Dieser Artikel beginnt mit den grundlegenden Konzepten und der Architektur von BERT, erläutert ausführlich seinen Vortrainings- und Feinabstimmungsmechanismus und zeigt anhand von Python- und PyTorch-Codebeispielen, wie dieses Modell in praktischen Anwendungen verwendet werden kann. Wir untersuchen die Kernfunktionen von BERT, einschließlich seines leistungsstarken Aufmerksamkeitsmechanismus und der Unterschiede zu anderen Transformer-Architekturen.
Folgen Sie TechLead und teilen Sie umfassendes Wissen über KI. Der Autor verfügt über mehr als 10 Jahre Erfahrung in den Bereichen Internet-Service-Architektur, KI-Produktentwicklung und Teammanagement. Er ist ein Fudan-Meister von Tongji, Mitglied des Fudan Robot Intelligence Laboratory, ein von Alibaba Cloud zertifizierter leitender Architekt und ein Projektmanagement-Experte , und erwirtschaftet Hunderte Millionen Umsätze in der KI-Produktentwicklung. Auftraggeber.
I. Einleitung
Im Zeitalter der Informationsexplosion ist die Verarbeitung natürlicher Sprache (NLP) zu einer äußerst wichtigen Disziplin geworden. Es wird nicht nur in Suchmaschinen und Empfehlungssystemen verwendet, sondern auch häufig in der Spracherkennung, Stimmungsanalyse und anderen Bereichen. Allerdings war das Verstehen und Generieren natürlicher Sprache schon immer eine große Herausforderung für maschinelles Lernen. Als nächstes werden wir uns eingehend mit einigen der traditionellen Ansätze zur Verarbeitung natürlicher Sprache und den verschiedenen Herausforderungen befassen, denen sie beim Umgang mit Sprachmodellen gegenüberstehen.
Ein Überblick über traditionelle NLP-Techniken
Regeln und Mustervergleich
Frühe NLP-Systeme basierten hauptsächlich auf Regeln und Mustervergleich. Diese Methoden sind gut interpretierbar, es mangelt ihnen jedoch an Flexibilität. Beispielsweise werden reguläre Ausdrücke und kontextfreie Grammatiken (CFGs) zum Textabgleich und zum Parsen von Satzstrukturen verwendet.
statistische Methoden
Mit der Verbesserung der Rechenleistung sind statistisch basierte Methoden wie Hidden-Markov-Modelle (HMM) und Maximum-Entropie-Modelle populär geworden. Diese Modelle werden mit riesigen Datenmengen trainiert, um Wortarten, syntaktische Strukturen und mehr zu erkennen.
Worteinbettungen und verteilte Darstellungen
Worteinbettungsmethoden wie Word2Vec und GloVe markieren die Transformation von NLP von der regelbasierten zur lernbasierten Vektordarstellung. Diese Modelle erfassen die semantische Beziehung zwischen Wörtern durch verteilte Darstellungen, können jedoch die Wortreihenfolge und Kontextinformationen nicht gut verarbeiten.
Recurrent Neural Network (RNN) und Long Short Term Memory Network (LSTM)
RNN- und LSTM-Modelle bieten leistungsfähigere Modellierungsfunktionen für Sequenzdaten. Insbesondere LSTM löst das Problem verschwindender und explodierender Gradienten durch seinen internen Gate-Mechanismus und ermöglicht es dem Modell, längere Abhängigkeiten zu erfassen.
Transformatorarchitektur
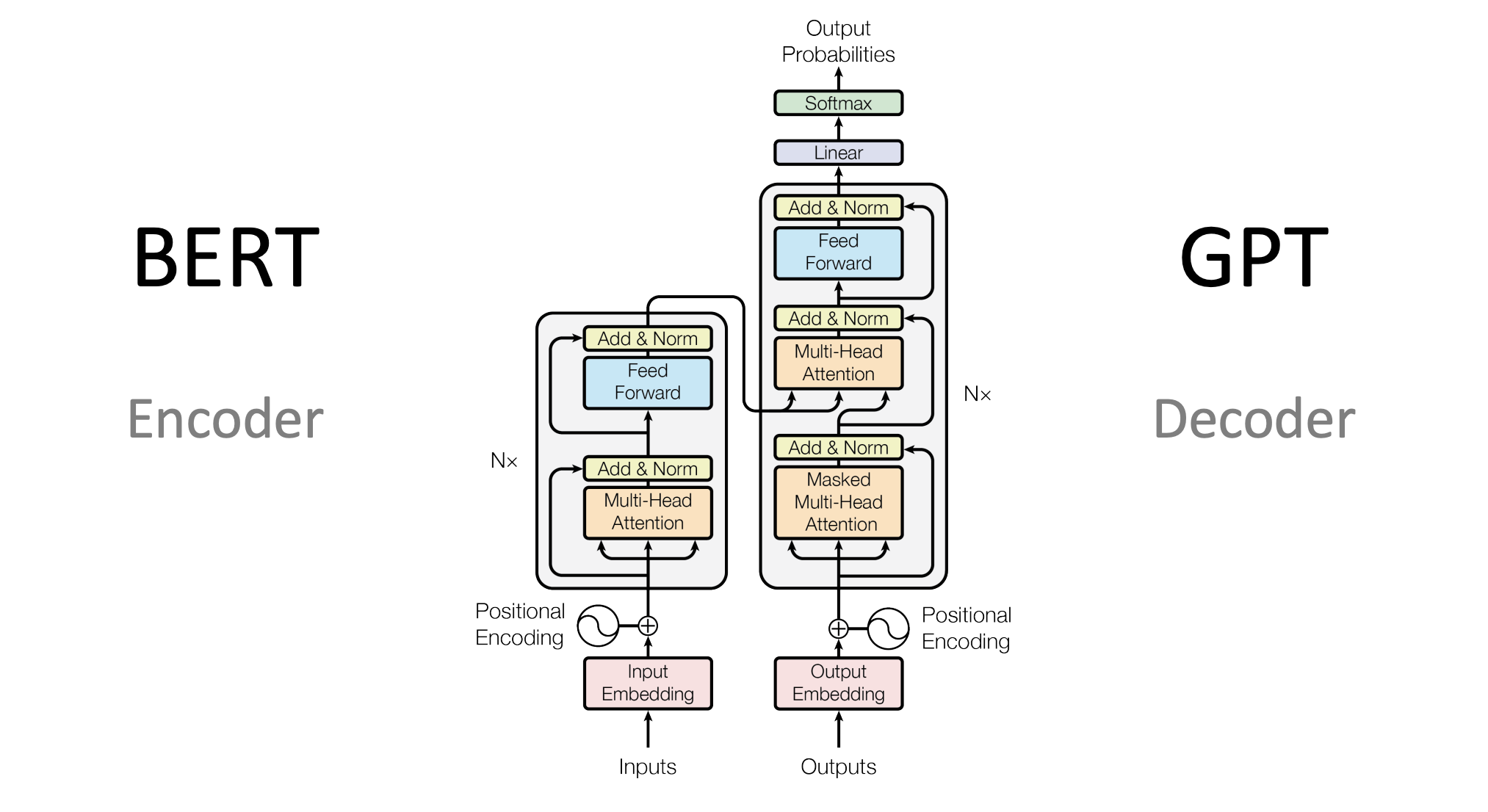
Das Transformer-Modell ändert das Muster der Sequenzmodellierung, verarbeitet Fernabhängigkeiten effektiv durch den Selbstaufmerksamkeitsmechanismus (Selbstaufmerksamkeit) und erreicht einen hohen Grad an Parallelisierung. Aber trotz dieser Fortschritte bleiben viele Herausforderungen und Mängel bestehen.
In diesem Zusammenhang entstand das BERT-Modell (Bidirektionale Encoder-Repräsentationen von Transformers), das eine Vielzahl fortschrittlicher Technologien kombiniert und bei mehreren NLP-Aufgaben bemerkenswerte Ergebnisse erzielt hat.
2. Was ist BERT?
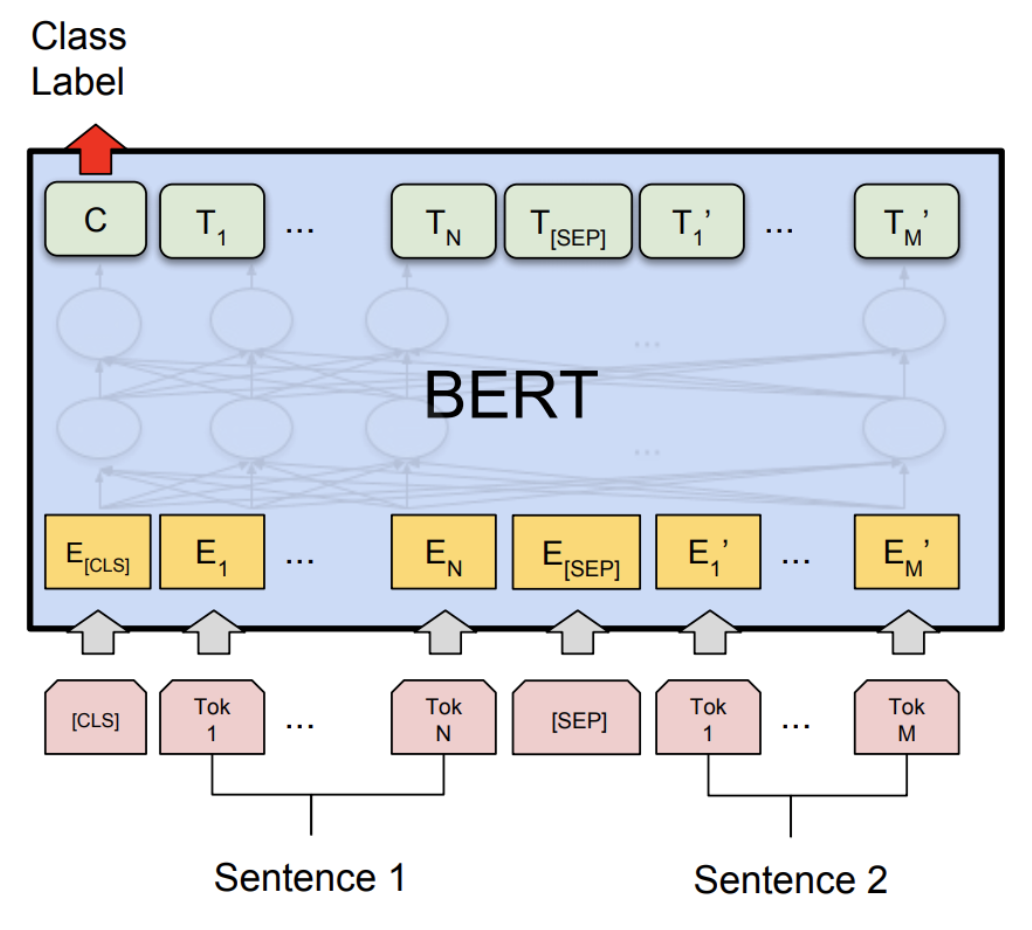
Architektur von BERT
Das BERT-Modell (Bidirektionale Encoder-Repräsentationen von Transformers) basiert auf der Transformer-Architektur und ermöglicht durch Vortraining und Feinabstimmung eine tiefgreifende Darstellung natürlicher Sprache. Bevor wir die verschiedenen Dimensionen und Details der BERT-Architektur vorstellen, verstehen wir zunächst ihr Gesamtkonzept.
Gesamtkonzept
Das Designkonzept von BERT basiert im Wesentlichen auf folgenden Punkten:
-
Bidirektional : Im Gegensatz zu herkömmlichen Einweg-Sprachmodellen kann BERT gleichzeitig den Kontext von Wörtern berücksichtigen.
-
Allgemeines : Durch Vortraining und Feinabstimmung kann BERT auf eine Vielzahl von Aufgaben zur Verarbeitung natürlicher Sprache angewendet werden.
-
Tiefe : BERT verfügt normalerweise über mehrere Schichten (normalerweise 12 oder mehr), wodurch das Modell komplexe semantische und syntaktische Informationen erfassen kann.
architektonische Komponenten
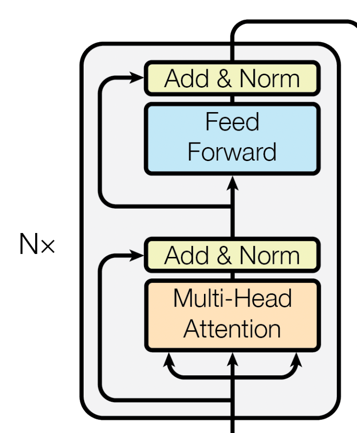
Encoder-Ebene
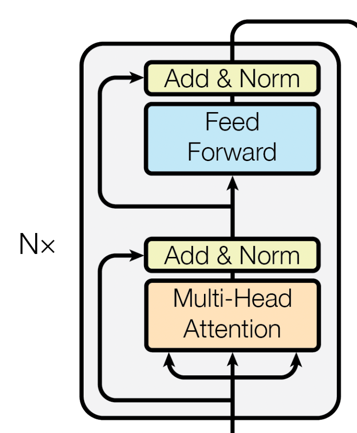
BERT basiert vollständig auf der Encoder-Schicht von Transformer. Jede Encoder-Schicht besteht aus zwei Hauptteilen:
-
Selbstaufmerksamkeit : Dieser Mechanismus ermöglicht es dem Modell, den Einfluss aller Wörter in der Eingabesequenz auf das aktuelle Wort zu berücksichtigen.
-
Feed-Forward-Neuronale Netzwerke : Auf der Grundlage der Selbstaufmerksamkeit führt das Feed-Forward-Neuronale Netzwerk weiterhin eine nichtlineare Transformation der Merkmale durch.
Einbettungsebene
BERT verwendet die drei Einbettungsmethoden Token Embeddings, Segment Embeddings und Position Embeddings, um die Eingabewörter und zusätzliche Informationen in festdimensionale Vektoren zu kodieren.
Kombination von Teilen
-
Jede Encoderschicht führt nacheinander Selbstaufmerksamkeits- und Feed-Forward-Berechnungen für neuronale Netzwerke durch und fügt zur Stabilisierung eine Schichtnormalisierung hinzu.
-
Alle Encoder-Ebenen sind gestapelt (Stacked), wodurch abstraktere und komplexere Funktionen Schicht für Schicht erfasst werden können.
-
Die Ausgabe der Einbettungsschicht wird als Eingabe der ersten Encoder-Schicht verwendet und dann Schicht für Schicht weitergegeben.
Architekturmerkmale
-
Parameterfreigabe : Während des Vortrainings und der Feinabstimmung werden die Parameter aller Encoder-Schichten gemeinsam genutzt.
-
Flexibilität : Aufgrund der Vielseitigkeit und Tiefe von BERT können Sie verschiedene Arten von Köpfen (Köpfe) basierend auf unterschiedlichen Aufgaben hinzufügen, z. B. Klassifizierungsköpfe oder Sequenzkennzeichnungsköpfe.
-
Hoher Rechenbedarf : BERT-Modelle haben normalerweise eine große Anzahl von Parametern (Hunderte Millionen oder mehr), sodass sie für das Training viele Rechenressourcen erfordern.
Durch ein solches Architekturdesign kann das BERT-Modell eine hervorragende Leistung bei einer Vielzahl von Aufgaben zur Verarbeitung natürlicher Sprache erzielen und gleichzeitig die Flexibilität und Skalierbarkeit des Modells gewährleisten.
3. Die Kernfunktionen von BERT
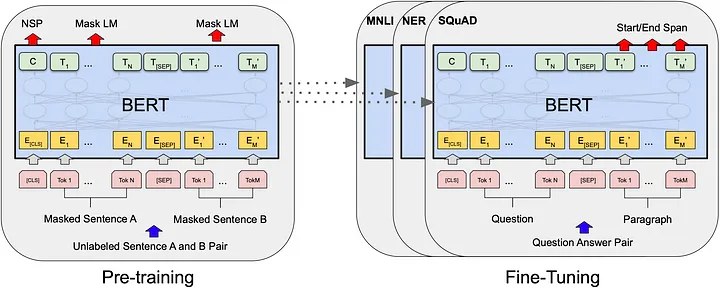
Das BERT-Modell hat nicht nur erhebliche Leistungsverbesserungen bei mehreren NLP-Aufgaben erzielt, sondern, was noch wichtiger ist, es hat eine Reihe innovativer Designs und Mechanismen in der Verarbeitung natürlicher Sprache eingeführt. Als Nächstes werden wir einige Kernfunktionen von BERT im Detail untersuchen.
Aufmerksamkeitsmechanismus
Selbstaufmerksamkeit
Selbstaufmerksamkeit ist ein sehr wichtiges Konzept im BERT-Modell. Im Gegensatz zu herkömmlichen Modellen, die bei der Verarbeitung von Sequenzdaten nur lokale oder vorgeordnete Kontextinformationen berücksichtigen können, ermöglicht der Selbstaufmerksamkeitsmechanismus dem Modell, alle Token in der Eingabesequenz zu beobachten und für jedes Token eine kontextbezogene Darstellung zu generieren.
# 自注意力机制的简单PyTorch代码示例
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, queries, mask):
N = queries.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
# Split the embedding into self.head different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = queries.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Scaled dot-product attention
attention = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
attention = attention.masked_fill(mask == 0, float("-1e20"))
attention = torch.nn.functional.softmax(attention, dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out
Mehrköpfige Aufmerksamkeit
BERT führt außerdem die Mehrkopfaufmerksamkeit (Multi-Head Attention) ein, die die Selbstaufmerksamkeit in mehrere „Köpfe“ aufteilt, wobei jeder „Kopf“ die Kontextinformationen verschiedener Teile der Sequenz lernt und die Informationen schließlich zusammenführt.
Vorschulung und Feinabstimmung
Der Erfolg des BERT-Modells ist größtenteils auf seine zweistufige Trainingsstrategie zurückzuführen: Vortraining (Pre-Training) und Feinabstimmung (Fine-Tuning). Im Folgenden werden wir die Merkmale, technischen Punkte und Aspekte, die Aufmerksamkeit bei diesen beiden Prozessen erfordern, im Detail besprechen.
Vortraining
Die Vortrainingsphase ist ein sehr wichtiger Schritt im Trainingsprozess des BERT-Modells. In dieser Phase wird das Modell an umfangreichen unbeschrifteten Textdaten trainiert, hauptsächlich durch die folgenden zwei Aufgaben:
-
Maskiertes Sprachmodell (Masked Language Model, MLM) : Bei dieser Aufgabe wird ein bestimmter Anteil der Wörter im Eingabesatz zufällig durch spezielle
[MASK]Tags ersetzt, und das Modell muss diese maskierten Wörter vorhersagen. -
Vorhersage des nächsten Satzes (Next Sentence Prediction, NSP) : Das Modell muss vorhersagen, ob die beiden gegebenen Sätze kontinuierlich sind.
Technischer Punkt :
-
Dynamische Maske : In jeder Trainingsepoche wird die Maske jedes vom Modell gesehenen Satzes randomisiert, was die Robustheit des Modells erhöht.
-
Wörtertrennung : BERT verwendet die WordPiece-Wörtertrennung, die effektiv mit nicht registrierten Wörtern (OOV) umgehen kann.
Zu beachtende Punkte :
- Die Datenmenge muss sehr groß sein, um die riesigen Modellparameter angemessen zu trainieren.
- Der Trainingsprozess erfordert normalerweise viele Rechenressourcen, beispielsweise eine Hochleistungs-GPU oder TPU.
Feinabstimmung
Nachdem das vorab trainierte Modell fertig ist, ist der nächste Schritt die Feinabstimmungsphase. Die Feinabstimmung wird normalerweise an kleinen Datensätzen mit Beschriftungen durchgeführt, um das Modell besser an eine bestimmte Aufgabe anzupassen.
Technischer Punkt :
-
Anpassung der Lernrate : Da das Modell anhand einer großen Datenmenge vorab trainiert wurde, wird die Lernrate in der Feinabstimmungsphase normalerweise relativ niedrig eingestellt.
-
Aufgabenspezifische Header : Abhängig von der Aufgabe werden dem BERT-Modell normalerweise verschiedene Netzwerkschichten hinzugefügt (z. B. vollständig verbundene Schichten für Klassifizierungsaufgaben, CRF-Schichten für die Sequenzkennzeichnung usw.).
Zu beachtende Punkte :
- Überanpassung vermeiden: Da Feinabstimmungsdatensätze normalerweise klein sind, muss eine geeignete Regularisierungsstrategie wie Dropout oder Gewichtsabfall sorgfältig ausgewählt werden.
Durch diese beiden Trainingsphasen kann BERT nicht nur umfangreiche semantische und grammatikalische Informationen erfassen, sondern auch für bestimmte Aufgaben optimiert werden, wodurch es bei verschiedenen NLP-Aufgaben sehr gute Leistungen erbringt.
Wie sich BERT von anderen Transformer-Architekturen unterscheidet
Richtlinien vor der Ausbildung
Obwohl die Transformer-Architektur normalerweise auch eine Form des Vortrainings durchläuft, hat BERT bewusst zwei Phasen konzipiert: Vortraining und Feinabstimmung. Dadurch kann BERT zunächst anhand umfangreicher, unbeschrifteter Daten vorab trainiert und dann für bestimmte Aufgaben feinabgestimmt werden, wodurch breitere Anwendungen möglich werden.
bidirektionale Kodierung
Die meisten Transformer-basierten Modelle (z. B. GPT) verwenden normalerweise nur eine unidirektionale oder bedingte Codierung. Im Gegensatz dazu verwendet BERT eine bidirektionale Codierung, mit der die Kontextinformationen der Token im Text vollständiger erfasst werden können.
Maskiertes Sprachmodell
BERT verwendet in der Vortrainingsphase eine spezielle Trainingsstrategie namens Masked Language Model (MLM). In diesem Prozess muss das Modell die zufällig in der Eingabesequenz maskierten Token vorhersagen, was das Modell dazu zwingt, die Satzstruktur und semantische Informationen besser zu verstehen.
4. Szenarioanwendung von BERT
Das BERT-Modell wird aufgrund seiner leistungsstarken Darstellungsfähigkeit und Flexibilität häufig in verschiedenen NLP-Aufgaben (Natural Language Processing) eingesetzt. Im Folgenden untersuchen wir mehrere gängige Anwendungsszenarien und stellen zugehörige Codebeispiele bereit.
Textkategorisierung
Die Textklassifizierung ist eine der grundlegendsten Aufgaben im NLP. Mit BERT können Sie Text ganz einfach in vordefinierte Kategorien klassifizieren.
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 准备输入数据
inputs = tokenizer("Hello, how are you?", return_tensors="pt")
# 前向传播
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1, label set as 1
outputs = model(**inputs, labels=labels)
loss = outputs.loss
logits = outputs.logits
Emotionsanalyse
Die Stimmungsanalyse ist eine Teilaufgabe der Textklassifizierung, die zur Beurteilung der Stimmung (positiv, negativ oder neutral) eines Textabschnitts verwendet wird.
# 继续使用上面的模型和分词器
inputs = tokenizer("I love programming.", return_tensors="pt")
# 判断情感
outputs = model(**inputs)
logits = outputs.logits
predictions = torch.softmax(logits, dim=-1)
Anerkennung benannter Entitäten (NER)
Bei der Erkennung benannter Entitäten geht es darum, bestimmte Arten von Entitäten (z. B. Personennamen, Ortsnamen, Organisationsnamen usw.) im Text zu identifizieren.
from transformers import BertForTokenClassification
# 加载用于Token分类的BERT模型
model = BertForTokenClassification.from_pretrained('dbmdz/bert-large-cased-finetuned-conll03-english')
# 输入数据
inputs = tokenizer("My name is John.", return_tensors="pt")
# 前向传播
outputs = model(**inputs)
logits = outputs.logits
Textzusammenfassung
Mit BERT lassen sich auch Textzusammenfassungen generieren, also die wichtigsten Informationen aus einem Langtext extrahieren.
from transformers import BertForConditionalGeneration
# 加载用于条件生成的BERT模型(这是一个假设的例子,实际BERT原生不支持条件生成)
model = BertForConditionalGeneration.from_pretrained('some-conditional-bert-model')
# 输入数据
inputs = tokenizer("The quick brown fox jumps over the lazy dog.", return_tensors="pt")
# 生成摘要
summary_ids = model.generate(inputs.input_ids, num_beams=4, min_length=5, max_length=20)
print(tokenizer.decode(summary_ids[0], skip_special_tokens=True))
Dies ist nur die Spitze des Eisbergs praktischer Anwendungen mit BERT. Seine flexiblen und leistungsstarken Funktionen ermöglichen einen breiten Einsatz bei verschiedenen komplexen NLP-Aufgaben. Mit angemessener Vorverarbeitung, Modellauswahl und Feinabstimmung können Sie mit BERT nahezu jedes Problem bei der Verarbeitung natürlicher Sprache lösen.
5. Python- und PyTorch-Implementierung von BERT

Laden vorab trainierter Modelle
Das Laden eines vorab trainierten BERT-Modells ist der erste Schritt bei der Verwendung von BERT für Aufgaben zur Verarbeitung natürlicher Sprache. Da BERT-Modelle normalerweise sehr groß sind, ist es nicht praktikabel, die gesamte Architektur manuell zu implementieren und vorab trainierte Gewichte zu laden. Glücklicherweise gibt es mehrere Bibliotheken, die diesen Prozess vereinfachen, darunter transformersdie Bibliothek, die einen umfangreichen Satz vorab trainierter Modelle und entsprechender Tools bereitstellt.
Installieren Sie abhängige Bibliotheken
Zuerst müssen Sie transformerseine torchBibliothek installieren. Sie können es mit dem folgenden pip-Befehl installieren:
pip install transformers
pip install torch
Laden Sie das Modell und den Tokenizer
Mithilfe transformersder Bibliothek wird das Laden des BERT-Modells und des entsprechenden Tokenizers sehr einfach. Hier ist ein einfaches Beispiel:
from transformers import BertTokenizer, BertModel
# 初始化分词器和模型
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")
# 查看模型架构
print(model)
Dieser Code lädt die Basisversion (ohne Gehäuse) von BERT und den zugehörigen Tokenizer herunter. Sie können auch andere Versionen auswählen, z. B. bert-large-uncased.
Eingabevorbereitung
Nach dem Laden des Modells und des Tokenizers besteht der nächste Schritt darin, die Eingabedaten vorzubereiten. Angenommen, wir haben einen Satz: „Hallo, BERT!“.
# 分词
inputs = tokenizer("Hello, BERT!", padding=True, truncation=True, return_tensors="pt")
print(inputs)
tokenizerkonvertiert Text automatisch in Eingabetensoren aller für das Modell erforderlichen Typen, einschließlich input_ids, attention_maskusw.
Modellargumentation
Nach der Vorbereitung der Eingabe besteht der nächste Schritt darin, das Modell abzuleiten, um verschiedene Ausgaben zu erhalten:
with torch.no_grad():
outputs = model(**inputs)
# 输出的是一个元组
# outputs[0] 是所有隐藏状态的最后一层的输出
# outputs[1] 是句子的CLS标签的隐藏状态
last_hidden_states = outputs[0]
pooler_output = outputs[1]
print(last_hidden_states.shape)
print(pooler_output.shape)
Der Ausgabetensor last_hidden_stateshat die Form [batch_size, sequence_length, hidden_dim], während pooler_outputdie Form ist [batch_size, hidden_dim].
Das Obige ist der gesamte Prozess des Ladens des vorab trainierten BERT-Modells und der Durchführung grundlegender Überlegungen. Nachdem Sie diese Grundlagen verstanden haben, können Sie BERT problemlos für verschiedene NLP-Aufgaben verwenden, einschließlich, aber nicht beschränkt auf, Textklassifizierung, Erkennung benannter Entitäten oder Frage-Antwort-Systeme.
Feinabstimmung des BERT-Modells
Die Feinabstimmung ist ein wichtiger Schritt bei der Anwendung eines vorab trainierten BERT-Modells auf bestimmte NLP-Aufgaben. Dabei trainieren wir das Modell weiter anhand eines aufgabenspezifischen Datensatzes, um Vorhersagen oder Klassifizierungen genauer zu treffen. transformersNachfolgend finden Sie die detaillierten Schritte zur Feinabstimmung mit PyTorch und der Bibliothek.
Datenaufbereitung
Angenommen, wir haben eine einfache Textklassifizierungsaufgabe mit zwei Klassen: positiv und negativ. Wir werden PyTorch DataLoaderzum DatasetLaden und Vorverarbeiten von Daten verwenden.
from torch.utils.data import DataLoader, Dataset
import torch
class TextClassificationDataset(Dataset):
def __init__(self, texts, labels, tokenizer):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
inputs = self.tokenizer(text, padding='max_length', truncation=True, max_length=512, return_tensors="pt")
return {
'input_ids': inputs['input_ids'].flatten(),
'attention_mask': inputs['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
# 假设texts和labels分别是文本和标签的列表
texts = ["I love programming", "I hate bugs"]
labels = [1, 0]
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
dataset = TextClassificationDataset(texts, labels, tokenizer)
dataloader = DataLoader(dataset, batch_size=2)
Feinabstimmung des Modells
Hier kombinieren wir das BERT-Modell mit einer einfachen Klassifizierungsschicht. Während des Feinabstimmungsprozesses werden dann die Gewichte des BERT-Modells und der Klassifizierungsschichten gleichzeitig aktualisiert.
from transformers import BertForSequenceClassification
from torch.optim import AdamW
# 初始化模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 使用AdamW优化器
optimizer = AdamW(model.parameters(), lr=1e-5)
# 训练模型
for epoch in range(3):
for batch in dataloader:
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['labels']
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f'Epoch {
epoch + 1} completed')
Modellbewertung
Nach der Feinabstimmung können wir die Leistung des Modells anhand des Testdatensatzes bewerten.
# 在测试数据集上进行评估...
Durch einen solchen Feinabstimmungsprozess kann das BERT-Modell nicht nur allgemeines Wissen aus dem Vortraining erlangen, sondern auch für bestimmte Aufgaben optimiert werden.
6. Zusammenfassung
Nach einer ausführlichen Diskussion über BERT (Bidirektionale Encoderdarstellungen von Transformers) hatten wir die Gelegenheit, einen Einblick in die inhärente Komplexität und den Funktionsreichtum dieser fortschrittlichen Architektur zu erhalten. Von seinem leistungsstarken bidirektionalen Aufmerksamkeitsmechanismus bis hin zu seinen vielfältigen Anwendungen des Vortrainings und der Feinabstimmung hat BERT neue Maßstäbe im Bereich der Verarbeitung natürlicher Sprache (NLP) gesetzt.
Der Wert der Architektur
-
Vortraining und Feinabstimmung : Das BERT-Paradigma zur Feinabstimmung vor dem Training ist nahezu eine „Einheitslösung“, die leicht an verschiedene NLP-Aufgaben angepasst werden kann und so die Komplexität und den Rechenaufwand von Trainingsmodellen reduziert kratzen.
-
Allgemeinheit vs. Spezialisierung : Ein weiterer Vorteil von BERT ist seine Flexibilität. Obwohl es sich beim ursprünglichen BERT-Modell um ein Allzweck-Sprachmodell handelt, kann es durch Feinabstimmung problemlos an mehrere Aufgaben und branchenspezifische Anforderungen angepasst werden.
-
Sehr gut interpretierbar : Während Deep-Learning-Modelle oft als „Black Boxes“ betrachtet werden, bieten BERT und andere aufmerksamkeitsbasierte Modelle ein gewisses Maß an Interpretierbarkeit. Durch die Analyse der Aufmerksamkeitsgewichte können wir beispielsweise verstehen, auf welche Teile der Eingabe das Modell bei der Entscheidungsfindung achtet.
Aussichten
-
Skalierbarkeit : Obwohl das BERT-Modell selbst bereits sehr umfangreich ist, ist seine Architektur skalierbar. Dies ebnet den Weg für zukünftige größere und komplexere Modelle, die das Potenzial haben, komplexere Sprachstrukturen und Semantiken zu erfassen.
-
Multimodales Lernen und gemeinsames Training : Mit fortschreitender Forschung gibt es einen zunehmenden Trend, BERT mit anderen Datentypen wie Bildern und Audio zu kombinieren. Diese multimodale Lernmethode wird die Generalisierungsfähigkeit und den Anwendungsbereich des Modells weiter verbessern.
-
Optimierung und Komprimierung : Obwohl BERT eine hervorragende Leistung aufweist, sind auch die Rechenkosten hoch. Daher wird die Modelloptimierung und -komprimierung eine wichtige Richtung zukünftiger Forschung sein, um diese Hochleistungsmodelle in ressourcenbeschränkten Umgebungen einzusetzen.
Zusammenfassend ist BERT nicht nur ein Meilenstein in der Verarbeitung natürlicher Sprache, sondern bietet auch einen fruchtbaren Boden für zukünftige Forschung und Anwendungen. Wie wir in diesem Artikel untersuchen, können wir dieses leistungsstarke Tool besser nutzen, um eine Vielzahl von Problemen zu lösen, indem wir seine internen Mechanismen verstehen und lernen, wie man es effektiv optimiert. Es besteht kein Zweifel, dass BERT und ähnliche Modelle auch in Zukunft die Entwicklung von NLP und KI anführen werden.
Folgen Sie TechLead und teilen Sie umfassendes Wissen über KI. Der Autor verfügt über mehr als 10 Jahre Erfahrung in den Bereichen Internet-Service-Architektur, KI-Produktentwicklung und Teammanagement. Er ist ein Fudan-Meister von Tongji, Mitglied des Fudan Robot Intelligence Laboratory, ein von Alibaba Cloud zertifizierter leitender Architekt und ein Projektmanagement-Experte , und erwirtschaftet Hunderte Millionen Umsätze in der KI-Produktentwicklung. Auftraggeber.