Tabla de contenido
1. Formas de mejorar la velocidad de E/S del disco
(1) Caché de disco (caché de disco)
1.1 - Método de entrega de datos
1.2 - Algoritmo de permutación
1.3 - Volver a escribir periódicamente en el disco
(2) Otras formas de mejorar la velocidad de E/S del disco
2.3 - Optimización de la distribución de bloques físicos
(3) Matriz elemental de disco (RAID) económica
2. Tecnología para mejorar la confiabilidad del disco
(1) La tecnología tolerante a fallas de primer nivel SFT-I
1.1 - Doble índice de contenidos y doble tabla de asignación de archivos
1.2 - Redirección de revisión y suma de comprobación de lectura tras escritura
(2) La tecnología tolerante a fallas de segundo nivel SFT-II
(3) Función tolerante a fallas basada en tecnología de clúster
3.1 - Modo de copia de seguridad en caliente de dos máquinas
3.2 - Dos máquinas están en modo de respaldo mutuo
3. Control de coherencia de los datos
1.1 - Definición de transacción
1.2 - Registro de transacciones
1.3 - Algoritmo de recuperación
(4) Problema de coherencia de datos de datos duplicados
1. Formas de mejorar la velocidad de E/S del disco
El rendimiento del sistema de archivos se puede manifestar en muchos aspectos, uno de los aspectos más importantes es la velocidad de acceso a los archivos, para mejorar la velocidad de acceso a los archivos podemos partir de tres aspectos:
- Mejore la estructura del directorio del archivo y el método de recuperación del directorio para reducir el tiempo de búsqueda del directorio.
- Elija una buena estructura de almacenamiento de archivos para mejorar la velocidad de acceso a los archivos.
- Mejore la velocidad de E/S del disco y pueda transferir rápidamente los datos del archivo desde el disco a la memoria.
En la actualidad, la velocidad de E/S del disco es mucho menor que la velocidad de acceso a la memoria, normalmente entre 4 y 6 órdenes de magnitud menor. Por lo tanto, la E/S del disco se ha convertido en el cuello de botella del sistema informático.
(1) Caché de disco (caché de disco)
La caché de disco se refiere a un conjunto de búfer para bloques de disco en la memoria , y se guarda una copia de algunos bloques de disco en el búfer.
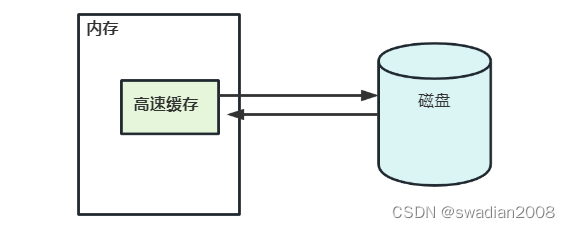
Los aspectos a considerar al diseñar una caché de disco son:
- Cómo pasar datos del caché del disco al proceso de solicitud. // entrega de datos
- Qué estrategia de reemplazo utilizar.
- Cuando los datos del bloque reparado se vuelven a escribir en el disco.
1.1 - Método de entrega de datos
La llamada entrega de datos se refiere a la transferencia de datos en el caché del disco al proceso solicitante . El sistema puede entregar datos al proceso solicitante de dos maneras:
- Entrega de datos : esta es la transferencia directa de datos desde el caché al espacio de trabajo de la memoria del proceso solicitante. // directamente a los datos
- Entrega de puntero : Sólo se entrega al proceso solicitante un puntero a un área de la caché .
La entrega de puntero ahorra el tiempo que tardan los datos en llegar desde el almacenamiento caché del disco al espacio de trabajo de la memoria del proceso debido a la pequeña cantidad de datos transferidos.
1.2 - Algoritmo de permutación
Los algoritmos de reemplazo comúnmente utilizados incluyen el algoritmo LRU usado menos recientemente , el algoritmo NRU usado menos recientemente y el algoritmo LFU usado menos recientemente .
Cuando el sistema diseña el algoritmo de reemplazo del caché, además de considerar el principio de que no se ha utilizado durante más tiempo, también se deben considerar los siguientes puntos: // Enlace de datos LRU
- Frecuencia de visitas . Normalmente, la frecuencia de acceso a la memoria asociativa es básicamente equivalente a la frecuencia de ejecución de instrucciones. La frecuencia de acceso a la caché del disco es comparable a la frecuencia de E/S del disco. Por tanto, la frecuencia de acceso a la memoria asociativa es mucho mayor que la frecuencia de acceso a la caché del disco.
- previsibilidad . A qué datos es posible que no se vuelva a acceder durante un largo período de tiempo, a qué datos se puede volver a acceder pronto y una parte considerable de ellos es predecible.
- Coherencia de los datos . Si los datos almacenados en el caché se modificaron pero no se copiaron nuevamente al disco, cuando el sistema falla, pueden ocurrir inconsistencias en los datos.
1.3 - Volver a escribir periódicamente en el disco
Según el algoritmo LRU, algunos datos de bloques de disco a los que se accede con frecuencia pueden permanecer en el caché y no se volverán a escribir en el disco durante mucho tiempo . Porque después de acceder a cualquier elemento de la cadena, se colgará al final de la cadena sin volver a escribirse en el disco. Solo los elementos a los que no se ha accedido se pueden mover al principio de la cadena y volver a escribirse en el disco. . //Al reemplazar, volver a escribir en el disco comenzando desde el principio de la cadena
Para resolver este problema, se agrega especialmente un programa de modificación (actualización) en el sistema UNIX para que se ejecute en segundo plano, y el programa llama periódicamente a una llamada al sistema SYNC. Su función principal es escribir forzosamente en el disco todos los datos del bloque de disco modificado en el caché . Generalmente, el intervalo de tiempo entre llamadas a SYNC dos veces se establece en 30 segundos. De esta forma, la pérdida de trabajo provocada por una falla del sistema no excederá la carga de trabajo de 30 segundos. // Escribe periódicamente, pero no puedes garantizar que los datos no se pierdan
(2) Otras formas de mejorar la velocidad de E/S del disco
2.1 - Leer con anticipación
Si se accede al archivo de forma secuencial , se puede predecir el bloque de disco que se leerá la próxima vez . En este momento, se puede adoptar el método de lectura previa, es decir, mientras se lee el bloque actual, los datos del siguiente bloque de disco (bloque leído por adelantado) también deben leerse en el búfer, lo que reduce en gran medida el tiempo. para leer datos.
2.2 - Escrituras retrasadas
La escritura retrasada se refiere a cambiar los datos del búfer que deben volver a escribirse en el disco inmediatamente, en lugar de colgarlos al final de la cola del búfer libre y no volver a escribir hasta que el búfer se asigne como búfer libre.
La ventaja de que los datos del búfer residan en la memoria es que cualquier proceso que acceda a los datos puede leerlos directamente sin acceder al disco . De esta forma, se puede reducir aún más el tiempo de IO del disco.
2.3 - Optimización de la distribución de bloques físicos
Idea: organizar dos bloques de datos en dos bloques de disco que pertenecen a la misma pista y aumentar considerablemente la velocidad de acceso a estos dos bloques de disco eliminando el movimiento del cabezal magnético entre pistas. //Escribe secuencialmente, reduciendo la distancia promedio de movimiento del cabezal magnético.
2.4 - Disco virtual
El llamado disco virtual utiliza espacio de memoria para emular el disco , también conocido como disco RAM.
El principal problema del disco virtual es: es una memoria volátil , por lo que una vez que falla el sistema o la fuente de alimentación, o cuando el sistema se reinicia, los datos originalmente almacenados en el disco virtual se perderán. Por lo tanto, los discos virtuales se utilizan generalmente para almacenar archivos temporales, como programas de destino generados al compilar programas.
La principal diferencia entre un disco virtual y un disco caché es que el contenido de un disco virtual está completamente bajo control del usuario, mientras que el contenido de un disco caché está controlado por el sistema operativo . Por ejemplo, el disco RAM está vacío al principio y solo después de que el usuario (programa) crea un archivo en el disco RAM, el disco RAM tiene contenido. // sólo entender
(3) Matriz elemental de disco (RAID) económica
Pensamiento: si la mejora del rendimiento mediante el uso de un componente es muy limitada, puede obtener una gran mejora del rendimiento utilizando varios componentes del mismo componente . // Como sistema monoprocesador -> sistema multiprocesador, sistema distribuido
La matriz redundante de discos económicos (RAID) es un almacenamiento en disco de gran capacidad compuesto por varios discos pequeños .
RAID no solo aumenta en gran medida la capacidad del disco, sino que también mejora en gran medida la velocidad de E/S del disco y la confiabilidad de todo el sistema de disco.
Intercalado paralelo: en un sistema con varias unidades de disco, el sistema divide los datos de cada bloque de disco en varios datos de bloques de subdisco y luego almacena los datos de cada bloque de subdisco en diferentes discos en la misma posición . En el futuro, cuando los datos de un bloque de disco se van a transferir a la memoria, se adopta el método de transmisión paralela para transmitir los datos de los bloques de subdisco en cada bloque de disco a la memoria al mismo tiempo, de modo que el El tiempo de transmisión se reduce considerablemente. //Transferencia de varios discos en paralelo
2. Tecnología para mejorar la confiabilidad del disco
La tecnología tolerante a fallas es una tecnología que mejora la confiabilidad del sistema al configurar componentes redundantes en el sistema . La tecnología de tolerancia a fallas de disco es una tecnología para mejorar la confiabilidad del sistema de disco agregando unidades de disco redundantes, controladores de disco y otros métodos. Es decir, cuando una determinada parte del sistema de disco tiene un defecto o falla, el disco aún puede funcionar normalmente sin causar pérdida o error de datos . // redundancia de componentes
La tecnología de disco tolerante a fallas a menudo también se denomina tecnología de sistema tolerante a fallas SFT. Se puede dividir en tres niveles: el primer nivel es la tecnología tolerante a fallas del disco de bajo nivel; el segundo nivel es la tecnología tolerante a fallas del disco de nivel medio; el tercer nivel es la tecnología tolerante a fallas del sistema, que implementa la tolerancia a fallas basada en tecnología de clústeres.
(1) La tecnología tolerante a fallas de primer nivel SFT-I
La tecnología tolerante a fallas de primer nivel (SFT-I) se utiliza principalmente para evitar la pérdida de datos causada por defectos en la superficie del disco e incluye medidas como directorios dobles , tablas de asignación de archivos dobles y verificación de lectura tras escritura .
1.1 - Doble índice de contenidos y doble tabla de asignación de archivos
El directorio de archivos y la tabla de asignación de archivos FAT almacenados en el disco son estructuras de datos importantes que se utilizan para la gestión de archivos. Para evitar que estas tablas se destruyan, la tabla de directorio (doble) y la FAT se pueden establecer por separado en diferentes discos o en diferentes áreas del disco . Uno de ellos es el directorio principal y la FAT principal, y el otro es el directorio de respaldo y la FAT de respaldo. //copia de seguridad del archivo
Una vez que el directorio de archivos principal o la FAT principal están dañados debido a un defecto de la superficie del disco, el sistema habilitará automáticamente el directorio de archivos de respaldo y la FAT de respaldo, para garantizar que los datos en el disco aún sean accesibles.
1.2 - Redirección de revisión y suma de comprobación de lectura tras escritura
Debido al alto precio del disco, en caso de una pequeña cantidad de defectos en la superficie del disco, se pueden tomar algunas medidas correctivas para continuar usándolo. Generalmente, se adoptan principalmente las siguientes dos medidas correctivas:
- Redirección de reparación en caliente , el sistema utiliza una pequeña parte de la capacidad del disco (por ejemplo, 2% ~ 3%) como área de redirección de reparación en caliente, que se utiliza para almacenar datos que se escribirán cuando se descubra que el disco está defectuoso, y todos los datos escritos en esta área Los datos se registran para que se pueda acceder a ellos más tarde. //Asignar un área dedicada para transportar datos de defectos
- En el método de verificación de lectura tras escritura , para garantizar que todos los datos escritos en el disco se puedan escribir en bloques de disco intactos, cada vez que se escribe un bloque de datos en el disco, se debe leer inmediatamente y enviar a In otro búfer, compare el contenido del búfer con los datos que quedan en el búfer de memoria después de escribir, y si los dos son consistentes, se considera que la escritura fue exitosa. De lo contrario, reescribe. Si los dos aún son inconsistentes después de la reescritura, se considera que el bloque de disco está defectuoso y, en este momento, los datos que deben escribirse en el bloque de disco se escriben en el área de redirección de reparación en caliente. // Después de escribirlo, léelo en voz alta para compararlo y verificarlo.
(2) La tecnología tolerante a fallas de segundo nivel SFT-II
La tecnología de tolerancia a fallas de segundo nivel se utiliza principalmente para evitar el mal funcionamiento del sistema causado por fallas de las unidades de disco y los controladores de disco . Se puede dividir en duplicación de disco y duplexación de disco .
2.1 - Duplicación de disco
Para evitar la pérdida de datos debido a una falla de la unidad de disco, se agrega la función de duplicación de disco. Para realizar esta función, se debe agregar una unidad de disco idéntica bajo el mismo controlador de disco . // Componentes redundantes, unidades de disco
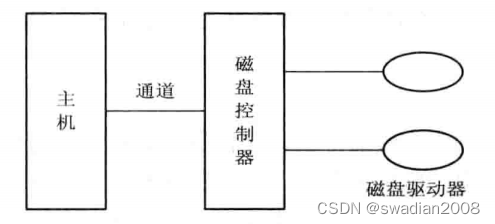
Cuando se utiliza el método de duplicación de disco, cada vez que los datos se escriben en el disco principal, es necesario escribirlos en el disco de respaldo para que los dos discos tengan exactamente el mismo mapa de bits. Piense en el disco de respaldo como un espejo del disco principal. Cuando falla la unidad de disco principal, el host aún puede funcionar normalmente después de cambiar debido a la existencia del disco de respaldo.
Aunque la duplicación de disco logra tolerancia a fallas , reduce la utilización del disco al 50 % y no logra aumentar la velocidad de E/S del disco del servidor. //considerar cuidadosamente
2.2 - Duplicación de disco
Si falla el controlador de disco que controla las dos unidades de disco, o falla la ruta entre la computadora host y el controlador de disco, la duplicación de disco no proporciona protección de datos. Por lo tanto, en la tecnología tolerante a fallas de segundo nivel, se agrega la función dúplex de disco, es decir, dos unidades de disco están conectadas respectivamente a los dos controladores de disco y las dos unidades de disco también se reflejan en un par.

En la duplexación de discos, el servidor de archivos escribe datos en dos discos bajo diferentes controladores al mismo tiempo, de modo que los dos tengan exactamente el mismo mapa de bits . Si un canal o controlador falla, el disco del otro canal aún puede funcionar normalmente sin pérdida de datos. Cuando el disco está en modo dúplex, dado que cada disco tiene su propio canal independiente, los datos se pueden escribir o leer desde el disco al mismo tiempo (en paralelo).
(3) Función tolerante a fallas basada en tecnología de clúster
El llamado cluster se refiere a un sistema informático unificado compuesto por un grupo de ordenadores autónomos interconectados , dando a las personas la sensación de que son una máquina. El uso de sistemas de clúster no solo puede mejorar la capacidad de procesamiento paralelo del sistema, sino también mejorar la disponibilidad del sistema. Actualmente son los sistemas de clúster con funciones tolerantes a fallas más utilizados. Hay tres modos de trabajo principales: modo de copia de seguridad en caliente, modo y modo de disco común .
3.1 - Modo de copia de seguridad en caliente de dos máquinas
En este modo de sistema, existen dos servidores con la misma capacidad de procesamiento, uno como servidor principal y otro como servidor de respaldo . Por lo general, el servidor principal está en ejecución y el servidor de respaldo siempre está monitoreando el funcionamiento del servidor principal. Una vez que el servidor principal falla, el servidor de respaldo inmediatamente asumirá el trabajo del servidor principal y se convertirá en el servidor principal del sistema, y el servidor reparado se utilizará como servidor de respaldo. //servidor maestro-esclavo

3.2 - Dos máquinas están en modo de respaldo mutuo
En el modo de copia de seguridad mutua de doble máquina, generalmente los dos servidores son servidores en línea y cada uno completa sus propias tareas, por ejemplo, uno se usa como servidor de base de datos y el otro como servidor de correo electrónico.

En el modo de copia de seguridad mutua, es mejor configurar dos discos duros en cada servidor , uno para cargar programas y aplicaciones del sistema y el otro para recibir datos de copia de seguridad enviados por otro servidor, como disco espejo del servidor. Durante el funcionamiento normal, el disco espejo está bloqueado para el usuario local, por lo que es más fácil garantizar la exactitud de los datos en el disco espejo. Si solo hay un disco duro, puede crear un disco virtual o una partición para almacenar programas y aplicaciones del sistema, así como datos de respaldo de otro servidor.
Si se detecta que un determinado servidor ha fallado a través del enlace de línea dedicada, en este momento, se utiliza el enrutador para verificar si el servidor realmente ha fallado. Si se confirma la falla, el servidor normal enviará un mensaje de difusión al cliente del servidor fallido, indicando que cambiará. Una vez que el cambio se realiza correctamente, el cliente puede continuar utilizando los servicios proporcionados por la red y acceder a los datos en el servidor sin volver a iniciar sesión. Para los clientes conectados a servidores que no tienen fallas, solo sentirán una ligera desaceleración en los servicios de red y no tendrán ningún impacto. Cuando el servidor defectuoso se repare y se vuelva a conectar a Internet, las funciones de servicio que se han migrado al servidor no defectuoso se devolverán y reanudarán el trabajo normal. // reemplazo de fallas y reparación de fallas
La ventaja de este modelo es que ambos servidores se pueden utilizar para procesar tareas, por lo que el sistema es más eficiente, y ahora este modelo se ha ampliado de dos máquinas a 4, 8, 16 o incluso más. Todas las máquinas del sistema se pueden utilizar para procesar tareas y, cuando una de ellas falla, el sistema puede designar otra máquina para que se haga cargo de su trabajo. //La forma en que usan los clusters modernos
3.3 - Modo de disco común
Para reducir la sobrecarga de copiar información, se pueden conectar varias computadoras a un sistema de disco común. El disco común está dividido en varios volúmenes. Utilice un volumen por computadora. Si una computadora falla, el sistema se reconfigura para seleccionar una máquina de reemplazo según una política de programación que sea propietaria de los volúmenes de la máquina fallida y pueda tomar el control de la computadora fallida. La ventaja de este modelo es que elimina el tiempo de copia de la información, reduciendo así la sobrecarga de la red y del servidor .
(4) Sistema de respaldo
Se debe configurar un sistema de respaldo en un sistema completo. Por un lado, debido a que el sistema de disco no es lo suficientemente grande, es imposible instalar todos los datos del sistema en el disco durante la operación, y los datos que no son necesarios pero que aún son útiles deben almacenarse en el sistema de respaldo para su preservación. . Por otro lado, para evitar fallas del sistema o infecciones de virus por errores o pérdida de datos en el sistema, también es necesario almacenar datos más importantes en el sistema de respaldo. En la actualidad, los equipos comúnmente utilizados como sistema de respaldo incluyen unidades de cinta, unidades de disco, discos duros y unidades de CD . //Es decir, algunos dispositivos persistentes se utilizan para almacenar físicamente y realizar copias de seguridad de los datos.
3. Control de coherencia de los datos
En aplicaciones prácticas, los mismos datos suelen estar contenidos en varios archivos. El llamado problema de coherencia de datos significa que se debe garantizar que los mismos datos almacenados en varios archivos sean los mismos bajo cualquier circunstancia . Por ejemplo, cuando encontramos que el precio de compra de un determinado producto es incorrecto, debemos modificar el precio del producto en una serie de documentos como diario, cuenta de pago, libro mayor y libro mayor al mismo tiempo para garantizar la coherencia de los datos. Sin embargo, si el sistema falla repentinamente cuando la modificación está en el medio, causará inconsistencia en los datos en cada cuenta y luego hará que varias cuentas sean inconsistentes. Para garantizar la coherencia de los datos, en los sistemas operativos modernos se configura un software que puede garantizar la coherencia de los datos .
(1) Asuntos
1.1 - Definición de transacción
Cuando una transacción modifica un lote de datos, los completa todos y reemplaza los datos originales con los datos modificados, o no modifica ninguno de ellos . Esta característica de las operaciones transaccionales es la atomicidad de las transacciones (Atomic).
No todas las series de operaciones realizadas como una sola unidad de programa pueden convertirse en una transacción, es decir, si se define como una transacción, se deben satisfacer cuatro atributos al mismo tiempo, a saber, el atributo de transacción ACID. Además de la atomicidad mencionada anteriormente, los atributos que deben tener las transacciones también son:
- Consistente , es decir, cuando se completa la transacción, todos los datos deben mantenerse en un estado consistente
- Aislado , es decir, la modificación de datos por una transacción debe estar aislada de cualquier otra transacción concurrente. En otras palabras, el estado de los datos cuando una transacción ve los datos, o el estado antes de que otra transacción concurrente modifique su estado, o el estado después de que otra transacción lo modifica, y no ningún dato de estado intermedio
- Persistencia (Durable) , es decir, una vez completada la transacción, su impacto en el sistema es permanente.
1.2 - Registro de transacciones
Para realizar la modificación atómica de una transacción, generalmente se implementa mediante una estructura de datos llamada registro de transacción . Estas estructuras de datos se colocan en una memoria muy confiable y se utilizan para registrar toda la información sobre la modificación de elementos de datos cuando se ejecuta la transacción, por lo que también se denominan registros en ejecución (Registro) . Este registro incluye los siguientes campos: //Esta es una ideología rectora muy general, muy importante
- Nombre de la transacción: un nombre único utilizado para identificar la transacción.
- Nombre del elemento de datos: es el nombre único del elemento de datos modificado.
- Valor antiguo: el valor del elemento de datos antes de la modificación.
- Nuevo Valor: El valor que tendrá el dato después de la modificación.
Cada registro en la tabla de registros de transacciones describe operaciones de transacción importantes en la operación de transacción, como modificar operación, iniciar transacción, confirmar transacción o transacción fallida, etc. // registrar transacción
1.3 - Algoritmo de recuperación
Dado que un conjunto de datos modificados por la transacción T y sus valores antes y después de la modificación se pueden encontrar en la tabla de registros de transacciones, el sistema que utiliza la tabla de registros de transacciones puede manejar cualquier falla sin que la falla se almacene en el no- memoria volátil pérdida de información. El algoritmo de recuperación puede aprovechar los dos procesos siguientes: //El método general de la base de datos
- deshacer(T) . Este proceso restaura todos los datos modificados por la transacción T al valor anterior a la modificación.
- rehacer(T) . Este procedimiento establece todos los datos modificados por la transacción T en nuevos valores.
Si el sistema falla, el sistema debería limpiar las transacciones anteriores. Al buscar la tabla de registros de transacciones, las transacciones que no se han limpiado se pueden dividir en dos categorías. //deshacer y rehacer registros
Un tipo es una transacción en la que se han completado todo tipo de operaciones contenidas en ella. La base para determinar este tipo de transacción es que la tabla de registros de transacciones contiene registros T (inicio) y registros T (compromiso). En este momento, el sistema utiliza el proceso de rehacer (T) para convertir todos los conjuntos de datos modificados al nuevo. valor.
El otro tipo es una transacción en la que no se completan todas las operaciones. Para la transacción T, si solo hay un registro T (inicio) pero ningún registro T (compromiso) en la tabla de Registro, entonces este T pertenece a este tipo de transacción. En este punto, el sistema utiliza el proceso de deshacer (T) para restaurar todos los datos modificados al valor anterior a la modificación.
(2) Punto de control
El papel de los puntos de control
Dado que puede haber muchas transacciones ejecutadas simultáneamente en el sistema, habrá muchos registros de ejecución de transacciones en la tabla de registros de transacciones. A medida que pase el tiempo, se registrarán más y más datos. Por lo tanto, una vez que el sistema falla, lleva mucho tiempo limpiar los registros en la tabla de registros de transacciones.
El objetivo principal de introducir puntos de control es hacer que la limpieza de los registros de transacciones en la tabla de registros de transacciones sea regular , es decir, realizar el siguiente trabajo a intervalos regulares:
- El primero es enviar todos los registros de la tabla de registros de transacciones actuales que residen en la memoria volátil (memoria) a la memoria estable.
- El segundo es enviar todos los datos modificados que residen en la memoria volátil a la memoria estable.
- Luego, envíe los registros de puntos de control en la tabla de registros de transacciones al almacenamiento estable.
- Finalmente, cada vez que aparece un registro (punto de control), el sistema realiza una operación de recuperación , es decir, la función de recuperación se realiza mediante el proceso de rehacer y deshacer.
Si una transacción T se confirma (se compromete) antes del punto de control , aparecerá un registro T (compromiso) antes del registro del punto de control en la tabla de registros de transacciones. En este caso, todos los datos modificados por T se escribieron en un almacenamiento estable antes del punto de control o se escribieron en un almacenamiento estable como parte del propio registro del punto de control. Por lo tanto, cuando el sistema falle en el futuro, no es necesario realizar la operación de rehacer. //Guardar los datos de la transacción confirmada por adelantado
Después de la introducción de puntos de control, la sobrecarga del procesamiento de recuperación se puede reducir considerablemente . Porque después de que ocurre una falla, no es necesario procesar todos los registros de transacciones en la tabla de registros de transacciones, solo es necesario procesar los registros de transacciones después del último punto de control.
Por lo tanto, la rutina de recuperación primero busca la tabla de registro de transacciones para determinar la última transacción T que comenzó a ejecutarse antes del punto de control más reciente. Después de encontrar dicha transacción, vuelva a buscar en la tabla de registros de transacciones, podrá encontrar el primer registro de punto de control, la rutina de recuperación volverá a buscar los registros de cada transacción desde el punto de control y utilizará el proceso de rehacer y deshacer para procesarlos. con. //Procesar datos en segmentos
(3) control de concurrencia
Debido a la naturaleza atómica de las transacciones, la ejecución de cada transacción debe realizarse en un orden determinado. Solo después de ejecutar una transacción se permite la ejecución de otra, es decir, la modificación de los elementos de datos por cada transacción es mutuamente excluyente . . La gente llama a esta característica secuencialidad, y la tecnología utilizada para lograr la secuencialidad transaccional se llama control de concurrencia. //Las transacciones con los mismos datos necesitan exclusión mutua
Técnicas de control de concurrencia comúnmente utilizadas en bases de datos: bloqueos de exclusión mutua y bloqueos compartidos . //es decir, bloqueo de lectura-escritura
(4) Problema de coherencia de datos de datos duplicados
Para garantizar la seguridad de los datos, el método más común es copiar archivos clave o estructuras de datos en varias copias y almacenarlas en diferentes lugares. Cuando el archivo principal (estructura de datos) falla, hay archivos de respaldo (estructura de datos) que se pueden utilizado, ya que provocará la pérdida de datos y no afectará el funcionamiento del sistema. Obviamente, los datos en el archivo principal (estructura de datos) deben ser consistentes con los datos correspondientes en cada archivo de respaldo . Además, algunas estructuras de datos (como la tabla de bloques de disco libres) se modifican constantemente durante el funcionamiento del sistema, por lo que también se debe garantizar la coherencia de los datos en la misma estructura de datos en diferentes lugares. //El problema más común en el cluster
// Para este problema, los sistemas distribuidos tienen soluciones y algoritmos correspondientes, que no se describirán en detalle aquí, si está interesado, puede prestar atención a los artículos siguientes.