El caché puede acelerar efectivamente la velocidad de lectura y escritura de las aplicaciones y también puede reducir la carga de back-end, lo cual es muy importante para el desarrollo de aplicaciones diarias. A continuación se presentarán las habilidades de uso de caché y las soluciones de diseño, incluido el siguiente contenido: análisis de costos y beneficios de caché, selección de estrategias de actualización de caché y escenarios de uso, método de control de granularidad de caché, optimización de problemas de penetración, optimización de problemas de pozo sin fondo, optimización de problemas de avalancha, tecla de acceso rápido Optimización de reconstrucción.
1. Análisis de beneficios y costos del almacenamiento en caché
El lado izquierdo de la figura siguiente muestra la arquitectura del cliente que llama directamente a la capa de almacenamiento, y el lado derecho muestra una arquitectura típica de capa de caché + capa de almacenamiento.
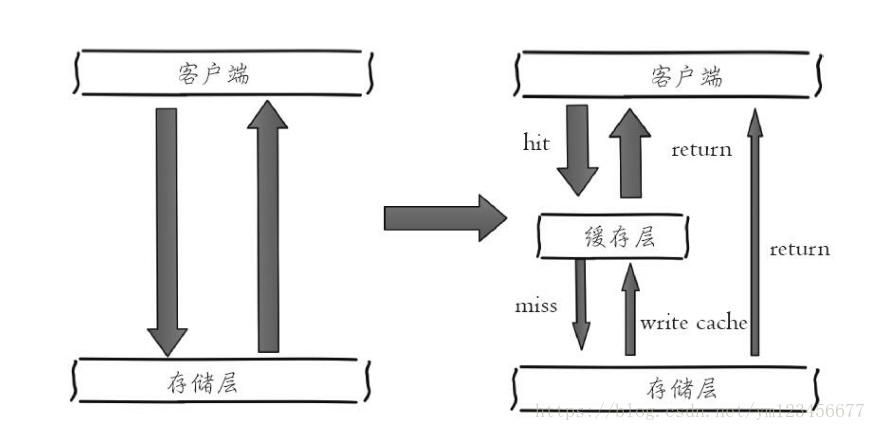
Analicemos los beneficios y costos que genera agregar el caché.
ingreso:
① Lectura y escritura aceleradas: debido a que el caché suele estar lleno y la capa de almacenamiento generalmente tiene un rendimiento de lectura y escritura insuficiente (como MySQL), el uso del caché puede acelerar efectivamente la lectura y escritura y optimizar la experiencia del usuario.
② Reduzca la carga del back-end: ayude al back-end a reducir las visitas y los cálculos complejos (como declaraciones SQL muy complejas), lo que reduce en gran medida la carga del back-end.
costo:
① Inconsistencia de datos: los datos en la capa de caché y la capa de almacenamiento tienen inconsistencias en una determinada ventana de tiempo, y la ventana de tiempo está relacionada con la estrategia de actualización.
② Costo de mantenimiento del código: después de agregar el caché, la lógica de la capa de caché y la capa de almacenamiento deben procesarse al mismo tiempo, lo que aumenta el costo de mantenimiento del código para los desarrolladores.
③ Costos de operación y mantenimiento: tome Redis Cluster como ejemplo, después de unirse, los costos de operación y mantenimiento aumentarán virtualmente.
Los escenarios de uso del almacenamiento en caché incluyen básicamente los dos tipos siguientes:
① Cálculos complicados y de alto costo: tomando MySQL como ejemplo, algunas operaciones o cálculos complejos (como una gran cantidad de operaciones de unión de tablas, algunos cálculos grupales), si no se agrega caché, no solo no pueden cumplir con la alta concurrencia, sino también trae enormes problemas a MySQL.
② Acelerar la respuesta a la solicitud: incluso si consultar un solo dato de back-end es lo suficientemente rápido (por ejemplo select * from table where id = ?), aún se puede usar el caché. Tomando Redis como ejemplo, se pueden completar decenas de miles de lecturas y escrituras por segundo, y las operaciones por lotes proporcionadas pueden optimizar la respuesta de toda la cadena de IO.
2. Estrategia de actualización de caché
Los datos en el caché serán inconsistentes con los datos reales en la fuente de datos durante un período de tiempo, y es necesario utilizar algunas estrategias para la actualización. A continuación se presentarán varias estrategias principales de actualización del caché.
① Eliminación del algoritmo LRU/LFU/FIFO :
El algoritmo de selección se utiliza generalmente para seleccionar datos existentes cuando el uso de la caché excede el valor máximo preestablecido. Por ejemplo, Redis utiliza la configuración maxmemory-policy como estrategia de eliminación de datos después del valor máximo de memoria.
② Eliminación de horas extras :
Al establecer un tiempo de vencimiento para los datos almacenados en caché, se eliminan automáticamente después del tiempo de vencimiento, como el comando de vencimiento proporcionado por Redis. Si la empresa puede tolerar la inconsistencia entre los datos de la capa de caché y los datos de la capa de almacenamiento durante un período de tiempo, puede establecer un tiempo de vencimiento para ello. Una vez que los datos caduquen, obtenga los datos de la fuente de datos real, vuelva a colocarlos en el caché y establezca el tiempo de vencimiento. Por ejemplo, la información descriptiva de un vídeo puede tolerar la inconsistencia de los datos en unos pocos minutos, pero cuando se trata de transacciones, las consecuencias se pueden imaginar.
③ Actualización activa :
El lado de la aplicación tiene altos requisitos de coherencia de los datos y necesita actualizar los datos almacenados en caché inmediatamente después de que se actualizan los datos reales. Por ejemplo, se puede utilizar un sistema de mensajes u otros medios para notificar actualizaciones de la memoria caché.
Comparación de tres estrategias de actualización comunes:

Hay dos sugerencias:
① Para servicios de baja consistencia, se recomienda configurar la memoria máxima y eliminar estrategias.
② Los servicios de alta coherencia pueden utilizar la eliminación del tiempo de espera y la actualización activa en combinación, de modo que incluso si hay un problema con la actualización activa, los datos sucios se pueden eliminar después del tiempo de vencimiento de los datos.
3. Control de granularidad de caché
El problema de la granularidad de la caché es un problema que se pasa fácilmente por alto. Si se usa incorrectamente, puede causar una gran pérdida de espacio inútil, desperdicio de ancho de banda de la red y poca versatilidad del código. Es necesario combinar de manera integral la versatilidad de los datos y el espacio. relación de ocupación y mantenibilidad del código. Haga un compromiso en tres puntos.
El caché se usa más comúnmente para la selección, Redis se usa para la capa de caché y MySQL se usa para la capa de almacenamiento.

4. Optimización de la penetración
La penetración de la caché se refiere a consultar datos que no existen en absoluto, y ni la capa de caché ni la capa de almacenamiento se verán afectadas. Por lo general, en aras de la tolerancia a fallas, si los datos no se pueden encontrar en la capa de almacenamiento, no escribirse en la capa de caché.
Por lo general, el número total de llamadas, el número de visitas en la capa de caché y el número de visitas en la capa de almacenamiento se pueden contar por separado en el programa. Si encuentra una gran cantidad de visitas vacías en la capa de almacenamiento, es posible que haya ser un problema de penetración de caché. Hay dos razones básicas para la penetración de la caché. En primer lugar, hay un problema con su propio código o datos comerciales y, en segundo lugar, algunos ataques maliciosos, rastreadores, etc., provocan una gran cantidad de visitas vacías. Veamos cómo resolver el problema de penetración de caché.
① Caché de objetos vacíos:
Como se muestra en la figura siguiente, cuando la capa de almacenamiento falla en el segundo paso, el objeto vacío aún se mantiene en la capa de caché y los datos se obtendrán del caché cuando se acceda a los datos más adelante, protegiendo así los datos de back-end. fuente.

Hay dos problemas con el almacenamiento en caché de objetos vacíos: primero, los valores vacíos se almacenan en caché, lo que significa que se almacenan más claves en la capa de caché y se requiere más espacio de memoria (si es un ataque, el problema es más grave). un método más efectivo es establecer un tiempo de caducidad corto para este tipo de datos y dejar que se eliminen automáticamente. En segundo lugar, los datos en la capa de caché y la capa de almacenamiento serán inconsistentes durante un período de tiempo, lo que puede tener un cierto impacto en el negocio. Por ejemplo, el tiempo de vencimiento se establece en 5 minutos. Si los datos se agregan a la capa de almacenamiento en este momento, habrá inconsistencias entre la capa de caché y los datos de la capa de almacenamiento durante este período. En este momento, el sistema de mensajes o Se pueden utilizar otros métodos para borrar el espacio vacío en la capa de caché.
② Intercepción del filtro Bloom:
Como se muestra en la figura siguiente, antes de acceder a la capa de caché y a la capa de almacenamiento, la clave existente se guarda de antemano con un filtro Bloom para realizar la primera capa de interceptación. Por ejemplo: un sistema de recomendación tiene 400 millones de ID de usuario, cada hora el ingeniero de algoritmos calculará los datos recomendados en función del comportamiento histórico anterior de cada usuario y los colocará en la capa de almacenamiento, pero el último usuario no tiene comportamiento histórico y caché. se producirá la penetración. Para ello, todos los usuarios que recomienden datos pueden incluirse en los filtros Bloom. Si el filtro Bloom cree que la identificación del usuario no existe, no se accederá a la capa de almacenamiento, lo que protege la capa de almacenamiento hasta cierto punto.

Comparación de esquema de filtro Bloom y objeto nulo de caché

Otro: una breve descripción del filtro Bloom:
Si desea juzgar si un elemento está en una colección, la idea general es guardar todos los elementos de la colección y luego determinarlo mediante comparación. La lista vinculada, el árbol, la tabla hash (también llamada tabla hash, tabla hash) y otras estructuras de datos son todas de esta manera. Pero a medida que aumenta el número de elementos de la colección, necesitamos cada vez más espacio de almacenamiento. Al mismo tiempo, la velocidad de recuperación es cada vez más lenta.
Bloom Filter es una estructura de datos aleatoria con alta eficiencia espacial. El filtro Bloom puede considerarse como una extensión del mapa de bits. Su principio es:
Cuando se agrega un elemento al conjunto, las funciones K Hash se utilizan para asignar este elemento a K puntos en una matriz de bits (matriz de bits) y establecerlos en 1. Al recuperar, solo necesitamos ver si estos puntos son todos 1 para saber (aproximadamente) si está en la colección:
Si alguno de estos puntos tiene 0, el elemento recuperado no debe estar allí; si todos son 1, es probable que el elemento recuperado esté allí.
5. Optimización del pozo sin fondo
Para satisfacer las necesidades comerciales, se puede agregar una gran cantidad de nuevos nodos de caché, pero se descubre que el rendimiento no ha mejorado sino que ha disminuido. Para explicarlo en una oración simple, más nodos no significan un mayor rendimiento. El llamado "pozo sin fondo" significa que más inversión no significa necesariamente más producción. Sin embargo, la distribución es inevitable, porque la cantidad de visitas y datos está aumentando y un nodo no puede resistirlo en absoluto, por lo que cómo realizar operaciones por lotes de manera eficiente en el caché distribuido es un punto difícil.
Análisis del problema del pozo sin fondo:
① Una operación por lotes del cliente implicará múltiples operaciones de red, lo que significa que la operación por lotes llevará más tiempo a medida que aumenta el número de nodos.
② El aumento en el número de conexiones de red también tendrá un cierto impacto en el rendimiento de los nodos.
¿Cómo optimizar las operaciones por lotes en condiciones distribuidas? Echemos un vistazo a las ideas comunes de optimización de IO:
-
Optimización del comando en sí, como optimización de declaraciones SQL, etc.
-
Reducir el número de comunicaciones de la red.
-
Reducir los costos de acceso, por ejemplo, los clientes usan conexiones/grupos de conexiones persistentes, NIO, etc.
Aquí asumimos que los comandos y las conexiones del cliente son óptimos y nos centramos en reducir la cantidad de operaciones de red. A continuación combinaremos algunas características de Redis Cluster para ilustrar los cuatro métodos de operación por lotes distribuidos.
① Comando en serie : dado que n claves se distribuyen uniformemente en cada nodo de Redis Cluster, no se pueden obtener al mismo tiempo usando el comando mget, por lo que, en términos generales, la forma más fácil de obtener los valores de n claves es ejecutarlas una vez. Por uno n comandos de obtención, este tipo de complejidad del tiempo de operación es alta, su tiempo de operación = n veces el tiempo de la red + n veces el tiempo del comando, el número de veces de la red es n. Obviamente esta solución no es óptima, pero es relativamente sencilla de implementar.
② Serial IO : Redis Cluster utiliza el algoritmo CRC16 para calcular el valor hash y luego toma el resto de 16383 para calcular el valor de la ranura. Al mismo tiempo, el cliente inteligente guardará la relación correspondiente entre la ranura y el nodo. Estos dos datos, la clave que pertenece al mismo nodo se archiva para obtener la sublista de claves de cada nodo, y luego se realiza la operación mget o Pipeline en cada nodo. Su tiempo de operación = tiempo de red del nodo + n tiempo de comando, el tiempo de red es el número de nodos Todo el proceso se muestra en la siguiente figura, obviamente esta solución es mucho mejor que la primera, pero si hay demasiados nodos, todavía hay ciertos problemas de rendimiento.

③ IO paralela : esta solución consiste en cambiar el último paso de la solución 2 a ejecución de subprocesos múltiples. Aunque el número de tiempos de red sigue siendo el número de nodos, debido al uso de tiempo de red de subprocesos múltiples, esta solución O(1)aumentará La complejidad de la programación.

④ implementación de hash_tag : la función hash_tag de Redis Cluster, que puede forzar la asignación de varias claves a un nodo, y su tiempo de operación = 1 tiempo de red + n tiempo de comando.
Comparación de cuatro soluciones de operación por lotes

6. Optimización de avalanchas
Avalancha de caché: dado que la capa de caché transporta una gran cantidad de solicitudes, la capa de almacenamiento está protegida de manera efectiva. Sin embargo, si la capa de caché no puede proporcionar servicios por algún motivo, todas las solicitudes llegarán a la capa de almacenamiento y la cantidad de llamadas al almacenamiento La capa aumentará drásticamente, lo que provocará que las capas de almacenamiento también sufran un tiempo de inactividad en cascada.
Para prevenir y solucionar el problema de la avalancha de caché, podemos partir de los siguientes tres aspectos:
① Garantizar una alta disponibilidad de los servicios de la capa de caché:
Si la capa de caché está diseñada para tener alta disponibilidad, incluso si los nodos individuales, las máquinas individuales o incluso las salas de computadoras están inactivos, aún se pueden proporcionar servicios. Por ejemplo, Redis Sentinel y Redis Cluster introducidos anteriormente han logrado una alta disponibilidad.
② Confíe en componentes de aislamiento para limitar y degradar el tráfico de backend :
En proyectos reales, necesitamos aislar recursos importantes (como Redis, MySQL, HBase, interfaces externas) para que cada recurso pueda ejecutarse de forma independiente en su propio grupo de subprocesos, incluso si hay un problema con recursos individuales, otros servicios Sin efecto . Sin embargo, cómo administrar el grupo de subprocesos, por ejemplo, cómo cerrar el grupo de recursos, abrir el grupo de recursos y administrar el umbral del grupo de recursos, sigue siendo bastante complicado.
③ Perforar por adelantado:
Antes de que el proyecto entre en línea, después de que la capa de almacenamiento en caché caiga, se ensayarán las condiciones de carga de la aplicación y el back-end y los posibles problemas, y se realizarán algunas configuraciones previas al plan sobre esta base.
7. Optimización de la reconstrucción de claves del punto de acceso
Los desarrolladores utilizan la estrategia de "almacenamiento en caché + tiempo de vencimiento" para acelerar la lectura y escritura de datos y garantizar actualizaciones periódicas de los datos. Este modo básicamente puede satisfacer la mayoría de las necesidades. Sin embargo, si ocurren dos problemas al mismo tiempo, puede causar daños fatales a la aplicación:
-
La clave actual es una tecla de acceso rápido (como una noticia de entretenimiento popular) y la cantidad de concurrencia es muy grande.
-
La reconstrucción del caché no se puede completar en poco tiempo, puede ser un cálculo complejo, como SQL complejo, múltiples IO, múltiples dependencias, etc. En el momento en que el caché deja de ser válido, hay una gran cantidad de subprocesos para reconstruir el caché, lo que aumenta la carga en el backend e incluso puede provocar que la aplicación falle.
No es muy complicado resolver este problema, pero no puede traer más problemas al sistema para resolverlo, por lo que es necesario formular los siguientes objetivos:
-
Reducir la cantidad de reconstrucciones de caché;
-
Los datos son lo más consistentes posible;
-
menor peligro potencial.
① Bloqueo mutex :
Este método solo permite que un subproceso reconstruya el caché, y otros subprocesos esperan a que el subproceso que reconstruye el caché termine de ejecutarse y luego obtienen datos del caché nuevamente. Todo el proceso se muestra en la figura.

El siguiente código utiliza el comando setnx de Redis para lograr las funciones anteriores:

1) Obtenga datos de Redis, si el valor no está vacío, devuelva el valor directamente; de lo contrario, realice los siguientes pasos 2.1) y 2.2).
2.1) Si el resultado de set(nx y ex) es verdadero, significa que ningún otro subproceso reconstruye el caché en este momento, entonces el subproceso actual ejecuta la lógica de construcción del caché.
2.2) Si el resultado de set (nx y ex) es falso, significa que otros subprocesos ya están realizando el trabajo de construir el caché en este momento, entonces el subproceso actual descansará durante un tiempo específico (por ejemplo, aquí 50 milisegundos). , dependiendo de la velocidad de construcción del caché), Vuelva a ejecutar la función hasta que se obtengan los datos.
② nunca caduca:
"Nunca caduca" tiene dos significados:
-
Desde la perspectiva del caché, de hecho no hay un tiempo de vencimiento establecido, por lo que no habrá problemas causados por el vencimiento de la tecla de acceso rápido, es decir, el "físico" no caduca.
-
Desde una perspectiva funcional, se establece un tiempo de vencimiento lógico para cada valor. Cuando se excede el tiempo de vencimiento lógico, se utilizará un hilo separado para construir el caché.
Desde la perspectiva del combate real, este método elimina efectivamente los problemas causados por las teclas de acceso rápido, pero el único inconveniente es que pueden ocurrir inconsistencias de datos durante la reconstrucción del caché, lo que depende de si el lado de la aplicación tolera esta inconsistencia.

Dos soluciones de teclas de acceso rápido:

Bueno, este es el final de este artículo, bienvenidos amigos a dejar un mensaje en segundo plano, díganme qué conocimientos de Redis han utilizado en el proyecto.