En la era actual del big data, el procesamiento y la gestión de datos son cada vez más complejos. Especialmente en sistemas distribuidos, cómo garantizar la coherencia e integridad de los datos es un gran desafío. Esto nos lleva al tema que vamos a discutir hoy: el procesamiento de transacciones distribuidas. El procesamiento de transacciones distribuidas es una tecnología que coordina y gestiona transacciones en sistemas distribuidos para garantizar la coherencia e integridad de los datos. Sin embargo, implementar un procesamiento de transacciones distribuidas eficaz no es fácil, ya que implica muchos problemas y desafíos complejos, como retrasos en la red, fallas del sistema, inconsistencias de datos, etc. En este artículo profundizaremos en la teoría y la práctica del procesamiento de transacciones distribuidas, incluidos sus principios básicos, principales tecnologías, aplicaciones prácticas, así como desafíos y posibles soluciones. Esperamos que a través de este artículo ayudemos a los lectores a obtener una comprensión más profunda del procesamiento de transacciones distribuidas y su importancia en la informática moderna.
Directorio de artículos
-
-
-
- 1. Introducción a las transacciones distribuidas
- 2. Introducción al protocolo 2PC y al protocolo 3PC
- 3. Algoritmo de Paxos
- 4. Algoritmo de balsa
-
- 4.1 Introducción al algoritmo Raft
- 4.2 Papel principal del algoritmo Raft
- 4.2 El proceso de elección de líder mediante el algoritmo Raft
- 4.3 Definiciones relacionadas del proceso de elección del algoritmo Raft
- 4.4 Estructura de registro del algoritmo de balsa
- 4.5 Replicación de registros del algoritmo Raft
- 4.6 Cambio de integrantes de la Balsa
- 5. Otros modelos de transacciones distribuidas
- 6. Práctica, optimización y desarrollo futuro del procesamiento de transacciones distribuidas.
-
-
1. Introducción a las transacciones distribuidas
1.1 Descripción general de los conceptos básicos de los sistemas distribuidos
Un sistema distribuido es un sistema en el que varios nodos informáticos están conectados a través de una red y colaboran para completar tareas. Estos nodos comparten los mismos datos y necesitan resolver problemas como la coherencia de los datos, la disponibilidad del sistema y la tolerancia a fallos. Los principales desafíos de los sistemas distribuidos incluyen: problemas de coherencia de los datos, problemas de comunicación de los nodos, problemas de recuperación de fallas, etc.
Conceptos relacionados:
- Coherencia de los datos: en un sistema distribuido, los datos se pueden copiar a varios nodos. Cuando los datos cambian en un nodo, este cambio debe sincronizarse con todos los demás nodos para garantizar que todos los nodos vean Los datos son consistentes;
- Disponibilidad del sistema: los sistemas distribuidos deben poder continuar brindando servicios en caso de falla del nodo. Esto suele lograrse mediante técnicas como la redundancia y el equilibrio de carga;
- Tolerancia a fallas: los sistemas distribuidos deben poder manejar fallas de nodos. Cuando un nodo falla, el sistema debe poder recuperarse automáticamente y continuar brindando servicios;
- Comunicación de nodos: los nodos de un sistema distribuido necesitan comunicarse a través de la red, lo que puede introducir retrasos y afectar el rendimiento del sistema. Además, la red puede fallar, lo que provocará una interrupción en la comunicación entre nodos;
- Recuperación de fallas: cuando uno o más nodos en un sistema distribuido fallan, el sistema debe poder detectar y recuperarse automáticamente de estas fallas para garantizar el funcionamiento normal del sistema.
Estas son cuestiones clave que deben abordarse en el diseño e implementación de sistemas distribuidos.
1.2 Descripción general de los conceptos básicos del procesamiento de transacciones
Una transacción es una secuencia de una o más operaciones de datos que se ejecutan en su conjunto, incluidas las operaciones de confirmación y reversión. Las transacciones deben cumplir con las cuatro características de ACID (atomicidad, consistencia, aislamiento y durabilidad). En un sistema de base de datos único, el procesamiento de transacciones es relativamente simple y el sistema de gestión de bases de datos (DBMS) puede controlar todas las operaciones y garantizar las características ACID.
Las transacciones deben cumplir las cuatro características de ACID, que se explican a continuación:
- Atomicidad: todas las operaciones en una transacción se completan por completo o no se completan y no terminarán en algún punto intermedio. Si se produce un error durante la ejecución de la transacción, se revertirá al estado anterior a que comenzara la transacción, como si la transacción nunca se hubiera ejecutado.
- Consistencia: las transacciones deben garantizar que el estado de la base de datos cambie de un estado consistente a otro estado consistente. La definición de estado consistente depende de las reglas comerciales de la base de datos.
- Aislamiento: cuando se ejecutan varias transacciones al mismo tiempo, la ejecución de una transacción no debería afectar la ejecución de otras transacciones.
- Durabilidad: Las modificaciones realizadas a la base de datos por transacciones comprometidas son permanentes y no se perderán incluso si ocurre una falla del sistema.
En un único sistema de base de datos, el sistema de gestión de bases de datos (DBMS) puede controlar todas las operaciones a través de mecanismos como bloqueos y registros para garantizar las características ACID de las transacciones. Sin embargo, en un entorno distribuido, el procesamiento de transacciones se vuelve más complejo ya que los datos pueden distribuirse en múltiples nodos.
1.3 Transacciones distribuidas
Cuando una transacción involucra múltiples nodos en un sistema distribuido, se forma una transacción distribuida. Las transacciones distribuidas deben mantener la coherencia de los datos en múltiples nodos y, al mismo tiempo, mejorar la disponibilidad y el rendimiento del sistema tanto como sea posible. Esto requiere el uso de algunas tecnologías y protocolos especiales, como envío en dos fases (2PC), envío en tres fases (3PC), TCC (Try-Confirm-Cancel), etc.
El procesamiento de transacciones distribuidas es el producto de la combinación de sistemas distribuidos y tecnología de procesamiento de transacciones, que determina en gran medida el rendimiento y la confiabilidad de los sistemas distribuidos.
2. Introducción al protocolo 2PC y al protocolo 3PC
2.1 Protocolo de presentación en dos etapas
El compromiso de dos fases (2PC) es un protocolo de transacciones distribuidas clásico que garantiza la coherencia del sistema al introducir un coordinador para coordinar las operaciones de todos los participantes y garantizar que todos los participantes realicen transacciones o no realicen sexo.
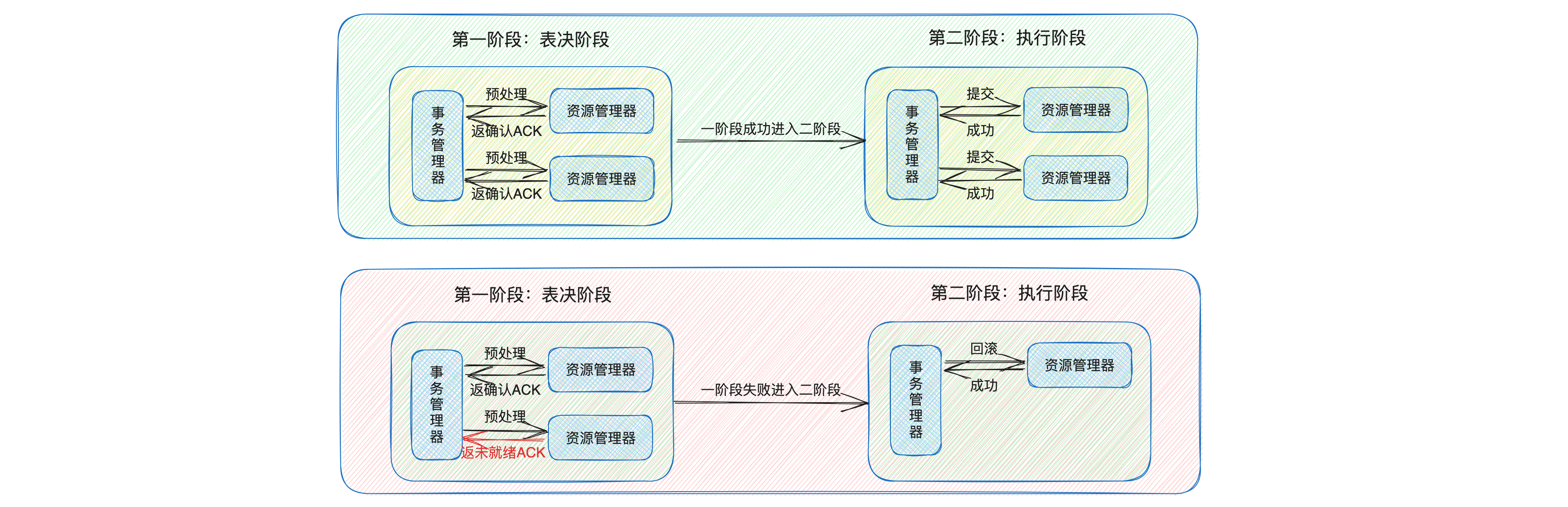
El proceso del protocolo de presentación de dos fases se puede dividir en dos etapas:
- Fase de compromiso previo (fase de votación): en esta fase, el coordinador envía solicitudes de compromiso previo a todos los participantes. Después de recibir las solicitudes, los participantes realizan operaciones de transacción y retroalimentan los resultados de la operación al coordinador. Si todos los participantes informan que la operación fue exitosa, el coordinador decide pasar a la siguiente fase; de lo contrario, el coordinador envía una solicitud para cancelar la transacción a todos los participantes;
- Fase de compromiso: en esta fase, el coordinador envía una solicitud de compromiso a todos los participantes, luego de recibir la solicitud, los participantes confirman la transacción y liberan los recursos ocupados en la fase de compromiso previo.
Aunque el protocolo de confirmación de dos fases puede garantizar la coherencia de las transacciones distribuidas, también tiene algunas deficiencias, como problemas de bloqueo de sincronización y problemas de punto único de falla.
- Problema de bloqueo sincrónico: en el protocolo de confirmación de dos fases, todos los participantes entrarán en un estado de bloqueo mientras esperan respuestas de otros participantes y del coordinador. Esto puede provocar una degradación del rendimiento del sistema;
- Problema de punto único de falla: en el protocolo de confirmación de dos fases, el coordinador desempeña un papel clave y necesita coordinar a todos los participantes para completar la transacción. Si el coordinador falla, es posible que no se complete toda la transacción.
Por lo tanto, en el diseño real del sistema, puede ser necesario seleccionar un protocolo de transacciones distribuidas más adecuado en función de los requisitos comerciales específicos y las características del sistema, como el protocolo de confirmación de tres fases (3PC), el modelo TCC (Try-Confirm-Cancel), etc. Estos protocolos y modelos resuelven hasta cierto punto el problema del protocolo de envío de dos fases y mejoran el rendimiento y la confiabilidad del sistema.
2.2 Acuerdo de presentación en tres etapas
El compromiso de tres fases (3PC) es una mejora del compromiso de dos fases (2PC), principalmente para resolver el problema de bloqueo en 2PC.
El protocolo 3PC divide la fase de votación de 2PC en dos fases: la fase de consulta (CanCommit) y la fase de precompromiso (PreCommit), más la fase de presentación final (DoCommit), para un total de tres fases.
- Fase de consulta (CanCommit): esta fase es similar a la fase de votación de 2PC: el coordinador envía una solicitud de CanCommit a todos los participantes para preguntarles si pueden enviar la transacción. Después de que cada participante recibe la solicitud CanCommit, solo realiza la ejecución previa de la transacción y no bloquea el recurso, y luego responde al coordinador si puede confirmar la transacción.
- Fase de precompromiso (PreCommit): si en la fase CanCommit, todos los participantes responden que pueden enviar la transacción, entonces el coordinador envía una solicitud de PreCommit a todos los participantes para prepararlos para enviar la transacción. Después de recibir la solicitud de PreCommit, el participante bloqueará los recursos para la operación de transacción y luego responderá que el coordinador está listo para confirmar la transacción.
- Fase de envío (DoCommit): si en la fase PreCommit, todos los participantes responden que están listos para enviar la transacción, entonces el coordinador envía una solicitud DoCommit a todos los participantes para permitirles enviar la transacción. Si algún participante responde que la transacción no se puede confirmar durante la fase de PreCommit, el coordinador envía una solicitud de reversión a todos los participantes para permitirles revertir la transacción.
En el protocolo 3PC, tanto el coordinador como los participantes han configurado un mecanismo de tiempo de espera, de modo que incluso si el coordinador falla, los participantes no serán bloqueados y esperarán para siempre, sino que confirmarán o revertirán automáticamente la transacción después del tiempo de espera, evitando así un largo período de tiempo bloque. Esta es una gran ventaja del protocolo 3PC sobre el protocolo 2PC.
Sin embargo, este mecanismo también puede generar problemas de coherencia de los datos. Por ejemplo, si el participante no recibe la respuesta de interrupción enviada por el coordinador a tiempo debido a razones de red, el participante puede realizar una operación de confirmación después de esperar el tiempo de espera, mientras que los datos de otros participantes que reciben la respuesta de interrupción y realizan la reversión será inconsistente con los datos de este participante. Este es un gran inconveniente del protocolo 3PC.
Por lo tanto, se puede decir que 2PC es un protocolo de coherencia sólida, mientras que 3PC mejora la disponibilidad del sistema al sacrificar cierta coherencia de los datos. En el diseño del sistema real, es necesario sopesar la relación entre coherencia y disponibilidad y seleccionar un protocolo de transacciones distribuidas apropiado en función de las necesidades y características del sistema.
3. Algoritmo de Paxos
3.1 Introducción al algoritmo Paxos
El algoritmo Paxos es un algoritmo de coherencia basado en el paso de mensajes propuesto por Leslie Lamport en 1990 para resolver problemas de coherencia en sistemas distribuidos. El algoritmo Paxos garantiza que en un sistema distribuido se pueda llegar a una decisión por consenso incluso si algunos nodos fallan.
El proceso del algoritmo Paxos puede verse como un proceso de presentación de dos etapas y múltiples rondas. Sin embargo, a diferencia del protocolo de confirmación de dos fases, el algoritmo de Paxos permite que nuevos proponentes participen en el proceso, mientras que el protocolo de confirmación de dos fases no. Además, el algoritmo de Paxos no tiene un coordinador centralizado y todos los nodos pueden actuar como proponentes, lo que hace que el algoritmo de Paxos sea más flexible y robusto cuando se trata de fallas de nodos.
3.2 Papel principal del algoritmo Paxos
Hay tres roles principales en el algoritmo de Paxos: proponente, aceptador y alumno.
- Proponente: La tarea principal del proponente es iniciar propuestas, que contienen un número de propuesta y un valor de propuesta. El proponente debe asegurarse de que el número de cada propuesta sea único;
- Aceptador: Los aceptantes son votantes de propuestas y votan sobre las propuestas emitidas por los proponentes. El destinatario debe asegurarse de aceptar sólo una propuesta en la misma ronda de votación;
- Estudiante: La tarea principal del estudiante es aprender la propuesta aceptada. Cuando más de la mitad de los destinatarios aceptan una propuesta, el sistema la considera aceptada y los alumnos deben aprender la propuesta;
En el proceso del algoritmo Paxos, el proponente primero inicia una propuesta, luego los aceptantes votan sobre la propuesta y finalmente el alumno aprende la propuesta aceptada. A través de este proceso, el algoritmo Paxos es capaz de llegar a decisiones consensuadas en sistemas distribuidos.
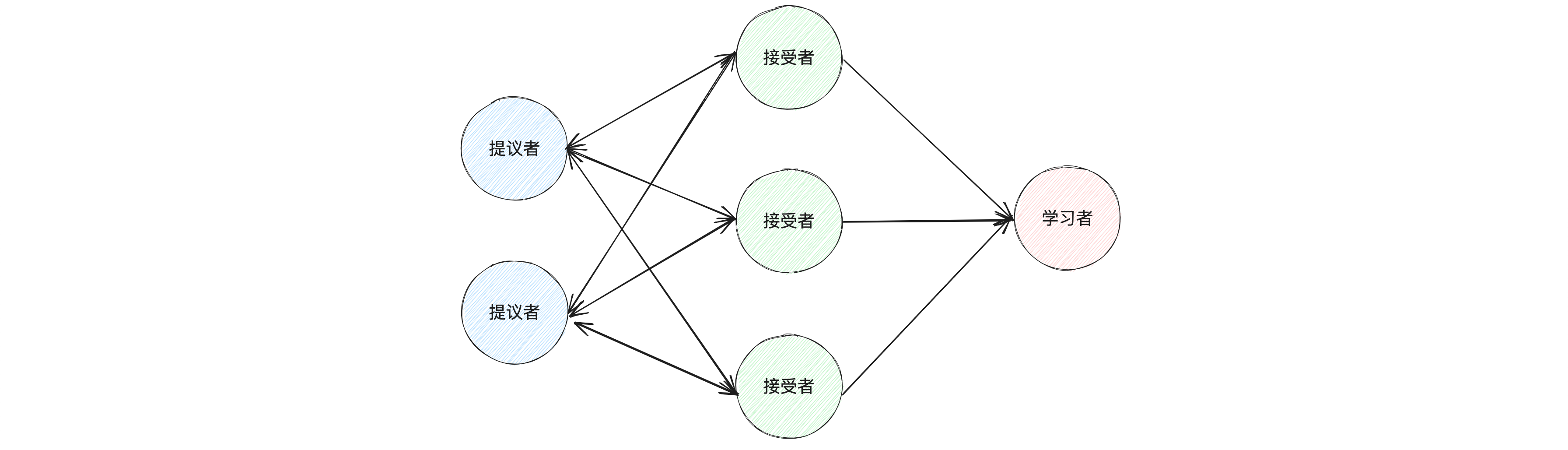
En el algoritmo Basic Paxos, un nodo puede desempeñar estos tres roles al mismo tiempo. Por ejemplo, en el sistema Chubby de Google, cada nodo es a la vez proponente, aceptor y alumno. Esto puede mejorar la tolerancia a fallas del sistema. Incluso si algunos nodos fallan, el sistema aún puede funcionar normalmente.
Acerca de las propuestas: en el algoritmo Paxos, las propuestas las inicia el proponente y se utilizan para alcanzar decisiones por consenso en el sistema distribuido. Una propuesta contiene principalmente dos partes: número de propuesta y valor de la propuesta.
- Número de propuesta: este es un número único a nivel mundial que se utiliza para identificar diferentes propuestas. En el algoritmo de Paxos, el número de propuesta debe cumplir dos condiciones: primero, el número de cada nueva propuesta iniciada por cada proponente debe ser mayor que el número de todas las propuestas iniciadas previamente por el proponente; segundo, cada número de propuesta debe ser globalmente único. , es decir, las propuestas iniciadas por diferentes proponentes no pueden tener el mismo número;
- Valor de la propuesta: este es el contenido específico de la propuesta, es decir, la decisión sobre la que el proponente espera que el sistema llegue a un consenso.
3.3 Etapa de preparación del algoritmo de Paxos
Preparar. En esta etapa, el Proponente selecciona un número de propuesta y lo envía a todos los Aceptantes. Después de que el aceptador recibe el número de propuesta, si el número es mayor que todos los números de propuesta que ha visto antes, aceptará el número de propuesta y devolverá la información de la propuesta previamente aceptada al proponente.
A continuación, damos un ejemplo: asumimos que el número de propuesta del cliente 1 es 1 y el número de propuesta del cliente 2 es 5. También asumimos que los nodos A y B reciben primero la solicitud de preparación del cliente 1 y el nodo C recibe primero la solicitud del cliente 1. La solicitud de preparación del cliente 2.
En la fase de preparación, primero, los clientes 1 y 2 actúan como proponentes y envían solicitudes de preparación que contienen números de propuesta a todos los destinatarios respectivamente:
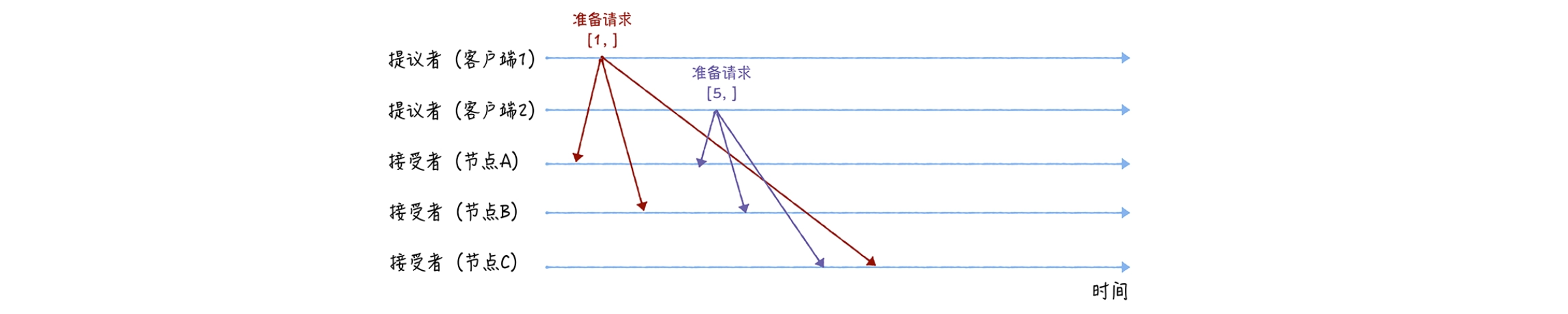
Ps: Cabe señalar que no es necesario especificar el valor de la propuesta en la solicitud de preparación, solo es necesario llevar el número de la propuesta.
Luego, cuando los nodos A y B reciban la solicitud de preparación con la propuesta número 1, y el nodo C reciba la solicitud de preparación con la propuesta número 5, realizará el siguiente procesamiento:
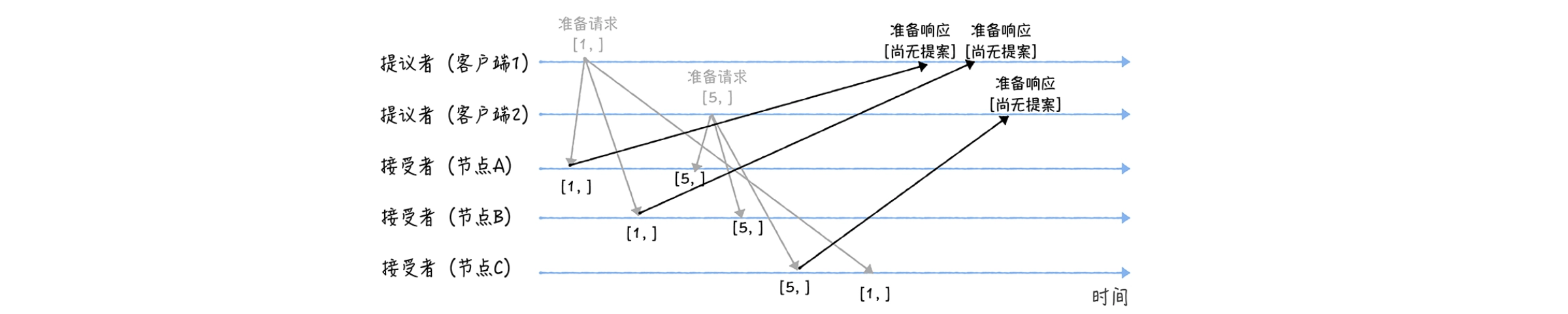
Para los nodos A y B, dado que no se ha aprobado ninguna propuesta antes, se devuelve una respuesta "aún no hay propuesta". En otras palabras, los nodos A y B le dicen al proponente que no he aprobado ninguna propuesta antes y prometen no responder a solicitudes de preparación con un número de propuesta menor o igual a 1 en el futuro, y no aprobarán propuestas con un número menor que 1;
Lo mismo ocurre con el nodo C. Devolverá una respuesta "aún no hay propuesta" y promete no responder a solicitudes de preparación con un número de propuesta menor o igual a 5 en el futuro, y no aprobará propuestas con un número menor. que 5.
Además, cuando los nodos A y B reciban una solicitud de preparación con la propuesta número 5, y el nodo C reciba una solicitud de preparación con la propuesta número 1, se realizará el siguiente procesamiento:
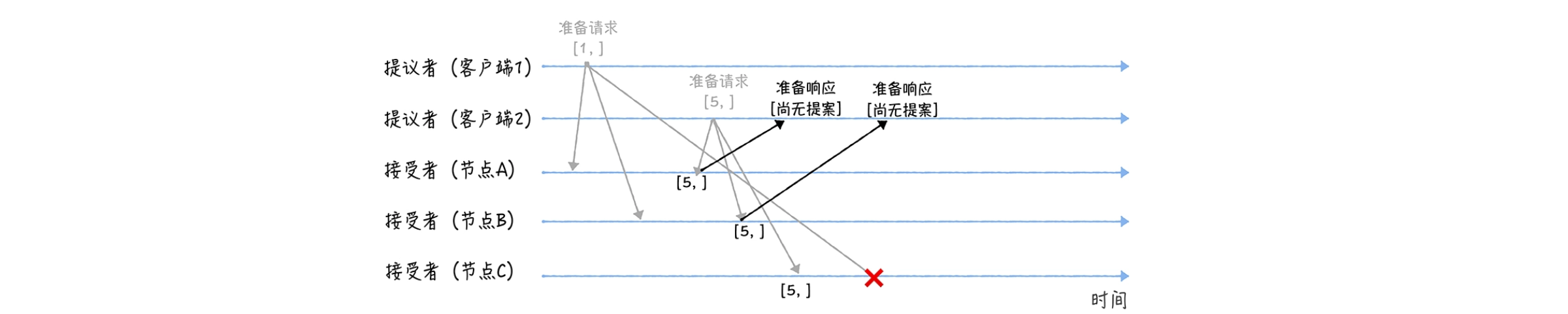
Cuando los nodos A y B reciben una solicitud de preparación con la propuesta número 5, debido a que la propuesta número 5 es mayor que la propuesta número 1 de la solicitud de preparación a la que respondieron previamente, y ninguno de los nodos ha aprobado ninguna propuesta, devolverá un "Aún no". respuesta "Sin propuesta", y se compromete a no responder a solicitudes de preparación con un número de propuesta menor o igual a 5 en el futuro, y no aprobará propuestas con un número menor a 5;
Cuando el nodo C recibe una solicitud de preparación con la propuesta número 1, dado que la propuesta número 1 es menor que la propuesta número 5 de la solicitud de preparación a la que respondió antes, descarta la solicitud de preparación y no responde.
Ps: en el proceso del algoritmo Paxos, el proponente primero enviará una solicitud de preparación con un número de propuesta a todos los destinatarios en la fase de preparación (fase de preparación). Si el destinatario no acepta la propuesta, puede deberse a que el número de propuesta es menor que el número de propuesta previamente aceptado por el destinatario. En este punto, el proponente debe elegir un número de propuesta nuevo y mayor y reiniciar la solicitud de preparación.
3.4 Etapa de aceptación del algoritmo de Paxos
Etapa de aceptación. En esta etapa, el proponente selecciona un valor de propuesta en función de los comentarios de los destinatarios y luego envía el número de propuesta y el valor de la propuesta a todos los destinatarios. Después de que el aceptador reciba la propuesta, si el número de la propuesta no es menor que los números de la propuesta que aceptó antes, entonces aceptará la propuesta.
Siguiendo el ejemplo anterior
En la fase de aceptación, primero, después de recibir las respuestas listas de la mayoría de los nodos, los clientes 1 y 2 enviarán solicitudes de aceptación respectivamente:
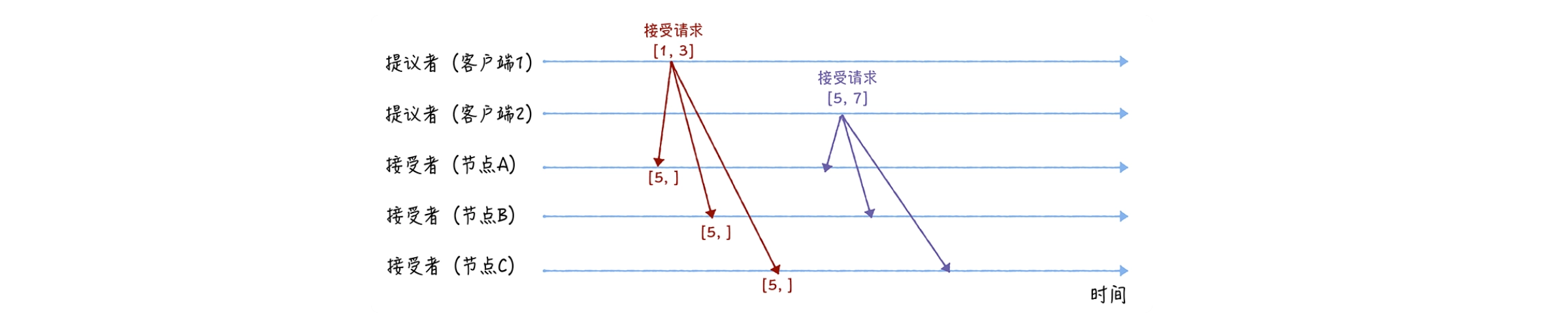
Cuando el cliente 1 recibe respuestas preparadas de la mayoría de los destinatarios (nodos A y B), establece el valor en la solicitud de aceptación en función del valor de la propuesta con el mayor número de propuesta en la respuesta. Debido a que este valor está vacío en las respuestas preparadas de los nodos A y B, utiliza su propio valor de propuesta 3 como valor de la propuesta y envía una solicitud de aceptación [1, 3];
Cuando el cliente 2 recibe las respuestas preparadas de la mayoría de los destinatarios (nodos A, B y nodo C), establece el valor en la solicitud de aceptación en función del valor de la propuesta con el número de propuesta más grande en la respuesta. Debido a que este valor está vacío en las respuestas preparadas de los nodos A, B y C, establece su propio valor de propuesta en 7. Como valor de la propuesta se envía una solicitud de aceptación [5, 7].
Cuando tres nodos reciban solicitudes de aceptación de 2 clientes, procederán de la siguiente manera:
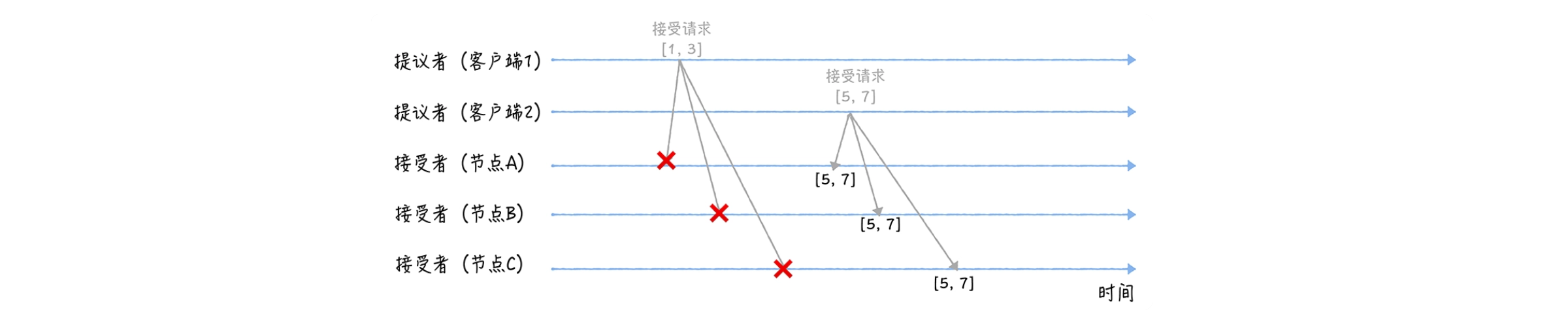
Cuando los nodos A, B y C reciben la solicitud de aceptación [1, 3], dado que la propuesta número 1 es menor que la propuesta mínima número 5 de la propuesta que los tres nodos se han comprometido a aprobar, la propuesta [1, 3] será rechazado. ;
Cuando los nodos A, B y C reciben la solicitud de aceptación [5, 7], el número de propuesta es 5. La propuesta mínima número 5 no es menor que la propuesta mínima número 5 que tres nodos se comprometen a aprobar, por lo que se aprueba la propuesta [5, 7], es decir, se acepta el valor 7, y los tres nodos llegan a un consenso de que El valor de X es 7.
Ps: si en la fase de aceptación (fase de aceptación), ningún aceptador acepta la solicitud de aceptación con el número de propuesta y el valor de la propuesta enviada por el proponente, entonces el proponente también debe elegir un número de propuesta nuevo y mayor y luego intentarlo. nuevamente Inicie una solicitud de aceptación.
De esta manera, el algoritmo de Paxos garantiza que incluso si una propuesta no es aceptada, el proponente finalmente pueda llegar a una decisión consensuada volviendo a presentar la propuesta. Por lo tanto, la propuesta del proponente no será descartada, sino que será presentada nuevamente hasta que sea aceptada.
Ps: si hay alumnos en el grupo, cuando el destinatario apruebe una propuesta, se notificará a todos los alumnos. Cuando el alumno descubre que la mayoría de los aceptantes han aprobado una determinada propuesta, también aprueba la propuesta y acepta el valor de la propuesta.
3.5 Acerca del algoritmo Multi-Paxos
Multi-Paxos es una versión optimizada del algoritmo Paxos, que se mejora sobre la base de Basic Paxos para mejorar el rendimiento y la disponibilidad del sistema.
En Basic Paxos, solo se puede negociar una decisión para lograr consenso a la vez, y cada decisión debe pasar por dos fases: la fase de preparación y la fase de aceptación. Esto significa que cada decisión requiere al menos dos rondas de paso de mensajes, lo que puede causar problemas de rendimiento en escenarios donde la latencia de la red es grande o es necesario tomar decisiones de coherencia con frecuencia.
Multi-Paxos reduce la cantidad de transmisiones de mensajes y mejora el rendimiento del sistema al introducir el concepto de líder. En Multi-Paxos se elige un líder y el líder es responsable de proponer propuestas. Después de que otros nodos acepten la propuesta del líder, aceptarán todas las propuestas posteriores del líder, a menos que el líder falle. De esta forma, además de la primera propuesta que debe pasar por la etapa de preparación y la etapa de aceptación, las propuestas posteriores solo necesitan pasar por la etapa de aceptación, reduciendo así el número de transmisiones de mensajes.
En general, Multi-Paxos reduce el número de transmisiones de mensajes y mejora el rendimiento y la disponibilidad del sistema al introducir el concepto de líder sobre la base de Basic Paxos.
4. Algoritmo de balsa
4.1 Introducción al algoritmo Raft
El algoritmo Raft es un algoritmo de consenso basado en el algoritmo Multi-Paxos propuesto por Diego Ongaro y John Ousterhout en 2013. Está simplificado y restringido según la idea Multi-Paxos de Lambert, por ejemplo, requiere que el registro sea continuo. y solo define tres estados: líder, seguidor y candidato, lo que hace que el algoritmo Raft sea más sencillo de entender e implementar que Multi-Paxos.
Por lo tanto, el algoritmo Raft se ha convertido en el algoritmo de consenso preferido para el desarrollo actual de sistemas distribuidos. La mayoría de los sistemas que utilizan el algoritmo Paxos (como Cubby, Spanner) se desarrollaron antes del lanzamiento del algoritmo Raft, cuando no había otras opciones. Ahora, la mayoría de los sistemas nuevos (como Etcd, Consul, CockroachDB) han optado por utilizar el algoritmo Raft.
Las principales características del algoritmo Raft incluyen:
- Fácil de entender e implementar: en comparación con el algoritmo Paxos, el algoritmo Raft es más simple, más intuitivo y más fácil de entender e implementar.
- Líder fuerte: hay un líder claro en el algoritmo Raft y todas las decisiones las toma el líder, lo que simplifica el proceso de toma de decisiones.
- Coherencia de registros: el algoritmo Raft requiere que los registros de todos los nodos de replicación sean coherentes, lo que garantiza la coherencia del sistema.
- Tres estados: los nodos en el algoritmo Raft tienen solo tres estados: líder, seguidor y candidato. Esto hace que las transiciones de estado sean más claras y sencillas.
Debido a las características anteriores, el algoritmo Raft se ha utilizado ampliamente en el desarrollo de sistemas distribuidos. Muchos sistemas distribuidos nuevos, como Etcd, Consul, CockroachDB, etc., han optado por utilizar el algoritmo Raft.
4.2 Papel principal del algoritmo Raft
En el algoritmo Raft, existen tres roles principales: líder, seguidor y candidato.
- Líder: el líder es responsable de manejar todas las interacciones del cliente, la replicación de registros y otras tareas críticas. Todos los demás servidores copian las entradas del líder;
- Seguidor: el seguidor recibe principalmente entradas de registro del líder y luego las escribe en su propio registro. Los seguidores no pueden manejar directamente las solicitudes de los clientes, pero pueden reenviarlas al líder;
- Candidato: Cuando un seguidor no recibe mensajes del líder durante un período de tiempo determinado, puede convertirse en candidato. El candidato solicitará votos de otros nodos y, si recibe votos de la mayoría de los nodos, se convertirá en el nuevo líder.
En el algoritmo Raft, todos los nodos son seguidores en el estado inicial. Si un seguidor no recibe un latido del líder, se convierte en candidato y comienza una elección. Una vez que se elige un nuevo líder, la red vuelve a un estado estable.
4.2 El proceso de elección de líder mediante el algoritmo Raft
El proceso de elección del algoritmo Raft incluye principalmente los siguientes pasos:
-
Iniciar elección: Cuando un seguidor no recibe un latido del líder durante un período de tiempo, se convertirá en candidato y comenzará una nueva ronda de elecciones. Este período de tiempo a menudo se denomina Tiempo de espera de elección y es aleatorio para evitar que varios nodos inicien elecciones al mismo tiempo.
-
Solicitar una votación: el candidato primero aumentará su número de período (Número de período) y luego enviará un mensaje de solicitud de votación (RequestVote) a todos los demás nodos.
-
Votación: después de recibir un mensaje solicitando una votación, otros nodos votarán por el candidato si no han votado antes y el registro del candidato es al menos tan nuevo como el suyo.
-
Obtención de votos: si un candidato recibe votos de la mayoría de los nodos en una ronda electoral, se convierte en el nuevo líder.
-
Conviértase en líder: después de convertirse en líder, el nuevo líder enviará mensajes de latido a otros nodos para informarles que es el nuevo líder.
A través de este proceso, el algoritmo Raft puede elegir un nuevo líder cuando el líder no logra garantizar el funcionamiento normal del sistema.
Para facilitar la comprensión, ilustro un proceso típico de elección de líder en forma de ilustración.
Primero, en el estado inicial, todos los nodos del clúster son seguidores.

El algoritmo Raft implementa la función de tiempo de espera aleatorio. En otras palabras, el intervalo de tiempo de espera para que cada nodo (Nodo) espere la información de latido del nodo líder es aleatorio. Como puede ver en la imagen de arriba, no hay ningún líder en el clúster y el nodo A tiene el tiempo de espera más pequeño (150 ms), y expirará primero porque no ha esperado la información de latido del líder.
En este momento, el nodo A aumenta su número de término (Número de término) y se recomienda a sí mismo como candidato. Primero emite un voto (Voto) por sí mismo y luego envía un mensaje RPC de solicitud de voto a otros nodos, pidiéndoles que se elijan a sí mismo. como candidato líder.
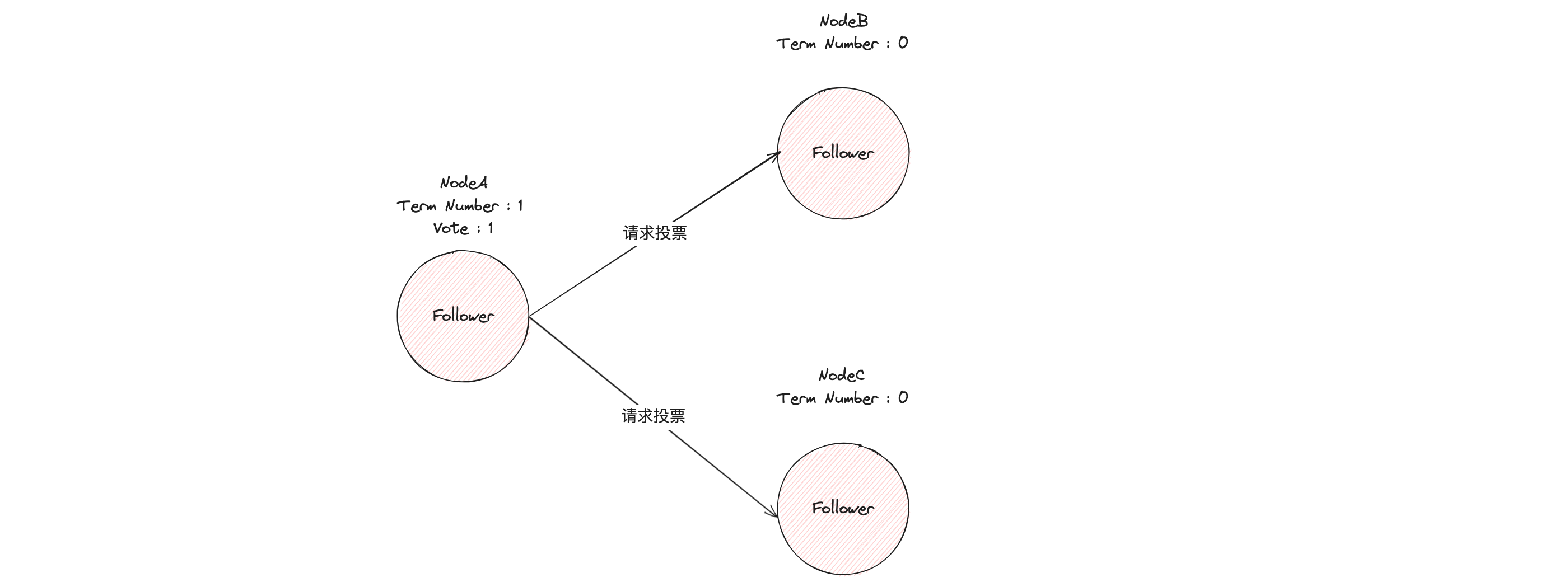
Si otros nodos reciben la solicitud del candidato A para votar el mensaje RPC y aún no han votado en el período número 1, votarán por el nodo A y aumentarán su número de período.
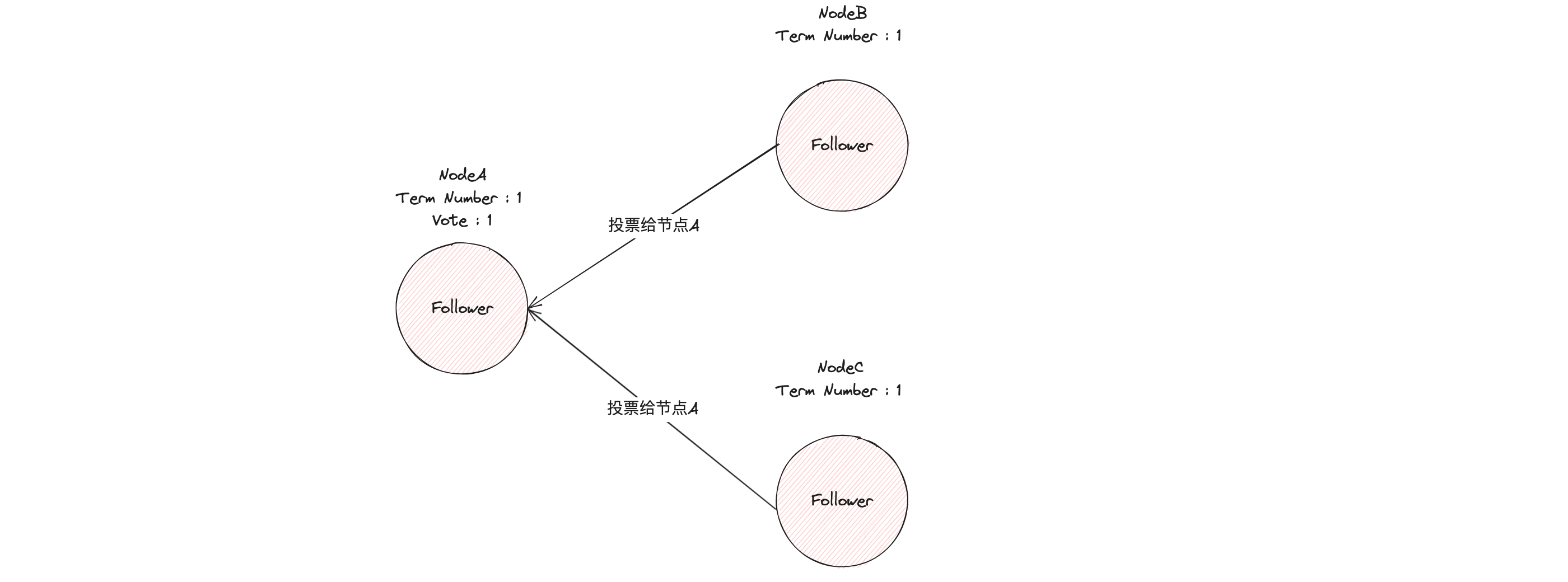
Si un candidato obtiene la mayoría de votos dentro del tiempo límite de las elecciones, se convierte en el nuevo líder para el mandato actual.

Después de que el nodo A sea elegido líder, enviará periódicamente mensajes de latido para notificar a otros servidores que es el líder, evitando que los seguidores inicien nuevas elecciones y usurpen el poder.
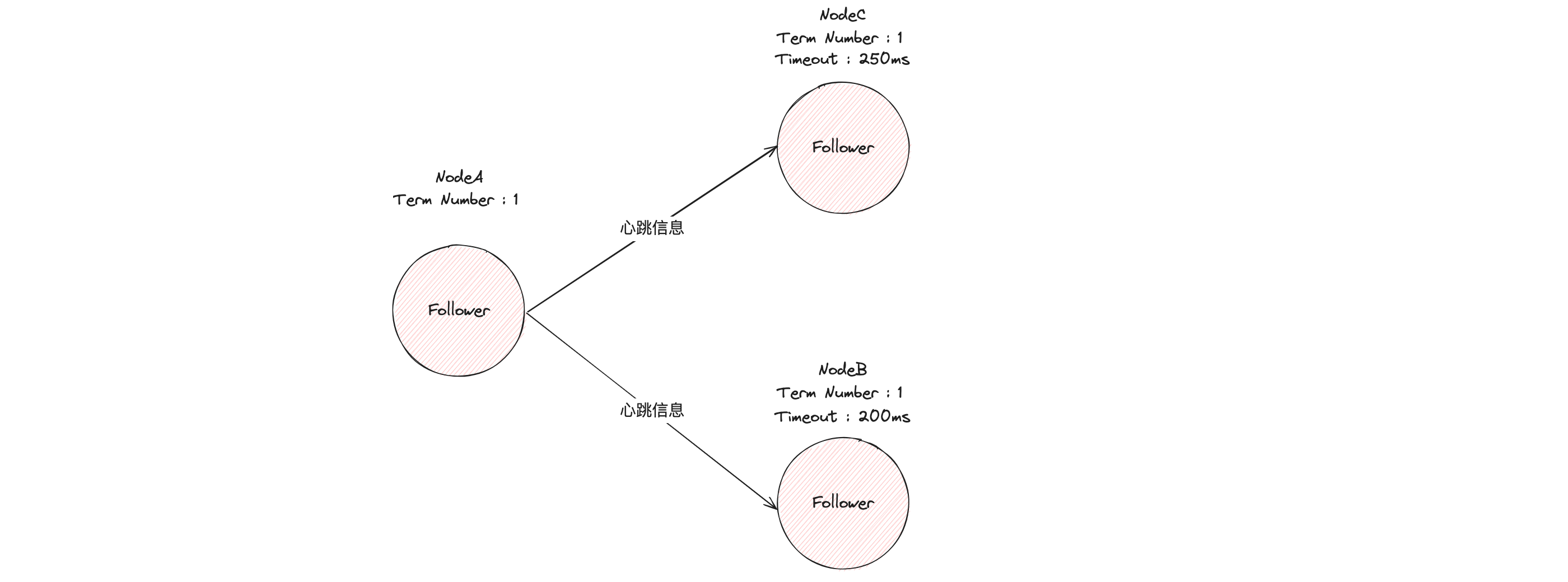
4.3 Definiciones relacionadas del proceso de elección del algoritmo Raft
Algunas definiciones relevantes del proceso de elección del algoritmo Raft:
- Comunicación entre nodos: en el algoritmo Raft, la comunicación entre nodos se logra principalmente mediante llamadas a procedimientos remotos (RPC). Los principales RPC incluyen RequestVote y AppendEntries.
- Término: en el algoritmo Raft, el término es un reloj lógico que se utiliza para distinguir diferentes ciclos electorales. Cada vez que comienza una nueva ronda de elecciones, se incrementa el número de mandatos. Los números de términos también se utilizan para evitar interferencias causadas por información caducada.
- Reglas de elección: hay dos reglas principales en el proceso de elección del algoritmo Raft. En primer lugar, un nodo sólo puede votar por el primer candidato que le solicite un voto y cuyo registro esté al menos tan actualizado como el suyo. En segundo lugar, un candidato debe obtener votos de una mayoría de nodos para convertirse en el nuevo líder.
- Tiempo de espera aleatorio: en el algoritmo Raft, el tiempo de espera aleatorio se utiliza para activar una nueva ronda de elecciones. Cuando un seguidor no recibe un latido del líder dentro del período de tiempo de espera, se convierte en candidato y comienza una nueva ronda de elecciones. Este tiempo de espera es aleatorio para evitar que varios nodos inicien elecciones al mismo tiempo.
4.4 Estructura de registro del algoritmo de balsa
El algoritmo Raft completa el procesamiento de transacciones distribuidas mediante la replicación de registros.
En el algoritmo Raft, la entrada de registro (Log Entry) es una estructura de datos clave, que incluye principalmente las siguientes partes:
- Comando: esta es una solicitud de operación enviada por el cliente al líder, como agregar un nuevo par clave-valor;
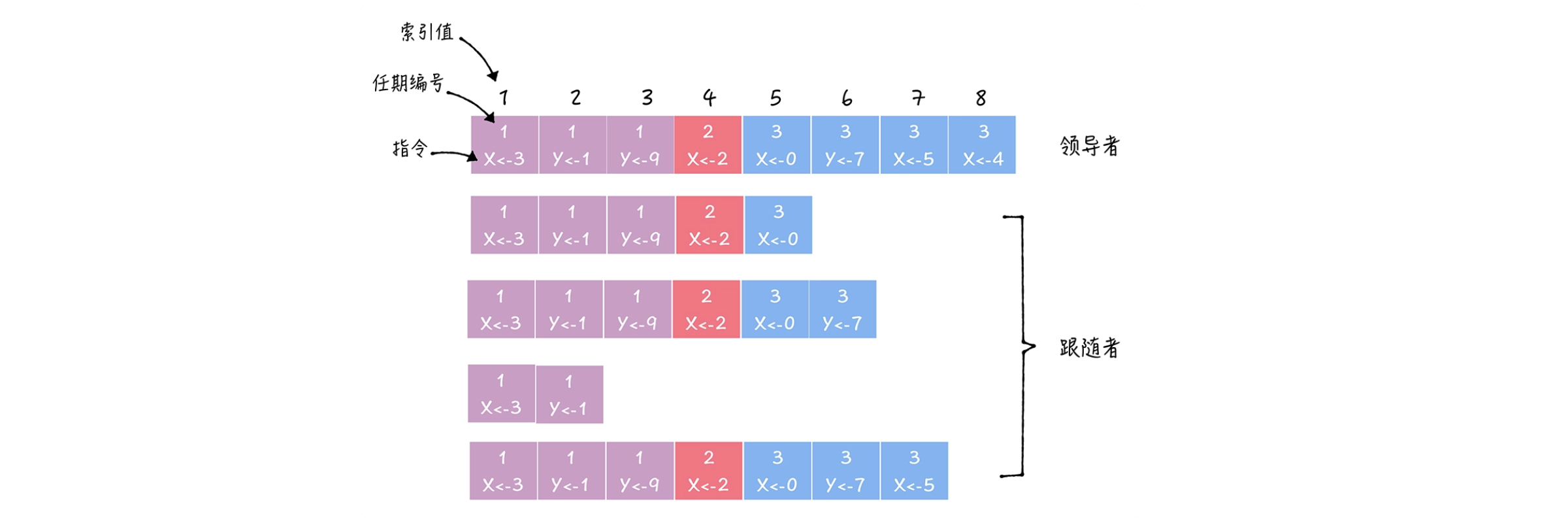
- Valor de índice (índice de registro): este es un número único que se utiliza para identificar la posición de esta entrada de registro en el registro. El índice se incrementa en el orden en que se agregan las entradas del registro;
- Número de término (Term): Este es un número que identifica el término en el que se agregó esta entrada de registro. El término número se puede utilizar para determinar la antigüedad de una entrada de registro.
A través de esta estructura, el registro del algoritmo Raft puede guardar todas las operaciones en el sistema y garantizar que estas operaciones se puedan ejecutar en el mismo orden en todos los nodos, logrando así la coherencia del sistema.
4.5 Replicación de registros del algoritmo Raft
La replicación de registros de Raft puede entenderse como una confirmación optimizada de dos fases (optimizando la segunda fase en una fase), que reduce los mensajes de ida y vuelta a la mitad, lo que significa reducir el retraso del mensaje a la mitad. ¿Cuál es el proceso específico de replicación de registros?
En este proceso, el líder primero copia las entradas del registro a otros seguidores y luego espera la confirmación de la mayoría de los seguidores. Una vez que la mayoría de los seguidores han confirmado, el líder aplica la entrada del registro a su máquina de estado y devuelve el éxito al cliente.
Una optimización clave en este proceso es que el líder no notifica directamente a los seguidores que realicen entradas de registro. En cambio, el seguidor conoce la posición de envío del registro del líder a través de la replicación del registro o mensajes de latido. Cuando el seguidor recibe el mensaje de latido del líder o un nuevo mensaje de replicación de registro, aplicará esta entrada de registro a su propia máquina de estado.
Esta optimización reduce la demora en el procesamiento de las solicitudes de los clientes, optimiza el envío de dos fases a una sola fase y reduce la demora del mensaje a la mitad. Este es un mecanismo importante para que el algoritmo Raft logre una coherencia distribuida.
El proceso de replicación de registros incluye principalmente los siguientes pasos:
- El cliente envía una solicitud: cuando el cliente tiene una nueva solicitud de operación, enviará la solicitud al líder (Líder);
- El líder agrega una entrada de registro: después de recibir la solicitud del cliente, el líder agregará la solicitud como una nueva entrada de registro a su propio registro;
- El líder copia las entradas del registro: el líder copia las nuevas entradas del registro a otros seguidores (Seguidor);
- Los seguidores escriben entradas de registro: después de recibir una solicitud de replicación del líder, el seguidor escribe nuevas entradas de registro en su propio registro;
- El líder confirma la entrada del registro: cuando la mayoría de los seguidores han escrito una nueva entrada del registro, el líder marca la entrada del registro como confirmada y aplica la entrada del registro a su propia máquina de estado;
- El líder notifica al seguidor que envíe la entrada del registro: el líder le dirá al seguidor que la entrada del registro se envió en el siguiente mensaje de latido, y el seguidor también debe aplicar esta entrada del registro a su propia máquina de estado;
A través de este proceso, el algoritmo Raft garantiza que todos los nodos del sistema vean las mismas operaciones y las realicen en el mismo orden, logrando así la coherencia del sistema.
4.6 Cambio de integrantes de la Balsa
En el algoritmo Raft, el cambio de miembros es un proceso importante y complejo. Para evitar la aparición de dos líderes durante el proceso de cambio de miembros, el algoritmo Raft adopta el método de consenso conjunto (Consenso Conjunto).
En el método de consenso conjunto, el algoritmo Raft primero creará una nueva configuración, que contiene nodos antiguos y nodos nuevos. Luego, el líder agregará esta nueva configuración como una entrada de registro a su registro y replicará esta entrada de registro en otros nodos. Cuando la mayoría de los nodos antiguos y nuevos hayan escrito la nueva configuración, el líder enviará esta configuración y la aplicará a su propia máquina de estado. Finalmente, el líder informará a otros nodos que se ha enviado la nueva configuración y otros nodos también deberían aplicar la nueva configuración a sus propias máquinas de estado.
Este proceso garantiza que durante los cambios de membresía, el sistema cambiará a la nueva configuración solo cuando la mayoría de los nodos antiguos y nuevos hayan aceptado la nueva configuración. Esto evita tener dos líderes durante los cambios de membresía.
Además, debido a que el método de consenso conjunto es difícil de implementar, han surgido cambios de servidor único, que es una mejora del algoritmo Raft. Puede simplificar el proceso de cambio de miembros, pero requiere mecanismos adicionales para garantizar la coherencia del sistema. .
5. Otros modelos de transacciones distribuidas
5.1 Modelo TCC
Modelo TCC: el modelo TCC (Probar-Confirmar-Cancelar) es un modelo de transacción de compensación de envío de dos etapas. En el modelo TCC, las transacciones se dividen en dos fases: fase de prueba (Try) y fase de confirmación (Confirm). Durante la fase de prueba, la transacción reserva los recursos necesarios del sistema. Durante la fase de confirmación, la transacción realmente realiza la operación y libera los recursos reservados. Si ocurre un error durante la fase de confirmación, la transacción ejecutará la fase de cancelación (Cancelar) para deshacer las operaciones realizadas durante la fase de intento.
Como modelo de transacción de compensación de envío de dos etapas, el modelo TCC (Probar-Confirmar-Cancelar) incluye principalmente las siguientes tres etapas:
- Etapa de prueba: esta etapa es principalmente para verificar el sistema comercial y reservar los recursos comerciales necesarios;
- Fase de confirmación: esta fase es principalmente para confirmar los recursos comerciales reservados en la fase de prueba. Si la fase de prueba se ejecuta con éxito, la fase de confirmación debe ser exitosa. Si esta fase falla, se reintentará hasta tener éxito o alcanzar el número máximo de reintentos;
- Fase de cancelación: esta fase se utiliza principalmente para revertir el negocio cuando falla la ejecución del negocio y cancelar los recursos comerciales reservados en la fase de prueba. Igual que la fase de Confirmación, si esta fase falla, se reintentará hasta tener éxito o alcanzar el número máximo de reintentos.
La ventaja del modelo TCC es que puede proporcionar una mejor garantía de coherencia empresarial, se controla a nivel de aplicación y no depende del soporte de middleware como la base de datos subyacente. Sin embargo, la desventaja del modelo TCC es que requiere modificar el código comercial y proporcionar tres operaciones para cada operación: probar, confirmar y cancelar, lo que aumenta la complejidad del desarrollo.
5.2 Modelo SAGA
Modelo SAGA: SAGA es un modelo de procesamiento de transacciones de larga duración. En el modelo SAGA, una transacción de larga duración se descompone en una serie de subtransacciones, que pueden ejecutarse de forma independiente y en diferentes momentos en el tiempo. Si una subtransacción falla, SAGA realizará una serie de operaciones de compensación para deshacer la subtransacción que se ha ejecutado. Este modelo es adecuado para manejar transacciones de larga duración y transacciones distribuidas.
El modelo SAGA incluye principalmente los siguientes tres pasos:
- Transacción dividida: divida una transacción larga en múltiples subtransacciones, cada subtransacción se puede completar y enviar de forma independiente.
- Ejecutar transacciones: ejecute estas subtransacciones en un orden determinado. Si todas las subtransacciones se ejecutan exitosamente, entonces toda la transacción larga se ejecuta exitosamente.
- Transacción de compensación: si alguna subtransacción falla durante la ejecución de subtransacciones, entonces se debe realizar una operación de compensación. La operación de compensación consiste en revertir las subtransacciones que se han ejecutado con éxito para garantizar la coherencia de los datos.
La ventaja del modelo SAGA es que puede manejar transacciones largas y orquestación de servicios, y no necesita depender del soporte de middleware como la base de datos subyacente como 2PC y 3PC. Sin embargo, la desventaja del modelo SAGA es la necesidad de proporcionar operaciones de compensación para cada subtransacción, lo que aumenta la complejidad del desarrollo. Al mismo tiempo, si la operación de compensación falla, puede producirse una inconsistencia en los datos.
5.3 Modelo ZAB
El modelo ZAB (ZooKeeper Atomic Broadcast) es un protocolo de coherencia utilizado por ZooKeeper. El protocolo ZAB se utiliza principalmente para garantizar la coherencia del estado en todos los servidores, especialmente cuando se elige un nuevo líder después de que el líder falla para garantizar la coherencia del estado del servicio. El protocolo ZAB incluye dos modos básicos: recuperación ante fallos y transmisión de mensajes.
- Recuperación de fallas: cuando el líder falla o la red se divide, ZooKeeper ingresará al modo de recuperación de fallas. En este modo, los nodos restantes elegirán un nuevo líder. Una vez elegido el nuevo líder, es necesario sincronizarlo con otros nodos para garantizar que todos los nodos tengan un estado coherente.
- Difusión de mensajes: cuando se elige al líder y el estado de todos los nodos es consistente, ZooKeeper ingresará al modo de transmisión de mensajes. En este modo, todas las solicitudes de transacción se reenvían al líder. Cuando el líder procesa una solicitud de transacción, primero transmitirá la solicitud de transacción como una propuesta a todos los seguidores. Cuando la mayoría de los seguidores hayan aceptado la propuesta, el líder presentará la propuesta y notificará a todos los seguidores para que la envíen.
De esta forma, el protocolo ZAB puede garantizar la coherencia del sistema en un entorno distribuido.
El protocolo ZAB (ZooKeeper Atomic Broadcast) es un protocolo de coherencia utilizado por ZooKeeper y tiene las siguientes ventajas:
-
Gran coherencia: el protocolo ZAB puede garantizar que todos los nodos en un entorno distribuido puedan ver el mismo estado y realizar operaciones en el mismo orden, logrando así una gran coherencia.
-
Tolerancia a fallos: el protocolo ZAB puede restaurar la coherencia del sistema después de que el líder falla eligiendo un nuevo líder y sincronizando el estado de todos los nodos.
-
Alta disponibilidad: el protocolo ZAB proporciona alta disponibilidad al replicar el estado en múltiples nodos. Incluso si algunos nodos fallan, el sistema puede continuar brindando servicios mientras la mayoría de los nodos sigan funcionando.
-
Garantía de secuencia: el protocolo ZAB puede garantizar que todas las solicitudes de transacciones se ejecuten en un orden global determinado. Esto es muy importante para aplicaciones que requieren coherencia secuencial.
-
Simplicidad: el protocolo ZAB es relativamente simple en diseño e implementación, lo que lo hace fácil de entender y usar.
Debido al espacio limitado, este artículo no proporciona un análisis más detallado ni una introducción a ZAB...
6. Práctica, optimización y desarrollo futuro del procesamiento de transacciones distribuidas.
6.1 Práctica de procesamiento de transacciones distribuidas
En los sistemas distribuidos reales, el procesamiento de transacciones distribuidas es una cuestión importante. A continuación se muestran algunos marcos y herramientas de código abierto de uso común:
-
Seata: Seata es una solución de transacciones distribuidas de código abierto de Alibaba que proporciona cuatro modos de transacciones distribuidas: AT, TCC, SAGA y XA. Seata utiliza el ID de transacción global XID para coordinar transacciones entre microservicios e implementa la reversión de transacciones a través de UndoLog para garantizar la coherencia de las transacciones en caso de fallas a nivel de red o aplicación.
-
RocketMQ: RocketMQ es el middleware de mensajería de código abierto de Alibaba y sus transacciones distribuidas se implementan principalmente a través de mecanismos de revisión y semimensaje. Después de que el productor envía el medio mensaje, RocketMQ volverá a consultar periódicamente con el productor para confirmar si el mensaje se puede consumir.
-
Apache Kafka: Kafka es una plataforma de procesamiento de flujo de código abierto que utiliza el mecanismo Semántica Exactamente Una Vez para garantizar la coherencia de las transacciones distribuidas. Las transacciones de Kafka se identifican mediante el ID de la transacción. Al iniciar una transacción, el productor enviará una solicitud InitProducerId al coordinador de transacciones de Kafka para obtener el ID de la transacción.
-
Apache Flink: Flink es un marco de procesamiento de flujo de código abierto que utiliza el mecanismo Checkpoint para garantizar la coherencia de las transacciones distribuidas. El mecanismo Checkpoint de Flink guarda periódicamente el estado del sistema y, cuando el sistema falla, se puede restaurar desde el último Checkpoint.
Todos los marcos y herramientas anteriores proporcionan potentes capacidades de procesamiento de transacciones distribuidas, y se pueden seleccionar las herramientas adecuadas en función de las necesidades comerciales reales y el entorno del sistema.
6.2 Optimización y mejora del procesamiento de transacciones distribuidas
En el procesamiento de transacciones distribuidas, la optimización y la mejora se centran principalmente en los siguientes aspectos:
-
Reducir el uso de bloqueos: los bloqueos son un mecanismo importante para garantizar la coherencia de las transacciones, pero demasiados bloqueos harán que el rendimiento del sistema se degrade. Por lo tanto, puede reducir el uso de bloqueos y mejorar la concurrencia del sistema optimizando el diseño y la secuencia de ejecución de las transacciones;
-
Procesamiento asincrónico y por lotes: la comunicación de red supone una sobrecarga importante al procesar transacciones distribuidas. La comunicación asincrónica y el procesamiento por lotes se pueden utilizar para reducir la cantidad y el retraso de las comunicaciones de la red y mejorar el rendimiento del sistema;
-
Utilice coherencia eventual: en algunos escenarios, ciertas inconsistencias de datos son aceptables. En estos escenarios, se pueden utilizar protocolos eventualmente consistentes, como el protocolo BASE, para reemplazar protocolos muy consistentes, como el protocolo de confirmación de dos fases, para mejorar el rendimiento del sistema;
-
Utilice transacciones de compensación: en algunos escenarios, las transacciones de compensación se pueden utilizar para manejar fallas en las transacciones. Las transacciones de compensación pueden realizar algunas operaciones para restaurar la coherencia del sistema después de que falla una transacción. Este método puede mejorar la confiabilidad del sistema, pero requiere el diseño de operaciones de compensación apropiadas;
-
Utilice la persistencia y el registro: mediante la persistencia y el registro, el estado de las transacciones se puede restaurar después de una falla del sistema para garantizar la coherencia del sistema. Al mismo tiempo, los registros también se pueden utilizar para monitorear y diagnosticar problemas del sistema.
En los sistemas reales, es necesario seleccionar métodos apropiados de optimización y mejora en función de las características y necesidades del sistema.
6.3 Desarrollo futuro del procesamiento de transacciones distribuidas
Con el desarrollo de los microservicios y la computación en la nube, la importancia del procesamiento de transacciones distribuidas se ha vuelto cada vez más prominente. Las siguientes son algunas posibles tendencias de desarrollo futuro y direcciones de investigación:
-
Elasticidad y adaptabilidad: a medida que aumenta la escala del sistema y cambian los requisitos comerciales, el procesamiento de transacciones distribuidas debe ser más elástico y adaptable, y puede ajustar dinámicamente las estrategias y parámetros del procesamiento de transacciones de acuerdo con el estado y la carga del sistema;
-
Eficiente y escalable: a medida que aumenta la cantidad de datos, el procesamiento de transacciones distribuidas debe poder manejar transacciones más grandes manteniendo un rendimiento eficiente. Esto puede requerir nuevos algoritmos y tecnologías, como algoritmos de procesamiento de transacciones distribuidas y paralelas, así como estructuras de datos y tecnologías de almacenamiento más eficientes;
-
Tolerancia a fallos y recuperación: a medida que aumenta la complejidad del sistema, las fallas y errores se vuelven más comunes. El procesamiento de transacciones distribuidas requiere capacidades de recuperación y tolerancia a fallas más sólidas, que pueden recuperarse rápidamente cuando ocurre una falla y al mismo tiempo garantizar la coherencia de las transacciones;
-
Seguridad y privacidad: con la creciente importancia de la seguridad y la privacidad de los datos, el procesamiento de transacciones distribuidas debe considerar cómo proteger la seguridad y la privacidad de los datos garantizando al mismo tiempo la coherencia;
-
Nuevos modelos informáticos: con el desarrollo de nuevos modelos informáticos, como la computación cuántica y la informática de punta, es posible que se necesiten nuevos modelos y protocolos de procesamiento de transacciones distribuidas para adaptarse a las características de estos nuevos modelos informáticos.
Todas las anteriores son posibles tendencias de desarrollo futuras y direcciones de investigación del procesamiento de transacciones distribuidas, pero el desarrollo específico debe observarse y juzgarse en función del desarrollo de la tecnología y los negocios.