Esta serie incluye:
- [Big Data] Explicación detallada de Flink (1): conceptos básicos
- [Big Data] Explicación detallada de Flink (2): Parte principal I
- [Big Data] Explicación detallada de Flink (3): Parte principal II
- [Big Data] Explicación detallada de Flink (4): Parte principal III
- [Big Data] Explicación detallada de Flink (5): Capítulo principal IV
- [Big Data] Explicación detallada de Flink (6): Código fuente Parte I
- [Big Data] Explicación detallada de Flink (7): Código fuente II
Explicación detallada de Flink (7): Código fuente II
- 69. ¿Cuál es la diferencia entre diagrama de flujo, diagrama de operación y diagrama de ejecución?
- 70. ¿Presentar el diagrama de flujo?
- 71. ¿Cuéntame sobre el diagrama de tarea?
- 72. ¿Cuéntanos sobre el diagrama de ejecución?
- 73. ¿Presentar el concepto de programador Flink?
- 74. ¿Cuántos tipos de comportamientos de programación de Flink existen?
- 75. ¿Cuántos modos de programación incluye Flink?
- 76. ¿Cuántos tipos de estrategias de programación de Flink existen?
- 77. ¿Qué estados contiene el ciclo de vida laboral de Flink?
- 78. ¿Qué estados contiene el ciclo de vida laboral de Task?
- 79. ¿Explica el proceso de programación de tareas de Flink?
- 80. ¿Qué significa la ranura de tareas de Flink?
- 81. ¿Qué significa compartir ranuras de Flink?
69. ¿Cuál es la diferencia entre diagrama de flujo, diagrama de operación y diagrama de ejecución?
Dado que Flink ahora implementa código integrado de flujo por lotes, la API de lotes está básicamente abandonada, por lo que no la presentaré demasiado. En la API de Flink DataStream, el gráfico de conversión interno de Graph es el siguiente:

Tomando WordCount como ejemplo, la programación de tareas entre el gráfico de flujo, el gráfico de trabajo, el gráfico de ejecución y el gráfico de ejecución física es la siguiente:

Para las aplicaciones informáticas de flujo de Flink, cuando ejecute el código de usuario, primero llame a la API DataStream para convertir el código de usuario en Transformación, luego pase por: StreamGraph → JobGraph → ExecutionGraphtres capas de conversión (estas son las estructuras de datos integradas de Flink) y finalmente pase por la ejecución de programación de Flink , en el clúster de Flink Inicie las tareas informáticas para formar un gráfico de ejecución física.
70. ¿Presentar el diagrama de flujo?

Hay dos objetos principales de StreamGraph: StreamNode y StreamEdge .
-
StreamNode se convierte a partir de Transformation. Se puede entender simplemente que StreamNode representa un operador, que existe como entidad y virtual, y puede tener múltiples entradas y salidas. La entidad StreamNode eventualmente se convierte en un operador físico, que está conectado virtualmente al borde de StreamEdge.
-
StreamEdge es el borde de StreamGraph, que se utiliza para conectar dos puntos StreamNode. Un StreamEdge puede tener múltiples bordes salientes, entrantes y otra información.
71. ¿Cuéntame sobre el diagrama de tarea?
JobGraph está optimizado a partir de StreamGraph. Combina operadores a través del mecanismo OperationChain. Durante la ejecución, se programan en el mismo subproceso de tarea para evitar la transferencia de datos entre subprocesos y entre redes.

Los objetos principales de JobGraph incluyen tres:
-
Punto JobVertex : después de la optimización de la fusión del operador, se pueden fusionar varios StreamNodes que cumplan las condiciones para generar un JobVertex, es decir, un JobVertex contiene uno o más operadores, la entrada de JobVertex es JobEdge y la salida es IntermediateDataSet.
-
Borde de JobEdge : JobEdge representa un canal de flujo de datos en JobGraph, su fuente de datos ascendente es IntermediateDataSet y su consumidor descendente es JobVertex. El modo de distribución de datos en JobEdge afectará directamente si la relación de conexión de datos entre Tareas es una conexión punto a punto o una conexión completa durante la ejecución.
-
IntermediateDataSet conjunto de datos intermedios : conjunto de datos intermedios IntermediateDataSet es una estructura lógica utilizada para representar la salida de JobVertex, es decir, el conjunto de datos generado por los operadores contenidos en JobVertex. En diferentes modos de ejecución, los tipos de partición de resultados correspondientes son diferentes, lo que determina el modo de intercambio de datos en el momento de la ejecución.
72. ¿Cuéntanos sobre el diagrama de ejecución?
ExecutionGraph es la estructura de datos central para programar la ejecución de trabajos de Flink, incluida toda la información de tareas de ejecución paralela en el trabajo, la relación de asociación entre tareas y la relación de flujo de datos.
Tanto StreamGraph como JobGraph se generan en Flink Client y luego se entregan al clúster de Flink. JobGraph a ExecutionGraph se completa en JobMaster y los cambios importantes durante el proceso de conversión son los siguientes:
- Se ha añadido el concepto de paralelismo para convertirlo en una estructura gráfica verdaderamente programable.
- generado 6 66 objetos centrales.

Gráfico de ejecución Los objetos principales de ExecutionGraph incluyen 6 66 :
-
ExecutionJobVertex : este objeto corresponde al JobVertex en JobGraph. El objeto también contiene un conjunto de ExecutionVertex, cuyo número es consistente con el paralelismo del StreamNode contenido en JobVertex, suponiendo que el paralelismo del StreamNode es 5 55 , entonces ExecutionJobVertex también contendrá5 55 EjecuciónVértice. ExecutionJobVertex se utiliza para encapsular un JobVertex en ExecutionJobVertex y crear ExecutionVertex, Execution, IntermediateResult e IntermediateResultPartition a su vez para enriquecer ExecutionGraph.
-
ExecutionVertex : ExecutionJobVertex paralelizará el trabajo y construirá instancias que se pueden ejecutar en paralelo. Cada instancia de ejecución paralela es ExecutionVertex.
-
IntermediateResult : IntermediateResult también se llama conjunto de resultados intermedio. Este objeto es un concepto lógico que representa la salida de ExecutionJobVertex, que corresponde a IntermediateDalaSet en JobGrap. El mismo ExecutionJobVertex puede tener múltiples resultados intermedios, dependiendo de cuántos bordes (JobEdge) tenga el JobVertex actual. . .
-
IntermediateResultPartition : IntermediateResultPartition también se denomina partición de resultados intermedios. significa 1 11 Resultado de salida de ExecutionVertex, asociado con ExecutionEdge.
-
ExecutionEdge : indica la entrada de ExecutionVertex, conectada a la IntermediateResultPartition generada en sentido ascendente. 1 11 La ejecución corresponde al único1 11 ParticiónResultadoIntermedio y1 11 EjecuciónVértice. 1 11 ExecutionVertex puede tener múltiples ExecutionEdge.
-
Ejecución : ExecutionVertex es equivalente a la plantilla de cada Tarea. Cuando realmente se ejecuta, la información en ExecutionVertex se empaquetará como 1 11 Ejecución, un intento de ejecutar un ExecutionVertex.
La actualización del estado de implementación de tareas y ejecución de tareas entre JobManager y TaskManager se identifica mediante ExecutionAttemptID.
73. ¿Presentar el concepto de programador Flink?
El programador es el componente central de la ejecución del trabajo de Flink y gestiona todos los procesos relacionados con la ejecución del trabajo, incluida la conversión de JobGraph a ExecutionGraph, la gestión del ciclo de vida del trabajo (liberación, cancelación, parada del trabajo), la gestión del ciclo de vida de la tarea del trabajo (liberación de la tarea, cancelar, detener), aplicación y liberación de recursos, conmutación por error de trabajos y tareas, etc.
-
DefaultScheduler : El programador predeterminado actual de Flink es el nuevo diseño de programación de Flink, que se utiliza
SchedulerStrategypara implementar la programación. -
LegacySchedular : el programador en el pasado implementó la lógica de programación de ejecución original.
74. ¿Cuántos tipos de comportamientos de programación de Flink existen?
La interfaz SchedulingStrategy define el comportamiento de programación, que contiene 4 44 comportamientos:

startScheduling: Entrada de programación, que activa el comportamiento de programación del programador.restartTasks: reinicie la tarea que no se pudo ejecutar, lo que generalmente se debe a una ejecución anormal de la tarea.onExecutionStateChange: Cuando cambia el estado de ejecución.onPartitionConsumable: Cuándo se pueden consumir los datos de IntermediateResultPartition.
75. ¿Cuántos modos de programación incluye Flink?
El modo de programación contiene 3 33 tipos: modo ansioso, modo por fases (Lazy_From_Source), modo de reutilización de ranura por fases (Lazy_From_Sources_With_Batch_Slot_Request).
-
Programación ansiosa : adecuada para la computación en flujo. Solicite todos los recursos necesarios a la vez. Si los recursos son insuficientes, el trabajo no podrá iniciarse.
-
Programación por fases :
LAZY_FROM_SOURCESadecuada para procesamiento por lotes. La programación comienza desde SourceTask en etapas. Al solicitar recursos, solicite todos los recursos necesarios en esta etapa a la vez. Después de ejecutar la tarea ascendente, comienza a programar y ejecutar la tarea descendente, lee los datos ascendentes y ejecuta las tareas de cálculo de esta etapa. Una vez completada la ejecución, programa las tareas de la siguiente etapa y las programa en gire hasta completar el trabajo. -
Programación de reutilización de ranuras por fases :
LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUESTadecuada para el procesamiento por lotes. Básicamente es lo mismo que la programación por fases, la diferencia es que este modo utiliza el modo de aplicación de recursos por lotes, que puede ejecutar trabajos cuando los recursos son insuficientes, pero es necesario asegurarse de que no haya un comportamiento aleatorio durante la ejecución del trabajo en esta etapa.
La lógica de aplicación de recursos del Eagerpatrón y el patrón actualmente a la vista son la misma y es una lógica de aplicación de recursos separada.LAZY_FROM_SOURCESLAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST
76. ¿Cuántos tipos de estrategias de programación de Flink existen?


Todas las estrategias de programación se implementan en el programador SchedulingStrategyy hay tres implementaciones:
-
EagerSchedulingStrategy : Adecuado para computación en flujo y programa todas las tareas al mismo tiempo.
-
LazyFromSourcesSchedulingStrategy : Adecuado para el procesamiento por lotes, la programación de vértices se realiza cuando los datos de entrada están listos (se completa el procesamiento ascendente).
-
PipelinedRegionSchedulingStrategy : Programación en la granularidad local de la tubería.
PipelinedRegionSchedulingStrategyes 1,11 1,11Agregado en 1.11 , desde 1.12 1.12A partir del 1.12 , la programación se realizará pipelined regionen
pipelined regiones un conjunto de tareas canalizadas. Esto significa que para regiontrabajos de transmisión con múltiples, ya no espera a que se obtengan todas las tareas antes de comenzar a implementarlas slot. En cambio, se puede implementar una vez que cualquiera regionhaya adquirido suficientes tareas . slotPara los trabajos por lotes, las tareas no se asignarán sloty las tareas no se implementarán individualmente. En cambio, una vez que regionse adquiere una misión suficiente slot, esa misión se implementará en la misma región que todas las demás misiones.
77. ¿Qué estados contiene el ciclo de vida laboral de Flink?
En el clúster de Flink, JobMaster es responsable de la gestión del ciclo de vida del trabajo y el comportamiento de gestión específico se implementa en el programador y en ExecutionGraph.
La transición de estado del ciclo de vida completo de un trabajo se muestra en la siguiente figura:

-
Un trabajo primero está en un estado creado (
created), luego cambia a un estado en ejecución (running) y, cuando todo el trabajo está terminado, cambia a un estado completado (finished). -
En caso de falla, el trabajo primero cambia al estado fallido (
failing), cancelando todas las tareas en ejecución. Si todos los nodos han alcanzado el estado final y el trabajo no se puede reiniciar, el estado pasa a Fallido (failed). -
Si el trabajo se puede reiniciar, ingresa al estado de reinicio (
restarting). Una vez que termine de reiniciarse, cambiará al estado creado (created). -
En caso de que el usuario cancele el trabajo, ingresa al estado de cancelación (
cancelling), que cancela todas las tareas actualmente en ejecución. Una vez que todas las tareas en ejecución han alcanzado el estado final, el trabajo pasa al estado cancelado (canceled).
El estado completado (finished), el estado cancelado (canceled) y el estado fallido (failed) representan un estado finalizado global y desencadenan la limpieza, mientras que el estado suspendido (suspended) está solo en un estado finalizado local. Significa que la ejecución del trabajo finaliza en el JobManager correspondiente, pero otro JobManager del clúster puede recuperar este trabajo del almacenamiento HA persistente y reiniciarlo. Por lo tanto, los trabajos que estén en estado suspendido no se limpiarán por completo.
78. ¿Qué estados contiene el ciclo de vida laboral de Task?
TaskManager es responsable de la gestión del ciclo de vida de la Tarea, notifica a JobMaster sobre los cambios de estado y realiza un seguimiento de los cambios de estado de la Ejecución en ExecutionGraph, una Ejecución para una Tarea.
El ciclo de vida de Task es el siguiente: un total de 8 88 estados.

Durante la ejecución de ExecutionGraph, cada tarea paralela pasa por varias etapas, desde la creación ( created) hasta la finalización ( finished) o el fallo ( failed), y el diagrama anterior ilustra los estados y las posibles transiciones entre ellos. Las tareas se pueden ejecutar varias veces (por ejemplo, conmutación por error). Cada Ejecución rastrea la ejecución de un ExecutionVertex, y cada ExecutionVertex tiene una Ejecución actual ( current execution) y una Ejecución predecesora ( prior execution).
79. ¿Explica el proceso de programación de tareas de Flink?
El diagrama de flujo de programación de tareas es el siguiente:

(1) Cuando Flink ejecuta el ejecutor, generará automáticamente un gráfico de flujo de datos DAG, es decir, Jobgraph, de acuerdo con el código del programa.
(2) ActorSystem crea Actor y envía el gráfico de flujo de datos a Actor en JobManager.
(3) JobManager continuará recibiendo el mensaje de latido de TaskManager para poder obtener un TaskManager válido.
(4) JobManager programa y ejecuta la Tarea en TaskManager a través del programador (en Flink, la unidad de programación más pequeña es la Tarea, que corresponde a un hilo).
(5) Durante la ejecución del programa, es posible la transmisión de datos entre Tarea y Tarea.
- Cliente de trabajo
- La responsabilidad principal es enviar la tarea. Después de enviarla, se puede finalizar el proceso o se puede devolver el resultado.
- Job Client no es una parte interna de la ejecución del programa Flink, pero es el punto de partida para la ejecución de la tarea.
- El Cliente de Trabajo es responsable de aceptar el código del programa del usuario, luego crear un flujo de datos y enviar el flujo de datos al Administrador de Trabajo para su posterior ejecución. Una vez completada la ejecución, Job Client devuelve el resultado al usuario.
- Administrador de trabajos
- La responsabilidad principal es programar el trabajo y coordinar las tareas para realizar los puntos de control.
- Debe haber al menos un maestro en el clúster, y el maestro es responsable de programar tareas, coordinar puntos de control y tolerancia a fallas.
- Puede haber varios maestros en un entorno de alta disponibilidad, pero uno debe ser el líder y los demás deben estar en espera.
Actor SystemJob Manager contieneSchedulertresCheckPointcomponentes importantes.- Después de que JobManager recibe la tarea del cliente, primero genera un plan de ejecución optimizado y luego lo programa en TaskManager para su ejecución.
- Administrador de tareas
- La responsabilidad principal es recibir tareas de JobManager, implementar e iniciar tareas, recibir y procesar datos ascendentes.
- Los TaskManagers son nodos trabajadores que ejecutan tareas en uno o más subprocesos en la JVM.
- TaskManager ha configurado ranuras al comienzo de la creación y cada ranura puede ejecutar una tarea.
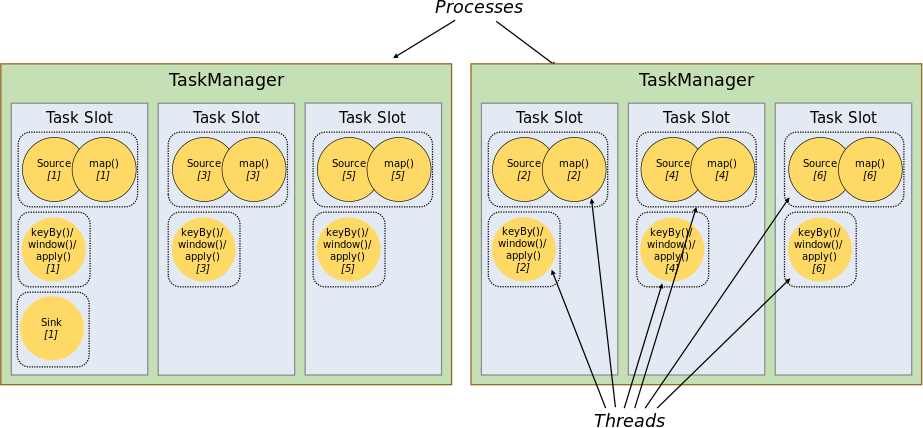
80. ¿Qué significa la ranura de tareas de Flink?

Cada TaskManager es un proceso JVM que puede ejecutar una o más subtareas en diferentes subprocesos. Para controlar workercuántos puede recibir task. Controlado workerpor (uno tiene al menos uno ). Cada uno representa un subconjunto de recursos de tamaño fijo propiedad del TaskManager.task slotworkertask slottask slot
En términos generales, la cantidad de ranuras que asignamos es igual a la cantidad de núcleos de la CPU, como 8 88 núcleos, luego asigne8 88 ranuras. Flink divide la memoria de un proceso en múltiplesslot. Hay 2 2en la foto.2 TaskManagers, cada TaskManager tiene3 33 ,slotcada unoslotocupa1/3 1/31/3 de memoria.
Una vez dividida la memoria en diferentes, slotse pueden obtener los siguientes beneficios:
- La tarea que TaskManager puede ejecutar al mismo tiempo como máximo es controlable, es decir 3 33 porque
slotno se puede exceder el número de. La función de la ranura de tarea es separar la memoria administrada de la tarea y no se producirá ningún aislamiento de la CPU. slotHay un espacio de memoria exclusivo, por lo que se pueden ejecutar varios trabajos diferentes en un TaskManager y los trabajos no se verán afectados.
Resumen: task slotel número de representa taskel número de TaskManagers que se pueden ejecutar en paralelo.
81. ¿Qué significa compartir ranuras de Flink?
De forma predeterminada, Flink permite que las subtareas compartan espacios, incluso si son subtareas de diferentes tareas, siempre que provengan del mismo trabajo. El resultado es una ranura que puede contener todo el proceso de un trabajo. Permitir compartir espacios tiene importantes beneficios:
-
Simplemente calcule el grado más alto de paralelismo (
parallelism) en el Trabajotask slot. Mientras esto se cumpla, también se podrán satisfacer otros trabajos. -
La distribución de recursos es más equitativa. Si hay más tiempo libre
slotse le pueden asignar más tareas. Si no se comparte el espacio para tareas en la figura, la fuente/mapa con carga bajasubtaskocupará muchos recursos, mientras que la ventana con carga altasubtaskcarecerá de recursos. -
Al compartir tareas y espacios, el paralelismo base (
base parallelism) se puede cambiar de 2 22 elevado a6 66 . Mejor utilización de los recursos asignados. Al mismo tiempo, también puede garantizar quesubtaskde asignaciónslotasignado por TaskManager sea más justo.