Tabla de contenido
1. Introducción a ShardingSphere
3. Cree un proyecto SpringBoot e introduzca dependencias.
4. Agregue configuración a application.properties
5. Cree las clases de entidad correspondientes y use MyBatis-Plus para construir CRUD rápidamente
6. Configuración de la clase de inicio principal
3. Intente crear subbases de datos y subtablas.
1. Cree la base de datos db_device_1. Y crea dos tablas físicas en la base de datos:
2. Ajustar la configuración de la fuente de datos
4. Realizar consultas en subbases de datos y subtablas.
1. Consulta basada en device_id
2. Consulta basada en el rango de device_id
4. Puntos de conocimiento básicos de la subbase de datos y la subtabla
2. Estrategia de fragmentación y fragmentación
3) estrategia de fragmentación
3. Implementación de la estrategia de fragmentación.
1) Fragmentación precisa de la estrategia de fragmentación estándar estándar
2) Fragmentación del alcance de la estrategia de fragmentación estándar estándar.
3) Estrategia de fragmentación compleja
4) Insinuar política de enrutamiento forzado
5. Lograr la separación entre lectura y escritura
1. Cree una base de datos de sincronización maestro-esclavo
2. Utilice sharding-jdbc para lograr la separación de lectura y escritura
6. Principio de implementación: modo de conexión
6.1.1.Modo de memoria limitada
6.1.2 Modo de restricción de conexión
6.2 Motor de ejecución automatizado
1. Introducción a ShardingSphere
Apache ShardingSphere es un ecosistema de soluciones de bases de datos distribuidas de código abierto que consta de JDBC, Proxy y Sidecar (en planificación), tres productos que se pueden implementar de forma independiente y admiten la implementación híbrida y el uso conjunto. Todos proporcionan funciones como expansión horizontal de datos estandarizados, transacciones distribuidas y gobernanza distribuida, y se pueden aplicar a varios escenarios de aplicaciones diversos, como isomorfismo de Java, lenguajes heterogéneos y nativos de la nube.
Apache ShardingSphere tiene como objetivo utilizar completa y razonablemente las capacidades informáticas y de almacenamiento de las bases de datos relacionales en escenarios distribuidos, pero no implementa una nueva base de datos relacional. Las bases de datos relacionales todavía ocupan una enorme cuota de mercado hoy en día y son la base de los sistemas centrales de las empresas. Será difícil deshacerse de ellas en el futuro. Nos centramos más en proporcionar incrementos sobre la base original que en la subversión.
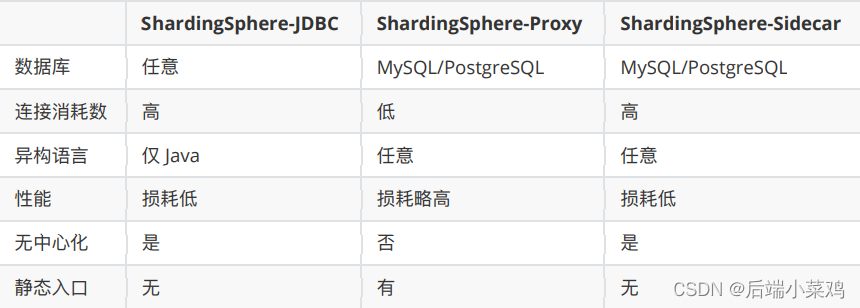
Sitio web oficial: Apache ShardingSphere
2. Inicio rápido (subtabla)
1. Crea una base de datos
Cree una base de datos denominada db_device_0.
2. Crea una mesa física
Lógicamente, tb_device representa una tabla que describe la información del dispositivo. Para reflejar el concepto de subtablas, la tabla tb_device se divide en dos. Entonces tb_device es la tabla lógica, y tb_device_0 y tb_device_1 son las tablas físicas de la tabla lógica.
CREATE TABLE `tb_device_0` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb3;
CREATE TABLE `tb_device_1` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb33. Cree un proyecto SpringBoot e introduzca dependencias.
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>4. Agregue configuración a application.properties
# 配置真实数据源
spring.shardingsphere.datasource.names=ds1
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/db_device_0?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.ds1.username=db_device_0
spring.shardingsphere.datasource.ds1.password=db_device_0
# 配置物理表
spring.shardingsphere.sharding.tables.tb_device.actual-data-nodes=ds1.tb_device_$->{0..1}
# 配置分表策略:根据device_id作为分⽚的依据(分⽚键、分片算法)
# 将device_id作为分片键
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.sharding-column=device_id
# 用device_id % 2 来作为分片算法 奇数会存入 tb_device_1 偶数会存入 tb_device_0
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.algorithm-expression=tb_device_$->{device_id%2}
# 开启SQL显示
spring.shardingsphere.props.sql.show = true
5. Cree las clases de entidad correspondientes y use MyBatis-Plus para construir CRUD rápidamente
package com.my.sharding.shperejdbc.demo.entity;
import lombok.Data;
@Data
public class TbDevice {
private Long deviceId;
private Integer deviceType;
}
6. Configuración de la clase de inicio principal
package com.my.sharding.shperejdbc.demo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
// 配置mybatis扫描的mapper!
@MapperScan("com.my.shardingshpere.jdbc.demo.mapper")
@SpringBootApplication
public class MyShardingShpereJdbcDemoApplication {
public static void main(String[] args) {
SpringApplication.run(MyShardingShpereJdbcDemoApplication.class, args);
}
}7. Escribir pruebas
@SpringBootTest
class MyShardingShpereJdbcDemoApplicationTests {
@Autowired
DeviceMapper deviceMapper;
@Test
void testInitData(){
for (int i = 0; i < 10; i++) {
TbDevice tbDevice = new TbDevice();
tbDevice.setDeviceId((long) i);
tbDevice.setDeviceType(i);
deviceMapper.insert(tbDevice);
}
}
}Ejecute y vea la base de datos:
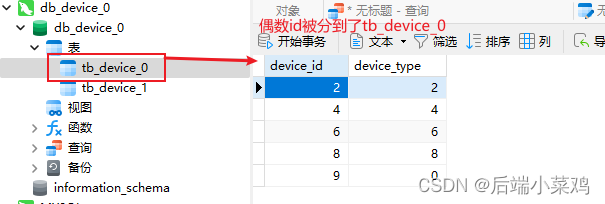
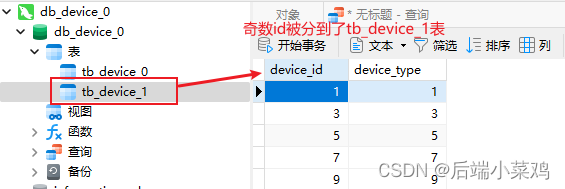
Se descubre que, de acuerdo con la estrategia de fragmentación, los datos con ID impares entre estos 10 datos se insertarán en la tabla tb_device_1, y los datos con ID impares se insertarán en la tabla tb_device_0.
3. Intente crear subbases de datos y subtablas.
1. Cree la base de datos db_device_1. Y crea dos tablas físicas en la base de datos:
CREATE TABLE `tb_device_0` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb3;
CREATE TABLE `tb_device_1` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb32. Ajustar la configuración de la fuente de datos
Proporcione dos fuentes de datos, utilice las dos bases de datos MySQL creadas previamente como fuentes de datos y cree una estrategia de fragmentación.
# 配置真实数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/db_device_0?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.ds0.username=db_device_0
spring.shardingsphere.datasource.ds0.password=db_device_0
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/db_device_1?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.ds1.username=db_device_1
spring.shardingsphere.datasource.ds1.password=db_device_1
# 配置物理表
spring.shardingsphere.sharding.tables.tb_device.actual-data-nodes=ds$->{0..1}.tb_device_$->{0..1}
# 配置分库策略
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=device_id
# ⾏表达式分⽚策略 使⽤Groovy的表达式
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{device_id%2}
# 配置分表策略:根据device_id作为分⽚的依据(分⽚键、分片算法)
# 将device_id作为分片键
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=device_id
# ⾏表达式分⽚策略 使⽤Groovy的表达式
# 用device_id % 2 来作为分片算法 奇数会存入 tb_device_1 偶数会存入 tb_device_0
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.algorithm-expression=tb_device_$->{device_id%2}
# 开启SQL显示
spring.shardingsphere.props.sql.show = true
En comparación con la configuración anterior, esta vez se agregó una estrategia de fragmentación para dos bases de datos y qué base de datos almacenar se determina en función de las características de paridad de device_id. Al mismo tiempo, se utilizaron scripts geniales para determinar la relación entre la base de datos y las tablas.
ds$->{0..1}.tb_device_$->{0..1}Equivalente a:
ds0.tb_device_0
ds0.tb_device_1
ds1.tb_device_0
ds1.tb_device_13. Ejecutar clase de prueba
Resultado: se descubre que los datos impares de device_id se almacenarán en la tabla ds1.tb_device_1 y los datos pares se almacenarán en la tabla ds0.tb_device_0.
4. Realizar consultas en subbases de datos y subtablas.
1. Consulta basada en device_id
/**
* 根据device_id查询
*/
@Test
void testQueryByDeviceId(){
QueryWrapper<TbDevice> wrapper = new QueryWrapper<>();
wrapper.eq("device_id",1);
List<TbDevice> list = deviceMapper.selectList(wrapper);
list.stream().forEach(e->{
System.out.println(e);
});
}Resultado: TbDevice (ID de dispositivo = 1, tipo de dispositivo = 1)
Y la biblioteca consultada es tb_device_1
2. Consulta basada en el rango de device_id
/**
* 根据 device_id 范围查询
*/
@Test
void testDeviceByRange(){
QueryWrapper<TbDevice> wrapper = new QueryWrapper<>();
wrapper.between("device_id",1,10);
List<TbDevice> devices = deviceMapper.selectList(wrapper);
devices.stream().forEach(e->{
System.out.println(e);
});
}resultado:
Error querying database. Cause: java.lang.IllegalStateException: Inline strategy cannot support this type sharding:RangeRouteValue(columnName=device_id, tableName=tb_device, valueRange=[1‥10])Motivo: la estrategia de fragmentación en línea no puede admitir consultas de rango.
4. Puntos de conocimiento básicos de la subbase de datos y la subtabla
1. Conceptos centrales
Antes de comprender la estrategia de fragmentación, primero comprendamos los siguientes conceptos clave: tabla lógica, tabla real, nodo de datos, tabla vinculante y tabla de transmisión.
- tabla lógica
Término general para tablas con la misma lógica y estructura de datos que las bases de datos (tablas) divididas horizontalmente. Ejemplo: los datos del pedido se dividen en 10 tablas según la mantisa de la clave principal, es decir, t_order_0 a t_order_9, y sus nombres de tablas lógicas son t_order.
- mesa real
Una tabla física que realmente existe en la base de datos fragmentada. Es decir, t_order_0 a t_order_9 en el ejemplo anterior.
- nodo de datos
La unidad más pequeña de fragmentación de datos. Consta del nombre de la fuente de datos y la tabla de datos, por ejemplo: ds_0.t_order_0.
- mesa de encuadernación
Se refiere a la tabla principal y a las subtablas con reglas de partición consistentes. Por ejemplo: la tabla t_order y la tabla t_order_item están divididas según order_id, por lo que las dos tablas están vinculadas entre sí. Las consultas de correlación de varias tablas entre tablas vinculadas no tendrán correlaciones de productos cartesianos y la eficiencia de las consultas de correlación mejorará enormemente. Por ejemplo, si el SQL es:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);Cuando la relación de la tabla vinculante no está configurada, suponiendo que la clave dividida order_id enruta el valor 10 al segmento 0 y el valor 11 al primer segmento, entonces el SQL enrutado debe ser 4 y se presentan como productos cartesianos:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);Después de configurar la relación de la tabla vinculante, el SQL de enrutamiento debe ser 2:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);Entre ellos, t_order está en el lado izquierdo de FROM, y ShardingSphere lo usará como la tabla principal de toda la tabla vinculante. Todos los cálculos de enrutamiento solo utilizarán la estrategia de la tabla principal, luego el cálculo de partición de la tabla t_order_item utilizará las condiciones de t_order. Por lo tanto, las claves de partición entre tablas vinculadas deben ser exactamente las mismas.
2. Estrategia de fragmentación y fragmentación
1) clave de fragmentación
El campo de la base de datos utilizado para la fragmentación es el campo clave para dividir horizontalmente la base de datos (tabla). Ejemplo: si la mantisa de la clave primaria del pedido en la tabla de pedidos está dividida en módulo, entonces la clave primaria del pedido es el campo dividido. Si no hay un campo de fragmentación en SQL, se realizará un enrutamiento completo y el rendimiento será deficiente. Además de admitir campos de fragmentación únicos, ShardingSphere también admite fragmentación basada en múltiples campos.
2) Algoritmo de fragmentación
Divida los datos mediante el algoritmo de división, que admite la división entre =, >=, , <, ENTRE e IN. El algoritmo de fragmentación debe ser implementado por los propios desarrolladores de aplicaciones y la flexibilidad que se puede lograr es muy alta. Actualmente, se proporcionan 4 algoritmos de fragmentación. Dado que el algoritmo de fragmentación está estrechamente relacionado con la implementación empresarial, no se proporciona ningún algoritmo de fragmentación incorporado, sino que se extraen varios escenarios a través de estrategias de fragmentación, lo que proporciona una abstracción de nivel superior y proporciona interfaces para que los desarrolladores de aplicaciones las implementen ellos mismos.
- Algoritmo de fragmentación exacto
Corresponde a PreciseShardingAlgorithm, que se utiliza para manejar el escenario de división = e IN usando una sola clave como clave de división. Debe usarse con StandardShardingStrategy.
- Algoritmo de partición de rango
Corresponde al RangeShardingAlgorithm, que se utiliza para manejar el escenario en el que se utiliza una única clave como clave de división ENTRE Y, >, =, <= para realizar la división. Debe usarse con StandardShardingStrategy.
- Algoritmo de fragmentación compuesto
Correspondiente al Algoritmo ComplexKeysSharding, que se utiliza para manejar escenarios en los que se utilizan múltiples claves como claves de fragmentación para la fragmentación. La lógica que contiene múltiples claves de fragmentación es relativamente compleja y los desarrolladores de aplicaciones deben manejar la complejidad por sí mismos. Debe usarse con ComplexShardingStrategy.
- Algoritmo de fragmentación de sugerencias
Corresponde a HintShardingAlgorithm, que se utiliza para manejar escenarios en los que se utiliza Hint para fragmentar. Debe usarse con HintShardingStrategy.
3) estrategia de fragmentación
Contiene la clave de fragmentación y el algoritmo de fragmentación. Debido a la independencia del algoritmo de fragmentación, se extrae de forma independiente. Lo que realmente se puede utilizar para las operaciones de fragmentación es la clave de fragmentación + algoritmo de fragmentación, que es la estrategia de fragmentación. Actualmente, se proporcionan 5 estrategias de fragmentación.
-
Estrategia de fragmentación estándar
Corresponde a StandardShardingStrategy. Proporciona fragmentación para =, >, =, , =, <= en declaraciones SQL. Si RangeShardingAlgorithm no está configurado, BETWEEN AND en SQL se procesará de acuerdo con el enrutamiento completo de la base de datos.
- Estrategia de fragmentación compuesta
Corresponde a ComplexShardingStrategy. Estrategia de fragmentación compuesta. Proporciona soporte para operaciones de división de =, >, =, <=, IN y BETWEEN AND en sentencias SQL. ComplexShardingStrategy admite múltiples claves de fragmento. Debido a la compleja relación entre múltiples claves de fragmento, no realiza demasiada encapsulación, sino que transmite directamente y de forma transparente la combinación de valor de clave de fragmento y el operador de fragmento al algoritmo de fragmentación, completamente implementado por la aplicación. desarrolladores para proporcionar la máxima flexibilidad.
- Estrategia de fragmentación de expresiones de filas
Corresponde a InlineShardingStrategy. Al utilizar expresiones Groovy, brinda soporte para operaciones de división de = e IN en declaraciones SQL, y solo admite claves de división únicas. Para un algoritmo de fragmentación simple, se puede utilizar mediante una configuración simple para evitar el tedioso desarrollo de código Java, como: t_user_$->{u_id % 8} significa que la tabla t_user se divide en 8 tablas según el módulo u_id 8. La tabla Los nombres son t_user_0 a t_user_7.
- Estrategia de fragmentación de sugerencias
Corresponde a HintShardingStrategy. Una estrategia para realizar fragmentación especificando valores de fragmentación a través de Hint en lugar de extraer valores de fragmentación de SQL.
- Sin estrategia de fragmentación
Corresponde a NoneShardingStrategy. Una estrategia no fragmentada.
3. Implementación de la estrategia de fragmentación.
1) Fragmentación precisa de la estrategia de fragmentación estándar estándar
En Estándar, las estrategias de fragmentación estándar se pueden configurar en bases de datos de fragmentación y tablas de fragmentación, respectivamente. Al configurar, debe especificar la clave de división, división precisa o división de rango.
- Configurar la fragmentación precisa de los fragmentos
# 配置分库策略 为 标准分片策略的精准分片
#standard
spring.shardingsphere.sharding.default-databaswe-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.database.MyDataBasePreciseAlgorithm
Es necesario proporcionar una clase de implementación que implemente el algoritmo de segmentación exacta, en la que la lógica de la segmentación exacta pueda tener el mismo significado que la expresión de fila en línea.
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class MyDataBasePreciseAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
*
* 数据库标准分片策略
* @param collection 数据源集合
* @param preciseShardingValue 分片条件
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
// 获取逻辑表明 tb_device
String logicTableName = preciseShardingValue.getLogicTableName();
// 获取分片键
String columnName = preciseShardingValue.getColumnName();
// 获取分片键的具体值
Long value = preciseShardingValue.getValue();
//根据分⽚策略:ds$->{device_id % 2} 做精确分⽚
String shardingKey = "ds"+(value%2);
if(!collection.contains(shardingKey)){
throw new UnsupportedOperationException("数据源:"+shardingKey+"不存在!");
}
return shardingKey;
}
}- Configure la fragmentación precisa de la tabla de fragmentación
# 配置分表策略 为 标准分片策略的精准分片
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.table.MyTablePreciseAlgorithm
Al mismo tiempo, es necesario proporcionar una clase de implementación para el algoritmo de fragmentación preciso para la fragmentación de tablas.
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class MyTablePreciseAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
String logicTableName = preciseShardingValue.getLogicTableName(); // 获取逻辑表名
Long value = preciseShardingValue.getValue(); // 获取具体分片键值
String shardingKey = logicTableName+"_"+(value % 2);
if(!collection.contains(shardingKey)){
throw new UnsupportedOperationException("数据表:"+shardingKey+"不存在!");
}
return shardingKey;
}
}El caso de prueba para realizar consultas precisas basadas en ID antes de realizar la prueba tiene el mismo efecto que antes: consultar una tabla en una determinada base de datos basada en ID
2) Fragmentación del alcance de la estrategia de fragmentación estándar estándar.
- Configurar el rango de fragmentación de la biblioteca de fragmentación
spring.shardingsphere.sharding.default-databaswe-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.database.MyDataBasePreciseAlgorithm
spring.shardingsphere.sharding.default-database-strategy.standard.range-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.database.MyDataBaseRangeAlgorithm
Proporciona una clase de implementación para el algoritmo de consulta de rango.
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.Collection;
public class MyDataBaseRangeAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* 直接返回所有的数据源
* 由于范围查询,需要在两个库的两张表中查。
* @param collection 具体的数据源集合
* @param rangeShardingValue
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return collection;
}
}
- Configurar fragmentación de rango para tablas de fragmentación
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.table.MyTablePreciseAlgorithm
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.range-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.table.MyTableRangeAlgorithm
Proporciona una clase de implementación para el algoritmo de consulta de rango:
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.Collection;
public class MyTableRangeAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return collection;
}
}En este punto, volví a ejecutar el caso de prueba de consulta de rango y descubrí que fue exitoso.
3) Estrategia de fragmentación compleja
@Test
void queryDeviceByRangeAndDeviceType(){
QueryWrapper<TbDevice> queryWrapper = new QueryWrapper<>();
queryWrapper.between("device_id",1,10);
queryWrapper.eq("device_type", 5);
List<TbDevice> deviceList =
deviceMapper.selectList(queryWrapper);
System.out.println(deviceList);
}Problemas con el código de prueba anterior:
Mientras realizamos una consulta de rango en ID_dispositivo, necesitamos hacer una búsqueda precisa basada en el tipo_dispositivo. Descubrimos que también necesitamos verificar tres tablas en dos bibliotecas, pero el tipo_dispositivo impar solo estará en la tabla impar de la biblioteca impar, lo que es redundante en este momento. Múltiples consultas innecesarias.
Para resolver búsquedas múltiples redundantes, puede utilizar la estrategia de fragmentación compleja.
- Estrategia de fragmentación compleja
Admite estrategias de fragmentación para múltiples campos.
# 配置分库策略 complex 传入多个分片键
spring.shardingsphere.sharding.default-database-strategy.complex.sharding-columns=device_id,device_type
spring.shardingsphere.sharding.default-database-strategy.complex.algorithm-class-name=com.sharding.algorithm.database.MyDataBaseComplexAlgorithm
# 配置分表策略 complex 传入多个分片键
spring.shardingsphere.sharding.tables.tb_device.table-strategy.complex.sharding-columns=device_id,device_type
spring.shardingsphere.sharding.tables.tb_device.table-strategy.complex.algorithm-class-name=com.sharding.algorithm.table.MyTableComplexAlgorithm
- Configure la clase de implementación del algoritmo de la biblioteca sucursal.
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.util.ArrayList;
import java.util.Collection;
public class MyDataBaseComplexAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
/**
*
* @param collection
* @param complexKeysShardingValue
* @return 这一次要查找的数据节点集合
*/
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {
Collection<Integer> deviceTypeValues = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("device_type");
Collection<String> databases = new ArrayList<>();
for (Integer deviceTypeValue : deviceTypeValues) {
String databaseName = "ds"+(deviceTypeValue % 2);
databases.add(databaseName);
}
return databases;
}
}- Configurar la clase de implementación del algoritmo de la subtabla
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.util.ArrayList;
import java.util.Collection;
public class MyTableComplexAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {
String logicTableName = complexKeysShardingValue.getLogicTableName();
Collection<Integer> deviceTypeValues = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("device_type");
Collection<String> tables = new ArrayList<>();
for (Integer deviceTypeValue : deviceTypeValues) {
tables.add(logicTableName+"_"+(deviceTypeValue%2));
}
return tables;
}
}prueba:

Sólo consultó la base de datos una vez
4) Insinuar política de enrutamiento forzado
La sugerencia puede forzar el enrutamiento a una determinada tabla en una determinada biblioteca independientemente de las características de la declaración SQL.
# 配置分库策略 ## ⾏表达式分⽚策略 使⽤Groovy的表达式
# inline
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{device_id%2}
Configurar la clase de implementación del algoritmo de sugerencias
import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;
import java.util.Arrays;
import java.util.Collection;
public class MyTableHintAlgorithm implements HintShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Long> hintShardingValue) {
String logicTableName = hintShardingValue.getLogicTableName();
String tableName = logicTableName + "_" +hintShardingValue.getValues().toArray()[0];
if(!collection.contains(tableName)){
throw new UnsupportedOperationException("数据表:"+tableName + "不存在");
}
return Arrays.asList(tableName);
}
}Caso de prueba:
@Test
void testHint(){
HintManager hintManager = HintManager.getInstance();
hintManager.addTableShardingValue("tb_device",0); // 强制指定只查询tb_device_0表
List<TbDevice> devices = deviceMapper.selectList(null);
devices.stream().forEach(System.out::println);
}resultado:

4. Mesa de encuadernación
Primero simulemos la aparición del producto cartesiano.
- Cree tablas tb_device_info_0, tb_device_info_1 para las dos bibliotecas:
CREATE TABLE `tb_device_info_0` (
`id` bigint NOT NULL,
`device_id` bigint DEFAULT NULL,
`device_intro` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;- Configure la estrategia de fragmentación para las tablas tb_device y tb_device_info.
#tb_device表的分⽚策略
spring.shardingsphere.sharding.tables.tb_device.actual-data-nodes=ds$->
{0..1}.tb_device_$->{0..1}
spring.shardingsphere.sharding.tables.tb_device.tablestrategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device.tablestrategy.inline.algorithm-expression=tb_device_$->{device_id%2}
#tb_device_info表的分⽚策略
spring.shardingsphere.sharding.tables.tb_device_info.actual-datanodes=ds$->{0..1}.tb_device_info_$->{0..1}
spring.shardingsphere.sharding.tables.tb_device_info.tablestrategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device_info.tablestrategy.inline.algorithm-expression=tb_device_info_$->{device_id%2}Las claves de partición de ambas tablas son device_id.
- Escribir casos de prueba e insertar datos.
@Test
void testInsertDeviceInfo(){
for (int i = 0; i < 10; i++) {
TbDevice tbDevice = new TbDevice();
tbDevice.setDeviceId((long) i);
tbDevice.setDeviceType(i);
deviceMapper.insert(tbDevice);
TbDeviceInfo tbDeviceInfo = new TbDeviceInfo();
tbDeviceInfo.setDeviceId((long) i);
tbDeviceInfo.setDeviceIntro(""+i);
deviceInfoMapper.insert(tbDeviceInfo);
}
}- El producto cartesiano aparece en la consulta de unión
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.lc.entity.TbDeviceInfo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface DeviceInfoMapper extends BaseMapper<TbDeviceInfo> {
@Select("select a.id,a.device_id,b.device_type,a.device_intro from tb_device_info a left join tb_device b on a.device_id = b.device_id")
public List<TbDeviceInfo> queryDeviceInfo();
}
@Test
void testQueryDeviceInfo(){
List<TbDeviceInfo> tbDeviceInfos = deviceInfoMapper.queryDeviceInfo();
tbDeviceInfos.stream().forEach(System.out::println);
}resultado:
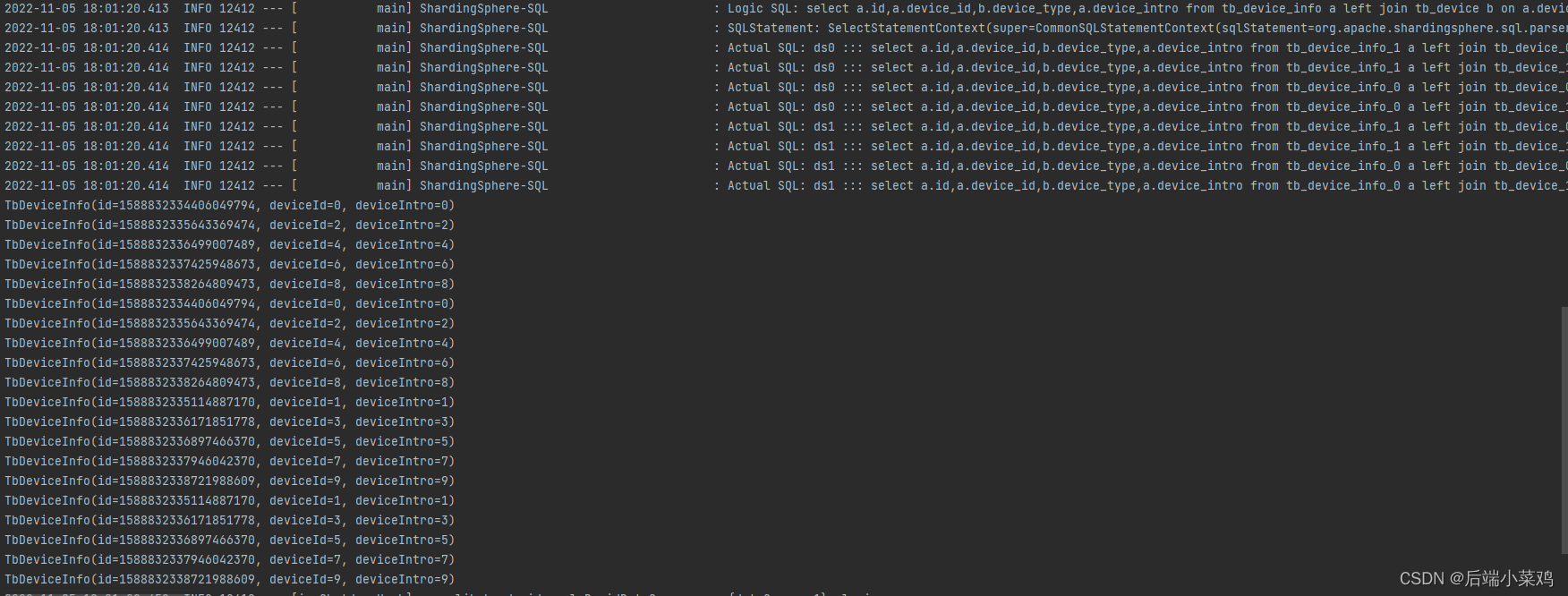
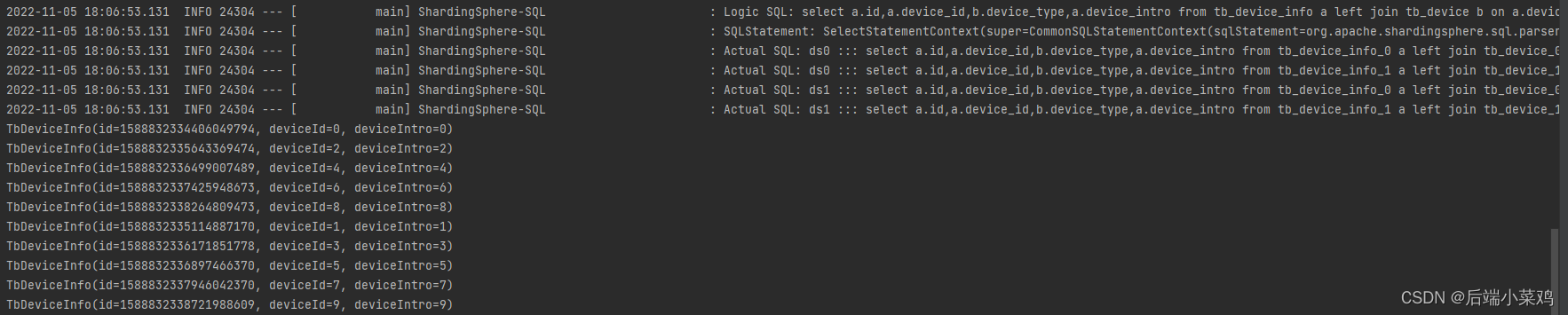
Como puede ver, se generó un producto cartesiano y se encontraron 20 datos.
- Configurar tabla de enlace
# 配置 绑定表
spring.shardingsphere.sharding.binding-tables[0]=tb_device,tb_device_infoVuelve a consultar y no aparece más producto cartesiano:
5. Lista de transmisión
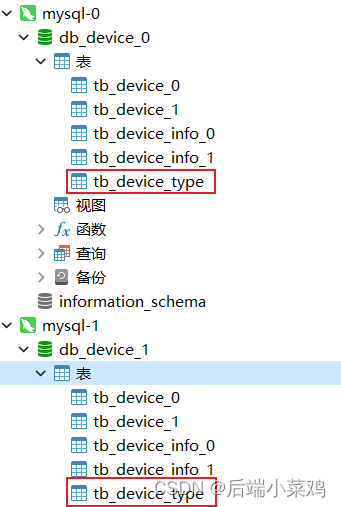
Ahora existe un escenario en el que los datos de la tabla tb_device_type correspondiente a la columna device_type no deben dividirse en tablas. Ambas bibliotecas deben tener la cantidad total de datos en la tabla.
- Cree tablas tb_device_type en ambas bases de datos
CREATE TABLE `tb_device_type` (
`type_id` int NOT NULL AUTO_INCREMENT,
`type_name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`type_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;- Configurar la lista de difusión
#⼴播表配置
spring.shardingsphere.sharding.broadcast-tables=tb_device_type
spring.shardingsphere.sharding.tables.tb_device_type.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.tb_device_type.key-generator.column=type_id- Escribir casos de prueba
@Test
void testInsertDeviceType(){
TbDeviceType tbDeviceType = new TbDeviceType();
tbDeviceType.setTypeId(1l);
tbDeviceType.setTypeName("消防器材");
deviceTypeMapper.insert(tbDeviceType);
TbDeviceType tbDeviceType1 = new TbDeviceType();
tbDeviceType1.setTypeId(2l);
tbDeviceType1.setTypeName("健身器材");
deviceTypeMapper.insert(tbDeviceType1);
}resultado:
Ambos tb_device_types de las dos bibliotecas han insertado dos datos.
5. Lograr la separación entre lectura y escritura
1. Cree una base de datos de sincronización maestro-esclavo
- Principio de sincronización maestro-esclavo
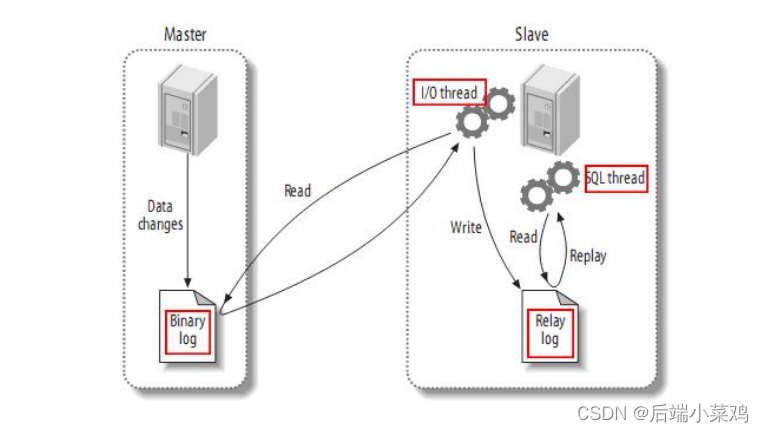
El maestro escribe datos en binlog. El esclavo lee los datos Binlog del nodo maestro en el archivo de registro de retransmisión local. En este momento, el esclavo se sincroniza continuamente con el maestro y los datos existen en el registro de retransmisión en lugar de caer en la base de datos. Entonces Slave inicia un hilo para escribir los datos en el registro de retransmisión en la base de datos.
- Prepare la base de datos maestra y la base de datos esclava
Cree docker-compose.yml en usr/local/docker/mysql y escriba:
version: '3.1'
services:
mysql:
restart: "always"
image: mysql:5.7.25
container_name: mysql-test-master
ports:
- 3308:3308
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 123456
command:
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
--explicit_defaults_for_timestamp=true
--lower_case_table_names=1
--max_allowed_packet=128M
--server-id=47
--log_bin=master-bin
--log_bin-index=master-bin.index
--skip-name-resolve
--sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO"
volumes:
- mysql-data:/var/lib/mysql
volumes:
mysql-data:
version: '3.1'
services:
mysql:
restart: "always"
image: mysql:5.7.25
container_name: mysql-test-slave
ports:
- 3309:3309
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 123456
command:
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
--explicit_defaults_for_timestamp=true
--lower_case_table_names=1
--max_allowed_packet=128M
--server-id=48
--relay-log=slave-relay-bin
--relay-log-index=slave-relay-bin.index
--log-bin=mysql-bin
--log-slave-updates=1
--sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO"
volumes:
- mysql-data:/var/lib/mysql1
volumes:
mysql-data:Comience a usar docker-compose up -d
Presta atención a la configuración:
Biblioteca principal:
ID de servicio: ID de servidor = 47
Habilitar binlog: log_bin=master-bin
binlog索引:log_bin-index=master-bin.index
De la biblioteca:
ID de servicio: ID de servidor = 48
Habilitar registro de retransmisión: retransmisión-log-index=slave-relay-bin.index
Habilitar registro de retransmisión: retransmisión-log=slave-relay-bin
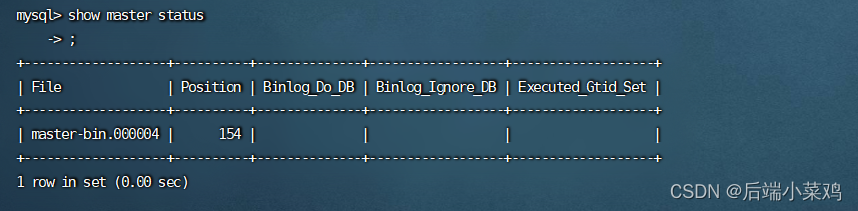
Use el comando bash para ingresar al contenedor de la biblioteca principal y use show master status para ver el nombre del archivo de registro y el desplazamiento.
 Utilice el comando bash para ingresar al contenedor esclavo y ejecute los siguientes comandos en secuencia:
Utilice el comando bash para ingresar al contenedor esclavo y ejecute los siguientes comandos en secuencia:
#登录从服务
mysql -u root -p;
#设置同步主节点:
CHANGE MASTER TO
MASTER_HOST='主库地址',
MASTER_PORT=3306,
MASTER_USER='root',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='master-bin.000006',
MASTER_LOG_POS=154;
#开启slave
start slave;
En este punto, se completa el clúster de sincronización maestro-esclavo.
Cree la base de datos db_device en la biblioteca principal y cree tablas en la biblioteca:
CREATE TABLE `tb_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;Se descubrió que la tabla también se creó sincrónicamente en la base de datos esclava después de la actualización.
2. Utilice sharding-jdbc para lograr la separación de lectura y escritura
- Escribir archivo de configuración
spring.shardingsphere.datasource.names=s0,m0
#配置主数据源
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/db_device?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123456
# 配置从数据源
spring.shardingsphere.datasource.s1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s1.url=jdbc:mysql://localhost:3306/db_device?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.s1.username=root
spring.shardingsphere.datasource.s1.password=123456
# 分配读写规则
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names[0]=s0
# 确定实际表
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ds0.tb_user
# 确定主键⽣成策略
spring.shardingsphere.sharding.tables.t_dict.key-generator.column=id
spring.shardingsphere.sharding.tables.t_dict.key-generator.type=SNOWFLAKE
# 开启显示sql语句
spring.shardingsphere.props.sql.show = true- Prueba de escritura de datos
@Test
void testInsertUser(){
for (int i = 0; i < 10; i++) {
TbUser user = new TbUser();
user.setName(""+i);
userMapper.insert(user);
}
En este momento, todos los datos solo se escribirán en la base de datos maestra y luego se sincronizarán con la base de datos esclava.
- Datos de lectura de prueba
Test
void testQueryUser(){
List<TbUser> tbUsers = userMapper.selectList(null);
tbUsers.forEach( tbUser -> System.out.println(tbUser));
}En este momento, todos los datos se leen de la base de datos esclava.
6. Principio de implementación: modo de conexión
ShardingSphere utiliza un conjunto de motores de ejecución automatizados para enviar de forma segura y eficiente el SQL real después de enrutarlo y reescribirlo a la fuente de datos subyacente para su ejecución. No simplemente envía SQL directamente a la fuente de datos para su ejecución a través de JDBC; ni coloca directamente las solicitudes de ejecución en el grupo de subprocesos para su ejecución simultánea. Presta más atención a equilibrar el consumo causado por la creación de conexiones de fuentes de datos y el uso de memoria, así como a maximizar la utilización razonable de la concurrencia y otros problemas. El objetivo del motor de ejecución es equilibrar automáticamente el control de recursos y la eficiencia de la ejecución.
6.1.Modo de conexión
Desde la perspectiva del control de recursos , el número de conexiones para que los usuarios empresariales accedan a la base de datos debe ser limitado . Puede evitar eficazmente que una determinada operación empresarial ocupe demasiados recursos, agotando así los recursos de conexión de la base de datos y afectando el acceso normal de otras empresas. Especialmente cuando hay muchas tablas de fragmentos en una instancia de base de datos, un SQL lógico que no contiene una clave de fragmento generará una gran cantidad de SQL reales que se encuentran en diferentes tablas en la misma base de datos. Si cada SQL real ocupa un Si hay un conexión independiente, entonces una consulta sin duda ocupará demasiados recursos. ( modo de memoria limitada )
Desde la perspectiva de la eficiencia de la ejecución , mantener una conexión de base de datos independiente para cada consulta de fragmento puede hacer un uso más efectivo de subprocesos múltiples para mejorar la eficiencia de la ejecución. Al abrir un hilo independiente para cada conexión de base de datos, se puede procesar en paralelo el consumo provocado por la E/S . Mantener una conexión de base de datos independiente para cada fragmento también puede evitar cargar prematuramente los datos de los resultados de la consulta en la memoria. Una conexión de base de datos independiente puede contener una referencia a la posición del cursor del conjunto de resultados de la consulta y mover el cursor cuando sea necesario obtener los datos correspondientes . ( Modo de restricción de conexión )
El método de fusionar resultados moviendo el cursor del conjunto de resultados hacia abajo se llama fusión de transmisión . No es necesario cargar todos los datos de resultados en la memoria , lo que puede ahorrar recursos de memoria de manera efectiva y, por lo tanto, reducir la frecuencia de recolección de basura. Cuando no es posible garantizar que cada consulta fragmentada contenga una conexión de base de datos independiente, el conjunto de resultados de la consulta actual debe cargarse en la memoria antes de reutilizar la conexión de la base de datos para obtener el conjunto de resultados de la consulta de la siguiente tabla fragmentada . Por lo tanto, incluso si se puede utilizar la fusión de transmisión, degenerará en fusión de memoria en este escenario.
Por un lado, es controlar y proteger los recursos de conexión de la base de datos, y por otro lado, es adoptar un mejor modo de fusión para ahorrar recursos de memoria de middleware. Cómo manejar la relación entre los dos es lo que necesita el motor de ejecución ShardingSphere. para resolver pregunta. Específicamente, si una parte de SQL necesita operar 200 tablas en una determinada instancia de base de datos después de haber sido dividida por ShardingSphere. Entonces, ¿deberíamos elegir crear 200 conexiones y ejecutarlas en paralelo, o elegir crear una conexión y ejecutarlas en serie? ¿Cómo debemos elegir entre eficiencia y control de recursos?
Para los escenarios anteriores, ShardingSphere proporciona una solución. Propone el concepto de Modo de Conexión y lo divide en dos tipos: modo de restricción de memoria (MEMORY_STRICTLY) y modo de restricción de conexión (CONNECTION_STRICTLY).
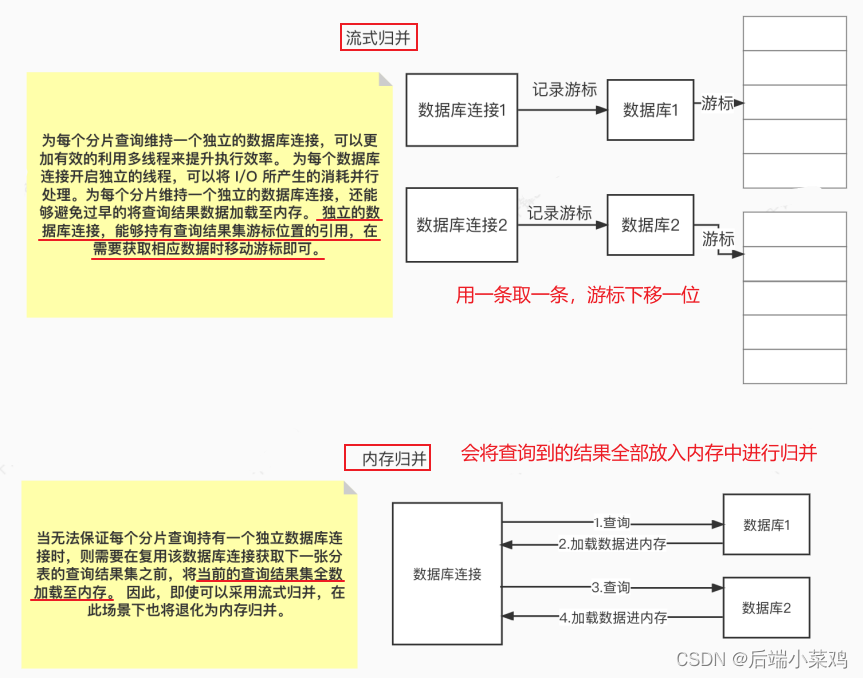
6.1.1.Modo de memoria limitada
La premisa para usar este modo es que ShardingSphere no limita la cantidad de conexiones de bases de datos consumidas por una operación . Si el SQL ejecutado real requiere operaciones en 200 tablas en una instancia de base de datos, cree una nueva conexión de base de datos para cada tabla y procésela simultáneamente a través de subprocesos múltiples para maximizar la eficiencia de la ejecución. Y cuando se cumplen las condiciones de SQL, se prefiere la combinación de transmisión para evitar el desbordamiento de la memoria o la recolección frecuente de basura.
6.1.2 Modo de restricción de conexión
La premisa para usar este modo es que ShardingSphere controla estrictamente la cantidad de conexiones de bases de datos consumidas para una operación . Si el SQL ejecutado real requiere operaciones en 200 tablas en una instancia de base de datos, solo se creará una conexión de base de datos única y las 200 tablas se procesarán en serie. Si los fragmentos de una operación están dispersos en diferentes bases de datos, todavía se utilizan subprocesos múltiples para procesar las operaciones en diferentes bibliotecas, pero cada operación de cada biblioteca solo crea una conexión de base de datos única. Esto puede evitar problemas causados por ocupar demasiadas conexiones de bases de datos para una solicitud. Este modo siempre selecciona la fusión de memoria.
6.2 Motor de ejecución automatizado
ShardingSphere inicialmente deja la decisión de qué modo usar a la configuración del usuario, lo que permite a los desarrolladores elegir usar el modo de memoria limitada o el modo de conexión limitada según los requisitos del escenario real de su propio negocio.
Para reducir los costos de uso del usuario y hacer que el modo de conexión sea dinámico, ShardingSphere refinó la idea de un motor de ejecución automatizado y asimiló internamente el concepto del modo de conexión. Los usuarios no necesitan saber cuáles son los llamados modos de límite de memoria y modos de límite de conexión, pero dejan que el motor de ejecución seleccione automáticamente el plan de ejecución óptimo según el escenario actual.
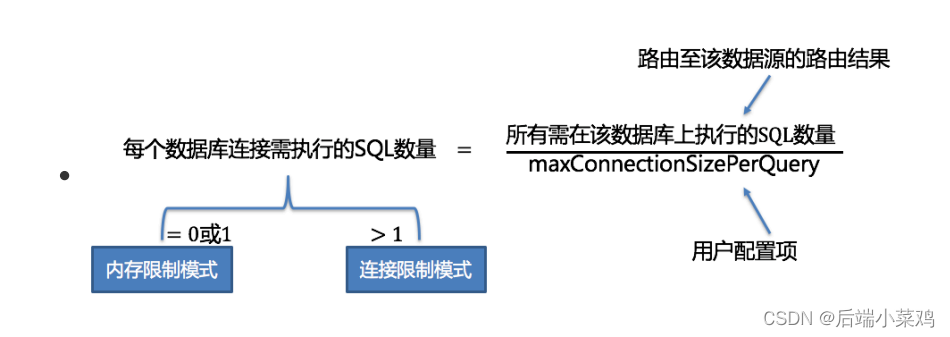
El motor de ejecución automatizada refina la granularidad de selección del modo de conexión para cada operación SQL. Para cada solicitud SQL, el motor de ejecución automatizada realizará cálculos y compensaciones en tiempo real en función de los resultados de su enrutamiento, y los ejecutará de forma autónoma utilizando el modo de conexión apropiado para lograr el equilibrio óptimo entre control de recursos y eficiencia. Para motores de ejecución automatizada, los usuarios solo necesitan configurar maxConnectionSizePerQuery Este parámetro indica el número máximo de conexiones permitidas para cada base de datos durante una consulta.
Dentro del rango permitido por maxConnectionSizePerQuery , cuando el número de solicitudes que una conexión necesita realizar es mayor que 1, significa que la conexión de base de datos actual no puede contener el conjunto de resultados de datos correspondiente y se debe utilizar la fusión de memoria ; por el contrario, cuando un Cuando el número de solicitudes que la conexión debe ejecutar es igual a 1, lo que significa que la conexión de la base de datos actual puede contener el conjunto de resultados de datos correspondiente y se puede utilizar la fusión de transmisión . Cada selección de modo de conexión es específica de cada base de datos física. En otras palabras, en la misma consulta, si se enruta a más de una base de datos, el modo de conexión de cada base de datos no es necesariamente el mismo y pueden existir de forma mixta. (Cuando maxConnectionSizePerQuery establecido por el usuario / el número de todos los SQL que deben ejecutarse en la base de datos es igual a 0 o 1, se utilizará el modo de límite de memoria . Si es mayor que 1 , el modo de límite de conexión será usado )