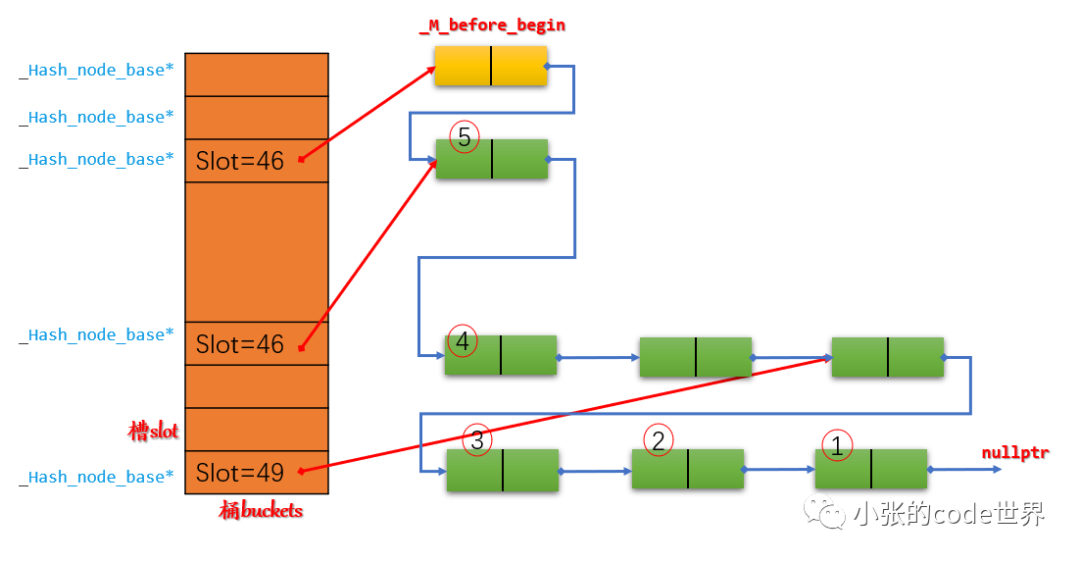
STL también utilizaMétodo de cadena abierta para resolver conflictos de hash, pero noUn espacio y una lista vinculada, peroToda la tabla hash es una lista vinculada, el nodo de cola de la ranura "anterior" apunta al nodo principal de la ranura "siguiente" no vacía, y lo que se almacena en la ranura esLa dirección del nodo anterior del nodo principal.. Énfasis en listas enlazadasNo se concatenan según el orden de la matriz de ranuras, es decir, los cubos, sino que se concatenan según el tiempo de inserción de los nodos.。
template <typename _NodeAlloc>
struct _Hashtable_alloc : private _Hashtable_ebo_helper<0, _NodeAlloc>
{
using __node_ptr = __node_type *;
using __node_base = _Hash_node_base;
using __node_base_ptr = __node_base *;
using __buckets_alloc_type =
__alloc_rebind<__node_alloc_type, __node_base_ptr>;
using __buckets_alloc_traits = std::allocator_traits<__buckets_alloc_type>;
using __buckets_ptr = __node_base_ptr *;
};
// Insert a node at the beginning of a bucket.
// 插入函数的底层均调用_M_insert_bucket_begin
// __bkt为slot的索引,__node为需要插入的节点,使用key与value构造出来
void
_M_insert_bucket_begin(size_type __bkt, __node_ptr __node)
{
// 如果所要插入的slot已经有节点,直接插入头部
if (_M_buckets[__bkt])
{
// Bucket is not empty, we just need to insert the new node
// after the bucket before begin.
__node->_M_nxt = _M_buckets[__bkt]->_M_nxt;
_M_buckets[__bkt]->_M_nxt = __node;
}
// 如果所要插入的slot还没插入过节点
else
{
// The bucket is empty, the new node is inserted at the
// beginning of the singly-linked list and the bucket will
// contain _M_before_begin pointer.
__node->_M_nxt = _M_before_begin._M_nxt;
_M_before_begin._M_nxt = __node;
if (__node->_M_nxt)
// We must update former begin bucket that is pointing to
// _M_before_begin.
_M_buckets[_M_bucket_index(*__node->_M_next())] = __node;
_M_buckets[__bkt] = &_M_before_begin;
}
}
El primer paso: Primero inserte tres elementos en la ranura 49 en secuencia. Dado que se insertan en la cabeza, el diagrama esquemático es el siguiente: El segundo paso
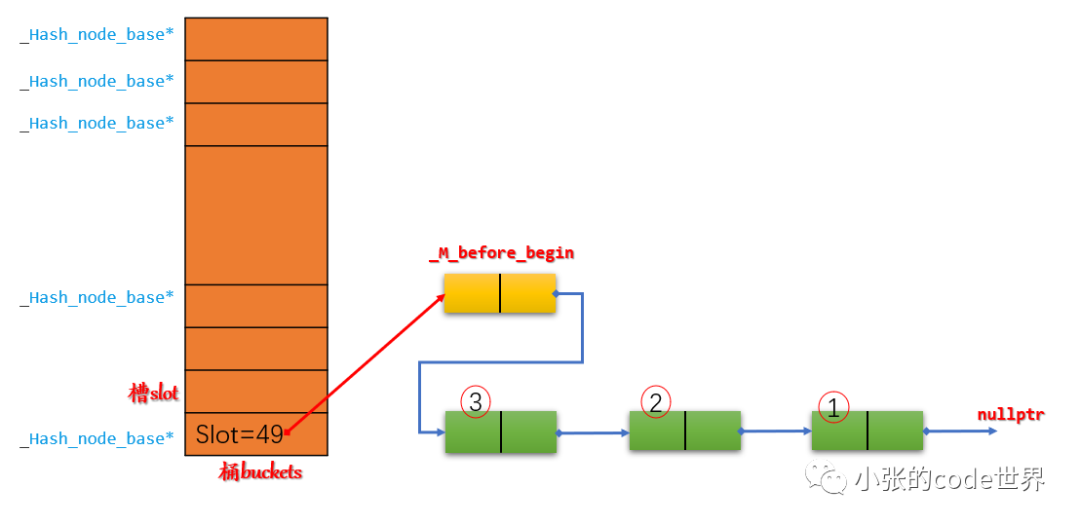
: Inserte un elemento 4 en la ranura 46. El diagrama esquemático es el siguiente:
2.1 Apunte el nuevo nodo 4 al siguiente de _M_before_begin;
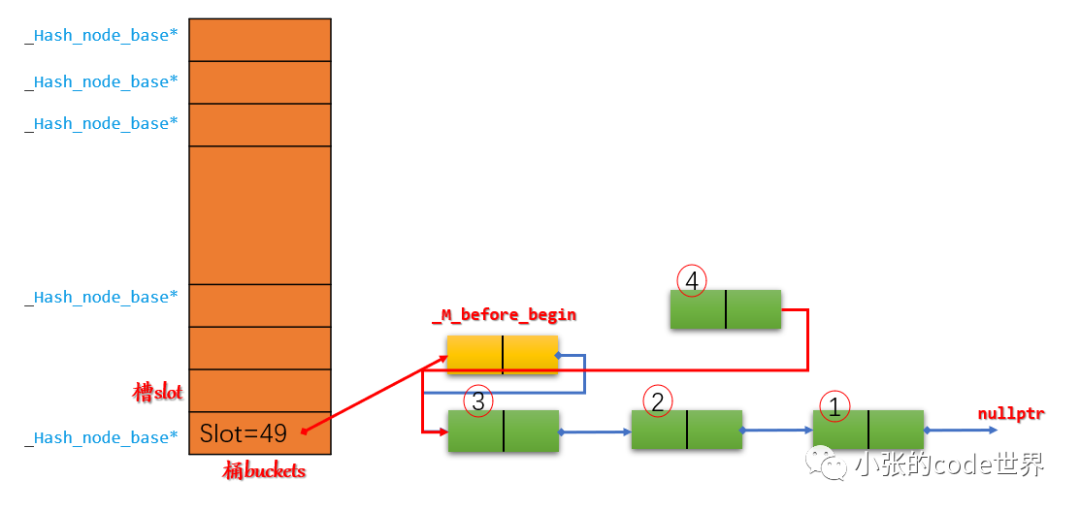
2.2 Luego, apunte al lado de _M_before_begin al nuevo nodo 4:
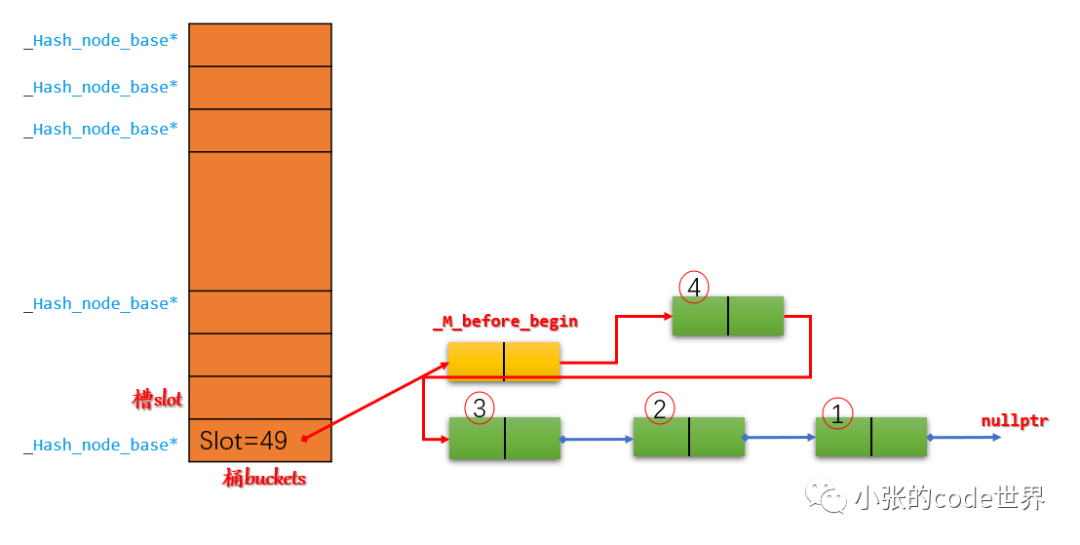
2.3 De acuerdo con _M_buckets[_M_bucket_index(__node->_M_next())] = __node;, modifique Slot49 a la dirección del nuevo nodo 4:
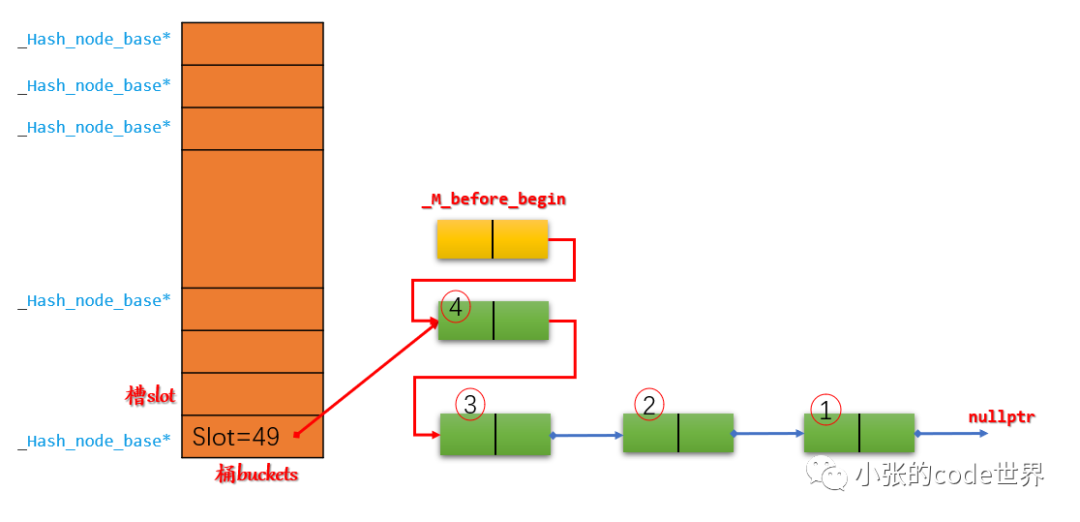
2.4 Punto Slot46 a _M_before_begin
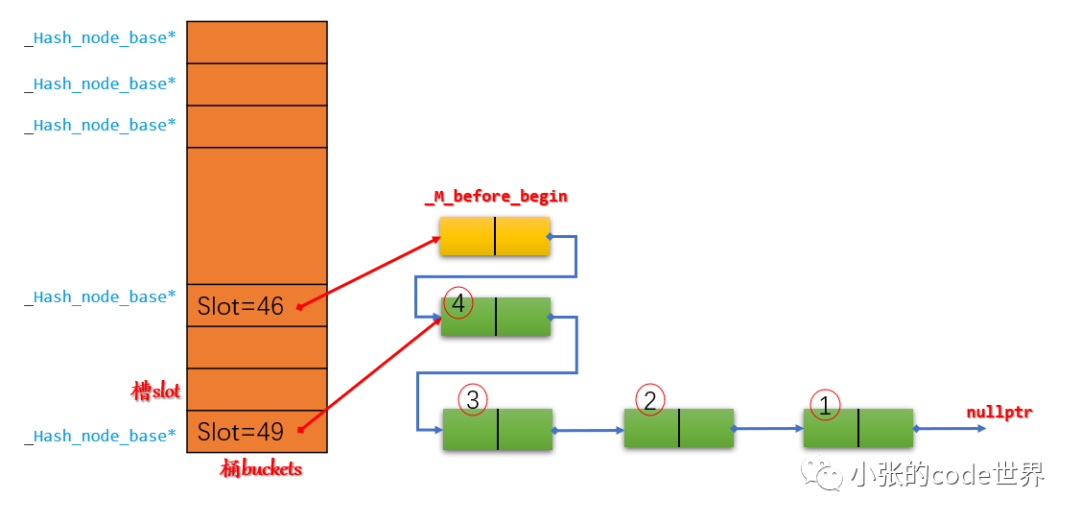
Paso 3: Inserte un elemento 5 en la ranura 3. El diagrama es el siguiente:
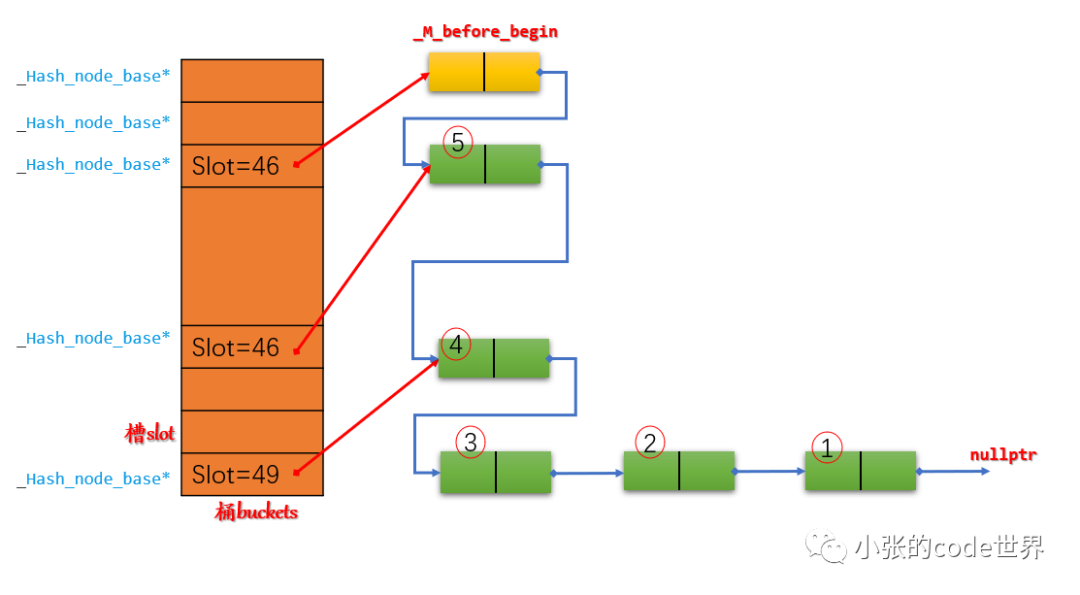
Finalmente, se insertan más elementos en secuencia:
| Clase de contenedor | _Llave | _Valor | _Alloc | _Extraer clave | _Igual | _Picadillo | _RangeHash | _No usado | _RehashPolicy | _Rasgos |
|---|---|---|---|---|---|---|---|---|---|---|
| mapa_desordenado | _Llave | std::par<const _Key, _Tp> | std::allocator<std::par<const _Key, _Tp>> | __detalle::_Select1st | std::equal_to<_Key> | hash<_Key> | __detalle::_Mod_range_hashing | __detalle::_Default_ranged_hash | __detalle::_Prime_rehash_policy | __uset_traits |
| mapa_multimapa desordenado | _Llave | std::par<const _Key, _Tp> | std::allocator<std::par<const _Key, _Tp>> | __detalle::_Select1st | std::equal_to<_Key> | hash<_Key> | __detalle::_Mod_range_hashing | __detalle::_Default_ranged_hash | __detalle::_Prime_rehash_policy | __uset_traits |
| conjunto_desordenado | _Valor | _Valor | std::asignador<_Value> | __detalle::_Identidad | std::equal_to<_Value> | hash<_Valor> | __detalle::_Mod_range_hashing | __detalle::_Default_ranged_hash | __detalle::_Prime_rehash_policy | __uset_traits |
| conjunto_multiconjunto desordenado | _Valor | _Valor | std::asignador<_Value> | __detalle::_Identidad | std::equal_to<_Value> | hash<_Valor> | __detalle::_Mod_range_hashing | __detalle::_Default_ranged_hash | __detalle::_Prime_rehash_policy | __uset_traits |
Los parámetros de plantilla enumerados en la tabla anterior incluyen:
- _Key: el tipo de valor clave del nodo.
- _Valor: el tipo de valor real del nodo.
- _Alloc: tipo de asignador utilizado para la asignación de memoria.
- _ExtractKey: Método para extraer valores clave de nodos.
- _Equal: un método para determinar si los valores clave son iguales o no.
- _Hash: el primer tipo de objeto de función hash.
- _RangeHash: el segundo tipo de objeto de función hash.
- _No utilizado: tipo de objeto de función hash.
- _RehashPolicy: clase de política de refrito.
- _Traits: clase "Extracción"
Se puede ver que _Hash = hash<_Key>, _RangeHash es __detail::_Mod_range_hashing, _Unused es __detail::_Default_ranged_hash. La relación entre el nombre de tipo _H1, el nombre de tipo _H2 y el nombre de tipo _Hash es la siguiente: _Unused(k, N) = _RangeHash(_Hash(k), N).
_Hashtable_base
Los comentarios son los siguientes:
★ Clase auxiliar que agrega administración del functor _Equal al tipo _Hash_code_base
Clase auxiliar que agrega administración del functor _Equal a _Hash_code_base.
/**
* Primary class template _Hashtable_base.
*
* Helper class adding management of _Equal functor to
* _Hash_code_base type.
*
* Base class templates are:
* - __detail::_Hash_code_base
* - __detail::_Hashtable_ebo_helper
*/
template <typename _Key, typename _Value, typename _ExtractKey,
typename _Equal, typename _Hash, typename _RangeHash,
typename _Unused, typename _Traits>
struct _Hashtable_base
: public _Hash_code_base<_Key, _Value, _ExtractKey, _Hash, _RangeHash,
_Unused, _Traits::__hash_cached::value>,
private _Hashtable_ebo_helper<0, _Equal>
{
}
Compare _Hash_code_base y _Hashtable_base. La única diferencia entre los dos es _Equal. Esta oración se explica en consecuencia.
Sus clases base tienen dos más:
__detail::_Hash_code_base
__detail::_Hashtable_ebo_helper
_Hash_code_base
El último __cache_hash_code de esta clase indica si se debe almacenar en caché el código hash.
O(1)
formación, El elemento se puede obtener con una complejidad de tiempo O (1) a través del índice, pero si no se conoce el índice, se requiere una complejidad de tiempo O (N) para encontrar el nodo. Para compensar esta deficiencia, hashtable utiliza una función hash para calcular el valor del índice del elemento para cumplir con la complejidad del tiempo de búsqueda de O (1). El proceso es el siguiente.
- Calcular el valor hash de un elemento. Para un único par clave-valor {clave, valor}, calcule el valor hash correspondiente al código hash clave = hash_func (clave).
- Calcula el índice de un elemento en una matriz. Dado que el código hash no está necesariamente en el rango [0, bucket_count], el código hash debe asignarse a este rango: índice = código hash % bucket_count.
Pero si hay varios nodos con el mismo valor de código hash al mismo tiempo, ¿los nodos insertados posteriormente no sobrescribirán los valores anteriores?conflicto de hash。
conflicto de hash
En una tabla hash, cada elemento de la matriz se llamabalde。
Para resolver conflictos de hash,En cada depósito de tabla hash, el depósito [índice] ya no almacena directamente el valor del nodo que se insertará, sino que almacena un nodo centinela para apuntar a una lista vinculada, que almacena el valor de cada nodo insertado.:
- El valor del índice del depósito todavía se calcula utilizando la función bucket_index, que se obtiene mediante la clave del nodo que se va a insertar.
- El valor del nodo a insertar se inserta en el encabezado de la lista vinculada señalada por el centinela. Debido a que se inserta el encabezado, todo el proceso de inserción todavía tiene una complejidad de tiempo O (1).
Cuando ocurre un conflicto de hash, todos los nodos con el mismo código hash se insertan en la misma lista vinculada. Dado que se utiliza el método de inserción de cabeza, incluso si ocurre un conflicto de hash, la complejidad del tiempo de inserción sigue siendo O (1).
degradación del hash
factor de carga
Para solucionar la degradación del hash, se introducen dos conceptos:
El factor de carga (load_factor) es la relación entre el número de elementos en la tabla hash y el número de depósitos en la tabla hash;
el factor de carga máximo (max_load_factor) es el límite superior del factor de carga
Deben satisfacer:
load_factor = map.size() / map.buck_count() // load_factor 计算方式
load_factor <= max_load_factor // 限制条件
Cuando la relación entre el número de elementos y el número de depósitos en la tabla hash es load_factor >= max_load_factor, la tabla hash realizará automáticamente el comportamiento Rehash para reducir el factor_carga:
- La expansión significa asignar una memoria más grande para dar cabida a más depósitos.
- Reinsertar . Siga los pasos de inserción anteriores para volver a insertar los nodos buck_size del depósito original en el nuevo depósito.
Después de Rehash, la cantidad de depósitos aumenta pero la cantidad de elementos permanece sin cambios y la condición load_factor < max_load_factor se cumple nuevamente.
Refrito
Dado que la tabla hash siempre debe satisfacer load_factor <= max_load_factor, limita el grado de conflicto hash, es decir, el número de nodos de la lista vinculada en cada depósito no aumentará indefinidamente. Cuando el número de nodos en toda la tabla hash alcanza un cierto nivel, será Rehash, asegurando la búsqueda y eliminación de la tabla hash. La complejidad del tiempo promedio sigue siendo O (1).
Hay una función de repetición en std::unordered_map, que puede provocar una repetición de std::unordered_map en cualquier momento, o puede ocurrir automáticamente cuando load_factor >= max_load_factor. Aviso:
- Diferentes compiladores tienen diferentes estrategias de expansión, por lo que es normal que la cantidad de depósitos después de la repetición del compilador sea inconsistente.
- Actualmente, el valor predeterminado del campo max_load_factor en msvc y g++ es 1.