Directorio de artículos
prefacio
Bean es un concepto central en el marco Spring, que se refiere a una instancia de objeto administrada por el contenedor Spring . Al desarrollar con Spring, generalmente definimos varios Beans para llevar diferentes funciones y componentes de la aplicación . Sin embargo, es posible que muchos desarrolladores solo presten atención a la definición y el uso de Bean, pero ignoren el alcance y el ciclo de vida de Bean, los cuales son cruciales para el rendimiento, la estabilidad y la capacidad de mantenimiento de una aplicación.
En este artículo, analizo en profundidad el alcance y el ciclo de vida de los beans y explico su impacto en las aplicaciones Spring. Intentaré explicar estos conceptos en un lenguaje sencillo y claro para que los lectores puedan comprenderlos y aplicarlos fácilmente a sus propias prácticas de desarrollo.
1. El alcance del frijol
Ver el término alcance de Bean por primera vez puede confundirnos, pero no importa, el siguiente caso simple nos dirá qué es el alcance de Bean.
1.1 Caso Bean modificado
Ahora hay un objeto Bean público que pueden usar los usuarios A y B, pero cuando A usa este objeto Bean, modifica silenciosamente los datos de este Bean, entonces, ¿hará que los usuarios B usen este objeto Bean cuando ocurran resultados inesperados?
Cree una UserBeanclase cuya función sea almacenar objetos en el contenedor Spring a través @Beande anotaciones , que contenga atributos y :UserUseridname
@Component
public class UserBeans {
@Bean
public User getUser(){
User user = new User();
user.setId(123);
user.setName("张三");
return user;
}
}
Luego cree una UserController1clase, @Controllerguárdela en el contenedor Spring mediante anotaciones y úsela para 属性注解obtener el objeto Bean en el contenedor Spring. Además, cree un printUsermétodo que cree una referencia temporal myUserque apunte al objeto Bean y luego modifique los datos del Bean:
@Controller
public class UserController1 {
@Autowired
private User user;
public void printUser(){
System.out.println("user: " + user);
User myUser = user;
myUser.setName("李四");
System.out.println("myUser: " + myUser);
System.out.println("user: " + user);
}
}
Cree otro UserController2, también use @Controlleranotaciones para almacenarlo en el contenedor Spring y luego úselo para 属性注解obtener el objeto Bean en el contenedor Spring. Además, cree un printUsermétodo que solo imprima el objeto Bean obtenido:
@Controller
public class UserController2 {
@Resource
private User user;
public void printUser(){
System.out.println("UserController2: user -> " + user);
}
}
Los métodos en la clase de inicio obtienen y mainrespectivamente , y luego ejecutan los métodos respectivamente para observar el impacto de modificar el objeto Bean.ApplicationContextUserController1UserController2
public static void main(String[] args) {
ApplicationContext context
= new ClassPathXmlApplicationContext("spring-config.xml");
UserController1 userController1
= context.getBean("userController1", UserController1.class);
UserController2 userController2
= context.getBean("userController2", UserController2.class);
userController1.printUser();
System.out.println("=========");
userController2.printUser();
}
El resultado de la ejecución es el siguiente:
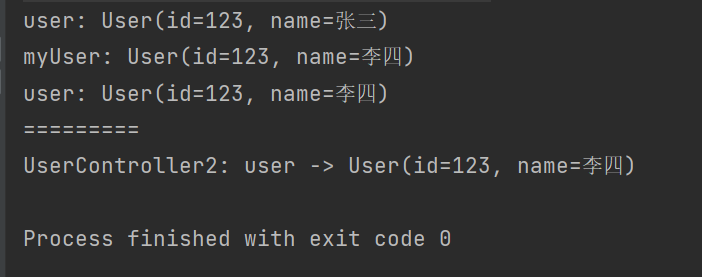
A partir de los resultados de la operación, cuando UserController1se modifican los datos del bean, UserController2los datos del bean obtenido también se modifican en este momento, entonces significa que solo hay una copia de un bean. almacenado en Spring, y es un modo singleton. Por lo tanto, el alcance predeterminado del Bean en el contenedor Spring es el modo singleton (singleton) .
1.2 Definición de alcance
El alcance (Scope) se utiliza en programación para describir el alcance de las variables o identificadores accesibles en el programa. En otras palabras, especifica en qué partes se puede hacer referencia y utilizar las variables . El alcance es un concepto importante porque ayuda a los programadores a evitar conflictos de nombres y comprender el ciclo de vida de las variables en el código .
En el marco Spring, el alcance se utiliza para definir el ciclo de vida y las reglas de visibilidad de los objetos Bean . 作用域决定了在不同的上下文环境中,Spring 容器如何管理和提供 Bean 对象. Por ejemplo, al definir un Bean, podemos especificar su alcance para determinar su comportamiento en la aplicación.
1.3 Seis ámbitos del frijol
Cuando el contenedor Spring inicializa una instancia de Bean, también especificará el alcance de la instancia. Si no modificamos el alcance que se especificará, Spring especificará un alcance predeterminado de forma predeterminada. Los siguientes son seis ámbitos en Spring, los últimos cuatro de los cuales son efectivos según Spring MVC, por lo que este artículo no los discutirá primero.
-
Alcance singleton (singleton) : este es
默认el alcance del contenedor Spring. Durante la vida útil de la aplicación, solo se creará una instancia del bean de este tipo y todas las referencias al bean ejecutarán el mismo objeto . A qué objetos Bean sin estado y seguros para subprocesos se aplica este alcance, como clases de utilidad, clases de configuración, etc. -
Alcance del prototipo (prototipo) : cada vez que se solicita un objeto Bean, el contenedor Spring creará una nueva instancia de Bean , por lo que en diferentes solicitudes se obtienen diferentes instancias de objeto. El alcance del prototipo es adecuado para objetos que tienen más estados y deben crearse y destruirse con frecuencia, como algunos beans relacionados con sesiones.
-
Alcance de la solicitud (solicitud) : el alcance de la solicitud es un alcance de uso común en aplicaciones web. Significa que cada solicitud HTTP creará una nueva instancia de Bean , que solo es válida durante el procesamiento de la solicitud actual. Cuando finalice la solicitud, el frijol será destruido. Estos ámbitos se utilizan normalmente para almacenar y procesar datos relacionados con una única solicitud.
-
Alcance de la sesión (sesión) : el alcance de la sesión es el alcance basado en la sesión del usuario en la aplicación web. Cada sesión HTTP (Session) corresponde a una instancia de Bean , que es válida durante toda la vida de la sesión. Este alcance es adecuado para objetos que necesitan mantener el estado durante toda la sesión, como la información de inicio de sesión del usuario.
-
Alcance global (aplicación) : el alcance global significa que solo se crea una instancia de Bean durante el ciclo de vida de toda la aplicación web . Los beans en este ámbito son visibles en toda la aplicación y son adecuados para la información de estado que debe compartirse en toda la aplicación.
-
Alcance de HTTP WebSocket (websocket) : el alcance de HTTP WebSocket es el alcance basado en la conexión WebSocket. Cada conexión WebSocket corresponde a una instancia de bean, que es válida durante toda la vida útil de la conexión WebSocket.
La diferencia entre alcance singleton (singleton) y alcance global (aplicación):
Tanto el alcance singleton como el alcance global solo crean un único objeto Bean, entonces, ¿cuál es la diferencia entre ellos?
1. Defina la ubicación:
- El alcance Singleton es parte de Spring Core y tiene efecto en todo el contenedor Spring IoC. Funciona con cualquier tipo de aplicación Spring, no solo con aplicaciones web.
- El alcance global es parte de Spring Web y entra en vigor en el contenedor de Servlet. Está diseñado específicamente para aplicaciones web y es compatible con la biblioteca Spring Web.
2. Ámbito de actuación:
- El alcance singleton solo garantiza que solo habrá una instancia de cada bean en el contenedor Spring IoC. Puede haber diferentes instancias de diferentes contenedores Spring IoC en toda la aplicación.
- El alcance global garantiza que solo habrá una instancia de cada bean en toda la aplicación web. Ya sea en el mismo contenedor de servlets o en un contenedor de servlets diferente, solo hay una instancia.
3. Escenarios de aplicación:
- El alcance singleton es adecuado para aquellos beans sin estado y seguros para subprocesos, como clases de herramientas, clases de configuración, etc. Dado que el bean singleton tiene solo una instancia en toda la aplicación, tiene ciertas ventajas en términos de rendimiento y utilización de recursos.
- El alcance global es adecuado para aquellos beans que necesitan compartir información de estado en toda la aplicación web, como objetos de configuración global, cachés globales, etc. Con alcance global, podemos asegurarnos de que estos objetos tengan solo una instancia en toda la aplicación y no se vean afectados por múltiples contenedores de servlets.
4. Gestionar contenedores:
- La gestión del alcance singleton es responsabilidad del contenedor Spring IoC, que es administrado por el contenedor IoC proporcionado por Spring Core y no tiene nada que ver con la aplicación web.
- La gestión del alcance global debe ser gestionada por el contenedor de servlet proporcionado por la biblioteca Spring Web, que está relacionado con el ciclo de vida de la aplicación web.
En resumen, el alcance singleton se aplica a todo el contenedor Spring IoC, lo que garantiza que cada bean tenga solo una instancia en el contenedor; mientras que el alcance global se aplica a toda la aplicación web, lo que garantiza que cada bean tenga solo una instancia en toda la aplicación. La elección de un alcance apropiado depende de los requisitos de aplicación específicos y las consideraciones de diseño.
1.4 Configuración del alcance del Bean
En Spring, hay dos formas de establecer el alcance del Bean: XML 配置和注解配置.
1. Configuración XML
En las etiquetas del archivo de configuración XML <bean>, puede utilizar scopeel atributo para establecer el alcance del Bean. Por ejemplo, para un Bean con alcance de prototipo, puedes configurarlo así:
<bean id="myBean" class="com.spring.demo.MyBean" scope="prototype">
<!-- Bean 的属性配置 -->
</bean>
Entre ellos scopese especifica el nombre del alcance, como por ejemplo: prototipo, singleton.
2. Configuración de anotaciones
Usar anotaciones para configurar el alcance de los beans es más conciso. En Spring, puede usar @Scopeanotaciones para especificar el alcance del Bean, como especificar el alcance del prototipo para la clase hace un momento UserBeans:
@Component
public class UserBeans {
@Bean(name = {
"user1"})
// @Scope("prototype") // 原型模式
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE) // 使用全局变量设置
public User getUser(){
User user = new User();
user.setId(123);
user.setName("张三");
return user;
}
}
En este punto, @Scopeel parámetro in puede ser el nombre del alcance, como por ejemplo: prototipo; también se puede ConfigurableBeanFactoryespecificar por clase. ConfigurableBeanFactoryEl código fuente de la clase:

Se puede encontrar que ConfigurableBeanFactoryla clase también es la encapsulación del nombre de dominio.
Cuando el alcance esté establecido en el modelo prototipo, ejecute nuevamente el código que acaba de modificar el contenido del Bean:

En este momento, se puede encontrar que ambos UserControllerobtenidos son objetos Bean nuevos, incluso si uno se modifica, el otro no se verá afectado.
2. Proceso de ejecución de Spring y ciclo de vida del Bean.
2.1 Proceso de ejecución de primavera
Flujo de ejecución de primavera:

-
Inicie el contenedor Spring:
- Cuando se inicia el contenedor Spring, leerá el archivo de configuración o escaneará la anotación para obtener la información de definición del bean.
-
Instanciar Bean (asignar espacio de memoria, desde cero):
- El contenedor Spring crea una instancia del objeto Bean de acuerdo con la información de configuración o la definición de anotación. El proceso de creación de instancias puede implicar la invocación de constructores y la creación de objetos dependientes.
-
Registro de beans en el contenedor Spring (operación de almacenamiento):
- El Bean instanciado se registra en el contenedor Spring, y el contenedor lo colocará en el ámbito de administración y asignará un identificador único (generalmente el nombre o ID del Bean) a cada Bean.
-
Inicialización de beans (operación de inicialización):
- Si el método de inicialización está configurado en la definición de Bean (por ejemplo, usando
init-methodatributos o@PostConstructanotaciones), el contenedor Spring llamará al método de inicialización después de la creación de instancias para realizar alguna lógica de inicialización.
- Si el método de inicialización está configurado en la definición de Bean (por ejemplo, usando
-
Ensamble el Bean en la clase requerida (tome la operación):
- Cuando otras clases necesitan usar un Bean, el contenedor Spring inyectará automáticamente el Bean correspondiente en la clase requerida de acuerdo con la configuración de inyección de dependencia. De esta manera, otras clases pueden usar directamente la instancia de Bean sin preocuparse por el proceso de creación y administración del objeto Bean.
-
Utilice frijoles:
- Ahora que Bean se ha ensamblado en las clases requeridas, se puede usar directamente en otras clases.
-
Destrucción de frijoles (operación de destrucción):
- Si la definición del bean está configurada con un método de destrucción (como el uso
destroy-methodde atributos o@PreDestroyanotaciones), el contenedor Spring llamará al método de destrucción cuando el contenedor esté cerrado para realizar algunas operaciones de limpieza.
- Si la definición del bean está configurada con un método de destrucción (como el uso
Cabe señalar que el ciclo de vida del Bean está bajo el control del contenedor Spring y los desarrolladores no necesitan administrar manualmente el proceso de creación y destrucción del Bean. Esta es la idea central de Spring IoC (Inversión de Control). A través de la inyección de dependencia, podemos centrarnos más en la realización de la lógica empresarial, sin tener que preocuparnos por la creación y gestión de objetos.
2.2 Ciclo de vida del frijol
El ciclo de vida de un bean se refiere a todo el proceso de una instancia de bean desde su creación hasta su destrucción. En el contenedor Spring, el ciclo de vida del Bean incluye principalmente las siguientes etapas:
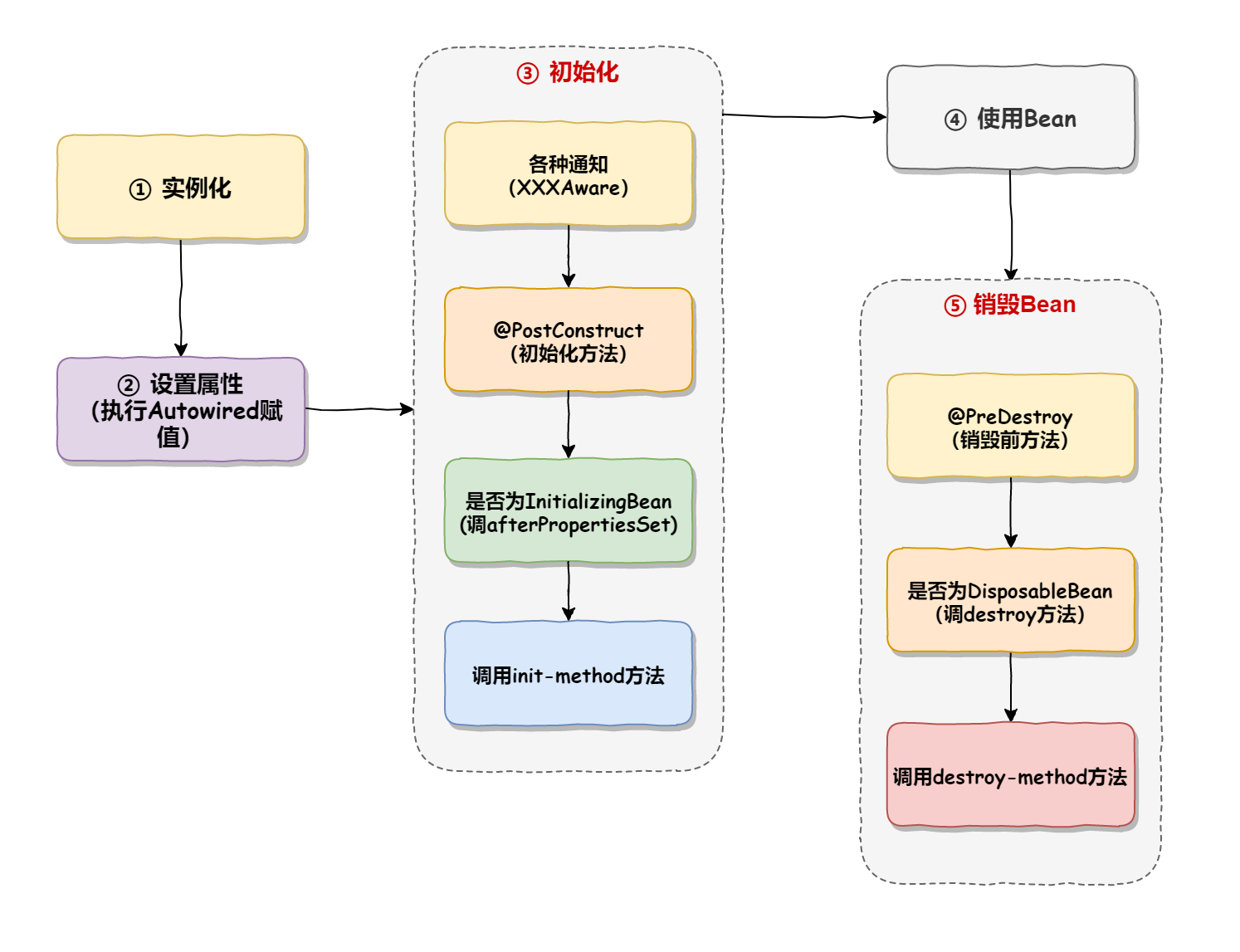
-
Creación de instancias : en esta etapa, el contenedor Spring creará instancias de Bean basadas en información de configuración y anotaciones. Este es el proceso "desde cero", es decir, asignar espacio de memoria y llamar al constructor para crear una instancia de Bean.
-
Establecer propiedades (inyección y ensamblaje de Bean) : después de la creación de instancias, el contenedor Spring inyectará valores de propiedad en las instancias de Bean de acuerdo con los archivos de configuración o anotaciones. Este es el proceso de inyección de dependencia (Inyección de dependencia), que establece el valor de propiedad de Bean mediante una propiedad o un método de construcción.
-
Inicialización del bean : una vez completada la asignación de atributos, el contenedor Spring realizará los siguientes pasos para inicializar el bean:
- Varias notificaciones : si Bean implementa la interfaz Aware correspondiente , Spring notificará al Bean el estado correspondiente a través del método de devolución de llamada, por ejemplo,
BeanNameAware, etc.BeanFactoryAwareApplicationContextAware - Método de preinicialización : ejecute
BeanPostProcessorel método de preinicialización, por ejemplopostProcessBeforeInitialization. - Método de inicialización (modo XML y modo de anotación) : si Bean define un método de inicialización (
@PostConstructanotación o implementaInitializingBeanuna interfaz), el contenedor Spring llamará a este método para una mayor inicialización después de configurar las propiedades. - Método posterior a la inicialización : si Bean define un método posterior a la inicialización, como el método
BeanPostProcessorde la clase de implementación de la interfazpostProcessAfterInitialization, el contenedor Spring llamará a este método después de que se inicialice el Bean.
- Varias notificaciones : si Bean implementa la interfaz Aware correspondiente , Spring notificará al Bean el estado correspondiente a través del método de devolución de llamada, por ejemplo,
-
Uso de Bean : una vez completada la inicialización, la aplicación puede utilizar la instancia de Bean. Se inyectará en otras clases u obtendrá y llamará a sus métodos a través del contenedor Spring.
-
Destruya el objeto Bean : cuando el contenedor se cierra o el programa finaliza, el contenedor Spring realizará los siguientes pasos para destruir el Bean:
- Destruir método previo: si el Bean define un método de destrucción, el contenedor Spring llamará a este método antes de que se destruya el Bean.
- Método de destrucción (modo XML y modo de anotación): si el Bean define un método de destrucción (
@PreDestroyanotación o implementaDisposableBeanuna interfaz), el contenedor Spring llamará a este método para limpiar cuando se destruya el Bean.
2.3 Demostración del ciclo de vida del Bean
El siguiente código demuestra un proceso completo del ciclo de vida del Bean y muestra los métodos de devolución de llamada de cada etapa del Bean en Spring. Echemos un vistazo al flujo de ejecución del ciclo de vida del Bean:
@Component
public class BeanComponent implements BeanNameAware, BeanPostProcessor {
@Override
public void setBeanName(String s) {
System.out.println("执行了通知,Bean name -> " + s);
}
// xml 的初始化方法
public void myInit(){
System.out.println("XML 方式初始化");
}
@PostConstruct
public void doPostConstruct(){
System.out.println("注解 的初始化方法");
}
public void sayHi(){
System.out.println("do sayHi()");
}
@PreDestroy
public void preDestroy(){
System.out.println("do PreDestroy");
}
// 前置方法
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("do postProcessBeforeInitialization");
return bean;
}
// 后置方法
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("do postProcessAfterInitialization");
return bean;
}
}
Primero, debe spring-config.xmlagregar el siguiente contenido al archivo de configuración:
<!-- XML 配置方式 -->
<bean id="beanComponent"
class="com.spring.demo.component.BeanComponent"
scope="prototype"
init-method="myInit" ></bean>
Simule el ciclo de vida de un frijol:
-
Crear una instancia del bean:
- El contenedor Spring lee el archivo de configuración o escanea las anotaciones, encuentra
BeanComponentla definición y crea una instancia del bean. En este punto, no se ha llamado al constructor del Bean.
- El contenedor Spring lee el archivo de configuración o escanea las anotaciones, encuentra
-
Establecer propiedades (inyección y ensamblaje de frijoles):
- Si es necesario, el contenedor Spring inyectará las propiedades correspondientes en
BeanComponentla instancia.
- Si es necesario, el contenedor Spring inyectará las propiedades correspondientes en
-
Inicialización del frijol:
- Realizar varias notificaciones: debido a que
BeanComponentimplementaBeanNameAwarela interfaz,setBeanNamese llamará al método y se imprimirá la salida执行了通知,Bean name -> beanComponent. - Método de preinicialización: si es un método de configuración XML,
myInitse llamará al método y se imprimirá el resultadoXML 方式初始化. - Método de inicialización (anotación @PostConstruct):
doPostConstructse llamará al método y se imprimirá el resultado注解 的初始化方法. - Método posterior a la inicialización:
postProcessAfterInitializationse llamará al método y se imprimirá el resultadodo postProcessAfterInitialization.
- Realizar varias notificaciones: debido a que
-
Utilice frijoles:
- Después de la inicialización,
BeanComponentla aplicación puede utilizar la instancia, como llamarsayHi()a métodos e imprimir resultadosdo sayHi().
- Después de la inicialización,
-
Destruye el objeto Bean:
- Cuando se cierra el contenedor o finaliza el programa,
preDestroyse llamará al método y se imprimirá la salidado PreDestroy.
- Cuando se cierra el contenedor o finaliza el programa,
Tenga en cuenta que en el ejemplo anterior, BeanPostProcessorla interfaz se utiliza para implementar los métodos previos y posteriores. Esta interfaz proporciona la capacidad de realizar procesamiento adicional en el bean antes y después de que se inicialice. En aplicaciones prácticas, BeanPostProcessorse puede personalizar alguna lógica de procesamiento específica implementando la interfaz, como la generación de proxy AOP.
El método para iniciar la clase main:
public static void main(String[] args) {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("spring-config.xml");
BeanComponent beanComponent= context.getBean("beanComponent", BeanComponent.class);
beanComponent.sayHi();
}
Resultado de la ejecución:
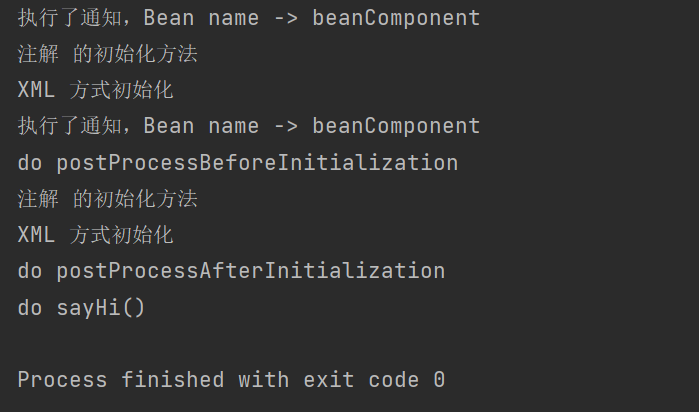
se encuentra que aquí se ejecutan dos notificaciones, la primera vez generalmente se debe a que la instanciación de Bean se ejecutará cuando se cree el contexto Spring; la segunda ejecución generalmente se debe a que se usa el modo prototipo, cuando la ejecución creará un getBeannuevo objeto Bean.