Liu Liangqi Arquitecto Alianza Tecnológica 2021-04-12 07:50
Extracto de:
https://mp.weixin.qq.com/s/o9HH-8TF0DbMqHrvsFh1NA
Con el rápido crecimiento de IOT, big data, Internet móvil y otras aplicaciones, se generan cada vez más datos y el mercado total de almacenamiento también aumenta año tras año. Se espera que el almacenamiento distribuido represente el 50% de todo el almacenamiento. mercado para 2021, y para 2027, el almacenamiento distribuido representará el 70% de todo el mercado. Ceph es un representante típico del software de almacenamiento distribuido.
Como proveedor de almacenamiento definido por software, Shanyan Data es inseparable de la combinación de desarrollo de software y hardware. La construcción de un ecosistema ARM con Huawei es el foco clave del desarrollo de Shanyan. En la actualidad, el MOS de almacenamiento de objetos y el USP de almacenamiento en bloque de Shanyan Data han completado el trabajo de adaptación en la plataforma Kunpeng y están listos para su uso comercial.
El siguiente es el intercambio de experiencias sobre el desarrollo y la aplicación de Ceph por parte de Liu Liangqi, ingeniero senior de investigación y desarrollo de Shanyan Data Cloud Storage, en la Conferencia de desarrolladores de Huawei.
1. ¿Qué es Ceph?

A nivel de usuario, Ceph proporciona tres servicios externos:
1. Almacenamiento en bloque (interfaz de almacenamiento en bloque RDB): como un disco U sin formato, cuando se conecta a una PC personal por primera vez, el sistema operativo Windows mostrará una interfaz de solicitud formateada para que el usuario seleccione parámetros, como los más importantes. Las opciones del sistema de archivos, como NTFS, exFAT y otros sistemas de archivos están disponibles para su selección. Después del formateo, el disco U se puede usar para crear directorios y copiar archivos. Antes de ingresar al edificio para trabajar y vivir, es necesario decorar el edificio. es decir, formateado. Es imposible que un edificio tenga una sola persona, por lo que es necesario gestionar la propiedad, que se puede comparar con un sistema de archivos.
2. Almacenamiento de objetos (almacenamiento de objetos RADOS GW): el almacenamiento de objetos también se usa ampliamente en la vida de todos, como el disco en la nube que usamos habitualmente o los teléfonos inteligentes que usamos tienen funciones de copia de seguridad en la nube, todo basado en el almacenamiento de objetos como desempeño comercial. Por lo tanto, el almacenamiento de objetos tiene como objetivo resolver el problema de almacenamiento de archivos irregulares masivos en la era de la información. Así como no existen dos hojas idénticas en el mundo, cada persona generará información diferente, cómo solucionar el almacenamiento de estos datos únicos, el almacenamiento de objetos proporciona una solución.
3. Sistema de archivos Flie System: El servicio de sistema de archivos proporcionado por Ceph se compara con el proceso de compra de una computadora personal. Los usuarios de bricolaje pueden comprar varios hardware y piezas para ensamblar e instalar un sistema operativo antes de usarlo. La máquina completa con sistema Windows preinstalado está disponible para que los usuarios elijan. Después de la compra, el usuario puede usarlo directamente después de encender la fuente de alimentación. El servicio de sistema de archivos proporcionado por Ceph es similar a una máquina tan completa: los usuarios solo necesitan montar el directorio correspondiente localmente para funcionar.
RGW: interfaz de almacenamiento de objetos, el uso de este servicio de interfaz requiere algún software de cliente; por supuesto, la función de copia de seguridad en la nube en el teléfono móvil es compatible con la aplicación integrada en el sistema operativo móvil, por lo que no es necesario instalar software adicional.
RBD: interfaz de almacenamiento en bloque. Si está utilizando un sistema Linux, puede usar el módulo del kernel krbd para generar directamente un dispositivo de bloque localmente para que lo usen los usuarios. Para el sistema Windows, se puede virtualizar un disco duro para que los usuarios lo utilicen a través del protocolo iSCSI.
RADOS: Más abajo está la capa de abstracción unificada RADOS de todo el clúster Ceph, es decir, un clúster de almacenamiento de objetos abstractos. Significa que todos los datos de la interfaz anterior se almacenarán en el clúster en forma de objetos después del procesamiento. Al mismo tiempo, RADOS también garantiza la coherencia de estos datos de interfaz en todo el clúster, mientras que LIBRADOS accede principalmente a la biblioteca de interfaz de la capa RADOS.
A continuación se muestran algunos componentes importantes del clúster Ceph, como mgr, mirror, etc. Estos grupos se distribuyen en cada servidor del clúster y no se muestran en la figura anterior. Las funciones de cada componente se describen brevemente a continuación:
-
MON: el monitor, que puede considerarse como el cerebro del cluster, es responsable del mantenimiento del estado del cluster y de la gestión de los metadatos.
-
MDS: Servicio de metadatos, que proporciona recuperación de jerarquía de archivos y gestión de metadatos para los servicios de interfaz de Ceph FS. Si no necesita los servicios de Ceph FS, puede optar por no implementar este componente.
-
OSD: Dispositivo de almacenamiento de objetos. Este es el dispositivo terminal que transporta principalmente datos del usuario en todo el clúster. Básicamente, todas las solicitudes de lectura y escritura de datos de los usuarios son finalmente ejecutadas por OSD. Por lo tanto, el rendimiento del OSD determina el rendimiento de todo el negocio de la capa superior. OSD generalmente vincula un gran espacio de almacenamiento, como un disco duro o una partición del disco duro, y la interfaz de almacenamiento local del espacio de almacenamiento de administración de OSD incluye principalmente File Store y Blue Store. Por supuesto, File Store también necesita utilizar un sistema de archivos local (como XFS) para administrar el espacio de almacenamiento. Blue Store puede hacerse cargo directamente del dispositivo sin formato, de modo que su ruta de E/S se pueda reducir para mejorar el rendimiento.
En general, Ceph es un sistema de almacenamiento distribuido unificado. Sus objetivos de diseño son buen rendimiento, confiabilidad y escalabilidad. Esto se debe a que, desde la perspectiva de la arquitectura de Ceph, no existe una capa de caché dedicada, por lo que el rendimiento no es muy ideal. La comunidad también ha estado promoviendo la función de caché jerárquico (nivel) para este problema, pero esta función aún no ha llegado a la etapa de producción; por lo que la práctica común actual es almacenar en caché los datos de Ceph en el nivel del sistema operativo; por ejemplo, el común La capa de bloque del kernel utiliza dm -cache, bcache, EnhanceIO y otros datos de caché de software de código abierto en un dispositivo de mayor velocidad (como SSD) a nivel del sistema operativo para mejorar el rendimiento de Ceph.
2. ¿Cuáles son los problemas con la arquitectura y el negocio existentes de Ceph?
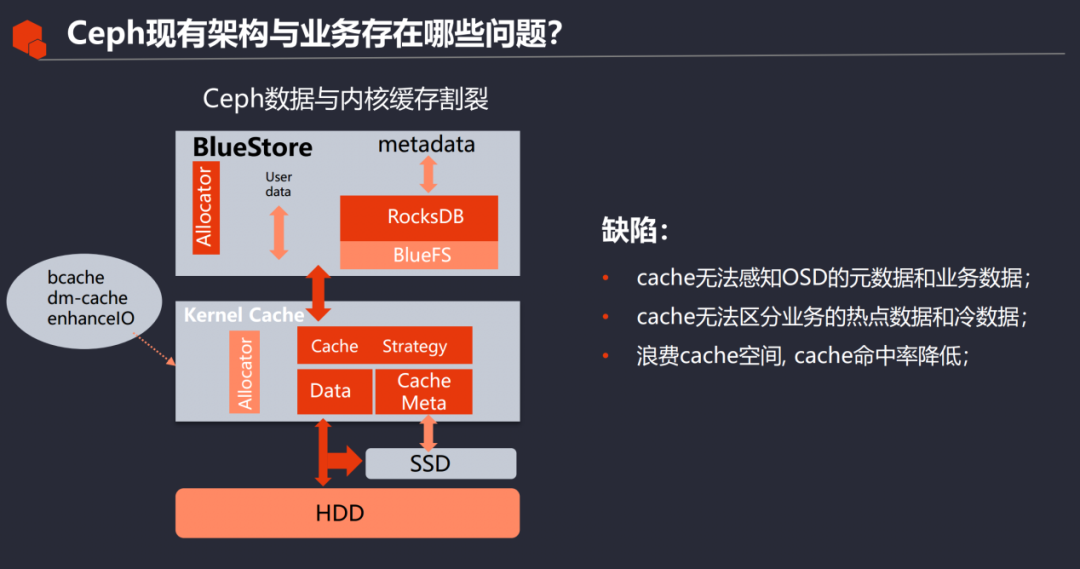
1. El problema de dividir los datos de Ceph y la caché del kernel . Tomando BlueStore como ejemplo, guarda los metadatos de OSD en RockDB y RockDB se ejecuta en un sistema de archivos simplificado (Blue FS). En este momento, se puede considerar que el IO de Blue FS son los metadatos de OSD, pero para En lo que respecta al caché del kernel, no puede percibir que los datos entregados por el OSD se dividen en metadatos y datos comerciales.
2. El caché del kernel no puede distinguir los datos activos y fríos del negocio OSD. Por ejemplo, el usuario configura una estrategia típica de almacenamiento de tres copias. En este momento, solo los datos de la copia maestra proporcionarán servicios de lectura y escritura para el cliente. , Mientras que la copia esclava directamente no usa el caché, sí, pero el caché de la capa del núcleo no puede distinguir esta diferencia. Si se utiliza DM Cache, se asignará un espacio en la memoria para almacenar en caché algunos datos, lo que sin duda desperdiciará recursos de memoria.
En términos generales, existen defectos como el desperdicio de espacio de caché en el caché del kernel, una baja tasa de aciertos de caché y la reducción de la vida útil del dispositivo de caché debido a las frecuentes actualizaciones de caché.
3. ¿Cuál es la solución?
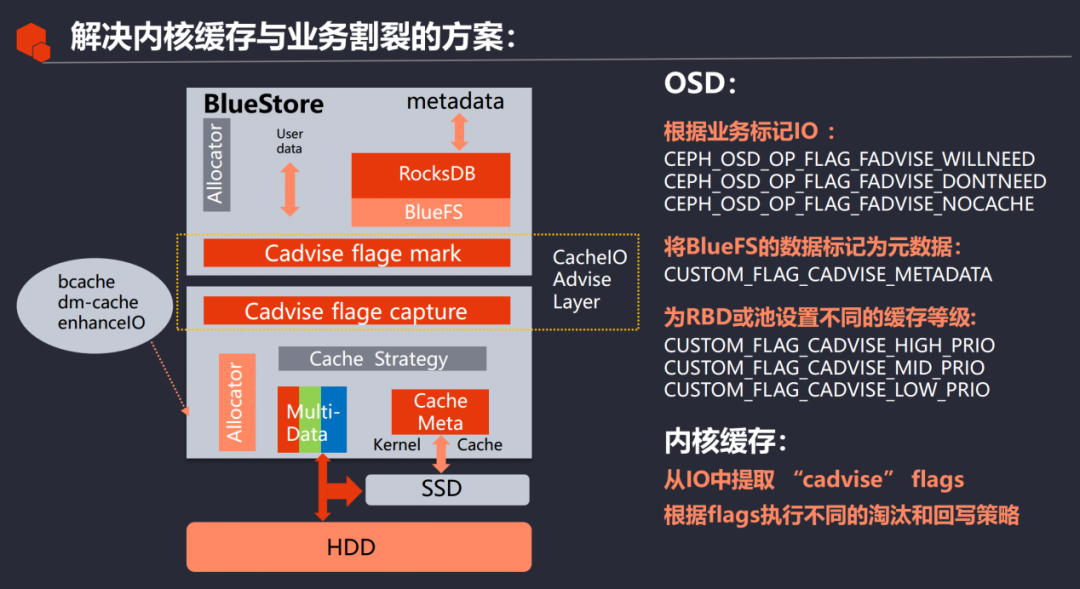
Agregue una capa de adaptación en el lugar donde BlueStore entrega IO para marcar el tipo de IO entregada y agregue una capa de adaptación en la entrada del caché del kernel para capturar el tipo de IO de OSD. Finalmente, al procesar el caché del kernel, de acuerdo con Los tipos IO tienen diferentes estrategias de reescritura y eliminación.
Por ejemplo, dos de las tres copias se llevan a la caché del kernel con la etiqueta NOCACHE a través de la capa de adaptación junto con la solicitud IO, de modo que la caché del kernel se puede escribir directamente en el disco de respaldo sin almacenamiento en caché. Al mismo tiempo, puede marcar el IO de Blue FS como tipo de metadatos, para que pueda permanecer en la memoria caché del kernel durante más tiempo. O, de acuerdo con las necesidades comerciales del usuario, marque los datos más importantes que el usuario tiene y lee y escribe con frecuencia como de alto nivel, y marque otros datos sin importancia como de nivel medio o bajo, y luego use el mismo método que los metadatos para alto nivel. nivel de datos en la caché del kernel La estrategia de procesamiento; de esta manera, se pueden implementar diferentes estrategias de eliminación y reescritura según las necesidades del usuario.
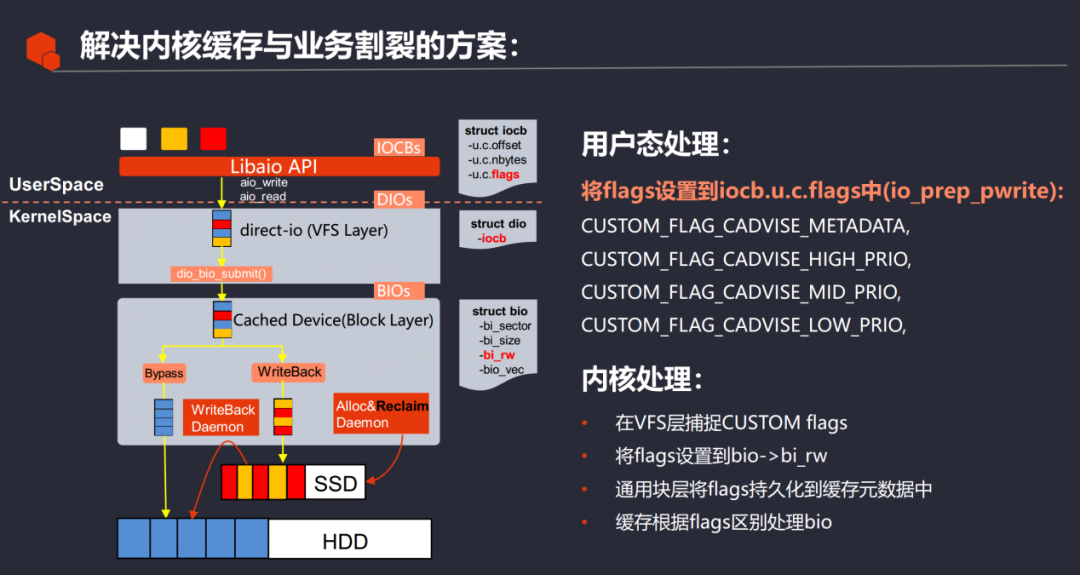
BlueStore utiliza la interfaz API de Libaio para emitir solicitudes de IO. En este momento, se necesita una estructura IOCB como parámetro IO de la solicitud emitida. Después de generar la estructura iocb a través de la función io_prep_pwrite, establezca el indicador io en la estructura de bandera de IOCB. .Como parámetro de io_submit, se envía juntos a la capa del núcleo; cuando el núcleo captura Direct io en la capa VFS, convierte el indicador en la estructura BIO de la capa general del dispositivo de bloque, como la estructura bi_rw de BIO. que se encuentra en la capa de bloque general en este momento. El caché del kernel puede capturar las etiquetas comerciales de la capa superior. El caché del kernel puede implementar diferentes estrategias de reescritura y asignación según diferentes etiquetas, como permitir que los metadatos residan en el caché por más tiempo o permitir que los datos y metadatos del usuario de alto nivel implementen la misma estrategia de almacenamiento en caché.
4. Problemas y desafíos que enfrenta Ceph en la arquitectura ARM
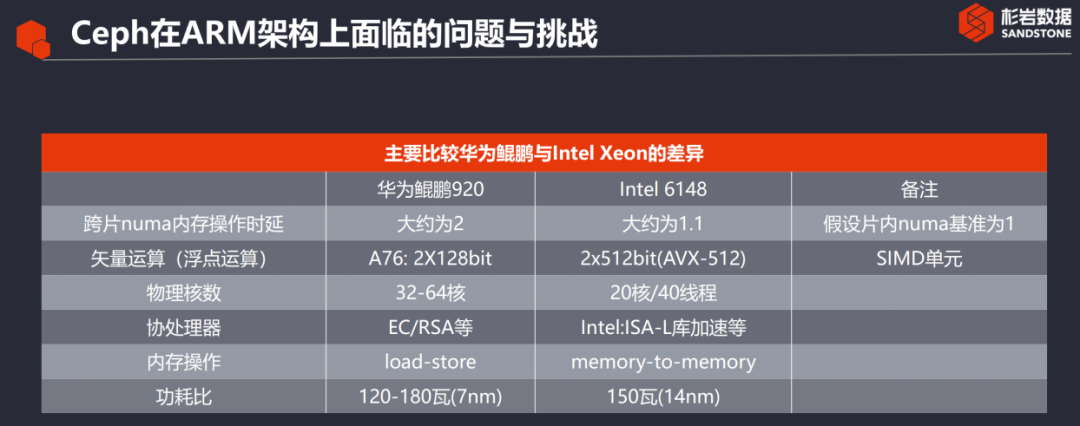
Existen seis diferencias principales entre los procesadores Huawei Kunpeng y los procesadores Intel Xeon:
1. Acceso entre chips de ARM: se refleja principalmente en la memoria (los datos son valores estimados, no datos medidos, sin evaluación). En comparación con X86, ARM no tiene ninguna ventaja, por lo que en los siguientes métodos de optimización, existen operaciones para evitar el numa entre chips.
2. Cálculo vectorial: No he obtenido los parámetros específicos de Kunpeng al respecto, tomando como referencia el A76 de ARM, desde el punto de vista actual, ARM no es dominante.
3. La cantidad de núcleos físicos: ARM tiene ventajas inherentes en la cantidad de núcleos físicos.
4. Coprocesadores: Aceleradores. En términos de aceleradores, Kunpeng 920 tiene coprocesadores periféricos como EC/RSA/zlib, que son más abundantes que el X86 6148 de uso general. Esta es la ventaja de Kunpeng 920.
5. Operación de memoria: ARM adopta la microarquitectura de almacenamiento de carga, que se entiende simplemente como: ARM necesita CPU para participar en la copia entre memoria y memoria, mientras que X86 puede directamente no necesitar CPU para participar en la memoria. -copia de transferencia de memoria. Esto está determinado por la microarquitectura ARM.
6. Relación de consumo de energía: el consumo de energía general por sí solo no es muy preciso. Después de todo, el consumo de energía también está relacionado con la cantidad de núcleos físicos habilitados. Por supuesto, la tecnología avanzada puede reducir el consumo de energía. En términos de la relación de consumo de energía de un solo núcleo físico, ARM tiene una ventaja sobre X86.
5. Ajuste de Ceph basado en la plataforma Kunpeng
Para Ceph en la plataforma Kunpeng, actualmente existen las siguientes soluciones de optimización principales:
1. Para el escenario de operación NUMA entre chips, el proceso se limita a ejecutarse en el chip NUMA.
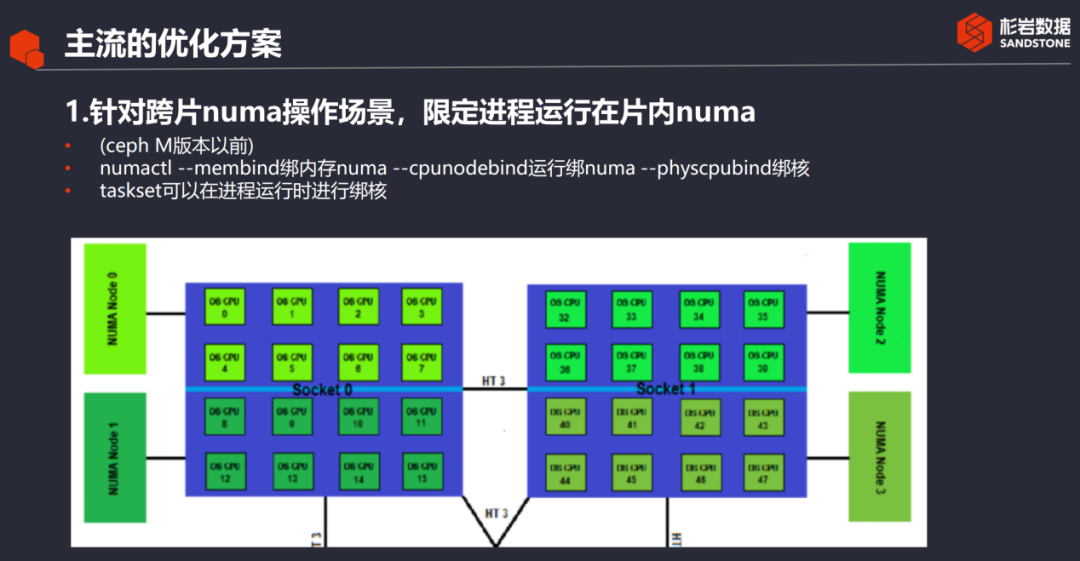
Para el escenario de operación NUMA entre sectores, el proceso se limita a los NUMA en el sector. Tomando a Ceph como ejemplo, Ceph M y versiones posteriores proporcionan un parámetro OSD_numa_node, que puede limitar el numa que ejecuta todo el proceso OSD. Si está utilizando otras versiones de ceph, puede utilizar las dos herramientas numactl y taskset para realizar la función de limitar la ejecución del proceso en el numa especificado.
numactl debe configurarse cuando se inicia el proceso. Los parámetros principales son NUMA (--membind), NUMA (--cpunodebind) que vincula el proceso para ejecutarse y, más detalladamente, el núcleo físico que vincula el proceso para ejecutarse (-- fiscpubind). Los conjuntos de tareas son más flexibles y se pueden configurar mientras se ejecuta el proceso. Antes de que se limite NUMA, el hardware correspondiente debe asignarse debajo del bus en el chip tanto como sea posible, como tarjetas de red, memoria, SSD, etc., debe asignarse debajo del bus en el chip correspondiente tanto como sea posible para evitar acceso entre chips.
2. El tablero corto de operación vectorial se llena con la ayuda del coprocesador.

En términos de computación vectorial, puede utilizar el acelerador de la plataforma Kunpeng 920. Huawei proporciona algunos documentos de interfaz de infraestructura y puede realizar las adaptaciones correspondientes en función de estos documentos; las configuraciones y configuraciones de parámetros deben adaptarse a nivel de código. Esta vez, es necesario trabajar mucho y realizar pruebas de estabilidad.
3. Aumentar el número de subprocesos/subprocesos y operaciones de memoria.
Aprovechando las ventajas de Kunpeng en los núcleos físicos, es posible agregar procesos o subprocesos para el procesamiento comercial correspondiente. Para subprocesos comerciales ocupados, los subprocesos se pueden dividir en dos y asignar a diferentes núcleos físicos.
En términos de operaciones de memoria, además de reducir las operaciones de memoria, Huawei ha lanzado un parche para la microarquitectura ARM. Este parche optimiza principalmente la interfaz de la memoria. Puede descargar el parche desde el sitio web de infraestructura de Huawei para mejorar el rendimiento. Además, existen otros métodos de optimización:
-
Interrupción de la vinculación de la tarjeta de red/SSD: el servicio irqbalace debe cerrarse primero; de lo contrario, el servicio irqbalace reequilibrará la vinculación.
-
Negocio de aislamiento de Cgroup: es más efectivo para subprocesos o procesos ocupados, principalmente según consideraciones de caché de la CPU. Si la CPU se cambia a procesos y subprocesos no relacionados, hará que la caché de la CPU se actualice, lo que provocará que la tasa de aciertos disminuya. La lectura anticipada de la caché también desperdicia ancho de banda de la memoria. Al mismo tiempo, una vez que se apaga la CPU del proceso, toda la canalización se vaciará/vaciará y la cantidad de instrucciones concurrentes también disminuirá en este momento, por lo que aún tiene un impacto en el rendimiento. La razón principal es que la mejora del rendimiento es relativamente grande cuando el negocio está relativamente ocupado.
-
Biblioteca de terceros: principalmente para optimizar la asignación de memoria y la eficiencia de recuperación, Tcmalloc y jemalloc son opcionales. Puede ir al sitio web de Tcmalloc y jemalloc para descargar archivos relacionados para leer.
A continuación, presentaré tres herramientas de observación del rendimiento de Ceph, como se muestra en la siguiente figura:
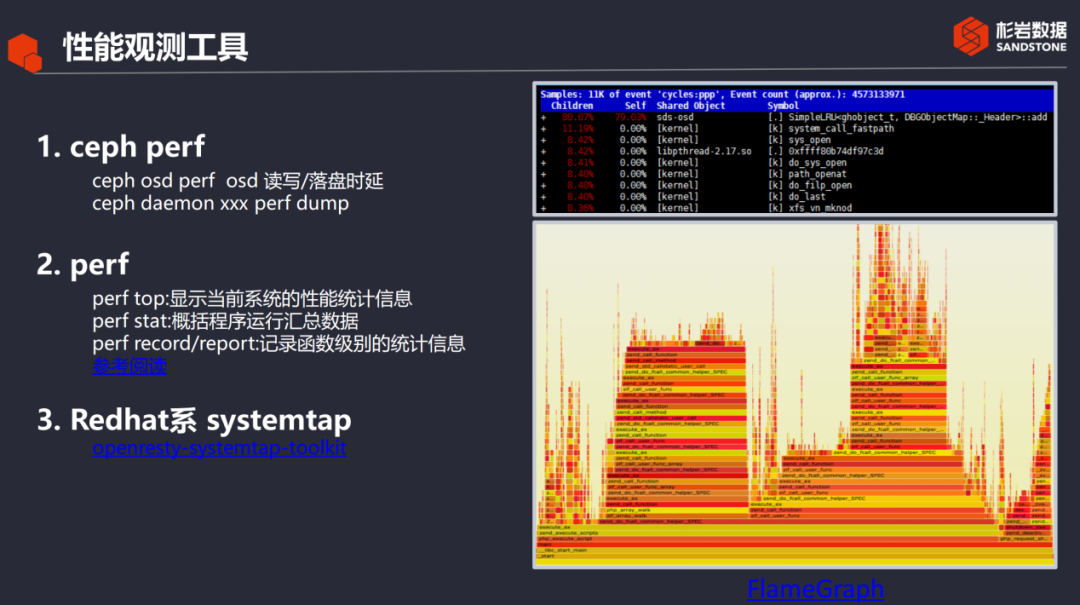
Demonio de rendimiento / rendimiento OSD de Ceph: esta es una herramienta que viene con Ceph. Entre ellos, el rendimiento OSD registra principalmente el retraso de la lectura y escritura de IO y puede juzgar inicialmente si el cuello de botella está en nuestro disco duro. Si es así, los métodos de optimización correspondientes se puede adoptar.
El demonio de rendimiento registra principalmente el flujo de procesamiento de toda la solicitud de IO en Ceph. El tiempo dedicado a estos flujos de procesamiento se exportará a través de este comando, que se puede utilizar para el diagnóstico preliminar.
Sistema operativo——Herramienta de rendimiento: la parte superior de rendimiento más utilizada muestra el estado de ejecución actual de todo el sistema. Como se muestra en la esquina superior derecha de la figura anterior, el proceso OSD obviamente consume una gran cantidad de CPU. Puede realizar un pelado jerárquico para encontrar la ubicación de las funciones activas y luego Optimización dirigida de las funciones activas. La estadística de rendimiento recopila principalmente la situación general del proceso durante un período de tiempo. También puede utilizar perf record para registrar datos y luego combinar FlamGraph para generar un gráfico de llamas, que es relativamente intuitivo. Concéntrese principalmente en algunas llamadas a funciones planas (figuras), porque la proporción de tiempo de CPU consumido aquí es relativamente grande, que es el objetivo de la optimización.
Systemtap: se utiliza principalmente en el sistema Redhat. Al recopilar la información operativa de las funciones del kernel, las llamadas al sistema, las funciones del usuario y los datos de entrada y salida de funciones, etc., el análisis a nivel de función se realiza en función de estos datos recopilados. Por ejemplo, basándose en la herramienta openresty-systemtap-toolkit, realice un desarrollo secundario. A través de la herramienta, puede analizar todo el sistema o dónde el programa tiene cuellos de botella y luego optimizar el rendimiento para los cuellos de botella.
6. ¿Cuál es el rendimiento del sistema de almacenamiento Ceph optimizado?
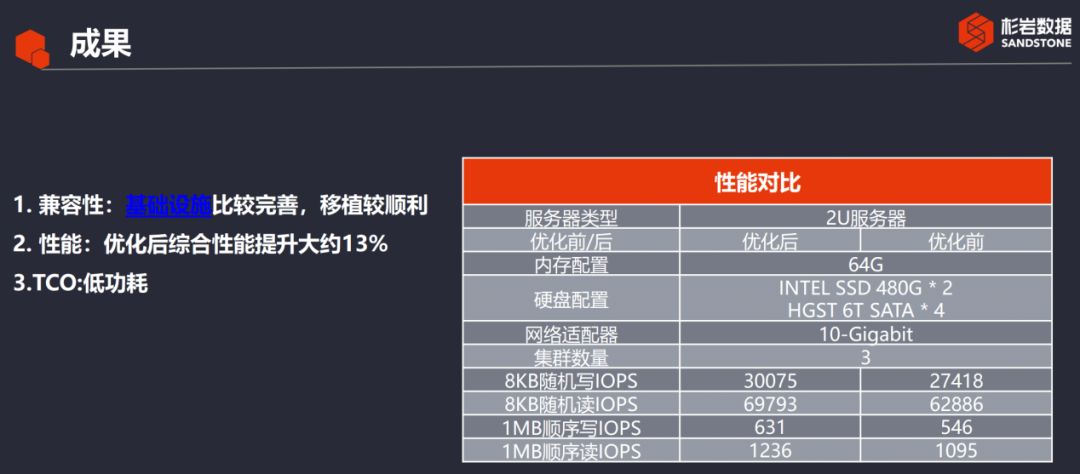
Compatibilidad: desde el principio hasta el final de todo el proceso, no hay un punto de bloqueo relativamente grande. La solución a la biblioteca dependiente y algunos problemas técnicos se pueden encontrar en el sitio web de infraestructura de Huawei. Todo el proceso de trasplantar Ceph a la plataforma Kunpeng es relativamente suave.
Rendimiento optimizado: según la comparación antes y después de la optimización según la configuración del servidor existente, la prueba aquí no es el límite de la CPU Kunpeng y el principal cuello de botella es el disco duro. Muestra principalmente los resultados después de la optimización mediante los métodos y medios de optimización introducidos anteriormente. Como se muestra en la tabla, se puede ver que se mejora el rendimiento optimizado.
Bajo consumo de energía: Se refleja principalmente en el hecho de que el consumo de energía de un solo núcleo físico de ARM es efectivamente menor que el de X86, por lo que tiene una ventaja en los costos operativos posteriores.
La siguiente es una introducción al estado de nuestros productos de almacenamiento en bloque que se ejecutan en la plataforma Kunpeng. La interfaz principal muestra el estado de todo el clúster de productos de almacenamiento en bloque. En la sección de información del nodo, se implementan componentes como el monitor y el OSD. La información del servidor aquí puede verse como el servidor TaiShan de Huawei, el servidor TaiShan 200 (modelo 2280) utiliza el procesador Kunpeng 920.
Para otras funciones de administración, como la administración de volúmenes, el sistema Linux se puede montar localmente a través del módulo krbd del kernel y también se puede montar en el sistema Windows a través del protocolo iSCSI para que lo utilicen los usuarios (Figura). Cuando existan otras funciones, esta no se ampliará.
6. Perspectivas y planes futuros
El primero es un plan a largo plazo basado en el servidor TaiShan, como lanzar un producto basado en un escenario de almacenamiento totalmente flash. En este escenario, todos los discos duros tienen un rendimiento relativamente alto y la red Ethernet tradicional será un cuello de botella. Ahora el servidor TaiShan solo admite la función RDMA, lo que allana el camino para la implementación de escenarios de almacenamiento totalmente flash, sin adaptación ni ajuste adicional de los puertos de red.
seastar Para la arquitectura ARM, el rendimiento está en desventaja cuando se accede entre chips en competencias de múltiples núcleos. En este momento, el marco seastar de programación sin compartir se utiliza para evitar las desventajas del acceso entre chips ARM; La comunidad de Seastar Architecture también está invirtiendo activamente en él y continuará con el seguimiento.
Finalmente, los productos de almacenamiento seguro son más importantes para el cifrado, descifrado y descompresión de datos, y los aceleradores periféricos de Kunpeng zlib/rsa/md5/sm3 pueden proporcionar procedimientos eficientes de procesamiento de seguridad de datos.
¿Es necesario recompilar el sistema operativo después de la transformación de la memoria caché del kernel fuertemente acoplada? No, la E / S se procesa mediante piratería del kernel en la capa VFS y no es necesario cambiar la lógica original del kernel, simplemente cargue el KO modificado en el sistema operativo para procesar nuestra IO personalizada.
¿Por qué no considerar crear el caché dentro de la Tienda azul? Blue Store fue diseñado por la comunidad para escenarios futuros totalmente flash y no consideró escenarios híbridos; y los escenarios híbridos son solo una etapa de transición, no a largo plazo, por lo que la comunidad no consideró agregar caché al diseñar; si el caché es Implementado en Blue Store, es contrario al concepto de diseño de la comunidad y, al mismo tiempo, hace que el procesamiento de toda la Blue Store sea extremadamente complicado, ya sea para hacer un seguimiento de la comunidad o impulsar cambios en la comunidad en el futuro. , será problemático.