I. Introducción
A medida que el campo de la inteligencia artificial continúa desarrollándose, la tecnología de procesamiento del lenguaje natural (PNL) continúa avanzando. En los últimos años, el revolucionario modelo de lenguaje grande (LLM) se ha convertido en una parte importante de la tecnología de PNL. Como tecnología que puede comprender y generar texto similar a un humano, LLM ha desempeñado un papel importante en tareas como la traducción automática, el análisis de sentimientos, los chatbots y la generación de contenido.
En este mundo donde el idioma es el puente, LLM tiene perspectivas de aplicación ilimitadas y la plataforma de innovación LangChain es un medio importante para utilizar plenamente el potencial de LLM. En este artículo, exploraremos las maravillas de LLM y presentaremos cómo usar LangChain para crear aplicaciones basadas en LLM.
2. Introducción
2.1 ¿Qué es el LLM?
LLM, o Large Language Model, es un modelo de lenguaje entrenado utilizando tecnología de aprendizaje profundo. Puede comprender y generar texto similar al humano entrenando con grandes cantidades de datos de texto, lo que la convierte en una herramienta poderosa para una variedad de aplicaciones. El objetivo principal de LLM es aprender y comprender con precisión el lenguaje humano para que las computadoras puedan entender y generar lenguaje de la misma manera que lo hacemos los humanos. La aparición y desarrollo de esta tecnología ha cambiado por completo la forma en que las computadoras entienden y generan el lenguaje humano. Actualmente, uno de los ejemplos más famosos de LLM es el modelo GPT de OpenAI, que ha recibido amplia atención y elogios por sus increíbles capacidades de generación de lenguaje. Además de la generación de textos, la traducción de idiomas, el análisis de sentimientos y otras aplicaciones, LLM también tiene una amplia gama de perspectivas de aplicación y desempeñará un papel cada vez más importante en el campo del procesamiento del lenguaje natural en el futuro.
2.2 ¿Qué es LangChain?
LangChain es una biblioteca Python de código abierto que proporciona a los desarrolladores las herramientas para crear aplicaciones impulsadas por modelos de lenguaje grandes (LLM). Más específicamente, LangChain es una herramienta de orquestación de mensajes que facilita a los desarrolladores vincular interactivamente diferentes mensajes.
LLM (como GPT-3) proporciona la finalización de una única pista; puede considerarlo como obtener el resultado completo de una única solicitud. Por ejemplo, puedes decir "prepárame un pastel" y LLM hará un pastel. También puedes emitir comandos más complejos como "Horneame un pastel de vainilla con glaseado de chocolate" y LLM también puede devolver dicho pastel.
Pero, ¿qué pasa si preguntas: “Dame los ingredientes que necesito para hornear un pastel y los pasos para hornearlo”? (Esto no sucede con LLM, pero sí con ChatGPT).
Para evitar que el usuario dé cada paso manualmente y determine el orden de ejecución, podemos usar LLM para generar el siguiente paso en cada punto y usar el resultado del paso anterior como contexto.
En resumen, LangChain es un marco que puede orquestar una serie de indicaciones para lograr el resultado deseado. Proporciona una forma fácil de usar para que los desarrolladores trabajen con LLM. En términos simplificados, LangChain es un contenedor que utiliza LLM.
2.3 ¿Qué es LangSmith?
LangSmith es una plataforma para crear aplicaciones LLM de nivel de producción. Le permite depurar, probar, evaluar y monitorear cadenas y agentes inteligentes creados en cualquier marco LLM y se integra perfectamente con LangChain, el marco de código abierto preferido creado con LLM.
2.4 LangChain LLM y otros modelos de lenguaje
La siguiente comparación destaca principalmente las características únicas y las diferencias funcionales entre LangChain LLM y otros modelos de lenguajes grandes convencionales:
-
Memoria : algunos LLM tienen mala memoria, lo que a menudo resulta en una pérdida de contexto si el mensaje excede los límites de memoria. LangChain proporciona indicaciones y respuestas de chat previas, lo que resuelve el problema de las limitaciones de memoria. El historial de mensajes de respuesta permite al usuario repetir mensajes anteriores al LLM para revisar el contexto anterior.
-
Cambio de LLM : en comparación con otros LLM que bloquean el software en una API de modelo único, LangChain proporciona una abstracción que simplifica el cambio de LLM o la integración de múltiples LLM en su aplicación. Esto es útil cuando desea actualizar la funcionalidad del software con modelos compactos como StableLM de Stability AI en GPT-3.5 de OpenAI.
-
Integración : integrar LangChain en su aplicación es fácil en comparación con otros LLM. Proporciona flujos de trabajo de canalización a través de cadenas y servidores proxy, lo que le permite integrar rápidamente LangChain en sus aplicaciones. En el caso de tuberías lineales, una cadena es esencialmente un objeto que conecta múltiples componentes. Los proxies son más avanzados y le permiten elegir cómo interactúan los componentes utilizando la lógica empresarial. Por ejemplo, es posible que desee utilizar lógica condicional para determinar la siguiente acción en función de los resultados del LLM.
-
Transferencia de datos : debido a la naturaleza generalmente basada en texto de LLM, pasar datos al modelo suele ser complicado. LangChain resuelve este problema mediante el uso de índices. Los índices permiten que las aplicaciones importen datos en un formato variable y almacenen los datos de manera que puedan entregarse a LLM fila por fila.
-
Respuesta : LangChain proporciona una herramienta de análisis de resultados que brinda la respuesta en un formato adecuado, a diferencia de otros modelos LLM donde la respuesta consiste en texto general. Cuando se utiliza inteligencia artificial en una aplicación, es mejor tener una respuesta estructurada que pueda programarse.
3. Configurar LangChain
A continuación, practicaremos cómo implementar LangChain en un escenario de aplicación real para comprender su principio de funcionamiento. Antes de comenzar el desarrollo, debe configurar un entorno de desarrollo.
3.1 Configurar el entorno de desarrollo
Primero, cree un entorno virtual e instale las siguientes dependencias:
-
OpenAI: integre la API GPT-3 en sus aplicaciones.
-
LangChain: integre LangChain en su aplicación.
Usando pip, ejecute el siguiente comando para instalar dependencias:
pip install langchain openai
3.2 Importar bibliotecas necesarias
import langchain
import openai
import os
import IPython
from langchain.llms import OpenAI
from dotenv import load_dotenv
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import LLMChain
from langchain.chains import RetrievalQA
from langchain import ConversationChain
load_dotenv()
# 配置OpenAI Key
openai.api_key = os.getenv("OPENAI_API_KEY")
4. Utilice LangChain LLM para desarrollar aplicaciones
El uso de LangChain LLM para tareas de generación y comprensión de texto requiere una serie de pasos. A continuación se muestra una explicación detallada y la implementación del código de cada parte.
4.1 Inicializar LLM
Primero necesitas importar las bibliotecas y dependencias necesarias.
from langchain import LangModel
# 指定要使用的语言模型
model_name = 'gpt3'
# 初始化 LLM
llm = LangModel(model_name)
4.1.1 Mensajes de entrada
Después de inicializar LLM, puede ingresar indicaciones para generar texto u obtener respuestas. Las sugerencias son el punto de partida para que los modelos de lenguaje generen texto. Puede proporcionar un único mensaje o varios mensajes según sus requisitos:
# 输入单个提示
prompt = "请按李白的风格为鲁迅写一首诗"
# 从前面的提示生成文本
generated_text = llm.generate_text(prompt)
4.1.2 Recuperar el texto o respuesta generada
Después de ingresar el mensaje, puede recuperar el texto generado o la respuesta de LLM. El texto o respuesta generado se basará en el contexto proporcionado por el mensaje y las capacidades del modelo de lenguaje:
# 打印生成的文本
print(generated_text)
# 打印回复
for response in responses:
print(response)
Si sigue estos pasos e implementa el código correspondiente, puede utilizar LangChain para interactuar sin problemas con LLM previamente capacitados y aprovechar sus capacidades para una variedad de tareas de generación y comprensión de texto.
5. ¿Introducción a los componentes de LangChain?
La diversidad funcional de LangChain ofrece a los desarrolladores una amplia gama de posibilidades para explorar y utilizar en sus aplicaciones. Profundicemos en los componentes clave de LangChain y comprendamos lo que cada componente puede lograr.
Los principales componentes admitidos en LangChain son los siguientes:
-
Modelos : varios tipos de modelos e integraciones de modelos, como ChatGPT de OpenAI.
-
Indicaciones : Gestión de indicaciones, optimización de indicaciones y serialización de indicaciones, afinando la comprensión semántica del modelo a través de indicaciones.
-
Memoria : se utiliza para guardar el estado del contexto al interactuar con el modelo.
-
Índices : utilizados para estructurar documentos para la interacción con modelos.
-
Cadenas : una serie de llamadas a varios componentes.
-
Agentes : Deciden qué acciones debe tomar el modelo, ejecutan y observan el proceso hasta su finalización.
5.1, modelo
Actualmente, están surgiendo muchos modelos nuevos de LLM. LangChain proporciona interfaces e integraciones simplificadas para varios modelos. En el núcleo de LangChain se encuentra un potente modelo de lenguaje (LLM) que permite que las aplicaciones comprendan y generen texto similar al humano. A través de LangChain, los desarrolladores tienen acceso a una gran cantidad de LLM, cada modelo está capacitado con grandes cantidades de datos y puede realizar una variedad de tareas relacionadas con el lenguaje de manera excelente. Ya sea para comprender las consultas de los usuarios, generar respuestas o realizar tareas lingüísticas complejas, los modelos de LangChain son la columna vertebral de las capacidades de procesamiento del lenguaje.
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003")
# LLM 将提示作为输入,输出一个完成的文本
prompt = "如何在浑浊的娱乐圈里更好的生存下去?"
completion = llm(prompt)
5.2 Modelo de chat
Esto utilizará la clase ChatOpenAI para establecer una conversación entre el usuario y el chatbot AI. La temperatura inicial del chatbot es 0, lo que hace que sus respuestas sean más centradas y seguras. La conversación comienza con un mensaje del sistema que explica el propósito del robot, seguido de un mensaje humano que expresa sus preferencias alimentarias. El chatbot generará una respuesta basada en la entrada proporcionada.
Utilice la clase ChatOpenAI para establecer una conversación entre el usuario y el chatbot AI. La temperatura inicial del chatbot es 0, lo que indica que el contenido de su respuesta es más centrado y seguro. La conversación de chat comienza con un mensaje del sistema que explica el propósito del robot, seguido de un mensaje humano que expresa las preferencias alimentarias. El chatbot generará una respuesta basada en la entrada proporcionada.
chat = ChatOpenAI(temperature=0)
chat(
[
SystemMessage(content="你好,我是 AI 聊天机器人。我可以帮助你提高关于健康饮食的建议。"),
HumanMessage(content="我想吃点甜点,但是不想吃巧克力,你有什么推荐吗?")
]
)
5.3 Modelo de incrustación de texto
Un modelo de incrustación de texto es un modelo que toma entrada de texto y la convierte en forma numérica para representar una lista incrustada del texto de entrada. Al utilizar estas incrustaciones, podemos extraer información del texto y usarla para determinar qué tan similares son dos textos (como resúmenes de películas).
embeddings = OpenAIEmbeddings()
text = "Alice 有一只鹦鹉。Alice 的宠物是什么动物?"
text_embedding = embeddings.embed_query(text)
5.4 Consejos
Las indicaciones de un modelo de lenguaje son un conjunto de instrucciones o entradas proporcionadas por el usuario para guiar las respuestas del modelo, ayudando al modelo a comprender el contexto y generar resultados relevantes y coherentes basados en el lenguaje, como responder una pregunta, completar una oración o participar en una actividad. El mensaje se refiere a la entrada requerida cuando el modelo genera contenido. Puede incluir el conocimiento previo requerido cuando el modelo genera contenido, las instrucciones que el usuario espera que ejecute el modelo, el formato que debe seguir la salida del modelo, etc. Porque diferentes indicaciones harán que la calidad del contenido generado por el modelo varíe mucho.
Los mensajes en LangChain tienen tres partes: plantillas de mensajes , analizadores de salida y selectores de ejemplo.
5.4.1 Plantillas de mensajes
La plantilla de aviso le permite generar un aviso correspondiente a través de una plantilla. La ventaja de esto es que el aviso se puede construir dinámicamente en función de la entrada del usuario o algunos otros parámetros.
5.4.2 Analizadores de salida
El modelo LLM genera texto, pero normalmente esperamos obtener algún resultado estructurado para su posterior procesamiento. La función principal de Output Parsers es analizar el texto LLM en datos estructurados.
En los analizadores de salida de LangChain, se deben implementar dos métodos:
-
getFormatInstructions(): strEste método devuelve una cadena que contiene la descripción del formato de salida del modelo de lenguaje. En pocas palabras, le indica al modelo LLM en qué formato se deben devolver los datos. -
parse(raw: string): anyEste método consiste en analizar una cadena original sin procesar en datos de una estructura específica.
5.4.3 Selectores de ejemplo
Para que el resultado de LLM coincida con el texto que espera, puede utilizar el método de pocas tomas, es decir, dar algunos ejemplos y dejar que LLM genere texto similar a los ejemplos. El método Few-shot puede evitar hasta cierto punto el problema de las fluctuaciones excesivas en la calidad de salida de LLM, pero también introducirá otros problemas, como seguir demasiado el estilo del ejemplo, lo que a veces hace que parezca forzado. juntos.
El selector de ejemplo es responsable de ayudarle a crear un mensaje de algunas tomas. EjemploSelector acepta un parámetro de longitud máxima y puede seleccionar dinámicamente la cantidad de ejemplos en función de la longitud de entrada del usuario para garantizar que el mensaje final no exceda el límite de longitud del mensaje del modelo LLM.
template = "明天{city}的天气如何?"
prompt = PromptTemplate(
input_variables=["city"],
template=template,
)
prompt.format(city="北京")
5.5 Cadena
Las cadenas, como sugiere el nombre, son secuencias de operaciones que permiten a la biblioteca LangChain manejar sin problemas la entrada y salida del modelo de lenguaje. Estos componentes de LangChain se componen básicamente de enlaces, que pueden ser otras cadenas o primitivas como sugerencias, modelos de lenguaje o utilidades.
Usar un LLM independiente está bien para algunas aplicaciones simples, pero muchas aplicaciones más complejas requieren LLM vinculados, ya sea entre sí o con otros expertos. LangChain proporciona interfaces estándar para cadenas, así como algunas implementaciones de cadenas comunes para facilitar su uso.
El proceso de combinar LLM con otros componentes para crear una aplicación se llama vinculación en LangChain. Ejemplos incluyen:
-
Combinando plantillas de mensajes y LLM
-
Se pueden combinar varios LLS de forma secuencial utilizando la salida del primer LLM como entrada para el segundo LLM.
-
Por ejemplo, combine LLM con datos externos para responder preguntas.
-
Combine LLM con memoria a largo plazo (por ejemplo, historial de chat).
chain = LLMChain(llm = llm,
prompt = prompt)
chain.run("colorful socks")
5.6 Índice
La falta de información contextual (como el acceso a documentos específicos o correos electrónicos) es un inconveniente importante de LLM. Permitir que LLM acceda a datos externos específicos le ayudará a evitar esta situación.
Una vez que los datos externos estén listos para almacenarse como un documento, puede indexarlos en una base de datos vectorial llamada VectorStore utilizando el modelo de incrustación de texto.
Vector Storage ahora almacena sus documentos como incrustados. Hay muchas acciones que ahora puede realizar utilizando estos datos externos. El siguiente es un ejemplo similar para explicar cómo utilizar la clase RetrievalQA para responder preguntas de recuperación.
# 将数据库转换为检索器
retriever = my_database.as_retriever()
# 创建 RetrievalQA 对象,指定语言模型、检索器和链路类型
qa = RetrievalQA.from_chain_type(
llm=my_llm,
chain_type="my_chain_type",
retriever=retriever,
return_source_documents=True)
# 定义一个问题
query = "什么是深度学习?"
# 使用 RetrievalQA 对象回答问题
result = qa({"query": query})
# 打印结果
print(result['result'])
5.7 Memoria
Para programas como los chatbots, poder recordar conversaciones anteriores es fundamental. Sin embargo, LLM carece de memoria a largo plazo de forma predeterminada a menos que ingrese al historial de chat. Al proporcionar múltiples opciones para manejar el historial de chat, LangChain resuelve este problema manteniendo todas las conversaciones, manteniéndose al día con las K conversaciones más recientes y resumiendo lo que se dijo.
# 创建 ConversationChain 对象,指定语言模型和 verbose 参数
conversation = ConversationChain(llm=my_llm, verbose=True)
# 输入一些句子
conversation.predict(input="我喜欢看电影。")
conversation.predict(input="我也喜欢听音乐。")
# 提问
conversation.predict(input="你喜欢什么类型的电影?")
6. Cree un chatbot conversacional
Los chatbots conversacionales se han convertido en una parte integral de muchas aplicaciones, brindando a los usuarios interacciones fluidas y experiencias personalizadas. La clave para desarrollar un chatbot exitoso es su capacidad para comprender y generar respuestas similares a las humanas. Con las capacidades avanzadas de procesamiento de lenguaje de LangChain, puede crear chatbots inteligentes que van más allá de los sistemas tradicionales basados en reglas.
6.1 Importar bibliotecas necesarias
from langchain.llms import OpenAI
from langchain import LLMChain
from langchain.prompts.prompt import PromptTemplate
# 导入聊天特定组件
from langchain.memory import ConversationBufferMemory
6.2 Usar plantillas de mensajes
Cree una plantilla de chatbot que genere chistes tomando la información del usuario e incorporándola a un formato de chiste predefinido. Utiliza PromptTemplate y ConversationBufferMemory para almacenar y recuperar el historial de chat, lo que permite al chatbot generar chistes contextualmente relevantes.
template = """
你是一名有趣的聊天机器人。你的目标是帮助用户制造笑话。将用户说的话转化为一个笑话
{chat_history}
用户: {human_input}
机器人:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input"],
template=template
)
memory = ConversationBufferMemory(memory_key="chat_history")
6.3 Chatbot
Configura una instancia de la clase LLMChain que utiliza el modelo de lenguaje OpenAI para generar respuestas. Luego, el método llm_chain.predict() se utiliza para generar una respuesta basada en la entrada proporcionada por el usuario.
llm_chain = LLMChain(
llm=OpenAI(temperature=0),
prompt=prompt,
verbose=True,
memory=memory
)
llm_chain.predict(human_input="苹果是水果还是蔬菜?")
7. Utilice LangSmith para perfeccionar el LLM
En primer lugar, el ecosistema LLM de código abierto ha crecido significativamente, desde modelos de última generación significativamente rezagados hasta LLM que pueden ejecutarse casi SOTA en ellos, gracias a conjuntos de datos de entrenamiento más grandes y la aplicación de técnicas de ajuste. En segundo lugar, OpenAI, un proveedor líder de LLM, ha lanzado soporte de ajuste para nuevos modelos, lo que significa que se espera que la tecnología de ajuste cambie la situación en la que los modelos antiguos no pueden competir con los nuevos.
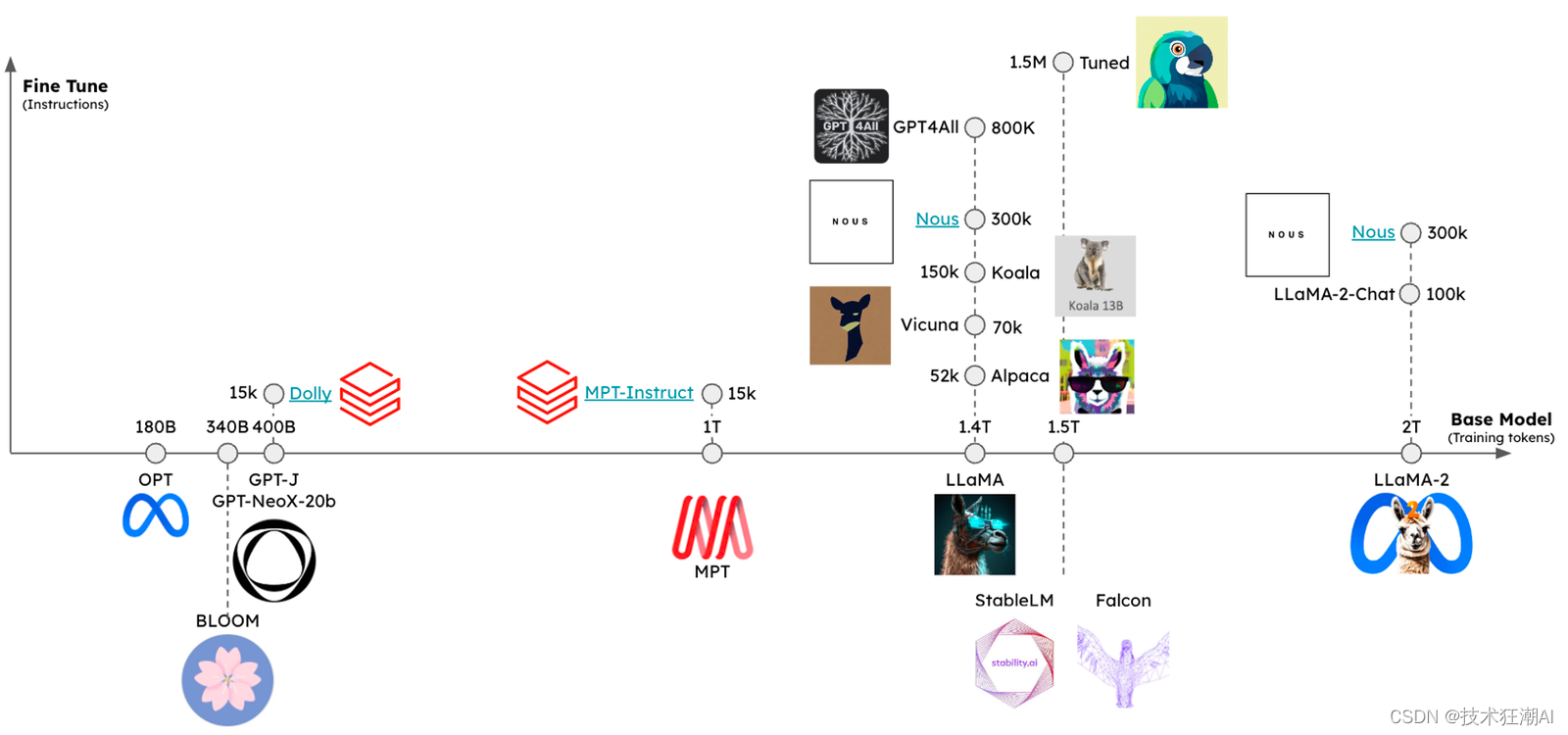
El ajuste es un proceso en el que un LLM previamente capacitado se capacita aún más en un conjunto de datos específico para adaptarlo a una tarea o dominio específico. Al exponer un modelo a datos específicos de la tarea, puede aprender a comprender mejor los matices, el contexto y las complejidades del dominio objetivo. Este proceso permite a los desarrolladores mejorar el rendimiento del modelo, aumentar la precisión y hacerlo más relevante para las aplicaciones del mundo real.
7.1 ¿Cuándo realizar el ajuste fino?
Hay dos formas principales en que LLM aprende nuevos conocimientos: actualizaciones de peso y sugerencias. Las actualizaciones de peso se pueden lograr mediante entrenamiento previo o ajuste, mientras que las sugerencias se pueden implementar mediante métodos como la generación aumentada de recuperación (RAG). Los pesos del modelo son similares a la memoria a largo plazo y las señales son similares a la memoria a corto plazo. Una analogía útil es comparar los empujones con la preparación para un examen una semana después y la inserción de conocimientos mediante indicaciones para realizar un examen utilizando notas abiertas.
Sin embargo, no se recomienda realizar ajustes al enseñar nuevos conocimientos en LLM o recordar hechos. John Schulman de OpenAI señaló en su charla que el ajuste puede provocar alucinaciones. Por el contrario, los empujones son más adecuados para enseñar tareas específicas y deben usarse junto con indicaciones o RAG. La situación específica depende de si el LLM requiere tareas bien definidas, ejemplos suficientes y/o falta de capacidades de aprendizaje contextual con pocas pistas. Anyscale resume bien estos puntos en su blog: El ajuste está al servicio de la forma, no de los hechos .
7.2 Cómo realizar ajustes
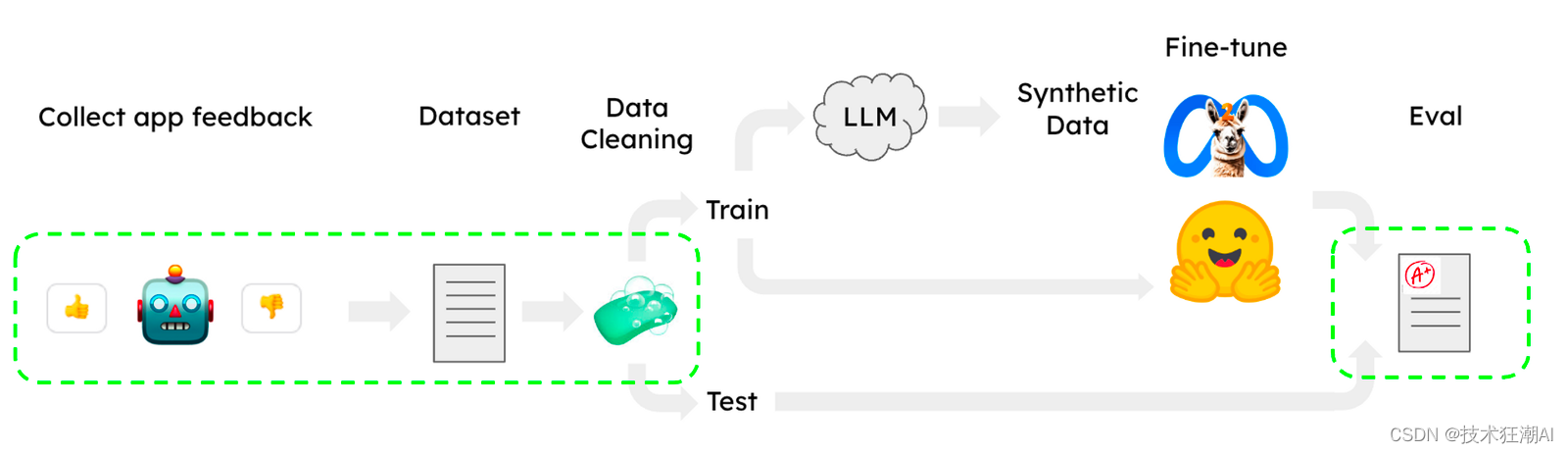
Se han publicado varios métodos útiles de ajuste de LLaMA para utilizar subconjuntos del corpus OpenAssistant en HuggingFace para tareas como chatear. Es importante tener en cuenta que estos flujos de trabajo se pueden ejecutar en una única GPU CoLab, lo que los hace fáciles de usar. Sin embargo, quedan dos cuestiones importantes durante el proceso de ajuste, a saber, la recopilación/limpieza y evaluación del conjunto de datos. A continuación presentaremos cómo utilizar LangSmith para resolver estos dos problemas (parte verde).
7.3 Tarea
Para tareas como clasificación/etiquetado o extracción, el ajuste fino es muy adecuado. Anyscale se perfeccionó utilizando LLaMA 7B y 13B LLM y logró resultados alentadores (superando a GPT4) en extracción, texto a SQL y control de calidad. Como caso de prueba, elegimos extraer conocimiento triple de la forma (sujeto, relación, objeto) del texto: donde los sujetos y los objetos son entidades y las relaciones son atributos o conexiones entre ellos. Estos tripletes pueden luego usarse para construir un gráfico de conocimiento, una base de datos que almacena información sobre entidades y sus relaciones. También creamos una aplicación Streamlit pública para extraer tripletas del texto ingresado por el usuario y exploramos la capacidad de LLM (GPT3.5 o 4) para extraer tripletas mediante llamadas a funciones. Al mismo tiempo, ajustamos LLaMA2-7b-chat y GPT-3.5 utilizando conjuntos de datos públicos.
7.4 Conjunto de datos
En la formación de LLM, la recopilación y limpieza de conjuntos de datos suelen ser tareas desafiantes. Al crear un proyecto en LangSmith, el álgebra se registra automáticamente, lo que facilita la obtención de grandes cantidades de datos. LangSmith proporciona una interfaz consultable para que pueda utilizar filtros de comentarios de los usuarios, etiquetas y otras métricas para seleccionar casos de mala calidad, corregirlos y guardarlos en un conjunto de datos que se puede utilizar para mejorar los resultados del modelo (ver más abajo).

Por ejemplo, creamos los conjuntos de datos de prueba y entrenamiento de LangSmith utilizando triples de gráficos de conocimiento de los conjuntos de datos públicos BenchIE y CarbIE. Convertimos estos datos a un formato JSON compartido, con cada triplete representado como {s: sujeto, o: objeto, r: relación}, y dividimos aleatoriamente los datos combinados en ~1500 oraciones etiquetadas. Conjunto de entrenamiento y conjunto de prueba de 100 oraciones. En CoLab, puede cargar fácilmente el conjunto de datos de LangSmith. Una vez cargado, podemos crear las instrucciones de ajuste utilizando el siguiente mensaje del sistema y la etiqueta de instrucción LLaMA (que se muestra a continuación):
"您是一个模型,任务是从给定的文本中提取知识图谱三元组。"
"这些三元组由三个部分组成:"
"- \"s\" 表示主题,即陈述的主要实体。"
"- \"object\" 表示主题所涉及的实体或概念。"
"- \"relation\" 表示主题和对象之间的关系。"
"您的目标是输入一个句子,并输出代表该句子中包含的知识的三元组。"
7.5 Cuantificación
Ajustamos el modelo de chat LLaMA con parámetros 7B. Se espera que esto se pueda hacer en una sola GPU (consulte la guía de HuggingFace), pero esto plantea un desafío: si cada parámetro es de 32 bits, el modelo LLaMA2 con parámetros 7B ocupará 28 GB de memoria, lo que supera la VRAM del GPU T4 (16 GB). Para resolver este problema, cuantificamos los parámetros del modelo, es decir, agrupamos los valores (por ejemplo, 16 valores con cuantificación de 4 bits), reduciendo así la memoria necesaria para almacenar el modelo (7B * 4 bits/parámetro = 3,5 GB). unas 8 veces.
7.6, LoRA suma qLoRA
Mientras el modelo está en la memoria, todavía necesitamos una forma de realizar ajustes con los limitados recursos restantes de la GPU. El ajuste fino eficiente de parámetros (PEFT) es un enfoque común para este propósito: LoRA congela los pesos del modelo previamente entrenado e inyecta una matriz de factorización de rango entrenable en la arquitectura del modelo en cada capa (ver aquí), reduciendo así el ajuste fino del parámetro entrenable. número de parámetros (por ejemplo, ~1% del modelo general). qLoRA amplía este enfoque congelando los pesos de cuantificación. Durante el ajuste fino, los pases hacia adelante y hacia atrás utilizan pesos cuantificados inversos y solo una pequeña parte del adaptador LoRA se mantiene en la memoria, lo que reduce la huella del modelo ajustado.
7.7 Formación
Comenzamos a utilizar el modelo de chat LLaMA-7b previamente entrenado llama-2-7b-chat-hf y lo ajustamos en el A100 en CoLab con aproximadamente 1500 instrucciones. Para la configuración del entrenamiento utilizamos los parámetros de ajuste fino de LLaMA (BitsAndBytes), cargando el modelo base con precisión de 4 bits, pero usando fp16 para los pases hacia adelante y hacia atrás. Utilizamos el ajuste fino supervisado (SFT) para ajustar las instrucciones, lo cual es muy rápido (<15 minutos) en el A100 para datos de tan pequeña escala.
7.8 Ajuste de OpenAI
Para ajustar el modelo de chat GPT-3.5-turbo de OpenAI, seleccionamos 50 ejemplos del conjunto de datos de entrenamiento y los convertimos en una lista de mensajes de chat en el formato deseado:
{
"messages": [
{
"role": "user",
"content": "从下面的句子中提取三连音:\n\n{sentence}"},
{
"role": "assistant",
"content": "{triples}"
},
...
]
}
Dado que el modelo base es tan versátil, no necesitamos una gran cantidad de datos para lograr el comportamiento deseado. El propósito de los datos de entrenamiento es guiar el modelo para que genere siempre el formato y estilo correctos, no enseñarle mucha información. Como veremos en la sección de evaluación a continuación, 50 ejemplos de entrenamiento son suficientes para que el modelo prediga tripletas en el formato correcto cada vez.
Cargamos los datos de ajuste a través del SDK de OpenAI y utilizamos el modelo resultante directamente en la clase ChatOpenAI de LangChain. El modelo ajustado se puede utilizar directamente:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model="ft:gpt-3.5-turbo-0613:{openaiOrg}::{modelId}")
Todo el proceso tomó solo unos minutos y no requirió cambios de código en nuestra cadena más que agregar algunos ejemplos en la plantilla de solicitud. Luego comparamos este modelo con otros modelos para evaluar su rendimiento. Puedes ver un ejemplo de todo el proceso en nuestro cuaderno CoLab.
7.9 Evaluación
Evaluamos cada modelo utilizando LangSmith y aplicamos el evaluador LLM (GPT-4) para calificar cada predicción y medir la diferencia fáctica entre las etiquetas identificadas por el evaluador y los triples predichos. Se imponen sanciones cuando las predicciones contienen tripletas que no están presentes en las etiquetas, o cuando las predicciones no contienen tripletas. Sin embargo, el evaluador será indulgente si la redacción exacta del objeto o relación difiere sin sentido. El rango de calificación es de 0 a 100. Realizamos la evaluación en CoLab, donde pudimos configurar fácilmente nuestro evaluador personalizado y nuestra cadena para realizar pruebas.
La siguiente tabla muestra los resultados de la evaluación del modelo de chat base de LLaMA y las variantes ajustadas. A modo de comparación, también comparamos 3 cadenas utilizando el modelo de chat de OpenAI: gpt-3.5-turbo con pocas sugerencias, un modelo gpt-3.5-turbo ajustado en 50 puntos de datos de entrenamiento y gpt-4 con una cadena de pocas sugerencias:
-
GPT-4 funciona mejor con algunas sugerencias de muestra
-
GPT-3.5 después del ajuste fino obtuvo el segundo lugar
-
LLaMA ajustado supera el rendimiento de GPT-3.5
-
Después del ajuste, el rendimiento de LLaMA mejora aproximadamente un 29 % en comparación con el LLaMA de referencia.
7.10 Conclusión
Podemos resumir algunas lecciones centrales:
-
LangSmith puede ayudar a resolver los puntos débiles al ajustar los flujos de trabajo, como la recopilación de datos, la evaluación y la inspección de resultados. Mostramos cómo LangSmith puede recopilar y cargar fácilmente conjuntos de datos, así como ejecutar evaluaciones y examinar generaciones específicas.
-
Las puntas RAG o insuficientes deben considerarse cuidadosamente antes de emprender ajustes más desafiantes y costosos. La pista de pocos disparos GPT-4 en realidad funciona mejor que todas nuestras variantes optimizadas.
-
Ajustar pequeños modelos de código abierto en tareas bien definidas puede superar a los modelos generalistas más grandes. Como informaron anteriormente Anyscale y otros, vemos que el modelo LLaMA2-chat-7B ajustado supera el rendimiento del LLM generalista más grande (GPT-3.5-turbo).
-
Hay muchas formas de mejorar el rendimiento del ajuste, en particular la definición cuidadosa de tareas y la gestión de conjuntos de datos. Algunas obras, como LIMA, logran un rendimiento impresionante al ajustar LLaMA con tan solo 1000 instrucciones seleccionadas para que sean de alta calidad. Una mayor recopilación/limpieza de datos, el uso de modelos base más grandes (por ejemplo, LLaMA 13B) y el escalado con servicios de GPU para realizar ajustes (Lambda Labs, Modal, Vast.ai, Mosaic, Anyscale, etc.) son formas previsibles de mejorar estos resultado.
En general, estos resultados (y el CoLab vinculado) proporcionan una forma rápida de ajustar el LLM de código abierto utilizando herramientas LangSmith para ayudar en todo el flujo de trabajo.
8. Beneficios de usar LangChain
-
Ajustar un LLM utilizando LangChain puede mejorar la precisión del modelo y la relevancia contextual para una tarea o dominio específico, lo que resulta en resultados de mayor calidad.
-
LangChain permite a los desarrolladores personalizar LLM para manejar tareas únicas, terminología específica de la industria y contexto de dominio específico para satisfacer las necesidades específicas de los usuarios.
-
Un LLM perfeccionado puede desarrollar aplicaciones potentes con una comprensión más profunda de lenguajes de dominios específicos, lo que da como resultado respuestas más precisas y conscientes del contexto.
-
El ajuste con LangChain reduce la necesidad de grandes cantidades de datos de entrenamiento y recursos informáticos, lo que ahorra tiempo y esfuerzo y, al mismo tiempo, logra mejoras significativas en el rendimiento.
9. Resumen
LangChain abre un mundo de posibilidades cuando se trata de crear aplicaciones basadas en LLM. Si su interés radica en la finalización de textos, la traducción de idiomas, el análisis de sentimientos, el resumen de textos o el reconocimiento de entidades nombradas. LangChain proporciona una plataforma intuitiva y una API potente para convertir sus ideas en realidad. Al aprovechar el poder de LLM, puede crear aplicaciones inteligentes que comprendan y generen texto similar al humano, revolucionando la forma en que interactuamos con el lenguaje.
Además, este artículo presenta las lecciones aprendidas para perfeccionar los LLM de código abierto, incluido el uso de la herramienta LangSmith para abordar los puntos débiles en el flujo de trabajo de ajuste, la consideración cuidadosa de RAG o sugerencias de spam y cómo el ajuste fino de modelos pequeños de código abierto puede superar a los más grandes. modelos generalistas. Además, el artículo menciona formas de mejorar el rendimiento, como una definición cuidadosa de las tareas y la gestión de conjuntos de datos, una mayor recopilación/limpieza de datos, el uso de modelos base más grandes y el escalado con servicios de GPU. En general, estos resultados proporcionan una forma rápida de ajustar el LLM de código abierto utilizando herramientas LangSmith para ayudar en todo el flujo de trabajo.
10. Referencias
-
LangChain : https://www.langchain.com/
-
LangChain GitHub : https://github.com/langchain-ai/langchain
-
Introducción a LangChain : https://www.pinecone.io/learn/series/langchain/langchain-intro/
-
LangSmith : https://docs.smith.langchain.com/
-
Anuncio de LangSmith : https://blog.langchain.dev/annunciando-langsmith/
Si está interesado en este artículo y desea obtener más información sobre las habilidades prácticas en el campo de la IA, puede seguir la cuenta pública "Technology Frenzy AI" . Aquí puede ver los artículos más recientes y actuales y tutoriales de casos prácticos en el campo AIGC.