목차 제목
목록 소개
- 리스트는 상수 범위 내의 어느 위치에나 삽입 및 삭제가 가능한 순차적 컨테이너이며, 컨테이너는 양방향으로 반복될 수 있습니다.
- 리스트의 맨 아래 레이어는 이중 연결 리스트 구조로, 이중 연결 리스트의 각 요소는 서로 연관되지 않은 독립 노드에 저장되며, 포인터는 노드의 이전 요소와 다음 요소를 가리킨다.
- list는 forward_list와 매우 유사합니다. 주요 차이점은 forward_list가 단일 연결 목록이고 앞으로만 반복할 수 있어 더 간단하고 효율적이라는 것입니다.
- 다른 순차 컨테이너(배열, 벡터, 데크)와 비교할 때 목록은 일반적으로 어떤 위치에서든 요소를 삽입하고 제거하는 데 더 나은 성능을 발휘합니다.
- 다른 순차 컨테이너와 비교했을 때 list와 Forward_list의 가장 큰 결함은 임의의 위치에서 임의 액세스를 지원하지 않는다는 것입니다. 예를 들어 목록의 여섯 번째 요소에 액세스하려면 알려진 위치(예: 헤드 또는 tail)을 반복하는 데 선형 시간 오버헤드가 필요한 위치로 이동합니다. 또한 목록에는 각 노드에 대한 관련 정보를 보관하기 위한 추가 공간이 필요합니다(이는 더 작은 유형의 요소를 저장하는 대규모 목록의 경우 중요한 요소일 수 있습니다).
목록 정의
가장 먼저 알아야 할 것은 목록이 클래스 템플릿이라는 것입니다. 목록을 사용하여 객체를 생성할 때 표시하고 인스턴스화해야 합니다. 그런 다음
여기 템플릿은 두 가지 유형을 제공합니다. 첫 번째 유형은 데이터 저장 유형이고 두 번째 유형은 첫 번째 유형입니다. 메모리 풀에 관한 것입니다. 여기서는 기본 유형이 제공되므로 여기서는 처리할 필요가 없습니다. 이 유형의 생성자를 다시 살펴보겠습니다.

이들은 네 가지 다른 목록 생성자입니다. 여기에서는 벡터와 마찬가지로 메모리 풀이 공간을 적용하는 데 사용되므로 여기에 매개변수가 하나 더 있다는 것을 알 수 있습니다.
const allocator_type& alloc = allocator_type()
하지만 다행스럽게도 여기에는 기본값이 제공되어 초보자가 매개 변수를 전달할 필요가 없지만 나중에 레벨이 매우 높아서 라이브러리의 메모리 풀이 제대로 작성되지 않은 것이 마음에 들지 않으면 메모리 풀을 작성할 수 있습니다. 우리 자신을 매개 변수로 사용하고 전달하면 우리는 모두 초보자이므로 너무 걱정하지 마십시오. 이 함수의 size_type은 부호 없는 정수를 의미합니다.

value_type은 첫 번째 템플릿 매개변수의 유형을 의미합니다.

첫 번째 형태:
explicit list (const allocator_type& alloc = allocator_type());
이것이 의미하는 바는 매개변수 없는 생성은 이 생성자에 의해 생성된 목록 객체에 내용이 없다는 것을 의미합니다(예: 다음 코드).
void test1()
{
list<int> l1;
list<int>::iterator it = l1.begin();
while (it!=l1.end())
{
cout << *it << " ";
++it;
}
}
이 코드를 실행하면 여기에 아무것도 인쇄되지 않은 것을 알 수 있습니다.
두 번째 형식은 다음과 같습니다.
explicit list (size_type n, const value_type& val = value_type(),
const allocator_type& alloc = allocator_type());
n개의 동일한 데이터를 사용하여 초기화합니다. 여기서 두 번째 매개변수를 전달하거나 전달하지 않을 수 있습니다. 그렇지 않은 경우 해당 유형의 기본 생성자가 할당을 위해 호출됩니다. 예를 들어 다음 코드는 다음과 같습니다.
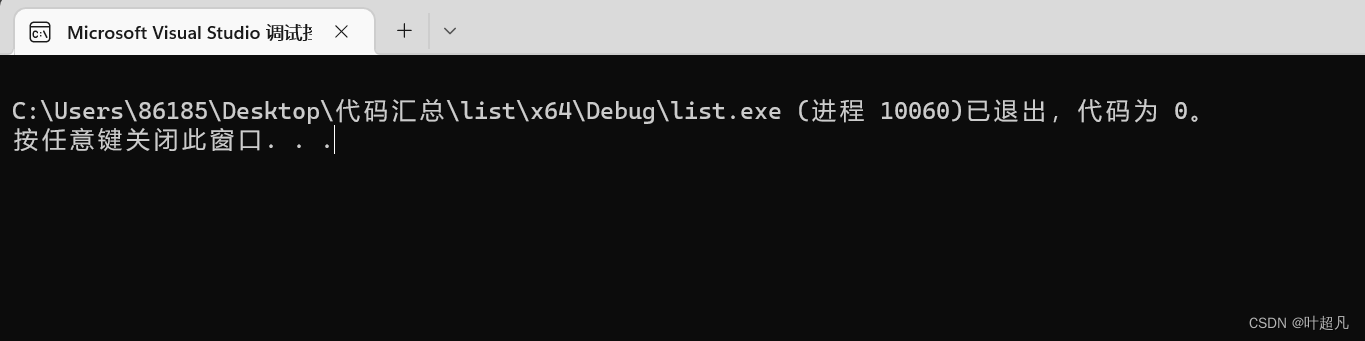
list<int> l1(10, 3);
list<int> l2(10);
cout << "l1的内容为:";
for (auto l : l1)
{
cout << l;
}
cout << endl;
cout << "l2的内容为:" ;
for (auto l : l2)
{
cout << l;
}
코드를 실행한 결과는 다음과 같습니다.
세 번째 형식:
template <class InputIterator>
list (InputIterator first, InputIterator last,
const allocator_type& alloc = allocator_type());
다음 코드와 같이 초기화를 위해 반복기 범위를 사용합니다.
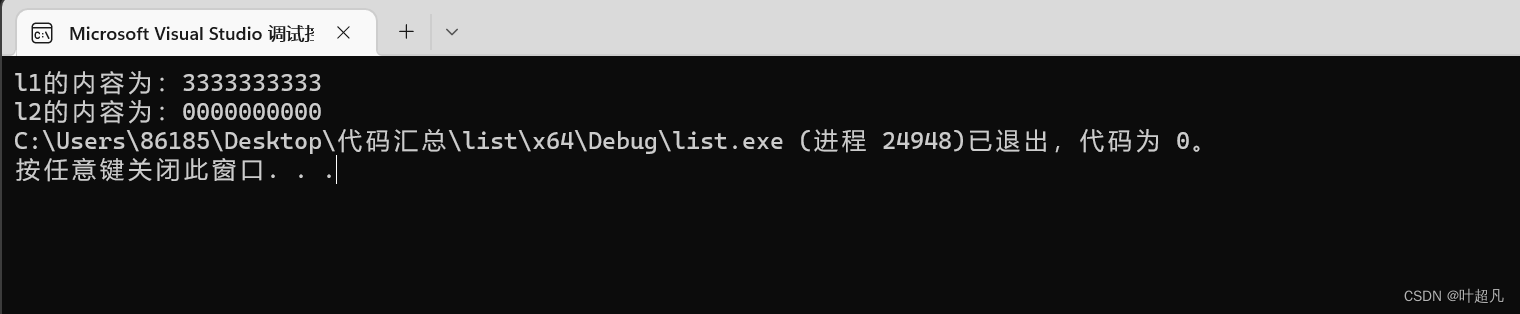
list<int>l1(5, 2);
list<int>::iterator it1 = l1.begin();
list<int>l2(++it1,--l1.end());
cout << "l1的内容为:";
for (auto l : l1)
{
cout << l;
}
cout << endl;
cout << "l2的内容为:" ;
for (auto l : l2)
{
cout << l;
}
여기서 모두가 주목해야 할 점은 목록의 반복자는 이전 문자열 및 벡터의 반복자처럼 해당 위치를 가리키는 상수를 추가할 수 없다는 점입니다. 위 코드를 실행한 결과는 다음과 같습니다.
네 번째 형식:
list (const list& x);
동일한 형식의 다른 목록 개체를 사용하여 개체를 초기화하면 여기서 사용 방법은 다음과 같습니다.
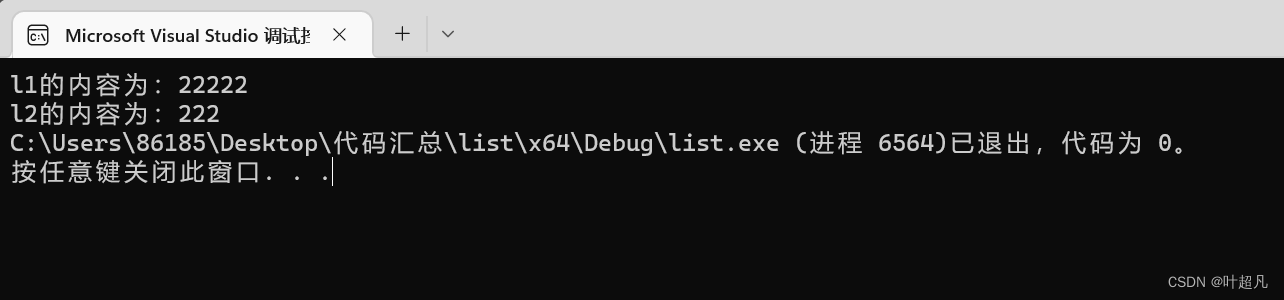
list<int>l1(5, 2);
list<int>l2(l1);
cout << "l1的内容为:";
for (auto l : l1)
{
cout << l;
}
cout << endl;
cout << "l2的内容为:";
for (auto l : l2)
{
cout << l;
}
이 코드를 실행한 결과는 다음과 같습니다.
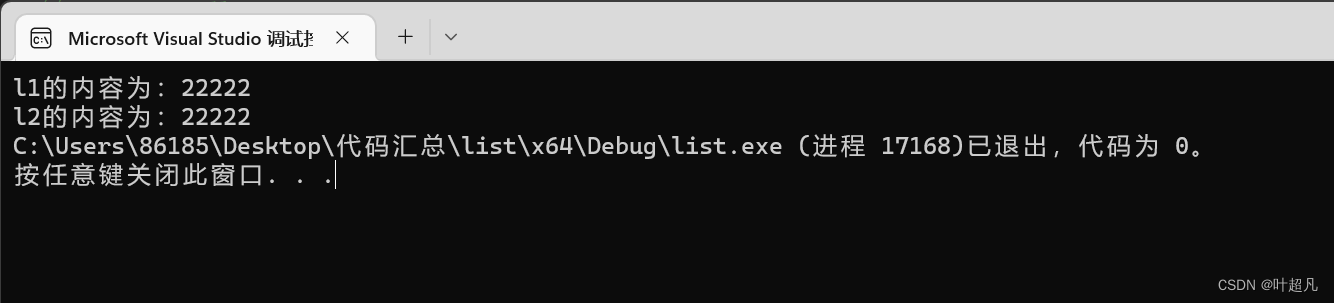
목록 순회
이전 문자열 및 벡터와의 차이점은 여기서 우리의 목록은 데이터를 순회하고 수정하기 위해 []를 사용하지 않는다는 것입니다. 문자열과 벡터는 모두 데이터를 연속적인 공간에 저장하고 목록이 다르기 때문에 데이터가 다른 위치에 저장됩니다. 그리고 이 데이터들은 포인터를 통해 서로 관련되어 있습니다. 그러면 여기에서 대괄호를 사용할 수 없는 이유를 배열을 사용하여 이해할 수 있습니다. 우선 배열 이름이 첫 번째 요소의 주소이고, 배열은 A 연속 범위에 있으며 각 요소의 주소 차이는 4입니다.
int arr[10]={
1,2,3,4,5,6,7,8,9,10};
arr 여기에는 이 배열의 첫 번째 요소인 1을 가리키는 주소가 있습니다. 이 형식을 사용하여 데이터에 액세스하는 경우:
int i=0;
cout<<arr[1]<<endl;
컴파일러는 여기서 arr[1]을 포인터 역참조 형식으로 변환합니다. *(arr + i)arr은 첫 번째 요소의 주소입니다. 주소 유형은 int* 유형입니다. 여기서 i가 0과 같을 때 여기의 주소는 변경되지 않습니다. 여기 i 값에 1을 추가하면 데이터 유형이 int이므로 여기 주소에 4가 추가되어 여기 포인터가 다음 요소를 가리킵니다. , 두 번째 요소를 얻었으므로 의문이 생깁니다. 리스트의 요소는 연속적인 공간에 있지 않습니다. [ ]를 사용하여 요소를 얻을 때 해당 요소는 1을 더하고 1을 빼서 얻을 수 있습니까? 내부 가치? 이는 분명히 작동하지 않으므로 목록 요소 탐색의 경우 반복자 탐색을 사용할 수 있습니다(예: 다음 코드).
void test2()
{
list<int> l1(10, 4);
list<int>::iterator it1 = l1.begin();
while (it1 != l1.end())
{
cout << *it1 << " ";
++it1;
}
}
이 코드의 실행 결과는 다음과 같습니다.

range for의 맨 아래 레이어는 반복자에 의해 구현되므로 range for도 목록 순회를 구현할 수 있습니다.
void test2()
{
list<int> l1(10, 4);
list<int>::iterator it1 = l1.begin();
while (it1 != l1.end())
{
cout << *it1 << " ";
++it1;
}
cout << endl;
for (auto l : l1)
{
cout << l << " ";
}
}
코드를 실행한 결과는 다음과 같습니다.
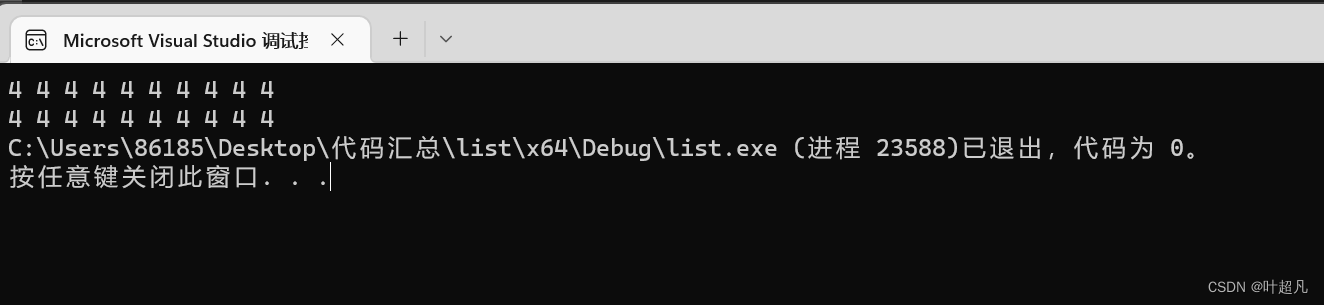
그러면 위의 내용이 리스트 순회 내용입니다.
목록 데이터 삽입
push_back
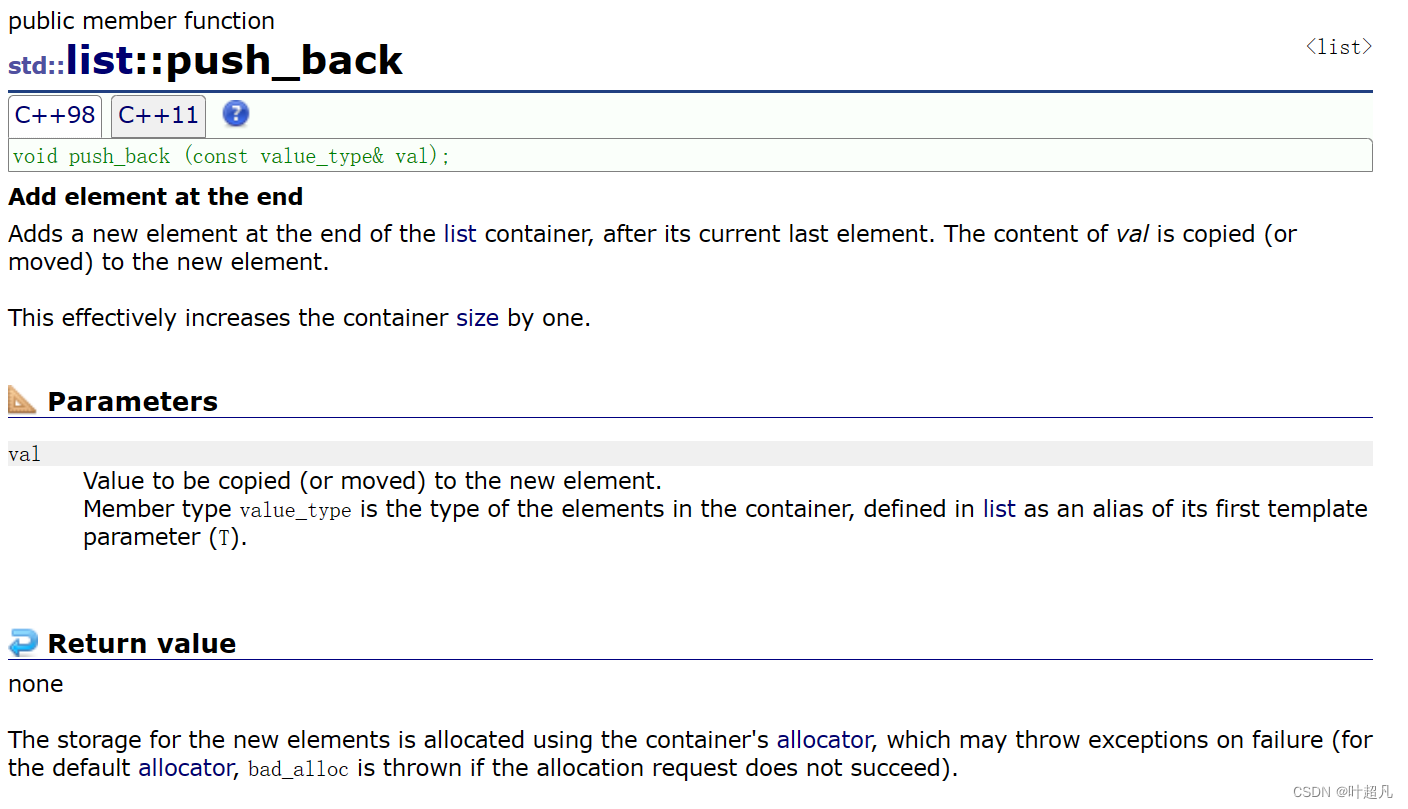
이 함수의 기능은 목록 객체의 끝에 데이터를 삽입하는 것으로, 다음 코드를 통해 이 함수의 기능을 확인할 수 있습니다.
void test3()
{
list<int> l1(5, 4);
l1.push_back(2);
for (auto l : l1)
{
cout << l << " ";
}
}
이 코드를 실행한 결과는 다음과 같습니다.
push_front
리스트의 데이터가 연속적인 공간에 있지 않기 때문에 객체의 선두에 내용을 삽입하면 데이터가 이동하지 않으므로 이 타입에서는 push_front 함수를 제공합니다. 이 함수의 사용 형태는 다음과 같습니다
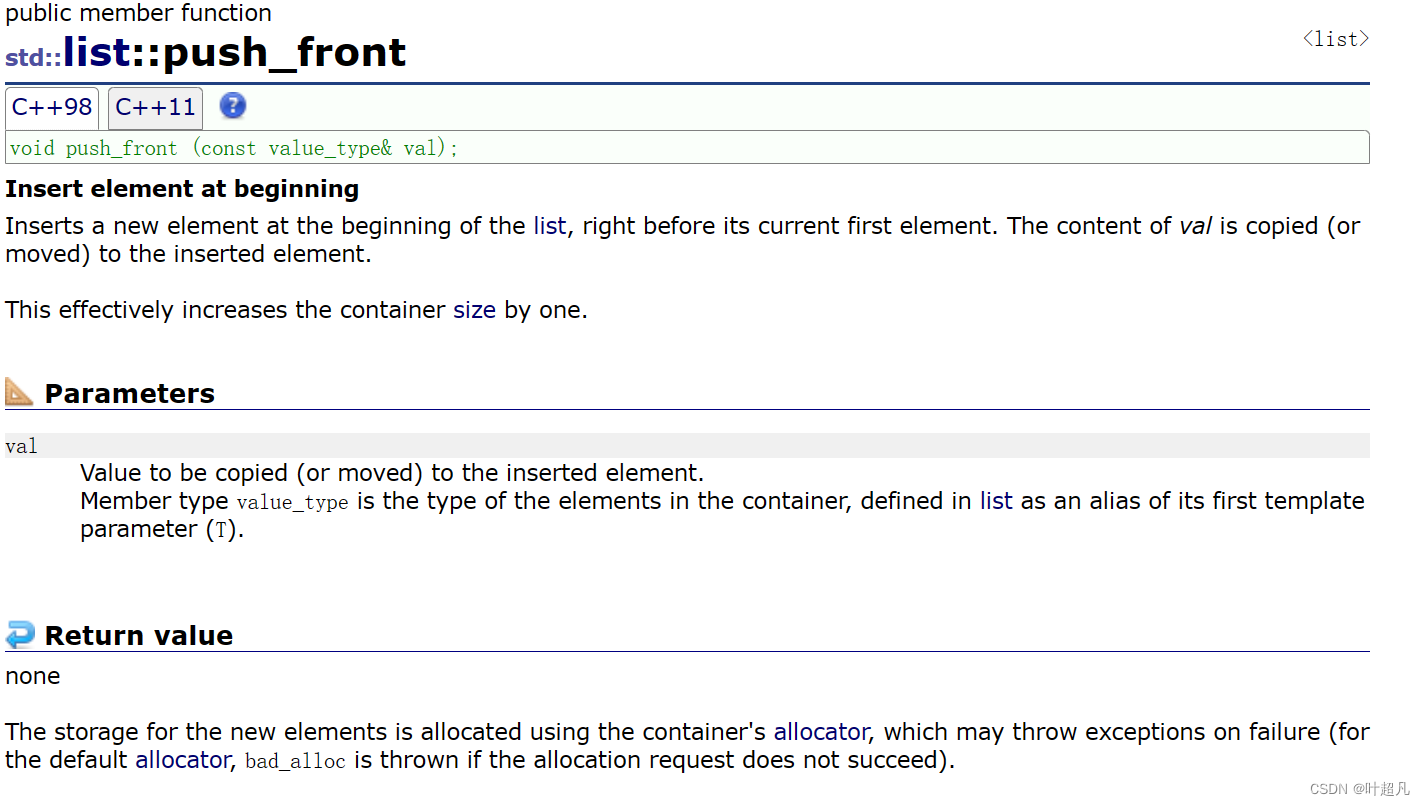
.
void test3()
{
list<int> l1(5, 4);
l1.push_back(2);
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
l1.push_front(1);
for (auto l : l1)
{
cout << l << " ";
}
}
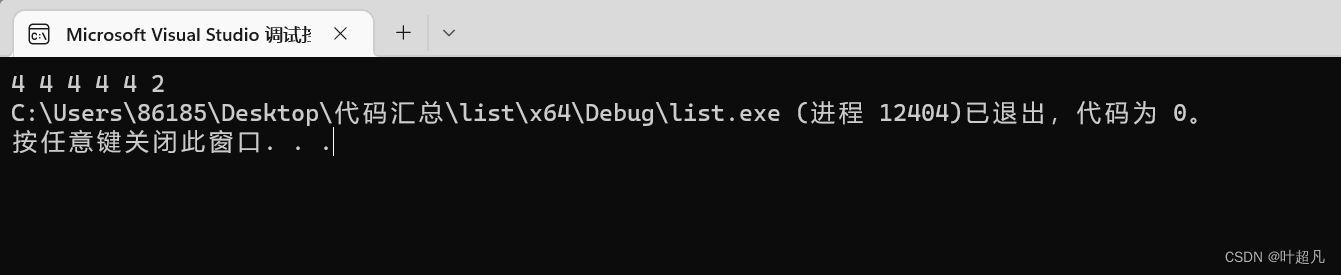
코드를 실행한 결과는 다음과 같습니다.

끼워 넣다
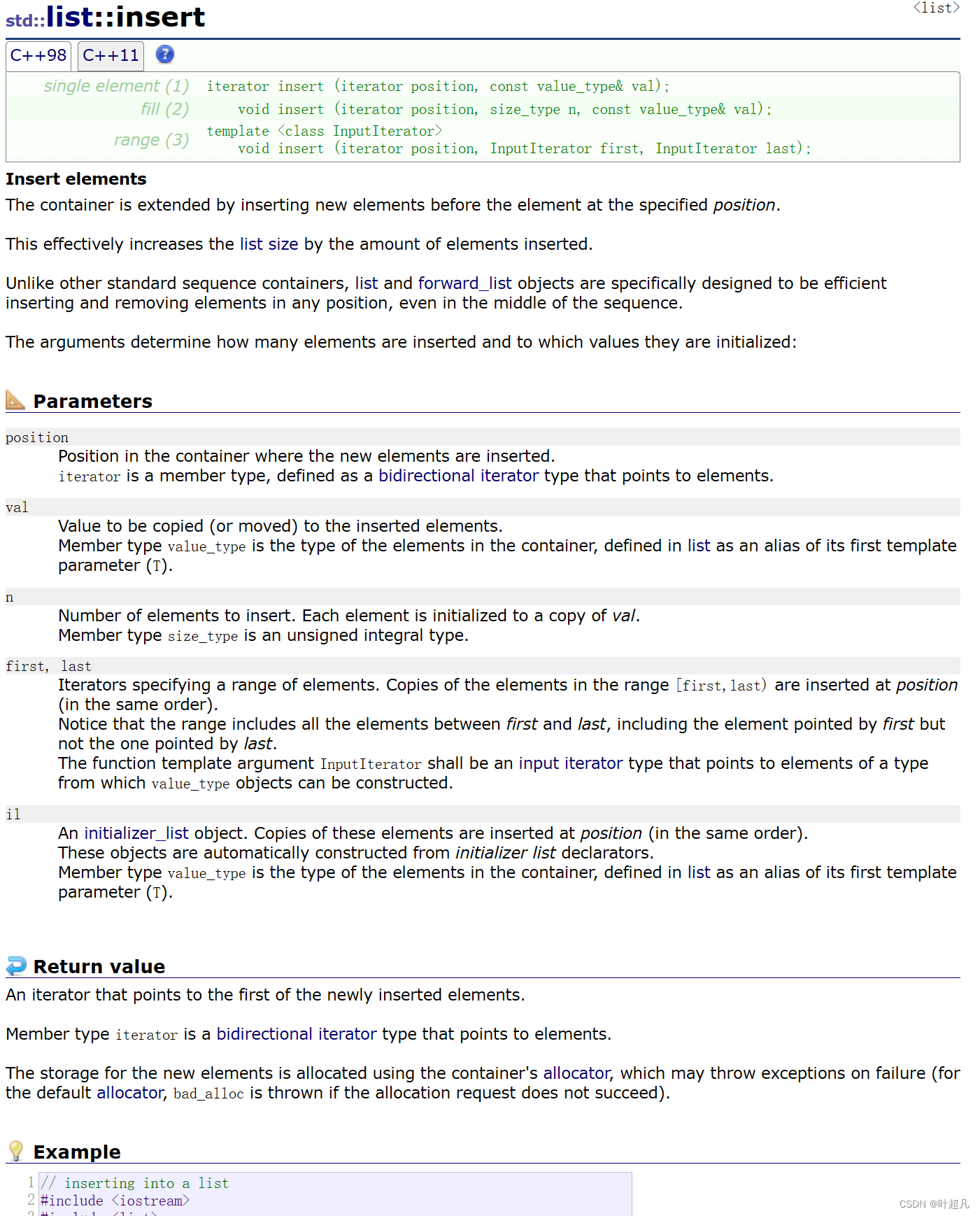
위의 두 함수는 객체의 머리 부분과 끝 부분에만 데이터를 삽입할 수 있으며 한 번에 한 개의 데이터만 삽입할 수 있습니다. 그러면 여기의 삽입 함수는 임의의 위치에 하나의 데이터를 삽입하거나 n개의 데이터를 삽입할 수 있습니다. 한 번에 동일한 데이터 또는 다른 개체의 데이터 조각 삽입을 사용하려면 반복자를 사용해야 하며 목록의 반복자는 정수를 더하거나 빼서 지정된 위치를 가리킬 수 없으므로 여기서 반복자는 라이브러리에서 find 함수를 사용해야 합니다.
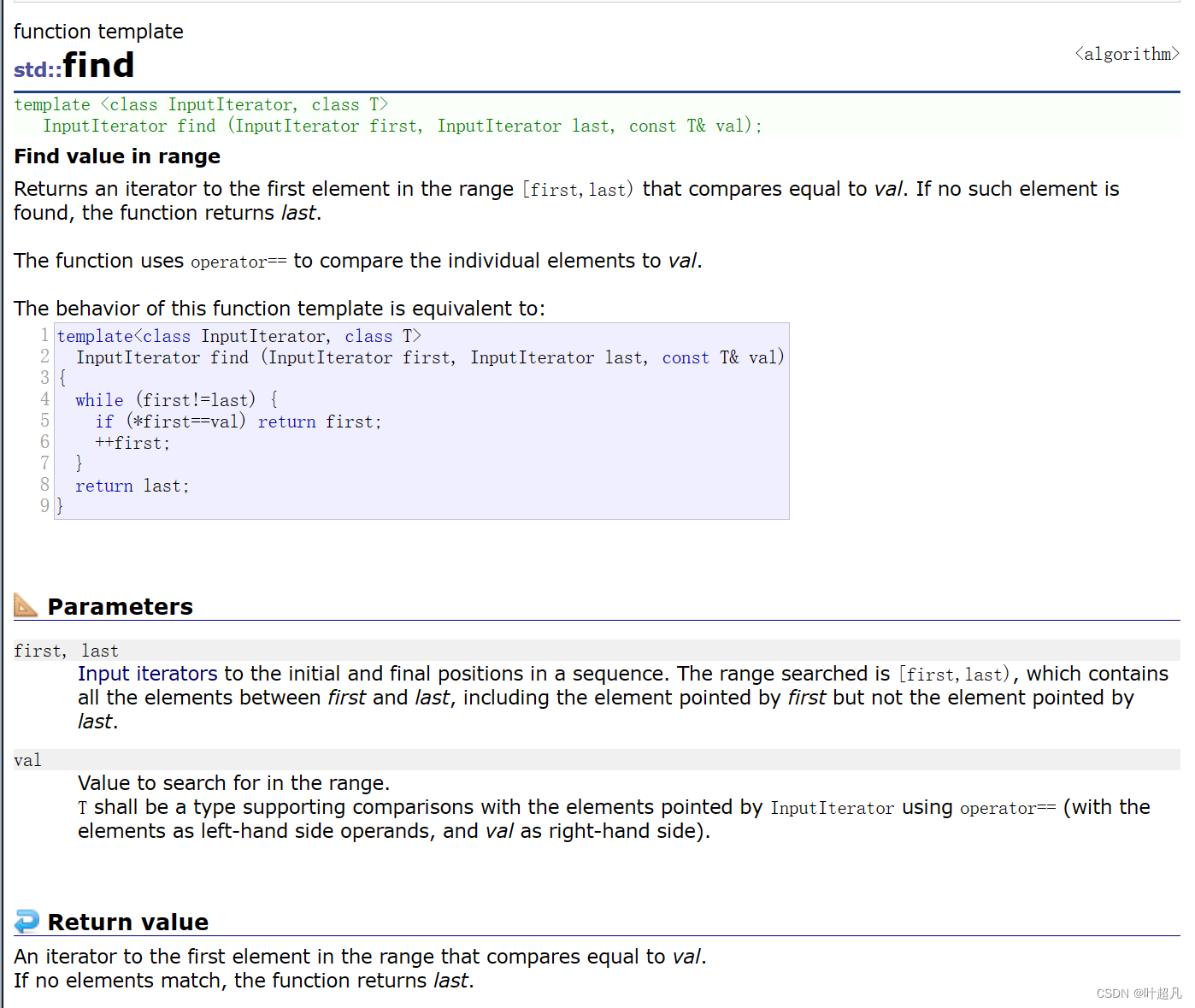
이 함수의 반환 유형은 반복자 유형이므로 이 함수의 반환 값을 사용하여 반복자를 초기화한 다음 삽입 함수를 더 잘 사용할 수 있습니다.여기서 사용 코드는 다음과 같습니다.
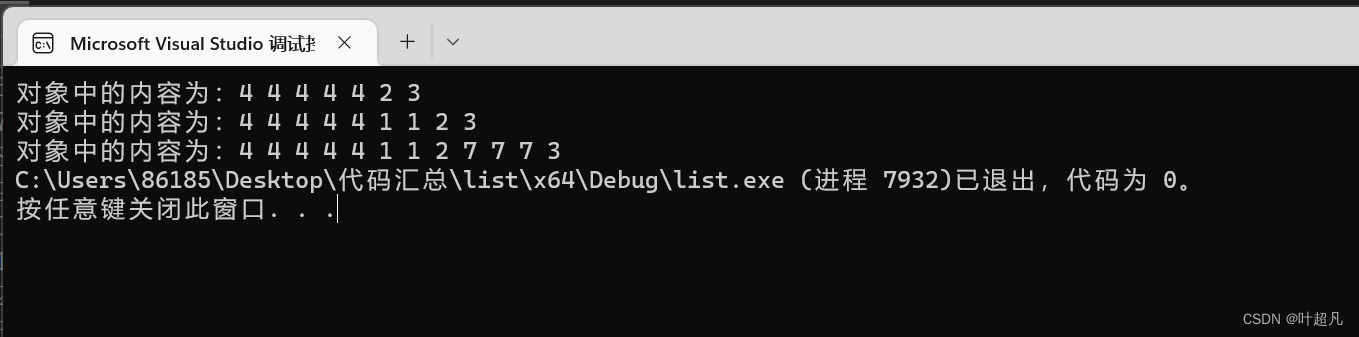
void test4()
{
list<int> l1(5,4);
l1.push_back(3);
list<int> ::iterator it1 = find(l1.begin(), l1.end(), 3);
it1=l1.insert(it1, 2);//指定位置插入一个数据,并更新迭代器的位置
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "对象中的内容为:";
l1.insert(it1,2, 1);//指定位置插入n个相同的数据
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
it1 = find(l1.begin(), l1.end(), 3);//再更新it1的值使其再指向原来的3
list<int> l2(3, 7);
cout << "对象中的内容为:";
l1. insert(it1, l2.begin(), l2.end());//指定位置插入一段数据
for (auto l : l1)
{
cout << l << " ";
}
}
그러면 이 코드를 실행한 결과는 다음과 같습니다.
목록삭제
팝백
이 함수의 기능은 tail 데이터를 삭제하는 것입니다.
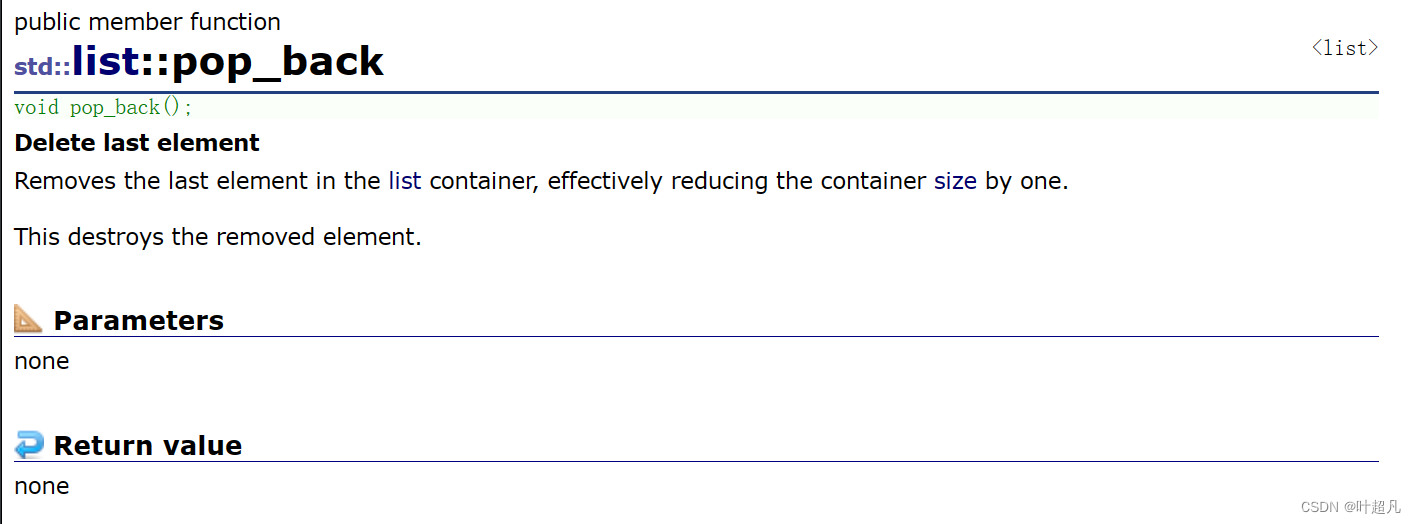
코드는 다음과 같이 사용됩니다.
void test5()
{
list<int> l1(5, 4);
l1.push_back(3);
l1.push_front(5);
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
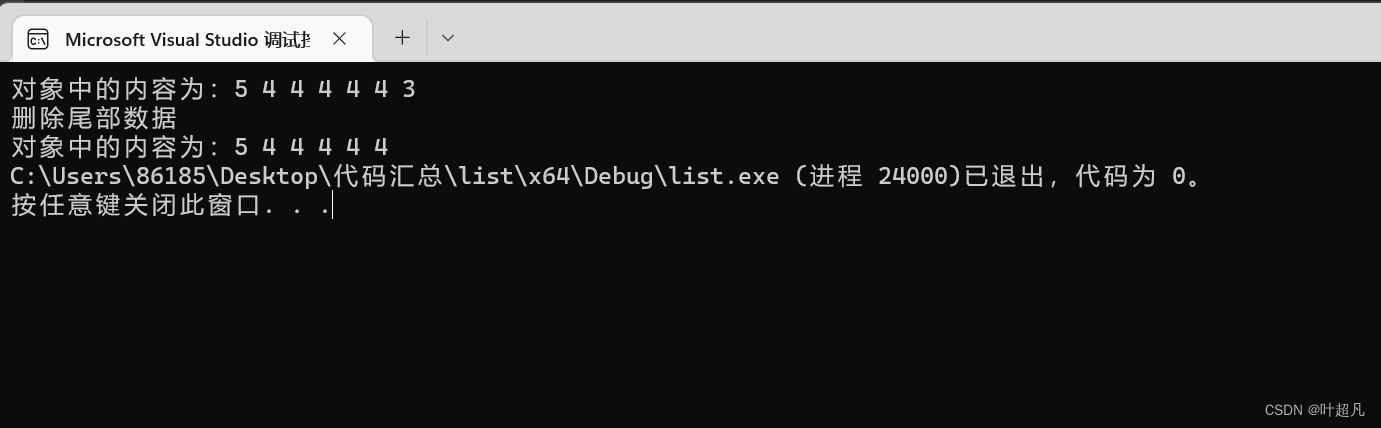
cout << "删除尾部数据"<<endl;
l1.pop_back();
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
}
코드를 실행한 결과는 다음과 같습니다.
팝 프론트
연결리스트이기 때문에 헤드에서 데이터를 삭제해도 데이터는 이동하지 않으므로 pop_front 함수가 있는데, 이 함수에 대한 소개는 다음과 같습니다.
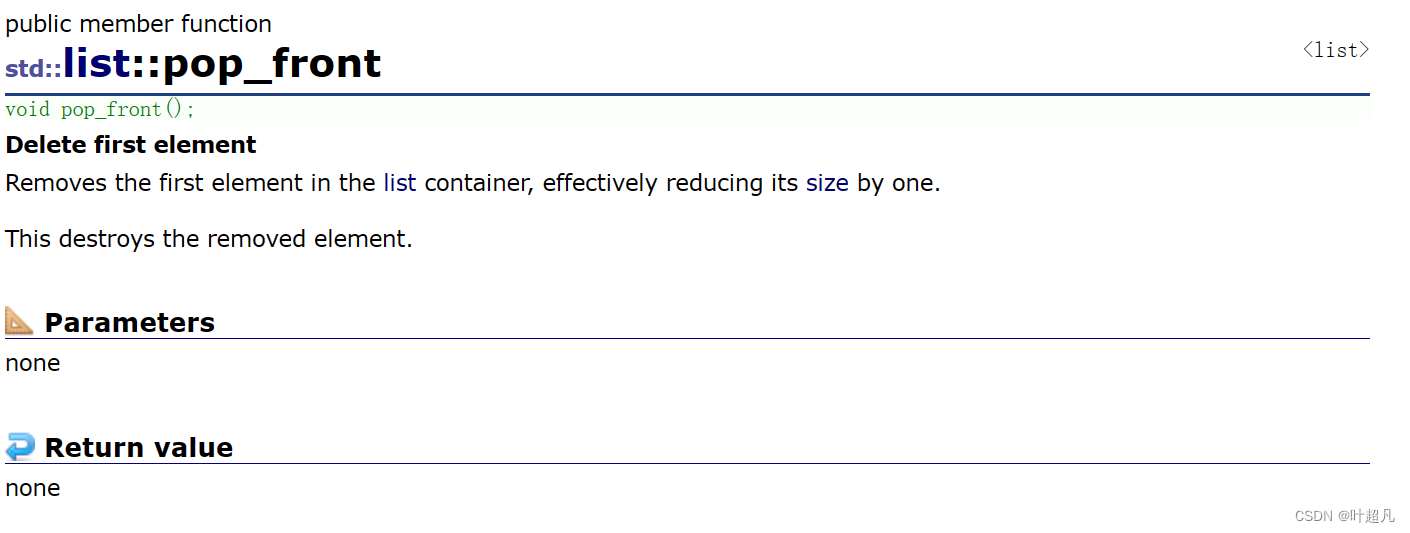
코드의 사용법은 다음과 같습니다.
void test5()
{
list<int> l1(5, 4);
l1.push_back(3);
l1.push_front(5);
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "删除尾部数据"<<endl;
l1.pop_back();
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
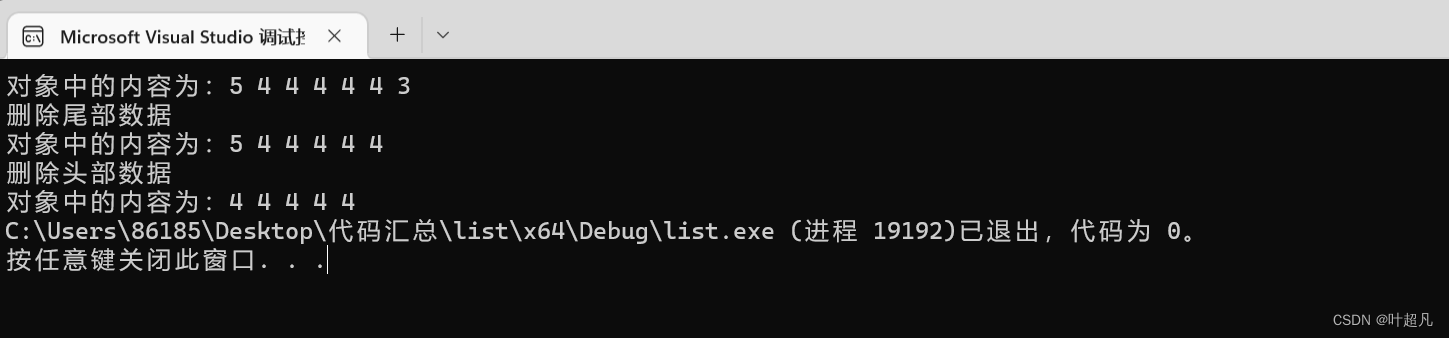
cout << "删除头部数据" << endl;
l1.pop_front();
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
}
코드를 실행한 결과는 다음과 같습니다.
삭제
지우기 함수는 어느 위치에서든 삭제할 수 있습니다. 이 함수의 매개변수를 살펴보겠습니다.
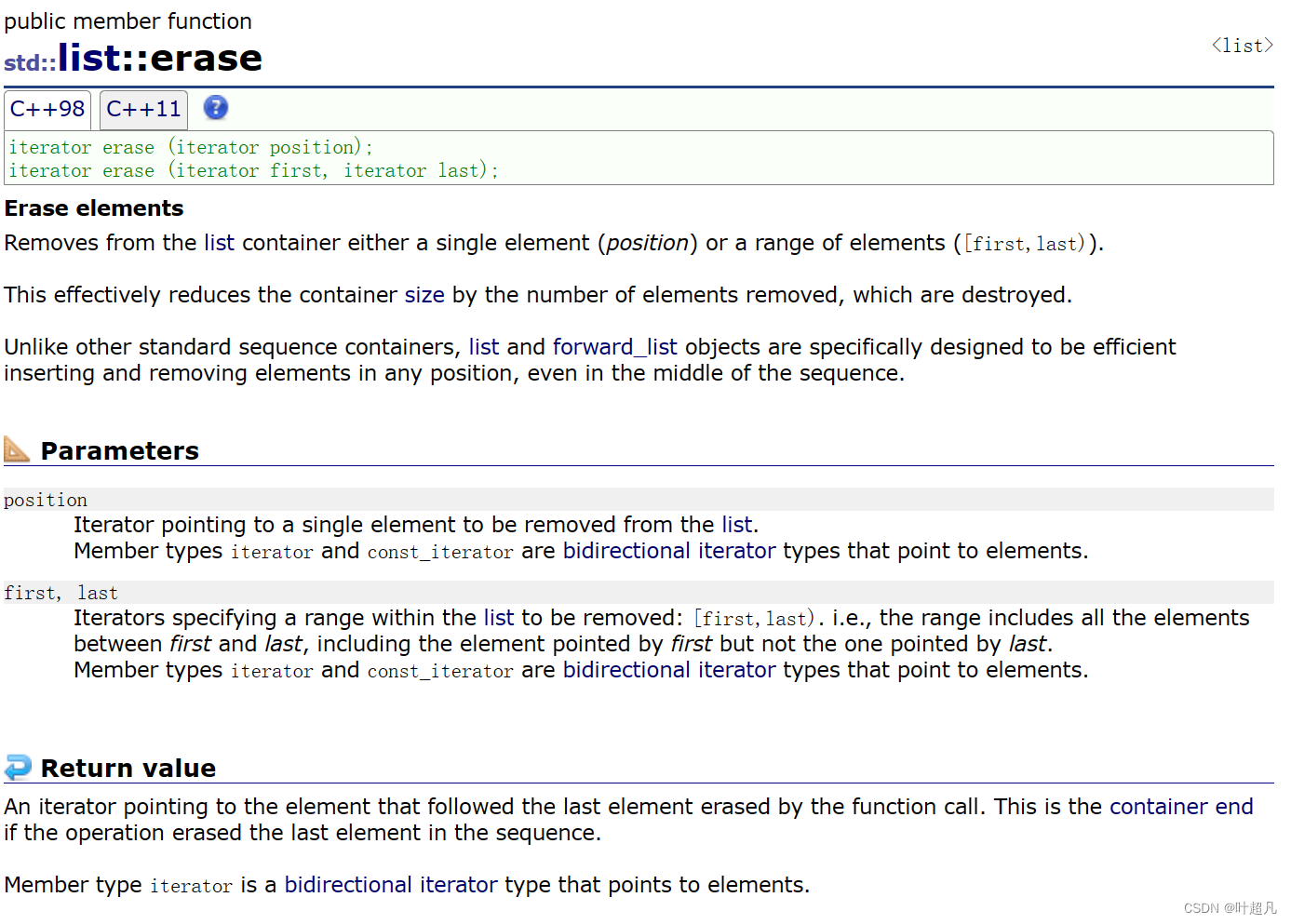
이 함수는 두 가지 다른 형태로 오버로드됩니다. 첫 번째 형태는 지정된 위치의 요소를 삭제하는 것을 의미하고, 두 번째 형태는 다음을 의미합니다. 객체의 데이터 조각을 삭제하므로 여기서는 다음 코드를 통해 이 함수의 사용을 이해할 수 있습니다.
void test6()
{
list<int> l1(2, 4);
l1.push_back(3);
l1.push_back(2);
l1.push_back(1);
l1.push_back(0);
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "删除指定位置的一个元素" << endl;
list<int>::iterator it1 = find(l1.begin(), l1.end(),3);
l1.erase(it1);
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "删除一段数据" << endl ;
cout << "对象中的内容为:";
l1.erase(++l1.begin(), --l1.end());
for (auto l : l1)
{
cout << l << " ";
}
}
코드의 실행 결과는 다음과 같습니다:
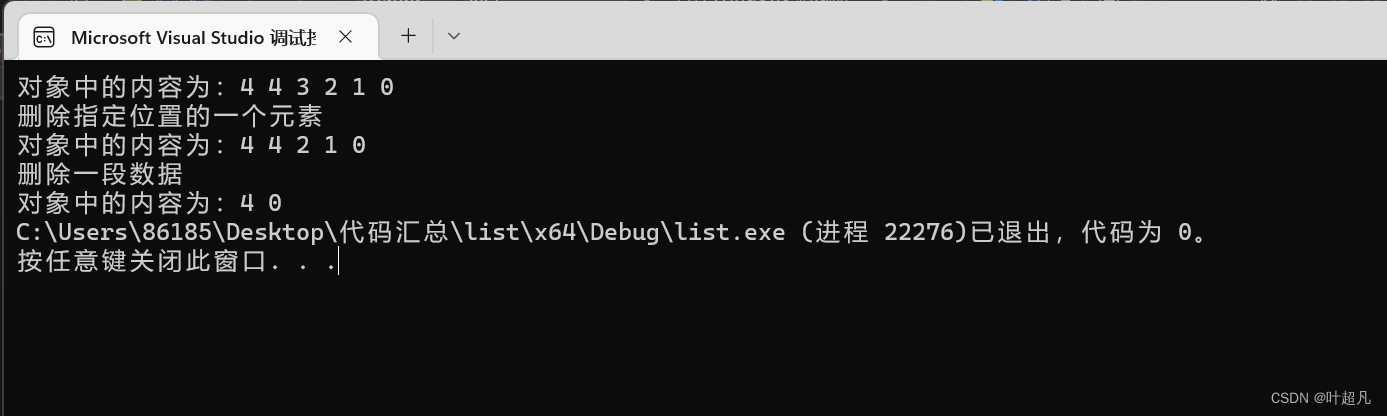
따라서 모두가 문제에 주의해야 합니다: 객체의 요소를 삭제하기 위해 반복자를 사용할 때 반복자는 유효하지 않습니다. 이유는 매우 간단합니다. 반복자는 다음을 가리킵니다. 데이터를 삭제하면 데이터가 삭제된 후 운영 체제에서 반복자가 가리키는 공간을 회수하게 됩니다. 이때 반복자는 포인터의 와일드 포인터와 동일하므로 모두 주의해야 합니다.
목록 정렬
C++ 자체에서는 데이터 정렬을 위한 정렬 함수를 제공합니다.
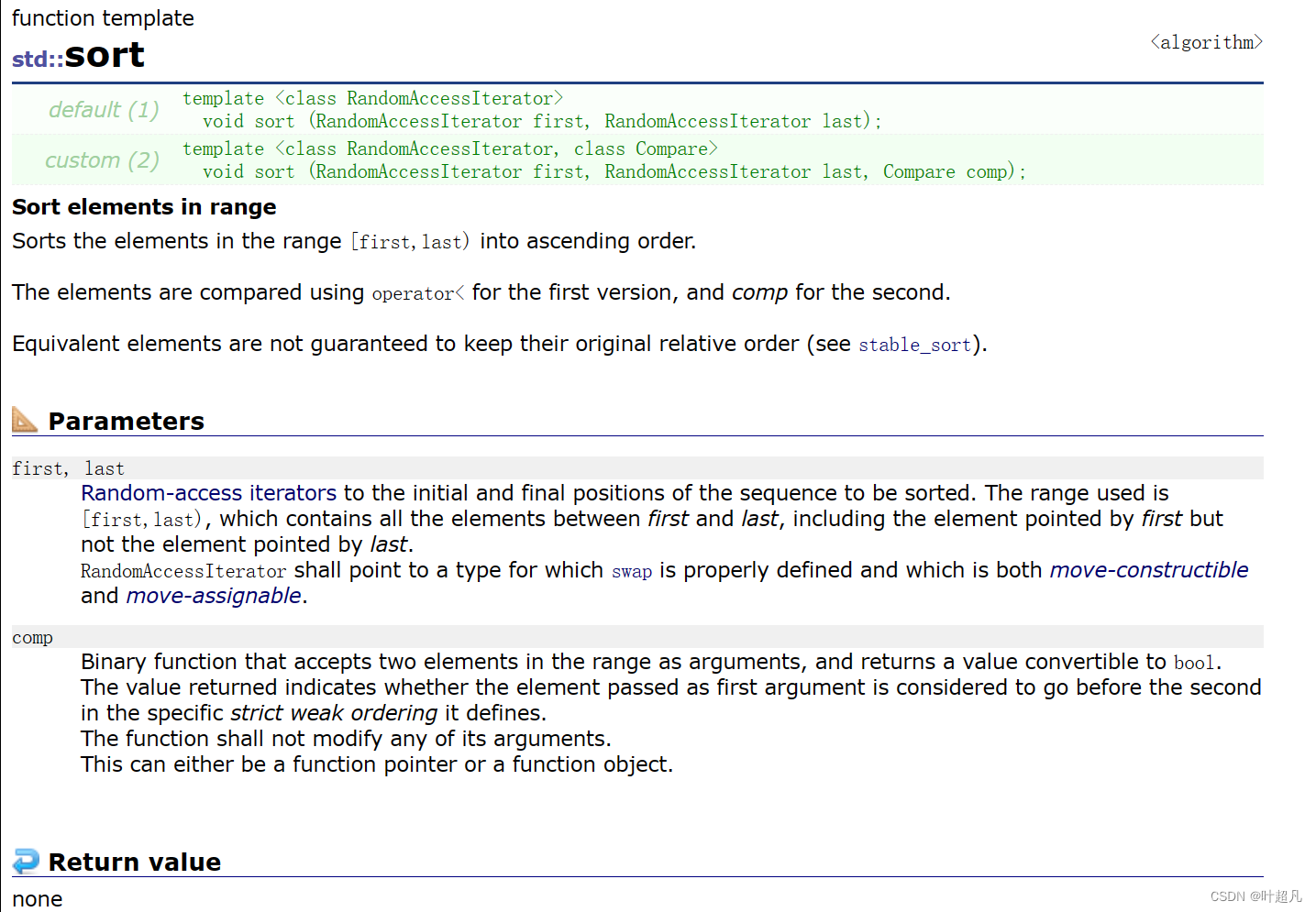
그렇다면 여기 목록이 자체 정렬 기능을 제공해야 하는 이유는 무엇입니까?
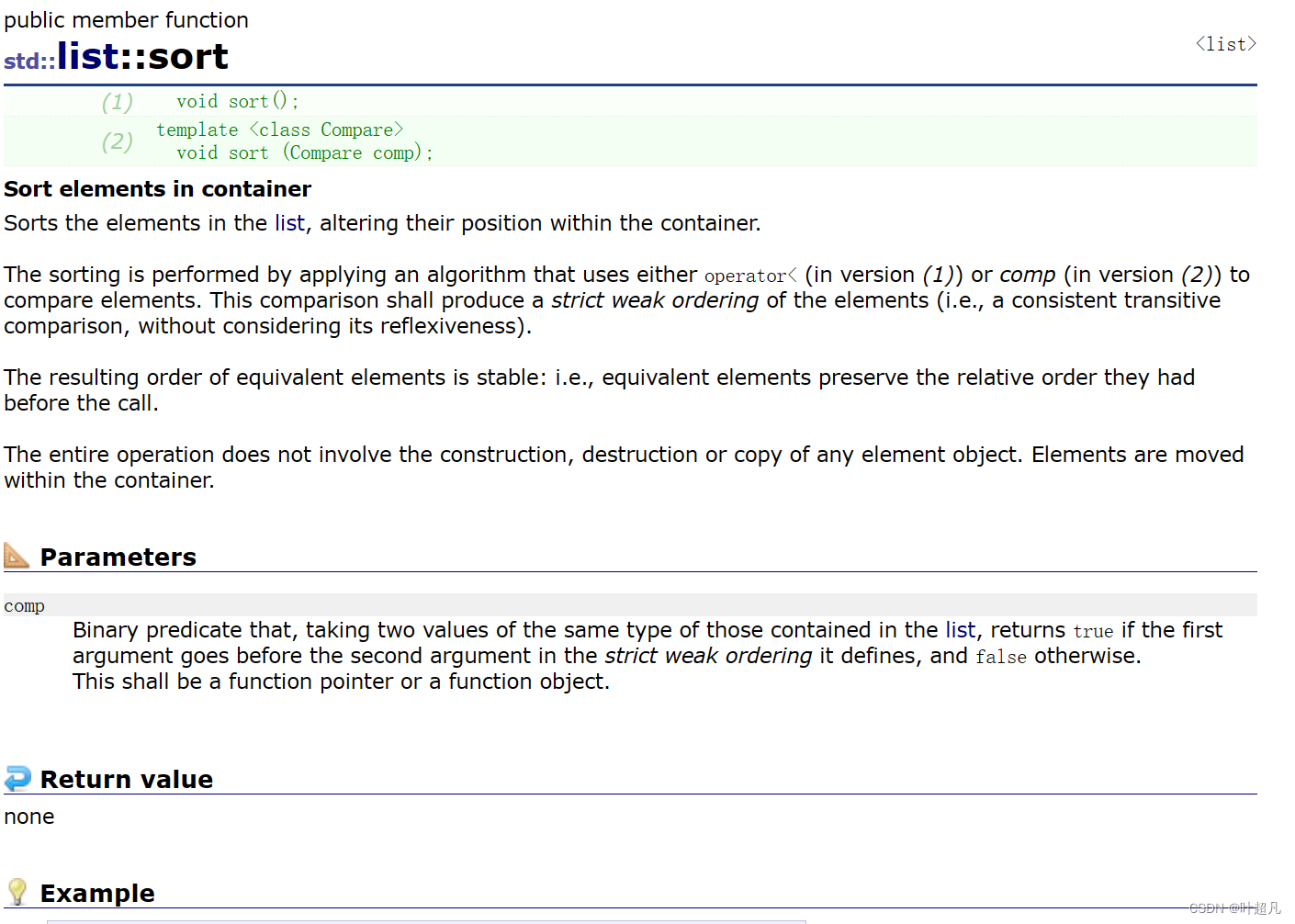
이 문제를 해결하기 위해 반복자의 분류에 대해 언급해야 하는데, C++에서는 반복자를 단방향 반복자, 양방향 반복자, 무작위 반복자의 세 가지 범주로 나눕니다. 단방향 반복자는 ++의 기능만 수행하므로 반복자는 다음 요소를 가리킵니다. 단방향 연결 리스트의 반복자는 단방향 반복자입니다. 양방향 반복자는 +만 수행할 수 없습니다. + 함수뿐만 아니라 - - 함수도 수행합니다. 이러한 종류의 반복자는 ++를 통해 다음 요소를 가리킬 수 있을 뿐만 아니라 - -를 사용하여 이전 요소를 가리킬 수도 있습니다. 여기서 우리의 목록 이중 연결 목록은 이러한 종류의 반복자입니다. ; 무작위 반복자는 양방향 반복자 위에도 있습니다. + 또는 -를 사용하여 다음 n 또는 처음 n 요소를 가리킬 수 있으며, 벡터 및 문자열의 반복자는 무작위 반복자입니다. 그런 다음 정렬의 매개변수 유형을 살펴보겠습니다. 시스템의 함수: 번역 RandomAccessIterator그것은 무작위 반복자이고 우리 목록의 반복자는 양방향 반복자입니다. 양방향 반복자를 사용하여 정렬 함수를 호출하면 어떤 일이 일어나는지 확인하십시오. 테스트 코드는 다음과 같습니다.
void test7()
{
list<int> l1(2, 4);
l1.push_back(3);
l1.push_back(2);
l1.push_back(1);
l1.push_back(0);
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "调用系统中的sort函数" << endl;
sort(l1.begin(), l1.end());
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
}
코드를 실행하면 여기에 오류가 보고된 것을 볼 수 있습니다. 여기에서

스왑을 수정하여 다음과 같이 변경합니다. l1.sort();이 경우 목록 라이브러리에서 스왑 함수를 호출하고 위 코드를 다시 실행하여 다음을 수행할 수 있습니다. 정상적으로 실행되고 있음을 확인합니다. :
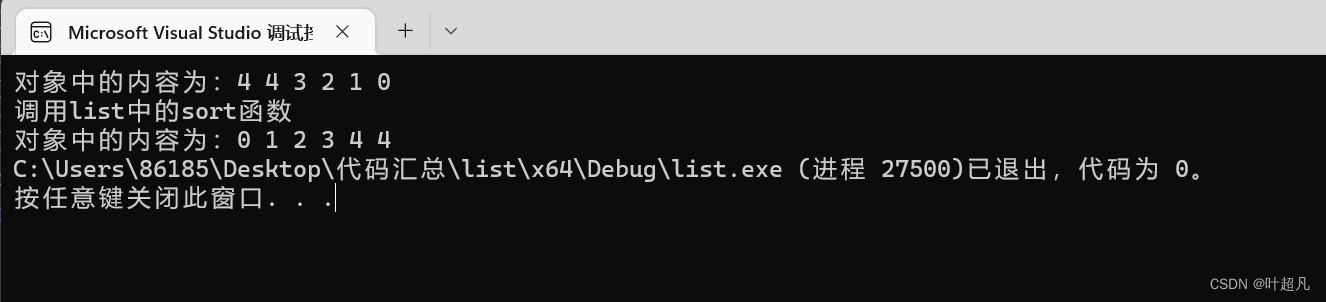
그렇다면 왜 그럴까요? 이유는 매우 간단합니다. 시스템의 정렬 기능은 구현 과정에서 두 개의 반복자를 뺀 다음 그 뺄셈의 결과를 사용하여 퀵 정렬을 결합하여 데이터 정렬을 구현합니다. 여기서 전달하는 반복자는 양방향 반복자 두 개의 반복자에 대한 빼기가 지원되지 않으므로 사용 시 오류가 발생하므로 리스트 라이브러리에서는 별도의 정렬 기능을 제공합니다. 목록의 정렬 기능은 빠른 정렬이 아닌 병합 정렬을 사용합니다.
목록 중복 제거
이 함수의 기능은 객체에서 중복된 데이터를 제거하는 것입니다.예를 들어 객체에 정수 1이 3개 있고 정수 2가 2개 있다고 가정하면 이 함수를 사용하면 객체에는 정수 1이 1개, 정수가 1개만 남게 됩니다. 2. 그러나 이 기능을 사용하기 위해서는 전제 조건이 있습니다. 즉, 객체의 데이터가 순서대로 되어 있어야 합니다. 예를 들어 다음 코드는 다음과 같습니다.
void test8()
{
list<int> l1(3, 2);
l1.push_back(1);
l1.push_back(2);
l1.push_back(6);
l1.push_back(2);
l1.push_back(3);
l1.push_back(4);
l1.push_back(1);
l1.push_back(2);
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "将对象的数据进行去重之后对象的内容为:";
l1.unique();
for (auto l : l1)
{
cout << l << " ";
}
}
여기에 있는 것은 정렬되지 않은 데이터이고 내부에 중복된 데이터가 있지만 위의 코드를 실행하면 여기서 중복 제거 기능이 작동하지 않는 것을 알 수 있습니다. 일부 내부 중복 데이터가 제거되었지만 개체에는 여전히 중복 데이터가 포함되어 있습니다

. 그러면 이것은 데이터가 순서가 없을 때 여기서 중복 제거 기능이 실패한다는 것을 증명할 수 있습니다. 중복 제거 기능 이전에 정렬 기능을 사용하여 객체의 데이터를 순서대로 변경하고 다시 실행하여 결과가 어떻게 될지 확인합니다. 코드:
void test8()
{
list<int> l1(3, 2);
l1.push_back(1);
l1.push_back(2);
l1.push_back(6);
l1.push_back(2);
l1.push_back(3);
l1.push_back(4);
l1.push_back(1);
l1.push_back(2);
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "将对象的内容变成有序的:" << endl;
l1.sort();
cout << "对象中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "将对象的数据进行去重" << endl;
cout << "对象中的内容为:";
l1.unique();
for (auto l : l1)
{
cout << l << " ";
}
}
코드의 실행 결과는 다음과 같습니다:
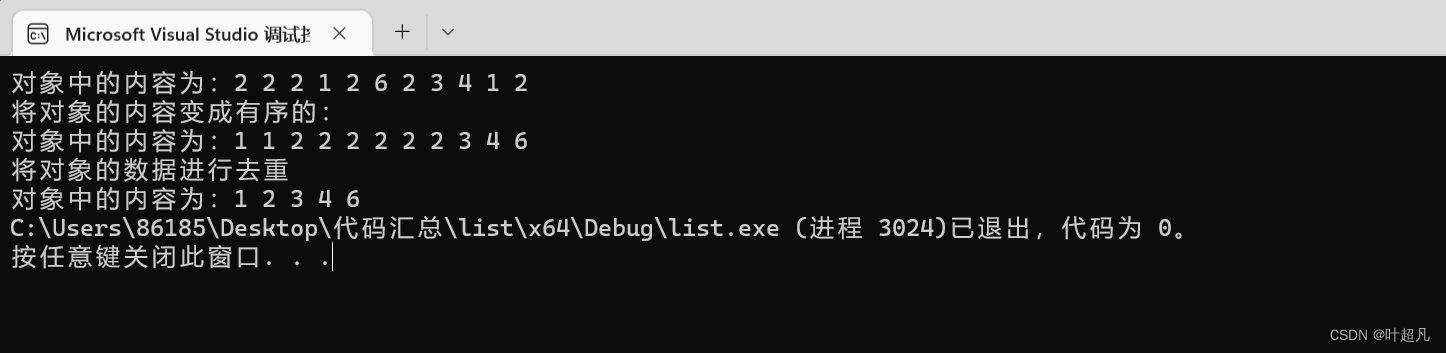
여기의 결과는 매우 분명합니다. 이 기능을 사용하기 전에 개체 데이터를 정렬하여 해당 역할을 수행할 수 있도록 해야 합니다. 따라서 모든 사람은 여기서 분명히 질문을 갖게 될 것입니다. 왜 직접적으로 어떻습니까? 고유한 기능으로 직접 정렬할 수 있나요? 이렇게 하면 우리가 직접 함수를 호출할 필요가 없고, 이렇게 하지 않는 이유도 매우 간단합니다. 이 함수를 호출하고 다시 정렬하시겠습니까? 따라서 고유함수에서는 우리가 전달하는 객체에 대한 정렬이 아닌 우리 사용자가 직접 정렬을 해줘야 하는 기능을 소개합니다.
목록 병합
동일한 데이터 유형의 두 목록 개체를 하나의 목록 개체로 병합하려면 다음 함수를 사용해야 합니다.
이 함수의 특징은 제공한 두 개체의 데이터가 순서대로 있을 때 이 함수를 사용하여 병합한다는 것입니다. 결과는 여전히 순서대로 유지되며 다음 코드를 볼 수 있습니다.
void test9()
{
list<int> l1(3, 2);
list<int> l2;
l2.push_back(1);
l2.push_back(2);
l2.push_back(3);
l2.push_back(4);
l2.push_back(5);
l1.merge(l2);
cout << "对象l1中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "对象l2中的内容为:";
for (auto l : l2)
{
cout << l << " ";
}
}
이 코드의 실행 결과는 다음과 같습니다.
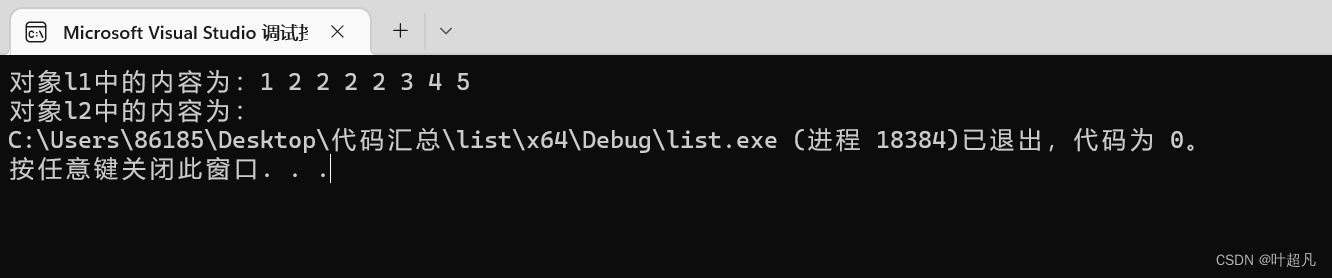
이 실행 결과를 통해 이 함수의 사용 특징은 어떤 개체가 이 함수를 호출하는지 알 수 있으며, 그러면 다른 개체의 내용이 이 개체에 병합되고 다른 개체의 내용이 병합됩니다. 내용은 삭제되므로 이것이 이 기능의 사용 규칙입니다.
목록 전송
목록을 다른 목록 객체로 전송하려면 다음 함수를 사용할 수 있습니다:
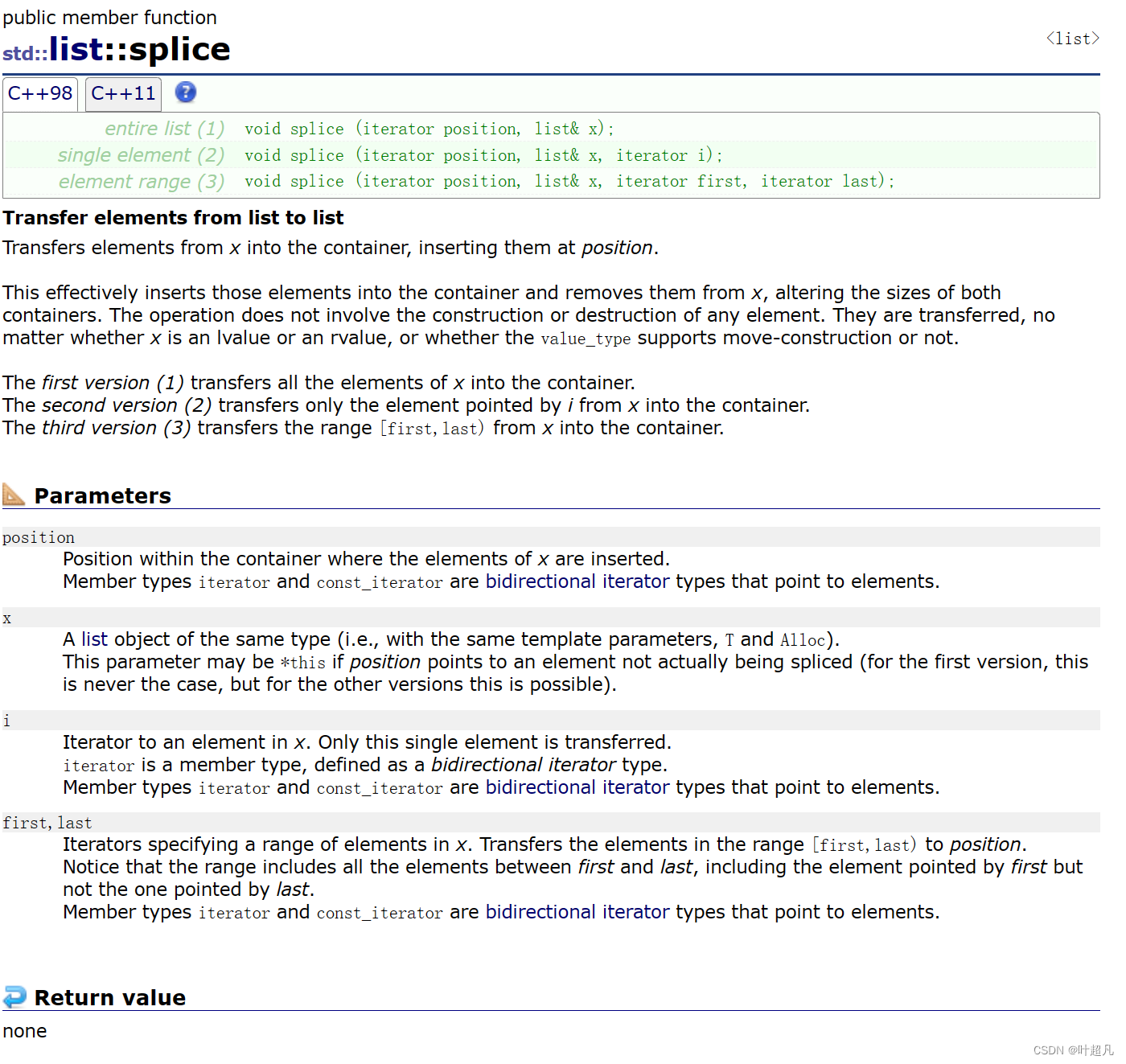
이 기능의 소개입니다. 한 객체의 내용을 다른 객체의 지정된 위치로 전송할 수 있습니다. 이것이 첫 번째 형태에 해당합니다. 방법 지정하려면:
void test10()
{
list<int> l1(3, 2);
list<int> l2;
l2.push_back(1);
l2.push_back(2);
l2.push_back(3);
l2.push_back(4);
l2.push_back(5);
cout << "对象l1中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
l1.splice(++l1.begin(), l2);
cout << "对象l1中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "对象l2中的内容为:";
for (auto l : l2)
{
cout << l << " ";
}
}
코드의 실행 결과는 다음과 같습니다:
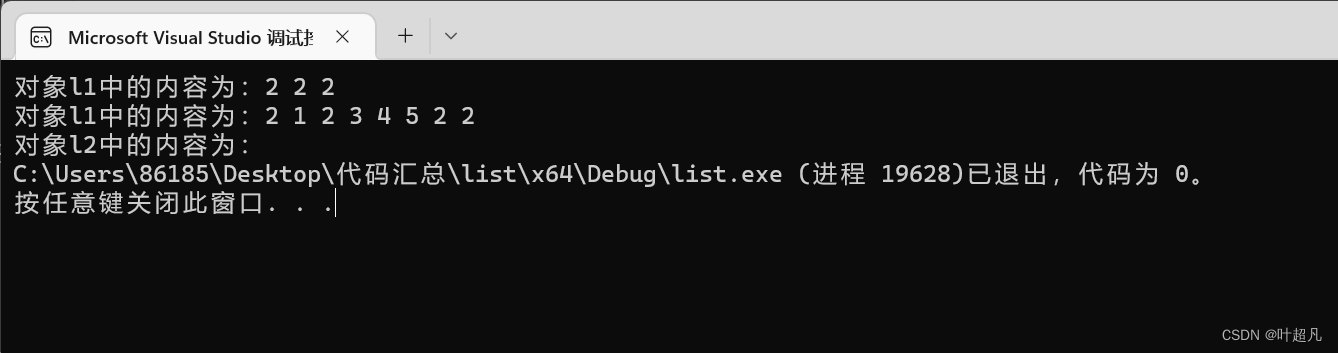
이 형식에서 이 함수를 사용하면 객체 l2의 내용이 완전히 사라지고 모든 것이 l1의 지정된 위치로 전송됩니다. 물론 내용의 일부를 전송할 수도 있습니다. 두 번째와 세 번째 형식을 사용해야 합니다. 두 번째 형식은 위치 i의 요소를 전송하는 것입니다. 세 번째 형식은 첫 번째와 끝 사이의 내용을 전송하는 것입니다. 다음 코드를 살펴보겠습니다. . 이것은 두 번째 형식에 해당하는 코드입니다.
void test11()
{
list<int> l1(3, 2);
list<int> l2;
l2.push_back(1);
l2.push_back(2);
l2.push_back(3);
l2.push_back(4);
l2.push_back(5);
cout << "对象l1中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
l1.splice(++l1.begin(),l2, ++l2.begin());
cout << "对象l1中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "对象l2中的内容为:";
for (auto l : l2)
{
cout << l << " ";
}
}
이 코드를 실행하면 단 하나의 요소만 전송되었음을 확인할 수 있습니다.
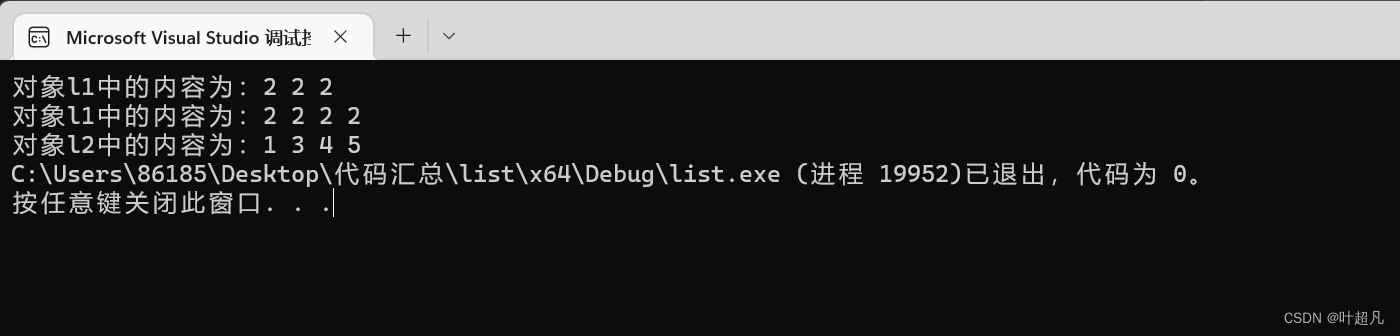
다음은 세 번째 코드 형식입니다.
void test12()
{
list<int> l1(3, 2);
list<int> l2;
l2.push_back(1);
l2.push_back(2);
l2.push_back(3);
l2.push_back(4);
l2.push_back(5);
cout << "对象l1中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
l1.splice(++l1.begin(), l2, ++l2.begin(),--l2.end());
cout << "对象l1中的内容为:";
for (auto l : l1)
{
cout << l << " ";
}
cout << endl;
cout << "对象l2中的内容为:";
for (auto l : l2)
{
cout << l << " ";
}
}
코드의 실행 결과는 다음과 같습니다.
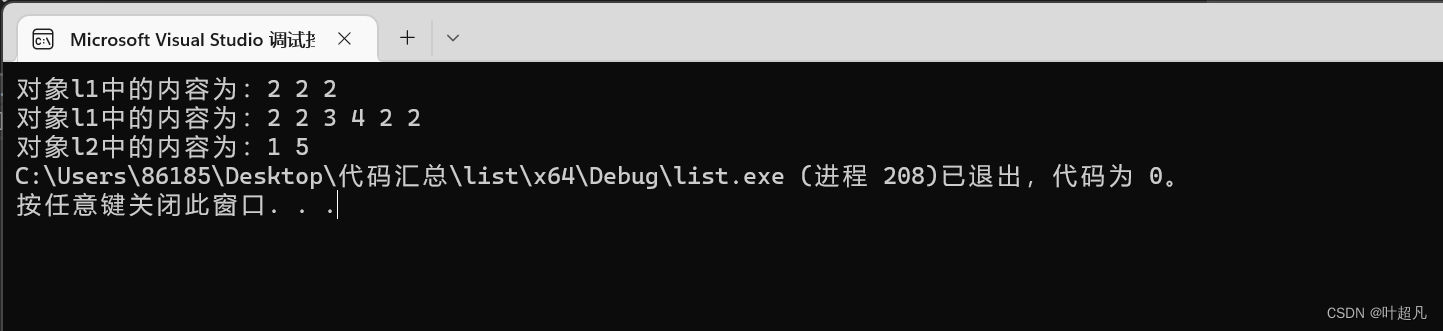
여기서는 l2의 첫 번째 요소와 마지막 요소를 제외하고 다른 모든 요소가 l1의 두 번째 요소로 이동되었음을 알 수 있으므로 이 함수를 사용하는 방법은 다음과 같습니다.
다른 기능 나열
비어 있는
이 객체의 콘텐츠가 비어 있는지 여부를 반환하는 데 사용됩니다.
크기
목록 객체의 길이를 반환합니다.
앞쪽
목록 객체의 첫 번째 요소를 반환합니다.
뒤쪽에
목록 객체의 마지막 요소를 반환합니다.
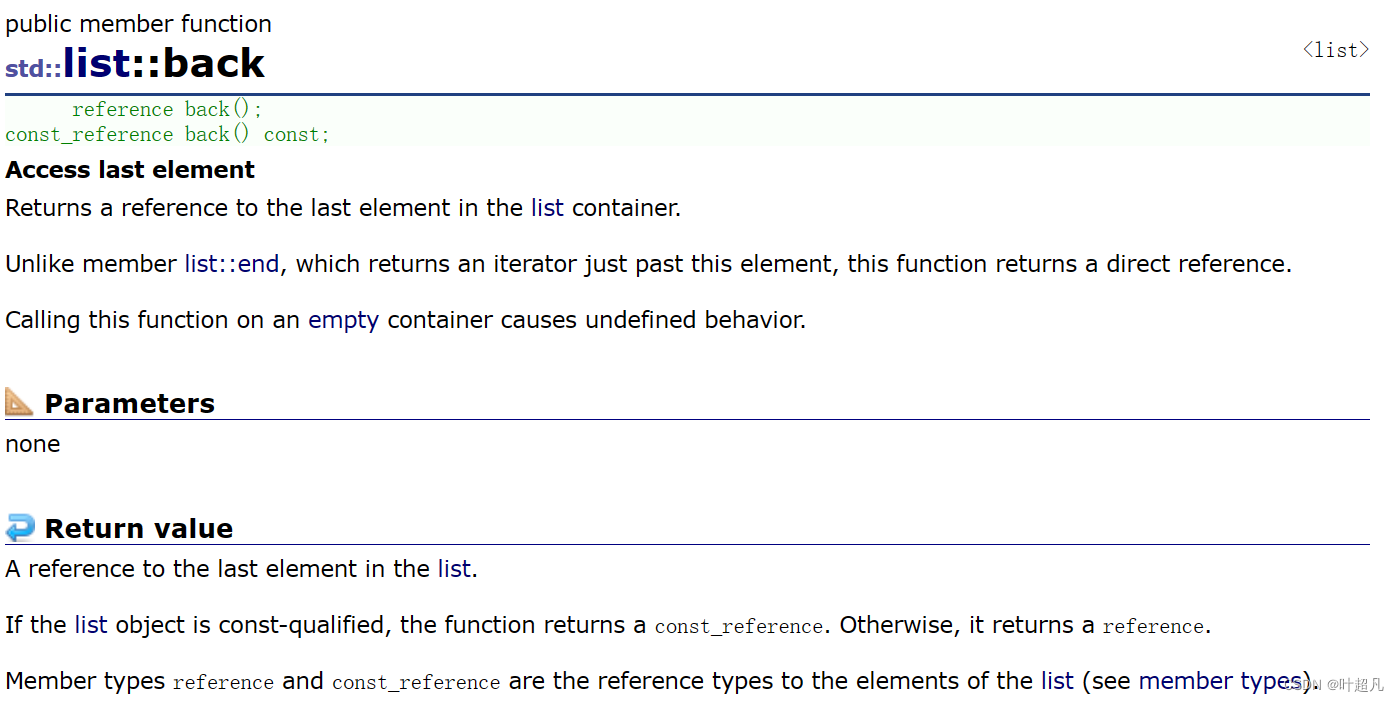
양수인
목록 개체의 공간을 지우고 새 내용으로 채웁니다.
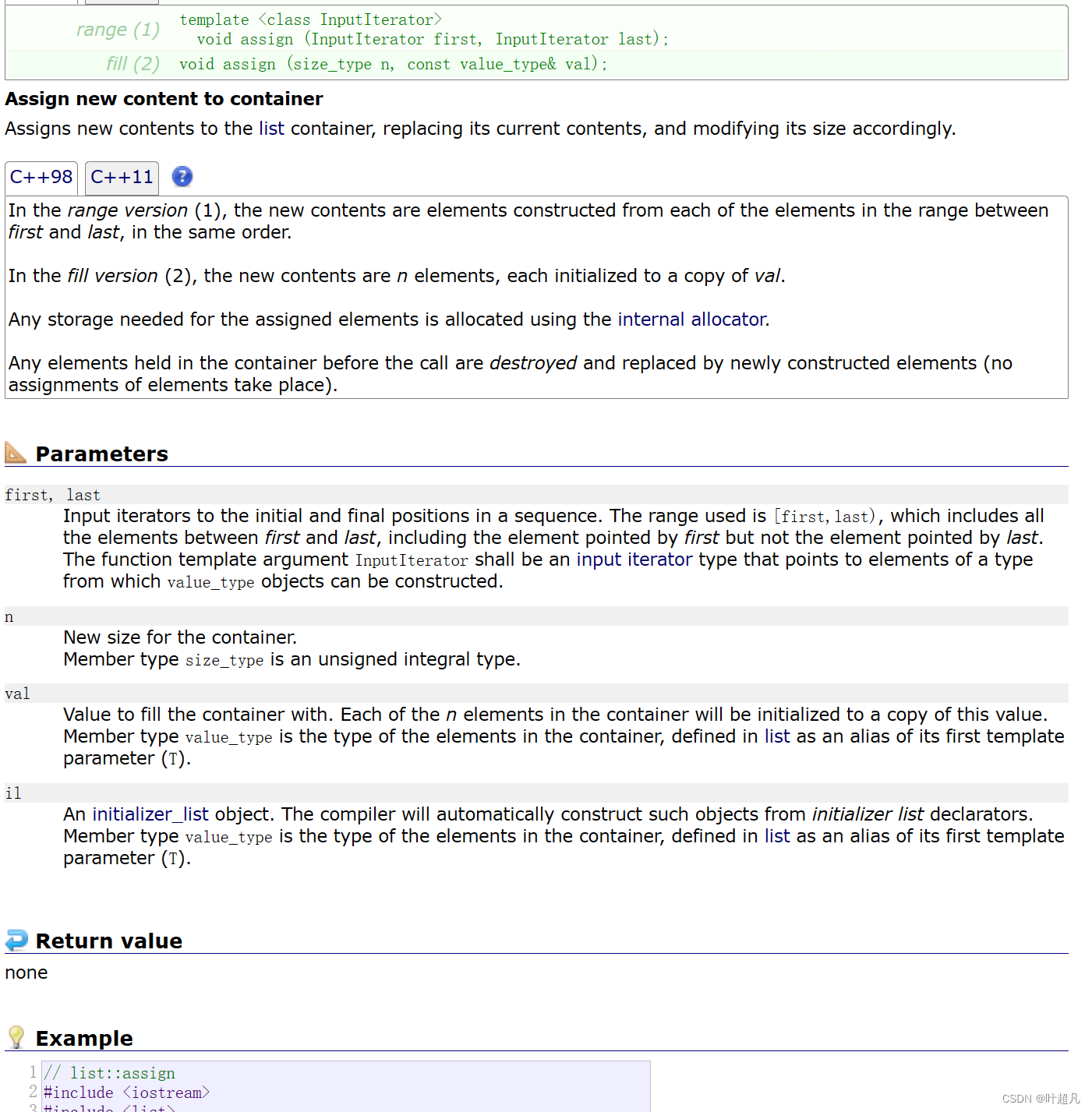
교환
두 목록 개체의 내용을 바꿉니다.

물론 이 목록은 사용자가 실수를 저지르고 덜 효율적인 라이브러리에서 스왑을 호출하는 것을 방지하기 위해 서로 다른 매개변수를 사용하는 두 개의 스왑도 제공합니다.
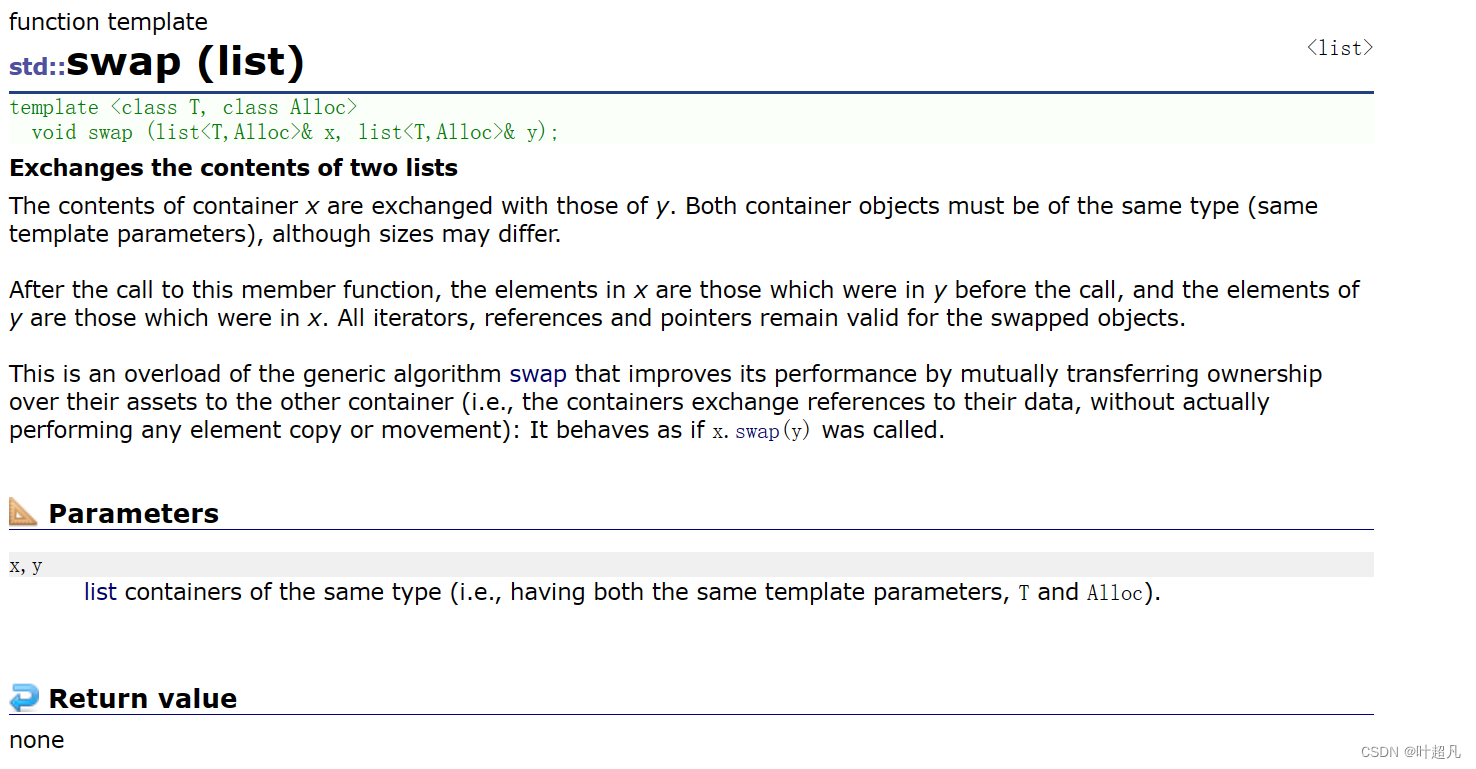
크기 조정
객체에서 길이를 수정합니다.수정된 길이가 원래 길이를 초과하는 경우 매개변수의 내용으로 채워집니다.
분명한
개체의 모든 내용을 지웁니다.
목록 정렬 효율성 문제
리스트에 정렬 기능이 제공되어 있음에도 불구하고, 실제로는 이 기능의 효율성이 너무 낮아 이 기능을 거의 사용하지 않고 있습니다.예를 들어, 다음 코드에서는 리스트의 정렬 기능과 정렬 기능을 결합합니다. 벡터의 함수 비교를 하려면 먼저 100만 개의 난수를 생성하고 이 난수의 꼬리를 두 개체에 삽입합니다.
void test14()
{
srand((unsigned int)time(0));
const int N = 1000000;
vector<int> v;
list<int> it1;
for (int i = 0; i < N; i++)
{
auto e = rand();
v.push_back(e);
it1.push_back(e);
}
}
그런 다음 clock 함수를 사용하여 시간을 측정하고 최종 결과를 인쇄합니다.
void test14()
{
srand((unsigned int)time(0));
const int N = 1000000;
vector<int> v;
list<int> it1;
for (int i = 0; i < N; i++)
{
auto e = rand();
v.push_back(e);
it1.push_back(e);
}
int begin1 = clock();
sort(v.begin(),v.end());
int end1 = clock();
int begin2 = clock();
it1.sort();
int end2 = clock();
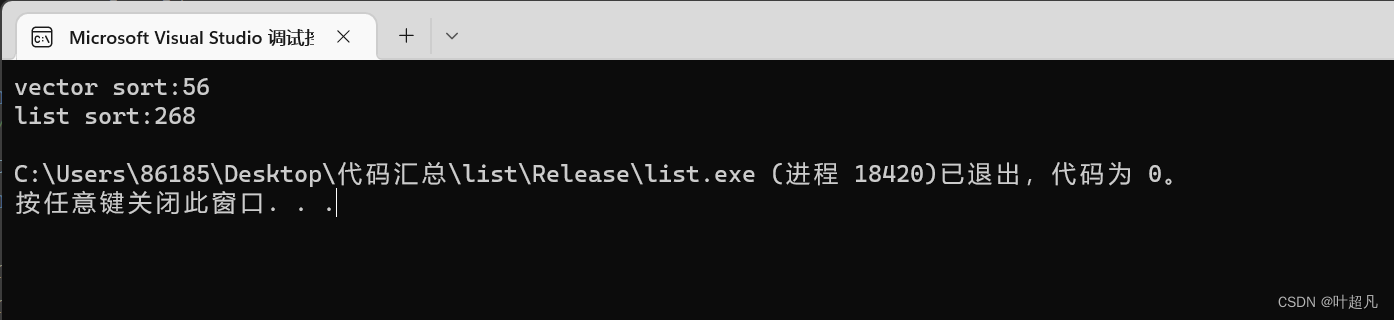
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
릴리스 환경에서 이 코드를 실행하면 두 가지 정렬의 효율성이 상당히 다르다는 것을 알 수 있습니다.

따라서 목록 데이터를 정렬하려고 할 때 일반적으로 사용하는 방법은 목록 데이터를 먼저 벡터에 복사하는 것입니다. , 벡터가 정렬되고 마지막으로 정렬된 결과가 목록에 복사되어 목록의 데이터 복사본을 구현합니다. 그런 다음 다음 코드는 위의 정렬을 개선한 것입니다.
void test13()
{
srand((unsigned int)time(0));
const int N = 1000000;
vector<int> v;
v.reserve(N);
list<int> lt1;
list<int> lt2;
for (int i = 0; i < N; ++i)
{
auto e = rand();
//v.push_back(e);
lt1.push_back(e);
lt2.push_back(e);
}
// 拷贝到vector排序,排完以后再拷贝回来
for (auto e : lt1)
{
v.push_back(e);
}
int begin1 = clock();
sort(v.begin(), v.end());
int end1 = clock();
size_t i = 0;
for (auto& e : lt1)
{
e = v[i++];
}
int begin2 = clock();
// sort(lt.begin(), lt.end());
lt2.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
우리는 이 코드를 실행하여 우리의 노력에도 불구하고 목록 정렬만 수행하는 것보다 효율성이 여전히 높다는 것을 발견했습니다.
그렇다면 이것이 목록 정렬의 효율성 문제이므로 모든 사람이 이를 이해하면 됩니다.