Directorio de artículos
-
-
- 1. Introducción a la JVM
- 2. Exploración en profundidad de la estructura interna de JVM
- 2.3 Práctica de ajuste del rendimiento del área de memoria JVM
- 3. Mecanismo de recolección de basura JVM
- 4. Herramientas JVM y ajuste del rendimiento
-
Mapa mental del blog

1. Introducción a la JVM
La Máquina Virtual Java ( JVM ) es el componente central de la tecnología Java, que proporciona la base para las funciones multiplataforma de Java. JVM no es solo una máquina virtual, es un entorno de ejecución completo responsable de cargar, verificar, compilar y ejecutar el código de bytes de Java. En esta sección, profundizaremos en la definición de JVM, su función principal y sus características multiplataforma.
1.1 Definición y función central
La Máquina Virtual Java es una instancia de computadora virtual que permite que las aplicaciones Java se ejecuten en cualquier dispositivo o sistema operativo siempre que el dispositivo o sistema operativo tenga una implementación JVM. La tarea principal de JVM es cargar archivos .class (código de bytes de Java) y ejecutarlos. Estos archivos de código de bytes se compilan a partir de archivos fuente .java mediante el compilador de Java.
Las funciones principales de la JVM se pueden resumir de la siguiente manera:
-
Carga de código de bytes : la JVM es responsable de cargar archivos .class desde el sistema de archivos o los recursos de la red.
-
Verificación del código de bytes : asegúrese de que el código de bytes cargado sea válido, seguro y no dañe las estructuras de datos internas de la JVM.
-
Compilación justo a tiempo : la JVM puede utilizar un compilador justo a tiempo (JIT) para convertir el código de bytes en código de máquina nativo para aumentar la velocidad de ejecución.
-
Programa de ejecución : JVM crea y administra todos los recursos del programa, como subprocesos, espacio de memoria y operaciones de E/S, y ejecuta código de bytes.
-
Proporciona bibliotecas integradas : la JVM proporciona la API de Java, que es un conjunto de bibliotecas de clases precompiladas que proporcionan funcionalidad básica a las aplicaciones Java.
1.2 Funciones multiplataforma de JVM
El lema de Java es "Escribe una vez, ejecuta en cualquier lugar". Esto se debe a la función multiplataforma de Java y la implementación de esta función depende de la JVM.
Cuando se compila un programa Java, se convierte en código de bytes independiente de la plataforma en lugar de código de máquina específico de un determinado sistema operativo. Esto significa que siempre que un dispositivo tenga instalada la JVM, puede ejecutar cualquier aplicación Java, independientemente de la plataforma en la que se escribió originalmente el programa.
Los beneficios de este enfoque son obvios:
-
Portabilidad : las aplicaciones Java pueden ejecutarse en cualquier dispositivo con una JVM instalada sin ninguna modificación.
-
Seguridad : dado que las aplicaciones Java se ejecutan en una máquina virtual, están aisladas del sistema operativo subyacente, lo que proporciona un entorno de ejecución seguro para la aplicación.
-
Rendimiento : aunque las aplicaciones Java se ejecutan en una máquina virtual, pueden ejecutarse a una velocidad comparable a la de las aplicaciones nativas mediante tecnología de compilación justo a tiempo.
-
Integración : las aplicaciones Java pueden interactuar con aplicaciones nativas escritas en otros lenguajes, lo que facilita la integración de aplicaciones complejas.
En resumen, JVM proporciona una base sólida para la tecnología Java, lo que lo convierte en uno de los lenguajes de programación más populares en la actualidad. Al obtener una comprensión profunda de la JVM, podemos comprender mejor cómo funciona Java, lo que nos permite escribir y optimizar aplicaciones Java de manera más eficiente.
2. Exploración en profundidad de la estructura interna de JVM
La máquina virtual Java (JVM) es un sistema complejo responsable de ejecutar el código de bytes de Java y proporcionar un entorno de ejecución para aplicaciones Java. Para comprender mejor el mecanismo de ejecución de los programas Java, debemos profundizar en la estructura interna de la JVM y cómo funciona.
2.1 Mecanismo de carga de clases
En Java, la carga, vinculación e inicialización de clases son la base para que la JVM ejecute programas Java. Estos procesos garantizan que las clases Java se carguen en la JVM de forma correcta y segura.
2.1.1 Modelo de delegación parental
El modelo de delegación principal es el mecanismo central de la carga de clases de Java. Garantiza la seguridad de la biblioteca principal de Java y evita que código malicioso altere la biblioteca de clases principal.
Cómo funciona :
cuando un cargador de clases intenta cargar una clase, primero solicita a su cargador de clases principal que complete la tarea. Este proceso se repetirá hasta el cargador de clases de inicio; solo si el cargador de clases principal no puede completar la tarea, el cargador de clases secundario intentará cargar la clase por sí mismo.
// 示例代码:自定义类加载器
public class CustomClassLoader extends ClassLoader {
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
// 委派给父类加载器
return super.loadClass(name);
}
}
Explicación del código : en el código anterior, creamos un cargador de clases personalizado. Cuando se llama a un método loadClass, primero lo delega en su cargador de clases principal.
Preguntas de la entrevista (Nube de Alibaba) :
¿Qué es la delegación de padres? Introducir algunos procesos operativos y beneficios del modelo de delegación principal;
Si un cargador de clases recibe una solicitud de carga de clases, no la cargará primero. En su lugar, delegará la solicitud al cargador de clases principal para su ejecución. Si el cargador de clases principal todavía tiene su cargador de clases principal, delegará aún más hacia arriba. recursivamente, y la solicitud eventualmente llegará al cargador de clases de inicio de nivel superior. Si el cargador de clases principal puede completar la tarea de carga de clases, regresará exitosamente. Si el cargador de clases principal no puede completar la tarea de carga, el cargador secundario intentará su propio Ir a cargar, este es el modelo de delegación de padres, es decir, cada hijo no está dispuesto a trabajar, y cada vez que hay un trabajo, se lo deja a su padre para que lo haga, hasta que el padre dice que no puedo. Si lo hace, el hijo encontrará la manera de completarlo por sí mismo. ¿No es este el modelo legendario de delegación de los padres?
proceso de acción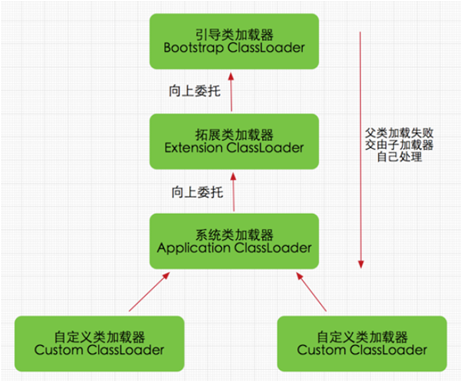
beneficio
Mecanismo de seguridad de Sandbox: la clase String.class escrita por usted mismo no se cargará, lo que puede evitar que la biblioteca API principal sea manipulada a voluntad y evitar la carga repetida de clases: cuando el padre ya ha cargado la clase, no es necesario para que el ClassLoader secundario lo cargue nuevamente.
2.1.2 Marco OSGI
OSGI (Open Service Gateway Initiative) es un marco modular de Java que permite a las aplicaciones instalar, iniciar, detener y desinstalar módulos dinámicamente.
Cómo funciona :
el marco OSGI utiliza su propio cargador de clases para cargar módulos. Esto permite que los módulos tengan sus propias versiones de clase, evitando conflictos de versiones de clase.
// 示例代码:OSGI BundleActivator
public class MyActivator implements BundleActivator {
public void start(BundleContext context) {
System.out.println("Module started");
}
public void stop(BundleContext context) {
System.out.println("Module stopped");
}
}
Explicación del código : el código anterior es un activador OSGI simple que imprime mensajes cuando el módulo se inicia y se detiene.
2.1.3 Clasificación del cargador de clases
En JVM, los cargadores de clases se dividen en tres tipos:
-
Bootstrap ClassLoader : responsable de cargar las bibliotecas de clases principales de JVM, como
java.lang.*. -
Extension ClassLoader : Responsable de cargar bibliotecas de extensiones de Java, como
javax.*. -
Application ClassLoader : Responsable de cargar la ruta de clase de la aplicación, la ruta del módulo, etc.
// 示例代码:获取类加载器
ClassLoader loader = MyClass.class.getClassLoader();
System.out.println(loader);
Explicación del código : el código anterior obtiene MyClassel cargador de clases y lo imprime.
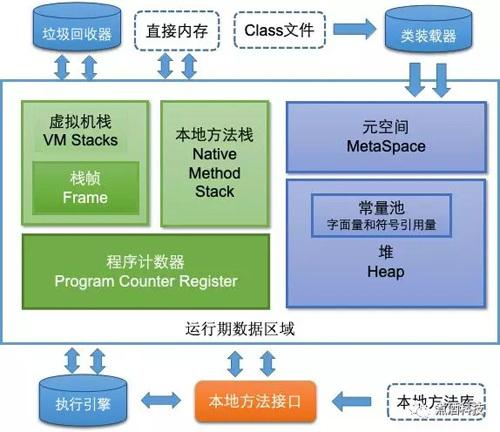
2.2 Área de datos de tiempo de ejecución de JVM
Cuando la JVM ejecuta un programa Java, utiliza múltiples áreas de memoria para almacenar datos. Comprender estas áreas y su propósito es fundamental para optimizar el rendimiento y diagnosticar problemas.
2.2.1 Contador de programa
El contador del programa es una pequeña área de memoria que almacena la dirección del código de bytes que el hilo ejecuta actualmente.
Cómo funciona :
cuando la JVM ejecuta un método, el contador del programa apunta a la primera instrucción de código de bytes de este método. A medida que se ejecutan las instrucciones de código de bytes, se incrementa el contador del programa.
// 示例代码:模拟程序计数器
public class ProgramCounterSimulation {
public static void main(String[] args) {
int counter = 0; // 模拟程序计数器
method1();
counter += 3; // 假设method1有3条字节码指令
method2();
counter += 2; // 假设method2有2条字节码指令
}
public static void method1() {
// ...
}
public static void method2() {
// ...
}
}
Explicación del código : el código anterior simula el principio de funcionamiento del contador del programa. Cuando se llama a un método, el contador del programa se incrementa, lo que refleja la ejecución de instrucciones de código de bytes.
2.2.2 Pila de métodos locales
La pila de métodos locales es un área de memoria que almacena variables locales, direcciones de retorno y otros datos de los métodos Java.
Cómo funciona :
cuando la JVM llama a un método, crea un marco de pila para el método y lo inserta en la pila de métodos local. Cuando este método regresa, su marco de pila aparece.
// 示例代码:模拟本地方法栈
public class LocalMethodStackSimulation {
public static void main(String[] args) {
method1();
method2();
}
public static void method1() {
int localVariable1 = 10; // 存储在本地方法栈中
// ...
}
public static void method2() {
String localVariable2 = "Hello"; // 存储在本地方法栈中
// ...
}
}
Explicación del código : el código anterior simula el principio de funcionamiento de la pila de métodos locales. Las variables locales para cada método se almacenan en la pila de métodos locales.
2.2.3 Pila de máquinas virtuales Java
La pila de la máquina virtual Java es un área de memoria que almacena la pila de operandos, la tabla de variables locales y otros datos de los métodos Java.
Principio de funcionamiento :
similar a la pila de métodos locales, cuando la JVM llama a un método, crea un marco de pila para este método y lo presiona.
Ingrese a la pila de la máquina virtual Java. Pero a diferencia de la pila de métodos nativos, la pila de la máquina virtual Java también almacena la pila de operandos, que es una pila que se utiliza para almacenar resultados intermedios durante el proceso de cálculo.
// 示例代码:模拟Java虚拟机栈
public class JVMStackSimulation {
public static void main(String[] args) {
int result = add(10, 20); // 操作数栈存储10和20,然后存储30(结果)
System.out.println(result);
}
public static int add(int a, int b) {
int sum = a + b; // 操作数栈存储a和b的值,然后存储它们的和
return sum;
}
}
Explicación del código : El código anterior simula el principio de funcionamiento de la pila de máquinas virtuales Java. addLa pila de operandos del método primero almacena alos bvalores de la suma y luego su suma.
2.2.4 Montón
El montón es un área de memoria importante en la JVM y se utiliza para almacenar instancias de objetos. Está dividido en generaciones jóvenes y mayores para optimizar el rendimiento de la recolección de basura.
Cómo funciona :
Los objetos recién creados se asignan por primera vez a la generación más joven. Con el tiempo, los objetos supervivientes pasan de la generación joven a la generación anterior. La recolección de basura ocurre principalmente entre las generaciones jóvenes, porque la mayoría de los objetos rápidamente se vuelven inalcanzables.
// 示例代码:创建对象
public class HeapSimulation {
public static void main(String[] args) {
Person person = new Person("Alice", 25); // 对象被分配在堆上
}
}
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
}
Explicación del código : el código anterior crea un Personobjeto, que se asigna en el montón.
2.2.5 Área de metadatos
El área de metadatos se utiliza para almacenar metadatos de clases cargadas por la JVM, como nombres de clases, campos y métodos. Esta zona no forma parte del montón y tiene su propia estrategia de recogida de basura.
Cómo funciona :
cuando la JVM carga una clase, almacena los metadatos de la clase en el área de metadatos. Esta área es de tamaño fijo y, si se llena, la JVM activa la recolección de basura para recuperar metadatos de las clases que ya no se utilizan.
// 示例代码:加载类
public class MetadataAreaSimulation {
public static void main(String[] args) throws ClassNotFoundException {
Class<?> clazz = Class.forName("com.example.MyClass"); // 类的元数据被存储在元数据区
}
}
Explicación del código : el código anterior carga una clase y almacena su información de metadatos en el área de metadatos.
2.3 Práctica de ajuste del rendimiento del área de memoria JVM
Comprender las áreas de memoria de la JVM es crucial para ajustar el rendimiento de las aplicaciones Java. Al ajustar el tamaño y los parámetros de estas regiones, podemos optimizar el rendimiento de la aplicación, reducir los tiempos de pausa de la recolección de basura y aumentar el rendimiento del sistema.
2.3.1 Ajuste de la memoria del montón
Caso práctico :
Supongamos que una aplicación web ocurre con frecuencia en situaciones de alta concurrencia OutOfMemoryError. A través del análisis, descubrimos que esto se debía a que la memoria del montón era demasiado pequeña.
Solución :
aumente el tamaño máximo del montón. Por ejemplo, establezca el tamaño máximo del montón en 2 GB:
java -Xmx2g -jar my-web-app.jar
Sugerencias :
- Utilice una herramienta de monitoreo como JVisualVM o JMC para verificar periódicamente el uso del montón.
- Si su aplicación tiene una gran cantidad de objetos efímeros, considere aumentar el tamaño de la generación joven.
- Si su aplicación tiene una gran cantidad de objetos de larga duración, considere aumentar el tamaño de la generación anterior.
2.3.2 Ajuste del área de metadatos
Caso práctico :
una aplicación genera y carga dinámicamente una gran cantidad de clases en tiempo de ejecución. Con el tiempo, la aplicación arrojó OutOfMemoryError: Metaspaceerrores.
Solución :
aumente el tamaño del área de metadatos. Por ejemplo, establezca el tamaño máximo del área de metadatos en 256 MB:
java -XX:MaxMetaspaceSize=256m -jar my-dynamic-app.jar
Sugerencias :
- Si su aplicación utiliza una gran cantidad de servidores proxy dinámicos o CGLIB, considere aumentar el tamaño del área de metadatos.
- Utilice
-XX:MetaspaceSizeparámetros para establecer el tamaño inicial del área de metadatos para evitar una expansión frecuente.
2.3.3 Ajustar la estrategia de recolección de basura
Caso práctico :
una aplicación de comercio en línea a menudo experimenta largas pausas en la recolección de basura en condiciones de alta concurrencia, lo que resulta en una experiencia de usuario degradada.
Solución :
cambie a un recolector de basura de baja latencia como G1 o ZGC:
java -XX:+UseG1GC -jar my-trading-app.jar
Sugerencias :
- Elija el recolector de basura adecuado según las necesidades de su aplicación. Por ejemplo, para aplicaciones de baja latencia, G1 o ZGC pueden ser una buena opción; para aplicaciones de alto rendimiento, Parallel GC puede ser más adecuado.
- Utilice
-XX:GCTimeRatiolos parámetros y-XX:MaxGCPauseMillispara ajustar el comportamiento de la recolección de basura.
3. Mecanismo de recolección de basura JVM
El mecanismo de recolección de basura (GC) de la Máquina Virtual Java (JVM) es un componente central de la administración de la memoria Java. Recicla automáticamente los objetos que ya no se utilizan, liberando así memoria. En esta sección, profundizaremos en el mecanismo de recolección de basura de JVM, incluidos los recolectores de GC comunes, los algoritmos de recolección de basura y las particiones de memoria de JVM.
3.1 Colectores de GC comunes
Java proporciona una variedad de recopiladores de GC, cada uno de los cuales tiene sus ventajas y escenarios de aplicación específicos. Elegir el recopilador adecuado puede mejorar significativamente el rendimiento de su aplicación.
3.1.1 Colector en serie
El recolector en serie es el recolector de GC más simple: funciona en un entorno de un solo subproceso y pausa todos los subprocesos de la aplicación mientras se realiza la recolección de basura.
Ventajas :
- Adecuado para aplicaciones de un solo hilo.
- Debido a que no hay sobrecarga de cambio de subprocesos, generalmente es más rápido que otros recopiladores en entornos de un solo subproceso.
Desventajas :
- No apto para aplicaciones multiproceso ya que puede provocar pausas prolongadas.
// 启用串行收集器
// JVM参数: -XX:+UseSerialGC
3.1.2 Recolector CMS (barrido de marcas concurrente)
El recopilador CMS es un recopilador concurrente que ejecuta las fases de marcado y barrido al mismo tiempo que el subproceso de la aplicación, reduciendo así los tiempos de pausa.
Ventajas :
- Adecuado para aplicaciones con estrictos requisitos de tiempo de respuesta.
- Ejecución concurrente para reducir el tiempo de pausa.
Desventajas :
- Puede resultar en un mayor uso de la CPU.
- Como no comprime, puede provocar fragmentación de la memoria.
// 启用CMS收集器
// JVM参数: -XX:+UseConcMarkSweepGC
3.1.3 Colector paralelo
El recolector paralelo funciona en un entorno de subprocesos múltiples y utiliza múltiples subprocesos durante la recolección de basura.
Ventajas :
- Adecuado para aplicaciones multiproceso.
- Puede aprovechar al máximo las CPU de varios núcleos.
Desventajas :
- Todos los subprocesos de la aplicación se pausan durante la recolección de basura.
// 启用并行收集器
// JVM参数: -XX:+UseParallelGC
3.1.4 Colector G1
El recolector G1 es un recolector orientado a regiones que divide el montón en múltiples regiones y recolecta preferentemente las regiones con mayor cantidad de basura.
Ventajas :
- Los tiempos de pausa se pueden predecir para cumplir con los requisitos de tiempo de respuesta.
- Utilice de manera eficiente CPU de múltiples núcleos y grandes cantidades de memoria.
Desventajas :
- Puede requerir más recursos de CPU.
// 启用G1收集器
// JVM参数: -XX:+UseG1GC
Pregunta de la entrevista: ¿
Cuáles son los dos tipos de GC? ¿Cuál es la diferencia entre GC menor y GC completo? ¿Cuándo se activará Full GC? ¿Qué algoritmos se utilizan?
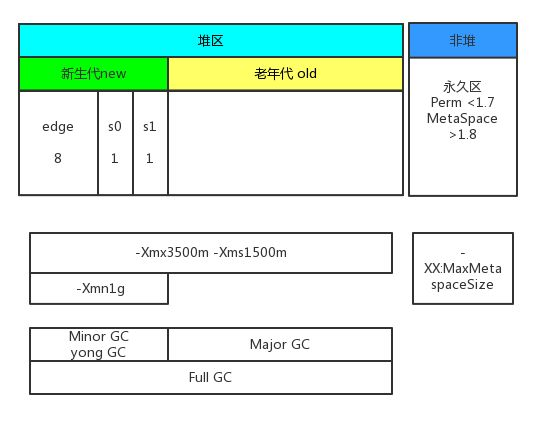
El proceso de desaparición de objetos del área de nueva generación se llama " GC menor "
El proceso de desaparición de objetos del área de la vieja generación se llama " GC mayor "
GC menor
Todo el proceso de limpieza de YouGen, limpieza de eden y limpieza de S0\S1 se deberá a la asignación de MinorGC.
Fallo (memoria insuficiente en el área YoungGen), lo que desencadena minorGC
Mayor GC
La memoria insuficiente en el área OldGen desencadena Major GC
GC completo
La GC completa consiste en limpiar todo el espacio del montón, incluidas la generación joven y la generación permanente.
Escenarios desencadenados por Full GC
1)Sistema.gc
2) la promoción falló (la promoción de generación falló, por ejemplo, los objetos supervivientes en el área del Edén fueron promovidos al área S y no pudieron ser liberados, e intentaron ser promovidos directamente al área Antigua pero no pudieron ser liberados, luego la Promoción Fallar activaría FullGC)
3) Fallo del modo concurrente de CMS
Porque el proceso de reciclaje de CMS se divide principalmente en cuatro pasos: 1.Marca inicial de CMS 2.Marca concurrente de CMS 3.Comentario de CMS 4.Barrido concurrente de CMS. En 2, el hilo gc y el hilo del usuario se ejecutan al mismo tiempo, por lo que el hilo del usuario aún puede generar basura al mismo tiempo. Si hay demasiada basura que no se puede colocar en el espacio reservado, CMS-Mode-Failure ocurrirá. Cambie al subproceso único SerialOld para realizar el barrido de marcas. -compact.
4) El tamaño promedio de la promoción de nueva generación es mayor que el espacio restante de la generación anterior (para evitar el fracaso de la promoción de nueva generación a la generación anterior). Cuando se usa G1 y CMS, FullGC ocurre como Serial + SerialOld . Cuando se usa ParalOld, FullGC aparece como ParallNew + ParallOld.
3.2 Algoritmo de recolección de basura
El algoritmo de recolección de basura determina cómo se identifican y reciclan los objetos que ya no se utilizan. Elegir el algoritmo apropiado puede mejorar la eficiencia de la recolección de basura.
3.2.1 Algoritmo de replicación
El algoritmo de copia divide el montón en dos regiones iguales, utilizando sólo una región a la vez. Cuando esta área se llena, copia los objetos aún activos a otra área y borra el área actual.
Ventajas :
- Sin fragmentación de la memoria.
- Sólo es necesario procesar objetos vivos.
Desventajas :
- La capacidad efectiva del montón se reduce a la mitad.
// 示例代码:复制算法的简化表示
public void copy() {
for (Object obj : fromSpace) {
if (isAlive(obj)) {
toSpace.add(obj);
}
}
fromSpace.clear();
swap(fromSpace, toSpace);
}
Explicación del código : el código anterior simula el principio de funcionamiento básico del algoritmo de replicación. Primero atraviesa fromSpace, copia objetos vivos toSpace, luego limpia fromSpacee intercambia los dos espacios.
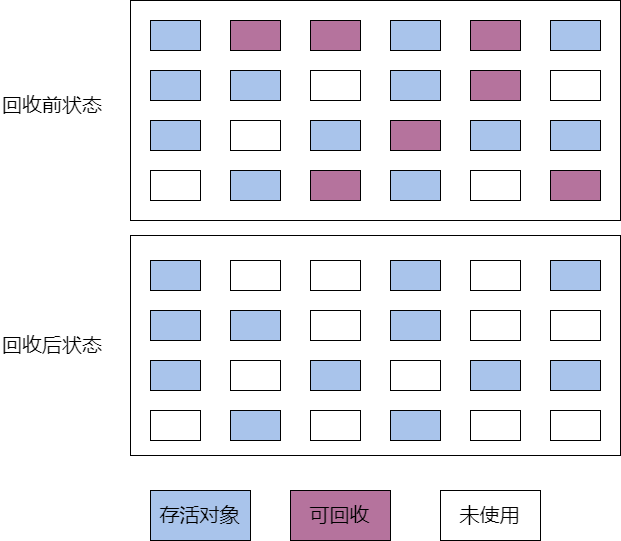
3.2.2 Algoritmo de barrido de marca
El algoritmo de barrido de marcas se divide en dos fases: la fase de marca y la fase de borrado. En la fase de marcado, marca todos los objetos vivos; en la fase de limpieza, borra todos los objetos no marcados.
Ventajas :
- No es necesario mover objetos.
- Cualquier objeto que ya no se utilice se puede reciclar.
Desventajas :
- Puede causar fragmentación de la memoria.
- La fase de purga puede provocar largos tiempos de pausa.
// 示例代码:标记-清除算法的简化表示
public void markAndSweep() {
markAllAliveObjects();
sweepUnmarkedObjects();
}
Explicación del código : el código anterior simula el principio de funcionamiento básico del algoritmo de barrido de marcas. Primero marca todos los objetos activos y luego borra todos los objetos no marcados.
3.2.3 Algoritmo de clasificación y marcado
El algoritmo de marca y barrido es una variante del algoritmo de marca y barrido que agrega una fase limpia entre las fases de marca y barrido. Durante la fase de desfragmentación, mueve todos los objetos supervivientes, eliminando así la fragmentación de la memoria.
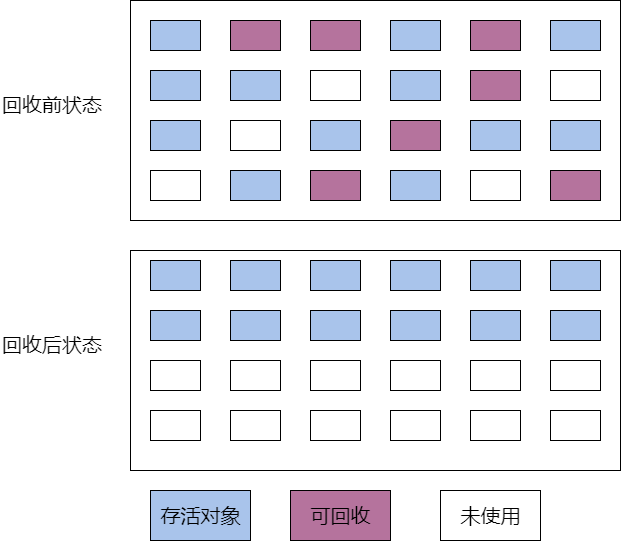
Ventajas :
- Sin fragmentación de la memoria.
- Cualquier objeto que ya no se utilice se puede reciclar.
Desventajas :
- Requiere objetos en movimiento, lo que puede resultar en tiempos más prolongados.
tiempo de pausa.
// 示例代码:标记-整理算法的简化表示
public void markCompact() {
markAllAliveObjects();
compactAliveObjects();
sweepUnmarkedObjects();
}
Explicación del código : el código anterior simula el principio de funcionamiento básico del algoritmo de marcado e intercalación. Primero marca todos los objetos vivos, luego los clasifica y finalmente borra todos los objetos no marcados.
3.3 partición de memoria JVM
La JVM divide la memoria en varias regiones, cada una con su propósito específico y su estrategia de recolección de basura.
3.3.1 Generación joven
La generación joven es parte del montón, que incluye el área de Eden y dos áreas de Survivor. La mayoría de los objetos recién creados se asignan primero al área del Edén. Cuando el área del Edén esté llena, los objetos supervivientes se trasladarán a un área de Superviviente y los objetos que no sobrevivan se reciclarán.
// 示例代码:创建一个新对象
Object obj = new Object();
Explicación del código : el código anterior crea un nuevo objeto, que primero se asigna al área de Eden.
3.3.2 Era antigua
La generación anterior es otra parte del montón que se utiliza para almacenar objetos de larga duración. Cuando un objeto sobrevive el tiempo suficiente en el área de Superviviente, pasará a la generación anterior.
// 示例代码:模拟对象的长时间存活
for (int i = 0; i < 10000; i++) {
Object obj = new Object();
// 使用obj...
}
Explicación del código : el código anterior crea una gran cantidad de objetos y los utiliza. Estos objetos pueden pasar a la generación anterior porque han sobrevivido el tiempo suficiente.
3.3.3 Área de metadatos
El área de metadatos se utiliza para almacenar información de metadatos de las clases cargadas por la JVM, como nombres de clases, campos y métodos. Esta zona no forma parte del montón y tiene su propia estrategia de recogida de basura.
// 示例代码:加载一个类
Class<?> clazz = Class.forName("com.example.MyClass");
Explicación del código : el código anterior carga una clase y almacena su información de metadatos en el área de metadatos.
4. Herramientas JVM y ajuste del rendimiento
La máquina virtual Java (JVM) proporciona una serie de herramientas para ayudar a los desarrolladores a monitorear, diagnosticar y optimizar el rendimiento de las aplicaciones. Estas herramientas nos brindan información profunda que nos permite comprender mejor cómo se comporta nuestra aplicación en tiempo de ejecución. En esta sección, exploraremos en detalle el uso de estas herramientas y su aplicación en el ajuste del rendimiento.
4.1 jmap: herramienta de mapeo de memoria Java
jmapEs una herramienta para generar volcados de montón y mapas de memoria. Nos ayuda a diagnosticar pérdidas de memoria y otros problemas relacionados con la memoria.
4.1.1 Generar un volcado de montón
Un volcado de montón es una instantánea de la memoria JVM, que contiene todos los objetos y sus referencias. Al analizar los volcados de memoria podemos identificar pérdidas de memoria y optimizar el uso de la memoria.
# 生成堆转储
jmap -dump:format=b,file=heapdump.hprof <pid>
Explicación del códigoheapdump.hprof : El comando anterior generará un archivo de volcado de montón con el nombre del ID del proceso especificado .
4.1.2 Ver información de configuración del montón
jmapTambién puede mostrar la información de configuración del montón de JVM, que es útil para ajustar el tamaño del montón y otros parámetros relacionados.
# 查看堆配置信息
jmap -heap <pid>
Explicación del código : el comando anterior mostrará la información de configuración del montón del proceso especificado, incluido el tamaño del montón, el uso y la estrategia de recolección de basura.
4.2 jhat: herramienta de análisis del montón de Java
jhatEs una herramienta para analizar volcados de montón. Puede analizar hprofarchivos y proporcionar una interfaz web para consultar los datos.
4.2.1 Iniciar jhat
# 使用jhat分析堆转储
jhat heapdump.hprof
Explicación del código : el comando anterior iniciará un servidor web, el puerto predeterminado es 7000, puede acceder a él en el navegador http://localhost:7000para ver los resultados del análisis.
4.2.2 Objeto de consulta
jhatProporciona un OOQL (lenguaje de consulta orientado a objetos) simple para consultar objetos. Por ejemplo, puede consultar todos Stringlos objetos o buscar referencias de objetos específicos.
4.3 jstack: herramienta de seguimiento de pila de subprocesos de Java
jstackEs una herramienta para generar seguimientos de pila de subprocesos. Puede ayudarnos a diagnosticar interbloqueos de subprocesos, falta de subprocesos y otros problemas de concurrencia.
4.3.1 Generar seguimientos de pila de subprocesos
# 生成线程堆栈跟踪
jstack <pid>
Explicación del código : el comando anterior generará un seguimiento de la pila de subprocesos para el ID del proceso especificado. Esta información de seguimiento puede ayudarnos a identificar el estado de los subprocesos y las tareas que están realizando.
4.4 jinfo: herramienta de información de configuración de Java
jinfoPuede mostrar y ajustar la configuración de JVM en tiempo de ejecución. Esto es útil para ajustar los parámetros de JVM.
4.4.1 Ver indicadores de JVM
# 查看JVM标志
jinfo -flags <pid>
Explicación del código : el comando anterior mostrará los indicadores JVM del proceso especificado, incluido el tamaño del montón, la estrategia de recolección de basura, etc.
4.4.2 Modificar indicadores JVM
# 修改JVM标志
jinfo -flag +PrintGCDetails <pid>
Explicación del código : el comando anterior habilitará el indicador para el proceso especificado PrintGCDetails, lo que hará que la JVM imprima registros detallados de recolección de basura.
4.5 jps: herramienta de estado del proceso Java
jpsEs una herramienta que muestra información del proceso Java. Puede enumerar todos los procesos Java que se ejecutan en la máquina local.
# 列出所有Java进程
jps -l
Explicación del código : el comando anterior enumerará todos los procesos Java que se ejecutan en la máquina local y sus nombres de clases principales.