
En las pruebas de software, a menudo nos encontramos con dos problemas (dificultades) básicos:
Es difícil garantizar que no se perderán pruebas: hemos realizado muchas pruebas, pero no sabemos cómo irán y no tenemos confianza en que habrá problemas después de que el software esté en línea;
Seleccionar casos de prueba a ejecutar: Ante una gran cantidad de casos de prueba de regresión, no tenemos tiempo suficiente para completar la prueba ¿Cómo seleccionar casos de prueba efectivos? Aunque tendremos algunas estrategias, como estrategias de prueba basadas en riesgos, estrategias de prueba basadas en perfiles operativos o estrategias de prueba combinadas, se basan principalmente en la experiencia de los evaluadores y son relativamente subjetivas.
La gente intentó resolver problemas tan básicos, lo que dio lugar a "pruebas de precisión". Bajo el modelo de desarrollo ágil, el ritmo de desarrollo se acelera y los recursos de prueba son menores que antes. Este problema es más prominente, por lo que prestamos más atención a las "pruebas precisas".
1. ¿Qué son las pruebas de precisión?
Las pruebas precisas consisten en responder a dos preguntas básicas a través de datos: ¿qué se mide y qué se va a medir? Es decir, las pruebas precisas utilizan algoritmos, medios técnicos y herramientas específicos para analizar el código, los procesos de ejecución del programa, los casos de prueba, etc., y las relaciones. entre ellos, obteniendo así información y conocimientos relevantes, posicionando y optimizando con precisión el alcance de la prueba (como simplificando los casos de prueba) y utilizando datos precisos para evaluar los resultados de las pruebas y la calidad del producto, haciendo que todo el proceso de prueba sea más eficiente, preciso y creíble, al tiempo que reducir eficazmente los riesgos de pruebas perdidas y minimizar los costos de las pruebas.
Las pruebas precisas son una tendencia importante en la construcción inteligente de la ingeniería de calidad y también son la encarnación de las pruebas de software digital: nos permiten comprender claramente el proceso de prueba y lograr los objetivos de prueba cuantitativos que necesitamos (como la cobertura de la prueba).
2. Método de implementación de prueba preciso
En principio, lograr pruebas precisas es relativamente sencillo: la clave es lograr dos tareas básicas:
Puede completar un análisis eficaz de la dependencia del código e incluso extenderse al análisis de la dependencia empresarial, de modo que pueda identificar de forma correcta y precisa el alcance del código afectado por cada modificación del código. El alcance del impacto del código puede ser preciso en métodos de clase, niveles de función o bloques de código;
Establezca una relación de mapeo entre el código y los casos de prueba, de modo que los casos de prueba que deben ejecutarse puedan recomendarse en función del alcance del impacto identificado.
Si desea establecer una relación de mapeo entre el código y los casos de prueba, o evaluar los efectos de las pruebas precisas, generalmente utilizará el análisis de cobertura de código para comprender mejor qué códigos ejecutan los casos de prueba y para aclarar aún más qué códigos están cubiertos durante ejecución de prueba. , qué códigos no están cubiertos en la ejecución de prueba, etc.
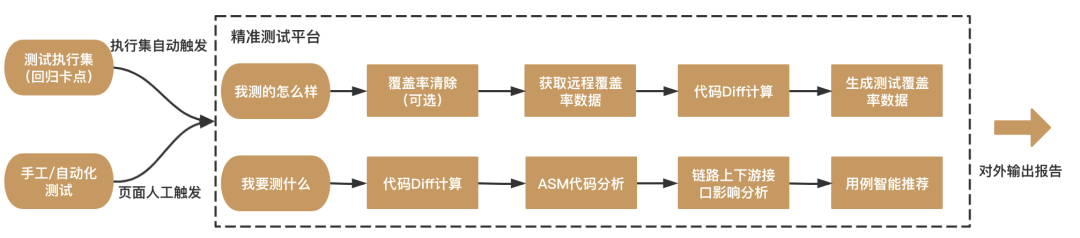
3. Práctica de pruebas precisa
En la práctica de una implementación de pruebas precisa, es necesario utilizar algunas herramientas de código abierto o desarrollar algunas plataformas usted mismo para lograr las dos tareas básicas anteriores. Por ejemplo, puede usar la plataforma de monitoreo de cobertura de código para recopilar datos de cobertura de código dinámico cuando el programa se está ejecutando y crear una base de conocimiento de casos de uso basada en esto; use el JVM-sandbox de código abierto (https://github.com/ alibaba/jvm-sandbox) puede registrar condiciones reales de funcionamiento del sistema (es decir, registro de tráfico).
También habrá diferentes tratamientos para casos de prueba ejecutados manualmente y scripts de prueba automatizados. Por ejemplo, la grabación de casos de prueba ejecutada manualmente utilizará el SDK integrado en el cliente para proporcionar una interfaz de usuario para que los usuarios realicen operaciones de grabación y completen la limpieza, recopilación e informes de datos, y luego los analicen en tiempo real en el servidor. Los scripts de prueba automatizados son relativamente simples: se pueden ejecutar uno por uno para recopilar datos de cobertura y es fácil establecer la relación entre el código y los casos de uso.
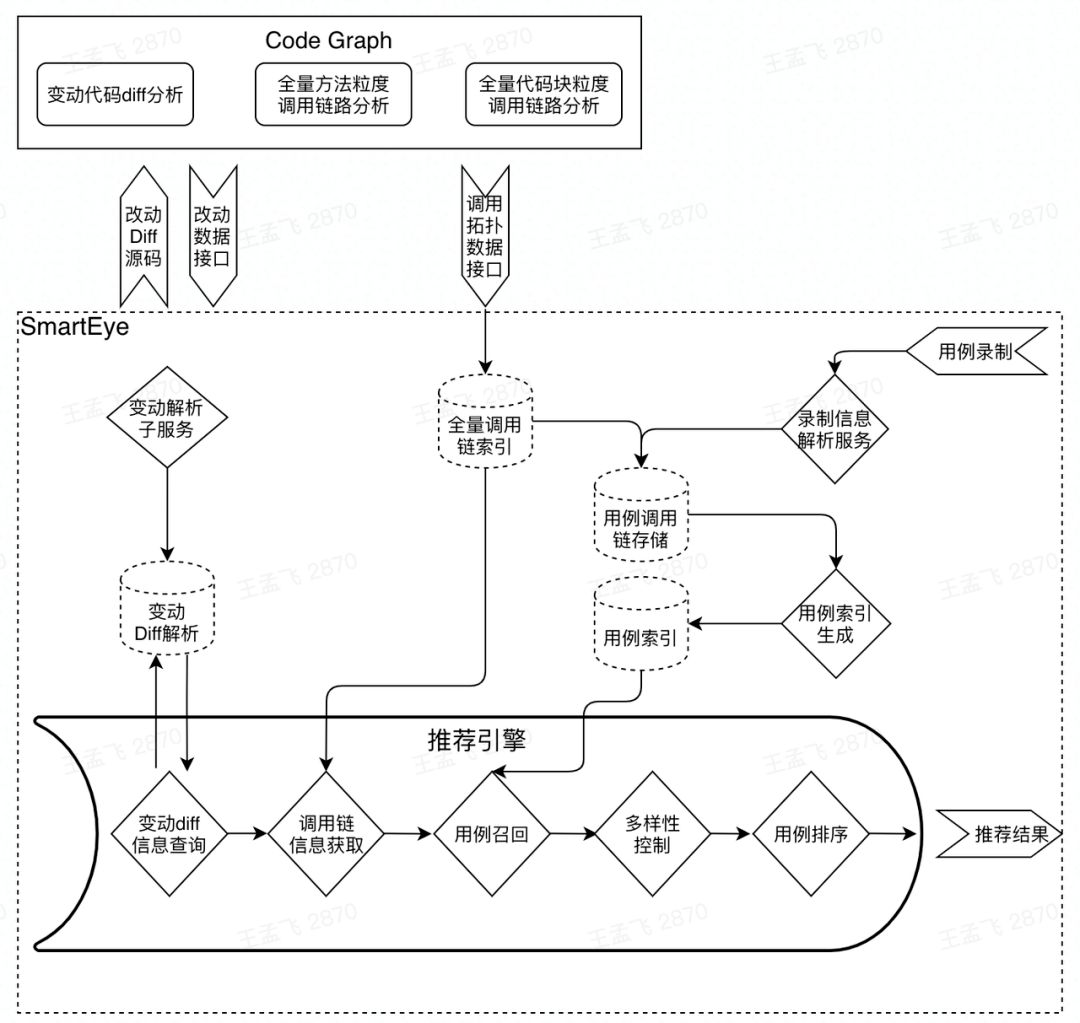
El análisis de dependencia a nivel de código también se puede extender al análisis de la cadena de llamadas, porque la información recopilada cuando el programa se está ejecutando puede reflejar más fielmente la relación de llamada (dependencia) del código, al igual que cuando hacemos análisis de dependencia del código. pasar del código fuente al código de bytes binario compilado puede reflejar más fielmente la relación de llamada al método/bloque de código.
Además, necesitamos crear un índice para el ID del caso de uso para mejorar la eficiencia de la recomendación de casos de uso. Según el método asociado (o bloque de código) del caso de uso, los enlaces de llamadas ascendentes y descendentes y la cobertura correspondiente, creamos diferentes versiones de información de llamadas con diferentes granularidades y proporcionamos servicios de índice de casos de prueba, servicios de recuperación de casos de uso, etc.
En la era actual de IA predominante, naturalmente podemos introducir gráficos de conocimiento y algoritmos de aprendizaje automático para optimizar aún más el efecto de las pruebas precisas. Por ejemplo:
La estructura de dependencia del código se puede almacenar a través de un gráfico, como una estructura como "(el código pertenece al paquete)-[incluir]->(archivo)-[incluir]->(función)-[llamar]->(función )". Después de obtener los datos originales de la cadena de llamadas del proyecto, recorremos profundamente cada enlace de llamada para recopilar la relación correspondiente de cada paquete, archivo, función, así como la ruta, ubicación, parámetros de entrada y salida, comentarios y código. líneas y otra información;
Puede recopilar además el peso de la "cadena de llamadas de función de caso de uso" para recomendar casos de uso basados en el peso;
De acuerdo con la similitud de los casos de uso, se pueden excluir algunos casos de uso con alta similitud, como segmentar todos los casos de uso, establecer un vocabulario, usar el método tf-idf para calcular la similitud de texto entre los casos de uso y usar GCN (gráfico neuronal convolucional). red) para calcular la similitud de casos de uso.
4. Preguntas frecuentes
P1: ¿Cómo construir un sistema de prueba preciso de 0 a 1?
R1: Puede comenzar basándose en la pila de tecnología Java y las herramientas correspondientes y derrotarlas una por una. Comience con el análisis de cobertura y el desarrollo para comprender la efectividad de los casos de prueba y mejorar la calidad y eficiencia de los casos de prueba; luego realice un análisis de dependencia del código, use Code diff para comprender el alcance de la influencia del código y establezca lentamente la relación entre el código y los casos de prueba. Las dependencias pueden lograr pruebas más precisas y efectivas; finalmente, avanzar hacia un enfoque totalmente automatizado para construir un sistema de pruebas eficiente y preciso, es decir, completar la construcción de la base de conocimiento del código y la base de conocimiento de casos de uso, completar el registro del tráfico y el análisis automático. de cadenas de llamadas, la construcción de plataformas de herramientas como recomendación automática y recuperación de casos de uso.
P2: ¿Puede proporcionar un plan de prueba preciso, completo, detallado y reutilizable? ¿Quiere saber más sobre qué herramientas de código abierto se pueden utilizar para crear esta plataforma de prueba precisa? ¿Cómo formar una cadena de herramientas que pueda respaldar la implementación rápida de pruebas precisas?
A2:: ByteDance y Youkudu presentados anteriormente han implementado soluciones de implementación completas, que gracias a las dos capacidades básicas de recopilación de tráfico y análisis de código, la recopilación de tráfico se puede realizar en base al JVM-sandbox de código abierto, aunque requiere un desarrollo secundario. Para el análisis de código, por un lado, puede usar la herramienta de diferenciación de código para comprender los cambios de código; por otro lado, puede usar herramientas AST (Babel, jscodeshift, esprima, recast, acorn, estraverse, etc.), análisis de cobertura. herramientas (como JaCoCo) y análisis de dependencia de Java (JDA) + jdeps propios de Java y otras soluciones para el análisis de dependencia de código.
P3: ¿Cómo lograr pruebas precisas de 1 a N y lograr una replicación a gran escala por parte de un equipo?
R3: Una vez que se crea un sistema de prueba preciso (plataforma), es relativamente fácil promoverlo en función de los beneficios de utilizar el equipo, porque los beneficios son obvios, especialmente cuando se ejecutan pruebas precisas de forma totalmente automatizada, y también se pueden coordinar. con algunas reglas y procesos unificados y, lo que es más importante, la plataforma de pruebas de precisión debe estar perfectamente conectada con la plataforma de I + D de la empresa. Idealmente, debería integrarse de manera flexible con la canalización de CI/CD, permitiendo que el equipo la use sin ningún problema.
P4: Las pruebas precisas solo se pueden utilizar para la regresión. ¿Cómo habilitar pruebas de nuevas funciones?
R4: Debido a que los casos de prueba de regresión aumentan constantemente y alcanzarán un nivel enorme, el costo de la regresión completa es muy alto. Al mismo tiempo, la cantidad de código nuevo/modificado es relativamente pequeña y el alcance del impacto es limitado. No es necesario ejecutar todos los casos de prueba de regresión. Seleccionar casos de uso según la experiencia provocará pruebas perdidas, por lo que es muy necesario realizar pruebas precisas. Las nuevas funciones son relativamente limitadas y es necesario ejecutar casos de prueba escritos para nuevas funciones, por lo que generalmente no hay necesidad de una estrategia de "pruebas precisas". Sin embargo, con la ayuda de una plataforma de pruebas precisa, se puede lograr una mejor cobertura de las pruebas y mejorar la calidad de los casos de prueba y la idoneidad de los resultados de las pruebas. Además, la nueva función será la función anterior en la próxima iteración y los casos de prueba escritos para ella también se convertirán en casos de prueba de regresión. Por lo tanto, la nueva función también debe ejecutarse en la plataforma de prueba precisa para obtener información sobre el código. y casos de prueba, y mejorar la base de conocimiento del código y el conocimiento de los casos de uso.
Finalmente me gustaría agradecer a todos los que leyeron atentamente mi artículo, la reciprocidad siempre es necesaria, aunque no es algo muy valioso, si puedes usarlo, puedes tomarlo directamente:

Esta información debería ser el almacén de preparación más completo y completo para los amigos [de pruebas de software]. Este almacén también ha acompañado a decenas de miles de ingenieros de pruebas en el viaje más difícil. ¡Espero que también pueda ayudarlo a usted!