Tabla de contenido
Introducción al conjunto de datos
El conjunto de datos utilizado en este artículo es un conjunto de datos de casco de fabricación propia, que contiene un total de 6696 imágenes, algunas de las cuales son las siguientes:

Y los correspondientes archivos de anotaciones xml 6696 en formato VOC, algunos de los archivos son los siguientes:
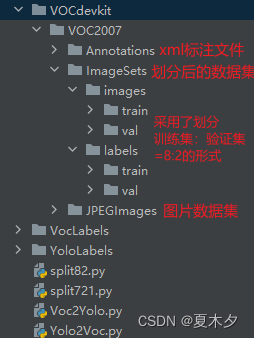
Primero, de acuerdo con los requisitos de formato del conjunto de VOC2007datos de, cree carpetas VOCdevkit,,,, y respectivamente . Su estructura jerárquica es la siguiente:VOC2007AnnotationsImageSetsJPEGImages
VOCdevkit
└───VOC2007
├───Annotations
├───ImageSets 【空】
└───JEPGImages
Entre ellos, Annotationsla carpeta se usa para almacenar archivos xml de datos de etiquetas, JEPGImagesla carpeta se usa para almacenar archivos de imágenes y la carpeta ImageSetsse usa para almacenar el conjunto de datos divididos.

- Entre ellos, proporcioné la conversión entre el formato VOC y el formato YOLO
Voc2Yolo.pyenYolo2Voc.pyel siguiente contenido; - El conjunto de datos se divide según
8:2y y también divido el conjunto de datos (conjunto de entrenamiento, conjunto de verificación, conjunto de prueba) en YOLO. Este blog proporciona7:2:1split82.pysplit721.py - Para descargar el conjunto de datos de este artículo de forma gratuita , vaya aquí
El siguiente código se puede copiar y ejecutar directamente para pruebas personales (todas las rutas siguientes se modifican a sus rutas correspondientes) {\color{Red} \mathbf{El siguiente código se puede copiar y ejecutar directamente para pruebas personales (todas las rutas siguientes se modifican a sus propias rutas correspondientes)} }El siguiente código se puede copiar y ejecutar directamente para pruebas personales (cambie todas las rutas siguientes a sus propias rutas correspondientes)
Convertir el formato VOC al formato YOLO
Al realizar la detección de objetivos, se obtiene una gran cantidad de conjuntos de datos a través de algunos métodos, ya sea descargados de Internet o IabelImgetiquetados manualmente uno por uno mediante software.
En la vida diaria, normalmente etiquetamos el formato VOC (archivo xml) porque contiene la mayor cantidad de datos y lo deja claro de un vistazo, como por ejemplo:
<annotation>
<folder>hat01</folder>
<filename>000000.jpg</filename>
<path>D:\dataset\000000.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>947</width>
<height>1421</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>hat</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>60</xmin>
<ymin>66</ymin>
<xmax>910</xmax>
<ymax>1108</ymax>
</bndbox>
</object>
</annotation>
Los datos en formato YOLO son muy abstractos, como por ejemplo:
0 0.512143611404435 0.4130893736805067 0.8975712777191129 0.733286418015482
Cuando utilizamos el algoritmo YOLO para la práctica de nuestro proyecto, es particularmente importante convertir el formato VOC (archivo xml) de los datos de la etiqueta al formato YOLO (archivo txt).
El contenido del código para convertir el formato VOC al formato YOLO Voc2Yolo.pyes el siguiente:
import os
import shutil
import cv2
from lxml import etree
def VOC2Yolo(class_num, voc_img_path, voc_xml_path, yolo_txt_save_path, yolo_img_save_path=None):
xmls = os.listdir(voc_xml_path)
xmls = [x for x in xmls if x.endswith('.xml')]
if yolo_img_save_path is not None:
if not os.path.exists(yolo_img_save_path):
os.mkdir(yolo_img_save_path)
if not os.path.exists(yolo_txt_save_path):
os.mkdir(yolo_txt_save_path)
all_xmls = len(xmls)
for idx, one_xml in enumerate(xmls):
xl = etree.parse(os.path.join(voc_xml_path, one_xml)) # os.path.join(a,b)会自动在ab之间加/
root = xl.getroot()
objects = root.findall('object')
img_size = root.find('size')
img_w = 0
img_h = 0
if img_size:
img_width = img_size.find('width')
if img_width is not None:
img_w = int(img_width.text)
img_height = img_size.find('height')
if img_height is not None:
img_h = int(img_height.text)
label_lines = []
for ob in objects:
one_annotation = {
}
label = ob.find('name').text
one_annotation['tag'] = label
one_annotation['flag'] = False
bbox = ob.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
if img_w == 0 or img_h == 0:
img = cv2.imread(os.path.join(voc_img_path, one_xml.replace('.xml', '.jpg')))
img_h, img_w = img.shape[:2]
bbox_w = (xmax - xmin) / img_w
bbox_h = (ymax - ymin) / img_h
bbox_cx = (xmin + xmax) / 2 / img_w
bbox_cy = (ymin + ymax) / 2 / img_h
try:
bbox_label = class_num[label]
label_lines.append(f'{
bbox_label} {
bbox_cx} {
bbox_cy} {
bbox_w} {
bbox_h}' + '\n')
except Exception as e:
print("not find number label in class_num ", e, one_xml)
label_lines = []
break
if len(label_lines):
with open(os.path.join(yolo_txt_save_path, one_xml.replace('.xml', '.txt')), 'w') as fp:
fp.writelines(label_lines)
if yolo_img_save_path is not None:
shutil.copy(os.path.join(voc_img_path, one_xml.replace('.xml', '.jpg')),
os.path.join(yolo_img_save_path))
print(f"processing: {
idx+1}/{
all_xmls}")
if __name__ == '__main__':
VOC2Yolo(
class_num={
'hat': 0, 'person': 1}, # 标签种类
voc_img_path='./VOCdevkit/VOC2007/JPEGImages', # 数据集图片文件夹存储路径
voc_xml_path='./VOCdevkit/VOC2007/Annotations', # 标签xml文件夹存储路径
yolo_txt_save_path='./YoloLabels' # 将要生成的txt文件夹存储路径
)
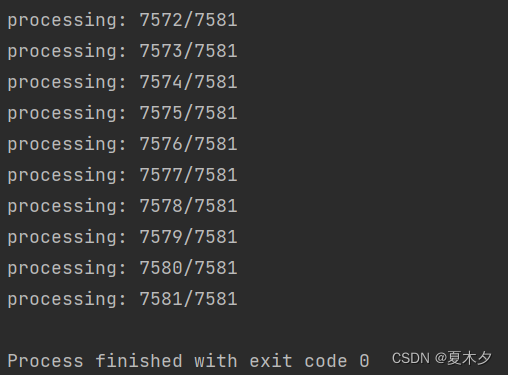
¡Conversión completada!
Convertir el formato YOLO al formato VOC
¿En qué circunstancias necesitamos convertir el formato YOLO al formato VOC?
Esta pregunta realmente me ha desconcertado por un tiempo. Cuando usamos el algoritmo YOLO para ejecutar código, ¿no necesitamos simplemente el archivo de anotaciones en formato YOLO? ¿No es este un formato YOLO ya preparado? ¿Por qué necesitamos ¿Convertirlo de nuevo al formato VOC?
Soy principiante y no lo sé. Woohoo ~ Si alguien lo sabe, puede comentar o enviarme un mensaje privado.
El código para convertir el formato YOLO al formato VOC Yolo2Voc.pyes el siguiente:
from xml.dom.minidom import Document
import os
import cv2
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
"""
dic = {
'0': "hat", # 创建字典用来对类型进行转换
'1': "person", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
}
files = os.listdir(txtPath)
all_txts = len(files)
if not os.path.exists(xmlPath):
os.mkdir(xmlPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
# txtFile = open(os.path.join(txtPath, name))
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
print(f"processing: {
i+1}/{
all_txts}")
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = "./VOCdevkit/VOC2007/JPEGImages/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "./YoloLabels/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = "./VocLabels/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)
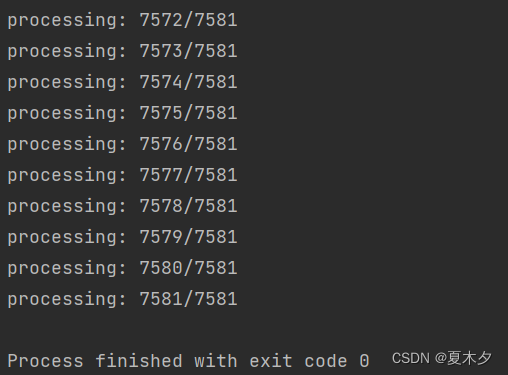
¡Conversión completada!
Después de completar la conversión entre el formato VOC de este artículo y el formato YOLO y mi otro blog YOLO dividiendo el conjunto de datos (conjunto de entrenamiento, conjunto de verificación, conjunto de prueba) , toda la estructura de mi proyecto se muestra a continuación: