Напишите каталог здесь:
Справочная статья: http://dblab.xmu.edu.cn/blog/931-2/ .
1. (Для реализации необходимо сначала установить Hadoop3)
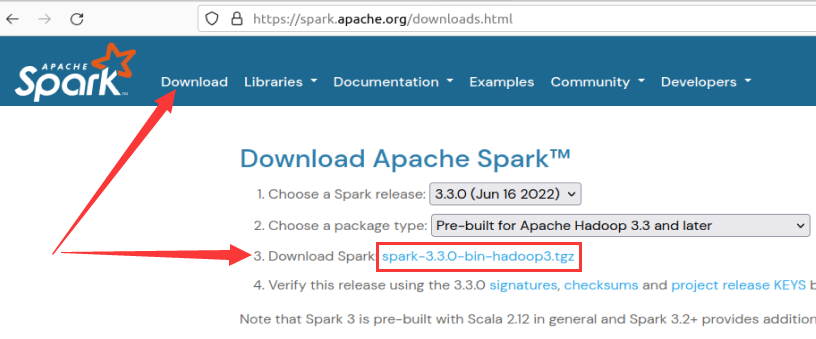
1. Загрузка с официального сайта: версия 3.
2. Конфигурация установки в автономном режиме:
Существует четыре основных режима развертывания Spark:
- Локальный режим (автономный режим)
- Автономный режим (с использованием простого менеджера кластеров, входящего в состав Spark),
- Режим YARN (использование YARN в качестве менеджера кластера)
- Режим Mesos (используйте Mesos в качестве менеджера кластера).
(1) Разархивируйте сжатый пакет в каталог, в котором ранее был установлен Hadoop: локальный компьютер-usr-local.
(2) перейдите в каталог:

(3) Имя распакованного сжатого пакета слишком длинное, мы изменили его на Spark: (

4) Предоставьте соответствующие разрешения файлу (lpp2 — это ваше имя Hadoop, которое можно просмотреть в параметр [Пользователь])

(5) Введите каталог файла Spark:

(6) Используйте cp, чтобы скопировать файл конфигурации и присвойте ему имя:

(7) Отредактируйте файл spark-env.sh (vim ./conf/spark-env. sh), в первой строке добавьте следующую информацию о конфигурации:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)

Нажмите i, чтобы войти в режим вставки. После завершения вставки
нажмите клавишу ESC, затем используйте клавишу Shift + двоеточие, чтобы ввести английское двоеточие, и оно будет создано внизу.
В это время мы вводим wq, нажимаем Enter, а затем [Сохранить и выйти] из редактора vim.
Если вы обеспокоены, вы можете войти в управление файлами и проверить:
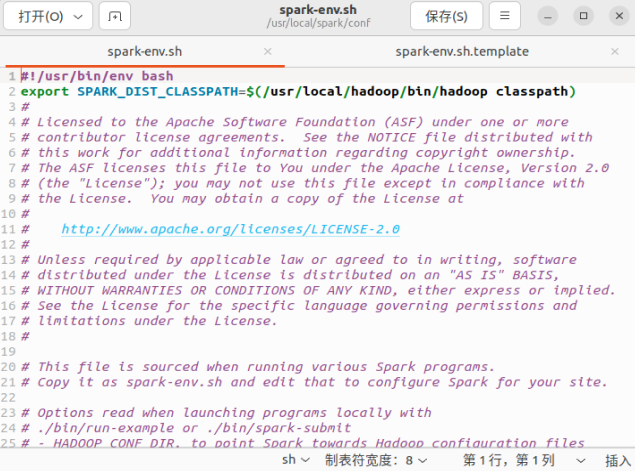
если вы будете осторожны, вы обнаружите, что на самом деле добавляется путь Hadoop.
Фактически, после получения вышеуказанной информации о конфигурации, 【Spark】就可以把数据存储到【Hadoop分布式文件系统HDFS】中,也可以从HDFS中读取数据. (Если 没有указанная выше информация настроена, Spark будет 只能читать и записывать локальные данные, а также 无法читать и записывать данные HDFS)
(8) Используйте эту команду напрямую в своей корзине, чтобы запустить ее: (Запустите собственный экземпляр, чтобы проверить успешность установки)

(9) Используйте каналы для фильтрации информации:
bin/run-example SparkPi 2>&1 | grep "Pi is"
Если выходной сигнал: π, то

3. Запустите приложения Spark в кластере.
- 1. Автономный режим.
Подобно платформе MapReduce1.0, сама платформа Spark также включает в себя полные службы планирования и управления ресурсами, которые можно независимо развертывать в кластере, не полагаясь на другие системы для предоставления служб управления ресурсами и планирования. С точки зрения архитектурного дизайна Spark полностью соответствует MapReduce1.0. Оба состоят из главного и нескольких подчиненных устройств и используют слоты в качестве единицы распределения ресурсов. Разница в том, что слоты в Spark больше не делятся на слоты карты и слоты сокращения, как MapReduce1.0. Вместо этого для использования различными задачами предназначен только один унифицированный слот. - 2. Режим Spark в Mesos
Mesos — это платформа планирования и управления ресурсами, которая может предоставлять услуги для работающего на ней Spark. В режиме Spark on Mesos Mesos отвечает за планирование различных ресурсов, необходимых программе Spark. Поскольку Mesos и Spark имеют определенное кровное родство, при проектировании и разработке платформы Spark полностью учитывается полная поддержка Mesos. Поэтому, условно говоря, Spark более эффективен при работе на Mesos, чем при работе на YARN. Более гибкий и естественный. . В настоящее время Spark официально рекомендует эту модель, поэтому многие компании также используют ее в практических приложениях.
- Режим Spark on YARN
Spark может работать на YARN и быть единообразно развернут с Hadoop, то есть «Spark on YARN». Его архитектура показана на рисунке 9-13. Управление ресурсами и планирование основаны на YARN, а распределенное хранилище — на HDFS.
Создание кластерной среды: http://dblab.xmu.edu.cn/blog/1187-2/
Здесь мы используем 3 машины (узла) в качестве примеров, чтобы продемонстрировать, как построить кластер Spark.
- Среди них 1 машина (узел) такая
Master节点, - Две другие машины (узлы) служат
Slave节点(то есть рабочими узлами), а имена их хостов — «Slave01» и «Slave02» соответственно.