Implementar tuberías Triton yolov5
1. ¿Por qué utilizar tuberías Triton?
Como todos sabemos, el servicio de modelo incluye no solo la inferencia basada en GPU, sino también el preproceso y el posproceso. Triton Pipelines es un flujo de trabajo que puede combinar diferentes servicios modelo en una aplicación completa. El mismo servicio modelo también puede ser utilizado por diferentes flujos de trabajo.
Por lo tanto, el preproceso o el posproceso se pueden implementar por separado y luego conectarse en serie con el módulo de inferencia a través de Pipeline. Los beneficios de hacer esto son:
-
Cada submódulo puede solicitar diferentes tipos y tamaños de recursos y configurar diferentes parámetros para maximizar la eficiencia del servicio modelo y aprovechar al máximo los recursos informáticos.
-
Puede evitar la sobrecarga de transferir tensores intermedios, reducir el tamaño de los datos transferidos a través de la red y minimizar la cantidad de solicitudes que deben enviarse a Triton.
Enlaces de código relacionados
2. Implementación de los oleoductos Tritón
Nvidia Triton proporciona dos métodos de implementación de canalizaciones: Business Logic Scripting (BLS) y Ensemble. A continuación se muestra una breve introducción a estos dos métodos.
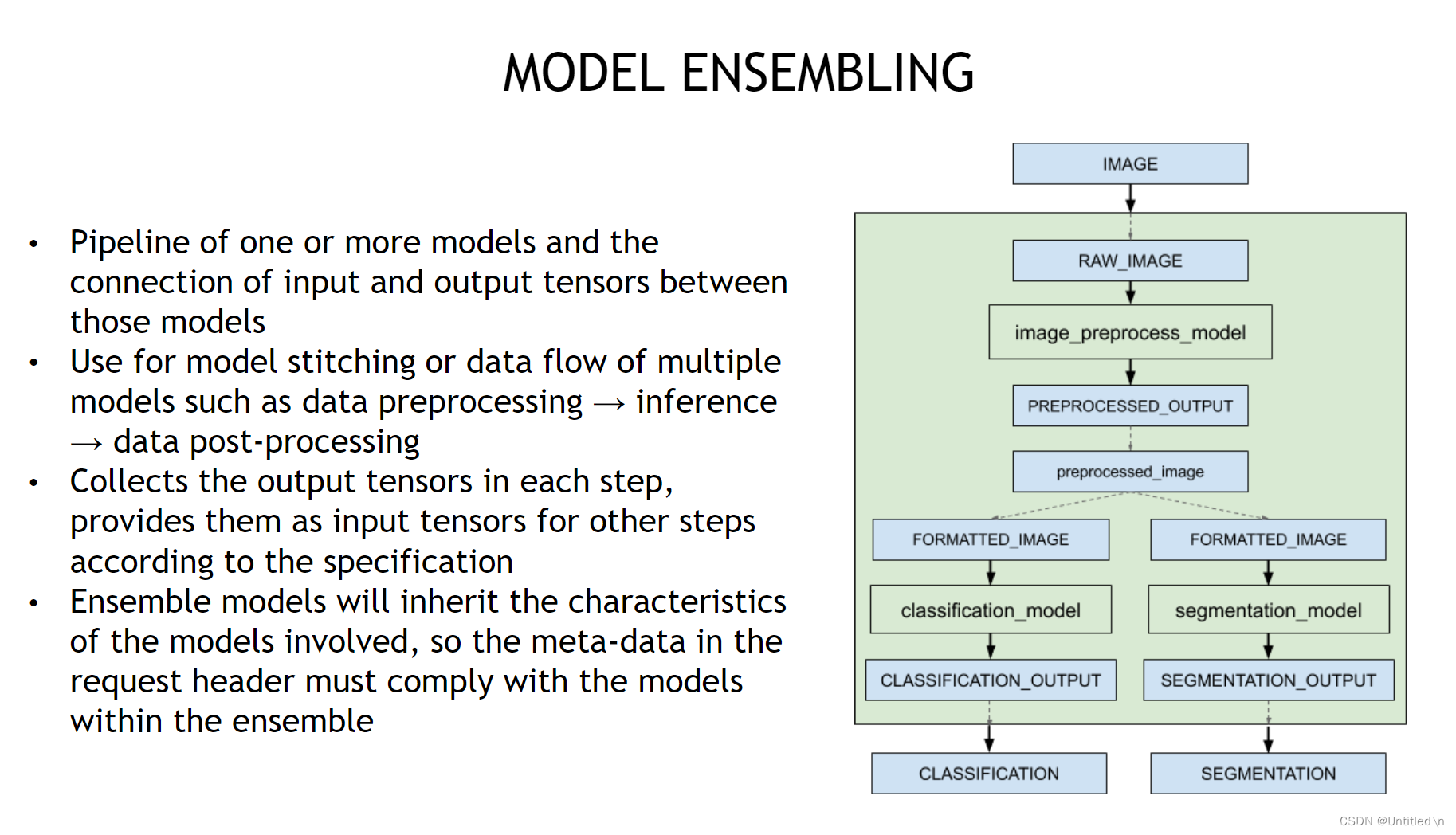
- Ensemble
se convierte en un flujo de trabajo al combinar varios modelos en el repositorio de modelos. Es una estrategia de programación de tuberías, no un modelo específico. Ensemble es más eficiente, pero no puede agregar juicios lógicos condicionales. Los datos solo pueden fluir de acuerdo con la canalización establecida, que es adecuada para escenarios con estructura de canalización fija.
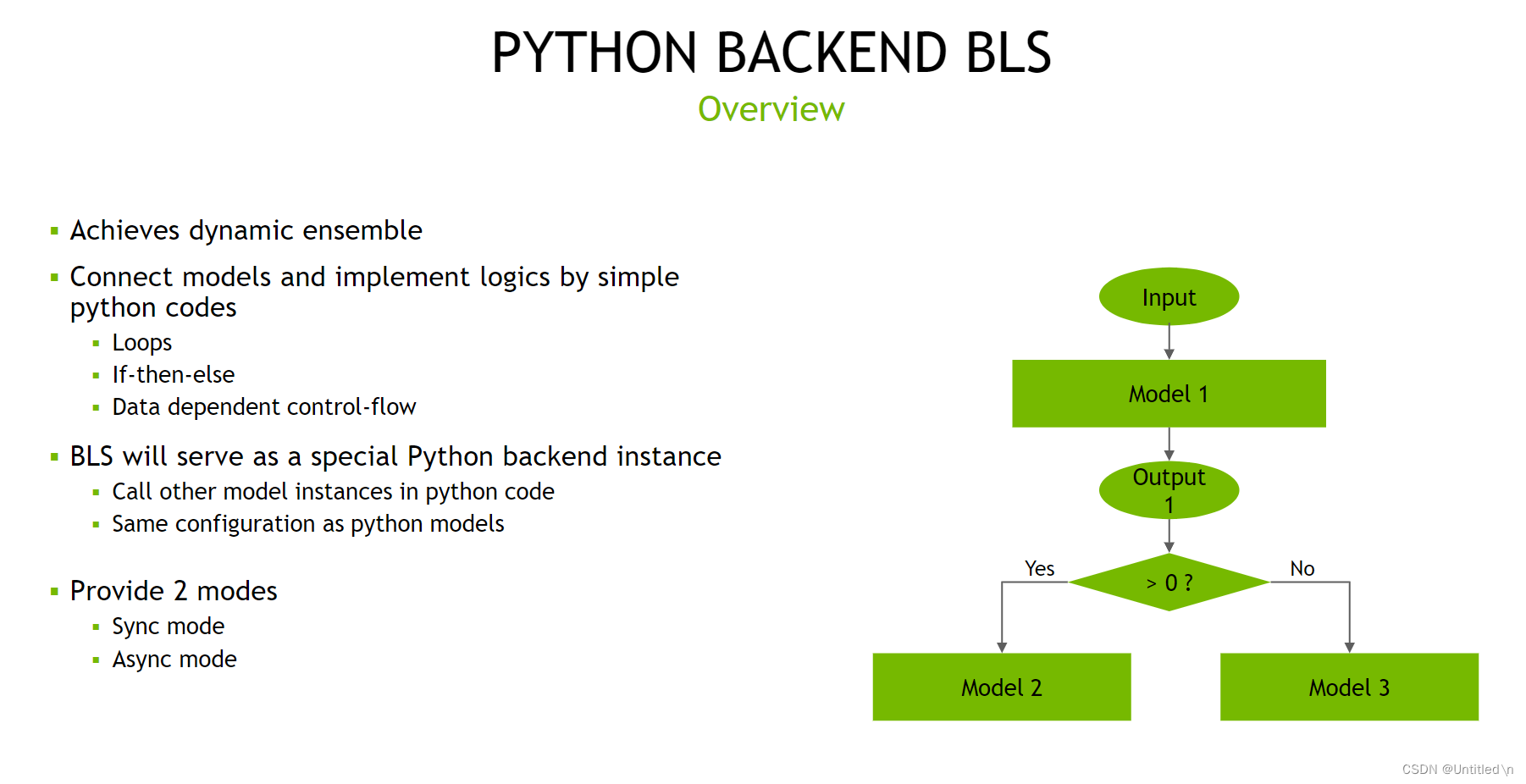
- BLS
es un backend especial de Python que llama a otras instancias de modelo a través del código Python. BLS es más flexible y puede agregar algo de lógica y bucles para combinar dinámicamente diferentes modelos para controlar la dirección del flujo de datos.
3. Cómo implementar los oleoductos Triton
Un punto de partida para implementar el módulo de proceso a través de Pipelines es reducir el tamaño de los datos transmitidos a través de la red. En el servicio del modelo de detección de objetivos, el volumen de datos de la entrada raw_image y los bboxes candidatos antes de nms es relativamente grande, por lo que una solución adecuada es implementar el módulo de postpreceso de nms solo a través del backend de Python y conectar los módulos de inferencia y nms a través de canalizaciones. el cliente necesita realizar el cambio de tamaño necesario y otras operaciones de preproceso en raw_data.
3.1 Flujo de trabajo
La configuración de Pipleine y el backend de Python se refieren al conjunto y bls de Model Repository
Los flujos de trabajo de los dos métodos de implementación son los siguientes:
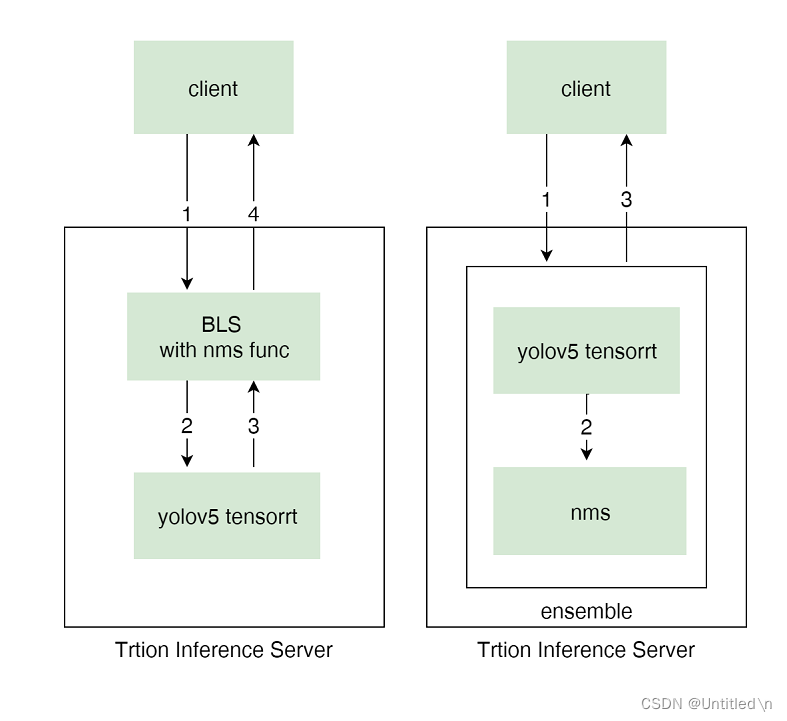
3.2 BLS
- flujo de datos
- Envíe la imagen redimensionada al servicio de modelo BLS a través de http/gRPC
- El servicio BLS llama al servicio del modelo tensorrt yolov5 a través de la API C
- Triton Server devuelve bboxes candidatos al servicio BLS
- El servicio BLS realiza operaciones nms en bboxes candidatos y devuelve los bboxes finales al cliente a través de http/gRPC.
3.3 Conjunto
- flujo de datos
- Envíe la imagen redimensionada al servicio de modelo de conjunto a través de http/gRPC
- El servicio de modelo de conjunto pasa los bboxes candidatos generados por tensorrt yolov5 al servicio de modelo nms a través de una copia de memoria.
- El servicio de modelo de conjunto devuelve la salida de bboxes por nms al cliente a través de http/gRPC
3.4 Aviso
El número de bboxes generados por NMS no es fijo y generalmente existen tres métodos de procesamiento:
- Realice relleno en bboxes, por ejemplo, la salida especificada es
[batch_size, padding_count, xywh or xyxy], donde padding_count se determina de acuerdo con el escenario real - Coloque el resultado de salida del modelo en un json y
json string ([N, 1])devuélvalo en forma de - Utilice el método de desacoplar la respuesta.
Este artículo utiliza relleno para resolver este problema.
from torch.nn import functional as F
i = torchvision.ops.nms(boxes, scores, nms_threshold)
# padding boxes to 300
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
bbox_pad_nums = max_det - i.shape[0]
output_bboxes[xi] = F.pad(x[i], (0,0,0, bbox_pad_nums), value=0)