Pregunta diaria de la Copa ACWing Blue Bridge
Nunca he tenido tiempo de resumir el algoritmo, y finalmente tengo tiempo de resumir el acwing. Como no tengo tiempo, solo he estudiado una pregunta de la Blue Bridge Cup de ACWING diariamente. . . Maldita sea
1. Truncar la matriz

En primer lugar, debemos saber que si sum(a) no es divisible por 3 o len(a) < 3, entonces definitivamente no podrá hacer que la suma de los tres subarreglos truncados sea la misma. Solo es necesario calcular el valor promedio y atravesar de adelante hacia atrás
. Obtendremos el 1 punto de corte promedio y también obtendremos los 2 puntos de corte promedio, lo que significa que la suma de los subarreglos antes del 1 punto de corte promedio es promedio , entonces la respuesta es en realidad el número de 2 puntos de corte promedio + el número en los 2 puntos de corte promedio El número de 1 punto de corte promedio anterior , por lo que solo necesitamos dejar que cuando tot = 2 promedio, la respuesta += el número de 1 puntos de corte promedio en ese momento.
¡Aviso! Al juzgar si tot = promedio o 2 promedio, primero debe juzgar si es igual a 2 promedio, porque cuando tot es igual a 0, 1 promedio == 2 promedio, si juzga 2 * promedio primero, comparará el primero. punto de truncamiento de nivel y el segundo nivel. Los puntos de corte de nivel están en el mismo lugar. .
Al mismo tiempo, considerando la situación en la que la matriz es todo 0, en este caso podemos usar C(len-1,2)
El código específico es el siguiente.
n = int(input())
a = [int(x) for x in input().split()]
def c(a,b):
res = 1
while b:
res = res * a / b
a -= 1
b -= 1
return int(res)
if sum(a) % 3 != 0 or len(a) < 3:
print(0)
elif a == [0]*len(a):
print(c(len(a)-1,2))
else:
average = sum(a) // 3
one = 0
res = 0
tot = 0
for i in range(n-1): # 最后一个点不能考虑进去,要留下一个做第三部分
tot += a[i]
if tot == 2*average: res += one
if tot == average:one += 1
print(res)
2. Cambiar elementos de la matriz

Inicialice una matriz V con tamaño (n+1). La inicialización es todo 0.
Solo necesita atravesar a[i] hasta i. Cuando se alcanza el i-ésimo recorrido, sumamos todo i - a[i] + 1 a i. 1.
Puedo representar la longitud real de la matriz V. Por ejemplo, cuando i = 5, entonces la longitud real de la matriz V es 5, porque solo se agregan 5 ceros al final, y luego se supone un [ 5] = 2, es decir, V[4] y V[5] + 1. ¿Por qué se puede usar + 1 aquí en lugar de hacerlo igual a 1? Debido a que no se ha restado todo el proceso, siempre que esta posición no sea igual a 0, significa que se ha cambiado, debe ser igual a 1,
y la realización de sumar 1 de i - a [i] + 1 a i es muy fácil de lograr a través de la diferencia Entendido
El código específico es el siguiente.
def add(l,r): # 差分,最后前缀和后L到R + 1
V[l] += 1
V[r+1] -= 1
t = int(input())
for _ in range(t):
## 第i次就等于从i- a[i] + 1到i 全变为1
## 利用差分,从 i - a[i] + 1 到 i 全部加1 ,因为不会减,所以最后只要前缀和不是0就代表他被换过
n = int(input())
a = [int(x) for x in input().split()]
V = [0]*(n+1) #直接开一个这么大的数组,直接开N TLE了
for i in range(1,n+1): # i要从1开始,i等于1表示数组中末尾添加了一个0
if a[i-1] == 0:continue
if (a[i-1] >= i):
add(0,i-1)
else:
add(i - a[i-1],i-1)
for i in range(n):
V[i+1] += V[i]
for i in range(n):
if V[i] != 0 :print(1,end = ' ')
else: print(0,end = ' ')
print()
3. ¿Dónde estoy?

Creo que lo principal de esta pregunta es considerar el almacenamiento hash de la cadena, porque la cadena no puede usar el subíndice para encontrar la primera letra como una matriz, por lo que la cadena debe procesarse y almacenarse primero, y luego atravesar la lista. , por ejemplo k = 4, coloque los primeros cuatro valores de la cadena en el conjunto y luego verifique si el valor hash de la cadena 2-5 está en el conjunto; si es así, devuelva False y luego encuentre
K. Simplemente comience a atravesar desde 1, pero la complejidad del tiempo es O (n) y puede quedarse atascado. Es mejor usar dos puntos.
El código específico es el siguiente.
hash de cadena
## 核心思想:将字符串看成P进制数,P的经验值是131或13331,取这两个值的冲突概率低
## 小技巧:取模的数用2^64,溢出的结果就是取模的结果
## h[k]存储字符串前k个字母的哈希值, p[k]存储 P^k mod 2^64
N = 10**5 +10
P = 131
M = 91815541
h = [0] * N
p = [0] * N
p[0] = 1
n = int(input())
s = " " + input()
for i in range(1,n+1):
h[i] = h[i-1]*P + ord(s[i]) % M
def get(l,r):
return (h[r] - h[l-1] * P**(r-l+1)) % M
def check(k):
a = set()
for i in range(1,n - k + 2):
if get(i,i + k -1) in a:
return False
else:
a.add(get(i,i+k-1))
return True
if __name__ == '__main__':
l,r = 1,n
while l < r:
mid = (l + r) >> 1
if check(mid): r = mid
else: l = mid + 1
print(r)
4. Eliminación de cadenas
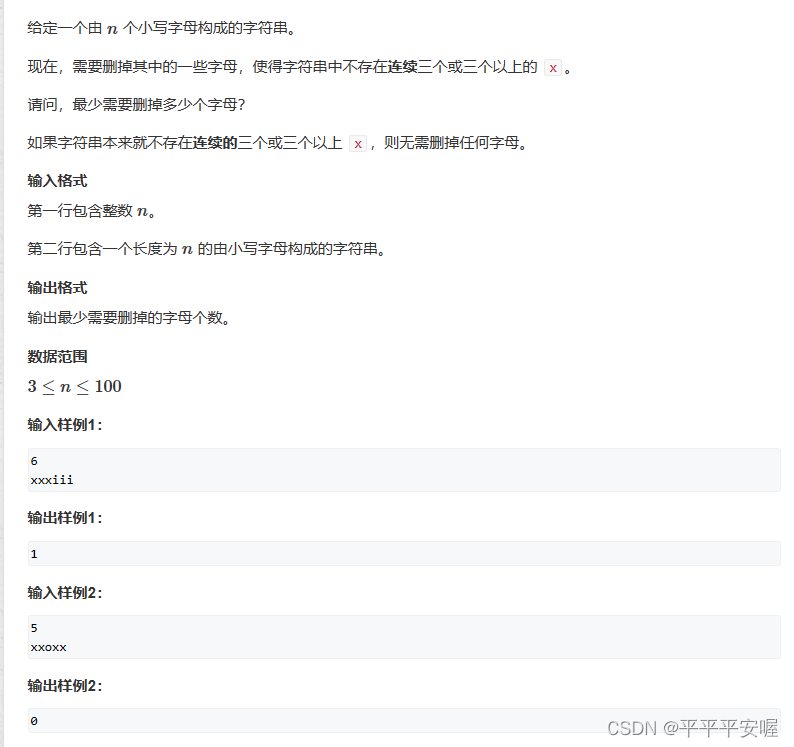
Esto es más fácil de hacer que Python. No sé nada más. Simplemente registre la longitud de x consecutivas y luego calcule al final. Solo mire el código.
El código específico es el siguiente.
n = int(input())
s = input()
lens = 0
lenshuzu = [] # 记录每一段连续的数组
for i in s:
if i == 'x':
lens += 1
else:
lenshuzu.append(lens)
lens = 0
lenshuzu.append(lens)
res = 0
for i in lenshuzu:
if i >= 3:
res += i - 2
print(res)
5. Ladrillos


Elijo usar el método codicioso para hacer esta pregunta. Hay dos tipos, todo negro y todo blanco
. Si es todo blanco, cuando veas un ladrillo negro, simplemente vuélvelo blanco
. La operación de entrada puede ser un poco problemática. para que yo escriba. . ¿Existe algún experto que tenga un método más sencillo que pueda guiarme?
El código específico es el siguiente.
T = int(input())
for _ in range(T):
k = int(input())
p = input()
p2 = p #记录一下
p = list(p)
caozuo1 = []
ans1 = 0
flag1 = False
flag2 = False
# 全变白色
for i in range(k-1):
if p[i] == 'B':
p[i] = 'W'
if p[i+1] == 'B':p[i+1] = 'W'
else: p[i+1] = 'B'
caozuo1.append(i+1)
ans1 += 1
if p == ['W']*k :flag1 = True
# 全变黑色
p2 = list(p2)
caozuo2 = []
ans2 = 0
for i in range(k-1):
if p2[i] == 'W':
p2[i] = 'B'
if p2[i+1] == 'W':p2[i+1] = 'B'
else: p2[i+1] = 'W'
caozuo2.append(i+1)
ans2 += 1
if p2 == ['B']*k:flag2 = True
if flag1 and flag2:
if ans1 < ans2:
print(ans1)
if caozuo1:
for i in caozuo1:
print(i,end = ' ')
print()
continue
else:
print(ans2)
if caozuo2:
for i in caozuo2:
print(i,end = ' ')
print()
continue
if flag1:
print(ans1)
if caozuo1:
for i in caozuo1:
print(i,end = ' ')
print()
continue
if flag2:
print(ans2)
if caozuo2:
for i in caozuo2:
print(i,end = ' ')
print()
continue
print(-1)
6. recorrido del árbol
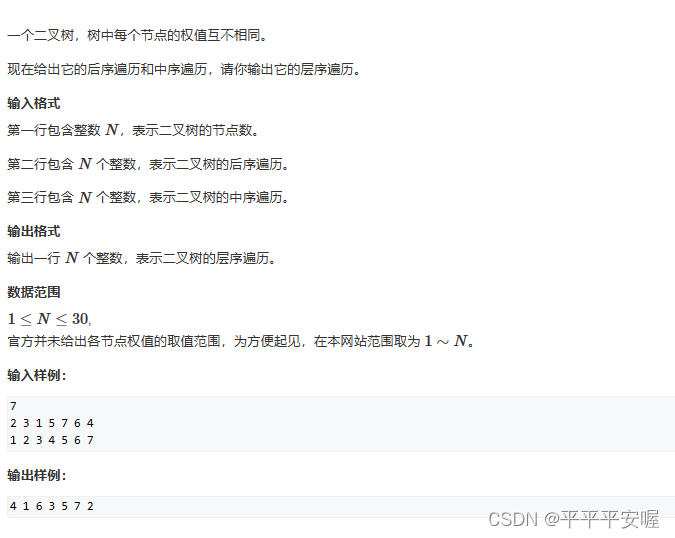
Esta pregunta se resuelve de forma recursiva: puede encontrar el orden interno y posterior de los subárboles izquierdo y derecho del nodo raíz a través del orden interno y posterior, y luego construirlo de forma recursiva.
Después de construir un árbol, simplemente use Dfs para buscarlo.
El código específico es el siguiente.
class TreeNode(object):
def __init__(self,x):
self.val = x
self.left = None
self.right = None
class Solution(object):
def buildTree(self,inorder,postorder): # inorder是中序,postorder是后序
if not postorder:
return None
root = TreeNode(postorder[-1])
root_index = inorder.index(postorder[-1]) # 根节点在中序中的坐标
left_i = inorder[:root_index] # 根据中序确定左右子树
right_i = inorder[root_index + 1:]
len_li = len(left_i) # 左子树长度
left_p = postorder[:len_li] # 确定后序遍历的左右子树
right_p = postorder[len_li:-1]
root.left = self.buildTree(left_i,left_p)
root.right = self.buildTree(right_i,right_p)
return root
def bfs(root): #广搜进行层序遍历
if root == None:
return
q = []
q.append(root)
head = 0
while len(q)!=0:
print(q[head].val,end=' ')
if q[head].left != None:
q.append(q[head].left)
if q[head].right != None:
q.append(q[head].right)
q.pop(0)
n = int(input())
posto = [int(x) for x in input().split()]
inord = [int(x) for x in input().split()]
solution = Solution()
root = solution.buildTree(inord,posto)
bfs(root)
7. Familiares

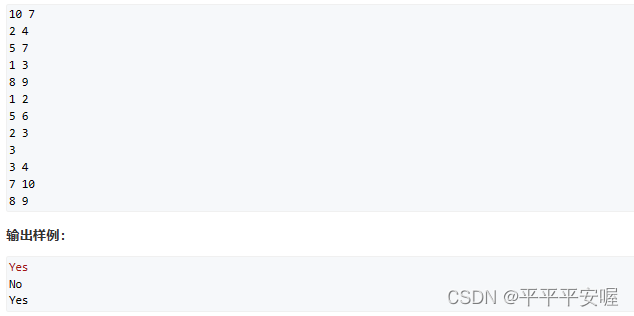
Ah, esta es una pregunta típica de búsqueda de unión. Simplemente deje que los mismos parientes tengan el mismo antepasado. No importa quién sea el antepasado. En pocas palabras, la búsqueda de unión es tener una matriz p, que representa quién es
su
padre. y luego cada uno atraviesa dos a y b a la vez. Si a y b no tienen el mismo antepasado, dejamos que el antepasado de a se convierta en el hijo del antepasado de b. De esta manera, a y b tienen el mismo antepasado, ¿bien?
Entonces, ¿cómo encontrar los antepasados de ayb? Esta es también la esencia de la búsqueda unida, una función de búsqueda.
def find(x):
if p[x] != x:
p[x] = find(p[x])
return p[x]
Si el padre de x no es él mismo, significa que x no es el antepasado de esta familia, ¿verdad? Entonces sea p [x] igual a encontrar (p [x]), y encontrar (p [x]) es encontrar el antepasado de p[x]. Busque en línea capa por capa. La esencia de esta función de búsqueda es que hará que p[x] = find(p[x]). Es decir, si encuentra el P[x] de un línea de ancestros, directamente pasará a ser de ellos. Ancestros, no sus padres.
Entonces sería fácil ver si sus ancestros son los mismos para representar si son un grupo.
El código completo específico es el siguiente
import sys
# 不知道为什么用map(int,input().split())会被卡。。
N, M = map(int, sys.stdin.readline().strip().split())
p = [i for i in range(N + 1)]
def find(x):
if p[x] != x:
p[x] = find(p[x])
return p[x]
for i in range(M):
a, b = map(int, sys.stdin.readline().strip().split())
pa, pb = find(a), find(b)
if pa != pb:
p[pa] = pb
q = int(input())
for i in range(q):
a, b = map(int, sys.stdin.readline().strip().split())
if find(a) == find(b):
print('Yes')
else:
print('No')
8. Dedos torpes

Mi idea para esta pregunta es cambiar cada bit del sistema binario, es decir, almacenar todas las posibles respuestas correctas en una lista y luego comparar las listas binaria y ternaria para encontrar las mismas. El sistema binario es fácil de hacer, 0 Simplemente use ^ para convertir entre
El código específico es el siguiente.
import copy
er = input()
three = input()
erjinzhi = []
sanjinzhi = []
for i in range(len(er)):
erjinzhi.append(int(er[i]))
for j in range(len(three)):
sanjinzhi.append(int(three[j]))
res_2 = []
res_3 = []
copy_erjinzhi = copy.deepcopy(erjinzhi)
for i in range(len(erjinzhi)): #勉强算20
erjinzhi = copy.deepcopy(copy_erjinzhi)
erjinzhi[i] = erjinzhi[i] ^ 1
lenlen = 2**(len(erjinzhi)-1)
res = 0
for j in erjinzhi:
res += j*lenlen
lenlen >>= 1
res_2.append(res)
copy_sanjinzhi = copy.deepcopy(sanjinzhi)
for i in range(len(sanjinzhi)): #勉强算20
for j in range(3):
sanjinzhi = copy.deepcopy(copy_sanjinzhi)
if sanjinzhi[i] != j:
sanjinzhi[i] = j
lenlen = 3**(len(sanjinzhi) - 1)
res = 0
for k in sanjinzhi:
res += k*lenlen
lenlen //= 3
res_3.append(res)
res = 0
for i in res_2:
for j in res_3:
if i == j:
res = max(res,i)
print(res)
9. Secuencia de cultivos
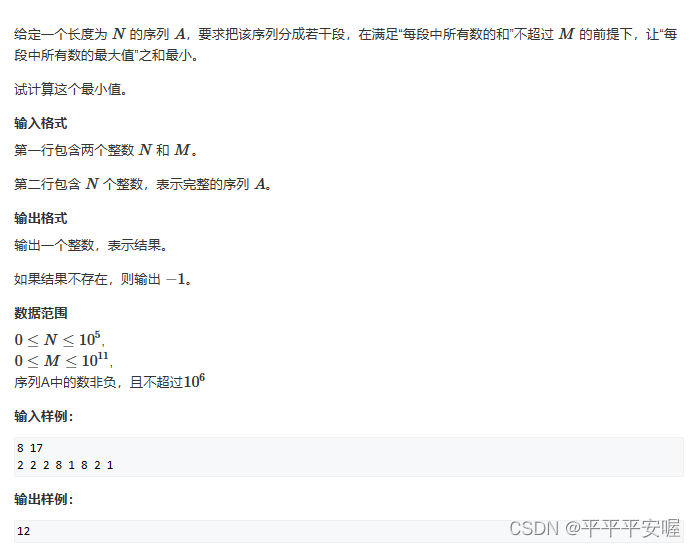
Yo tampoco lo entiendo. . Sentir lástima
10.Ciclo


En primer lugar, necesitamos saber para qué se utiliza la siguiente matriz del algoritmo KMP. Puede encontrar una matriz con el mismo número de sufijos y prefijos. Para conocer el método específico, puede ver mi algoritmo de escritura a mano KMP.
Entonces solo necesitamos escanearlo de principio a fin, siempre que (i % (i-next[i])) == 0, significa que hay una sección repetida y la longitud es i // (i - next [i]). Por ejemplo, abcabcabcabc cuando
i es igual a 12, es la longitud completa. Entonces next[i] = 9
satisface la condición, ¿verdad? La longitud es 4
El código específico es el siguiente.
def find_next(p):
next = [0] * (len(p)+1)
j,k = 0,-1
next[0] = -1 # 防止死循环 k一直等于0 j也不加
while(j <= len(p) - 1):
if (k == -1 or p[j] == p[k]):
j += 1
k += 1
next[j] = k
else:
k = next[k]
next[0] = 0
return next
if __name__ == '__main__':
flag = 1
while True:
n = int(input())
if n == 0: break
print('Test case #{}'.format(flag))
s = input()
next = find_next(s)
for i in range(2,n+1):
if i % (i - next[i]) == 0 and next[i]:
print('{} {}'.format(i,i//(i - next[i])))
print()
flag += 1
11. Suma máxima XOR

Primero encuentre la suma XOR [i] de los primeros i números y luego realice una prueba dentro de una ventana deslizante de tamaño m.
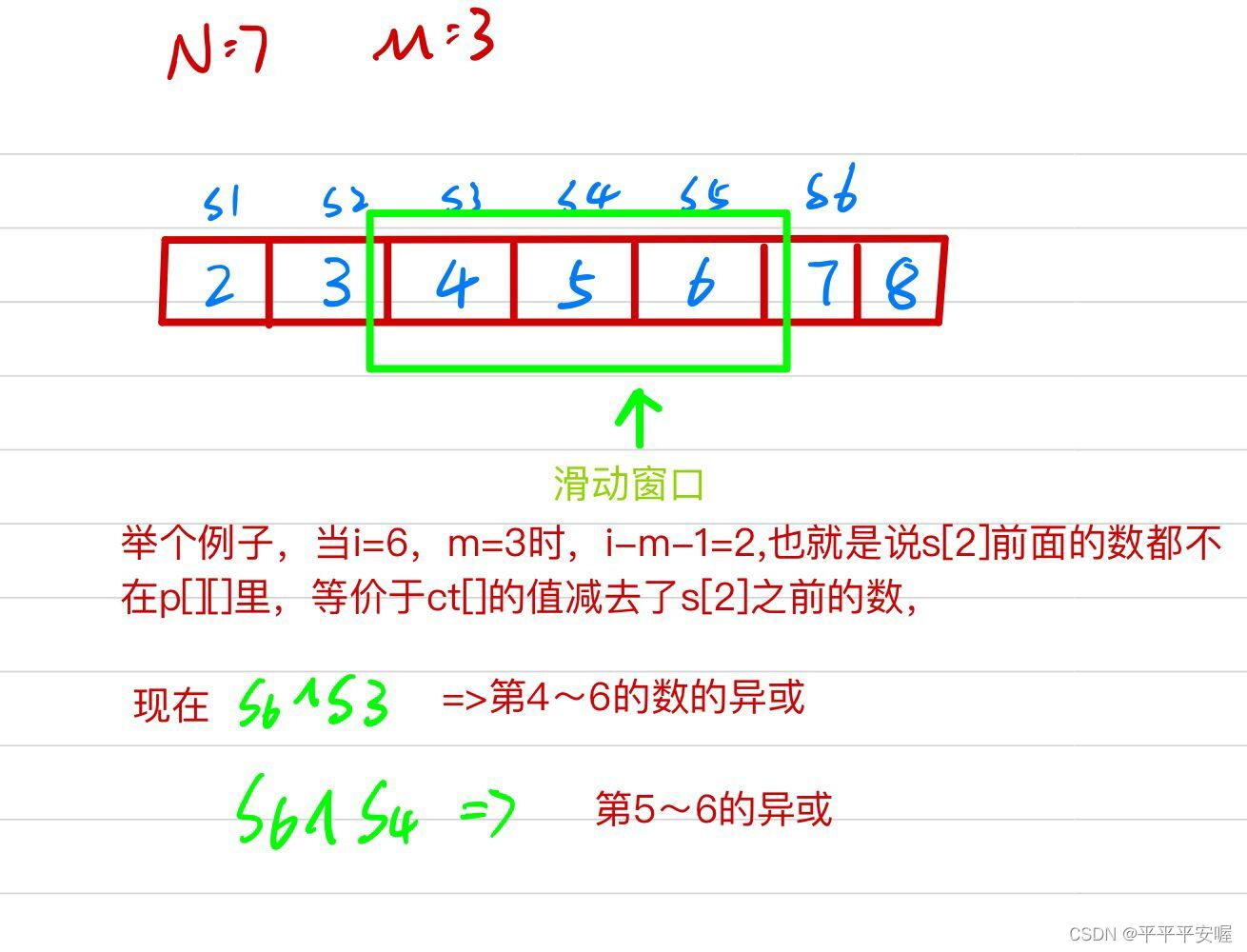
Consulte https://www.acwing.com/solution/content/48648/Use
a trie tree , Cada número se registra en un árbol trie, una puntuación binaria, cada nodo tiene un hijo 0, 1, usamos 30 capas aquí, lo cual es completamente suficiente, y luego le damos el número binario de cada número para almacenarlo, primero
calcule el prefijo XOR suma s[i]
requiere XOR suma a[l] ... a[r] se convierte en prefijo XOR suma matriz (s[r]^s[l-1])
El código específico es el siguiente.
N = 100010 * 31
M = 100010
son = [[0]*2 for _ in range(N)] # son[p][n] n 只有两个取值为0和1,
idx = 0
s = [0]*M
cnt = [0]*N # cnt变量表示这个节点在构建字典树的时候保存了几次
# 遍历的时候,如果节点的cnt>0,就代表可以接着往下走,
def insert(x,v):
global idx,son,s,cnt
p = 0
for i in range(30,-1,-1):
# 意思就是一棵树有30层,来代表每个数的二进制数
u = x >> i & 1
if(int(not son[p][u])): # p的儿子有0和1两条路径
idx += 1
son[p][u] = idx
p = son[p][u] #p变为儿子,如果v是1,那么这条路径的p的1儿子+1
cnt[p] += v
### 我们遍历的话肯定是想从最高位开始,走1的分支,因为那样异或和才会更大
def query(x):
# res 初始值为s[i]
res = x
p = 0
for i in range(30,-1,-1):
u = x >> i & 1 # x的二进制的第i位
## 现在x的第i位是u ,所以我们要走跟u相反的,这样他们异或才会为1
if cnt[son[p][int(not u)]]: # 就是存在和不存在 p 有两个儿子嘛,一个是0一个是1,如果u是1,就要看p的0的儿子还有没有
u = int(not u)
res ^= u << i # u << i 因为之前 u = x >> i & 1 了,现在还回去
# print(res)
p = son[p][u] # 接着往下走
return res
if __name__ == '__main__':
n,m = map(int,input().split())
a = [int(x) for x in input().split()]
for i in range(1,n+1):
s[i] = s[i-1]^a[i-1]
insert(s[0],1)
Res = 0
for i in range(1,n+1):
if i > m :
insert(s[i - m - 1],-1)
Res = max(Res,query(s[i]))
insert(s[i],1) # 把s[i]加入到树中
print(Res)
12. Reenvío de Weibo

Una plantilla de bfs muy tradicional. Solo necesitas registrar a los fans de todos y luego atravesar la capa L.
El código específico es el siguiente.
N = 1010
son = [[] for _ in range(N)]
from collections import deque
st = [False] * N
N,L = map(int,input().split())
for i in range(1,N+1):
M = [int(x) for x in input().split()] # 记录一下第i个的信息
if M[0] != 0: # 如果用户i有关注人的话
for j in range(M[0]):
son[M[j+1]].append(i) # son记录的是谁关注了你
K = [int(x) for x in input().split()]
def bfs(): #传统bfs
res = -1
for _ in range(L+1): # 遍历L次
sizes = len(q)
for _ in range(sizes): # 每次只遍历他这一层的数
tmp = q.popleft()
if not st[tmp]: # 这个人没被传播过
res += 1
for i in son[tmp]:
q.append(i)
st[tmp] = True
return res
for i in range(K[0]):
st = [False] * 1010
k = K[i+1]
q = deque()
q.append(k)
print(bfs())
13. Número de caminos diferentes

Esta es una pregunta de búsqueda profunda muy estándar, no siento que necesite hablar demasiado, solo mire el código y es fácil de entender.
El código específico es el siguiente.
n,m,k = map(int,input().split())
migong = []
res = 0
s = [False] * 1000010 # 最多六位数
for _ in range(n):
migong.append([int(x) for x in input().split()]) # 存储迷宫
directions = [(1,0),(-1,0),(0,1),(0,-1)] # 四个方向
def dfs(i,j,p,o):
global res
if p == k: # P是长度,长度为k的时候,组成的数字要是之前没有过,res就+1
if not s[o]:
s[o] = True
res += 1
return
for direction in directions:
x,y = i + direction[0],j+direction[1]
if x >= 0 and x < n and y >= 0 and y < m: # 四个方向都走一遍
dfs(x,y,p+1,10*o + migong[x][y]) # 深搜
for i in range(n):
for j in range(m):
dfs(i,j,0,migong[i][j]) # 每个点为起点都深搜一下
print(res)
14. Construya un gráfico acíclico dirigido.

En primer lugar, tenemos que juzgar si es un gráfico cíclico. Si es así, debemos pasarlo. Solo depende de si el número total de clasificaciones topológicas es n. Si es un gráfico cíclico, el número de resultados de la clasificación topológica la clasificación no puede ser n., porque el anillo no se agregará a la clasificación topológica,
entonces, siempre que siga el orden de la clasificación topológica y agregue la dirección del borde no dirigido, definitivamente no formará un gráfico cíclico.
El código específico es el siguiente.
import collections
T = int(input())
def topsort(): # 拓扑排序并判断是否会构成有环图
Q = collections.deque()
for x in range(1,n+1):
if indegree[x] == 0:
Q.append(x)
cnt = 0
while Q:
x = Q.popleft()
rec_topsort.append(x)
cnt += 1
for y in adjvex[x]:
indegree[y] -= 1
if indegree[y] == 0:Q.append(y)
return cnt == n
for _ in range(T):
n,m = map(int,input().split())
adjvex = collections.defaultdict(list) # 有向边
indegree = [0 for _ in range(n+1)] # 入度
aedge = [] # 无向边
for _ in range(m):
t,x,y = map(int,input().split())
if t == 1:
adjvex[x].append(y) # X --> Y
indegree[y] += 1
else:
aedge.append((x,y))
rec_topsort = [] # 拓扑排序
if not topsort():print('NO')
else:
print('YES')
x_pos = dict()
for i, x in enumerate(rec_topsort):
x_pos[x] = i
for x,y in aedge: #通过拓扑排序去构建无向边的方向,这样无论如何都不会构成有向图
if x_pos[y] < x_pos[x]:
x,y = y,x
print("{} {}".format(x,y))
for x,ys in adjvex.items():
for y in ys:
print("{} {}".format(x,y))
15. Distancia más corta

El algoritmo de Dijkstra almacena la distancia en una matriz, y luego es el algoritmo de Dijkstra estándar. Siento que estas preguntas son muy buenas y bastante representativas. Recuerde recordar la plantilla y será fácil de resolver.
El código específico es el siguiente.
from collections import deque
N,M = map(int,input().split())
max_c = 10010
g = [[max_c]*(N+1) for _ in range(N+1)]
for _ in range(M):
a,b,c = map(int,input().split())
g[a][b] = c
g[b][a] = c
K = int(input())
store = []
for _ in range(K):
x = int(input())
store.append(x)
Q = int(input())
for _ in range(Q):
dist = [max_c]*(N+1)
st = [False] * (N+1)
y = int(input())
dist[y] = 0
for _ in range(N+1):
t = -1
for j in range(1,N+1):
if (not st[j] and (t == -1 or dist[t] > dist[j])):
t = j
st[t] = True # 找到一个距离选中集合最近的点
for j in range(N+1):
dist[j] = min(dist[j],dist[t] + g[t][j],dist[t] + g[j][t]) # 加入了之后更新所有的距离
res = max_c
for i in store:
res = min(dist[i],res)
print(res)
16. Hibridación de cultivos


Hice esta pregunta en la Copa Lanqiao. Utilicé la búsqueda profunda, pero no pude pasar la búsqueda profunda aquí. Como me estaba preparando para la Copa Lanqiao, utilicé la búsqueda profunda aquí, pero esta pregunta debería ser una pregunta de búsqueda profunda de SPFA
. Es muy sencillo, empieza por la semilla que quieras y busca hacia abajo, por ejemplo si quiero la semilla nº 6, veré quién la consigue cruzando con quién. Suponiendo que la semilla 1 + la semilla 2 se obtendrán mediante cruzamiento, entonces el tiempo para obtener la semilla 6 será igual a max (el tiempo para obtener 1, el tiempo para obtener 2) + max (el tiempo en que cada una madura)) y así en recursivamente.
El código específico es el siguiente.
# 蓝桥杯能过代码,这里会报Runtime error
N,M,K,T = map(int,input().split())
time = [int(x) for x in input().split()] # 第i种作物种植时间
have = [int(x) for x in input().split()] # 已有的种子
cross = [[] for _ in range(N+1)]
for _ in range(K):
a,b,c = map(int,input().split())
cross[c].append((a,b))
st = [False]*(N+1) # 是否确定最短路
g = [100000]*(N+1) # 最短路
for i in have:
st[i] = True
g[i] = 0
def dfs(u):
if st[u] : return g[u]
for a,b in cross[u]:
g[u] = min(g[u],max(dfs(a),dfs(b)) + max(time[a-1] , time[b-1]))
st[u] = True
return g[u]
print(dfs(T))
17.Ferrocarriles y carreteras

Esta pregunta no necesita considerar que el tren y el auto chocarán en el medio, porque si el tren puede llegar a i en la ciudad de i, entonces significa que el auto no puede ir directamente a i, por lo que solo necesitamos preguntar dos veces para llegar al destino. El tiempo más corto para un automóvil, tome el valor máximo
. Dado que la cantidad de datos es relativamente pequeña, use floyd
primero para construir ferrocarriles y carreteras. Esto debería ser fácil de construir, y luego floyd también es fácil de escribir Es un bucle de tres capas, o (n ^ 3) Complejidad de tiempo, pero los datos de esta pregunta son pequeños, así que solo uso este y es más fácil de escribir.
El código específico es el siguiente.
n,m = map(int,input().split())
inf = 1000
road = [[False]*(n+1) for _ in range(n+1)]
a = [[inf] * (n+1) for _ in range(n+1)] # 铁路
b = [[inf] * (n+1) for _ in range(n+1)] # 公路
for i in range(n+1):
a[i][i] = 0
for _ in range(m):
x,y = map(int,input().split())
road[x][y] = road[x][y] = True
a[x][y] = a[y][x] = min(a[x][y],1) # 有铁路距离就为1了
for i in range(1,n+1):
for j in range(1,n+1):
if not road[i][j] and not road[j][i]:
b[i][j] = min(b[i][j],1)
def floyd():
for k in range(1,n+1):
for i in range(1,n+1):
for j in range(1,n+1):
a[i][j] = min(a[i][j],a[i][k] + a[k][j])
if a[1][n] == 1000:
return -1
for k in range(1,n+1):
for i in range(1,n+1):
for j in range(1,n+1):
b[i][j] = min(b[i][j],b[i][k] + b[k][j])
if b[1][n] == 1000:
return -1
return max(a[1][n],b[1][n])
print(floyd())
18. Electrificar la ciudad


Esta sensación de electricidad es el árbol de expansión mínima. Lo entendí a grandes rasgos antes, pero hoy estoy demasiado cansado para pensar en ello de nuevo. Volveré a ello más tarde.
El código específico es el siguiente.
INF = 10 ** 16
n = int(input())
nodes = []
for _ in range(n):
x, y = map(int, input().split())
nodes.append((x, y))
cs = [] + [int(x) for x in input().split()]
ks = [] + [int(x) for x in input().split()]
edge = [[INF for _ in range(n + 1)] for _ in range(n + 1)]
for i in range(n):
for j in range(i, n):
xi, yi = nodes[i]
xj, yj = nodes[j]
dist = abs(xi - xj) + abs(yi - yj)
cost = dist * (ks[i] + ks[j])
edge[i][j] = cost
edge[j][i] = cost
#-------------- prim 算法求最小生成树MST 稠密图:for循环 稀疏图:才用minHeap-------------#
MST_cost = 0
MST = [False for _ in range(n + 1)]
#----初试化时,每个结点直接连发电站
dist = [INF for _ in range(n + 1)] #从发电站 n出发
for x in range(n):
dist[x] = cs[x] #初始化,每个点自己连接发电站
dist_prev = [n for _ in range(n + 1)] #MST中点的前驱结点(与dist的初始化一致,前驱结点是发电站)
rec = [] #记录直接连接发电站的点
line = [] #记录发电线
dist[n] = 0
MST[n] = True
for _ in range(n):
#----寻找候选区中,dist最小的点(距离MST最近的点)
t = -1
for x in range(n):
if MST[x] == False and (t == -1 or (0 <= t and dist[x] < dist[t])):
t = x
#----正式加入MST
MST[t] = True
MST_cost += dist[t]
#---- 记录本题的需要
if dist_prev[t] == n: #从发电站连过来的
rec.append(t)
else: #不是从发电站连过来的
line.append((dist_prev[t], t))
#----把t加入后,产生了影响。经过t的,与MST的距离dist可能会变短
for y in range(n):
if MST[y] == False and edge[t][y] < dist[y]:
dist[y] = edge[t][y]
dist_prev[y] = t
res2 = len(rec) #电站数量
print(MST_cost) #MST的花费
print(res2) #与发电站直接相连的点
for i in rec:
print(i + 1, end = ' ') #与发电站直接相连的点们
print()
print(n - res2) #不用直接发电,拉电线的数量
for a, b in line:
print("{} {}".format(a + 1, b + 1)) #拉电线的点对们
19. árbol binario

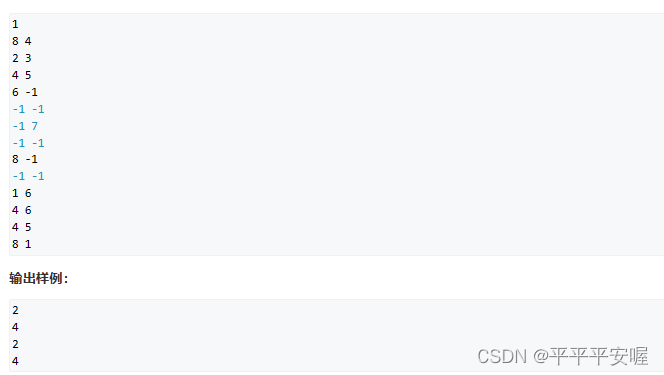
Usando ancestros comunes, esta es la primera vez que me encuentro con esto, es encontrar los ancestros comunes de dos nodos, entonces las rutas de estos dos nodos serán iguales a profundo (a) + profundo (b) - 2 * profundo ( ancestro), Esto debería ser fácil de entender.
Entonces, ¿cómo se encuentra el primer ancestro común? Mire sus profundidades. Quien sea más profundo subirá hasta que ambos tengan la misma profundidad. Luego subirán juntos hasta que ambos sean
el Lo mismo. Es fácil entender
cómo encontrar la profundidad de , y es fácil de encontrar, solo una recursividad y se acabó, búsqueda profunda.
El código específico es el siguiente.
T = int(input())
N = 1010
import sys
sys.setrecursionlimit(10000) # 增加递归深度,要不会出问题
def dfs(root,deep): # 作用是找到每个点的当前深度
if root == -1: return
deeps[root] = deep
dfs(l[root],deep + 1)
dfs(r[root],deep + 1)
def LCA(x,y): # 找到x,y最近的公共祖先
while deeps[x] > deeps[y]: # x深x就往上走
x = p[x]
while deeps[y] > deeps[x]:
y = p[y]
while x != y : # 这时候x,y应该在同一高度了,一起往上走
x = p[x]
y = p[y]
return x # 直到找到第一个相同的点
for _ in range(T):
l,r,p,deeps = [-1]*N,[-1]*N,[-1]*N,[0]*N
n,m = map(int,input().split())
for i in range(1,n+1):
left,right = map(int,input().split())
l[i] = left
if left != -1: p[left] = i
r[i] = right
if right != -1: p[right] = i
dfs(1,1) # 初始深度为1,反正是相对的,因为我们初始为0,这里就设置为1了
for i in range(m):
a,b = map(int,input().split())
print(deeps[a] + deeps[b] - 2*deeps[LCA(a,b)])
20. El bullpen perfecto

Este es un problema de emparejamiento muy clásico. A diferencia del problema de emparejamiento macho-hembra que conocía antes, este emparejamiento unilateral con solo vacas requiere que
definamos una función de búsqueda. Si buscar devuelve Verdadero, significa que puedes vivir en esta habitación. . Si es falso, dijo que no podía vivir en esta habitación.
Primero escriba todo el código y luego explíquelo uno por uno.
def find(u):
for i in range(max_numer[u]): # 遍历u牛喜欢的房间
v = love[u][i] # 牛住下这个单间
if not vis[v]: # 如果v在这次没有被遍历过
vis[v] = True
if choose[v] == 0 or find(choose[v]):
choose[v] = u
return True
return False
if __name__ == '__main__':
N,M = map(int,input().split()) # 牛的数量以及单间的数量
love = [[] for _ in range(N+1)] #
choose = [0] * (N+1) # 单间里住下了哪头牛
max_numer = [0] * (N+1)
for i in range(1,N+1):
l = [int(x) for x in input().split()]
max_numer[i] = l[0]
for j in range(l[0]):
love[i].append(l[j+1])
res = 0
for i in range(1,N+1):
vis = [False] * (N + 1) # 是否被访问过,每次都要重置一下,因为上次访问过的跟这次的没关系
if find(i) : res += 1
print(res)
love [u] [i] significa que la vaca u-ésima está dispuesta a vivir en la habitación i-ésima. El
núcleo es la función de búsqueda. Al juzgar si una vaca puede vivir en esta habitación, si la habitación que le gusta a la vaca ha sido atravesado, significa que esta vaca no puede vivir en esta habitación, porque si ha sido atravesado antes, significa que no es posible. Si está bien, devolverá True. Nota: nuestro hallazgo es para una vaca, Atravesaremos de 1 a N, cada vaca se encontrará una vez, si esta ubicación no se ha atravesado antes y nadie vive en este lugar (elija [v] == 0) o la vaca que vive aquí puede vivir en otras ubicaciones ( encontrar (elegir [v])) Entonces esta vaca puede vivir. Expliquemos
por qué buscar (elegir [v]) significa que la vaca que originalmente vivía aquí puede vivir en otros lugares.
Primero, elegir [v] representa que la vaca vivió originalmente en v. Denotemos a la vaca en la posición como j. Ahora la pregunta que tenemos que considerar es cuándo encontrar (j), ¿elegirá j vivir en la posición de v? La respuesta es no, porque podemos ver que en esta iteración de búsqueda, vis[v] se ha marcado como Verdadero, por lo que ya no elegirá el lugar v para vivir.
21. Problema de números primos

La idea es encontrar los números primos del 2 al n y registrarlos, luego cada vez que registres un número primo, tienes que ver si se puede expresar sumando los números primos anteriores y luego + 1.
El código específico es el siguiente.
import math
T = int(input())
for _ in range(T):
zhisu = []
res = 0
n,k = map(int,input().split())
for i in range(2,n+1): #判断i是否是质数
Flag = False
for j in range(2,int(math.sqrt(i)) + 1):
if i % j == 0:
Flag = True
break
else: zhisu.append(i)
if Flag: continue
if len(zhisu) >= 3:
for l in range(len(zhisu) - 2):
if zhisu[l] + zhisu[l+1] + 1 == zhisu[len(zhisu)-1]:
res += 1
break
if res >= k : print('YES')
else: print('NO')
22. Deshazte de las ratas

Solo cuenta cuántas pistas hay para ratones y ametralladoras, es muy simple, solo mira el código.
El código específico es el siguiente.
n,x0,y0 = map(int,input().split())
mice = []
for _ in range(n):
x,y = map(int,input().split())
mice.append((x,y))
## 统计有多少个斜率就行
res = set()
for x,y in mice:
if x - x0 != 0:
k = (y - y0)/(x - x0) # 斜率
else:
k = 9999
res.add(k)
print(len(res))
23.La siguiente dirección

El poder rápido más básico
de
El código específico es el siguiente.
m = 233333
x,n = map(int,input().split())
res = 1
while n:
if n & 1: # n的二进制第一位
res = res * x % m
x = x * x % m
n = n >> 1
print(res)
Si n es 1 en su bit, entonces res = res * x % m
y luego recuerda x*x%m, piensa en la lógica de que
el primer bit de n es 1, lo cual equivale al
segundo bit de res * x n Si es 1, entonces es equivalente a res * x * x. Si
el tercer bit de n es 1, es equivalente a res * x * x * x * x.
24. Coma frutas.

Divida a los niños en k+1 grupos. Los niños de cada grupo toman las mismas frutas, pero las frutas en los dos grupos adyacentes deben ser diferentes. Seleccione
k + 1 grupos, es decir, de n-1 brechas., seleccione k brechas como C(n-1,k)
y luego, excepto que el primer grupo tiene m métodos de selección, los grupos restantes (n-1) tienen solo (m-1) métodos de selección de grupos,
por lo que el final debe ser C( n-1.k) m (m-1)^(n-1)
Después de llegar a esta conclusión, vemos que el resultado es mod998244353, por lo que no podemos calcularlo simplemente y
necesitamos usar el elemento inverso (el método de Fermat). Pequeño teorema) y potencia rápida.
El código específico es el siguiente.
M = 998244353
def qmi(a,b): # a的b次方mod m
res = 1
while(b):
if (b & 1): res = res * a % M
b = b >> 1
a = a * a % M
return int(res % M)
def C(a,b):
res = 1
for i in range(b):
res = res * (a-i) % M
res = res * pow(i+1, M-2, M) % M # 使用费马小定理求逆元
return res
n,m,k = map(int,input().split())
print(int(C(n-1,k) * m * qmi(m-1,k) % M))
PD: El papel del elemento inverso:
en teoría de números, el recíproco de a no es 1/a (100/50)%20 = 2 ≠ (100%20) / (50%20) %20 = 0
25. Juego de guijarros
Referencia de: https://www.acwing.com/solution/content/72694/
El código específico es el siguiente.
T = int(input())
for _ in range(T):
n,k = map(int,input().split())
if k % 3 :
if (n%3): print("Alice") # 后手必胜
else:print('Bob')
else:
n %= k+1
if n == k : # n == k 先手必胜
print('Alice')
else: # 否则判断n % 3 是否等于0
if n % 3 == 0: # 后手必胜
print('Bob')
else:
print('Alice')
## 参考https://www.acwing.com/solution/content/72694/
26. División de enteros

El problema de la mochila equivale a tener un número infinito de artículos con volúmenes de 1, 2, 4 y 8.
dp[j] representa cuántos artículos se pueden guardar en una mochila con una capacidad de j.
Si el volumen actual del artículo es yo, entonces dp[j] = (dp[ j] + dp[ji])mod10^9
El código específico es el siguiente.
##相当于无限个体积为1,2,4,8的物品
MOD = 10**9
n = int(input())
dp = [0]*(n+1)
dp[0] = 1
i = 1
while i <= n: # 选体积为i这个物品
for j in range(i,n+1): # 背包大于i的都能选她
dp[j] = (dp[j] + dp[j - i]) % MOD
i <<= 1 # 扩大两倍
print(dp[n])
27.La suma más grande

Para esta pregunta que requiere la suma de dos subarreglos no repetidos, registramos f[i] como la suma del subarreglo continuo más grande de 1-i, g[i] como la suma del subarreglo continuo más grande en, representado por s y
a La suma de subarreglo continua más grande al final de [i]
Entonces f[i] = max(f[i-1],s)
es la misma para g[i]
. Luego itera a través de él y encuentra max. El específico el código es el siguiente
El código específico es el siguiente.
T = int(input())
N = 50050
inf = -0x3f3f3f3f3f
for _ in range(T):
n = int(input())
a = [0] + [int(x) for x in input().split()]
## f[i] 表示 1 - i 最大连续子数组的和
## g[i] 表示 i 到 n 最大连续子数组的和
f, g = [inf] * (N), [inf] * (N)
s = 0 # s表示以a[i]结尾的最大连续子数组
for i in range(1,n+1):
s = max(0,s) + a[i]
f[i] = max(f[i - 1],s) # f[i-1]就表示不以a[i]为结尾了
s = 0
for i in range(n,0,-1):
s = max(0,s) + a[i]
g[i] = max(g[i + 1] , s)
res = inf
for i in range(1,n+1):
res = max(res, f[i] + g[i+1])
print(res)
28. colorear


El código específico es el siguiente.
Primero convierte todos los bloques conectados en un color
n = int(input())
col = []
c = [int(x) for x in input().split()]
for i in range(len(c)):
if i == 0:
col.append(c[i])
else:
if c[i] == c[i-1]: continue
else:
col.append(c[i])
n = len(col)
col = [0] + col
dp = [[0]*(n+1) for _ in range(n+1)]
for lenn in range(2,n+1):
for l in range(1,n + 2 - lenn):
r = l + lenn - 1
if col[l] == col[r]:
dp[l][r] = dp[l+1][r-1] + 1
else:
dp[l][r] = min(dp[l+1][r] , dp[l][r - 1]) + 1
print(dp[1][n])
## 参考自https://www.acwing.com/solution/content/69707/
Específicamente por qué este método puede hacer que el bloque conectado involucrado incluya el bloque conectado seleccionado al comienzo de la operación. No tengo idea. ¿Tal vez desciende capa por capa? Al final, definitivamente estará diseñado hasta el fondo dp.
29. Color de las hojas.
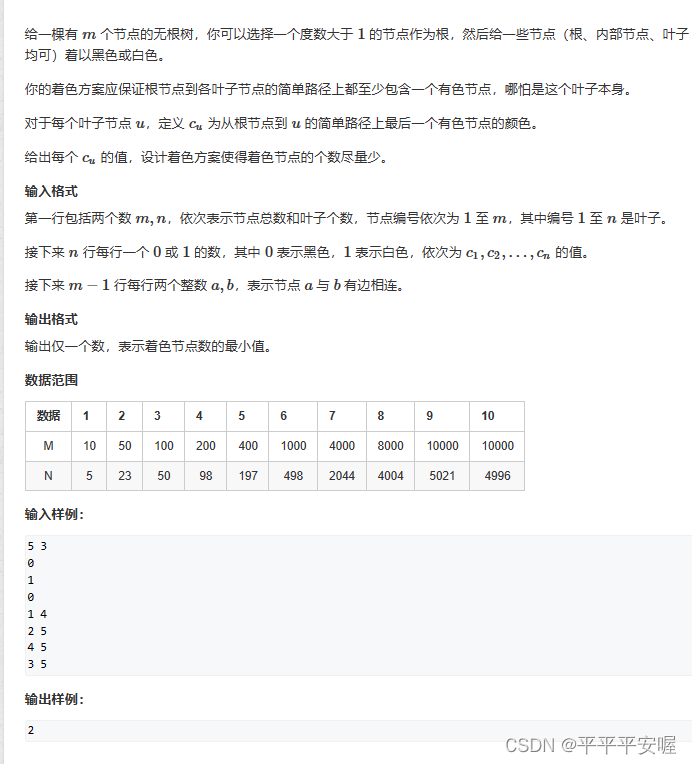
No podía entender la pregunta, así que decidí hacer una fiesta de baile sin jefe, usando también árbol DP.
29. Baila sin jefe

Mirando hacia abajo desde BOSS, f[u][i] representa el índice de felicidad del nodo u.
Supongamos que j es el hijo de u,
f[u][1]. Primero, será = happy[u]
f[u][ 1] + = f[j][0]
f[u][0] += máx(f[j][0],f[j][1])
El código específico es el siguiente.
## 题目都看不懂,于是决定做一下 没有上司的舞会, 就代表刷这模块了
def dfs(u): # 深度优先往下搜
f[u][1] = happy[u] # 有这个节点
i = h[u]
while i != -1: # 找他的儿子
j = e[i]
dfs(j)
f[u][1] += f[j][0] # 有父节点
f[u][0] += max(f[j][0],f[j][1]) # 没有父节点
i = ne[i]
def add(a,b): # b当a的儿子
global idx
e[idx] = b
ne[idx] = h[a]
h[a] = idx
idx += 1
if __name__ == '__main__':
N = 6010
h,e,ne,idx = [-1]*N ,[0]*N, [-1]*N,0
happy,f,has_fa = [0]*N,[[0]*2 for _ in range(N)], [False] * N
n = int(input())
for i in range(1,n+1):
happy[i] = int(input())
for i in range(n-1):
a,b = map(int,input().split())
add(b,a)
has_fa[a] = True
root = 1
while has_fa[root] : root +=1 # 找到boss,就是没有父节点的
dfs(root)
print(max(f[root][0],f[root][1]))
30. Suma máxima de subsecuencia creciente

Un BP violento como el mío debería poder pasar TLE, pero yo no puedo pasarlos todos, pero ese es el nivel actual. .
Sea f[i] la subsecuencia ascendente máxima que termina en a[i] y
atraviese j de 1 a i
si a[j] < a[i]
f[i] = max(f[i], f[j] + a[i])
Finalmente, solo encuentra max(f)
El código específico es el siguiente.
## 优先考虑暴力 BP 肯定会TLE,但是先这样把,到时候复盘的时候如果想做再用树形DP
# f[i] 表示 以a[i] 结尾的 最大上升子序列和
# f[i] = f[j] + a[i] 1 <=j < i a[j] < a[i]
N = 100010
n = int(input())
a = [0] + [int(x) for x in input().split()]
f = [0] * N
for i in range(1,n + 1):
f[i] = a[i] #先加上自己
for j in range(1,i):
if a[i] > a[j]:
f[i] = max(f[i] , f[j] + a[i])
print(max(f))
PD: Las preguntas 31 y 32 son todas preguntas avanzadas, no es algo que pueda hacer.
Eso es todo.