머리말
소위 정렬이란 데이터 세트를 증가 또는 감소 방식으로 배열하여 이 데이터 세트를 순서대로 만드는 것입니다. 정렬은 생활 속에서 널리 사용되며 각계각층에서 사용됩니다. 예를 들어 온라인 쇼핑을 할 때 우리는 특정 정렬 방법에 따라 물건을 선택합니다. 따라서 정렬 구현을 이해하는 것이 매우 중요합니다.
목차
1. 정렬의 개념
정렬: 소위 정렬은 하나 또는 일부 키워드의 크기에 따라 특정 규칙에 따라 레코드 문자열을 증가 또는 감소하는 순서로 만드는 것입니다.
안정성: 정렬할 레코드 순서에 동일한 키워드를 가진 여러 개의 레코드가 있고, 이러한 레코드의 상대적 순서는 정렬 후에도 변경되지 않는다고 가정합니다. 즉, 원래 순서 r[i] = r[j], r[ i]가 r[j] 앞에 있고, 정렬 후 r[i]가 r[j] 앞에 있으면 이 정렬 알고리즘은 안정적이라고 하고 그렇지 않으면 불안정하다고 합니다.
내부 정렬: 모든 데이터 요소가 메모리에 배치되는 정렬입니다.
외부 정렬: 동시에 메모리에 배치할 수 없는 데이터 요소가 너무 많아서 정렬 프로세스의 요구 사항에 따라 내부 메모리와 외부 메모리 간에 데이터를 이동할 수 있습니다.
2. 일반적인 정렬 알고리즘

3. 공통 정렬 알고리즘 구현
3.1 삽입 정렬
기본 아이디어: 모든 시퀀스가 삽입되고 새로운 정렬된 시퀀스가 얻어질 때까지 키 값에 따라 이미 정렬된 순서에 정렬할 레코드를 하나씩 삽입합니다.
실제로 우리는 포커를 할 때 삽입 정렬이라는 아이디어를 사용했습니다.

3.1.1 직접 삽입 정렬
i번째 요소를 삽입할 때 이전 array[0], array[1],...,array[i-1]은 이미 정렬되어 있는데, 이때 arryy[i]와 array[i의 정렬 코드는 다음과 같습니다. -1]이 사용됨 , array[i-2], array[i-3],... 정렬 코드 순서를 비교하여 array[i]를 삽입하려는 삽입 위치와 삽입 순서를 찾습니다. 원래 위치의 요소는 뒤로 이동됩니다.
비교 과정에서는 오름차순으로 정렬되어 있으면 현재 값과 먼저 비교하고, 현재 값보다 작으면 현재 값의 이전 요소와 비교하고, 이전 값보다 크면 현재 값과 비교한다. 현재 값의 요소는 현재 값의 이전 요소 뒤에 삽입됩니다. , 현재 값의 이전 요소보다 작은 경우 삽입할 적절한 위치를 찾을 때까지 이전 요소와 계속 비교합니다. 가장 작은 값을 배열의 시작 부분에 삽입합니다. 그림과 같이:

void InsertSort(int* a, int n)//升序排序
{
assert(a);
for (int i = 0; i < n - 1; ++i)
{
int end = i;
int tmp = a[end + 1];//保存数据,后面移动的时候数据会被覆盖
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];//将数据向后移动空出位置
--end;//迭代继续向前比较
}
else
{
break;//插入到
}
}
a[end + 1] = tmp;
}
}직접 삽입 정렬의 기능 요약:
1. 시간 복잡도는 O(N*2)입니다.
2. 정렬된 순서가 가까울수록 시간 복잡도는 낮아집니다.
3. 안정성: 안정적입니다.
4. 공간복잡도 O(1)로 안정적인 정렬이다.
구현 코드:
3.1.2 힐 정렬
Hill 정렬은 감소증분 정렬 방법이라고도 합니다. Hill 정렬의 기본 아이디어는 먼저 정수를 선택하고, 정렬할 파일의 레코드를 그룹으로 나누고, 간격이 있는 모든 레코드를 하나의 그룹으로 나누고, 각 그룹의 레코드를 정렬하는 것입니다. 그런 다음 위의 그룹화 및 정렬 작업을 반복합니다. gap = 1이면 모든 레코드가 균일하게 정렬됩니다.
직설적으로 말하면 Hill 정렬은 직접 삽입 정렬에서 돌파구를 찾는데, 직접 삽입 정렬의 시간 복잡도는 매우 높지만, 직접 삽입 정렬은 정렬이 되어 있거나 정렬에 가까울 때 매우 효율적입니다 . 질서정연에 가깝나요? 이를 위해서는 사전 정렬이 필요합니다 . 사전 정렬을 통해 배열이 거의 정렬되고 마지막 직접 삽입 정렬이 매우 빠르게 수행되므로 Hill 정렬은 직접 삽입 정렬에 적합한 최적화입니다.
힐 정렬은 두 단계로 나뉩니다.
1. 배열 사전 정렬
배열을 간격에 따라 여러 그룹으로 나누고 먼저 간격이 있는 그룹을 정렬하여 간격이 순서대로 되도록 한 다음 간격을 줄입니다. 위의 과정을 반복하세요.
2. 직접 삽입 정렬
gap이 1일 때 직접 삽입 정렬과 동일하다.아주 간단한 것 같지 않니?

그림과 같이:
//希尔排序
void ShellSort(int* a, int n)
{
assert(a);//确保指针不为空
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;//保证最后一次排序的间隔是1,进过计算gap按照三分之一减少是最优的
for (int i = 0; i < n - gap; ++i)//排升序
{
int end = i;
int tmp = a[end + gap];//防止数据被覆盖
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];//移动数组,继续在前面比较
end = end - gap;
}
else
{
break;
}
}
a[end + gap] = tmp;//将数据插入到数组中
}
Print(a, 10);
printf(" gap = %d\n", gap);
printf("\n");
}
}Hill 정렬의 특징 요약
1. Hill 정렬은 직접 삽입 정렬을 최적화한 것입니다.
2. 간격이 1보다 크면 배열을 더 가까운 순서로 만들기 위해 사전 정렬됩니다. gap == 1이면 배열이 거의 정렬되어 있으므로 빠르게 정렬할 수 있습니다. 이러한 방식으로 전반적인 최적화 효과를 얻을 수 있습니다. 이를 구현한 후 성능 테스트를 비교할 수 있습니다.
3. Hill 정렬의 시간복잡도는 gap의 값을 취하는 방법이 다양하여 계산이 어렵기 때문에 계산이 어렵다. 따라서 Hill 정렬의 시간복잡도는 많은 책에서 고정되어 있지 않다.

여기서의 간격은 Knuth의 방법에 따라 계산되므로
당분간 그에 따라 계산됩니다.

3.2 선택 정렬
기본 아이디어: 매번 정렬할 데이터에서 가장 작은(또는 가장 큰 요소)을 선택하고 정렬할 배열이 정렬될 때까지 시퀀스의 시작 부분에 저장합니다.
3.2.1 힙 정렬
참고: 힙 정렬
3.2.2 직접 선택 정렬
오름차순 정렬: 요소 세트 array[i]-array[n-1]에서 가장 큰(가장 작은) 키 코드를 가진 데이터 요소를 선택합니다.
세트의 마지막(첫 번째) 요소가 아닌 경우 세트의 마지막(첫 번째) 요소와 교환합니다.
세트에 하나의 요소가 남을 때까지 나머지 array[i]--array[n -2](array[i+1] --array[n-1]) 세트에서 위 단계를 반복합니다.
void SelectSort(int* a, int n)
{
assert(a);//确保a存在
//排升序
int left = 0;
int right = n - 1;
while (left < right)
{
int maxDex = right;
int minDex = left;
//遍历剩余的数组每次找出最大的和最小的将最大的换到n-1的位置,将最小的放到j位置
for (int i = left; i <= right; ++i)
{
if (a[maxDex] < a[i] )
{
maxDex = i;//记录最大值的下标
}
if (a[minDex] > a[i] )
{
minDex = i;//记录最小值的下标
}
}
Swap(&a[minDex], &a[left]);
if (left == maxDex)//说明最大值的下标在最左边,上一步的交换让最大值已经不是最左边,而是下标minDex
maxDex = minDex;
Swap(&a[maxDex], &a[right]);
left++;
right--;
}
}시간 복잡도는 O(n*n)입니다.
void SelectSort(int* a, int n)
{
assert(a);//确保a存在
//排升序
int left = 0;
int right = n - 1;
while (left < right)
{
int maxDex = right;
int minDex = left;
//遍历剩余的数组每次找出最大的和最小的将最大的换到n-1的位置,将最小的放到j位置
for (int i = left; i <= right; ++i)
{
if (a[maxDex] < a[i] )
{
maxDex = i;//记录最大值的下标
}
if (a[minDex] > a[i] )
{
minDex = i;//记录最小值的下标
}
}
Swap(&a[minDex], &a[left]);
if (left == maxDex)//说明最大值的下标在最左边,上一步的交换让最大值已经不是最左边,而是下标minDex
maxDex = minDex;
Swap(&a[maxDex], &a[right]);
left++;
right--;
}
}3.3 교환 정렬
3.3.1 버블정렬
자세한 내용은 버블 정렬을 참조하세요 .
3.3.2 퀵 정렬
자세한 내용은 빠른 정렬을 참조하세요 .
퀵 정렬의 재귀적 구현 방법 외에 비재귀적 구현 방법도 있는데, 그렇다면 비재귀를 통해 퀵 정렬을 구현하는 방법은 무엇일까요? 퀵 정렬을 구현하는 재귀적 방법은 함수를 통해 스택 프레임을 호출하여 구현된다는 것은 우리 모두 알고 있습니다. 실제로 비재귀도 함수를 시뮬레이션하고 스택을 통해 스택 프레임을 호출하는 과정을 시뮬레이션하여 구현합니다. 데이터 구조.
데이터 구조 스택과 운영 체제 스택은 동일하지 않지만 속성은 동일합니다(후입선출) .스택을 통해 어떻게 시뮬레이션합니까?
암호:
// 快速排序 非递归实现
void QuickSortNonR(int* a, int begin, int end)
{
//创建并初始化栈
Stack st;
StackInit(&st);
//将区间[left,right]入栈
StackPush(&st, end);
StackPush(&st, begin);
//通过栈来模拟快排递归时的调用
//数据结构实现的栈和操作系统的栈的特性是一样的
while (!StackEmpty(&st))
{
int left = StackTop(&st);
StackPop(&st);
int right = StackTop(&st);
StackPop(&st);//如栈的时候先右后左,出栈的时候先左后右
int midi = PartSort1(a, left, right);//对子区间进行快速排序的单趟排序
//将左右子区间都入栈
if (midi + 1 < right)//右边区间至少存在一个数
{
StackPush(&st, right);
StackPush(&st, midi + 1);
}
if (left < midi - 1)//左边区间至少存在一个数
{
StackPush(&st, midi - 1);
StackPush(&st, left);
}
}
StackDestory(&st);
}3.4 병합 정렬
3.4.1 병합 정렬
병합 정렬(Merge Sort)은 병합 연산을 기반으로 하는 효과적인 정렬 알고리즘으로, 이 알고리즘은 분할 정복 방법의 일반적인 응용으로, 이미 정렬된 하위 시퀀스를 병합하여 완전히 정렬된 시퀀스를 얻습니다. 하위 시퀀스를 병합하면 전체 간격이 순서대로 만들어집니다. 두 개의 정렬된 목록이 하나의 정렬된 목록으로 병합되는 경우 이를 양방향 병합이라고 합니다. 병합 정렬의 핵심 단계는 다음과 같습니다.

암호:
//单趟归并排序
void _MergeSortSignal(int *a, int begin1, int end1, int begin2, int end2, int *tmp)//闭区间
{
int begin = begin1;//保存数组起始的位置方便拷贝
tmp = (int*)malloc(sizeof(int) * (10 + 1));
int i = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
//将剩下的一个数组尾插到tmp
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
for (int j = begin ; j <= end2; ++j)
{
a[j] = tmp[j];
}
free(tmp);
}
// 归并排序递归实现
void _MergeSort(int* a, int left, int right, int * tmp)
{
if (left >= right)//区间只剩下一个数
{
return;
}
int midi = (left + right) / 2;
_MergeSort(a, left, midi, tmp);
_MergeSort(a, midi + 1, right, tmp);
//合并有序的小区间
_MergeSortSignal(a, left, midi, midi + 1, right, tmp);
}
void MergeSort(int* a, int n)
{
//int* tmp = (int*)malloc( sizeof(int) * n);
_MergeSort(a, 0, n - 1,NULL);//闭区间[left,right]
//free(tmp);
}
병합 정렬의 비재귀적 방법:
스택을 사용하여 문제를 시뮬레이션하면 문제는 더욱 복잡해지게 되는데, 위의 그림을 보면 병합 정렬이란 정렬할 범위가 질서정연해질 때까지 정렬할 범위를 지속적으로 줄이는 과정임을 쉽게 알 수 있다. 음, 간격에 숫자가 하나만 있으면 순서가 있어야 한다는 것을 찾는 것은 어렵지 않으므로 이 아이디어를 채택하여 먼저 인접한 연속 숫자를 병합합니다. 간격은 1이므로 다음 번에는 인접한 숫자가 병합됩니다. 두 숫자는 이미 순서대로 있으므로 간격 길이가 2인 두 개의 인접한 하위 간격을 순서 있는 간격으로 병합해야 합니다. , gap = 2 등 그냥 gap을 늘리면 되는데 언제 끝나나?글쎄, gap이 배열의 길이보다 크거나 같을 때까지 배열은 순서대로 있어야 한다. 현재로서는 병합할 필요가 없습니다.
참고: 병합을 위해 하위 구간을 분할할 때 두 번째 구간의 길이가 첫 번째 구간의 길이보다 작거나 두 번째 구간이 존재하지 않는 경우가 있으므로 경계 수정에 주의가 필요합니다. 두 번째 간격 또는 두 번째 간격만 하위 간격인 경우 이번에는 병합 정렬을 수행할 필요가 없습니다.
//将两个有序小区间合并为一个
void _MergeSortSignal(int *a, int begin1, int end1, int begin2, int end2, int *tmp)//闭区间
{
int begin = begin1;//保存数组起始的位置方便拷贝
tmp = (int*)malloc(sizeof(int) * (10 + 1));
int i = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
//将剩下的一个数组尾插到tmp
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
for (int j = begin ; j <= end2; ++j)
{
a[j] = tmp[j];
}
free(tmp);
}
// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
{
//实现思路:这里如果借助栈来模拟会将问题变得复杂起来,所以可以采取循环的方式
//直接归并,第一次是相邻的两个数归并,这时候gap为1,第二次gap为而就是区间[i,i+gap-1] 和区间[i+gap,i+2*gap -1]进行插入排序,依次类推
//直到gap不小于数组的长度就结束
int gap = 1;
while (gap < n)
{
//单趟归并排序
for (int i = 0; i < n;++i)
{
//采用闭区间
//[i,i+gap-1] 和[i+gap,i+2*gap]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//调用将两个数组合并成一个数组的函数
if (begin2 >= n)
{
break;//说明要排序第二组不存在,只有第一组,本次不需要再排
}
if (end2 >= n)
{
//需要修正第二组的边界
end2 = n - 1;
}
_MergeSortSignal(a, begin1, end1, begin2, end2, NULL);
}
gap *= 2;
}
}
3.4.2 병합정렬 응용-외부정렬
병합 정렬은 다른 정렬과 다릅니다. 다른 정렬은 메모리 정렬에 적합하지만 병합 정렬은 메모리 정렬만 할 수 있는 것이 아니라 데이터가 많을 경우 메모리에 담을 수 없고 파일에만 저장할 수 있습니다. 이번에는 다른 정렬을 사용하기가 별로 쉽지 않은데, 병합 정렬은 데이터를 정렬해서 파일 내에서 할 수 있기 때문에 병합 정렬도 외부 정렬이다.
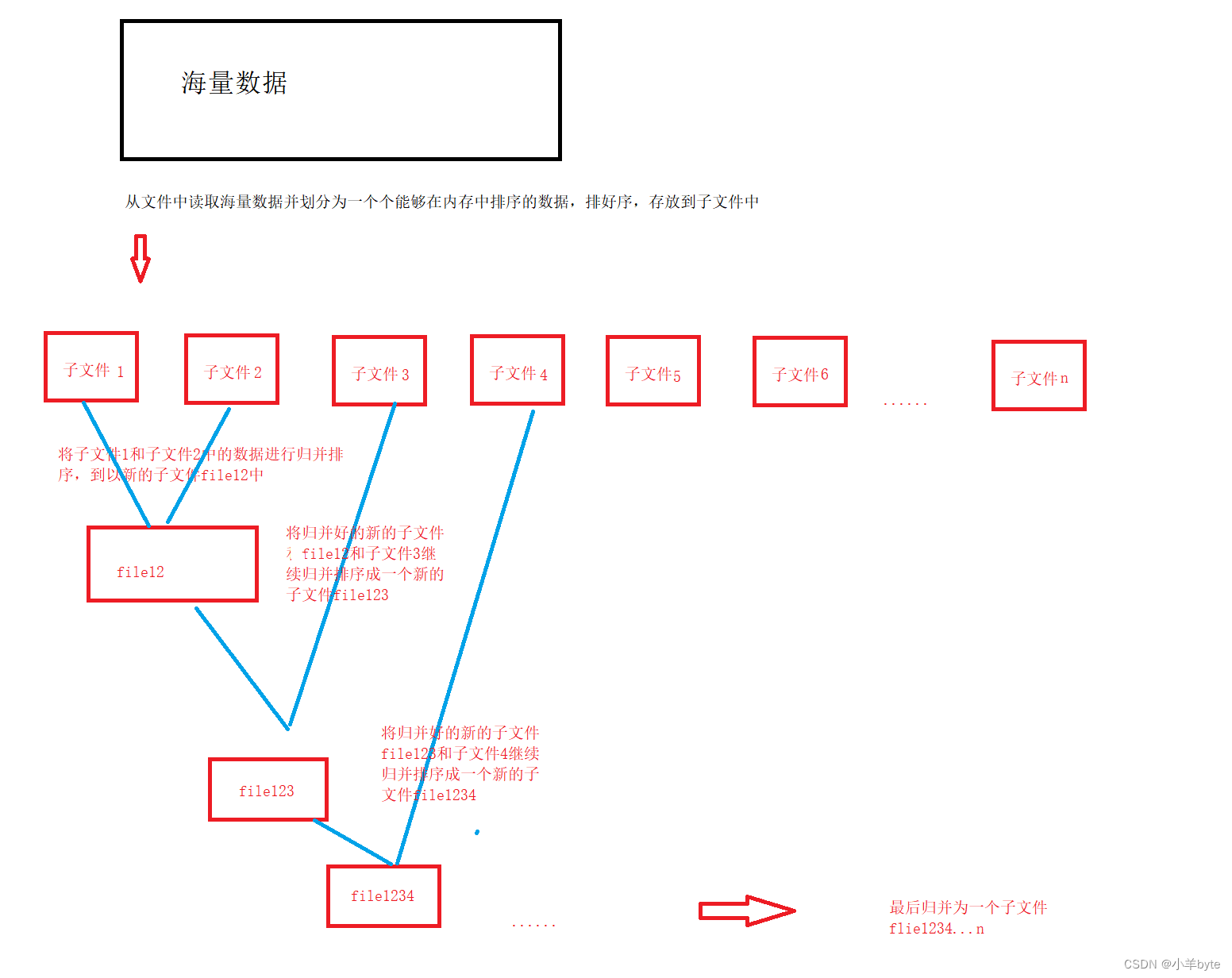
이제 한번에 메모리에 올릴 수 없는 엄청난 양의 데이터가 있다고 가정하고, 데이터를 정렬하고 결과를 파일로 저장하는 프로그램을 작성해 보겠습니다.
아이디어는 다음과 같습니다.
1. 먼저, 데이터를 여러 부분으로 나누어야 하며, 나누어진 각 부분을 한 번에 메모리에 로드하여 정렬할 수 있습니다.
2. 분할된 데이터를 하위 파일로 한번에 저장하고, 퀵 정렬을 이용하여 데이터를 정리합니다.
3. 이 시점에서 병합 정렬의 전제 조건이 충족되었으며 각 하위 시퀀스가 순서대로 정렬되어 있습니다. 이때 우리는 매번 두 파일의 데이터를 읽고 비교하여 새 파일로 병합하기만 하면 됩니다. 마지막으로 정렬된 모든 하위 구간이 하나의 파일로 병합될 때까지 동일한 방식으로 진행합니다. 이때 이 파일의 데이터는 모두 정렬됩니다.
암호:
//将两个文件中的有序数据合并到一个文件中并且保持有序
void _MergeFile(const char* file1, const char* file2, const char* mfile)
{
FILE* fout1 = fopen(file1, "r");
if (fout1 == NULL)
{
printf("fout1打开文件失败\n");
exit(-1);
}
FILE* fout2 = fopen(file2, "r");
if (fout2 == NULL)
{
printf("fout2打开文件失败\n");
exit(-1);
}
FILE* fin = fopen(mfile, "w");
if(fin == NULL)
{
printf("fin打开文件失败\n");
exit(-1);
}
int num1, num2;
int ret1 = fscanf(fout1, "%d\n", &num1);
int ret2 = fscanf(fout2, "%d\n", &num2);
//在文件中读数据进行归并排序
while (ret1 != EOF && ret2 != EOF)
{
if (num1 < num2)
{
fprintf(fin, "%d\n", num1);
//再去fout1所指的文件中读取数据
ret1 = fscanf(fout1, "%d\n", &num1);
}
else
{
fprintf(fin, "%d\n", num2);
//再去fout2所指的文件中读取数据
ret2 = fscanf(fout2, "%d\n", &num2);
}
}
while (ret1 != EOF)
{
fprintf(fin, "%d\n", num1);
ret1 = fscanf(fout1, "%d\n", &num1);
}
while (ret2 != EOF)
{
fprintf(fin, "%d\n", num2);
ret2 = fscanf(fout2, "%d\n", &num2);
}
fclose(fout1);
fclose(fout2);
fclose(fin);
}
void MergeSortFile(const char* file)//文件归并排序
{
//打开文件
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
printf("打开文件失败\n");
exit(-1);
}
int n = 10;
int a[10] = { 0 };
char subr[1024] ;
/*memset(subr, 0, 1024);
memset(a, 0, sizeof(int) * n);*/
int num = 0;
int i = 0;
int fileI = 1;
while (fscanf(fout, "%d\n",&num )!=EOF)
{
if (i < n - 1)
{
a[i++] = num;
}
else
{
a[i] = num;
QuickSort(a, 0, n - 1);//对内存中的数据进行排序
sprintf(subr, "%d", fileI++);
FILE* fin = fopen(subr, "w");
if (fin == NULL)
{
printf("打开文件失败\n");
exit(-1);
}
//写数据到文件中
for (int j = 0; j < n; ++j)
{
fprintf(fin, "%d\n", a[j]);
}
//关闭文件
i = 0;//置零对下一组数据进行操作
/*memset(subr, 0, 1024);
memset(a, 0, sizeof(int) * n);*/
fclose(fin);
}
}
//外排序
//利用互相归并到文件中,实现整体有序
char file1[100] = "1";
char file2[100];
char mfile[100] = "12";
for (int i = 2; i <= n; ++i)
{
sprintf(file2, "%d", i);
//读取FIle和file2,进行归并排序出mfile
_MergeFile(file1, file2, mfile);
strcpy(file1,mfile);
sprintf(mfile, "%s%d", mfile, i + 1);
}
fclose(fout);
return NULL;
}
3.5 비비교 정렬
이름에서 알 수 있듯이, 비비교 정렬은 요소를 비교하지 않고 정렬할 수 있는데, 여기서 소개하는 것이 카운팅 정렬 입니다 .
비둘기집 원리라고도 알려진 계수 정렬은 해시 직접 값 방법을 변형하여 적용한 것입니다. 단계:
1. 같은 요소가 나타나는 횟수를 센다
2. 통계 결과를 바탕으로 시퀀스를 원래 시퀀스로 재활용합니다.

암호:
// 计数排序
void CountSort(int* a, int n)
{
//先遍历数组,找出最大值和最小值用来确定范围
int max = a[0];
int min = a[0];
for (int i = 0; i < n; ++i)
{
if (max < a[i])
{
max = a[i];
}
if (min > a[i])
{
min = a[i];
}
}
//然后根据最大值和最小值的范围开辟空间
int range = max - min + 1;
int* CountArray = (int*)calloc(sizeof(int), range);
//统计原数组中每个数出现的次数
for (int i = 0; i < n; ++i)
{
CountArray[ a[i] - min ] ++ ;//利用相对位置来计算数据出现的个数
}
/*Print(CountArray, 9);
printf("\n");*/
//将临时数组中的数,覆盖到原数组中
int j = 0;
for (int i = 0; i < range; ++i)
{
while (CountArray[ i ]--)
{
a[j++ ] = i + min;//将每个数据从临时数组中拿出来加上相对数据min,然后对数组进行覆盖
}
}
//释放临时开辟的空间
free(CountArray);
}
계산 정렬의 기능 요약:
1. 집계 정렬은 데이터 범위가 집중되어 있을 때 매우 효율적이지만 적용 범위와 시나리오가 제한됩니다.
2. 시간 복잡도 O(max(N, 범위))
3. 공간 복잡도 O(범위)
4. 정렬 알고리즘의 복잡성 및 안정성 분석

안정성이란 무엇입니까? 일반적으로 배열 내 동일한 요소의 상대적 위치가 정렬 후에도 변경되지 않는다는 의미입니다 . 그렇다면 안정성 또는 불안정성의 영향은 무엇입니까? 이는 일부 특별한 시나리오에 영향을 미칩니다. 예를 들어 시험에서 상위 3명에게 상이 주어져야 합니다. 상위 3명을 어떻게 결정합니까? 예를 들어 상위 5위의 점수는 99 98 97 97 97입니다. 이 경우 3위, 4위, 5위의 점수가 동일하므로 상위 3위를 직접 결정하는 것은 불가능하므로 또 다른 규칙이 있습니다. 이때, 이 게임의 결과가 같을 경우, 시간이 더 짧은 쪽이 앞서는 것이 규칙입니다. 따라서 이 경우에는 안정적인 정렬을 통해 상위 3개를 결정할 수 있어 누구에게나 공평하지만, 불안정한 정렬이라면 결과는 불공정하다.
선택 정렬이 불안정한 경우 일련의 집합에 동일한 최대값이 여러 개 나타나는 경우 어떤 것을 선택할지 문제가 되거나 아래와 같습니다.
힙 정렬도 불안정하여 힙을 만들거나 숫자를 선택할 때 아래쪽으로 조정해야 하며 아래쪽으로 조정하면 그림과 같이 동일한 요소의 상대적 순서가 변경될 수 있습니다.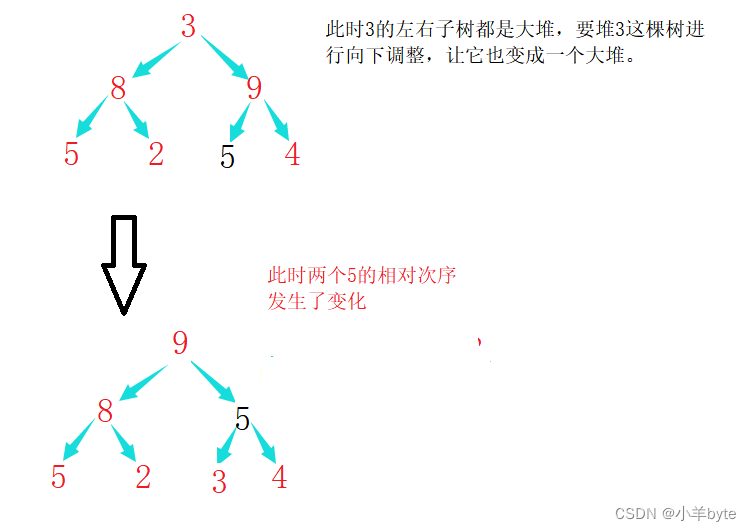
퀵 정렬도 불안정합니다. 비교를 위해 벤치마크를 선택하면 상대 순서가 바뀔 수 있기 때문입니다.
Hill 정렬도 불안정합니다. 왜냐하면 사전 정렬 중에 동일한 숫자가 다른 그룹으로 나누어질 수 있어 상대적인 순서가 보장되지 않기 때문입니다. 카운팅 정렬은 원래 배열에서 각 요소의 발생 횟수를 계산하므로 동일한 요소의 상대적 위치를 보장할 수 있는 방법이 없습니다.