1. Uso básico de ES
1. Crea un índice
Cree un índice de prueba http://localhost:9200/test
2. Eliminar índice
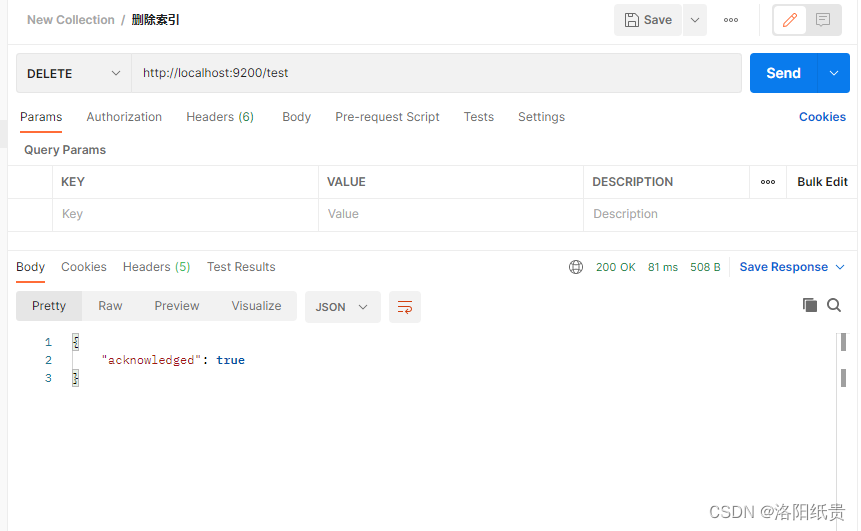
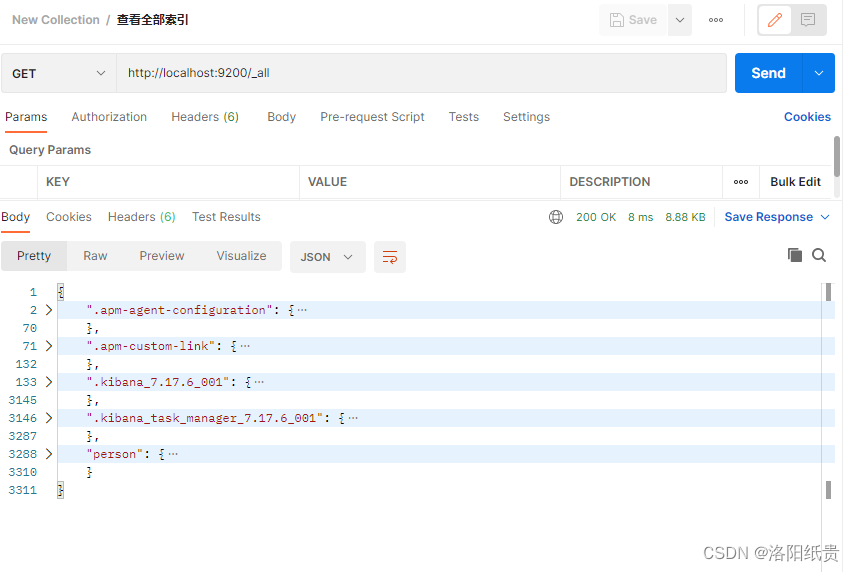
3. Ver índice
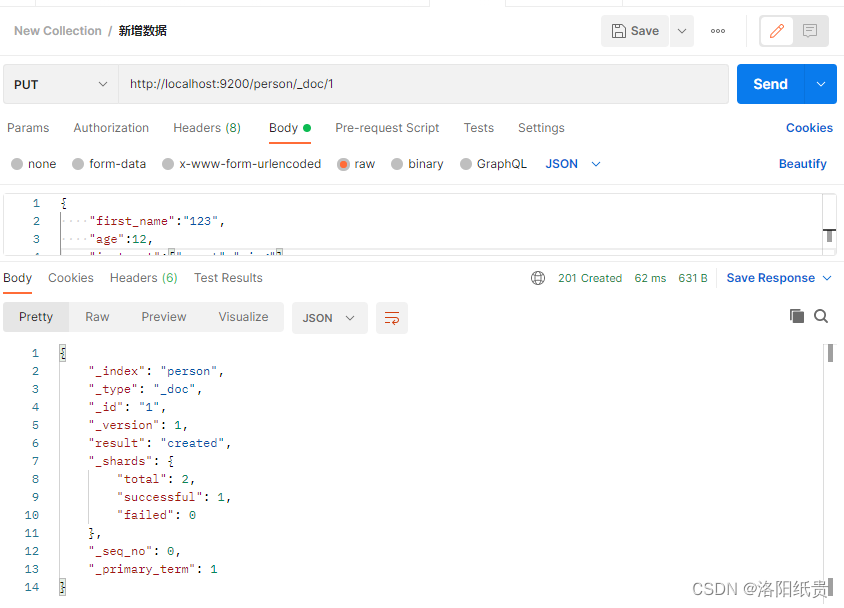
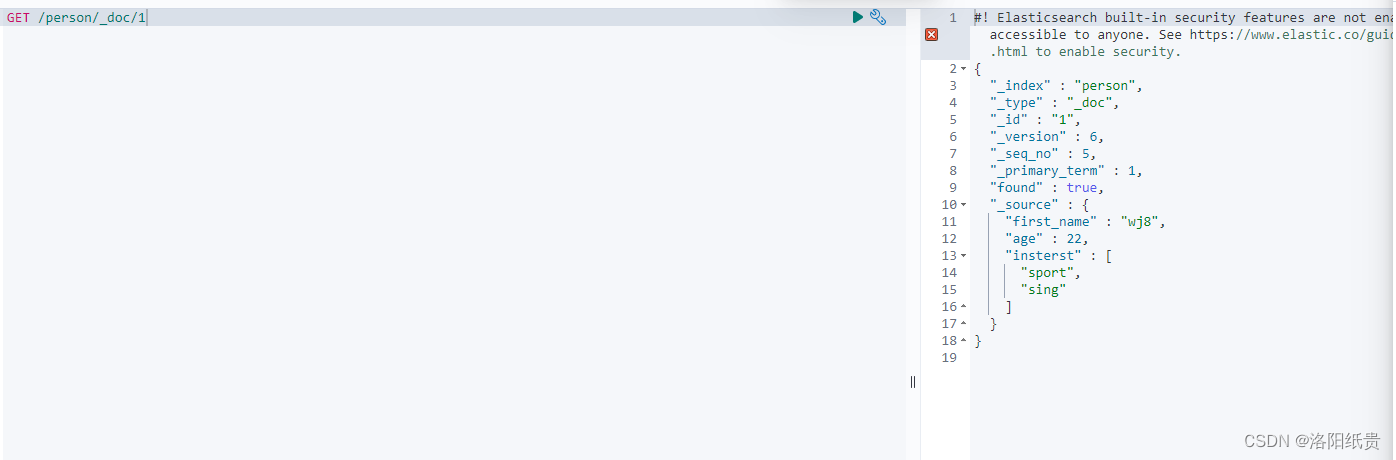
4. Agregue nuevos datos al índice.
http://localhost:9200/persona/_doc/
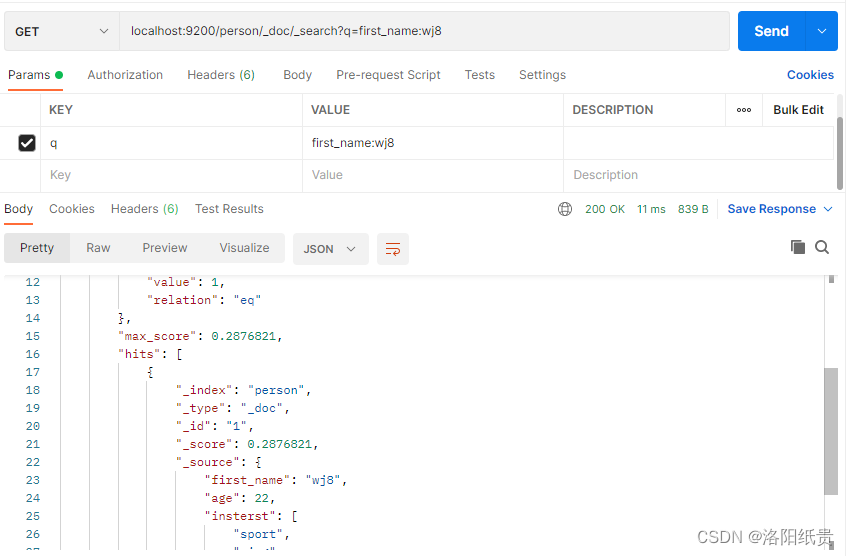
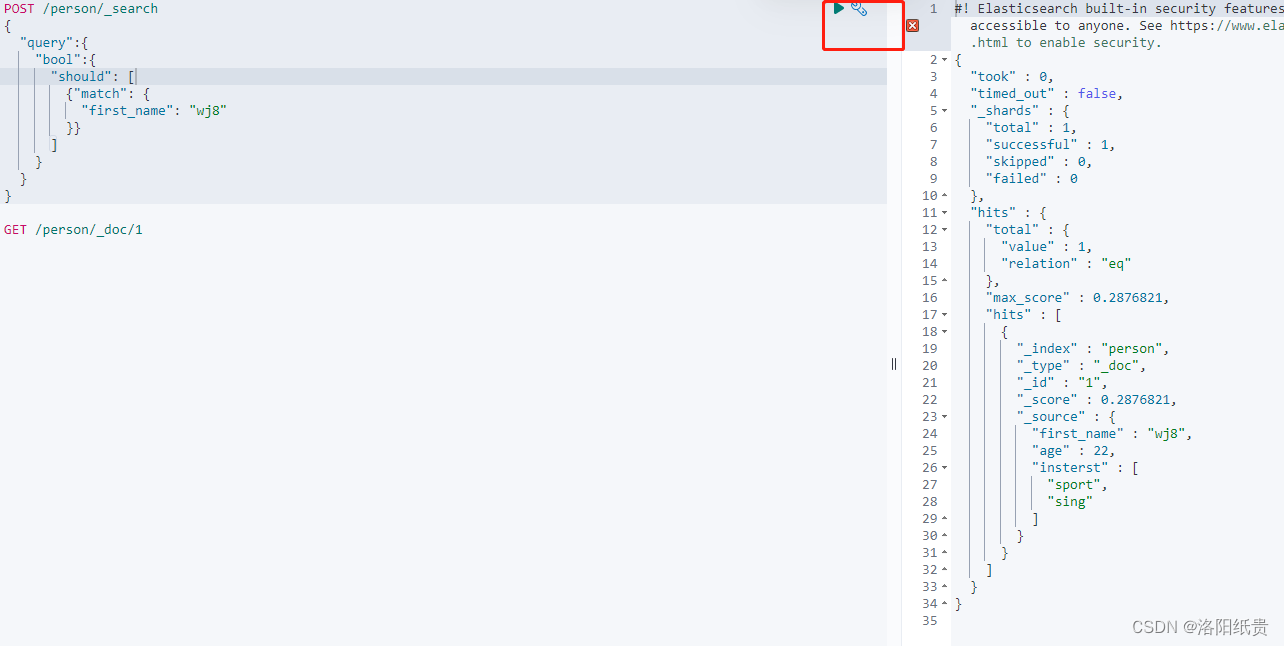
5. Buscar datos
http://localhost:9200/person/_doc/_search?q=first_name:wj
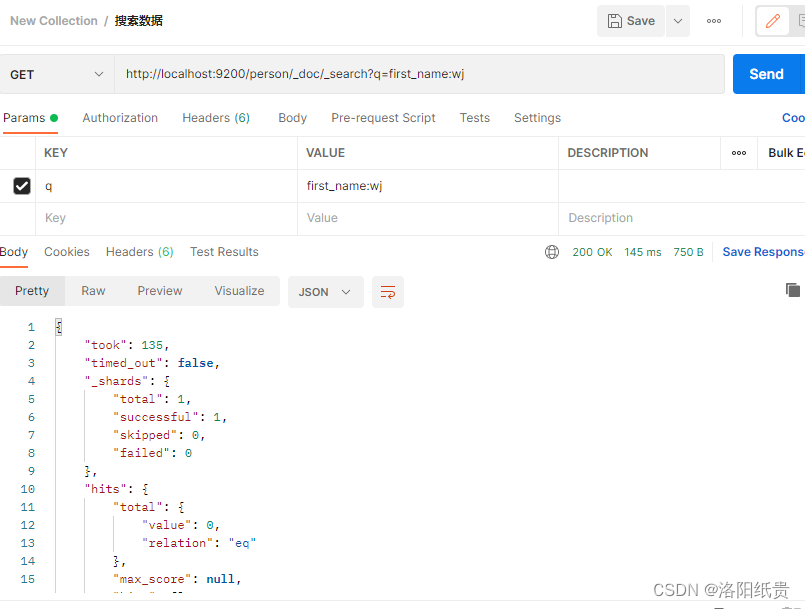
Pero no encontré ninguna coincidencia y luego descubrí que debía estar escrito como wj8, que se agregó antes.
2. Uso de Kibana
http://localhost:5601/app/home#/
Kibana se conecta al ES iniciado de forma predeterminada

3. El principio de implementación de búsqueda de ES (por actualizar)

Elasticsearch (base de datos no relacional) ⇒ Índice ⇒ Documento ⇒ Campos
Una instancia de ES en ejecución es un nodo.
4. MySQL, sincronización de datos ES
Cuando los datos de MySQL cambian, elasticsearch también debe cambiar en consecuencia, que es la sincronización de datos entre elasticsearch y mysql .
Hay tres soluciones comunes de sincronización de datos:
1. Llamada sincrónica

-
Ventajas: simple de implementar, tosco
-
Desventajas: alto grado de acoplamiento empresarial
2. Notificación asincrónica
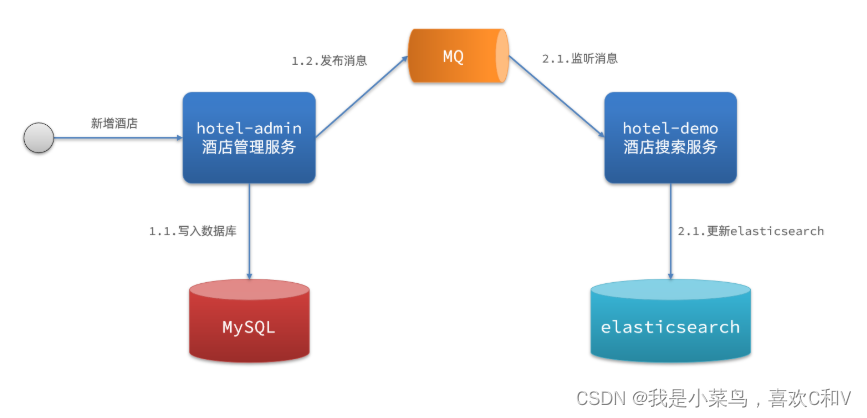
-
Ventajas: bajo acoplamiento, dificultad de implementación media
-
Desventajas: confiar en la confiabilidad de mq
3. Supervisar el registro bin
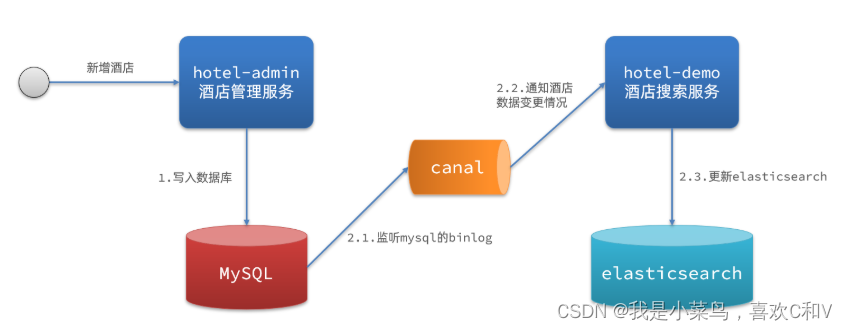
-
Ventajas: Servicios completamente desacoplados.
-
Desventajas: habilitar binlog aumenta la carga sobre la base de datos y hace que la implementación sea compleja.
Reimpreso en: Sincronización de datos entre ES y MYSQL_Soy novato, me gusta C y V blog-CSDN blog_es+mysql
Entre ellos, el binlog de middleware de código abierto:
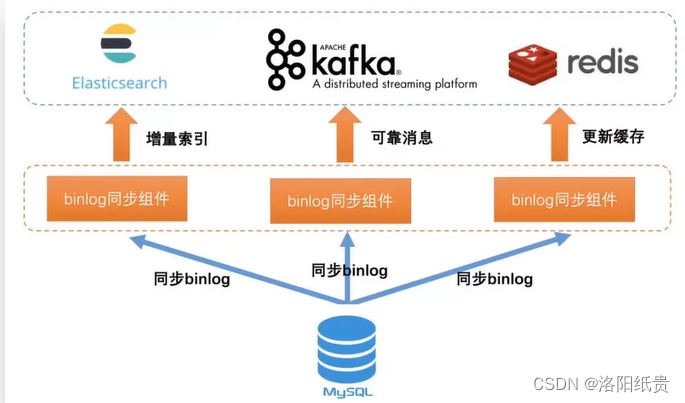
Actualmente, hay uno mejor en China, Canal, que es la herramienta de sincronización binlog de código abierto de Alibaba. Binlog se puede analizar y los datos analizados se pueden sincronizar con cualquier almacenamiento de destino.
Todavía hay uno
Sin embargo, go-mysql-elasticsearch tiene requisitos de versión para mysql y es.
MySQL supported version < 8.0
ES supported version < 6.0En segundo lugar, el sitio web oficial de ES también tiene un logstash.

Logstash es un canal de procesamiento de datos del lado del servidor abierto y gratuito que ingiere datos de múltiples fuentes, los transforma y los envía a su "repositorio" favorito.
Logstash es una herramienta poderosa que se integra con varias implementaciones. Proporciona una gran cantidad de complementos para ayudarlo a analizar, enriquecer, transformar y almacenar en búfer datos de diversas fuentes. Si sus datos requieren un procesamiento adicional que no está disponible en Beats, deberá agregar Logstash a su implementación.
Dirección de descarga: Logstash 7.17.6 | Elástico
Necesito conectarme a jdbc, introduje jar.
5. Segmentador de palabras chinas ES
| tokenizador | efecto |
| Estándar | Tokenizador predeterminado de ES, clasifica palabras y realiza procesamiento de minúsculas |
| Simple | Divida según lo que no sea letras, luego elimine lo que no sea letras y realice el procesamiento en minúsculas |
| Detener | Filtre según las palabras vacías y realice el procesamiento en minúsculas. Las palabras vacías incluyen the, a y is. |
| Espacio en blanco | Dividir según espacios, el chino no es compatible |
| Idioma | Se dice que proporciona segmentadores de palabras para más de 30 idiomas comunes, pero no es compatible con el chino. |
| Tamborileo | La segmentación de palabras se realiza de acuerdo con expresiones regulares, el valor predeterminado es \W+, que representa no letras. |
| Palabra clave | Sin segmentación de palabras, salida completa |
Tokenizador estándar:
英文:
POST _analyze
{
"analyzer":"standard",
"text": "hello world"
}
结果:
{
"tokens" : [
{
"token" : "hello",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "world",
"start_offset" : 6,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 1
}
]
}
中文:
POST _analyze
{
"analyzer":"standard",
"text": "我是中国人"
}
结果: 拆成单个字了,不理想
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "中",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "国",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "人",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
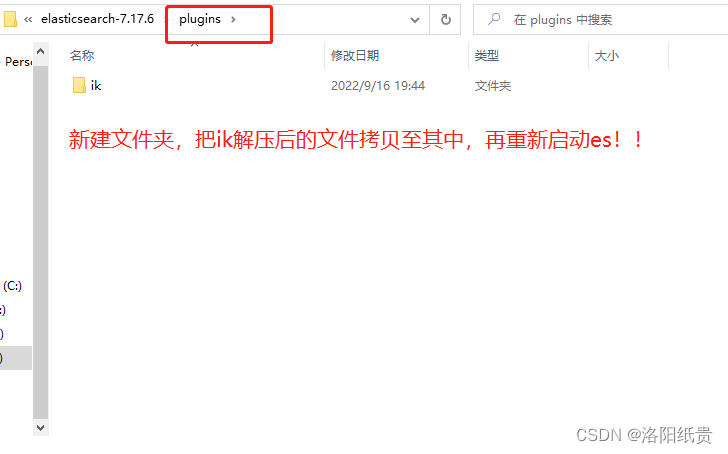
}Obviamente, el chino es extremadamente hostil, por lo que el segmentador de palabras IK de código abierto resolverá este problema. IK es actualmente el complemento con mejor soporte chino.
POST _analyze
{
"analyzer":"ik_smart",
"text": "我是中国人"
}
POST _analyze
{
"analyzer":"ik_max_word",
"text": "我是哪里人呢"
}
结果:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}