1. Explicación detallada de la cola de mensajes.
Message Queue ( Message Queue ) es un componente importante en un sistema distribuido . Su escenario de uso general se puede describir simplemente como: cuando no es necesario obtener los resultados de inmediato, pero es necesario controlar la concurrencia, casi se necesita Message Queue. .cuando
Resuelve principalmente: acoplamiento de aplicaciones , mensajería asincrónica , reducción de tráfico y otros problemas. Logre un alto rendimiento, alta disponibilidad, escalabilidad y, en última instancia, una arquitectura consistente. Es un middleware indispensable para sistemas distribuidos a gran escala.
Actualmente en entornos de producción, las colas de mensajes más utilizadas incluyen ActiveMQ , RabbitMQ, ZeroMQ, Kafka, MetaMQ, RocketMQ, etc.
1. Dos modelos de colas de mensajes.
1.1 Modelo punto a punto
Cada mensaje tiene un solo receptor ( Consumidor ). Una vez que se envía el mensaje, ya no está en la cola de mensajes.
No hay dependencia entre el remitente y el receptor. Después de que el remitente envía el mensaje, no importa si hay un receptor ejecutándose. o no, no afectará lo siguiente: Enviar una vez

1.2 Modelo de publicación y suscripción
Cada mensaje puede tener múltiples suscriptores.
Cada suscriptor puede recibir todos los mensajes del tema.

La diferencia entre los dos modelos: si un mensaje se puede consumir varias veces.
Si solo hay un suscriptor, los dos modelos son básicamente iguales, por lo que el modelo de publicación-suscripción es compatible con el modelo de cola a nivel funcional.
2. La cola de mensajes implementa transacciones distribuidas.
Una implementación de transacción estricta tiene cuatro propiedades ACID: atomicidad, consistencia, aislamiento y durabilidad.
Atomicidad: una operación de transacción es indivisible. O todas tienen éxito o todas fallan. La mitad de ellas tienen éxito y la otra mitad fallan.
Consistencia: en el momento antes de que se complete la ejecución de la transacción, los datos leídos deben ser los datos antes de la actualización, y los datos leídos después de la actualización deben ser los datos después de la actualización Aislamiento: la ejecución
de una transacción no puede ser interferida por otras transacciones (las operaciones dentro una transacción y los datos utilizados Los datos están aislados de otras transacciones en curso y las transacciones ejecutadas simultáneamente no pueden interferir entre sí).
Durabilidad: una vez que se envía una transacción, las operaciones y fallas posteriores no tendrán ningún impacto en el resultado de la transacción.
En un sistema distribuido, es muy difícil lograr la coherencia de los datos por sí solo, por lo que generalmente solo se garantiza la coherencia máxima. Las implementaciones de transacciones distribuidas más comunes incluyen
1), 2PC ( compromiso de dos fases ) compromiso de dos fases
2), TCC ( intentar-confirmar-cancelar )
3), mensaje de transacción
3. Implementación de transacciones distribuidas en cola de mensajes
Tanto Kafka como RocketMQ proporcionan funciones relacionadas con transacciones, tomemos órdenes como ejemplo para ver cómo implementarlas.
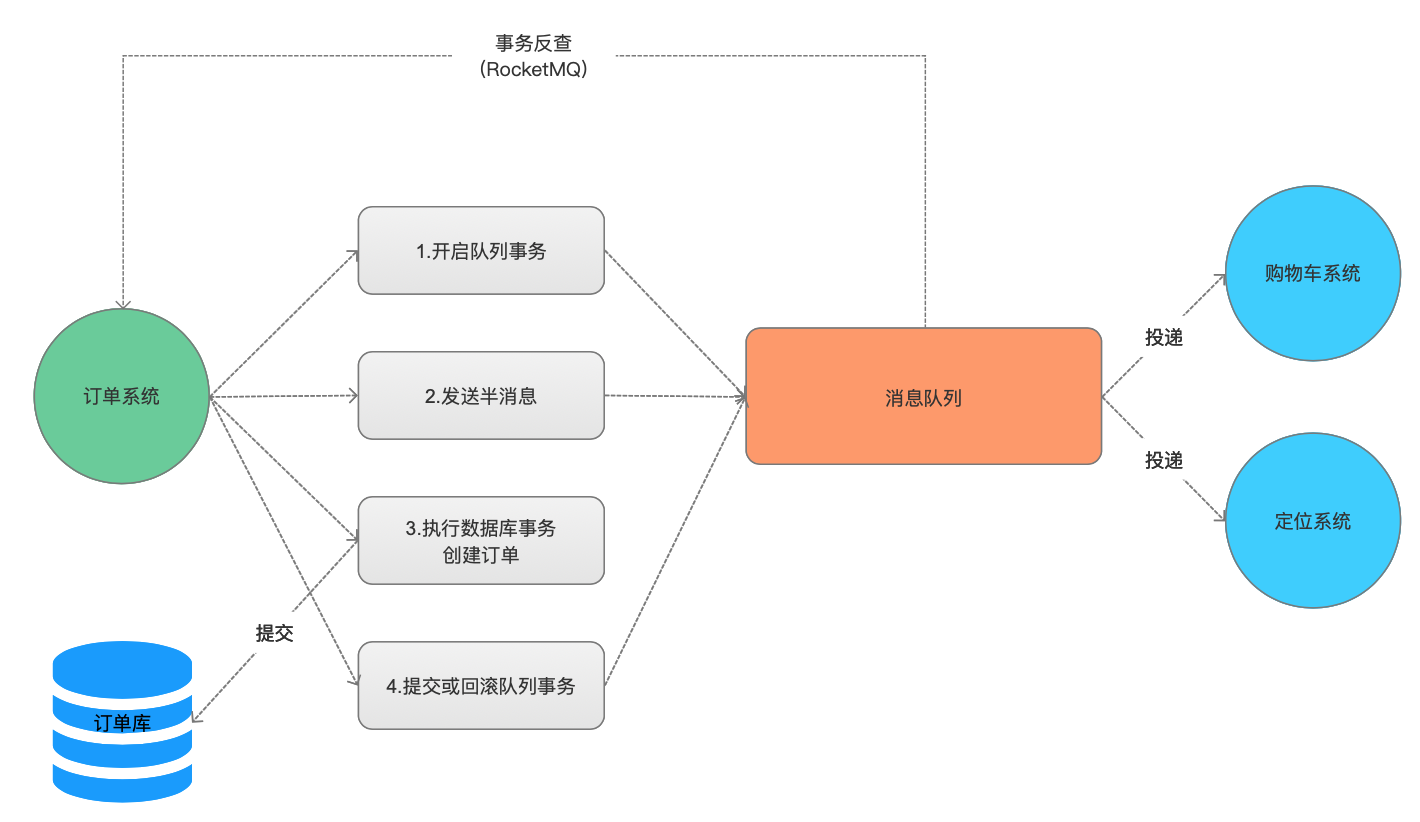
Tanto Kafka como RocketMQ proporcionan funciones relacionadas con transacciones: El núcleo: medio mensaje y
medio mensaje: este medio mensaje no significa que el contenido del mensaje esté incompleto, sino que antes de enviar la transacción, el mensaje es invisible para el consumidor ( sendMessageInTransaction )
(1) Escenarios de aplicación (o funciones) de colas de mensajes
Los escenarios de aplicación se dividen en: procesamiento asincrónico , desacoplamiento de aplicaciones , corte de tráfico , comunicación de mensajes , etc., los más importantes son: procesamiento asincrónico , desacoplamiento de aplicaciones , corte de tráfico
1. Procesamiento asincrónico
Escenario: Luego de que el usuario se registra, es necesario enviar correos electrónicos de registro e información de registro, existen dos métodos tradicionales: método serial y método paralelo.
Desventajas del modelo tradicional: parte de la lógica empresarial no esencial se ejecuta de forma sincrónica, lo que requiere demasiado tiempo.
Ventajas del modelo middleware: escribe mensajes en la cola de mensajes y la lógica empresarial no esencial se ejecuta de forma asincrónica, lo que acelera la velocidad. respuesta.
1.1 Modo serie
Después de que la información de registro se escribe correctamente en la base de datos, se envía un correo electrónico de registro y luego se envía un SMS de registro. Después de completar todas las tareas, la información se devuelve al cliente, como se muestra en la figura
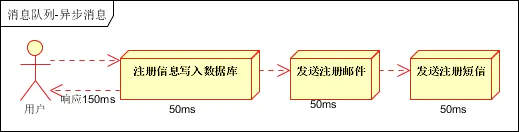
1.2 Método paralelo
Una vez que la información de registro se escribe correctamente en la base de datos, el correo electrónico de registro y el SMS de registro se envían al mismo tiempo. Una vez ejecutadas todas las tareas, la información se devuelve al cliente. En comparación con el modo serie, el modo paralelo puede mejorar la eficiencia de ejecución y reducir el tiempo de ejecución.
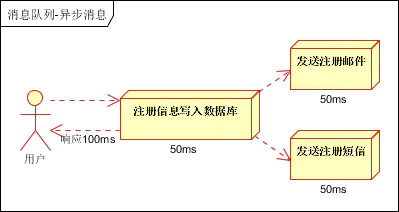
Supongamos que las tres operaciones requieren 50 ms de tiempo de ejecución. Excluyendo los factores de red, la ejecución final se completa. El modo serie requiere 150 ms, mientras que el modo paralelo requiere 100 ms
porque el número de solicitudes procesadas por la CPU en unidad de tiempo es el mismo. : CPU cada 1 El segundo rendimiento es 100 veces, luego la cantidad de solicitudes que se pueden ejecutar en 1 segundo en modo serie es 1000/150, que es menos de 7 veces; la cantidad de solicitudes que se pueden ejecutar en 1 segundo en El modo paralelo es 1000/100, que es 10 veces. Se puede ver
que los métodos tradicionales en serie y paralelo estarán limitados por el rendimiento del sistema, entonces, ¿cómo resolver este problema?
Necesitamos introducir una cola de mensajes para procesar la lógica empresarial no esencial de forma asincrónica. El proceso resultante es el siguiente:
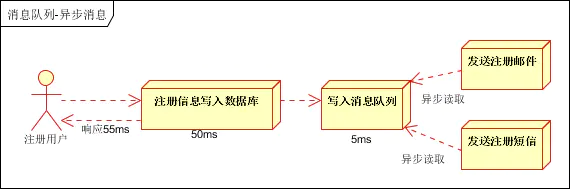
De acuerdo con el proceso anterior, el tiempo de respuesta del usuario es básicamente equivalente al tiempo que lleva escribir los datos del usuario en la base de datos. Después de enviar correos electrónicos de registro y enviar mensajes SMS de registro, los resultados de la ejecución se pueden devolver después de escribirse en la cola de mensajes. El tiempo que lleva escribir la cola de mensajes es muy corto, es rápido y casi puede ignorarse. Esto también puede aumentar el rendimiento del sistema a 20 QPS (velocidad de consulta por segundo ) , que es casi 3 veces mayor que el modo serie y 2 veces mayor que el modo paralelo.
QPS: tasa de consultas por segundo, que es una medida de cuánto tráfico maneja un servidor de consultas específico dentro de un período de tiempo específico.
En Internet, la tasa de consultas por segundo se usa a menudo para medir el rendimiento de la máquina servidor del sistema de nombres de dominio, que es el QPS correspondiente a fetches/sec , que es el número de solicitudes de respuesta por segundo, que es la capacidad máxima de rendimiento. .
2. Desacoplamiento de aplicaciones
Escenario: Un determinado sistema A necesita tratar con otros sistemas (es decir, llamar a métodos). Si otros sistemas cambian o se agregan nuevos sistemas, el sistema A también cambiará. En este caso, el grado de acoplamiento es relativamente alto y es más molesto.
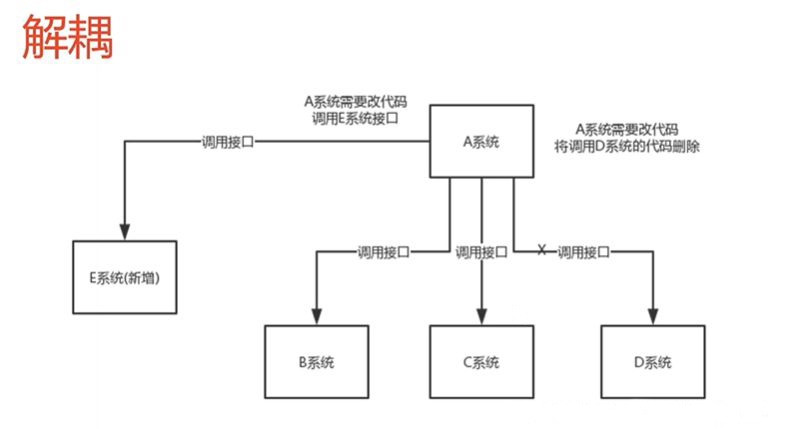
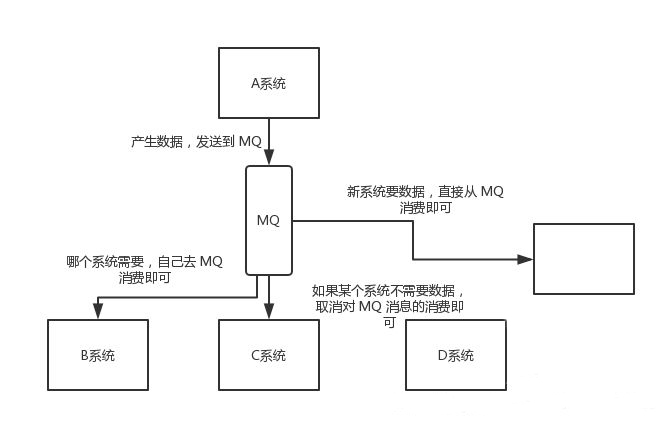
Patrón de middleware: utilice colas de mensajes para resolver este problema
Nuestro sistema A envía los datos generados a la cola de mensajes, y otros sistemas van a la cola de mensajes para su consumo, luego la reducción o adición de otros sistemas tiene poco que ver con el sistema A, para lograr la función de desacoplamiento.
3. Agudización del tráfico
Por ejemplo, en el escenario del negocio de venta flash de productos, el tráfico generalmente aumentará considerablemente y la aplicación colapsará debido al tráfico excesivo. Para resolver este problema, generalmente es necesario agregar una cola de mensajes al front-end de la aplicación.
1), puede controlar la cantidad de personas que participan en el evento
2), puede aliviar la enorme presión sobre las aplicaciones causada por el alto tráfico en un corto período de tiempo
El método de procesamiento es el que se muestra en la figura:
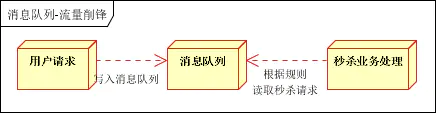
1) Después de recibir la solicitud del usuario, el servidor primero escribe en la cola de mensajes. En este momento, si el número de mensajes en la cola de mensajes excede el número máximo, la solicitud del usuario será rechazada directamente o se devolverá la página de error. 2) El negocio de venta flash lee la información de la solicitud
en la cola de mensajes de acuerdo con el reglas de venta flash y realiza el procesamiento posterior.
4. Comunicación de mensajes
El procesamiento de registros se refiere al uso de colas de mensajes en el procesamiento de registros, como las aplicaciones Kafka, para resolver el problema de una gran cantidad de transmisiones de registros.
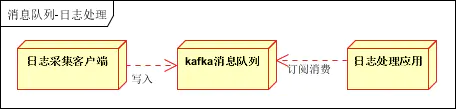
Cliente de recopilación de registros: responsable de la recopilación de datos de registro, la escritura programada y la escritura en la cola de Kafka.
Cola de mensajes de Kafka: responsable de recibir, almacenar y reenviar datos de registro.
Aplicación de procesamiento de registros: suscribirse y consumir datos de registro en la cola de Kafka.
(2) Desventajas de usar colas de mensajes
1. Se reduce la disponibilidad del sistema: La disponibilidad del sistema se reduce hasta cierto punto, ¿por qué dices esto? Antes de unirse a MQ, no tiene que pensar en la pérdida de mensajes o en que MQ cuelgue, etc. Sin embargo, después de presentar MQ, ¡debe pensar en ello!
2. Mayor complejidad del sistema: después de unirse a MQ, debe asegurarse de que los mensajes no se consuman repetidamente, lidiar con la pérdida de mensajes, garantizar el orden de entrega de los mensajes y otros problemas.
3. Problema de coherencia: la cola de mensajes puede volverse asincrónica, y la asincrónica generada por la cola de mensajes puede mejorar la velocidad de respuesta del sistema. Pero, ¿qué pasa si el verdadero consumidor del mensaje no lo consume correctamente? Esto conducirá a la inconsistencia de los datos.
(3) Colas de mensajes comunes
| Comparación de colas de mensajes comunes |
|---|
| ActivoMQ | ConejoMQ | cohetemq | kafka | |
| Lenguaje de desarrollo | Java | erlang | Java | escala |
| Rendimiento de una sola máquina | Nivel 10,000 | Nivel 10,000 | Cien mil nivel | Cien mil nivel |
| Oportunidad | nivel ms | nosotros nivel | nivel ms | Dentro del nivel ms |
| Disponibilidad | Alto (arquitectura maestro-esclavo) | Alto (arquitectura maestro-esclavo) | Muy alto (arquitectura distribuida) | Muy alto (arquitectura distribuida) |
| Características | Producto maduro, utilizado en muchas empresas; tiene más documentación; tiene buen soporte para varios protocolos | Desarrollado en base a Erlang, tiene sólidas capacidades de concurrencia, rendimiento extremadamente bueno, baja latencia e interfaces de administración ricas. | MQ tiene funciones relativamente completas y buena escalabilidad. | Solo se admiten las funciones principales de MQ. Algunas funciones de consulta de mensajes, rastreo de mensajes y otras no se proporcionan. Después de todo, está preparado para big data y se usa ampliamente en el campo de big data. |
Con base en la comparación anterior, se pueden sacar las siguientes conclusiones.
1) Para las pequeñas y medianas empresas de software, se recomienda elegir RabbitMQ
porque el lenguaje erlang se caracteriza inherentemente por una alta concurrencia y su interfaz de administración es muy conveniente de usar. Como dice el refrán, Xiao He también es un éxito y Xiao He es un fracaso. Sus deficiencias también están aquí: aunque RabbitMQ es de código abierto, ¿cuántos programadores en China pueden personalizar y desarrollar Erlang ? Afortunadamente, la comunidad RabbitMQ es muy activa y puede resolver errores encontrados durante el proceso de desarrollo . Esto es muy importante para las pequeñas y medianas empresas. La razón por la que
no se considera Kafka es que las pequeñas y medianas empresas de software no son tan buenas. Como empresas de Internet y la cantidad de datos no es tan grande. Se debe preferir el middleware de mensajes con funciones relativamente completas, por lo que Kafka excluye rocketmq
. La razón para no considerar rocketmq es que rocketmq es producido por Alibaba. Si Alibaba deja de mantener rocketmq , pequeño Y las empresas medianas generalmente no pueden prescindir de personas para llevar a cabo un desarrollo personalizado de rocketmq
2) Las grandes empresas de software deberían elegir entre rocketMQ y kafka en función de aplicaciones específicas
. Las grandes empresas de software tienen fondos suficientes para construir un entorno distribuido y una cantidad de datos suficientemente grande. Para rocketMQ , las grandes empresas de software también pueden dedicar mano de obra al desarrollo personalizado de rocketMQ . Después de todo , todavía hay bastantes personas en China que tienen la capacidad de modificar el código fuente JAVA . En cuanto a Kafka , dependiendo del escenario empresarial, si tiene una función de recopilación de registros, Kafka es definitivamente la primera opción . Cuál elegir depende del escenario de uso.
(4) Alta disponibilidad de la cola de mensajes.
El clúster rcoketMQ tiene modo multimaestro , modo de replicación asíncrono multimaestro y multiesclavo , y modo de escritura dual síncrono multimaestro y multiesclavo, como se muestra en la figura :
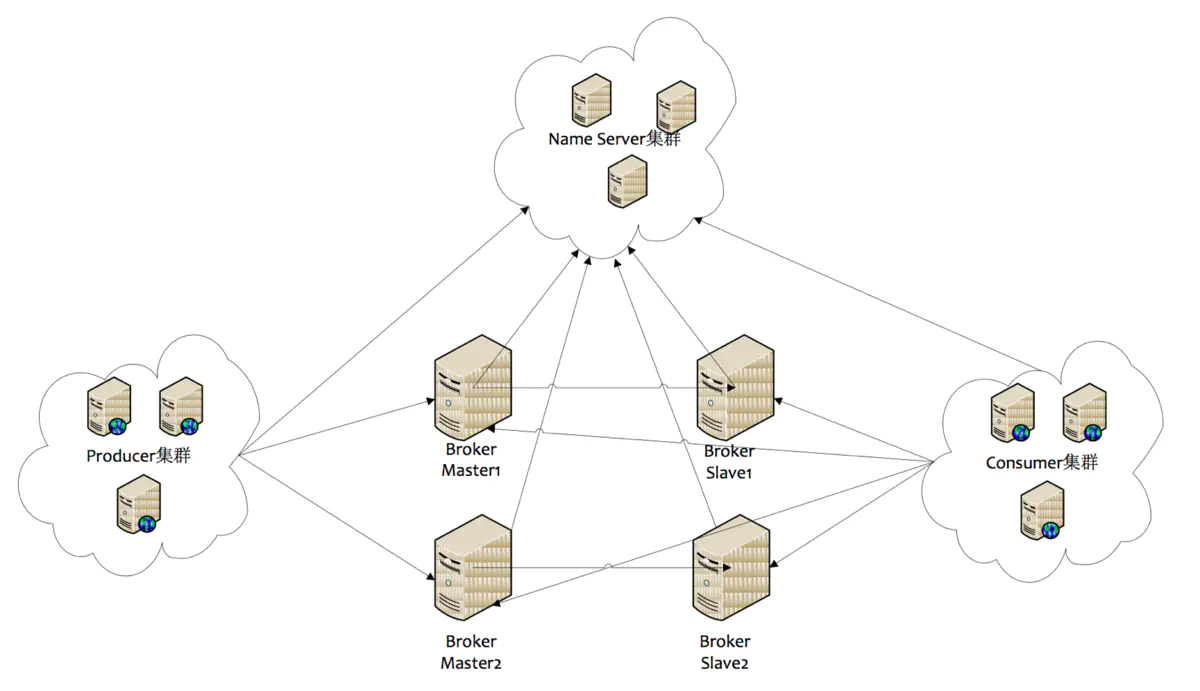
El productor establece una conexión larga con uno de los nodos (seleccionados aleatoriamente) en el clúster de NameServer , obtiene periódicamente información de enrutamiento de temas de NameServer , establece una conexión larga con el Broker Master que proporciona servicios de temas y envía periódicamente latidos al Broker . El Productor solo puede enviar mensajes al Broker master , pero el Consumidor es diferente. Establece conexiones a largo plazo con el Master y el Slave que brindan servicios de Tema al mismo tiempo. Puede suscribirse a mensajes del Broker Master o del Broker. Esclavo .
kafka
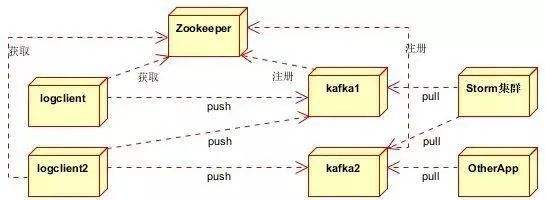
Un clúster de Kafka típico contiene varios productores (que pueden ser vistas de página generadas por el front-end web o registros del servidor, CPU del sistema , memoria , etc.), varios intermediarios ( Kafka admite la expansión horizontal. Generalmente, cuanto mayor sea el número de intermediarios , mayor será la tasa de rendimiento del clúster ), varios grupos de consumidores y un clúster Zookeeper . Kafka utiliza Zookeeper para administrar la configuración del clúster, elegir líderes y reequilibrar cuando cambia el grupo de consumidores . El productor usa el modo push para publicar mensajes al intermediario y el consumidor usa el modo pull para suscribirse y consumir mensajes del intermediario .
RabbitMQ: También existen modos de clúster ordinario y de clúster espejo, que no explicaré en detalle aquí.
(5) Consumo repetido de mensajes.
El motivo del consumo repetido: cuando el consumidor consume un mensaje, una vez que se completa el consumo, enviará un mensaje de confirmación a la cola de mensajes, la cola de mensajes sabrá que el mensaje se ha consumido y lo eliminará de la cola de mensajes. . Es solo que diferentes colas de mensajes envían diferentes formas de información de confirmación. Por ejemplo, RabbitMQ envía un mensaje de confirmación ACK y RocketMQ devuelve una bandera de éxito CONSUME_SUCCESS . Kafka en realidad tiene el concepto de desplazamiento . En pocas palabras, cada mensaje tiene un desplazamiento . Después de que Kafka consume el mensaje, debe enviar el desplazamiento para que la cola de mensajes sepa que lo ha consumido. ¿Cuál es el motivo del consumo repetido? Debido a la transmisión de la red y otras fallas, la información de confirmación no se transmite a la cola de mensajes, lo que hace que la cola de mensajes no sepa que ha consumido el mensaje y lo distribuya a otros consumidores nuevamente. .
Solución:
1. Por ejemplo: recibe este mensaje y realiza una operación de inserción en la base de datos. Eso sería fácil. Déle a este mensaje una clave primaria única. Luego, incluso si hay un consumo repetido, causará un conflicto de clave primaria y evitará datos sucios en la base de datos. 2. Por ejemplo: si recibe este mensaje y realiza
una redis operación set, entonces Es fácil y no hay necesidad de resolverlo, porque el resultado será el mismo sin importar cuántas veces lo configures. La operación set se considera una operación idempotente. 3. Prepare un medio de terceros
: para registros de consumo. Tomando Redis como ejemplo, asigne una identificación global al mensaje. Mientras se consuma el mensaje, <id, mensaje> se escribirá en redis en forma de KV. Antes de que el consumidor comience a consumir, primero puede verificar si existe algún registro de consumo en redis.
(6) Transmisión sexual del consumo
Cada tipo de MQ debe analizarse desde tres perspectivas: el productor pierde datos, la cola de mensajes pierde datos y el consumidor pierde datos.
ConejoMQ
1. El productor pierde datos
Desde la perspectiva de que el productor pierda datos, RabbitMQ proporciona modos de transacción y confirmación para garantizar que el productor no pierda mensajes.
El mecanismo de transacción significa que antes de enviar el mensaje, abra la transacción ( channel.txSelect() ) y luego envíe el mensaje. Si el proceso de envío Si ocurre alguna excepción en la transacción, la transacción se revertirá ( channel.txRollback() ). Si la transmisión es exitosa, la transacción se enviará ( channel.txCommit() ).
Sin embargo, el La desventaja es que se reduce el rendimiento. Por lo tanto, el modo de confirmación se utiliza principalmente en producción . Una vez que el canal ingresa al modo de confirmación , a todos los mensajes publicados en el canal se les asignará una ID única (comenzando desde 1). Una vez que el mensaje se entregue a todas las colas coincidentes, RabbitMQ enviará un Ack al productor (contiene la ID ), que permite al productor saber que el mensaje ha llegado correctamente a la cola de destino. Si rabiitMQ no puede procesar el mensaje, le enviará un mensaje Nack y podrá volver a intentar la operación.
2. La cola de mensajes pierde datos.
Para hacer frente a la situación de pérdida de datos en la cola de mensajes, generalmente se habilita la configuración del disco persistente. Esta configuración de persistencia se puede utilizar junto con el mecanismo de confirmación . Puede enviar una señal de confirmación al productor después de que el mensaje persista en el disco. De esta manera, si RabbitMQ muere antes de que el mensaje persista en el disco, entonces el productor no puede recibir la señal Ack y el productor la reenviará automáticamente
. Entonces, ¿cómo persistir? En realidad es muy fácil. Simplemente siga los siguientes dos pasos. :
1. Persistencia de colala durable se establece en ** verdadero, ** representa una cola duradera
. 2. Establezca deliveryMode = 2 al enviar un mensaje
. Después de configurar deliveryMode = 2 de esta manera, incluso si RabbitMQ se cuelga, los datos se puede restaurar después de reiniciar.
3. Los consumidores pierden datos
Los consumidores generalmente pierden datos porque utilizan el modo de mensaje de confirmación automática. En este modo, los consumidores acusan recibo automáticamente del mensaje. En este momento, rahbitMQ eliminará inmediatamente el mensaje. En este caso, si el consumidor encuentra una excepción y no puede procesar el mensaje, el mensaje se perderá.
En cuanto a la solución, simplemente confirme el mensaje manualmente.
2. Instalación de RabbitMQ
1. Instale Erlang
Descarga oficial de Erlang: Descargas - Erlang/OTP
[root@servers ~]# yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel
[root@servers ~]# tar xvf otp_src_24.2-rc1.tar.gz
[root@servers ~]# cd otp_src_24.2
[root@servers otp_src_24.2]# ./configure --prefix=/usr/local/erlang --with-ssl -enable-threads -enable-smmp-support -enable-kernel-poll --enable-hipe --without-javac
[root@servers otp_src_24.2]# make && make install
[root@servers otp_src_24.2]# vim /etc/profile
................ 在最后加入
........
ERLANG_HOME=/usr/local/erlang
PATH=$ERLANG_HOME/bin:$PATH
export ERLANG_HOME
export PATH
保存
root@servers ~]# source /etc/profile
[root@servers ~]# erl #验证是否安装成功
Erlang/OTP 24 [erts-12.0] [source] [64-bit] [smp:1:1] [ds:1:1:10] [async-threads:1]
Eshell V12.0 (abort with ^G)
1>
ctrl + C 退出 如果一次没有退出就多按几次
2. Instale RadditMQ
Descargue RabbitMQ: https://github.com/rabbitmq/rabbitmq-server/releases/tag/v3.9.12
[root@servers ~]# xz -d rabbitmq-server-generic-unix-3.9.12.tar.xz
[root@servers ~]# tar xf rabbitmq-server-generic-unix-3.9.12.tar
[root@servers ~]# cp -rf rabbitmq_server-3.9.12 /usr/local/
[root@servers ~]# cd /usr/local/
[root@servers local]# mv rabbitmq_server-3.9.12 rabbitmq
[root@servers local]# cd rabbitmq/sbin/
[root@servers sbin]# ./rabbitmq-plugins enable rabbitmq_management #开启管理页面插件
Enabling plugins on node rabbit@C7--13:
rabbitmq_management
The following plugins have been configured:
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@C7--13...
The following plugins have been enabled:
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
set 3 plugins.
Offline change; changes will take effect at broker restart.
Iniciar y cerrar servicios
[root@servers sbin]# ./rabbitmq-server #启动,ctrl + c 退出及关闭
[root@servers sbin]# ./rabbitmq-server -detached #在后台启动服务
[root@servers sbin]# ./rabbitmqctl stop #关闭服务
Agregar cuenta de administrador
Agregar usuarios después de comenzar en segundo plano
添加用户格式: ./rabbitmqctl add_user 用户名 密码
[root@servers sbin]# ./rabbitmqctl add_user admin 123.com
Adding user "admin" ...
Done. Don't forget to grant the user permissions to some virtual hosts! See 'rabbitmqctl help set_permissions' to learn more.
分配用户标签格式: ./rabbitmqctl add_user_tags 用户名 管理员标签[administrator]
[root@servers sbin]# ./rabbitmqctl set_user_tags admin administrator
Setting tags for user "admin" to [administrator] ...
prueba de acceso
Ingrese el usuario previamente configurado: admin y contraseña: 123.com para iniciar sesión
3. Explicación detallada de RabbitMQ
(1) Introducción a AMQP
RabbitMQ es un software de intermediación de mensajes de código abierto (también conocido como middleware orientado a mensajes) que implementa el protocolo avanzado de cola de mensajes ( protocolo AMQP ). El servidor RabbitMQ está escrito en el lenguaje Erlang , mientras que la agrupación en clústeres y la conmutación por error se basan en el marco de la plataforma abierta de telecomunicaciones. Todos los lenguajes de programación principales tienen bibliotecas cliente que se comunican con la interfaz proxy.
AMQPProtocolo : El protocolo avanzado de cola de mensajes es un estándar abierto para protocolos de capa de aplicación y está diseñado para middleware orientado a mensajes. El middleware de mensajes se utiliza principalmente para el desacoplamiento entre componentes. El remitente de un mensaje no necesita conocer la existencia del consumidor del mensaje y viceversa. Las
AMQPcaracterísticas principales del protocolo son la orientación a mensajes, las colas, el enrutamiento (incluido el punto a -apuntar y publicar/suscribir) y confiabilidad. Secure
RabbitMQ es una implementación AMQP de código abierto. El servidor está escrito en lenguaje Erlang y admite una variedad de clientes, tales como: Python , Ruby , .NET , Java , JMS , C. , PHP , ActionScript , XMPP , STOMP , etc., y es compatible con AJAX . Se utiliza para almacenar y reenviar mensajes en sistemas distribuidos y tiene un buen rendimiento en términos de facilidad de uso, escalabilidad y alta disponibilidad.
| Protocolo de tres capas AMQP | |
|---|---|
| Capa de módulo | Ubicado en el nivel más alto del protocolo, define principalmente algunos comandos para que los llame el cliente. El cliente puede usar estos comandos para implementar su propia lógica de negocios. Por ejemplo, el cliente puede declarar una cola a través de queue.declare y usar consumir Comando para obtener mensajes en una cola . |
| Capa de sesión | Es el principal responsable de enviar los comandos del cliente al servidor y devolver la respuesta del servidor al cliente. Es el principal responsable de proporcionar confiabilidad, mecanismo de sincronización y manejo de errores para la comunicación entre el cliente y el servidor. |
| Capa de transporte | Transmite principalmente flujos de datos binarios y proporciona procesamiento de tramas, multiplexación de canales, detección de errores y representación de datos. |
(2) Función
| almacenamiento y reenvio | Múltiples remitentes de mensajes, receptor de un solo mensaje |
|---|---|
| Transacciones distribuidas | Múltiples remitentes de mensajes, múltiples receptores de mensajes |
| publicarsuscribir | Múltiples remitentes de mensajes, múltiples receptores de mensajes |
| enrutamiento basado en contenido | Múltiples remitentes de mensajes, múltiples receptores de mensajes |
| cola de transferencia de archivos | Múltiples remitentes de mensajes, múltiples receptores de mensajes |
| conexión punto a punto | Remitente de un solo mensaje, receptor de un solo mensaje |
(3) Descripción terminológica
Modelo AMQP ( AMQP Model) |
Un marco lógico representado por las entidades clave y la semántica que debe proporcionar un servidor compatible con AMQP . Para implementar la semántica definida en esta especificación, los clientes pueden enviar comandos para controlar el servidor AMQP . |
|---|---|
conectar ( Connection) |
Una conexión de red, como una conexión de socket TCP/IP |
sesión ( Session) |
Conversaciones con nombre entre puntos finales. Dentro del contexto de una sesión, se garantiza que se entregará "exactamente una vez" |
canal ( Channel) |
Un canal de flujo de datos bidireccional independiente dentro de una conexión multiplexada. Proporcionar un medio de transmisión físico para la sesión. |
cliente ( Client) |
El iniciador de la conexión o sesión AMQP . AMQP es asimétrico, los clientes producen y consumen mensajes y los servidores almacenan y enrutan estos mensajes. |
servidor ( Server) |
Un proceso que acepta conexiones de clientes e implementa funciones de enrutamiento y cola de mensajes AMQP . También llamado "agente de mensajes" |
punto final ( Peer) |
Cualquiera de las partes de la conversación AMQP . Una conexión AMQP consta de dos puntos finales (uno es el cliente y el otro es el servidor) |
Socio ( Partner) |
Al describir la interacción entre dos puntos finales, el término "socio" se utiliza como abreviatura del "otro" punto final. Por ejemplo, definimos el punto final A y el punto final B. Cuando se comunican, el punto final B es el socio del punto final A y el punto final A es el socio del punto final B. |
conjunto de fragmentos ( Assembly) |
Una colección ordenada de segmentos que forman una unidad lógica de trabajo. |
segmento ( Segment) |
Una colección ordenada de fotogramas, que forma una subunidad completa del conjunto de fragmentos. |
marco ( Frame) |
Una unidad atómica de transporte AMQP . Un marco es cualquier fragmento de un segmento. |
controlar ( Control) |
Instrucciones unidireccionales, la especificación AMQP supone que la transmisión de estas instrucciones no es confiable |
comando ( Command) |
Instrucciones que requieren confirmación La especificación AMQP estipula que la transmisión de estas instrucciones es confiable. |
Excepción ( Exception) |
Estado de error que puede ocurrir al ejecutar uno o más comandos |
clase ( Class) |
Un lote de comandos o controles AMQP utilizados para describir una función específica. |
Encabezado del mensaje ( Header) |
Una sección especial que describe los atributos de los datos del mensaje. |
Cuerpo del mensaje ( Body) |
包含应用程序数据的一种特殊段。消息体段对于服务器来说完全透明——服务器不能查看或者修改消息体 |
消息内容(Content) |
包含在消息体段中的的消息数据 |
交换器(Exchange) |
服务器中的实体,用来接收生产者发送的消息并将这些消息路由给服务器中的队列 |
交换器类型(Exchange Type) |
基于不同路由语义的交换器类 |
消息队列(Message Queue) |
一个命名实体,用来保存消息直到发送给消费者 |
绑定器(Binding) |
消息队列和交换器之间的关联 |
绑定器关键字(Binding Key) |
绑定的名称。一些交换器类型可能使用这个名称作为定义绑定器路由行为的模式 |
路由关键字(Routing Key) |
一个消息头,交换器可以用这个消息头决定如何路由某条消息 |
持久存储(Durable) |
一种服务器资源,当服务器重启时,保存的消息数据不会丢失 |
临时存储(Transient) |
一种服务器资源,当服务器重启时,保存的消息数据会丢失 |
持久化(Persistent) |
服务器将消息保存在可靠磁盘存储中,当服务器重启时,消息不会丢失 |
非持久化(Non-Persistent) |
服务器将消息保存在内存中,当服务器重启时,消息可能丢失 |
消费者(Consumer) |
一个从消息队列中请求消息的客户端应用程序 |
生产者(Producer) |
一个向交换器发布消息的客户端应用程序 |
虚拟主机(Virtual Host) |
一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。客户端应用程序在登录到服务器之后,可以选择一个虚拟主机 |
(四)、RabbitMQ的工作流程
消息队列有三个概念: 发消息者、消息队列、收消息者。RabbitMQ 在这个基本概念之上, 多做了一层抽象, 在发消息者和队列之间, 加入了交换器 (Exchange)。这样发消息者和消息队列就没有直接联系,转而变成发消息者把消息发给交换器,交换器根据调度策略再把消息转发给消息队列
消息生产者并没有直接将消息发送给消息队列,而是通过建立与Exchange的Channel,将消息发送给Exchange。Exchange根据路由规则,将消息转发给指定的消息队列。消息队列储存消息,等待消费者取出消息。消费者通过建立与消息队列相连的Channel,从消息队列中获取消息
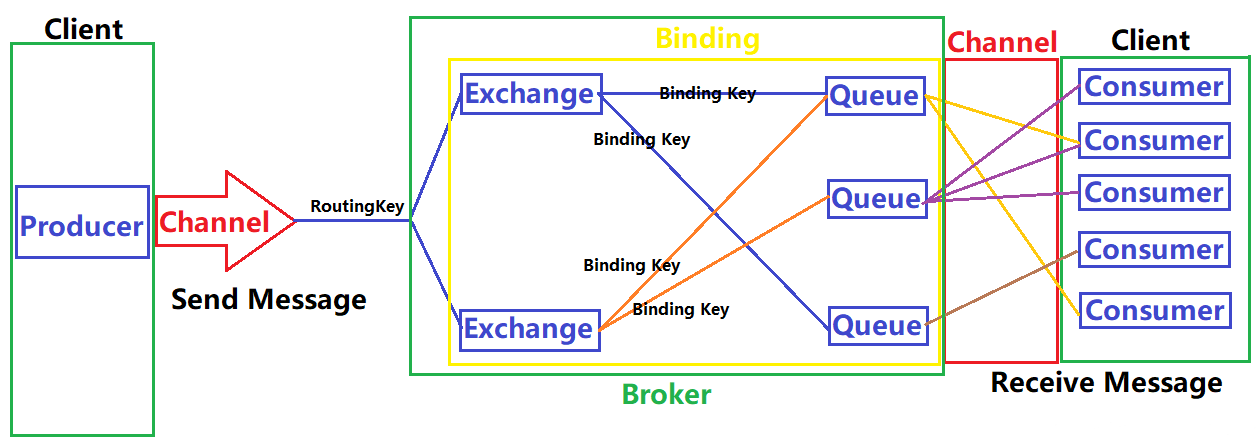
| Producer(消息的生产者) | 向消息队列发布消息的客户端应用程序 |
|---|---|
| Channel(信道) | 多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内的虚拟连接,复用TCP连接的通道 |
| Routing Key(路由键) | 消息头的一个属性,用于标记消息的路由规则,决定了交换机的转发路径。最大长度255 字节 |
| Broker | RabbitMQ Server,服务器实体 |
| Binding(绑定) | 用于建立Exchange和Queue之间的关联。一个绑定就是基于Binding Key将Exchange和Queue连接起来的路由规则,所以可以将交换器理解成一个由Binding构成的路由表 |
| Exchange(交换器|路由器) | 提供Producer到Queue之间的匹配,接收生产者发送的消息并将这些消息按照路由规则转发到消息队列。交换器用于转发消息,它不会存储消息 ,如果没有 Queue绑定到 Exchange 的话,它会直接丢弃掉 Producer 发送过来的消息。交换器有四种消息调度策略,分别是fanout, direct, topic, headers |
| Binding Key(绑定键) | Exchange与Queue的绑定关系,用于匹配Routing Key。最大长度255 字节 |
| Queue(消息队列) | 存储消息的一种数据结构,用来保存消息,直到消息发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将消息取走。需要注意,当多个消费者订阅同一个Queue,这时Queue中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,每一条消息只能被一个订阅者接收 |
| Consumer(消息的消费者) | 从消息队列取得消息的客户端应用程序 |
| Message(消息) | 消息由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(消息优先权)、delivery-mode(是否持久性存储)等 |
(五)、Exchange消息调度策略
交换器的功能主要是接收消息并且转发到绑定的队列,交换器不存储消息,在启用ack模式后,交换器找不到队列会返回错误
调度策略是指Exchange在收到生产者发送的消息后依据什么规则把消息转发到一个或多个队列中保存。调度策略与三个因素相关:Exchange Type(Exchange的类型),Binding Key(Exchange和Queue的绑定关系),消息的标记信息(Routing Key和headers)
Exchange根据消息的Routing Key和Exchange绑定Queue的Binding Key分配消息。生产者在将消息发送给Exchange的时候,一般会指定一个Routing Key,来指定这个消息的路由规则,而这个Routing Key需要与Exchange Type及Binding Key联合使用才能最终生效
在Exchange Type与Binding Key固定的情况下(一般这些内容都是固定配置好的),我们的生产者就可以在发送消息给Exchange时,通过指定Routing Key来决定消息流向哪里
交换器的四种消息调度策略:fanout, direct, topic, headers
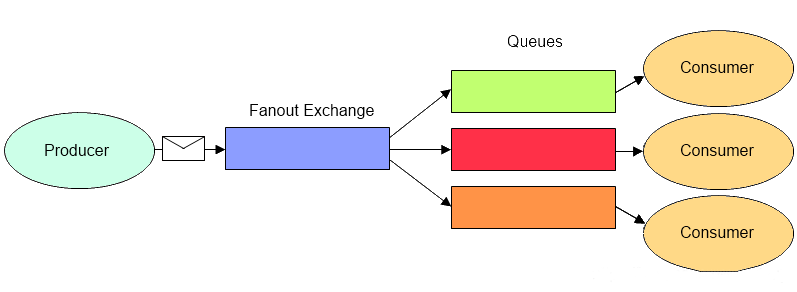
1、Fanout (订阅模式**/**广播模式)
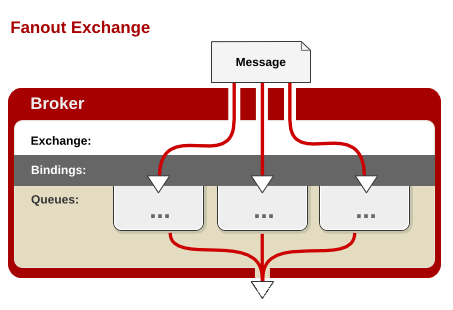
交换器会把所有发送到该交换器的消息路由到所有与该交换器绑定的消息队列中。订阅模式
与Binding Key和Routing Key无关,交换器将接受到的消息分发给有绑定关系的所有消息队列队列(不论Binding Key和Routing Key是什么)。类似于子网广播,子网内的每台主机都获得了一份复制的消息。Fanout交换机转发消息是最快的
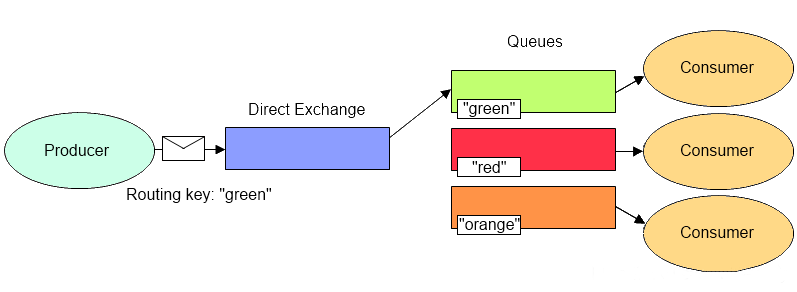
2、Direct(路由模式)
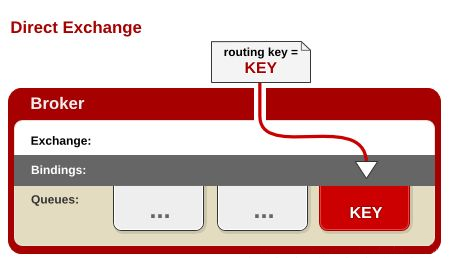
精确匹配:当消息的Routing Key与 Exchange和Queue 之间的Binding Key完全匹配,如果匹配成功,将消息分发到该Queue。只有当Routing Key和Binding Key完全匹配的时候,消息队列才可以获取消息。Direct是Exchange的默认模式
RabbitMQ默认提供了一个Exchange,名字是空字符串,类型是Direct,绑定到所有的Queue(每一个Queue和这个无名Exchange之间的Binding Key是Queue的名字)。所以,有时候我们感觉不需要交换器也可以发送和接收消息,但是实际上是使用了RabbitMQ默认提供的Exchange
3、Topic (通配符模式)
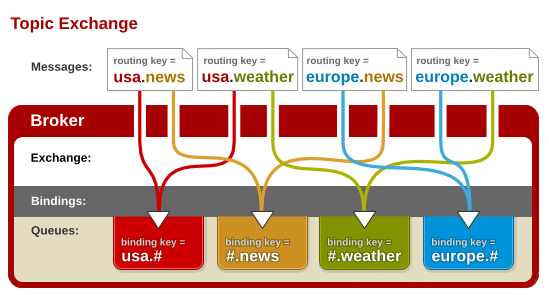
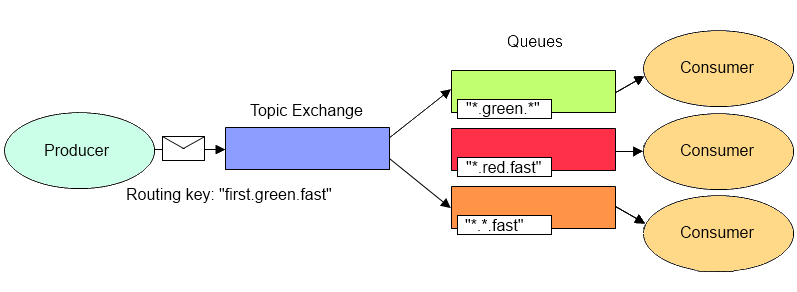
按照正则表达式模糊匹配:用消息的Routing Key与 Exchange和Queue 之间的Binding Key进行模糊匹配,如果匹配成功,将消息分发到该Queue
Routing Key是一个句点号“. ”分隔的字符串(我们将被句点号“. ”分隔开的每一段独立的字符串称为一个单词)。Binding Key与Routing Key一样也是句点号“. ”分隔的字符串。Binding Key中可以存在两种特殊字符“ * ”与“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
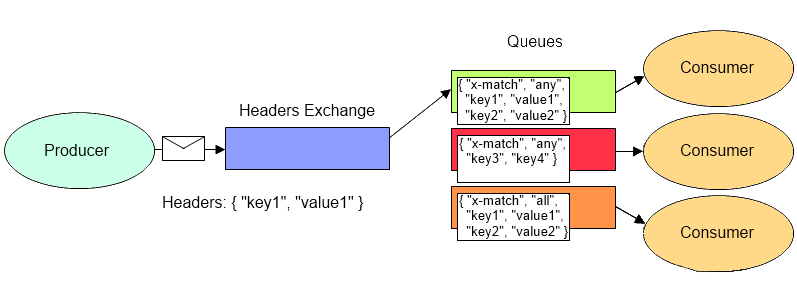
4、Headers(键值对模式)
Headers不依赖于Routing Key与Binding Key的匹配规则来转发消息,交换器的路由规则是通过消息头的Headers属性来进行匹配转发的,类似HTTP请求的Headers
在绑定Queue与Exchange时指定一组键值对,键值对的Hash结构中要求携带一个键“x-match”,这个键的Value可以是any或all,代表消息携带的Hash是需要全部匹配(all),还是仅匹配一个键(any)
当消息发送到Exchange时,交换器会取到该消息的headers,对比其中的键值对是否完全匹配Queue与Exchange绑定时指定的键值对;如果完全匹配则消息会路由到该Queue,否则不会路由到该Queue。Headers交换机的优势是匹配的规则不被限定为字符串(String),而是Object类型
(六)、RPC(Remote Procedure Call,远程过程调用)
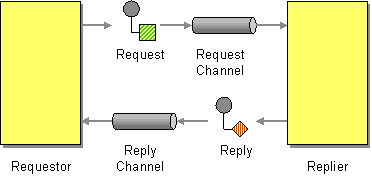
MQ本身是基于异步的消息处理,前面的示例中所有的生产者(P)将消息发送到RabbitMQ后不会知道消费者(C)处理成功或者失败(甚至连有没有消费者来处理这条消息都不知道)
但实际的应用场景中,我们很可能需要一些同步处理,需要同步等待服务端将我的消息处理完成后再进行下一步处理。这相当于RPC(Remote Procedure Call,远程过程调用)。在RabbitMQ中也支持RPC
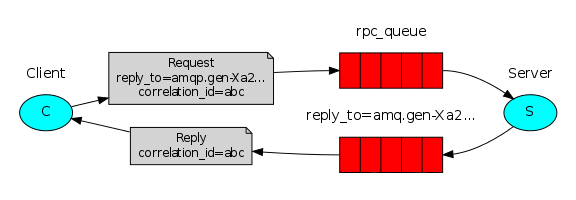
RabbitMQ中实现RPC的机制是:
1、客户端发送请求(消息)时,在消息的属性(MessageProperties,在AMQP协议中定义了14个属性,这些属性会随着消息一起发送)中设置两个值replyTo(一个Queue名称,用于告诉服务器处理完成后将通知我的消息发送到这个Queue中)和correlationId(此次请求的标识号,服务器处理完成后需要将此属性返还,客户端将根据这个id了解哪条请求被成功执行了或执行失败)
2、服务器端收到消息并处理
3、服务器端处理完消息后,将生成一条应答消息到replyTo指定的Queue,同时带上correlationId属性
4、客户端之前已订阅replyTo指定的Queue,从中收到服务器的应答消息后,根据其中的correlationId属性分析哪条请求被执行了,根据执行结果进行后续业务处理
(七)、消息确认:Message acknowledgment
在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失。为了避免这种情况发生,我们可以要求消费者在消费完消息后发送一个回执给RabbitMQ,RabbitMQ收到消息回执(Message acknowledgment)后才将该消息从Queue中移除;如果RabbitMQ没有收到回执并检测到消费者的RabbitMQ连接断开,则RabbitMQ会将该消息发送给其他消费者(如果存在多个消费者)进行处理。这里不存在Timeout概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的RabbitMQ连接断开
这里会产生另外一个问题,如果我们的开发人员在处理完业务逻辑后,忘记发送回执给RabbitMQ,这将会导致严重的问题,Queue中堆积的消息会越来越多,消费者重启后会重复消费这些消息并重复执行业务逻辑
如果我们采用no-ack的方式进行确认,也就是说,每次Consumer接到数据后,而不管是否处理完成,RabbitMQ会立即把这个Message标记为完成,然后从queue中删除了
(八)、消息持久化:Message durability
如果我们希望即使在RabbitMQ服务重启的情况下,也不会丢失消息,我们可以将Queue与Message都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果我们需要对这种小概率事件也要管理起来,那么我们要用到事务
(九)、分发机制
我们在应用程序使用消息系统时,一般情况下生产者往队列里插入数据时速度是比较快的,但是消费者消费数据往往涉及到一些业务逻辑处理导致速度跟不上生产者生产数据。因此如果一个生产者对应一个消费者的话,很容易导致很多消息堆积在队列里。这时,就得使用工作队列了。一个队列有多个消费者同时消费数据
工作队列有两种分发数据的方式: 轮询分发(Round-robin)和 公平分发(Fair dispatch)
轮询分发:队列给每一个消费者发送数量一样的数据
公平分发: 消费者设置每次从队列中取一条数据,并且消费完后手动应答,继续从队列取下一个数据
1、轮询分发:Round-robin dispatching
如果工作队列中有两个消费者,两个消费者得到的数据量一样的,并不会因为两个消费者处理数据速度不一样使得两个消费者取得不一样数量的数据。但是这种分发方式存在着一些隐患,消费者虽然得到了消息,但是如果消费者没能成功处理业务逻辑,在RabbitMQ中也不存在这条消息。就会出现消息丢失并且业务逻辑没能成功处理的情况
2、公平分发:Fair dispatch
消费者设置每次从队列里取一条数据,并且关闭自动回复机制,每次取完一条数据后,手动回复并继续取下一条数据。与轮询分发不同的是,当每个消费都设置了每次只会从队列取一条数据时,并且关闭自动应答,在每次处理完数据后手动给队列发送确认收到数据。这样队列就会公平给每个消息费者发送数据,消费一条再发第二条,而且可以在管理界面中看到数据是一条条随着消费者消费完从而减少的,并不是一下子全部分发完了。采用公平分发方式就不会出现消息丢失并且业务逻辑没能成功处理的情况
(十)、事务
对事务的支持是AMQP协议的一个重要特性。假设当生产者将一个持久化消息发送给服务器时,因为consume 命令本身没有任何Response返回,所以即使服务器崩溃,没有持久化该消息,生产者也无法获知该消息已经丢失。如果此时使用事务,即通过txSelect()开启一个事务,然后发送消息给服务器,然后通过txCommit() 提交该事务,即可以保证,如果txCommit()提交了,则该消息一定会持久化,如果txCommit() 还未提交即服务器崩溃,则该消息不会服务器接收。当然Rabbit MQ 也提供了txRollback() 命令用于回滚某一个事务
(十一)、Confirm机制
使用事务固然可以保证只有提交的事务,才会被服务器执行。但是这样同时也将客户端与消息服务器同步起来,这背离了消息队列解耦的本质。Rabbit MQ提供了一个更加轻量级的机制来保证生产者可以感知服务器消息是否已被路由到正确的队列中——Confirm。如果设置channel为confirm状态,则通过该channel发送的消息都会被分配一个唯一的ID,然后一旦该消息被正确的路由到匹配的队列中后,服务器会返回给生产者一个Confirm,该Confirm包含该消息的ID,这样生产者就会知道该消息已被正确分发。对于持久化消息,只有该消息被持久化后,才会返回Confirm。Confirm机制的最大优点在于异步,生产者在发送消息以后,即可继续执行其他任务。而服务器返回Confirm后,会触发生产者的回调函数,生产者在回调函数中处理Confirm信息。如果消息服务器发生异常,导致该消息丢失,会返回给生产者一个nack,表示消息已经丢失,这样生产者就可以通过重发消息,保证消息不丢失。Confirm机制在性能上要比事务优越很多。但是Confirm机制,无法进行回滚,就是一旦服务器崩溃,生产者无法得到Confirm信息,生产者其实本身也不知道该消息是否已经被持久化,只有继续重发来保证消息不丢失,但是如果原先已经持久化的消息,并不会被回滚,这样队列中就会存在两条相同的消息,系统需要支持去重
(十二)、Alternate Exchange(代替交换器)
Alternate Exchange是Rabbitmq自己扩展的功能,不是AMQP协议定义的
创建Exchange指定该Exchange的Alternate Exchange,发送消息的时候如果Exchange没有成功把消息路由到队列中去,这就会将此消息路由到Alternate Exchange属性指定的Exchange上了。需要在创建Exchange时添加alternate-exchange属性。如果Alternate Exchange也没能成功把消息路由到队列中去,这个消息就会丢失。可以触发publish confirm机制,表示这个消息没有确认
创建交换器时需要指定如下属性
Map<String,Object> argsMap = new HashMap<>();
argsMap.put(“alternate-exchange”,“Alternate Exchange Name”);
(十三)、TTL(生存时间)
RabbitMQ允许您为消息和队列设置TTL(生存时间)。 可以使用可选的队列参数或策略完成(推荐使用后一个选项)。 可以为单个队列,一组队列或单个消息应用消息TTL
设置消息的过期时间
MessageProperties messageProperties = new MessageProperties();
messageProperties.setExpiration(“30000”);
设置队列中消息的过期时间
在声明一个队列时,可以指定队列中消息的过期时间,需要添加x-message-ttl属性
Map<String, Object> arguments = new HashMap<>();
arguments.put(“x-message-ttl”,30000);
如果同时制定了Message TTL,Queue TTL,则时间短的生效
(十四)、Queue Length Limit(队列长度限制)
可以设置队列中消息数量的限制,如果测试队列中最多只有5个消息,当第六条消息发送过来的时候,会删除最早的那条消息。队列中永远只有5条消息
使用代码声明含有x-max-length和x-max-length-bytes属性的队列
Max length(x-max-length) 用来控制队列中消息的数量
如果超出数量,则先到达的消息将会被删除掉
Max length bytes(x-max-length-bytes) 用来控制队列中消息总的大小
如果超过总大小,则最先到达的消息将会被删除,直到总大小不超过x-max-length-byte为止
Map<String, Object> arguments = new HashMap<>();
arguments.put(“x-max-length”,3); #表示队列中最多存放三条消息
Map<String, Object> arguments = new HashMap<>();
arguments.put(“x-max-length-bytes”,10); #队列中消息总的空间大小
(十五)、Dead Letter Exchange(死信交换器)
在队列上指定一个Exchange,则在该队列上发生如下情况
1、 消息被拒绝(basic.reject or basic.nack),且requeue=false
2、 消息过期而被删除(TTL)
3、 消息数量超过队列最大限制而被删除
4、 消息总大小超过队列最大限制而被删除
就会把该消息转发到指定的这个exchange
需要定义了x-dead-letter-exchange属性,同时也可以指定一个可选的x-dead-letter-routing-key,表示默认的routing-key,如果没有指定,则使用消息原来的routeing-key进行转发
当定义队列时指定了x-dead-letter-exchange(x-dead-letter-routing-key视情况而定),并且消费端执行拒绝策略的时候将消息路由到指定的Exchange中去
我们知道还有二种情况会造成消息转发到死信队列
一种是消息过期而被删除,可以使用这个方式使的rabbitmq实现延迟队列的作用。还有一种就是消息数量超过队列最大限制而被删除或者消息总大小超过队列最大限制而被删除
(十六)、priority queue(优先级队列)
声明队列时需要指定x-max-priority属性,并设置一个优先级数值
消息优先级属性
MessageProperties messageProperties = new MessageProperties();
messageProperties.setPriority(priority);
如果设置的优先级小于等于队列设置的x-max-priority属性,优先级有效
如果设置的优先级大于队列设置的x-max-priority属性,则优先级失效
创建优先级队列,需要增加x-max-priority参数,指定一个数字。表示最大的优先级,建议优先级设置为1~10之间
发送消息的时候,需要设置priority属性,最好不要超过上面指定的最大的优先级
如果生产端发送很慢,消费者消息很快,则有可能不会严格的按照优先级来进行消费
1、发送的消息的优先级属性小于设置的队列属性x-max-priority值,则按优先级的高低进行消费,数字越高则优先级越高
2、送的消息的优先级属性都大于设置的队列属性x-max-priority值,则设置的优先级失效,按照入队列的顺序进行消费
3、 费端一直进行监听,而发送端一条条的发送消息,优先级属性也会失效
RabbitMQ不能保证消息的严格的顺序消费
(十七)、延迟队列
延迟队列就是进入该队列的消息会被延迟消费的队列。而一般的队列,消息一旦入队了之后就会被消费者马上消费
延迟队列多用于需要延迟工作的场景
最常见的是以下两种场景:
1、 消费
如:用户生成订单之后,需要过一段时间校验订单的支付状态,如果订单仍未支付则需要及时地关闭订单
用户注册成功之后,需要过一段时间比如一周后校验用户的使用情况,如果发现用户活跃度较低,则发送邮件或者短信来提醒用户使用
2、延迟重试
如:消费者从队列里消费消息时失败了,但是想要延迟一段时间后自动重试
我们可以利用RabbitMQ的两个特性,一个是Time-To-Live Extensions,另一个是Dead Letter Exchanges。实现延迟队列
Time-To-Live Extensions
RabbitMQ允许我们为消息或者队列设置TTL(time to live),也就是过期时间。TTL表明了一条消息可在队列中存活的最大时间,单位为毫秒。也就是说,当某条消息被设置了TTL或者当某条消息进入了设置了TTL的队列时,这条消息会在经过TTL秒后“死亡”,成为Dead Letter。如果既配置了消息的TTL,又配置了队列的TTL,那么较小的那个值会被取用
Dead Letter Exchange
刚才提到了,被设置了TTL的消息在过期后会成为Dead Letter。其实在RabbitMQ中,一共有三种消息的“死亡”形式:
1、消息被拒绝。通过调用basic.reject或者basic.nack并且设置的requeue参数为false
2、消息因为设置了TTL而过期
3、消息进入了一条已经达到最大长度的队列
如果队列设置了Dead Letter Exchange(DLX),那么这些Dead Letter就会被重新publish到Dead Letter Exchange,通过Dead Letter Exchange路由到其他队列
四、RabbitMQ配置
(一)、RabbitMQ 常用命令
1、Vhost虚拟机
每个RabbitMQ服务器都能创建虚拟主机(virtual host),简称vhost。每个vhost本质上是一个独立的小型RabbitMQ服务器,拥有自己独立的队列、交换器及绑定关系等,并且它拥有自己独立的权限,RabbitMQ默认创建vhost为 / ”
创建vhost
rabbitmqctl add_vhost {
vhost}
查看所有vhost
rabbitmqctl list_vhosts
删除指定vhost
rabbitmqctl delete_vhost {
vhost}
2、用户管理
在RabbitMQ中,用户是访问控制的基本单元,且单个用户可以跨越多个vhost进行授权
创建用户
rabbitmqctl add_user {
username} {
password}
修改密码
rabbitmqctl change_password {
username} {
password}
清除密码
rabbitmqctl clear_password {
username}
验证用户
rabbitmqctl authenticate_user {
username} {
password}
删除用户
rabbitmqctl delete_user {
username}
用户列表
rabbitmqctl list_users
3、权限管理
用户权限指的是用户对exchange,queue的操作权限,包括配置权限,读写权限。配置权限会影响到exchange,queue的声明和删除。读写权限影响到从queue里取消息,向exchange发送消息以及queue和exchange的绑定(bind)操作
RabbitMQ中,权限控制是以vhost为单位,创建用户时,将被指定至少一个vhost,默认的vhost是 “ / ”
授予权限
rabbitmqctl set_permissions [-p vhost] {
user}{
conf}{
write}{
read}
| 配置项 | 说明 |
|---|---|
| vhost | 授权用户访问指定的vhost |
| user | 用户名 |
| conf | 一个用于匹配用户在哪些资源上拥有可配置权限的正则表达式,例如:".*"表示全部 |
| write | 一个用于匹配用户在哪些资源上拥有可写权限的正则表达式 ,例如:".*"表示全部 |
| read | 一个用于匹配用户在哪些资源上拥有可读权限的正则表达式,例如:".*"表示全部 |
收回权限
rabbitmqctl clear_permissions [-p vhost] {username}
虚拟主机权限列表
rabbitmqctl list_permissions [-p vhost]
查看指定用户权限
rabbitmqctl list_user_permissions {username}
4、角色分配
rabbitmq的角色有5种类型
rabbitmqctl set_user_tags {
username} {
tag…}
User为用户名
Tag为角色名(对应的administrator,monitoring,policymaker,management,或其他自定义名称)
也可以给同一用户设置多个角色,例:
rabbitmqctl set_user_tags hncscwc monitoring policymaker
| 配置项 | 说明 |
|---|---|
| none其他 | 无任何角色,新创建的用户默认角色为none |
| management普通管理者 | 可以访问web管理页面,无法看到节点信息,也无法对策略进行管理 |
| policymaker策略制定者 | 包含management的所有权限,并可以管理策略和参数,但无法查看节点的相关信息 |
| monitoring监控者 | 包含management的所有权限,并可以看到所有连接(启用management plugin的情况下)、信道及节点相关信息(进程数,内存使用情况,磁盘使用情况等) |
| administartor超级管理员 | 包含minitoring的所有权限,并可以管理用户、虚拟主机、权限、策略、参数 |
5、Web端管理
RabbitMQ Management 插件可以提供Web界面来管理RabbitMQ中的虚拟主机、用户、角色、队列、交换器、绑定关系、策略、参数等,也可用于监控RabbitMQ服务的状态及一些统计信息
启动插件
rabbitmq-plugins enable rabbitmq_management
关闭插件
rabbitmq-plugins disable rabbitmq_management
插件列表:其中标记为[E*]为显示启动,其中标记为[e*]为隐式启动,开启此功能后需要重启服务才可以正式生效
rabbitmq-plugins list
6、RabbitMQ 管理
[root@servers sbin]# ./rabbitmq-server #启动,ctrl + c 退出及关闭
[root@servers sbin]# ./rabbitmq-server -detached #在后台启动服务
[root@servers sbin]# ./rabbitmqctl stop #关闭服务
[root@C7--13 sbin]# ./rabbitmq-server status #查看状态
7、查看队列列表
rabbitmqctl list_queues[-p vhost][queueinfoitem…]
| 返回列 | 说明 |
|---|---|
| name | 队列名称 |
| durable | 队列是否持久化 |
| auto_delete | 队列是否自动删除 |
| arguments | 队列参数 |
| policy | 应用到队列上的策略名称 |
| pid | 队列关联的进程ID |
| owner_pid | 处理排他队列连接的进程ID |
| exclusive | 队列是否排他 |
8、查看交换器列表
rabbitmqctl list_exchanges [-p vhost][exchangeinfoitem…]
| 返回列 | 说明 |
|---|---|
| name | 交换器名称 |
| type | 交换器类型 |
| durable | 交换器是否持久化 |
| auto_delete | 交换器是否自动删除 |
| internal | 是否是内置交换器 |
| arguments | 交换器的参数 |
| policy | 交换器的策略 |
9、查看绑定关系的列表
rabbitmqctl list_bindings [-p] [bindinginfoitem…]
| 返回列 | 说明 |
|---|---|
| source_name | 消息来源的名称 |
| source_kind | 消息来源的类别 |
| destination_name | 消息目的地的名称 |
| destination_kind | 消息目的地的种类 |
| routing_key | 绑定的路由键 |
| arguments | 绑定的参数 |
10、查看连接信息列表
rabbitmqctl list_connections [connectioninfoitem …]
| 返回列 | 说明 |
|---|---|
| pid | 与连接相关的进程ID |
| name | 连接名称 |
| port | 服务器端口 |
| host | 服务器主机名 |
| peer_port | 服务器对端端口。当一个客户端与服务器连接时,这个客户端的端口就是peer_port |
| peer_host | 服务器对端主机名称,或IP |
| ssl | 是否启用SSL |
| state | 连接状态,包括starting\tning\opening\running\flow\blocking\blocked\closing\closed |
| channels | 连接中的信道个数 |
| protocol | 使用的AMQP协议版本 |
| user | 与连接相关的用户名 |
| vhost | 与连接相关的vhost名称 |
| timeout | 连接超时时长,单位秒 |
11、查看信道列表
rabbitmqctl list_channels [channelinfoitem…]
| 返回列 | 说明 |
|---|---|
| pid | 与连接相关的进程ID |
| connection | 信道所属连接的进程ID |
| name | 信道名称 |
| number | 信道的序号 |
| user | 与连接相关的用户名 |
| vhost | 与连接相关的vhost名称 |
| transactional | 信道是否处于事务模式 |
| confirm | 信道是否处于 publisher confirm模式 |
| consumer_count | 信道中的消费者个数 |
| messages_unacknowledged | 已投递但是还未被ack的消息个数 |
| messages_uncommitted | 已接收但是还未提交事务的消息个数 |
| acks_uncommitted | 已ack收到但是还未提交事务的消息个数 |
| messages_unconfirmed | 已发送但是还未确认的消息个数 |
| perfetch_count | 消费者的Qos个数限制,0表示无上限 |
| global_prefetch_count | 整个信道的Qos个数限制 |
12、查看消费者列表
rabbitmqctl list_consumers [-p vhost]
| 返回列 | 说明 |
|---|---|
| arguments | 参数 |
| canal_pid | ID del proceso del canal |
| etiqueta_consumidor | marca de consumo |
| prefetch_count | El límite en la cantidad de Qos para los consumidores , 0 significa que no hay límite superior |
| nombre_cola | nombre de la cola |
(2) Operaciones básicas de la interfaz web.
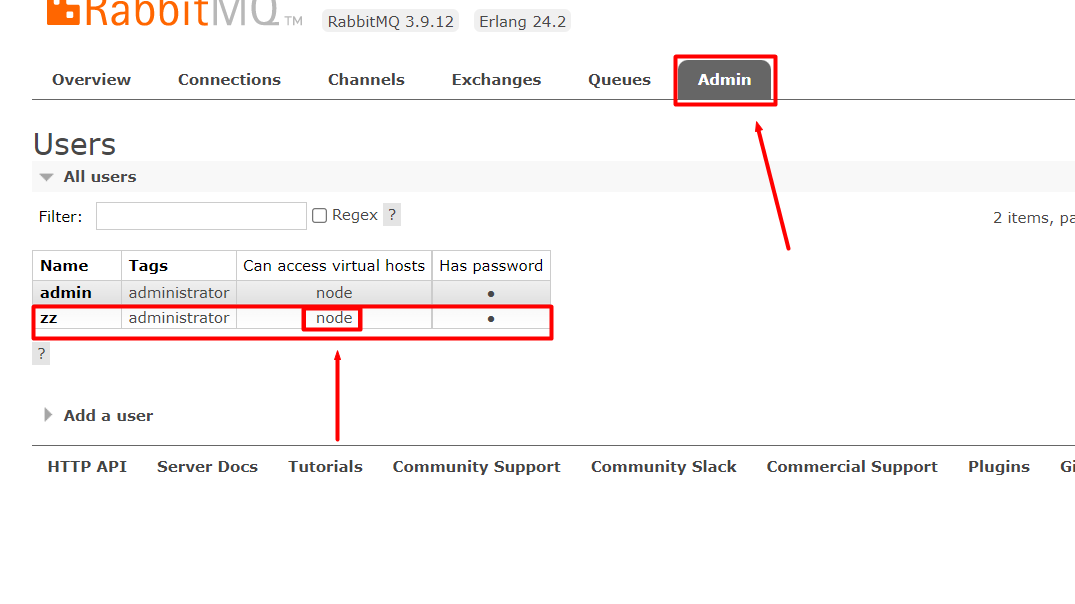
1. Agregar usuario

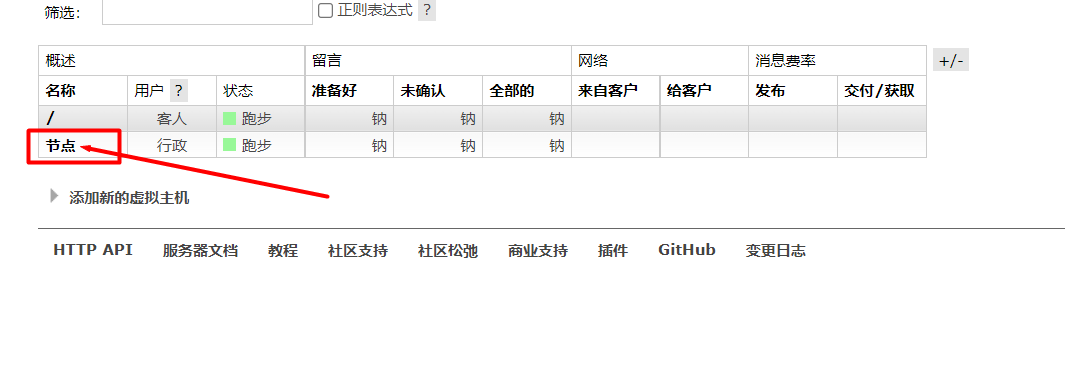
2. Crear un host virtual  3. Vincular usuarios al host virtual
3. Vincular usuarios al host virtual