El principio básico es permitir que la base de datos maestra maneje las operaciones transaccionales de agregar, modificar y eliminar (INSERT, UPDATE, DELETE), mientras que la base de datos esclava maneja las operaciones de consulta SELECT. La replicación de bases de datos se utiliza para sincronizar los cambios causados por operaciones transaccionales en las bases de datos esclavas del clúster. Si el programa utiliza muchas bases de datos, tiene menos actualizaciones y tiene muchas consultas, se considerará la función de separación de lectura y escritura. Debido a que la operación de "escritura" de la base de datos (puede tardar 3 minutos en escribir 100.000 datos en MySQL) lleva relativamente tiempo, pero la operación de "lectura" de la base de datos (puede que sólo tarde 5 segundos en leer 100.000 datos de MySQL) es relativamente rápido. Por lo tanto, la separación de lectura y escritura puede resolver el problema de afectar la eficiencia de las consultas al escribir en la base de datos.
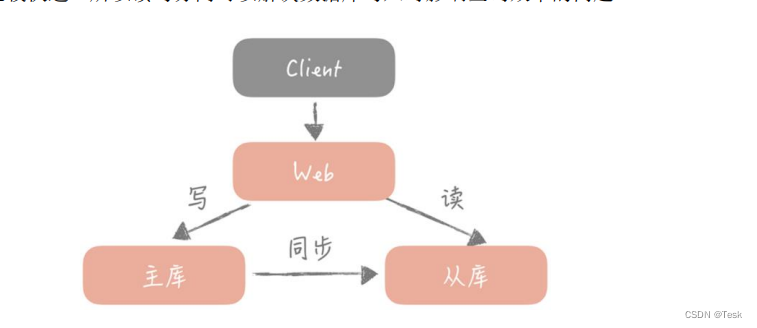
Hay muchas formas de implementar la separación de lectura y escritura, hoy usamos Mycat.
Logre la separación de lectura y escritura a través de Mycat: utilice la función de separación de lectura y escritura proporcionada por Mycat para conectar varias bases de datos. La fuente de datos solo necesita conectarse a Mycat. Para los desarrolladores, todavía está conectado a una base de datos (en realidad, el middleware Mycat de la base de datos) y no es necesario elegir diferentes bibliotecas según los diferentes negocios, por lo que no habrá código redundante.
Presentando Mycat
Con el desarrollo de Internet, la magnitud de los datos también ha crecido exponencialmente, de GB a TB y a PB. Varias operaciones con datos se están volviendo cada vez más difíciles y las bases de datos relacionales tradicionales ya no pueden satisfacer las necesidades de consultas e inserción rápidas de datos. En este momento, la aparición de NoSQL resolvió temporalmente esta crisis. Mejora el rendimiento al reducir la seguridad de los datos, reducir el soporte para transacciones y reducir el soporte para consultas complejas. Sin embargo, hay ocasiones en las que NoSQL no puede cumplir con escenarios de uso, como escenarios donde los indicadores de seguridad y transacciones son absolutamente necesarios. En este momento, todavía necesita utilizar una base de datos relacional. ¿Cómo utilizar una base de datos relacional para resolver el problema del almacenamiento masivo? En este momento, se necesita un clúster de bases de datos. Para mejorar el rendimiento de las consultas, los datos de una base de datos se dispersan en diferentes bases de datos para su almacenamiento. Para solucionar este problema, apareció Mycat. Mycat es actualmente el middleware de base de datos de código abierto más popular basado en el lenguaje Java, es un servidor que implementa el protocolo MySQL y su función principal es subbase de datos y subtabla. Al cooperar con el modo maestro-esclavo de la base de datos, también se puede realizar la función de separación de lectura y escritura. Mycat es una nueva generación de productos de bases de datos de nivel empresarial que combina bases de datos tradicionales y nuevos almacenes de datos distribuidos, puede almacenar grandes cantidades de datos de bases de datos y mejorar el rendimiento de las consultas.

Como se muestra en la imagen de arriba
Mycat utiliza el protocolo de comunicación MySQL para simular un servidor MySQL y establece un modelo lógico completo de esquema (base de datos), tabla (tabla de datos) y usuario (usuario), y asigna este conjunto de modelos lógicos al nodo de almacenamiento back-end. DataNode (Instancia MySQL), de esta manera, todos los clientes y lenguajes de programación que pueden usar MySQL pueden usar Mycat como servidor MySQL sin desarrollar un nuevo protocolo de cliente.
Preparación básica
| IP | nombre de la CPU | nodo |
| 192.168.200.10 | mysql1 | grupo |
| 192.168.200.20 | mysql2 | grupo |
| 192.168.200.30 | mi gato | anfitrión |
1. Configure hosts (mapeo de IP de host) para tres servidores de clúster
vi /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.200.10 mysql1
192.168.200.20 mysql2
192.168.200.30 mycat2. El clúster de la base de datos necesita instalar el servicio de base de datos MariaDB, configurar el archivo fuente de instalación de Yum para la máquina virtual del clúster, usar el archivo gpmall-repo proporcionado para cargarlo en el directorio /opt de la máquina virtual mycat y configurar el Yum local. fuente.
mkdir /opt/centos
mount /dev/cdrom /opt/centos/
mv /etc/yum.repos.d/* /media/
vi /etc/yum.repos.d/local.repo [centos]
name=centos
baseurl=file:///opt/centos
gpgcheck=0
enabled=1
[mariadb]
name=mariadb
baseurl=file:///opt/gpmall-repo
gpgcheck=0
enabled=14. Mycat es desarrollado por Java, por lo que se debe instalar un entorno JDK (la implementación del servicio de middleware Mycat requiere la implementación de JDK 1.7 o una versión superior del entorno de software JDK, y aquí se implementa la versión JDK 1.8).
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel

5. Apague el firewall (cambie las reglas)
iptables -F
iptables -X
iptables -Z
iptables-save #保存防火墙规则2. Implementar el servicio de middleware de separación de lectura y escritura Mycat
1. Instale el servicio Mycat (paquete binario)
Cargue el paquete binario en el directorio /root, descomprímalo en /usr/local y finalmente otorgue permisos al directorio Mycat descomprimido.
tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz -C
/usr/local
chmod -R 777 /usr/local/mycat/Agregue la variable del sistema Mycat en el archivo de variables del sistema y hágala efectiva.
echo export MYCAT_HOME=/usr/local/mycat/ >> /etc/profilesource /etc/profile2. Edite el archivo de edición de la biblioteca lógica de Mycat
El archivo de configuración esquema.xml que configura la separación de lectura y escritura del servicio Mycat se encuentra en el directorio /usr/local/mycat/conf/. Puede definir una biblioteca lógica en el archivo para que los usuarios puedan administrar la base de datos MariaDB correspondiente a la biblioteca lógica a través del servicio Mycat. Defina aquí un esquema de biblioteca lógica, y el nombre es USERDB; la base de datos correspondiente de esta biblioteca lógica USERDB es prueba (ya instalada al implementar la base de datos maestro-esclavo); configure el nodo de escritura de la base de datos como el nodo maestro mysql1; configure la base de datos Nodo de lectura como nodo esclavo mysql2.
vi /usr/local/mycat/conf/schema.xmlNota: La IP debe modificarse a la dirección IP real.
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
8
<schema name="USERDB" checkSQLschema="true" sqlMaxLimit="100"
dataNode="dn1"></schema>
<dataNode name="dn1" dataHost="localhost1" database="test" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" dbType="mysql"
dbDriver="native" writeType="0" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.200.10:3306" user="root"
password="000000">
<readHost host="hostS1" url="192.168.200.20:3306" user="root"
password="000000" />
</writeHost>
</dataHost>
</mycat:schema>Descripción del código:
⚫ sqlMaxLimit: configura el número de consulta predeterminado.
⚫ base de datos: es el nombre real de la base de datos.
⚫ balance="0": el mecanismo de separación de lectura y escritura no está habilitado y todas las operaciones de lectura se envían al writeHost disponible actualmente.
⚫ balance="1": Todos los readHost y stand by writeHost participan en el equilibrio de carga de la declaración de selección. En pocas palabras, cuando el modo dual-master dual-slave (M1->S1, M2->S2 y M1 y M2 están mutuamente activos y en espera), en circunstancias normales, M2, S1 y S2 participan en el equilibrio de carga de la declaración seleccionada.
⚫ balance="2": todas las operaciones de lectura se distribuyen aleatoriamente en writeHost y readhost.
⚫ balance="3": todas las solicitudes de lectura se distribuyen aleatoriamente al readhost correspondiente al escritorHost para su ejecución. El escritorHost no soporta la presión de lectura. Tenga en cuenta que balance=3 solo está disponible en 1.4 y versiones posteriores, pero no en 1.3. versiones.
⚫ writeType="0": Todas las operaciones de escritura se envían al primer writeHost configurado. Si el primero falla, debe cambiar al segundo writeHost superviviente. Prevalecerá el que se haya cambiado después del reinicio. El cambio se registra en el archivo de configuración dnindex.properties.
⚫ writeType="1": todas las operaciones de escritura se envían aleatoriamente al writeHost configurado
3. Modificar los permisos del archivo de configuración.
chown root:root /usr/local/mycat/conf/schema.xml4. Editar el usuario de acceso de mycat
Modifique el archivo server.xml en el directorio /usr/local/mycat/conf/, modifique la contraseña de acceso y la base de datos del usuario raíz, establezca la contraseña en 000000 y use la biblioteca lógica para acceder a Mycat como USERDB.
vi /usr/local/mycat/conf/server.xmlAgregue al final del archivo de configuración:
<user name="root">
<property name="password">000000</property>
<property name="schemas">USERDB</property>Luego borre estas líneas:
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user> 
La primera configuración raíz también debe eliminarse, porque configuró un usuario raíz y no se permite la existencia de dos usuarios raíz. La configuración agregada debe escribirse en </mycat:server>.
Finalmente guardar y salir.
5. Finalmente inicie el servicio Mycat.
/bin/bash /usr/local/mycat/bin/mycat start
Aparecen los puertos 9066 y 8066 y el inicio se realiza correctamente.
3. Verifique la función de separación de lectura y escritura del servicio de clúster de la base de datos.
1 Utilice el servicio Mycat para consultar información de la base de datos
yum install -y MariaDB-client2. Utilice el comando mysql en la máquina virtual Mycat para ver la biblioteca lógica USERDB del servicio Mycat. Debido a que las 10 bibliotecas lógicas USERDB de Mycat corresponden a la prueba de la base de datos (ya instalada al implementar la base de datos maestro-esclavo), puede ver la tabla empresa que se ha creado en la biblioteca.
mysql -h127.0.0.1 -P8066 -uroot -p000000show databases;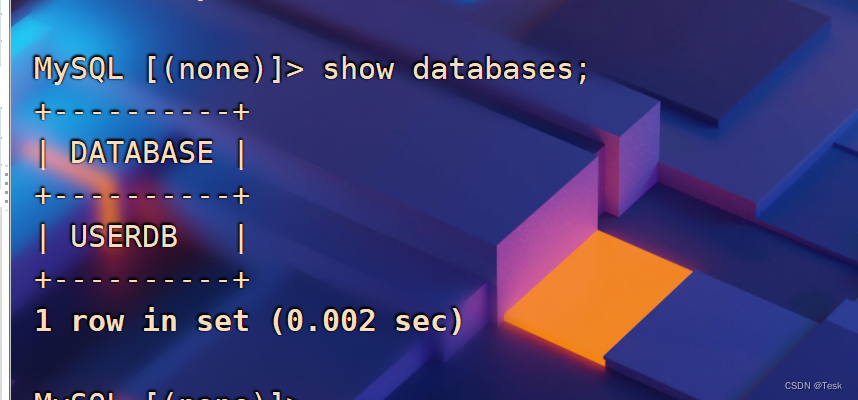
use USERDB #更改数据库
show tables;
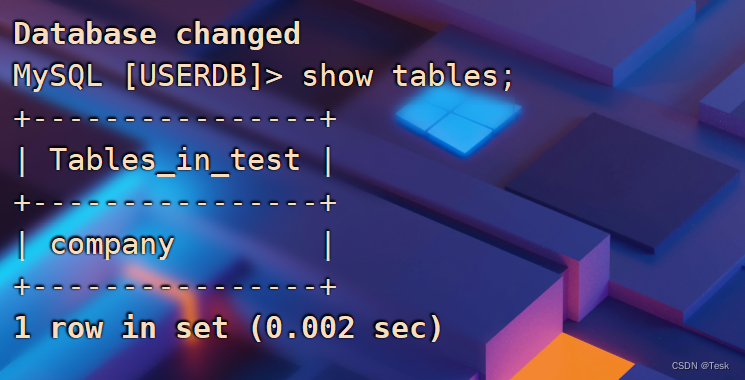
select * from company;
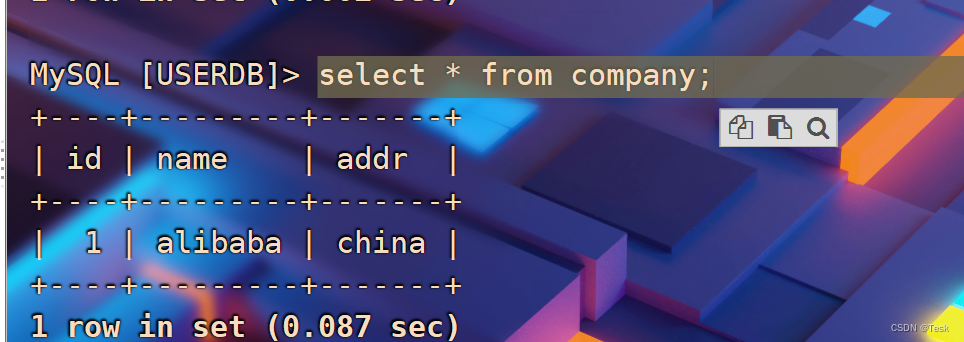
3. Utilice el servicio Mycat para agregar datos de tabla (nodo Mycat)
Utilice el comando mysql en la máquina virtual Mycat para agregar un dato (2, "basketball", "usa") a la tabla de la empresa. Una vez completada la adición, vea la información de la tabla.
insert into company values(2,"bastetball","usa");select * from company;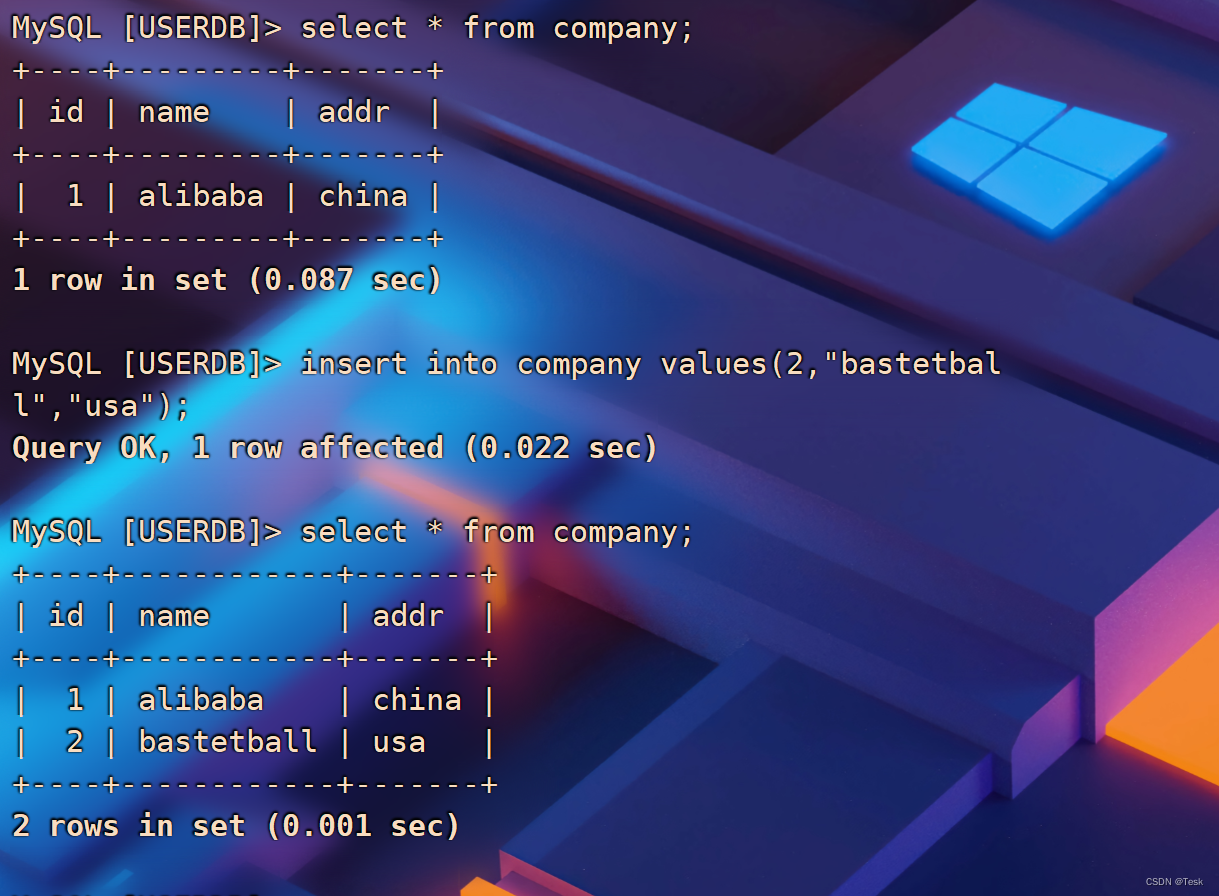
(3) Verifique que el servicio Mycat separe las operaciones de lectura y escritura de la base de datos
Utilice el comando mysql en el nodo de la máquina virtual Mycat para consultar la información de separación de las operaciones de lectura y escritura de la base de datos a través del puerto 9066. Puede ver que todas las operaciones de escritura WRITE_LOAD están en el nodo de la base de datos principal mysql1, y todas las operaciones de lectura READ_LOAD están en el nodo de la base de datos principal mysql2. Se puede ver que las operaciones de lectura y escritura de la base de datos se han separado en los nodos mysql1 y mysql2.
mysql -h127.0.0.1 -P9066 -uroot -p000000 -e 'show @@datasource;'
Se completa la separación de lectura y escritura de Mycat.