En 1974, el ganador del Premio Turing, Charles Bachman, asistió a una conferencia sobre bases de datos y conoció a Edgar Corder.
Cord aún no ha recibido el Premio Turing, pero su base de datos relacional es como un sol rojo que sale del este: el Premio Turing es sólo cuestión de tiempo.
Uno es el líder de las bases de datos en red y el otro es el abanderado de las bases de datos relacionales. Los dos maestros iniciaron un debate como si Marte chocara contra la Tierra.

Para los programadores actuales, las bases de datos relacionales como MySQL y Oracle son algo común.
En los libros de texto sobre bases de datos, las bases de datos relacionales se presentan casi por completo, y las bases de datos jerárquicas y las bases de datos en red son solo un pequeño adorno en la historia de las bases de datos.
Pero en la década de 1970, la nueva base de datos relacional fue cuestionada.
Porque en ese momento todos creían que los programadores deberían ser navegantes de estructuras de datos. Los programadores pueden recordar la relación entre cada registro y otros registros en la base de datos de la red, y luego navegar y acceder entre cada registro a través de "punteros".
Codd tenía una idea completamente diferente: los programadores no deberían tocar la estructura física subyacente.
Debería haber un lenguaje declarativo de nivel superior para acceder a los datos, completamente aislado del método de almacenamiento de datos subyacente de la base de datos.
Si utiliza un lenguaje declarativo para describir una consulta, ¿puede la base de datos convertirla "inteligentemente" en una consulta física subyacente?
Ya sabes, desarrollar compiladores para lenguajes de alto nivel (como Fortran) requirió mucho esfuerzo.
En 1972, IBM reclutó tropas y decidió conquistar esta montaña.
IBM está desarrollando un conjunto de prototipos de productos de bases de datos relacionales centrados en el instituto de investigación de San José, California, donde se encuentra Code.
A este proyecto prototipo se unen dos jóvenes estudiantes de doctorado, y juntos harán una gran aportación que quedará para la historia.

Tanto Chamberlain como Boyce respaldaron firmemente el modelo relacional de Codd.
Creo que esta idea es simple y hermosa, con un solo inconveniente: ¡es demasiado matemática!

Basada en el modelo relacional, la solución de consulta propuesta por Codd es aún más desalentadora.

Chamberlain y Beuys decidieron ocultar la parte matemática.
Llamaron tabla a la relación y luego reemplazaron los complejos símbolos matemáticos con un simple inglés SELECCIONAR DESDE DÓNDE para que la gente común pueda entenderlo.

Con el tiempo, el oscuro álgebra relacional y el cálculo relacional se convirtieron en un inglés que los no expertos pueden entender.

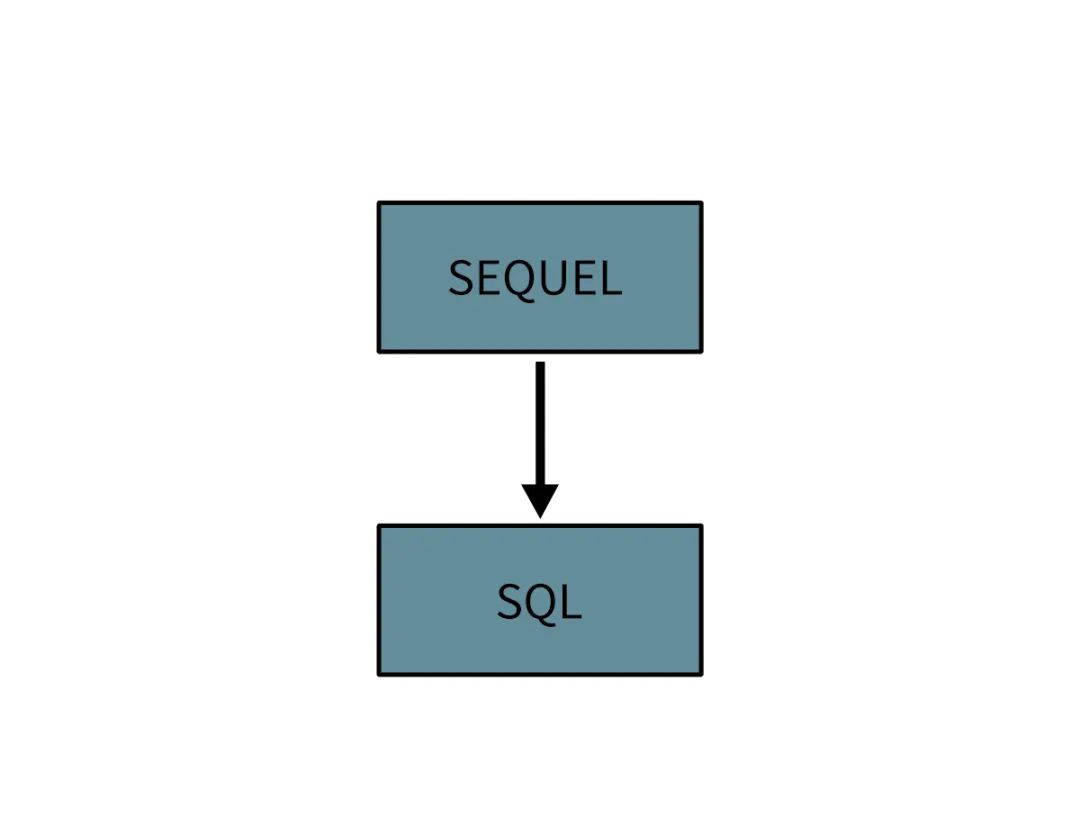
Llamaron a este lenguaje SEQUEL: Structured English Query Language, que es un lenguaje de consulta estructurado en inglés.
Más tarde, como SEQUEL ya era la marca registrada de una empresa británica, los dos tuvieron una idea y cambiaron el nombre a SQL, que es más sencillo y fácil de recordar.
En ese momento, IBM no tenía idea de comercializar SEQUL, por lo que permitió a Chamberlain y Boyce publicar el artículo en una conferencia técnica.
Los dos lanzaron una moneda para determinar quién leería el periódico y Boyce ganó.

Pero desafortunadamente, apenas un mes después de la reunión, Boyce murió de un tumor cerebral a la edad de 27 años.

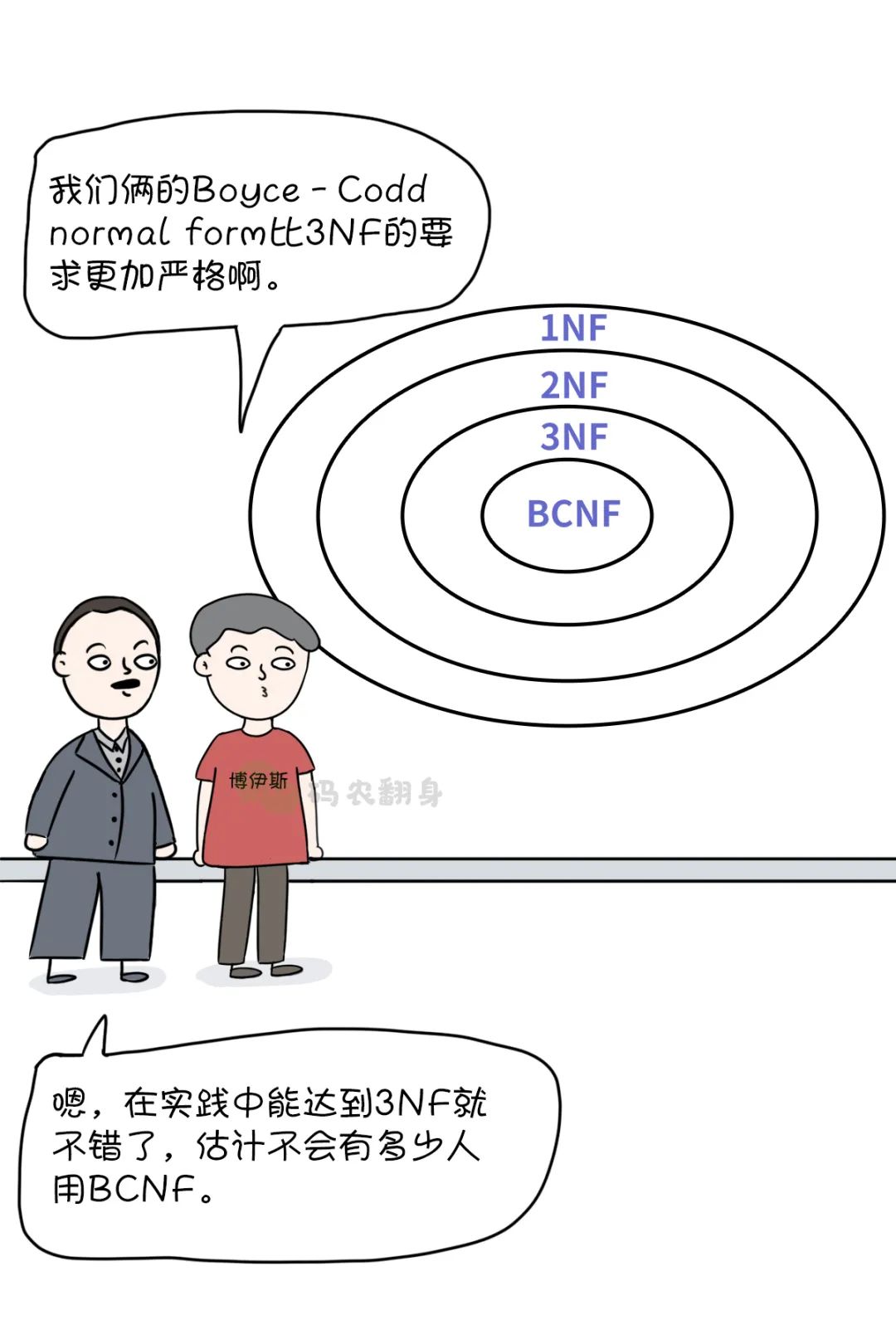
La contribución de Boyce no es solo SQL: colaboró con Codd para establecer un concepto que debe enseñarse en los libros de texto de bases de datos: Paradigma BCNF .
Chamberlain, que había perdido a su mejor amigo, pasó a cumplir el legado de Beuys.
Fue nombrado director técnico de System R, implementando SQL en System R, y también lo utilizó para demostrar las capacidades de la base de datos relacional: si era capaz de procesar transacciones comerciales.
Al mismo tiempo, con el mismo propósito, UC Berkeley también está desarrollando una base de datos relacional llamada Ingres, pero han propuesto su propio lenguaje de consulta: QUEL.

En la década de 1980, el precio de las computadoras siguió cayendo y finalmente alcanzó un punto crítico: un gran número de empresas podían comprar computadoras y software y almacenar sus formularios en papel en las computadoras.
La demanda de bases de datos comenzó a aumentar. Dado que las "tablas" son muy fáciles de entender, se ha vuelto sencillo desarrollar programas basados en bases de datos relacionales. Tanto System R como Ingres han logrado el éxito, pero ¿quién puede dominar el mundo entre SQL y QUEL?
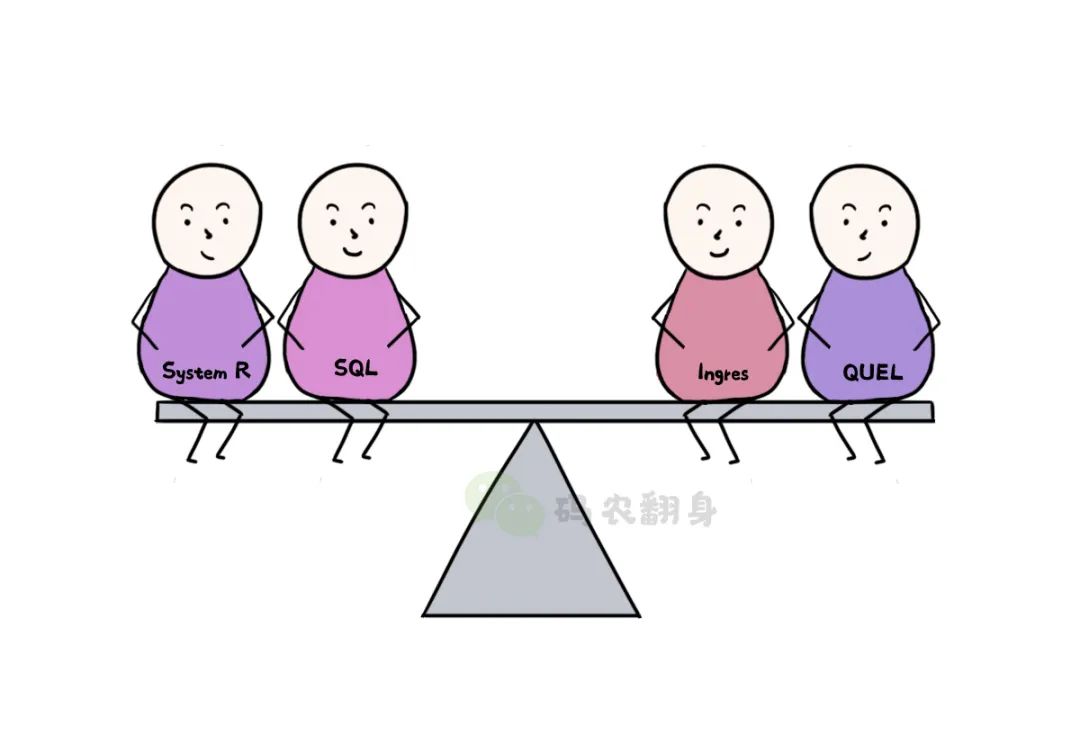
En ese momento, en San José, ciudad donde se encuentra Code, un joven llamado Larry cambió el equilibrio de la balanza.

Larry inmediatamente formó una pequeña empresa con dos de sus amigos para desarrollar una base de datos relacional basada en la minicomputadora VAX.
Profundamente influenciado por los artículos de Chamberlain y Beuys, naturalmente eligió SQL.

En 1979, se lanzó oficialmente Oracle y Larry confió en su "relación" para vender con éxito la base de datos a varios departamentos del gobierno de EE. UU.

La aplicación de Oracle en el gobierno de los EE. UU. fue tan exitosa que el gobierno de los EE. UU. emitió un estándar federal de procesamiento de información, especificando que SQL debe usarse en bases de datos federales en lugar de otros lenguajes de consulta.
Nunca imaginarías que Oracle, que ahora es famoso, haya hecho una contribución significativa a la popularización de SQL.
Pronto, organizaciones importantes como ANSI e ISO adoptaron SQL como estándar formal.
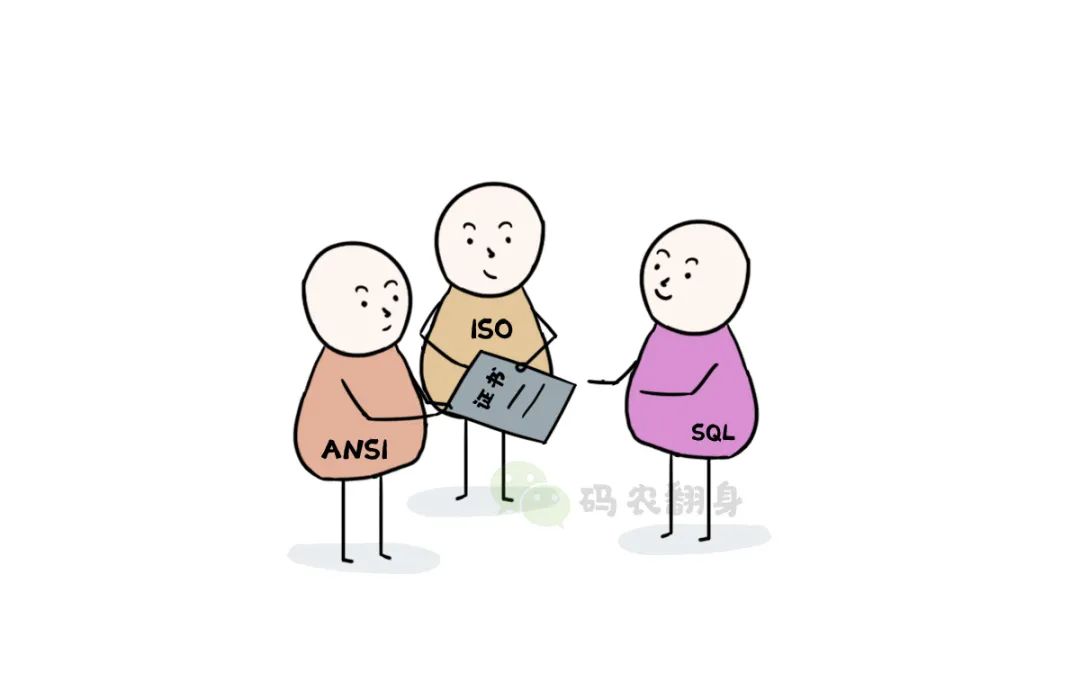
El SQL certificado oficialmente derrotó a QUEL y se convirtió en el ganador final.
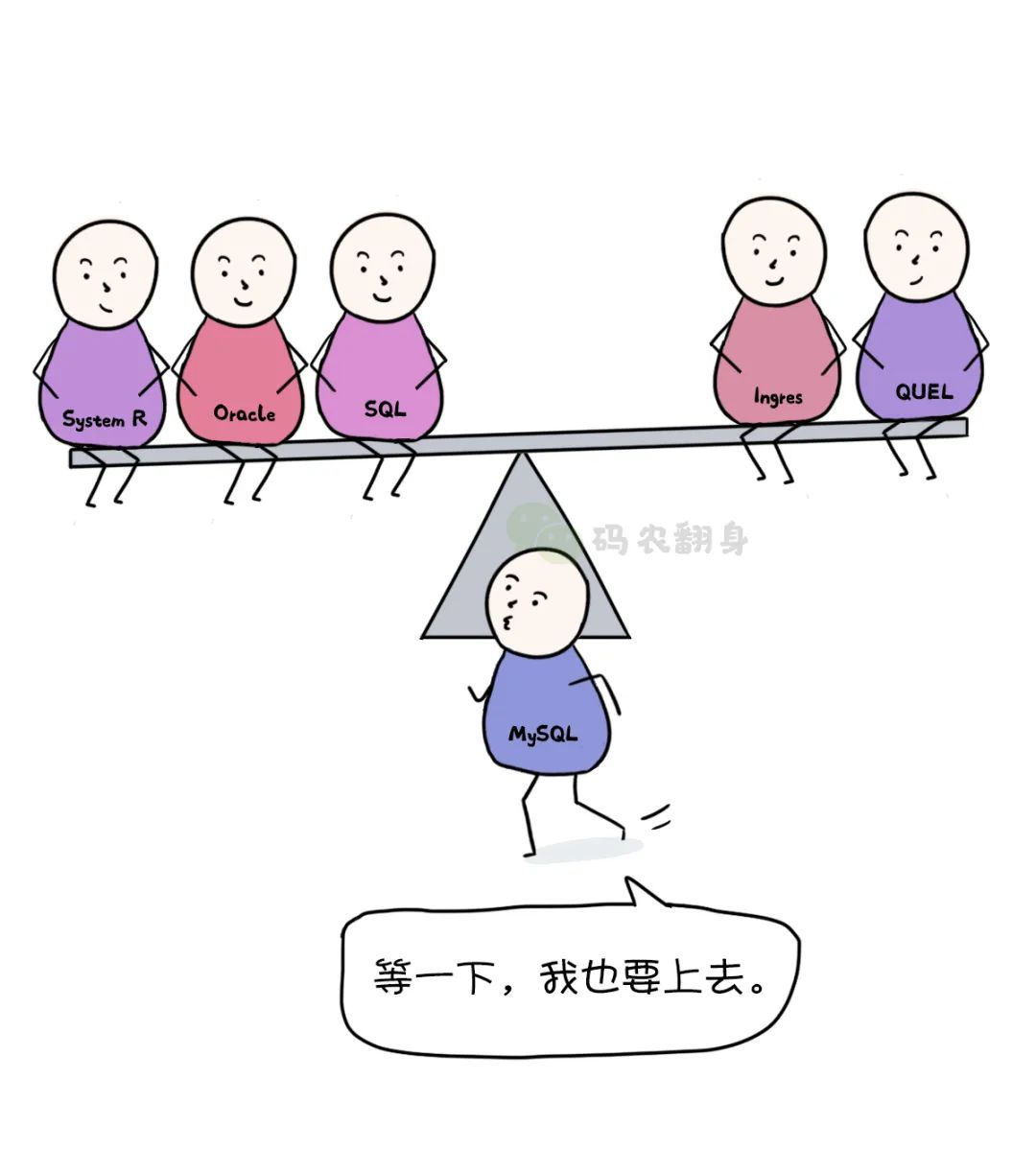
En la década de 1990, incluso el propio Ingres abandonó QUEL y comenzó a adoptar SQL.
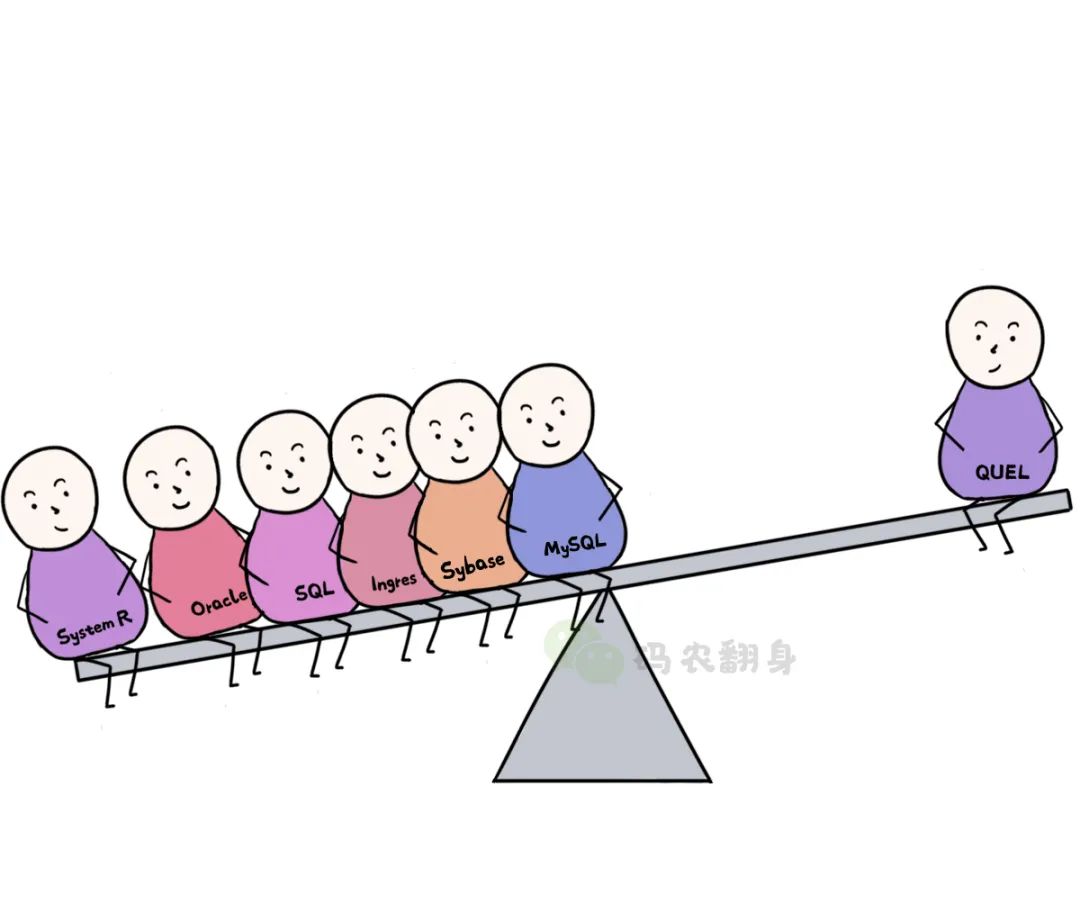
Los datos relacionales y SQL arrasaron el mercado en las décadas de 1980 y 1990 y se generalizaron.
Codd ganó el premio Turing en 1983. Chamberlain ganó el premio ACM Software Systems en 1988.

A finales de la década de 1990 surgió un nuevo formato de datos: XML.
XML es muy popular y todo el mundo quiere tener algo que ver con XML.

Este formato de datos es muy diferente de una base de datos relacional y también enfrenta el problema de cómo consultarlo.
Chamberlain utilizó su experiencia para definir un nuevo lenguaje de consulta, XQuery .
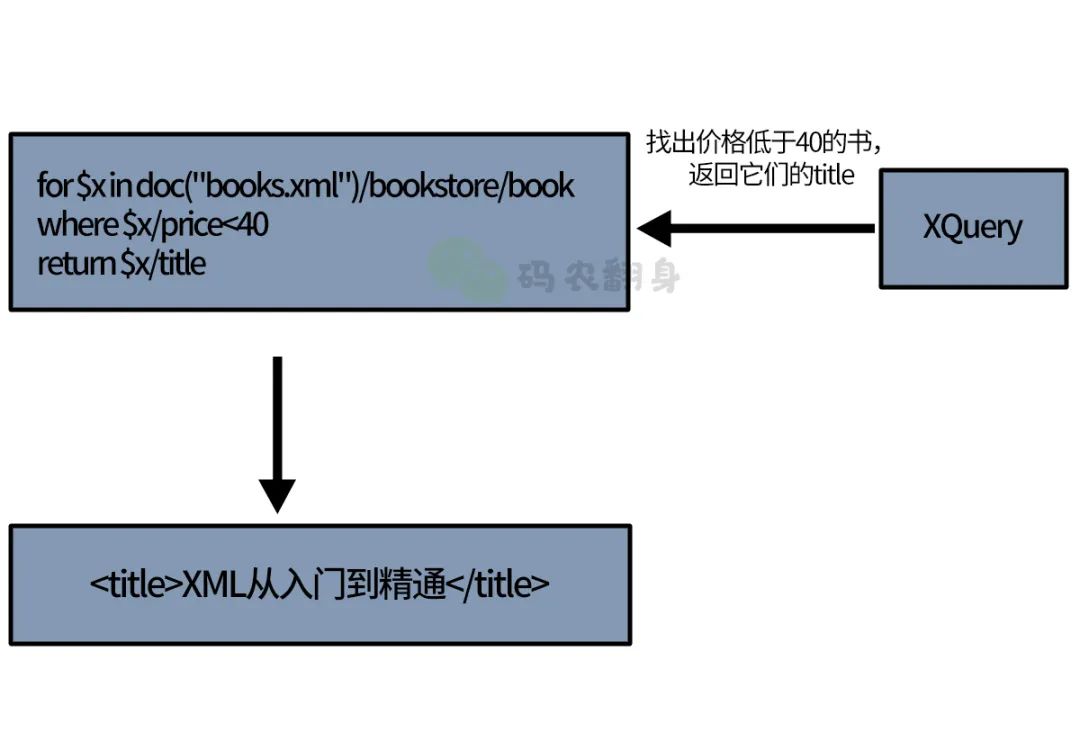
Pero el tiempo ha demostrado que XML no se ha convertido en un formato de almacenamiento de datos ampliamente utilizado, por lo que XQuery no se utiliza tanto como SQL.

Después de años de desarrollo, SQL ha ejercido una amplia influencia y ha ocupado con éxito las mentes de los programadores.
Para reducir los costos de aprendizaje, muchos productos se esfuerzan por estar más cerca de SQL incluso aunque la capa subyacente no sea una base de datos relacional, especialmente conceptos básicos como SELECT, FROM, WHERE, Order By y Group.

SQL se ha convertido en el rey de la consulta de datos.
Hasta que un día, apareció un tipo llamado NoSQL con un grupo de chicos.
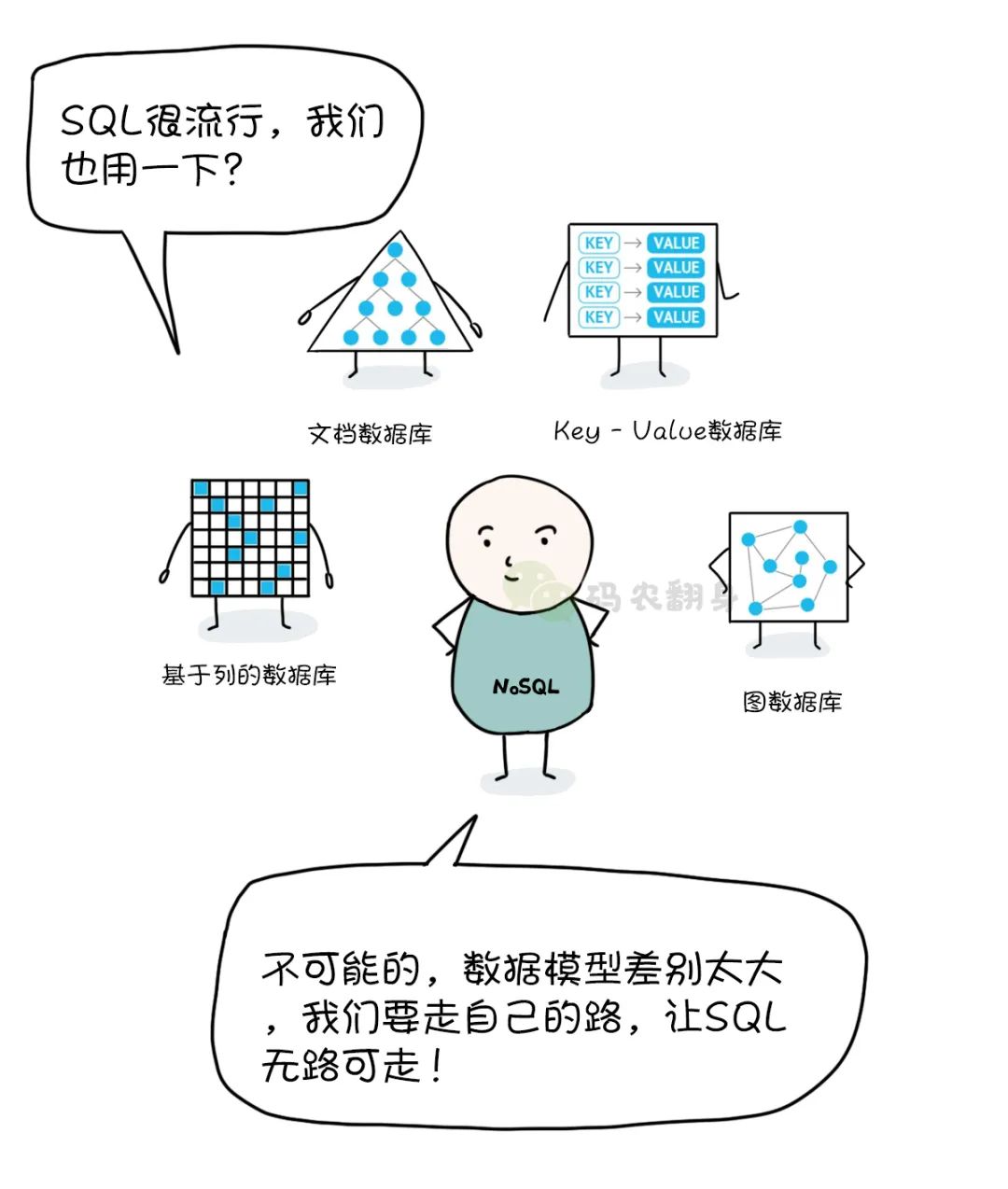
(encima)