Prefacio
Con la llegada de la era digital, la tecnología de procesamiento de imágenes de documentos desempeña un papel cada vez más importante en todos los ámbitos de la vida. En el foro especial del 12.º Foro de la Cumbre de la Industria Inteligente de China 2023 (CIIS 2023), el Dr. Ding Kai, subdirector general e ingeniero senior de la División de Plataforma de Tecnología Inteligente de la Información Hehe, compartió las dificultades actuales que enfrenta el procesamiento de imágenes de documentos y discutió los principales temas. Modelar avances y nuevas exploraciones en este campo.
El hermano Xu Zhu recopiló los puntos clave y mi comprensión personal y los compartió con todos ~
1. ¿Qué es el procesamiento de imágenes de documentos?
El procesamiento de imágenes de documentos se refiere al análisis y comprensión de imágenes de documentos a través de computadoras para lograr la extracción y el procesamiento automatizados de información. La imagen del documento puede ser un archivo escaneado, una fotografía u otro archivo de imagen. El procesamiento de imágenes de documentos puede incluir tareas como reconocimiento de texto, análisis de diseño, comprensión de relaciones entre entidades y segmentación de imágenes.
El procesamiento de imágenes de documentos tiene importantes aplicaciones en muchos campos, como la oficina automatizada, las finanzas, la educación, etc. A través del procesamiento automatizado, se puede mejorar la eficiencia del trabajo, se pueden reducir los errores manuales y la recuperación y extracción de información se puede realizar de forma más rápida y precisa.
2. Dificultades técnicas en el análisis, reconocimiento y comprensión de imágenes de documentos.
El primero es la diversidad de escenas y formatos: diferentes tipos de documentos tienen diferentes formatos y diseños, lo que plantea grandes desafíos para el análisis y la comprensión de las imágenes de los documentos.
En segundo lugar, la forma es incontrolable: la forma del documento puede estar curvada, doblada o dañada, lo que dificulta el reconocimiento y la restauración del documento.

Además, la incertidumbre del equipo de adquisición y la diversidad de necesidades de los usuarios también aumentan la complejidad del procesamiento de imágenes de documentos.
Alta precisión: instrumentos financieros

Comprensible: educación, archivos, oficina.


Finalmente, la iluminación es incontrolable. El brillo y el ángulo de la iluminación en el entorno de captura de documentos también tendrán un impacto importante en la calidad de la imagen.
3. Presentación de la empresa
Jeje Information se ha centrado en tecnologías centrales en el campo del reconocimiento de texto inteligente y big data comercial , centrándose en los campos de análisis y reconocimiento de imágenes de documentos y comprensión de texto, y ha estado profundamente involucrado en la inteligencia artificial durante 17 años . He oído hablar de Jeje Información, pero su familia Deberías haber oído hablar de los productos: busca y escanea en la tienda de aplicaciones, y aparecerá el primer producto.

La versión gratuita de Scanner Almighty ocupa el primer lugar en la clasificación de descargas de aplicaciones gratuitas de productividad en 105 países y regiones (incluida China) en la App Store.
4. Temas de investigación del modelo grande de imágenes de documentos
El análisis, reconocimiento y comprensión de imágenes de documentos son temas importantes de investigación. Durante el proceso de preprocesamiento y análisis de imágenes de documentos, se requieren pasos como la mejora de bordes, la eliminación de muaré, la corrección de curvatura, la compresión de imágenes y la detección de PS para mejorar la precisión del análisis y reconocimiento posteriores. El análisis y reconocimiento de documentos incluye tareas como reconocimiento de texto, reconocimiento de tablas y análisis de archivos electrónicos para lograr una extracción y expresión precisas del contenido del documento. El análisis y la restauración del diseño implican enlaces centrales como la detección de elementos, la identificación de elementos y la restauración del diseño para restaurar con precisión la información de diseño original del documento.
La extracción y comprensión de información de documentos es uno de los aspectos importantes de la investigación. La tecnología de extracción de información puede extraer y organizar información específica en documentos, responder preguntas planteadas por los usuarios o generar automáticamente resúmenes de documentos. Además, los problemas de seguridad de la IA también son un aspecto que no se puede ignorar: es necesario prestar atención a tecnologías como la clasificación de manipulación, la detección de manipulación, la detección sintética y la detección de generación de IA para garantizar la autenticidad e integridad de los documentos.
Además, el conocimiento, la recuperación y la gestión del almacenamiento son también una de las direcciones importantes de la investigación. Al extraer información en profundidad, como relaciones entre entidades y temas de documentos, se puede establecer un gráfico de conocimiento para lograr expresión visual y recuperación rápida de documentos. Al mismo tiempo, combinado con tecnologías como ERP/OA y SAP, se puede crear un sistema de gestión de documentos eficiente e inteligente para respaldar el trabajo diario de oficina y la toma de decisiones.
5. Avances en modelos de imágenes de documentos grandes
5.1 Modelo grande propietario de imagen de documento
Los modelos de imágenes de documentos de gran tamaño han logrado avances significativos en los últimos años, los más notables de los cuales son algunos modelos propietarios como la serie LayoutLM, UDOP y LiLT. Estos modelos están previamente entrenados y ajustados para tareas posteriores basadas en el codificador Transformer multimodal y tienen un rendimiento significativo en el procesamiento de imágenes de documentos.
La serie LayoutLM es una serie de modelos lanzados por Microsoft, incluidos LayoutLM, LayoutLMv2, LayoutLMv3 y LayoutXLM. Estos modelos aprovechan el codificador Transformer multimodal para el entrenamiento previo y mejoran el rendimiento mediante el ajuste de las tareas posteriores.
UDOP es otro modelo unificado de procesamiento de documentos propuesto por Microsoft, que utiliza un codificador unificado Vision-Text-Layout y decodificadores Text-Layouot y Vision separados. Este modelo tiene como objetivo unificar varias tareas de procesamiento de documentos en un marco para mejorar la eficiencia y precisión del procesamiento.
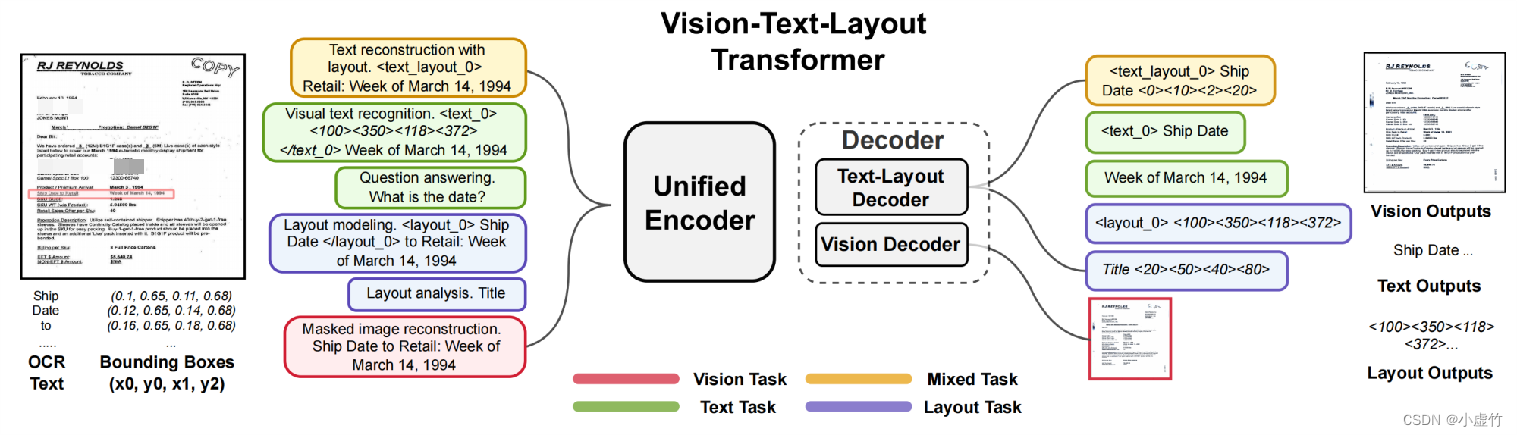
LiLT es un nuevo marco de extracción de información multimodal para el desacoplamiento y el modelado conjunto de modelos visuales y modelos de lenguaje grandes que están investigando Hehe Information y la Universidad Tecnológica del Sur de China . Este marco integra modelos visuales y de lenguaje a través del Módulo de atención complementaria bidireccional (BiCAM) y tiene un rendimiento superior en escenarios de muestra pequeña/muestra cero en varios idiomas. Curiosamente, LiLT se puede combinar de manera flexible con modelos de preentrenamiento de texto en uno o varios idiomas para resolver tareas posteriores, y también muestra un rendimiento superior en tareas posteriores en un solo idioma (especialmente en conjuntos de datos con menos muestras de entrenamiento). LiLT también generalmente funciona mejor que LayoutXLM en conjuntos de datos de un solo idioma de uso común.

Finalmente, Donut es un modelo Transformer desarrollado por NAVER para la comprensión de documentos sin OCR. El desarrollo de este modelo puede simplificar los procesos de procesamiento de documentos y aumentar la precisión y eficiencia del procesamiento.

5.2 Modelo grande multimodal
BLIP2 es un modelo lanzado por el equipo de Salesforce en enero de 2023. Utiliza un transformador de consulta liviano para conectar el codificador de imágenes previamente entrenado y el decodificador LLM. En la etapa de aprendizaje de representación, el modelo permite a Q-Former extraer características relacionadas con el texto a través de tres tareas: aprendizaje de comparación de imagen-texto, generación de imagen-texto y coincidencia de imagen-texto. En la etapa de preentrenamiento generativo, el codificador visual y Q-Former se conectan al LLM congelado y las características visuales se alinean con el LLM a través del entrenamiento generativo.

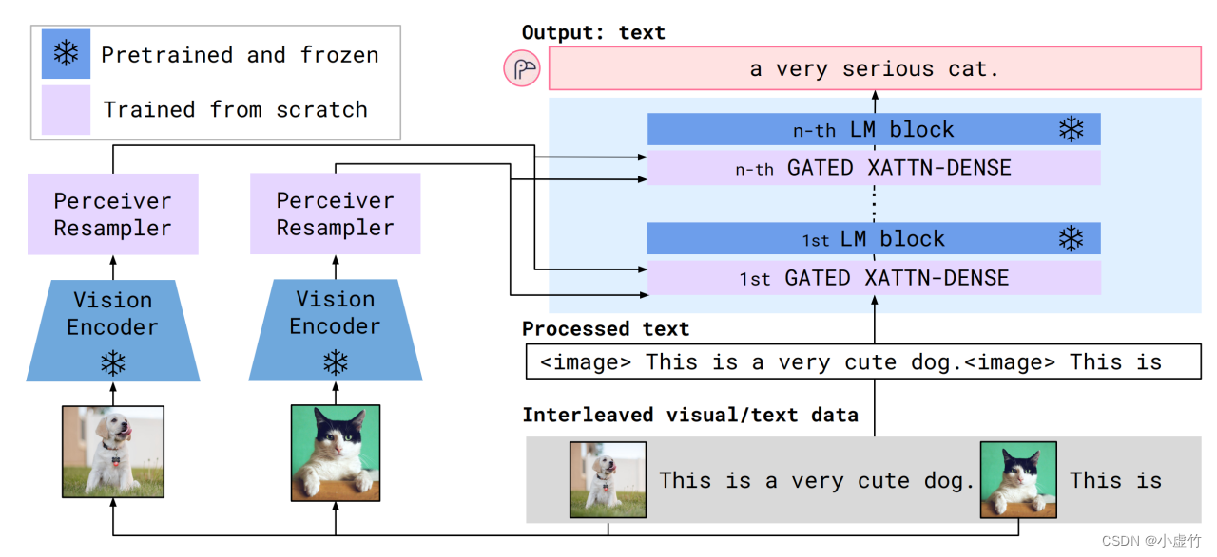
Flamingo es un modelo publicado por DeepMind en 2022, que agrega una capa de atención cerrada a LLM para introducir información visual. Este modelo congela Vision Encoder y LLM, y agrega el módulo Perceiver Resampler después de Visual Encoder para mejorar la representación visual. Además, se agrega un módulo cerrado con densidad de xattn antes de cada capa de LLM para mejorar la interacción de información entre módulos. En marzo de 2023, el equipo de LAION lanzó OpenFlamingo, una réplica de código abierto del modelo Flamingo de DeepMind.
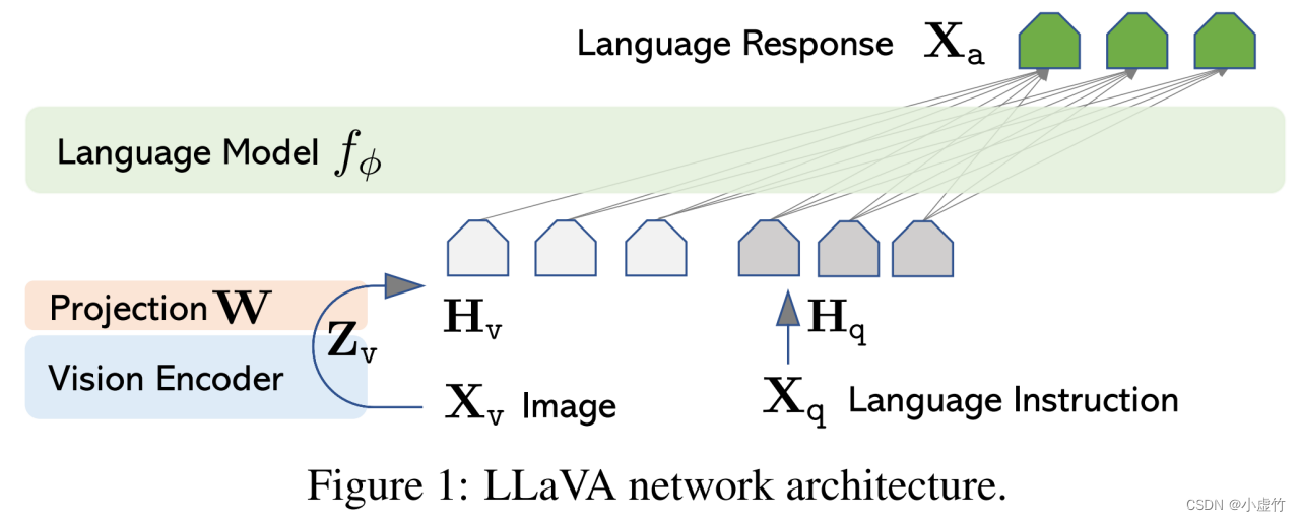
LLaVA es un modelo lanzado recientemente por Microsoft que conecta CLIP ViT-L y LLaMA mediante una capa totalmente conectada. El modelo utiliza GPT-4 y Self-Instruct para generar datos de seguimiento de instrucciones de 158k de alta calidad.
Finalmente, MiniGPT-4 es un modelo que utiliza ViT+Q-Former para la parte visual, Vicuña para la parte del modelo de lenguaje y una capa completamente conectada entre los módulos visual y de lenguaje.
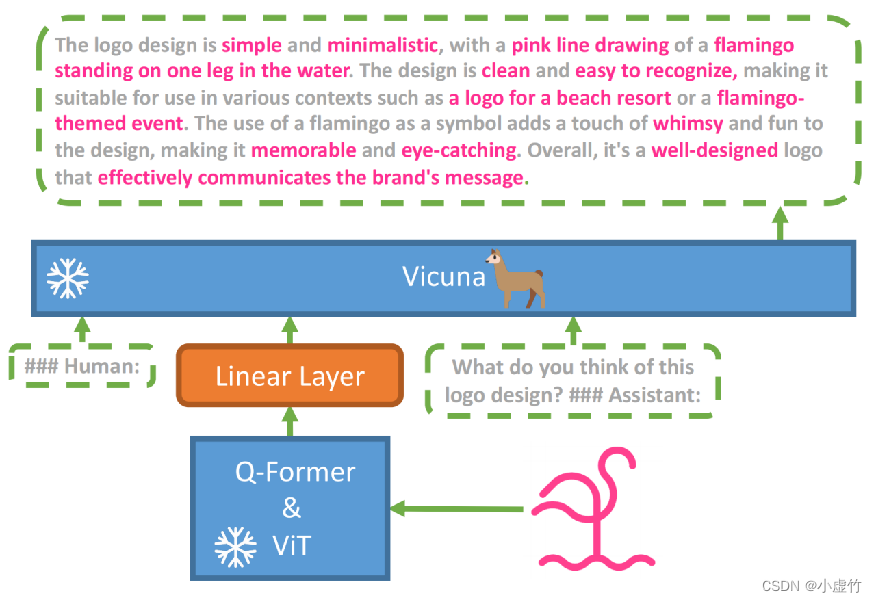
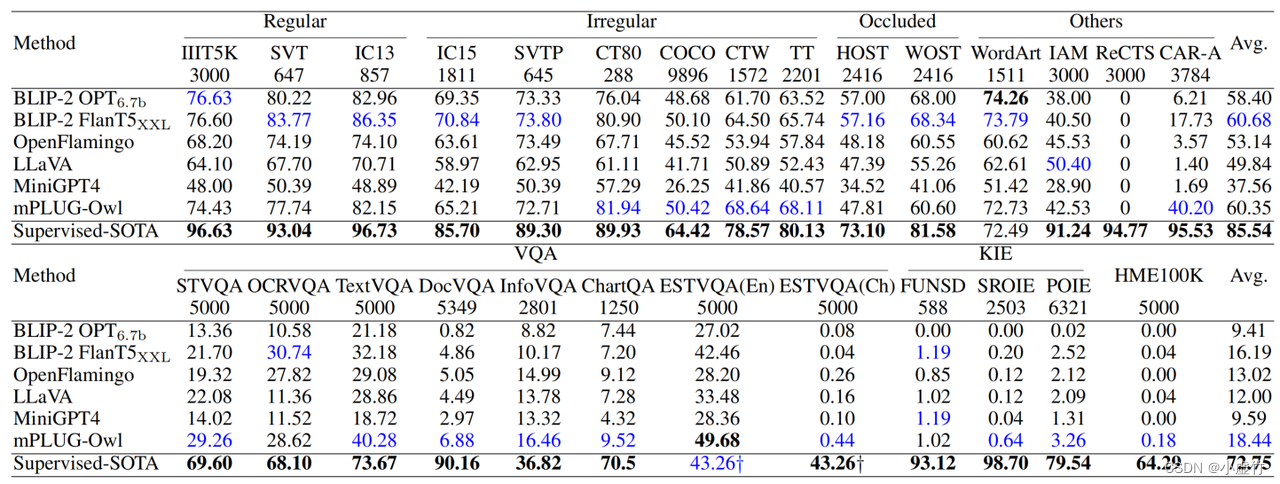
Limitaciones del uso de grandes modelos multimodales en el campo de OCR
Los modelos grandes multimodales funcionan bien cuando manejan texto destacado, pero tienden a funcionar mal cuando manejan texto detallado. Esto se debe a limitaciones en la resolución y los datos de entrenamiento del codificador visual. Aunque los modelos existentes han logrado grandes avances, todavía tienen algunas limitaciones.
La resolución del codificador visual tiene un gran impacto en el rendimiento de grandes modelos multimodales. Dado que la información visual suele contener una gran cantidad de detalles y complejidad, se necesitan codificadores de alta resolución para capturar estos detalles. Sin embargo, el coste computacional de los codificadores de alta resolución es correspondientemente alto, lo que limita la velocidad de entrenamiento y la eficiencia del modelo.
Los datos de entrenamiento también son un factor que limita el rendimiento de grandes modelos multimodales. Los modelos existentes se basan principalmente en conjuntos de datos previos al entrenamiento a gran escala para el entrenamiento, y estos conjuntos de datos a menudo solo contienen algunas imágenes y texto a gran escala. Por lo tanto, es posible que estos modelos no manejen bien algunos textos detallados porque no han visto este tipo de textos en el conjunto de datos de entrenamiento.
La forma en que se procesan los grandes modelos multimodales también es uno de los factores que afectan su rendimiento. Dado que estos modelos se centran principalmente en la correspondencia intermodal entre imágenes y texto, pueden ignorar cierta información detallada dentro del texto. Esto hace que estos modelos funcionen mal al procesar texto detallado que requiere atención al detalle.
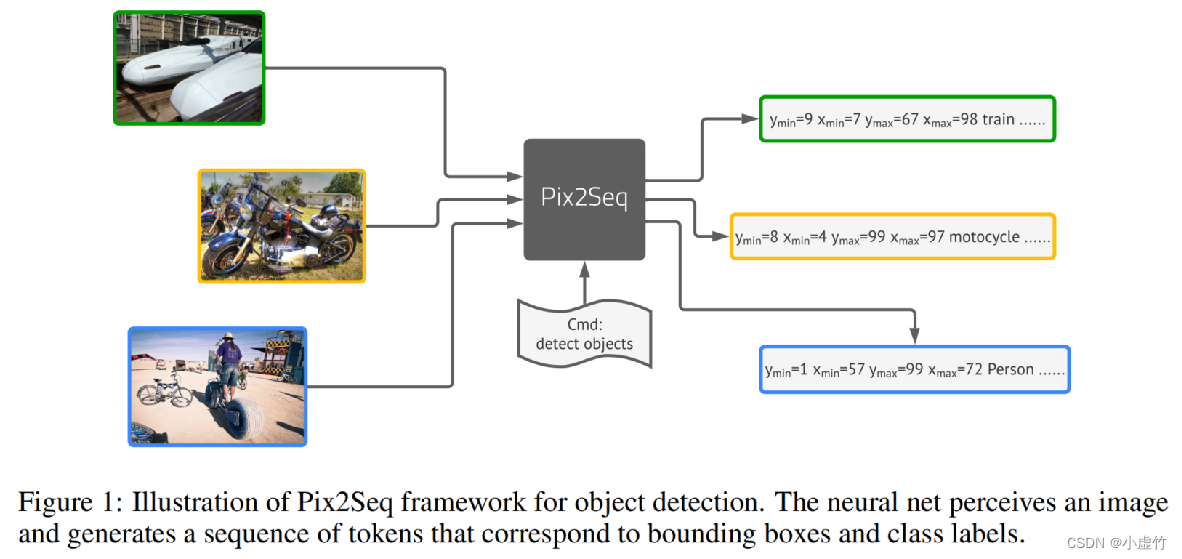
5.3 Serie de modelos grandes Pixel2seq
El método Pix2Seq de Google convierte la tarea de detección de objetivos en una tarea de modelado de lenguaje de imagen a secuencia. A través del modelado de lenguaje, el modelo aprende a extraer características útiles de la imagen y realizar una clasificación razonable, completando así la tarea de detección de objetivos. Este método utiliza tecnología de aprendizaje profundo y entrena una gran cantidad de datos para que el modelo pueda identificar de forma rápida y precisa varios objetivos en la imagen.
Después de Pix2Seq, Google propuso un marco más completo, Pix2Seq v2. Pix2Seq v2 es un marco de tareas de visión basado en predicción de secuencia unificada, que se puede utilizar para resolver diversos problemas de visión, como detección de objetivos, clasificación de imágenes, segmentación de imágenes, etc. Este marco adopta un nuevo mecanismo de atención, que permite que el modelo se centre mejor en áreas clave de la imagen de entrada para completar mejor la tarea.
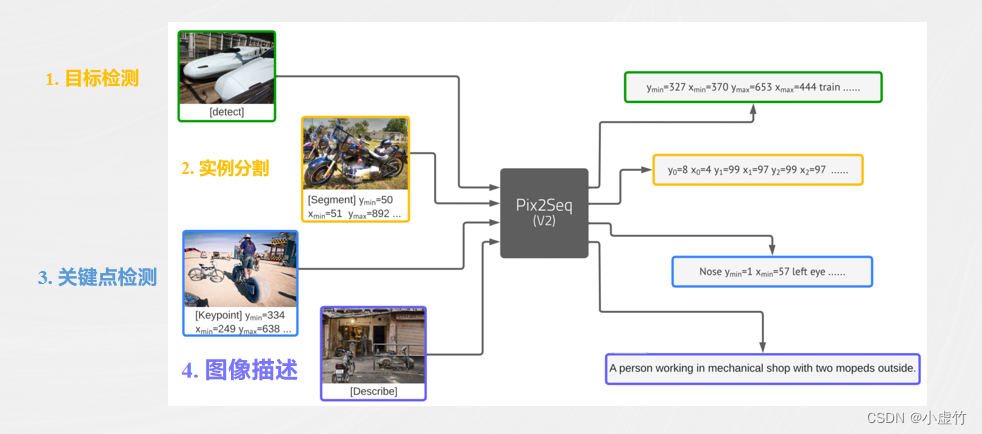
A diferencia de Google, Microsoft ha propuesto un método de codificador multimodal (imagen y texto) + decodificador autorregresivo llamado UniTAB, que puede completar una variedad de tareas de Vision-Language (VL). Este método combina orgánicamente dos modalidades diferentes, imagen y texto, y utiliza un decodificador autorregresivo para la predicción, logrando así tareas de clasificación de imágenes y detección de objetivos más eficientes y precisas.
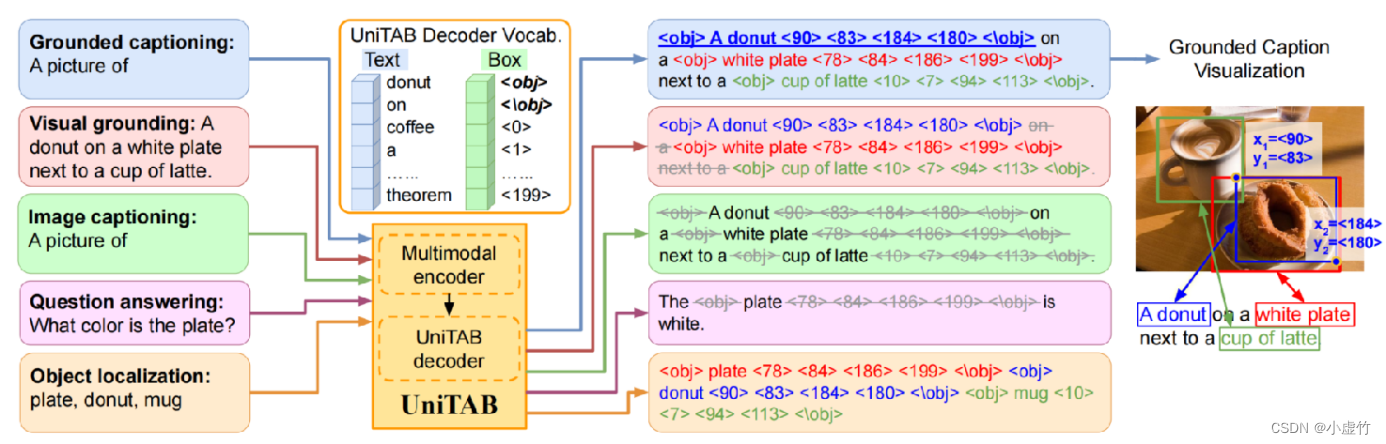
Meta también propuso un nuevo método TURRÓN. Este método realiza la salida de la imagen del documento a la secuencia del documento utilizando Swin Transformer y Transformer Decoder. Swin Transformer es una nueva estructura Transformer que interactúa con información local y global y tiene mejores capacidades de expresión de características visuales. El Transformer Decoder puede convertir las diversas características visuales mencionadas anteriormente en formato de texto, lo que facilita que las personas comprendan el contenido de la imagen.

6. Exploración de modelos de imágenes de documentos grandes.
6.1 Ideas de diseño para un modelo grande de imagen de documento
El análisis de reconocimiento de imágenes de documentos es un campo integral que cubre una variedad de tareas que se pueden definir en forma de predicción de secuencia. Ya sea texto, párrafos, análisis de diseño, tablas o fórmulas, etc., todos pueden procesarse mediante modelos basados en predicción de secuencia.
Al realizar tareas de OCR, podemos utilizar diferentes indicaciones para guiar al modelo a completar varias tareas. Por ejemplo, podemos ingresar instrucciones específicas o información contextual para permitir que el modelo comprenda y reconozca mejor el contenido del documento.
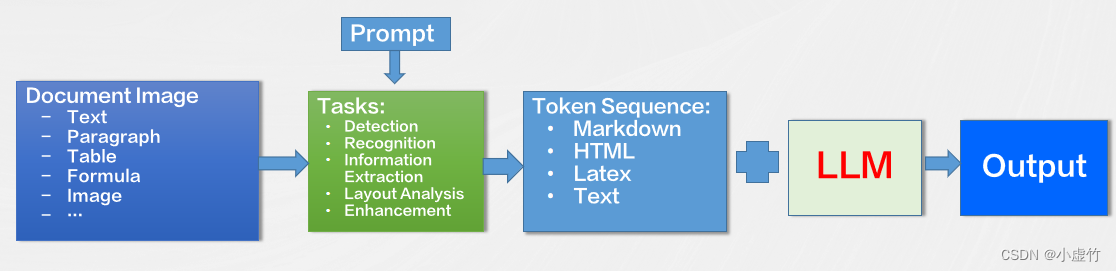
Además del reconocimiento básico de caracteres y vocabulario, la tecnología OCR también puede admitir el análisis de reconocimiento de imágenes de documentos a nivel de capítulo. Esto significa que todo el documento se puede escanear, analizar y generar en formatos estándar como Markdown, HTML o texto sin formato. Este método puede ayudarnos a organizar y procesar el contenido del documento de manera más eficiente, mejorando así en gran medida la eficiencia del trabajo.
En los últimos años, LLM (Large Scale Language Model) ha logrado grandes avances en el campo del procesamiento del lenguaje natural. De manera similar, LLM también se puede aplicar a trabajos relacionados con la comprensión de documentos. Al combinar LLM con la tecnología OCR, podemos comprender mejor el contenido del documento y extraer información útil del mismo. Esto promoverá aún más el desarrollo de la tecnología de procesamiento de documentos y mejorará los niveles de automatización y la eficiencia de la producción.
6.2 Modelo grande de imagen de documento SPTS
SPTS es un método innovador de detección y reconocimiento de texto de un extremo a otro que subvierte el proceso tradicional de detección y reconocimiento de texto. Los métodos tradicionales suelen tratar la detección y el reconocimiento de texto como dos tareas independientes, lo que da lugar a procesos de procesamiento complejos y redundantes. SPTS integra estas dos tareas y define la detección y el reconocimiento de texto como tareas de predicción de imagen a secuencia, lo que simplifica enormemente el proceso de procesamiento. Además, SPTS utiliza tecnología de anotación de un solo punto para indicar la posición del texto, lo que puede reducir en gran medida los costos de anotación. Al mismo tiempo, no requiere muestreo de RoI ni operaciones complejas de posprocesamiento, integrando verdaderamente la detección y el reconocimiento.


SPTS v2 desacopla la detección y el reconocimiento en dos procesos: detección autorregresiva de un solo punto y reconocimiento de texto paralelo. Entre ellos, IAD obtiene de forma autorregresiva las coordenadas de un solo punto de cada texto en función de las características del codificador visual. Este proceso es autorregresivo, por lo que puede mejorar en gran medida la velocidad de inferencia. PRD obtiene los resultados de reconocimiento de cada texto en paralelo en función de las características de un solo punto de IAD. Este método de procesamiento en paralelo puede mejorar aún más la eficiencia del procesamiento. SPTS v2 también se puede aplicar a una variedad de escenarios de OCR diferentes.

El modelo unificado de OCR basado en SPTS (SPTS v3) define múltiples tareas de OCR como una forma de predicción de secuencia. Al utilizar diferentes indicaciones para guiar al modelo a completar diferentes tareas de OCR, la capacidad de generalización del modelo se puede mejorar enormemente. Por ejemplo, puedes usar "¿dónde está la fecha en este documento?" para preguntar la ubicación de una fecha en un documento, o "¿cuál es el texto en esta imagen?" para identificar el texto en una imagen. Además, SPTS v3 sigue la estructura de imagen a secuencia de CNN + Transformer Encoder + Transformer Decoder de SPTS, lo que le permite manejar varias tareas de OCR de manera más eficiente.

6.3 Próxima dirección de investigación
Un modelo de sistema complejo debería necesitar:
En la capa de entrada, el modelo puede recibir cualquier tipo de archivo de texto como entrada, incluidos documentos de Word, documentos PDF, etc. La tarea principal de esta capa es preprocesar datos de texto sin formato y preparar datos para etapas de procesamiento posteriores.
La capa de procesamiento es la parte central del modelo y realizará una serie de análisis y operaciones sobre los datos del texto de entrada, como segmentación de palabras, análisis gramatical, análisis semántico y revisión ortográfica. Estos pasos de procesamiento pueden ayudar al modelo a comprender y procesar mejor los datos de texto.
En la capa de salida, el modelo mostrará visualmente los resultados procesados, que pueden ser en forma de cuadros, gráficos, texto, etc. La tarea principal de esta capa es presentar resultados complejos del procesamiento de datos a los usuarios de una manera fácil de entender.
Aunque este modelo ha logrado un procesamiento de datos eficiente, todavía tiene margen para un mayor desarrollo y optimización. Por ejemplo, puede explorar cómo identificar y procesar varios tipos de datos de texto con mayor precisión, cómo mejorar el análisis de sintaxis y las técnicas de comprensión semántica para mejorar el rendimiento del modelo y cómo diseñar e implementar métodos de visualización de datos más efectivos para ayudar a los usuarios a comprender mejor. y utilizar la salida del modelo. La investigación y el desarrollo en estas direcciones promoverán el avance de la tecnología de procesamiento de datos textuales y tendrán un profundo impacto en muchos campos.
-
7. Resumen
Con la llegada de la era digital, la tecnología de procesamiento de imágenes de documentos se ha vuelto cada vez más importante. El procesamiento de imágenes de documentos utiliza computadoras para analizar y comprender las imágenes de los documentos para lograr la extracción y el procesamiento automatizados de la información. El procesamiento de imágenes de documentos se utiliza ampliamente en diversas industrias, como la automatización de oficinas, las finanzas y la educación. Al automatizar el procesamiento, puede aumentar la productividad, reducir los errores y proporcionar una recuperación y extracción de información más rápida y precisa.
Sin embargo, el procesamiento de imágenes de documentos enfrenta algunas dificultades técnicas. El primero es la diversidad de diferentes tipos de documentos. Los diferentes formatos y diseños plantean desafíos para el análisis y la comprensión. En segundo lugar, la forma es incontrolable: los documentos pueden estar curvados, doblados o dañados, lo que dificulta su identificación y restauración. Además, la incertidumbre del equipo de recolección y la diversidad de necesidades de los usuarios también aumentan la complejidad del procesamiento. Por último, la incontrolabilidad de la iluminación también tendrá un impacto importante en la calidad de la imagen.
Los modelos propietarios como la serie LayoutLM, UDOP, LiLT y Donut han logrado un rendimiento notable en el procesamiento de imágenes de documentos. Además, los grandes modelos multimodales como BLIP2, Flamingo y LLaVA también han logrado avances importantes en el procesamiento de imágenes de documentos.
Los modelos grandes multimodales todavía tienen limitaciones en el manejo de texto detallado. La resolución del codificador visual y las limitaciones de los datos de entrenamiento afectan su rendimiento. Además, estos modelos pueden ignorar la información interna y funcionar mal al procesar texto detallado.
Para seguir desarrollando la tecnología de procesamiento de imágenes de documentos, se pueden explorar las siguientes direcciones: optimizar el preprocesamiento de texto, mejorar los métodos de análisis y operación, mejorar el análisis de sintaxis y la tecnología de comprensión semántica, diseñar métodos de visualización de datos más efectivos, etc. Estos estudios promoverán el avance de la tecnología de procesamiento de imágenes de documentos y tendrán un profundo impacto en diversos campos.
Soy el hermano Xu Zhu, hasta luego ~