Four solutions for distributed sessions
1. Cookie and session
Both cookie and session are session methods used to track user identity information.
The data stored in the cookie is stored on the local client, which is easy for users to obtain, but the security is not high and the stored data is small.
The data stored in the session is stored in the server, which is not easy for users to obtain, has high security, and stores large data.
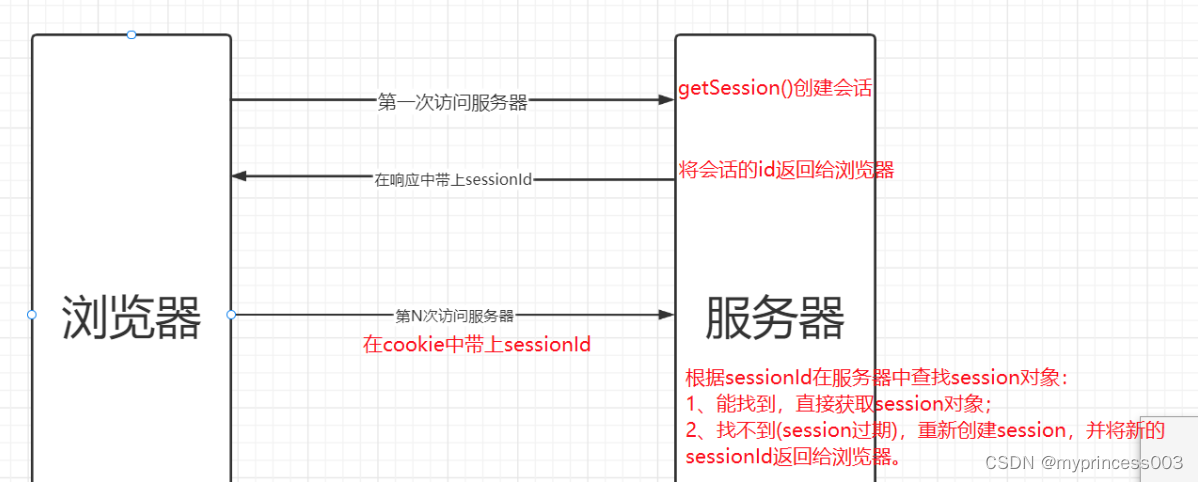
Usually, the server saves the user information in the server through the session, and then returns the sessionId to the client cookie. When the client makes the next request, it can bring the sessionId in the cookie, and the server can pass the sessionId. Find the corresponding session object in the memory and get the information of the current user.
The process can be shown as follows:
2. Background introduction
In a traditional project, in a single-server scenario, the session object of the server is stored in the local memory, and each request from the browser will hit the server. Therefore, as long as the session has not expired, it must be able to obtain to the session object.
But in a multi-server scenario, or a microservice project, a project has multiple instances. Multiple requests from the browser may be sent to different servers after passing through the nginx reverse proxy. The scenario is as follows:
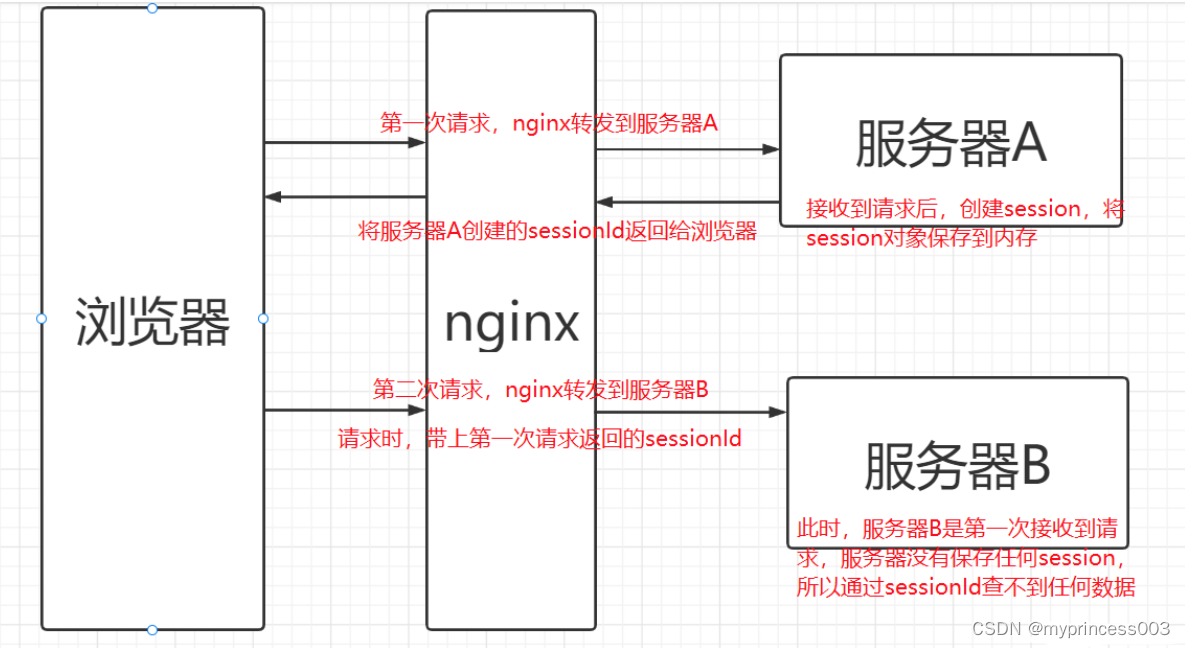
3. Solution
3.1, session replication
session synchronization, allowing servers under the cluster to perform session synchronization, a traditional server cluster session management mechanism, often used in cluster environments with few servers.
Under the cluster, the session data of the servers performing session synchronization are the same, and if any server hangs up, the user's session data will not be lost.
However, session synchronization is to asynchronously synchronize sessions through broadcasting, and data transmission will be performed through the network. When there are more and more servers, session synchronization will occupy a large amount of bandwidth, and the session data that each server needs to store is also increasing, occupying a large amount of server memory.
Therefore, the session synchronization strategy is generally applicable to scenarios with few cluster servers.
3.2. Client-side storage (not recommended)
directly store the session data in the cookie of the browser. When the browser initiates a request, the session data is sent to the client through the cookie. Because cookies are insecure and easy to obtain, they are usually used to store some insensitive information.
However, since cookies are not safe, and each http request will carry the complete user information stored in the cookie, it will increase the network transmission overhead, and the cookie has a storage size limit. So basically don't use this method.
3.3. Hash Consistency
Modify the load balancing configuration of nginx, set it to ip-hash strategy, bind the client and server, so that requests from the same ip are all forwarded to the same server.
This solution is simple to configure, but after a server hangs up, all session information on the server will be lost, and the client bound to the server must log in again. And during horizontal expansion, the client ip will be hashed again, and some ip will be remapped to the server.
# 配置负载均衡服务器组名称和地址
upstream web_server {
ip_hash;
server 192.168.12.36;
server 192.168.12.37;
server 192.168.12.38;
}
# nginx路由配置
server {
listen 8080;
server_name localhost;
location / {
proxy_pass http://web_server;
}
}
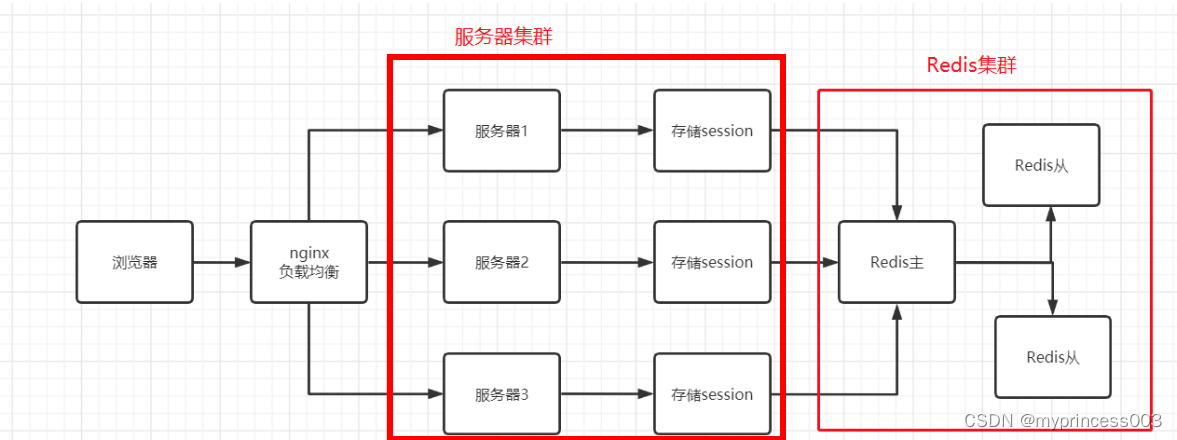
3.4. Redis-based distributed session (recommended)
stores the sessions of all servers under the cluster in the redis cluster.
Directly use the Spring Session encapsulated by Spring, introduce related dependencies, and be easy to use. Session data is stored in redis, seamlessly connected, and has no security risks; and Redis can also be used as a master-slave cluster architecture for easy management. The only disadvantage is that the server needs to do a network interaction with Redis, which has a little more network overhead.
3.4.1、引入相关依赖
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
3.4.2. Java configuration
@Configuration
@EnableRedisHttpSession
public class Config {
@Bean
public LettuceConnectionFactory connectionFactory() {
return new LettuceConnectionFactory();
}
}
3.4.3, Redis configuration
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.password=123456
spring.redis.database=0