Directorio de artículos
- Prefacio
- 1. La idea de lista doblemente enlazada.
- En segundo lugar, el análisis de implementación de la lista circular doble enlazada líder.
- En segundo lugar, la realización de la lista circular principal de doble enlace 1
-
- 1. Tome la iniciativa en la lista circular de doble enlace para obtener una descripción general de los archivos de encabezado
- 2. Inicialización de la lista circular doble enlazada principal
- 3. Liderar la inserción de una lista circular doble enlazada.
- 4. Imprima y destruya la lista circular principal con doble enlace.
- 5. Busque y elimine la lista circular doble enlazada principal.
- 3. Implementación de la lista circular doble enlazada líder 2
- 4. Encapsulación oculta de la lista circular doblemente enlazada principal
- 5. Tome la iniciativa en encapsular la lista circular doble enlazada en una biblioteca.
-
- 1. La lista circular de encabezado con doble enlace se encapsula como una vista previa del archivo de encabezado de la biblioteca.
- 2. El archivo fuente para la implementación de la función de lista doblemente enlazada del primer bucle.
- 3. Tome la iniciativa en encapsular la lista circular doble enlazada en una biblioteca.
- 6. Analice parte de la lista doblemente enlazada del kernel para implementar rápidamente una lista doblemente enlazada.
- Siete, lista doblemente enlazada para lograr 2 códigos
- Resumir
Prefacio
Creo que después del estudio anterior todos ya entendieron los defectos y usos de la lista simple, hoy aprendemos la lista doble, que es diferente a antes, hoy la realización de la lista doble es una un poco más difícil, pero creo que estas dificultades no son un problema para todos. En comparación con la implementación de la lista de enlace simple anterior, nuestro tipo de datos es fijo. Lo que se pasa en la función principal requiere el tipo de datos correspondiente en nuestra estructura de lista de enlace simple. Hoy cambiaremos la implementación de la lista de enlace doble. list a la función principal (usuario) para pasar cualquiera. Podemos recibir e implementar todos los tipos de datos.
Este capítulo incluye puntos de conocimiento sobre punteros de función, funciones de devolución de llamada y matrices flexibles. Los amigos que lo hayan olvidado pueden revisarlos en este capítulo.
Cómo se almacenan las listas enlazadas en el espacio:
1. La idea de lista doblemente enlazada.
Antes de darnos cuenta, conozcamos la lista doblemente enlazada:
qué es una lista doblemente enlazada: hay dos punteros anterior y siguiente en el nodo de la lista doblemente enlazada, que apuntan al nodo predecesor y al nodo sucesor respectivamente.
Ventajas de la lista de doble enlace: resuelva el problema de que cuando una lista de enlace simple quiere acceder al nodo predecesor de un nodo, solo puede atravesar desde el principio. La complejidad de acceder al nodo sucesor es O (1), y la La complejidad de acceder al nodo predecesor es una pregunta O (n).
La estructura de la lista doblemente enlazada:

en una lista doblemente enlazada que no es circular, el nodo principal o el primer nodo de la lista doblemente enlazada no tiene un nodo predecesor y el último nodo no tiene un nodo sucesor. ¡El nodo principal no almacena datos válidos! ! !
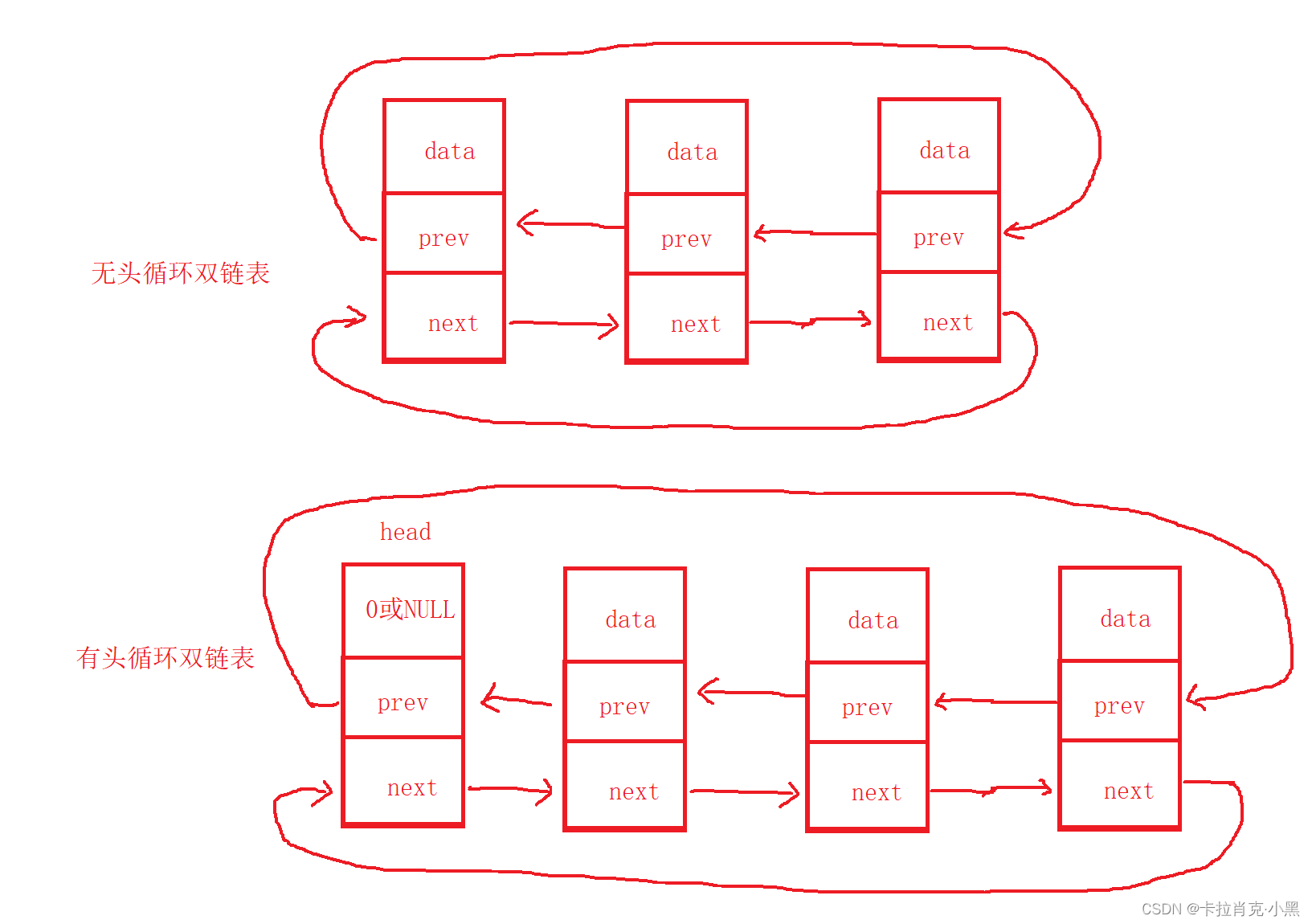
En una lista circular doblemente enlazada, el nodo principal o el primer nodo de la lista doblemente enlazada, el nodo predecesor es el último nodo y el nodo sucesor del último nodo es el nodo principal o el primer nodo de la lista doblemente enlazada. lista enlazada. ¡El nodo principal no almacena datos válidos! ! !
Creo que ya tenemos una idea general de la implementación a través de la estructura, y lo que queremos lograr hoy es la estructura más perfecta en la lista doblemente enlazada. La lista doblemente enlazada con el ciclo principal es también la estructura que utilizará habitualmente en el futuro.
En segundo lugar, el análisis de implementación de la lista circular doble enlazada líder.
Queremos darnos cuenta de que cualquier tipo de datos pasado por el usuario (función principal) puede formar nuestra lista doblemente enlazada, por lo que se desconoce el tipo de campo de datos de la lista doblemente enlazada del usuario, entonces, ¿qué tipo de datos queremos construir? Cuando elegimos un puntero de tipo char, habrá un nuevo problema: ¿cómo debe responder el usuario a un puntero de tipo entero o estructura char pasado? En respuesta a los problemas anteriores, diseñamos dos estructuras:
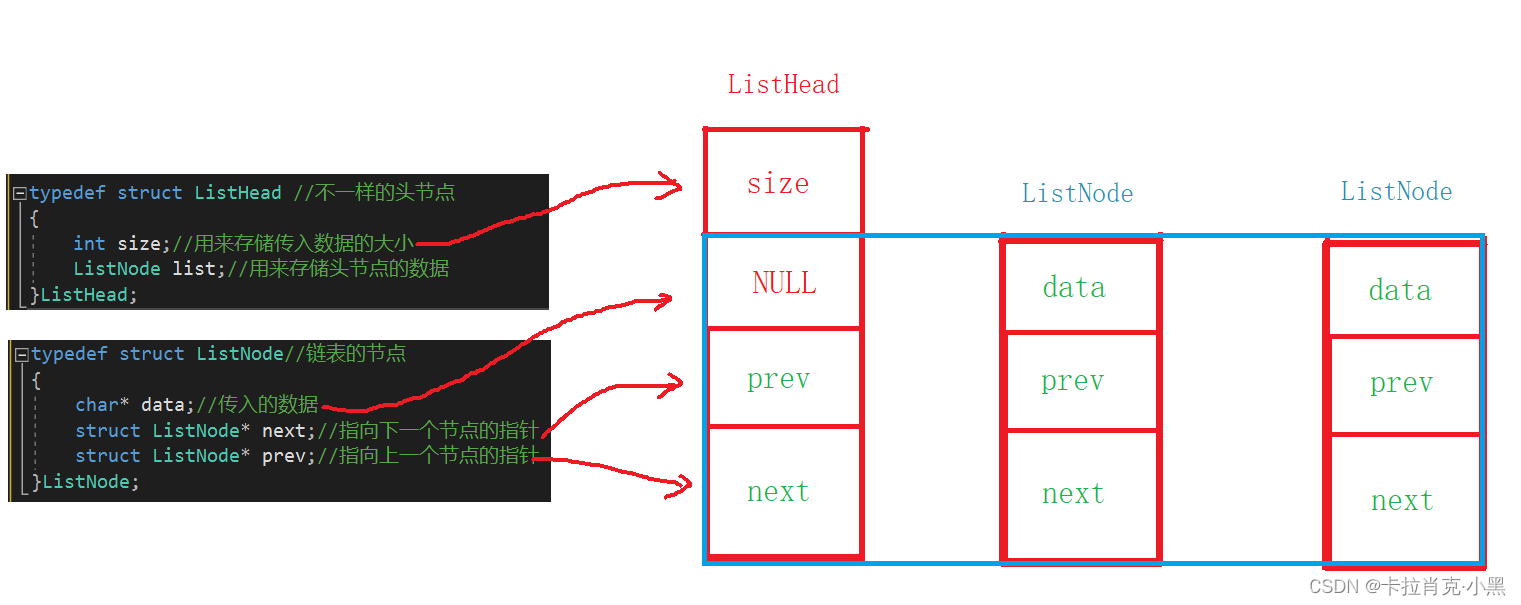
esta es la estructura que diseñamos, dado que nuestro nodo principal no almacena datos y es diferente de otros nodos, ¿cómo debemos apuntarlo?
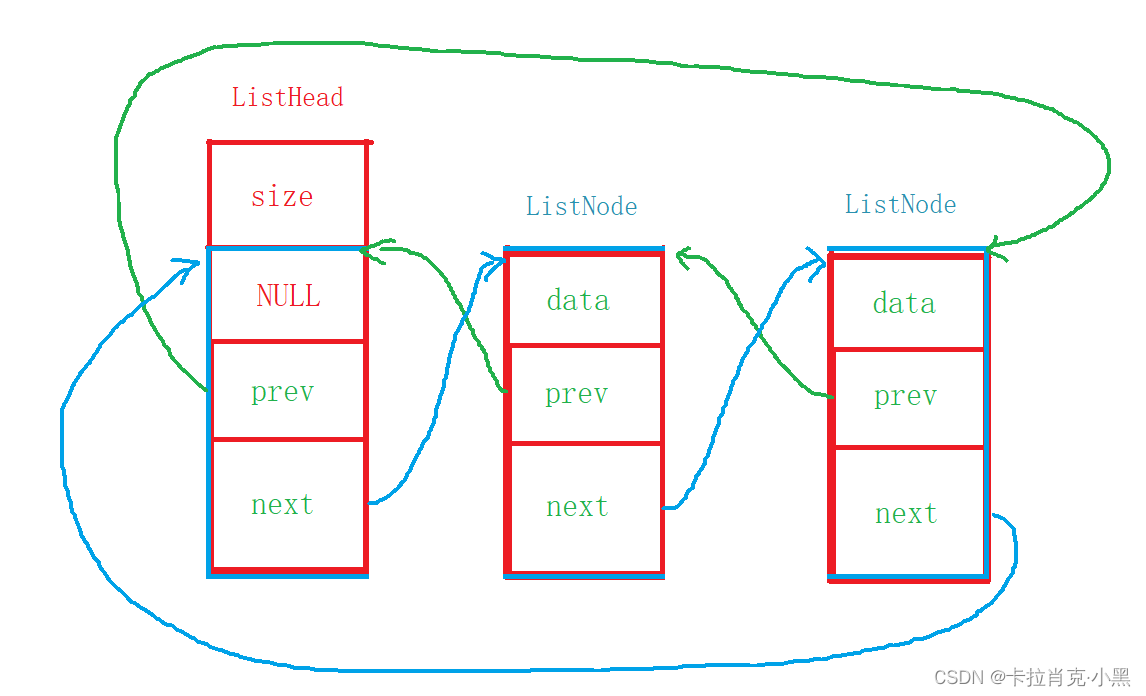
Nuestro puntero apunta a la posición. Apuntamos los punteros del nodo de cola y del primer nodo válido a la posición del miembro del nodo de lista enlazada del nodo principal. De esta forma nuestra lista enlazada será circular.
En segundo lugar, la realización de la lista circular principal de doble enlace 1
1. Tome la iniciativa en la lista circular de doble enlace para obtener una descripción general de los archivos de encabezado
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<time.h>
#define HEADINSERTION 1 //头插选项
#define BACKINSERTION 2 //尾插选项
typedef struct ListNode//链表的节点
{
char* data;//传入的数据
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
}ListNode;
typedef struct ListHead //不一样的头节点
{
int size;//用来存储传入数据的大小
ListNode list;//用来存储头节点的数据
}ListHead;
typedef void Printf(const void* );//对用户传递的打印函数进行重命名
typedef int Cmp(const void*, const void*);//对用户传递的打印函数进行重命名
ListHead* ListCreate(int datasize);//用来创建特殊的头节点
void Destory(ListHead* pHead);// 双向链表销毁
void ListPrint(ListHead* pHead, Printf* print);// 双向链表打印
int ListInsert(ListHead* pHead, const void* pos, int Optional);//双向链表的插入
void* ListFind(ListHead* pHead, const void* key,Cmp* cmp);//双向链表查找
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp);//双向链表删除
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp,void* retu);//双向链表删除,并把删除节点返回
Primero veamos las funciones en el archivo de encabezado y veamos por qué está diseñado de esta manera. Te las respondemos una a una a continuación.
2. Inicialización de la lista circular doble enlazada principal
ListHead* ListCreate(int datasize)//用来创建特殊的头节点
{
ListHead* pHead = (ListHead*)malloc(sizeof(ListHead));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->size = datasize;//用来接收用户要构建链表的数据区的大小
pHead->list.data = NULL;//头节点不存储有效数据,所以置为NULL
pHead->list.next = &pHead->list;//后继节点指向自己
pHead->list.prev = &pHead->list;//前驱节点指向自己
return pHead;
}
Necesitamos construir nuestro nodo principal especial durante la inicialización. Solo cuando sepamos el tamaño del área de datos que el usuario desea construir podremos crear espacio para inserciones posteriores.
3. Liderar la inserción de una lista circular doble enlazada.
//pos:用来接收用户所传数据,由于用户所传数据未知,所以我们用void指针进行接收
//Optional:插入选择,接收用户是头插还是尾插
//#define HEADINSERTION 1 //头插选项,在我们的头文件中定义的
//#define BACKINSERTION 2 //尾插选项,在我们的头文件中定义的
int ListInsert(ListHead* pHead, const void* pos, int Optional)//双向链表的插入
{
assert(pHead);
ListNode* node = (ListNode*)malloc(sizeof(ListNode));
if (node == NULL)//开辟空间失败就报错结束
{
perror("node malloc");//节点开辟失败
return 1;//返回值为1代表节点开辟失败
}
node->data = (char*)malloc(sizeof(char) * pHead->size);//数据区的开辟,开辟的大小为用户所传的大小
if (node->data == NULL)
{
free(node);//释放开辟好的节点,防止内存泄露
perror("node->data malloc");//数据域开辟失败,进行报错
return 2;//返回值为2代表节点开辟成功,但数据区开辟失败
}
memcpy(node->data, (char*)pos,pHead->size);//把数据拷贝到我们开的节点中
if (HEADINSERTION == Optional)//判断是否为头插
{
node->next = (pHead->list).next;
node->prev = &(pHead->list);//取头节点中的链表节点地址
}
else if (BACKINSERTION == Optional)//判断是否为尾插
{
node->next = &pHead->list;
node->prev = pHead->list.prev;
}
else
{
free(node->data);//释放开辟好的数据区
free(node);//释放开辟好的节点,防止内存泄露
return 3;//返回值为3代表插入位置不符合要求
}
node->prev->next = node;
node->next->prev = node;
return 0;//代表此函数正常结束
}
En el proyecto, es ilegal que especifiquemos aleatoriamente la posición a insertar, porque se desconoce el contenido de los elementos de la lista vinculada y la inserción aleatoria es fácil de destruir la estructura, por lo que aquí implementamos la inserción de cola y la inserción de cabeza. Insertamos apuntando al nodo principal para señalar la posición del nodo de la lista de doble enlace en el nodo principal, ¡no a la posición que comienza desde el tamaño! ! !
Implementamos el enchufe principal y el enchufe trasero según la elección del usuario, y no es necesario dividirlos en dos funciones para implementarlo aquí.
En el proyecto, necesitamos usar menos funciones de impresión en la función, aquí regresamos por el valor de retorno y el usuario puede juzgar la causa del error a través del valor de retorno. Esto asegura la unidad de nuestra función.
Se desconoce el área de datos pasada por el usuario, por lo que debemos usar la función de biblioteca memcpy o strcpy para copiarla.
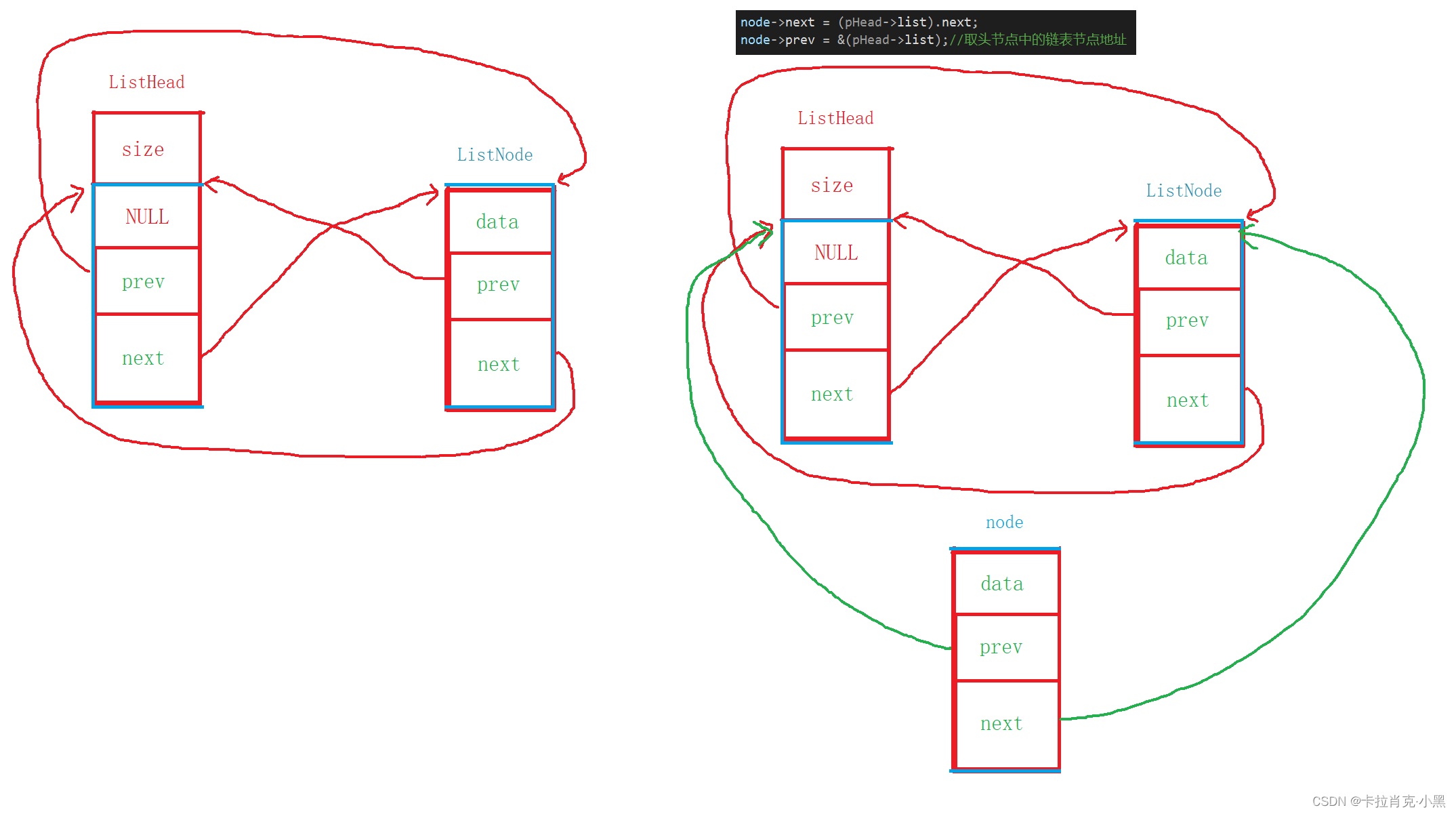
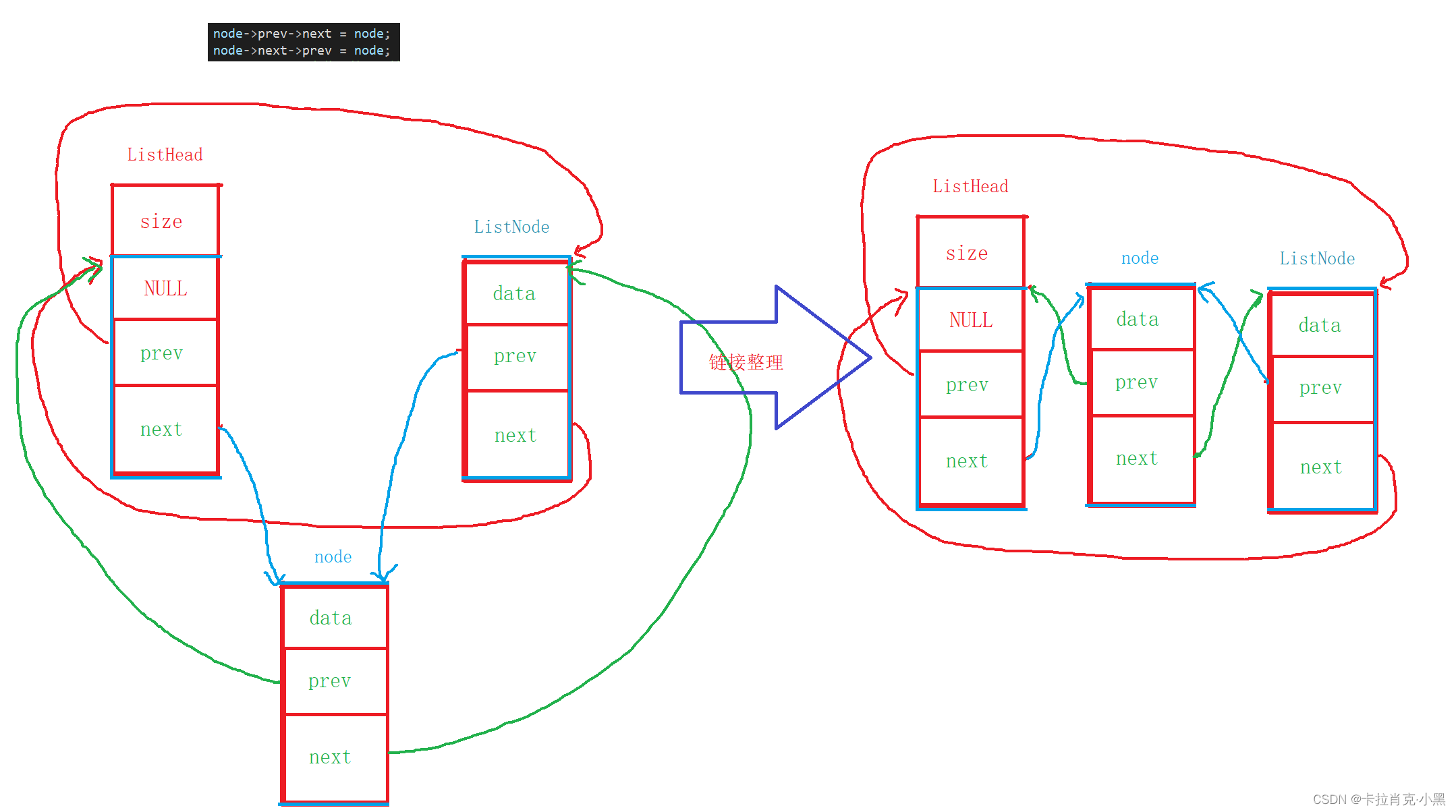
La idea de implementar la inserción de la cabeza y la inserción de la cola aquí es la misma: puedes hacer un dibujo. Debemos prestar atención a que cuando los nodos de nuestra lista de doble enlace se abren con éxito, pero el área de datos no se abre, los nodos abiertos deben liberarse; de lo contrario, se producirán pérdidas de memoria.
4. Imprima y destruya la lista circular principal con doble enlace.
void Destory(ListHead* pHead)// 双向链表销毁
{
assert(pHead);
ListNode* pos = (&pHead->list)->next;//从头节点的下一个节点开始
while (pos != &pHead->list)
{
ListNode* del = pos;//要释放的节点
pos = pos->next;//保存下一个节点
free(del->data);//data数据也是动态开辟的
free(del);//释放节点
}
}
void ListPrint(ListHead* pHead, Printf * print)// 双向链表打印,使用回调函数
{
assert(pHead);
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
print(pos->data);//调用用户提供的打印函数
pos = pos->next;
}
}
Aquí, si es el nodo principal se determina comparando la dirección del nodo de la lista doblemente enlazada y el nodo de la lista doblemente enlazado en el nodo principal.
¿Cómo imprimimos cuando no sabemos el tipo de usuario?
Esto se hace a través de la función de devolución de llamada. Como no conocemos el tipo de datos del usuario, pero el usuario sí lo sabe, podemos configurar el tipo de función y dejar que el usuario la implemente por sí mismo, y luego lo llamamos a través de la función de devolución de llamada.
Esta función de cambio de nombre de nuestro archivo de encabezado funciona aquí
typedef void Printf(const void* );//对用户传递的打印函数进行重命名
//void Printf(const void* );//用户需要实现的函数
//typedef对该函数进行重命名
Aquí está la función de prueba:
#define NAME_SIZE 32
typedef struct Stu
{
int id;
char name[NAME_SIZE];
int math;
int chinese;
}Stu;
void Printf_s(const void* print)//用户写的打印函数
{
Stu* prin = (Stu*)print;//把void类型转换为用户的类型
printf("id:%2d name:%s math:%2d chinese:%2d\n",prin->id, prin->name, prin->math, prin->chinese);
}
void test1()
{
ListHead* pHead = ListCreate(sizeof(Stu));
Stu stu;
int i = 0;
for (i = 0; i < 5; i++)
{
stu.id = i;
snprintf(stu.name, NAME_SIZE, "stu%d:", i);
stu.math = rand()%100;
stu.chinese = rand()%100;
ListInsert(pHead, &stu, 1);//传入1,进行头插
//ListInsert(pHead, &stu, 2);//传入2,进行尾插
}
ListPrint(pHead, Printf_s);// 双向链表打印
Destory(pHead);// 双向链表销毁
}
int main()
{
srand((unsigned)time(NULL));
test1();
return 0;
}
Inserción de cabeza:
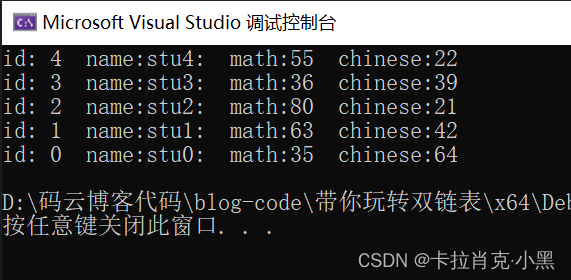
Inserción de cola:

Seleccionamos aleatoriamente los valores para las puntuaciones, por lo que los dos resultados son diferentes. El método que utilizamos para asignar valores a la matriz de cadenas aquí es el mismo que el método de una lista enlazada individualmente. No hay mucha introducción aquí.
5. Busque y elimine la lista circular doble enlazada principal.
ListNode* find(ListHead* pHead, const void* key, Cmp* cmp)//双向链表查找
{
assert(pHead);
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
if (cmp(key, pos->data) == 0)//调用用户提供的比较函数
{
break;
}
pos = pos->next;
}
return pos;//如果找到时,循环终止,返回值为找到的节点,如果找不到,则返回pos为头节点。
}
void* ListFind(ListHead* pHead, const void* key, Cmp* cmp)//双向链表查找
{
assert(pHead);
return (void*)find(pHead, key, cmp)->data;//返会我们的数据区。如果返回的头节点,头节点的值为NULL。不影响我们正常判断
}
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp)//双向链表删除
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del->data);//我们的数据区也是动态开辟的,所以也要内存释放
free(del);
return 0;
}
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp, void* retu)//双向链表删除,并把删除节点返回
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
if (del->data != NULL)
{
memcpy(retu, del->data, pHead->size);//通过函数参数返回
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del->data);
free(del);
return 0;
}
Para implementar la búsqueda y eliminación, primero debemos encontrar el nodo, por lo que creamos una función separada para devolver el nodo buscado. Como no sabemos el tipo a comparar, necesitamos recibir el tipo que el usuario desea comparar y la función de comparación proporcionada por el usuario para implementar nuestra búsqueda.
Nuestro nodo principal no contiene datos válidos, configuramos los datos del nodo principal para que estén vacíos, por lo que si no se encuentra la búsqueda, los datos que devolvemos son los datos del nodo principal (NULL).
Configuramos dos funciones de eliminación, una es eliminar directamente y la otra es eliminar y devolver el valor eliminado al usuario. Las dos implementaciones tienen la misma idea, pero una tiene un parámetro adicional.
typedef int Cmp(const void*, const void*);//对用户传递的比较函数进行重命名
Función de prueba:
#define NAME_SIZE 32
typedef struct Stu
{
int id;
char name[NAME_SIZE];
int math;
int chinese;
}Stu;
void Printf_s(const void* print)//用户写的打印函数
{
Stu* prin = (Stu*)print;
printf("id:%2d name:%s math:%2d chinese:%2d\n",prin->id, prin->name, prin->math, prin->chinese);
}
int cmp_id(const void* s1, const void*s2)//用户写的比较函数
{
int *key = (int*)s1;
Stu *stu = (Stu*)s2;
return (*key - stu->id);
}
int cmp_name(const void* s1, const void* s2)//用户写的name比较函数
{
char* key = (char*)s1;
Stu* stu = (Stu*)s2;
return strcmp(key, stu->name);
}
void test1()
{
ListHead* pHead = ListCreate(sizeof(Stu));
Stu stu;
int i = 0;
for (i = 0; i < 5; i++)
{
stu.id = i;
snprintf(stu.name, NAME_SIZE, "stu%d:", i);
stu.math = rand()%100;
stu.chinese = rand()%100;
ListInsert(pHead, &stu, 1);//传入1,进行头插
//ListInsert(pHead, &stu, 2);//传入2,进行尾插
}
ListPrint(pHead, Printf_s);// 双向链表打印
printf("\n\n");
//链表元素的查找,通过id查找
int id = 3;
Stu *st = ListFind(pHead, &id, cmp_id);
if (st == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(st);
}
//链表元素的删除,通过id删除
printf("\n\n");
Listdestroy(pHead, &id, cmp_id);
ListPrint(pHead, Printf_s);
//链表元素的删除并且返回,通过姓名删除
printf("\n\n");
char* p = "stu2:";//不要忘了加分号
Stu *s = &stu;
Listtravel(pHead, p, cmp_name, s);
if (s == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(s);
}
printf("\n\n");
ListPrint(pHead, Printf_s);
Destory(pHead);// 双向链表销毁
}
int main()
{
srand((unsigned)time(NULL));
test1();
return 0;
}
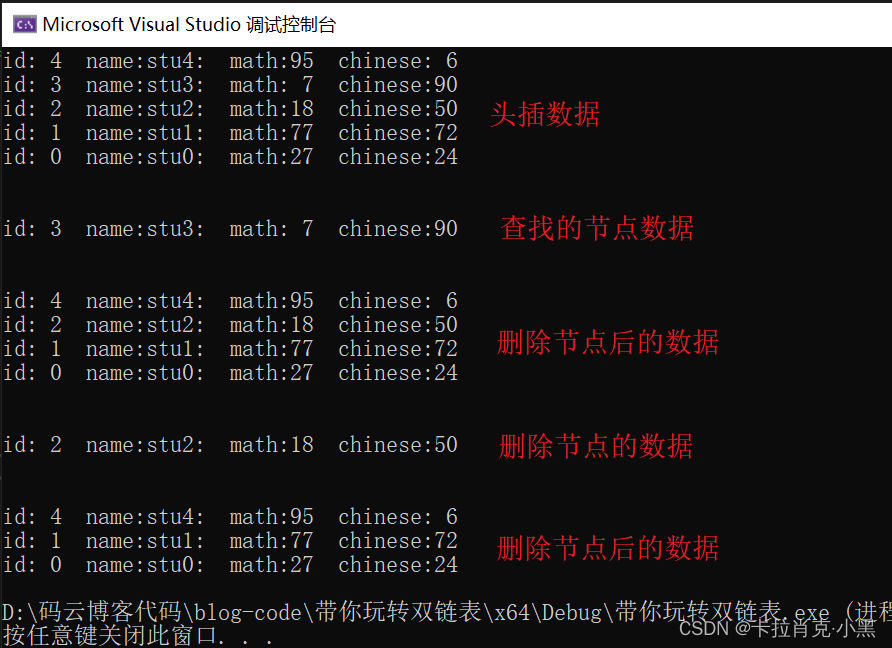
Para verificar que podemos seleccionar cualquier tipo, aquí usamos la eliminación de identificación y la eliminación de nombre respectivamente. La idea de implementación aquí es la misma que la función de biblioteca qsort.
3. Implementación de la lista circular doble enlazada líder 2
El primer método que utilizamos es el espacio abierto por la memoria dinámica. ¿No podemos abrir dinámicamente el espacio de nuestra área de datos? La respuesta es sí. Nuestra segunda idea es implementar nuestra lista doblemente enlazada sin abrir dinámicamente el área de datos.
Nuestra segunda idea es realizar cambios basados en la implementación de la primera función y simplemente mantener la función de prueba y la función no modificada sin cambios. ! !
1. Tome la iniciativa en la implementación de la estructura 2 de la lista cíclica de doble enlace
typedef struct ListNode//链表的节点
{
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
char data[];//传入的数据
//char data[1];//传入的数据
}ListNode;
typedef struct ListHead //不一样的头节点
{
int size;//用来存储传入数据的大小
ListNode list;//用来存储头节点的数据
}ListHead;
Aquí lo implementamos a través de una matriz flexible. Si el compilador no admite matrices flexibles, puede asignar el número de elementos en la matriz a 1.
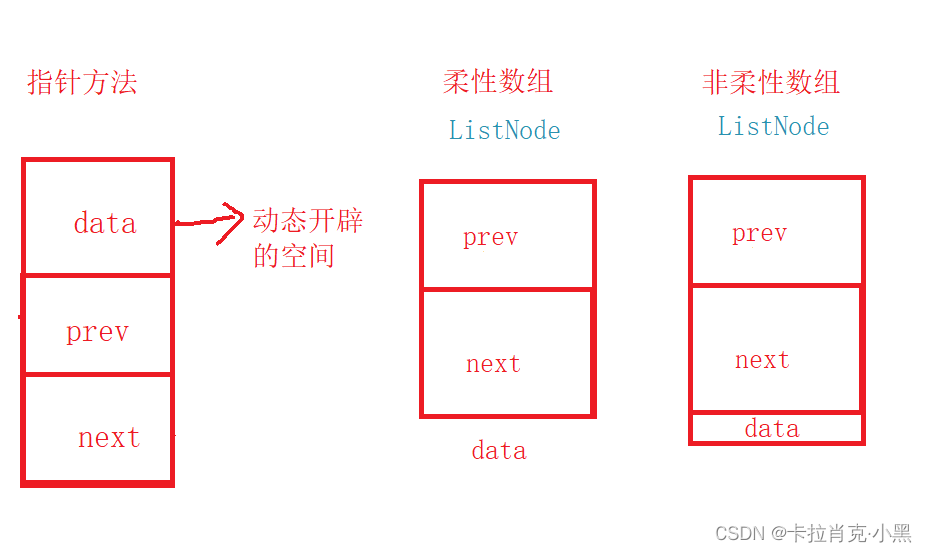
En este caso, la finalidad de nuestros datos es poder facilitarnos la búsqueda de la dirección del área de datos.
2. Tome la iniciativa en el bucle de la lista doblemente enlazada para implementar cambios de funciones.
ListHead* ListCreate(int datasize)//用来创建特殊的头节点
{
ListHead* pHead = (ListHead*)malloc(sizeof(ListHead));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->size = datasize;
pHead->list.next = &pHead->list;//后继节点指向自己
pHead->list.prev = &pHead->list;//前驱节点指向自己
return pHead;
}
Aquí nuestra área de datos ya no necesita abrir espacio dinámicamente, por lo que no es necesario asignar valores aquí.
void Destory(ListHead* pHead)// 双向链表销毁
{
assert(pHead);
ListNode* pos = (&pHead->list)->next;//从头节点的下一个节点开始
while (pos != &pHead->list)
{
ListNode* del = pos;//要释放的节点
pos = pos->next;//保存下一个节点
free(del);
}
}
int ListInsert(ListHead* pHead, const void* pos, int Optional)//双向链表的插入
{
assert(pHead);
ListNode* node = (ListNode*)malloc(sizeof(ListNode)+pHead->size);//申请一个节点结构体的大小加上用户所传数据大小
if (node == NULL)//开辟空间失败就报错结束
{
perror("node malloc");//节点开辟失败
return 1;//返回值为1代表节点开辟失败
}
memcpy(node->data, (char*)pos,pHead->size);//把数据拷贝到我们开的节点中
if (HEADINSERTION == Optional)//判断是否为头插
{
node->next = (pHead->list).next;
node->prev = &(pHead->list);
}
else if (BACKINSERTION == Optional)//判断是否为尾插
{
node->next = &pHead->list;
node->prev = pHead->list.prev;
}
else
{
return 2;//返回值为3代表插入位置不符合要求
}
node->prev->next = node;
node->next->prev = node;
return 0;//代表此函数正常结束
}
Aquí necesitamos eliminar la función que libera y abre espacio, solo necesitamos abrir el espacio para dos punteros y el tamaño del espacio de los datos pasados por el usuario para la estructura de lista doblemente enlazada.
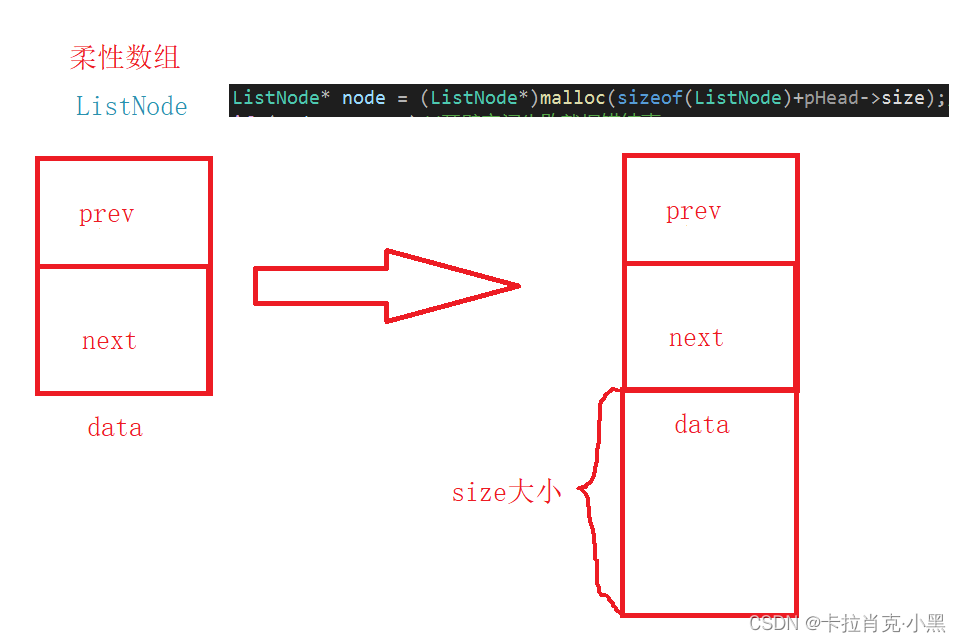
Los datos que copiamos se colocan en el área de datos.
void* ListFind(ListHead* pHead, const void* key, Cmp* cmp)//双向链表查找
{
assert(pHead);
ListNode* pos = find(pHead, key, cmp);
if (pos == &pHead->list)//如果是头节点,则证明没找到
{
return NULL;
}
return pos->data;//返会我们的数据区。
}
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp)//双向链表删除
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp, void* retu)//双向链表删除,并把删除节点返回
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
if (del->data != NULL)
{
memcpy(retu, del->data, pHead->size);//通过函数参数返回
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
Aquí eliminamos las funciones que liberan memoria en el área de datos y liberamos memoria, y agregamos el juicio de si es el nodo principal, porque nuestro nodo principal no tiene memoria en el área de datos.
Ejecute la prueba:
4. Encapsulación oculta de la lista circular doblemente enlazada principal
¡Nuestra encapsulación oculta se basa en la realización de dos cambios! ! !
1. Vista previa del archivo de encabezado encapsulado oculto de la lista doblemente enlazada del bucle de encabezado
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<time.h>
#define HEADINSERTION 1 //头插选项
#define BACKINSERTION 2 //尾插选项
typedef void Printf(const void*);//对用户传递的打印函数进行重命名
typedef int Cmp(const void*, const void*);//对用户传递的打印函数进行重命名
typedef struct ListNode//链表的节点
{
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
char data[];//传入的数据
}ListNode;
typedef struct ListHead //不一样的头节点
{
int size;//用来存储传入数据的大小
void (*destory)(struct ListHead* pHead);//双向链表销毁
void (*listprint)(struct ListHead* pHead, Printf* print);//双向链表打印
int (*listinsert)(struct ListHead* pHead, const void* pos, int Optional);//双向链表的插入
void* (*listfind)(struct ListHead* pHead, const void* key, Cmp* cmp);//双向链表查找
int (*listdestroy)(struct ListHead* pHead, const void* key, Cmp* cmp);//双向链表删除
int (*listtravel)(struct ListHead* pHead, const void* key, Cmp* cmp, void* retu);//双向链表删除,并把删除节点返回
ListNode list;//用来存储头节点的数据,柔性数组,这个必须放在最下方
}ListHead;
ListHead* ListCreate(int datasize);//用来创建特殊的头节点
Aquí configuramos todas las funciones que queremos implementar como punteros de función, de modo que los usuarios de funciones puedan llamarlas directamente a través de la estructura sin saber cómo se implementan nuestras funciones.
2. Cambios en la función de lista doblemente enlazada del primer bucle.
Estamos realizando cambios basados en el segundo, por lo que aquí solo mostramos el código modificado.
//提前声明
void Destory(struct ListHead* pHead);// 双向链表销毁
void ListPrint(struct ListHead* pHead, Printf* print);// 双向链表打印
int ListInsert(struct ListHead* pHead, const void* pos, int Optional);//双向链表的插入
void* ListFind(struct ListHead* pHead, const void* key,Cmp* cmp);//双向链表查找
int Listdestroy(struct ListHead* pHead, const void* key, Cmp* cmp);//双向链表删除
int Listtravel(struct ListHead* pHead, const void* key, Cmp* cmp,void* retu);//双向链表删除,并把删除节点返回
ListHead* ListCreate(int datasize)//用来创建特殊的头节点
{
ListHead* pHead = (ListHead*)malloc(sizeof(ListHead));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->size = datasize;
pHead->list.next = &pHead->list;//后继节点指向自己
pHead->list.prev = &pHead->list;//前驱节点指向自己
pHead->destory = Destory;//把我们封装函数指针指向相应的函数
pHead->listprint = ListPrint;
pHead->listinsert = ListInsert;
pHead->listfind = ListFind;
pHead->listdestroy = Listdestroy;
pHead->listtravel = Listtravel;
return pHead;
}
Cuando asignamos un puntero a función, primero debemos declarar la función a la que queremos apuntar, para que no se informe ningún error.
Modificación de la función de prueba:
#define NAME_SIZE 32
typedef struct Stu
{
int id;
char name[NAME_SIZE];
int math;
int chinese;
}Stu;
void Printf_s(const void* print)//用户写的打印函数
{
Stu* prin = (Stu*)print;
printf("id:%2d name:%s math:%2d chinese:%2d\n",prin->id, prin->name, prin->math, prin->chinese);
}
int cmp_id(const void* s1, const void*s2)//用户写的id比较函数
{
int *key = (int*)s1;
Stu *stu = (Stu*)s2;
return (*key - stu->id);
}
int cmp_name(const void* s1, const void* s2)//用户写的name比较函数
{
char* key = (char*)s1;
Stu* stu = (Stu*)s2;
return strcmp(key,stu->name);
}
void test1()
{
ListHead* pHead = ListCreate(sizeof(Stu));
Stu stu;
int i = 0;
for (i = 0; i < 5; i++)
{
stu.id = i;
snprintf(stu.name, NAME_SIZE, "stu%d:", i);
stu.math = rand()%100;
stu.chinese = rand()%100;
pHead->listinsert(pHead, &stu, 2);
}
pHead->listprint(pHead, Printf_s);// 双向链表打印
//链表元素的查找,通过id查找
printf("\n\n");
int id = 3;
Stu *st = pHead->listfind(pHead, &id, cmp_id);
if (st == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(st);
}
//链表元素的删除,通过id删除
printf("\n\n");
pHead->listdestroy(pHead, &id, cmp_id);
pHead->listprint(pHead, Printf_s);
//链表元素的删除,通过姓名删除
printf("\n\n");
char* p = "stu2:";//不要忘了加分号
Stu *s = &stu;
pHead->listtravel(pHead, p, cmp_name, s);
if (s == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(s);
}
printf("\n\n");
pHead->listprint(pHead, Printf_s);
pHead->destory(pHead);// 双向链表销毁
}
int main()
{
srand((unsigned)time(NULL));
test1();
return 0;
}
Necesitamos llamar a la parte de la estructura transpuesta que implementamos a través de la función.
5. Tome la iniciativa en encapsular la lista circular doble enlazada en una biblioteca.
¡Nuestra encapsulación como biblioteca también realiza cambios basados en la implementación 2! ! !
1. La lista circular de encabezado con doble enlace se encapsula como una vista previa del archivo de encabezado de la biblioteca.
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<time.h>
#define HEADINSERTION 1 //头插选项
#define BACKINSERTION 2 //尾插选项
//可以做出成一个动态库或静态库,不需要知道我们的结构体类型就可以操作构建一个结构体
typedef void ListHead;// 把void类型改为ListHead,我们函数进行传参都是用的void
typedef void Printf(const void* );//对用户传递的打印函数进行重命名
typedef int Cmp(const void*, const void*);//对用户传递的打印函数进行重命名
ListHead* ListCreate(int datasize);//用来创建特殊的头节点
void Destory(ListHead* pHead);// 双向链表销毁
void ListPrint(ListHead* pHead, Printf* print);// 双向链表打印
int ListInsert(ListHead* pHead, const void* pos, int Optional);//双向链表的插入
void* ListFind(ListHead* pHead, const void* key,Cmp* cmp);//双向链表查找
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp);//双向链表删除
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp,void* retu);//双向链表删除,并把删除节点返回
Aquí hemos implementado la ocultación de nuestra estructura. El usuario no conoce el tipo de nuestra estructura, solo sabe qué funciones puede lograr nuestra función, y los parámetros pasados son todos tipos de puntero vacío. Esto evita que los usuarios conozcan nuestro tipo de estructura y realicen cambios. Colocamos el tipo de estructura en el archivo fuente donde implementamos la función.
2. El archivo fuente para la implementación de la función de lista doblemente enlazada del primer bucle.
typedef struct ListNode//链表的节点
{
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
char data[];//传入的数据
}ListNode;
struct ListHead //不一样的头节点
{
int size;//用来存储传入数据的大小
ListNode list;//用来存储头节点的数据
};
ListHead* ListCreate(int datasize)//用来创建特殊的头节点
{
struct ListHead* pHead = (struct ListHead*)malloc(sizeof(struct ListHead));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->size = datasize;
pHead->list.next = &pHead->list;//后继节点指向自己
pHead->list.prev = &pHead->list;//前驱节点指向自己
return pHead;
}
void Destory(ListHead* p)// 双向链表销毁
{
assert(p);
struct ListHead *pHead = p;
ListNode* pos = (&pHead->list)->next;//从头节点的下一个节点开始
while (pos != &pHead->list)
{
ListNode* del = pos;//要释放的节点
pos = pos->next;//保存下一个节点
free(del);
}
}
void ListPrint(ListHead* p, Printf * print)// 双向链表打印,使用回调函数
{
assert(p);
struct ListHead* pHead = p;
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
print(pos->data);//调用用户提供的打印函数
pos = pos->next;
}
}
int ListInsert(ListHead* p, const void* pos, int Optional)//双向链表的插入
{
assert(p);
struct ListHead* pHead = p;
ListNode* node = (ListNode*)malloc(sizeof(ListNode)+pHead->size);//申请一个节点结构体的大小加上用户所传数据大小
if (node == NULL)//开辟空间失败就报错结束
{
perror("node malloc");//节点开辟失败
return 1;//返回值为1代表节点开辟失败
}
memcpy(node->data, (char*)pos,pHead->size);//把数据拷贝到我们开的节点中
if (HEADINSERTION == Optional)//判断是否为头插
{
node->next = (pHead->list).next;
node->prev = &(pHead->list);
}
else if (BACKINSERTION == Optional)//判断是否为尾插
{
node->next = &pHead->list;
node->prev = pHead->list.prev;
}
else
{
return 2;//返回值为3代表插入位置不符合要求
}
node->prev->next = node;
node->next->prev = node;
return 0;//代表此函数正常结束
}
ListNode* find(ListHead* p, const void* key, Cmp* cmp)//双向链表查找
{
assert(p);
struct ListHead* pHead = p;
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
if (cmp(key, pos->data) == 0)//调用用户提供的比较函数
{
break;
}
pos = pos->next;
}
return pos;//如果找到时,循环终止,返回值为找到的节点,如果找不到,则返回pos为头节点。
}
void* ListFind(ListHead* p, const void* key, Cmp* cmp)//双向链表查找
{
assert(p);
struct ListHead* pHead = p;
ListNode* pos = find(pHead, key, cmp);
if (pos == &pHead->list)//如果是头节点,则证明没找到
{
return NULL;
}
return pos->data;//返会我们的数据区。
}
int Listdestroy(ListHead* p, const void* key, Cmp* cmp)//双向链表删除
{
assert(p);
struct ListHead* pHead = p;
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
int Listtravel(ListHead* p, const void* key, Cmp* cmp, void* retu)//双向链表删除,并把删除节点返回
{
assert(p);
struct ListHead* pHead = p;
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
if (del->data != NULL)
{
memcpy(retu, del->data, pHead->size);//通过函数参数返回
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
Lo que cambiamos es convertir el puntero de tipo vacío al tipo de nuestra propia estructura en la función que implementamos.
Nuestra función de prueba es la misma que implementamos 2.
3. Tome la iniciativa en encapsular la lista circular doble enlazada en una biblioteca.
1. Busque el proyecto, seleccione Propiedades y, en las propiedades de configuración, cambie el tipo de configuración a biblioteca estática (.lib).
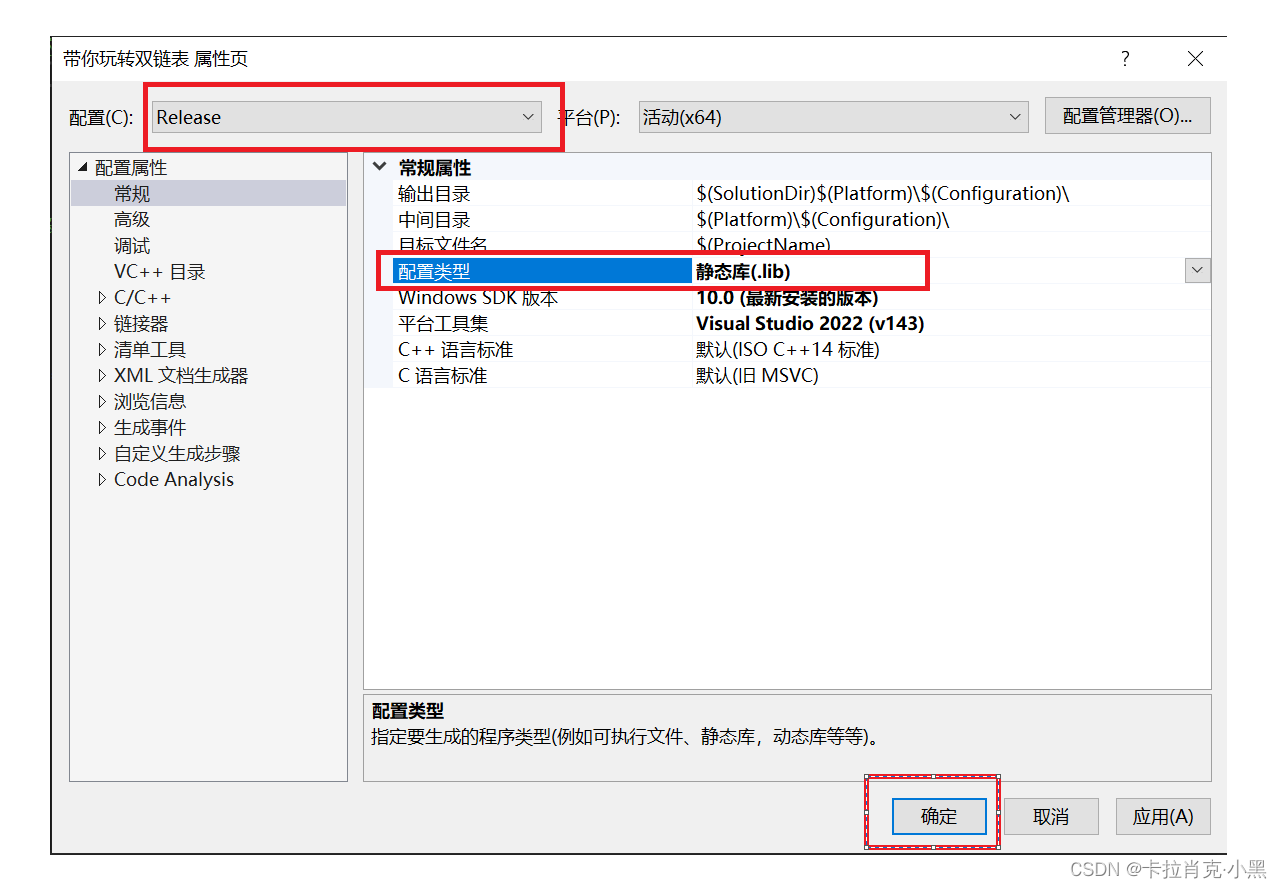
2. Generar
3. Busque nuestro archivo .lib en nuestro archivo de proyecto, que es la biblioteca estática generada.
6. Analice parte de la lista doblemente enlazada del kernel para implementar rápidamente una lista doblemente enlazada.
1. Análisis parcial de la lista doble enlazada del kernel.

El puntero de nodo de tiempo más importante en la lista vinculada, miramos la estructura de la lista vinculada en el kernel, no hay ningún área de datos en ella, necesitamos incluir su estructura en nuestra estructura para crear una lista doblemente vinculada. Puede aparecer en cualquier parte de nuestra estructura.
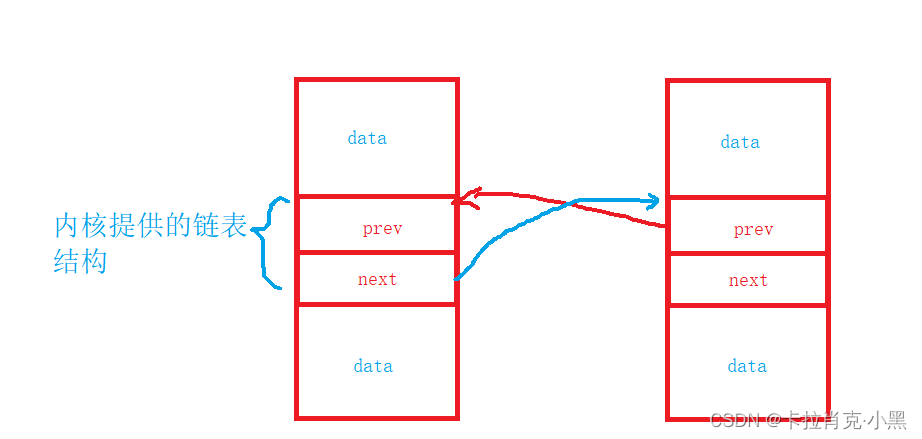

La inserción de cabeza y la inserción de cola implementadas aquí son funciones definidas, y luego llamamos a esta función para realizar nuestra inserción y eliminación.
2. Implemente rápidamente una lista circular doble enlazada inicial simple
typedef struct ListNode//链表的节点
{
int data;
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
}ListNode;
ListNode* ListCreate()//用来创建头节点
{
ListNode* pHead = (ListNode*)malloc(sizeof(ListNode));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->data = 0;
pHead->next = pHead;//后继节点指向自己
pHead->prev = pHead;//前驱节点指向自己
return pHead;
}
void Destory(ListNode* pHead)// 双向链表销毁
{
assert(pHead);
ListNode* pos = pHead->next;//从头节点的下一个节点开始
while (pos != pHead)
{
ListNode* del = pos;//要释放的节点
pos = pos->next;//保存下一个节点
free(del);//释放节点
}
}
void ListPrint(ListNode* pHead)// 双向链表打印
{
assert(pHead);
ListNode* pos = pHead->next;//从头节点的下一个节点开始
while (pos != pHead)
{
printf("%d->", pos->data);
pos = pos->next;
}
printf("\n");
}
void ListInsert(ListNode* pos, int key)//双向链表的插入
{
assert(pos);
ListNode* init = (ListNode*)malloc(sizeof(ListNode));
if (init == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
init->data = key;
init->next = pos->next;
init->prev = pos;
pos->next->prev = init;
pos->next = init;
}
void Listdestroy(ListNode* pHead,ListNode* pos)//双向链表删除
{
assert(pos);
if (pos == pHead)
{
return;
}
ListNode* del = pos;
pos->prev->next = pos->next;
pos->next->prev = pos->prev;
free(del);
}
void SListPushBack(ListNode* pHead, int x)//单链表尾插
{
assert(pHead);
ListInsert(pHead->prev, x);
}
void SListPushFront(ListNode* pHead, int x)//单链表的头插
{
assert(pHead);
ListInsert(pHead, x);
}
void SListPopBack(ListNode* pHead)// 单链表的尾删
{
assert(pHead);
Listdestroy(pHead,pHead->prev);
}
void SListPopFront(ListNode* pHead)// 单链表头删
{
assert(pHead);
Listdestroy(pHead,pHead->next);
}
ListNode* ListFind(ListNode* pHead, int key)//双向链表查找
{
assert(pos);
ListNode* pos = pHead->next;
while (pos != pHead)
{
if (pos->data == key)
{
return pos;
}
pos = pos->next;
}
return NULL;
}
Según el código anterior, podemos ver que solo necesitamos implementar la inserción y eliminación de la lista doblemente enlazada para realizar la mayoría de las funciones de la lista doblemente enlazada.
Creo que a través de tantos casos y ejercicios, todos comprenden la implementación y el uso de listas doblemente vinculadas, implementémoslo usted mismo.
Siete, lista doblemente enlazada para lograr 2 códigos
Dado que nuestras bibliotecas de encapsulación y composición posteriores se modifican a través de 2, echemos un vistazo más de cerca al código que implementa 2.
1. El archivo de encabezado del código de implementación 2 de la lista doblemente enlazada
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<time.h>
#define HEADINSERTION 1 //头插选项
#define BACKINSERTION 2 //尾插选项
typedef struct ListNode//链表的节点
{
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
char data[];//传入的数据
//char data[1];//传入的数据
}ListNode;
typedef struct ListHead //不一样的头节点
{
int size;//用来存储传入数据的大小
ListNode list;//用来存储头节点的数据
}ListHead;
typedef void Printf(const void* );//对用户传递的打印函数进行重命名
typedef int Cmp(const void*, const void*);//对用户传递的打印函数进行重命名
ListHead* ListCreate(int datasize);//用来创建特殊的头节点
void Destory(ListHead* pHead);// 双向链表销毁
void ListPrint(ListHead* pHead, Printf* print);// 双向链表打印
int ListInsert(ListHead* pHead, const void* pos, int Optional);//双向链表的插入
void* ListFind(ListHead* pHead, const void* key,Cmp* cmp);//双向链表查找
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp);//双向链表删除
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp,void* retu);//双向链表删除,并把删除节点返回
2. Archivo fuente de implementación de 2 funciones de lista doblemente enlazada
#include"main2.h"
ListHead* ListCreate(int datasize)//用来创建特殊的头节点
{
ListHead* pHead = (ListHead*)malloc(sizeof(ListHead));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->size = datasize;
pHead->list.next = &pHead->list;//后继节点指向自己
pHead->list.prev = &pHead->list;//前驱节点指向自己
return pHead;
}
void Destory(ListHead* pHead)// 双向链表销毁
{
assert(pHead);
ListNode* pos = (&pHead->list)->next;//从头节点的下一个节点开始
while (pos != &pHead->list)
{
ListNode* del = pos;//要释放的节点
pos = pos->next;//保存下一个节点
free(del);
}
}
void ListPrint(ListHead* pHead, Printf * print)// 双向链表打印,使用回调函数
{
assert(pHead);
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
print(pos->data);//调用用户提供的打印函数
pos = pos->next;
}
}
int ListInsert(ListHead* pHead, const void* pos, int Optional)//双向链表的插入
{
assert(pHead);
ListNode* node = (ListNode*)malloc(sizeof(ListNode)+pHead->size);//申请一个节点结构体的大小加上用户所传数据大小
if (node == NULL)//开辟空间失败就报错结束
{
perror("node malloc");//节点开辟失败
return 1;//返回值为1代表节点开辟失败
}
memcpy(node->data, (char*)pos,pHead->size);//把数据拷贝到我们开的节点中
if (HEADINSERTION == Optional)//判断是否为头插
{
node->next = (pHead->list).next;
node->prev = &(pHead->list);
}
else if (BACKINSERTION == Optional)//判断是否为尾插
{
node->next = &pHead->list;
node->prev = pHead->list.prev;
}
else
{
return 2;//返回值为3代表插入位置不符合要求
}
node->prev->next = node;
node->next->prev = node;
return 0;//代表此函数正常结束
}
ListNode* find(ListHead* pHead, const void* key, Cmp* cmp)//双向链表查找
{
assert(pHead);
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
if (cmp(key, pos->data) == 0)//调用用户提供的比较函数
{
break;
}
pos = pos->next;
}
return pos;//如果找到时,循环终止,返回值为找到的节点,如果找不到,则返回pos为头节点。
}
void* ListFind(ListHead* pHead, const void* key, Cmp* cmp)//双向链表查找
{
assert(pHead);
ListNode* pos = find(pHead, key, cmp);
if (pos == &pHead->list)//如果是头节点,则证明没找到
{
return NULL;
}
return pos->data;//返会我们的数据区。
}
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp)//双向链表删除
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp, void* retu)//双向链表删除,并把删除节点返回
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
if (del->data != NULL)
{
memcpy(retu, del->data, pHead->size);//通过函数参数返回
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
3. Implementación de lista doblemente enlazada 2 archivo fuente de función principal
#include"main2.h"
#define NAME_SIZE 32
typedef struct Stu
{
int id;
char name[NAME_SIZE];
int math;
int chinese;
}Stu;
void Printf_s(const void* print)//用户写的打印函数
{
Stu* prin = (Stu*)print;
printf("id:%2d name:%s math:%2d chinese:%2d\n",prin->id, prin->name, prin->math, prin->chinese);
}
int cmp_id(const void* s1, const void*s2)//用户写的比较函数
{
int *key = (int*)s1;
Stu *stu = (Stu*)s2;
return (*key - stu->id);
}
int cmp_name(const void* s1, const void* s2)//用户写的name比较函数
{
char* key = (char*)s1;
Stu* stu = (Stu*)s2;
return strcmp(key, stu->name);
}
void test1()
{
ListHead* pHead = ListCreate(sizeof(Stu));
Stu stu;
int i = 0;
for (i = 0; i < 5; i++)
{
stu.id = i;
snprintf(stu.name, NAME_SIZE, "stu%d:", i);
stu.math = rand()%100;
stu.chinese = rand()%100;
ListInsert(pHead, &stu, 1);//传入1,进行头插
//ListInsert(pHead, &stu, 2);//传入2,进行尾插
}
ListPrint(pHead, Printf_s);// 双向链表打印
//链表元素的查找,通过id查找
printf("\n\n");
int id = 3;
Stu *st = ListFind(pHead, &id, cmp_id);
if (st == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(st);
}
//链表元素的删除,通过id删除
printf("\n\n");
Listdestroy(pHead, &id, cmp_id);
ListPrint(pHead, Printf_s);
//链表元素的删除并且返回,通过姓名删除
printf("\n\n");
char* p = "stu2:";//不要忘了加分号
Stu *s = &stu;
Listtravel(pHead, p, cmp_name, s);
if (s == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(s);
}
printf("\n\n");
ListPrint(pHead, Printf_s);
Destory(pHead);// 双向链表销毁
}
int main()
{
srand((unsigned)time(NULL));
test1();
return 0;
}
Resumir
Creo que todos ya tienen un conocimiento profundo de nuestra lista de doble enlace. Esta lista circular principal será la estructura que más usaremos , por lo que esto requiere que tengamos un conocimiento y un dominio profundos. Todos son bienvenidos a dejar un mensaje. Gracias por el apoyo.