De: estación de trabajo de PNL
Ingrese al grupo de PNL—> Únase al grupo de intercambio de PNL
escribir delante
La formación previa es una tarea que consume muchos recursos, especialmente en la era del LLM. Con el código abierto de LLama2, cada vez más personas han comenzado a intentar mejorar el chino en este poderoso modelo base en inglés. Sin embargo, ¿cómo podemos garantizar que el modelo aprenda el "conocimiento chino" sin perder el "conocimiento inglés" original?
Hoy les traigo un artículo sobre Entrenamiento previo continuo (del Sr. He Zhi, Zhihu@何志), Entrenamiento previo continuo de modelos de lenguaje grandes: ¿Cómo (re)calentar su modelo?
知乎:https://zhuanlan.zhihu.com/p/654463331
paper:https://arxiv.org/pdf/2308.04014.pdf1. Configuraciones experimentales
El autor utiliza un modelo Pythia de tamaño 410M, que ha sido previamente entrenado con los datos de Pile y luego ajustado con el conjunto de datos descendente SlimPajama.
El artículo utiliza directamente la pérdida como índice de evaluación, es decir, cuanto menor es la pérdida, más fuerte será el efecto en las tareas ascendentes (o descendentes).
Pythia: https://huggingface.co/EleutherAI/pythia-410m-v0
Pile: https://huggingface.co/datasets/EleutherAI/pile
SlimPajama: https://www.cerebras.net/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama2. Conclusiones clave
2.1 El número de pasos de calentamiento no afectará el rendimiento final
El calentamiento es una estrategia comúnmente utilizada en el ajuste fino, lo que significa que la tasa de aprendizaje aumenta lentamente desde un valor muy pequeño hasta el valor máximo. Entonces, ¿cuánto es el mejor momento para que dure esta etapa de "lento ascenso"?
El autor utilizó cuatro pasos de precalentamiento diferentes: 0%, 0,5%, 1% y 2% para realizar experimentos: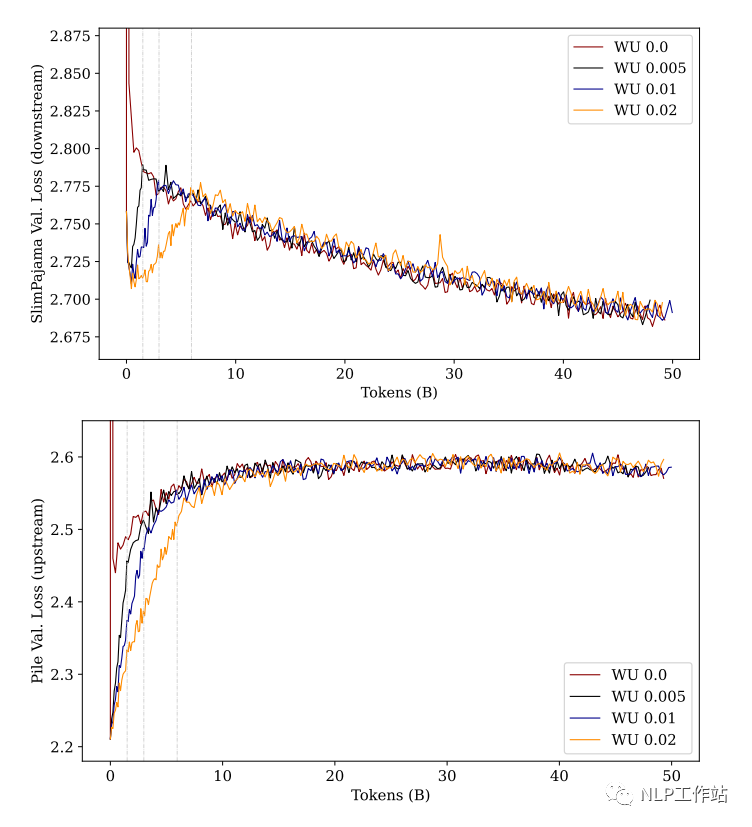
Como puede ver en la figura anterior: cuando el modelo esté "completamente" entrenado, el rendimiento final será similar sin importar cuán largos sean los pasos de calentamiento.
Sin embargo, esta premisa es "entrenamiento completo", si solo nos fijamos en la etapa inicial del entrenamiento, utilice un mayor número de pasos de calentamiento (línea amarilla). Ya sea una "tarea ascendente" o una "tarea descendente", la pérdida del modelo es menor que otros pasos de preparación (el proceso descendente aprende más rápido, el ascendente se olvida lentamente).
2.2 Cuanto mayor sea la tasa de aprendizaje, mejores serán las tareas posteriores y peores las tareas anteriores.
Para explorar el impacto de la tasa de aprendizaje en el efecto del aprendizaje, el autor utilizó 4 tasas de aprendizaje máximas diferentes para realizar experimentos comparativos.
Además, se comparó el efecto del modelo entrenado desde cero: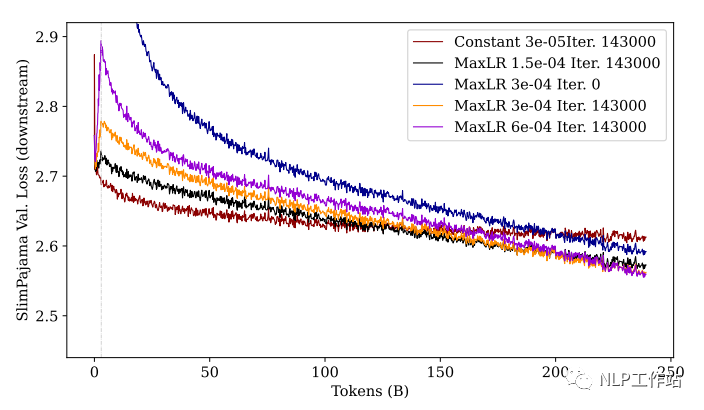
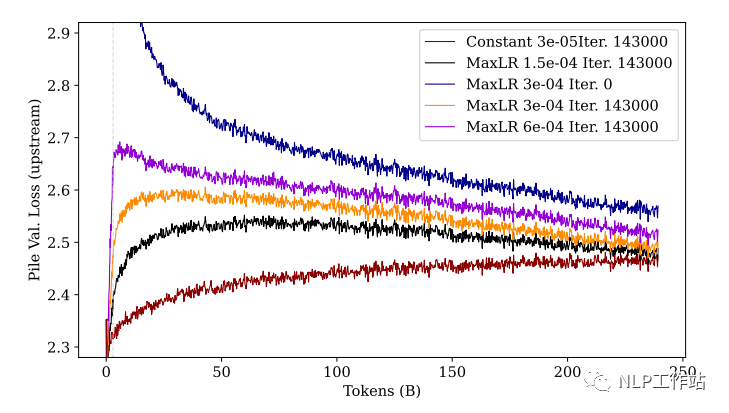
Como se puede ver en la figura: después de un entrenamiento suficiente, cuanto mayor sea la tasa de aprendizaje (púrpura), mejor será el rendimiento posterior y peor será el rendimiento ascendente (olvidando más). De manera similar, observamos el entrenamiento inicial: aunque la línea violeta tiene la pérdida más baja al final, la pérdida aumentará mucho en la etapa inicial y luego disminuirá.
PD: Permítanme explicar por qué aquí se presta tanta atención a la etapa inicial del entrenamiento, porque en el entrenamiento real, es posible que no necesariamente mejoremos los 250 mil millones de tokens que se muestran en la figura, especialmente cuando los parámetros del modelo son grandes. Por lo tanto, cuando los recursos no permiten un entrenamiento suficiente, una tasa de aprendizaje menor y un número mayor de pasos de calentamiento pueden ser una buena opción.
Además, se puede ver en la figura que el modelo sin entrenamiento previo (azul) no es tan efectivo como el modelo previamente entrenado en las tareas ascendentes y descendentes.
Esto nos anima a seguir entrenando en un modelo previamente entrenado (para aprovechar el conocimiento previo) a la hora de realizar tareas de formación hoy.
2.3 Usar Rewarmup en el preentrenamiento inicial dañará el rendimiento
Aunque la estrategia de calentamiento tiene mejores resultados tanto en Finetune como en Continuar preentrenamiento (en comparación con la tasa de aprendizaje constante), esto se basa en la premisa de "cambiar el conjunto de datos de entrenamiento (distribución de datos)".
El autor hizo un experimento, no cambió el conjunto de datos, pero continuó entrenando con el "conjunto de datos previo al entrenamiento (The Pile)" anterior: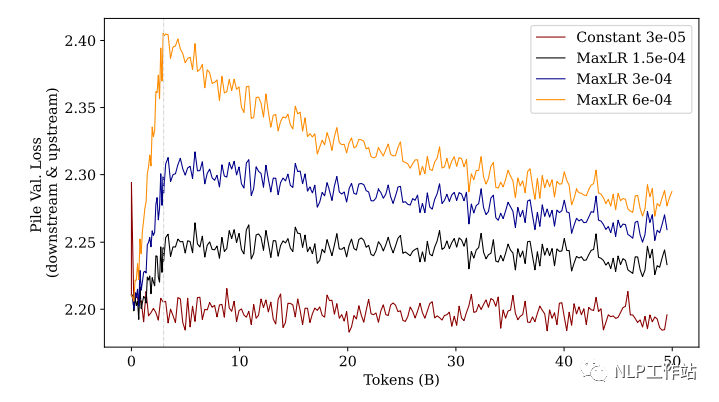
De los resultados de la figura, podemos encontrar que no importa cuán grande sea la estrategia de calentamiento de la tasa de aprendizaje, el efecto no es tan bueno como usar una tasa de aprendizaje constante.
Esto demuestra además que usar el calentamiento en el conjunto de datos original y luego entrenar causará daños en el rendimiento. Cuanto mayor sea la tasa de aprendizaje, mayor será el daño, y este daño no se puede recuperar en entrenamientos posteriores.
PD: Aquí se nos recuerda que cuando encontramos una interrupción del entrenamiento durante el preentrenamiento y necesitamos continuar entrenando, debemos restaurar la tasa de aprendizaje al estado anterior a la interrupción (ya sea un valor o una tasa de caída) cuando reiniciemos el entrenamiento. .
3. Limitaciones experimentales
El autor publicó algunas limitaciones para llegar a la conclusión anterior al final del artículo.
3.1 La distribución de datos ascendentes y descendentes es similar
Debido a que existe cierta superposición de datos entre el conjunto de datos ascendente [Pile] y el conjunto de datos descendente [SlimPajama] seleccionado en el experimento,
Por lo tanto, la distribución de datos ascendentes y descendentes es relativamente similar, pero en nuestras tareas de entrenamiento reales, la diferencia entre los datos ascendentes y descendentes puede ser mucho mayor que esto.
3.2 El modelo es de pequeña escala.
El tamaño del modelo utilizado en el artículo es 410M, que está lejos de la escala de LLM con la que la gente comenzó con 7B hoy.
Sin embargo, el equipo planea seguir probándolo en las escalas 3B y 7B en el próximo trabajo y espera conocer sus conclusiones experimentales finales.
Ingrese al grupo de PNL—> Únase al grupo de intercambio de PNL