
この記事の著者は 黄暉文です
Amazonクラウドテクノロジーシニアデベロッパーエバンジェリスト
前回の記事では、Generative AI のもう 1 つの急速に進歩している分野であるText-to-Image の分野について探求を開始しました。CLIP、OpenCLIP、拡散モデル、DALL-E-2 モデル、安定拡散モデルなど、Text-to-Image の基本的な内容を概説します。
今回の内容は主要論文をText-to-Imageの方向で解釈したものになります。
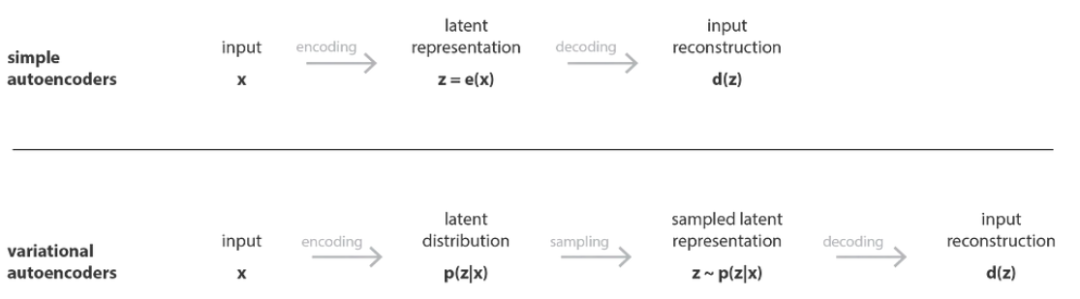
変分オートエンコーダ VAE 論文の解釈
変分オートエンコーダ
1. オートエンコーダーのアーキテクチャ
オートエンコーダー (Auto-Encoder) は、入力データの圧縮表現を学習するための教師なし学習ニューラル ネットワークです。具体的には、次の 2 つの部分に分けることができます。
エンコーダ:データを低次元表現に圧縮する役割を果たします。
デコーダー:低次元表現を元のデータに復元する役割を果たします。
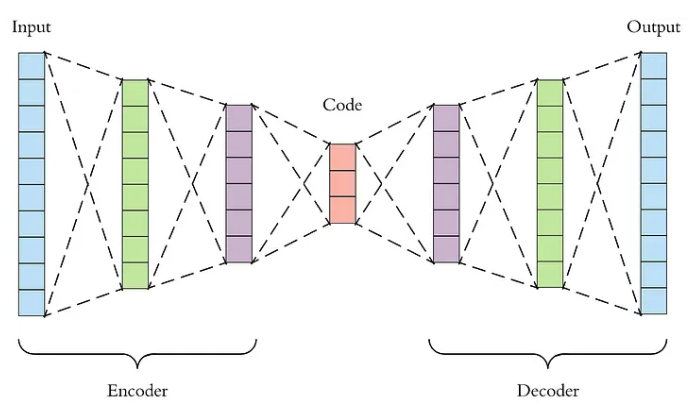
出典: https://towardsdatascience.com/applied-deep-learning-part-3-autoencoders-1c083af4d798
これを読んだ読者の中には、「デコーダはいくつかの低次元ベクトルを入力するだけで高次元の画像データを出力できるのに、デコーダ モデルを生成モデルとして直接使用できるの?」と疑問に思う人もいるかもしれません。たとえば、いくつかのベクトルは低次元空間でランダムに生成され、画像を生成するためにデコーダに送信されます。
これを行わない理由は、ランダム生成の大部分が無意味なノイズであり、分布を明示的にモデル化していないため、どのベクトルが有用な画像を生成するかわからないためです。トレーニングに使用するデータセットは通常有限です。したがって、有限の応答しかありません。しかし、低次元空間全体は非常に大きいため、この空間内でランダムにサンプリングするだけでは、有用な画像を生成するためのサンプリングの確率は高くありません。
また、VAE (変分自動エンコーダ) は、分布を明示的にモデル化する AE に基づいており、オートエンコーダが適格な、または優れた生成モデルになるのに役立ちます。
2. 次元削減と潜在空間
次元削減と潜在空間
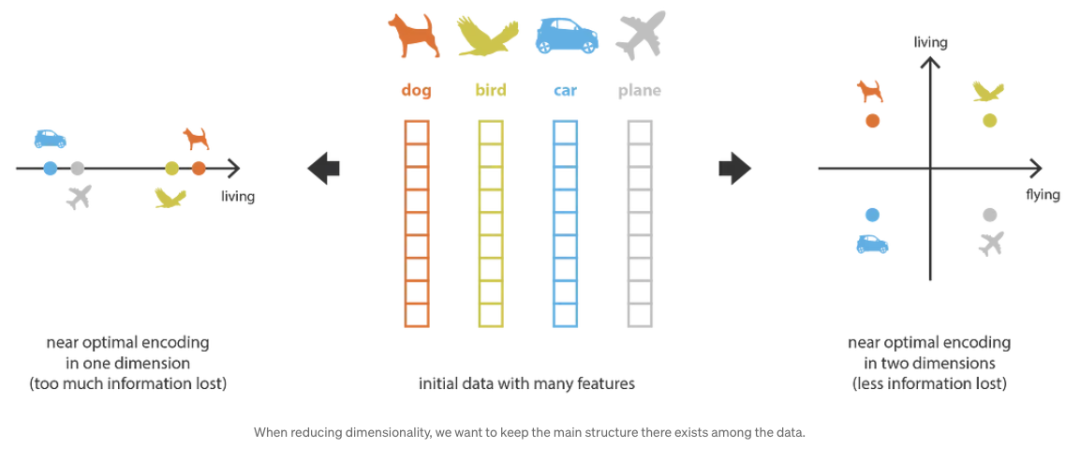
前のセクションでは、すべての生成 AI 分野で非常に重要な次元削減の概念 (Dimensionality Reduction) について説明しました。このセクションでは素人向けに説明します。
機械学習における次元削減とは、一部のデータを記述する特徴の数を減らすプロセスです。この削減は、低次元データが必要な場合 (データの視覚化、データ ストレージ、大量のデータ) の多くの場合、選択 (既存のフィーチャの一部のみを保持する) または抽出 (古いフィーチャに基づいて作成される新しいフィーチャの数を減らす) によって実現できます。計算など)非常に便利です。
まず、「古い特徴」表現から (選択または抽出によって) 「新しい特徴」表現を生成し、逆にデコードするプロセスをエンコーダーと呼びます。次元削減はデータ圧縮として解釈できます。エンコーダがデータを (初期空間から潜在空間とも呼ばれる、エンコードされた空間まで) 圧縮し、デコーダがそれを解凍します。もちろん、初期のデータ分布、潜在空間の次元、およびエンコーダの定義によっては、この圧縮は非可逆圧縮になる可能性があります。つまり、エンコード中に一部の情報が失われ、デコード時に回復できなくなります。

出典: https://theaiSummer.com/latent-variable-models/
自動エンコーダ (Auto-Encoder) は、ニューラル ネットワークを使用して次元を削減します。オートエンコーダの一般的なアイデアは非常にシンプルで、エンコーダとデコーダをニューラル ネットワークとして設定し、反復最適化プロセスを使用して最適なエンコードおよびデコード スキームを学習することが含まれます。したがって、反復ごとに、オートエンコーダ アーキテクチャにデータを供給し (エンコーダの後にデコーダが続きます)、エンコードおよびデコードされた出力を元のデータと比較し、アーキテクチャを通じて誤差を逆伝播してネットワークの重みを更新します。 。
オートエンコーダーのアーキテクチャ全体により、情報の主要な構造部分のみが通過して再構築されることが保証されます。全体的なフレームワークの観点から、考慮されたエンコーダ ファミリ E はエンコーダ ネットワーク アーキテクチャによって定義され、考慮されたデコーダ ファミリ D はデコーダ ネットワーク アーキテクチャによって定義され、再構成エラーを最小限に抑えるために、これらのネットワークのパラメータは勾配降下法です。 (Gradient Decent) を完了します。以下に示すように:
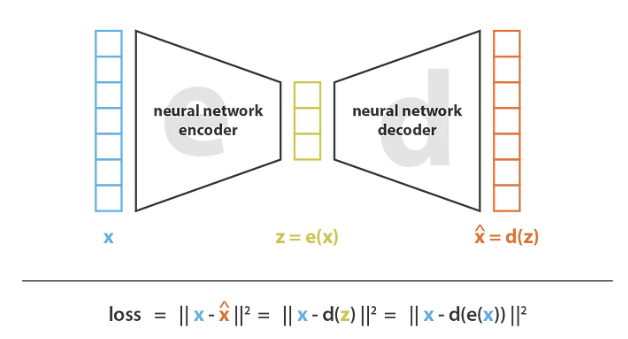
出典: https://towardsdatascience.com/ Understanding-variational-autoencoders-vaes-f70510919f73
このオートエンコーダ構造は、現実世界では 2 つの主要な課題に直面しています。
第一に、再構成損失を伴わない大幅な次元削減は、多くの場合、潜在空間における解釈可能かつ活用可能な構造の欠如、またはより単純に規則性の欠如という犠牲を伴います; 第二に、ほとんどの場合、次元削減の最終的な目標は次のとおりではありません。データの次元数を減らすためだけでなく、データ構造情報の大部分を単純化された表現で保持するためでもあります。
これら 2 つの理由により、現実の世界では、次元削減の最終目標に従って、潜在空間のサイズとオートエンコーダーの「深さ」 (圧縮の程度と品質を定義する) を慎重に制御し、調整する必要があります。以下に示すように:
出典: https://towardsdatascience.com/ Understanding-variational-autoencoders-vaes-f70510919f73
3. 変分オートエンコーダ
変分オートエンコーダ
これまでの知識ベースを整えた後、いよいよ VAE に関するこの論文の本質を探ることができます。

出典: https://arxiv.org/pdf/1312.6114.pdf
これまで、次元削減の問題について説明し、勾配降下法でトレーニングできるエンコーダ/デコーダ アーキテクチャであるオートエンコーダを紹介しました。次に、コンテンツ生成問題を関連付けて、この問題を解決する際のオートエンコーダーの制限を確認してから、変分オートエンコーダー (変分オートエンコーダー) を紹介します。
コンテンツ生成と自動エンコーダの組み合わせに関して、潜在空間に十分なルールがある場合、潜在空間からポイントをランダムに選択してデコードして新しいコンテンツを取得できるか、と考えるかもしれません。以下に示すように:
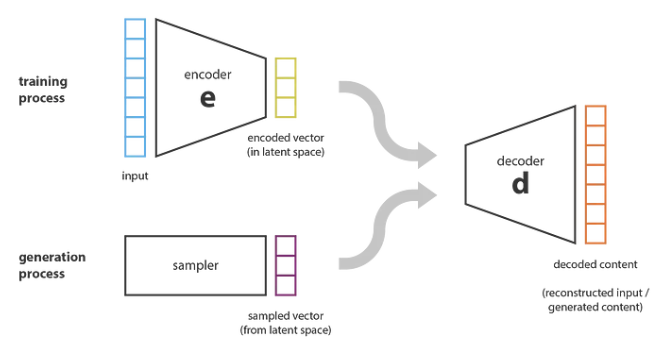
出典: https://towardsdatascience.com/ Understanding-variational-autoencoders-vaes-f70510919f73
変分オートエンコーダの定義
したがって、自動エンコーダのデコーダを生成目的に使用できるようにするには、潜在空間が十分に規則的であることを確認する必要があります。このような規則性を得るために考えられる解決策は、トレーニング中に明示的な正則化を導入することです。変分オートエンコーダは、過学習を回避し、潜在空間が生成プロセスに対して適切に特徴付けられるようにトレーニングが正規化されるオートエンコーダとして定義できます。
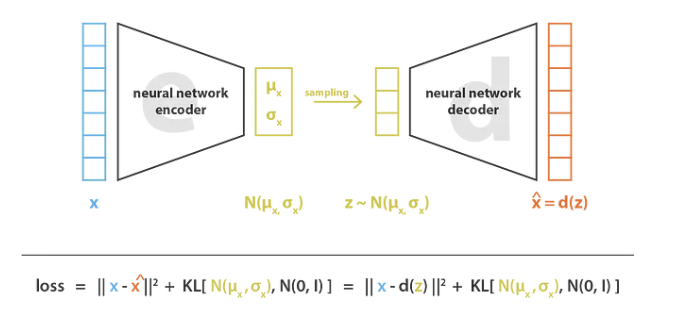
標準のオートエンコーダと同様に、変分オートエンコーダはエンコーダとデコーダで構成されるアーキテクチャであり、エンコードされたデコードされたデータと元のデータの間の再構成エラーを最小限に抑えるようにトレーニングされます。ただし、潜在空間に何らかの正則化を適用するために、エンコードとデコードのプロセスにわずかな変更を加えます。入力を単一点としてエンコードする代わりに、潜在空間全体にわたる分布としてエンコードします。次に、次のようにモデルをトレーニングします。
入力は潜在空間上の分布としてエンコードされます
潜在空間内の点はこの分布からサンプリングされます
サンプリングポイントをデコードすると、再構成誤差を計算できます
再構築エラーがネットワークを通じて逆伝播される
以下に示すように:
出典: https://towardsdatascience.com/ Understanding-variational-autoencoders-vaes-f70510919f73
実際、エンコード分布は正規になるように選択されているため、エンコーダはこれらのガウス分布を表す平均行列と共分散行列を返すようにトレーニングできます。入力が単一点分布ではなく分散を伴う分布としてエンコードされる理由は、潜在空間正則化を非常に自然に表現するためです。このようにして、潜在空間のローカル正則化とグローバル正則化の両方が保証されます (分散はローカル正則化を制御し、平均はグローバル正則化を制御します)。
したがって、VAE をトレーニングするときに最小化される損失関数は、「再構成項」(最後の層に位置する) と「正則化」(潜在層に位置する) で構成されます。後者は、エンコーダを次の値に近づけることによって分布を返す傾向があります。潜在空間の構成を調整するための標準正規分布。この正則化は、リターン分布と標準ガウス分布の間の KL 発散 (Kulback-Leibler Divergence) として表現されます。2 つのガウス分布間の KL 発散は閉じた形式であるため、2 つの分布の平均と共分散を直接使用できます。マトリックス表現。以下に示すように:
出典: https://towardsdatascience.com/ Understanding-variational-autoencoders-vaes-f70510919f73
VAE についての私の個人的な理解は、VAE アーキテクチャの中核は 2 つのエンコーダであり、1 つは平均値の計算に使用され、もう 1 つは分散の計算に使用され、平均値と分散はニューラルを使用して VAE アーキテクチャによって計算されます。通信網。
VAE は基本的に、従来のオートエンコーダに基づいてエンコーダ (VAE で平均を計算するためのネットワークに対応) の結果に「ガウス ノイズ」を追加するため、結果として得られるデコーダはノイズに対して堅牢になります。また、追加の KL 損失(目的は、平均値を 0 にし、分散 1) を作成することです。実際には、エンコーダーの正規化項目と同等であり、エンコーダーからのすべてのものが平均値 0 になることが望まれます。
別のエンコーダー (分散を計算するネットワークに相当) を使用して、ノイズ強度を動的に調整します。Decoder が十分にトレーニングされていない場合 (再構成誤差が KL 損失よりもはるかに大きい場合、KL は Kullback-Leibler の略語で、確率分布の類似性を測定する古典的な関数として使用されます)、ノイズは適切に低減されます ( KL 損失が増加する)、フィッティングが容易になります (再構成誤差が減少し始める)。逆に、デコーダが適切にトレーニングされている場合 (再構成誤差が KL 損失より小さい)、ノイズが増加します (KL 損失が減少します)。フィッティングがより困難になるため (再構成エラー、構造エラーが増加し始める)、Decoder は生成能力を向上させる方法を見つける必要があります。
この本質は、VAE の論文では、以下の論文のスクリーンショットに示されているように、絶妙な数式を使用して説明されています。
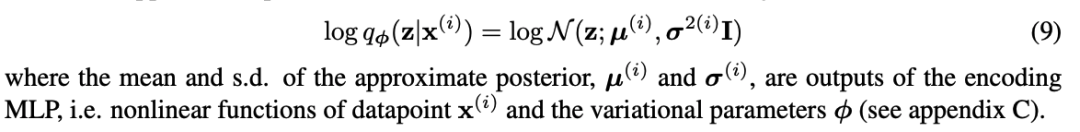
出典: https://arxiv.org/pdf/1312.6114.pdf
4. VAE 論文の見解
この VAE ペーパーの主なポイントは次のとおりです。
次元削減は、一部のデータを記述する特徴の数を減らすプロセス (初期特徴のサブセットのみを選択するか、それらを少数の新しい特徴にマージするかのいずれか) であるため、エンコード プロセスと考えることができます。
オートエンコーダは、データ トラバーサルのボトルネックを形成するエンコーダとデコーダで構成されるニューラル ネットワーク アーキテクチャであり、再構成エラーを減らすことを目的として、エンコードとデコードのプロセス (勾配降下反復による) トレーニング中に失われる情報を最小限にするようにトレーニングされます) ;
オーバーフィッティングにより、オートエンコーダーの潜在空間は非常に不規則になる可能性があります (潜在空間内の近い点が大幅に異なるデコードされたデータを提供する可能性があり、潜在空間のいくつかの点がデコード後に無意味なコンテンツを提供する可能性があります)。実際には、潜在空間から点をサンプリングし、それをデコーダに渡して新しいデータを取得するだけの生成プロセスを定義します。
変分オートエンコーダ (VAE) は、エンコーダが単一点ではなく潜在空間にわたる分布を返し、この返された分布に対して損失関数に正則化項を追加することによって、潜在空間の不一致に対処するオートエンコーダです。潜在空間の組織化。
データを記述するための単純な基礎となる確率モデルを仮定すると、変分推論の統計的手法 (そのため、変分オートエンコーダーという名前が付けられています) を使用して、VAE の損失関数を構成する再構成項と正則化項を慎重に導き出すことができます。
普及モデルシリーズ論文の解釈
普及モデル
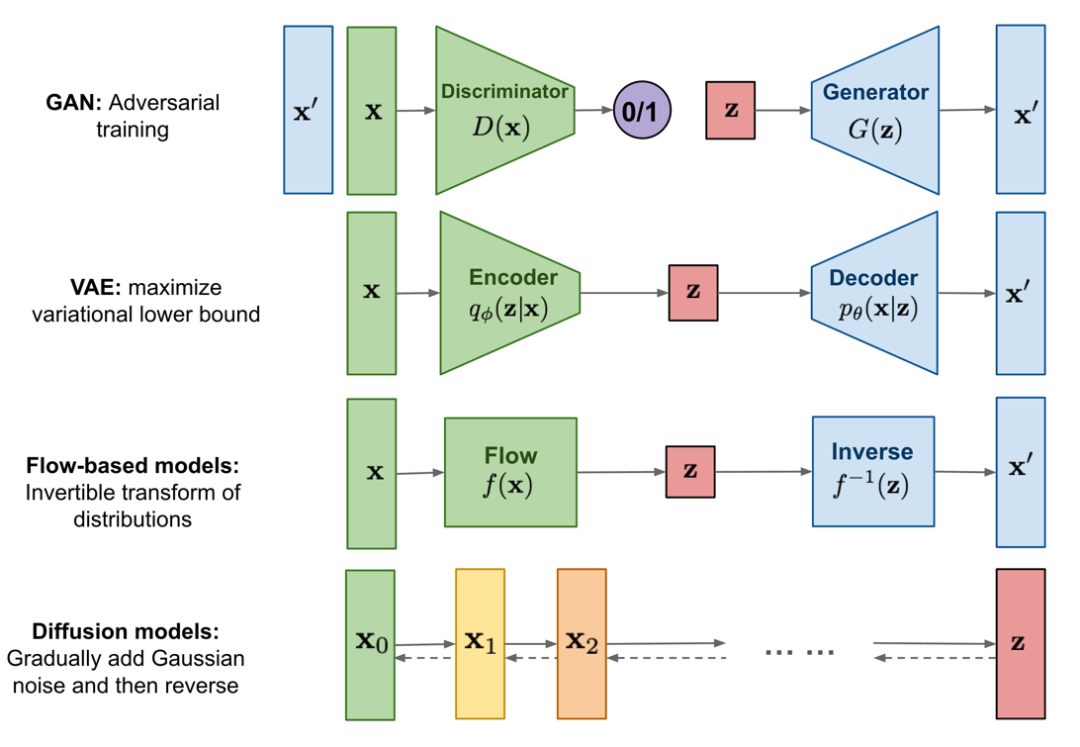
ヴィンセント グラフの分野で拡散モデルが主流になる前には、3 種類の生成モデルがありました。彼らです:
GAN (敵対的生成ネットワーク)
VAE (変分自動エンコード)
フローベースのモデル
これらのモデルはすべて、高品質のサンプルを生成することに大きな成功を収めていますが、それぞれに独自の制限があります。敵対的なトレーニングの性質により、GAN モデルのトレーニングは不安定で多様性が低い可能性があること、VAE はサロゲート損失 (Surrogate Loss) 関数に依存していること、フロー モデルは可逆変換を構築するために特殊なアーキテクチャを使用する必要があることはよく知られています。
代理損失関数:
https://baike.baidu.com/item/%E4%BB%A3%E7%90%86%E6%8D%9F%E5%A4%B1%E5%87%BD%E6%95%B0/22787203
拡散モデルは非平衡熱力学からインスピレーションを得ています。彼らは、ランダム ノイズをデータにゆっくりと追加するマルコフ拡散連鎖を定義し、拡散プロセスを逆にしてノイズから目的のデータ サンプルを構築する方法を学習しました。VAE やフローベースのモデルとは異なり、拡散モデルは固定プロセスを通じて学習され、潜在変数は高次元になります (元のデータと同じ)。以下に示すように:
出典: https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
拡散モデルの重要な貢献の 1 つは、トレーニング プロセス (DDPM のトレーニング プロセスなど) において、差を最小限に抑えるために、実際のノイズがノイズ推定モデル ∈ θ (x t , t) によって予測されることです。推定ノイズと実際のノイズの差。この貢献については後ほど詳しく説明します。
1. 普及モデルの概要
拡散生成モデルに基づくいくつかの主要な論文には、すべて同様の考え方があり、拡散確率モデル (Sohl-Dickstein et al., 2015)、ノイズ条件付きスコアリング ネットワーク (NCSN; Yang & Ermon, 2019)、およびノイズ除去モデルの拡散確率 ( DDPM;Ho et al.、2020)。
Sohl-Dickstein 他、2015:
https://arxiv.org/abs/1503.03585
ヤン&エルモン、2019年:
https://arxiv.org/abs/1907.05600
ホー他、2020:
https://arxiv.org/abs/2006.11239
1
順拡散プロセス
順拡散プロセス
実際のデータ分布からサンプリングされたデータ点 x 0 ~q(x) が与えられた場合、順拡散プロセスを定義しましょう。このプロセスでは、ステップ T でサンプルに少量のガウス ノイズを追加して、一連のノイズのあるサンプル x 1 ,...x Tを生成します。そのステップ サイズは分散スケジュール {β t ∈(0, 1 )} T (t=1) :
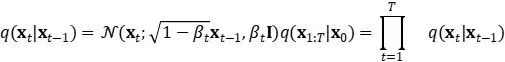
データサンプル x 0 は、ステップ t が大きくなるにつれて、その顕著な特徴を徐々に失います。T→∞の場合、x T は 等方性ガウス分布に相当します。以下に示すように:
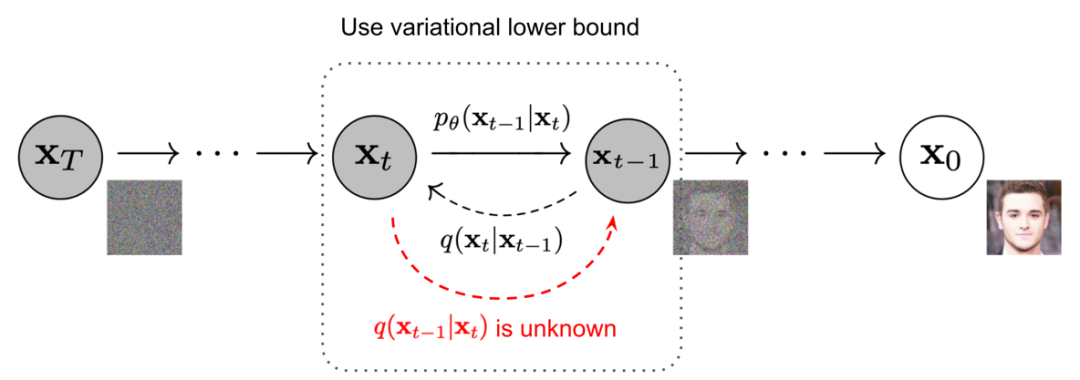
ノイズをゆっくりと追加 (除去) することによってサンプルを生成する順 (逆) 拡散プロセスのマルコフ連鎖。(画像出典: Ho et al. 2020、いくつかの追加注釈付き)
順拡散プロセスと逆拡散プロセスはどちらもマルコフプロセスであり、唯一の違いは次のとおりです。
順拡散プロセスの各条件付き確率のガウス分布の平均と分散は(β t と x 0に応じて)決定されています が、逆拡散プロセスの平均と分散はニューラル ネットワークを通じて学習する必要があります。
マルコフ過程:
https://zhuanlan.zhihu.com/p/426290103
上記の手順のもう 1 つの優れた特性は、次の図に示すように、再パラメータ化されたトリックを使用して、任意のタイム ステップ x tを閉じた形式で サンプリングできることです。
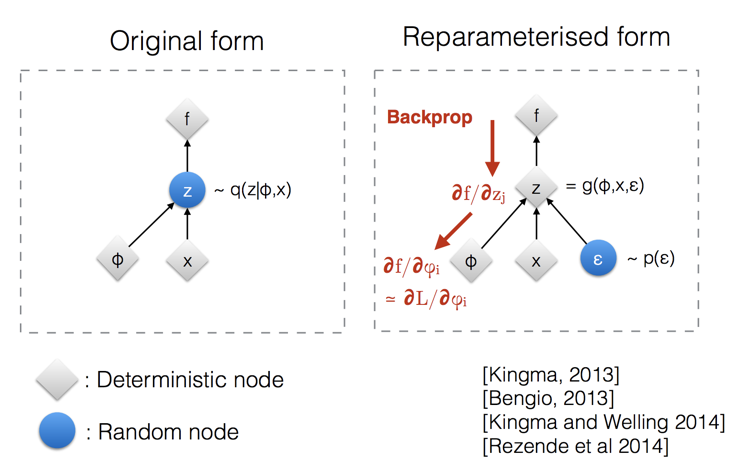
再パラメータ化トリックによってサンプリング プロセスがトレーニング可能になる様子の図。(画像出典: Kingma の NIPS 2015 ワークショップ トークのスライド 12)
再パラメータ化のトリックは、ガウス分布だけでなく、他のタイプの分布にも機能します。多変量ガウスの場合、モデルは上記の再パラメータ化手法を使用し、平均 μ と分散 σ で分布を学習することによってトレーニング可能になります。一方、ランダム性は確率変数 ∈~N(0,Ι) で表されます。以下の図は、多変量ガウス仮定を使用した変分オートエンコーダ モデルの概略図です。この変分オートエンコーダ モデルについては、前の章で詳しく説明しました。
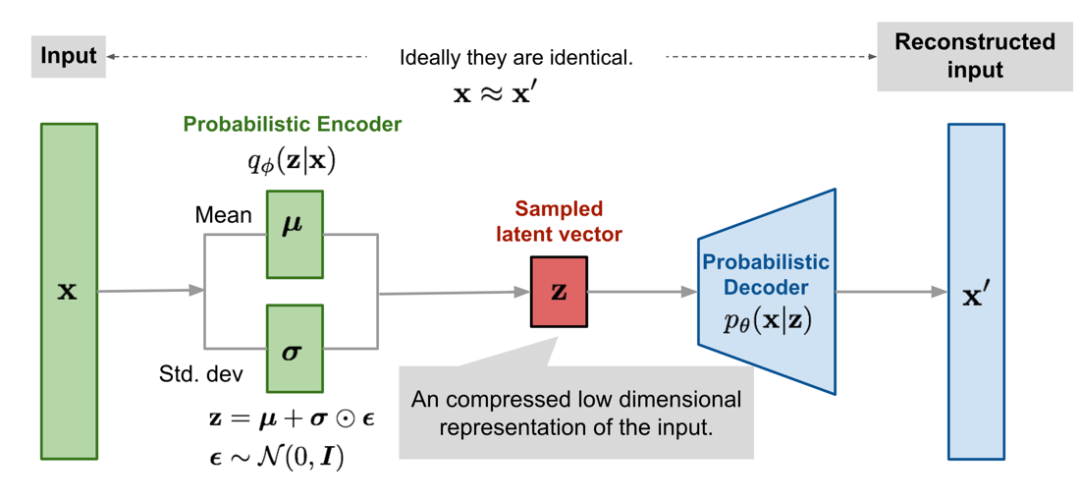
出典: https://lilianweng.github.io/posts/2018-08-12-vae/#reparameterization-trick
このスペースでは、前方拡散プロセスの数学的導出プロセスについては詳しく説明しません。興味のある学生は、次の記事の「前方拡散プロセス」セクションの内容を参照してください。
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
以下に概要を示します。
標準の確率的勾配降下法 (SGD) 法と比較すると、拡散モデルは確率的勾配ランジュバン ダイナミクス (確率的勾配ランジュバン ダイナミクス) の方法を指します。この方法では、パラメータの更新にガウス ノイズを注入して、極小値への崩壊を回避できます。
2
逆拡散プロセス
逆拡散プロセス
上記のプロセスを逆にして、q(x t-1 |x t ) からサンプリングできれば、ガウス ノイズ入力 x T ~N(0,Ι) から実際のサンプルを再作成できます。β t が十分に小さい場合、q(x t-1 |x t ) もガウス分布になることに注意してください。ただし、次の図に示すように、 q(x t-1 |x t ) を推定するにはデータセット全体を使用する必要があるため、簡単に推定することはできません。
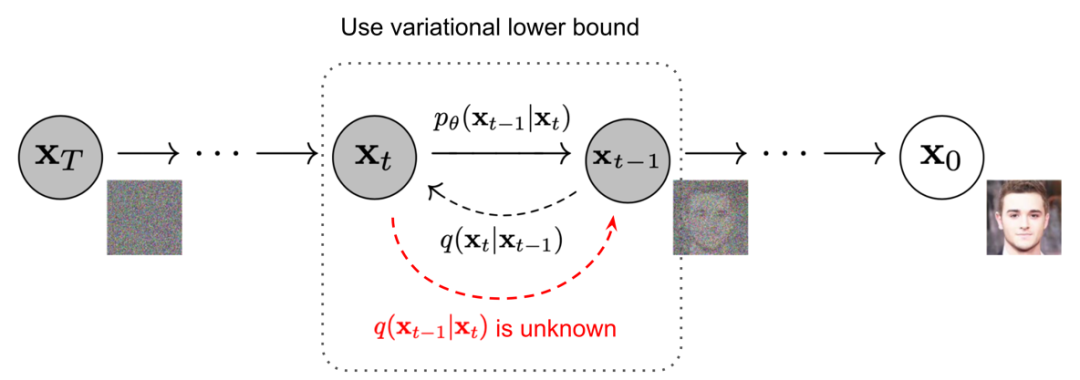
画像出典: Ho et al. 2020 年、いくつかの追加注釈あり
したがって、逆拡散プロセスを実行するには、これらの条件付き確率を近似するようにモデル ρ θをトレーニングする必要があります。
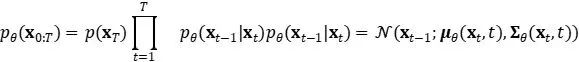
以下の図は、「Sohl-Dickstein et al., 2015」論文の 2D スイス ロール データをモデル化するために拡散モデルをトレーニングする例を示しています。
Sohl-Dickstein 他、2015
https://arxiv.org/abs/1503.03585
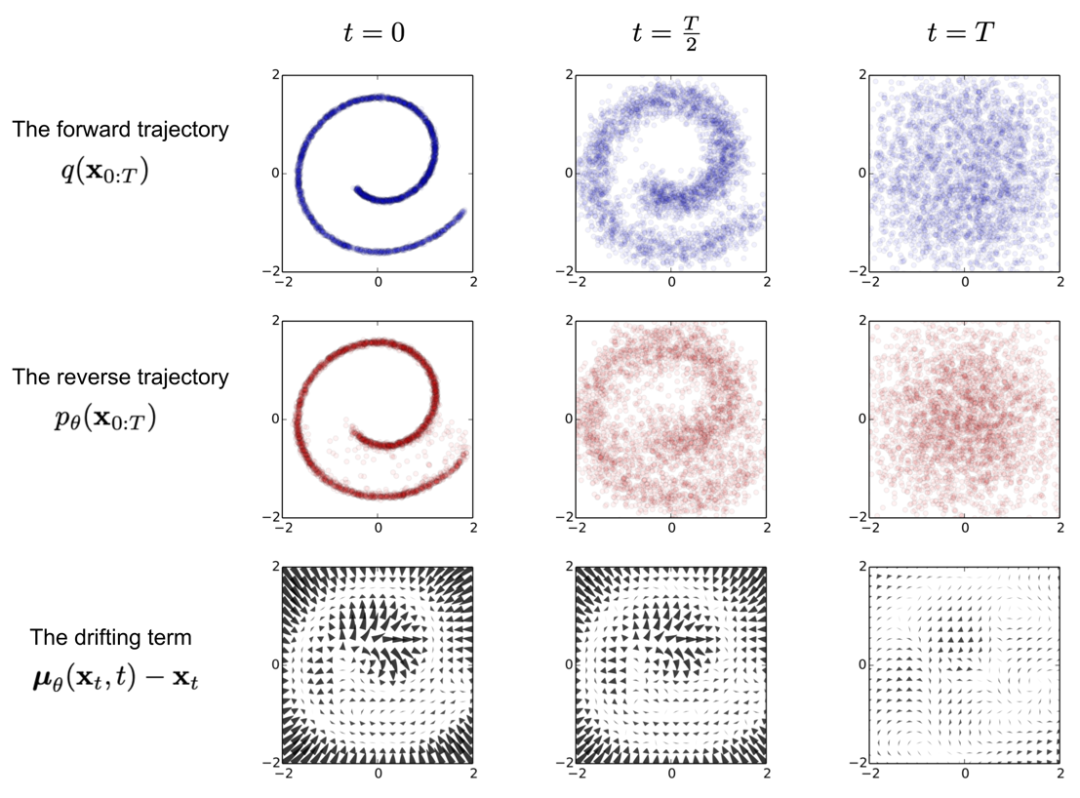
画像出典: Sohl-Dickstein 他、2015
最初の行は、順方向軌道 q(x 0:T ) から始まるタイム スライスを示します。データ分布は左側からガウス拡散を受け、右側のガウス拡散により恒等共分散ガウス分布に徐々に変換されます。
中央の行は、訓練された逆軌道 ρθ(x 0:T )の対応するタイム スライスを示します。特徴共分散ガウス分布 (右) は、学習された平均関数と共分散関数によるガウス拡散プロセスを受け、徐々に元のデータ分布 (左) に戻ります。
最後の行は、同じ逆拡散プロセスのドリフト項μ θ (x t ,t)-x t の場合を示しています。
3
DDPM ペーパーとパラメトリック L t
前に述べたように、逆拡散プロセスで条件付き確率分布を近似するにはニューラル ネットワークを学習する必要があります。
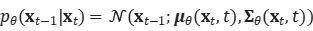
以下を予測するためにμ θを訓練したいと考えています 。
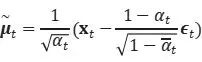
xtはトレーニング時に入力として利用できるため、代わりにタイム ステップ t で入力xtから ∈ tを予測 するようにガウス ノイズ項を再パラメータ化できます。
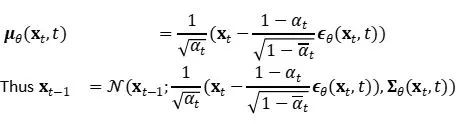
後で、いくつかの数式を使用して簡略化することができます。特定の数学的導出プロセスに興味がある読者は、次の記事を参照してください。
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
簡略化された結果については、次の DDPM 論文を参照できます。

出典: https://arxiv.org/abs/2006.11239

DDPM のトレーニングおよびサンプリング アルゴリズム (画像出典: Ho et al. 2020)
上記の単純化された結果の理由は、DDPM の論文で述べられていますが、主に Ho et al. (2020) が重み付け項を無視した単純化された目的を使用した場合にトレーニング拡散モデルがより適切に機能することを経験的に発見したためです。
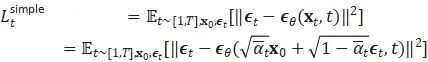
最終的な簡略化された式は次のとおりです。
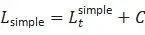
ここで、C は θ に依存しない定数です。
ホー他 (2020):
https://arxiv.org/abs/2006.11239
2. 拡散モデルのサンプリングの高速化
拡散モデルのサンプリングを高速化
1
DDIM論文の解釈
逆拡散プロセス後のマルコフ連鎖を介して DDPM からサンプルを生成するのは、最大で数千ステップかかる可能性があるため、非常に時間がかかります。Song らによる 2020 DDIM 論文のデータには、「たとえば、DDPM からサイズ 32×32 の 50,000 枚の画像をサンプリングするには約 20 時間かかりますが、Nvidia 2080 Ti GPU 上の GAN からサンプリングするには 1 分もかかりません」と述べられています。 。」
Song らによる 2020 DDIM 論文:
https://arxiv.org/abs/2010.02502

出典: https://arxiv.org/pdf/2010.02502.pdf
DDIM は同じ限界ノイズ分布を持ちますが、ノイズを元のデータ サンプルに決定論的にマッピングします。生成中、拡散ステップのサブセット {τ 1 ,…,τ S } のみをサンプリングし、DDIM の推論プロセスは次のようになります。
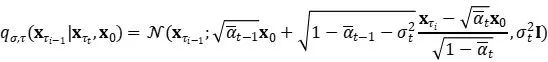
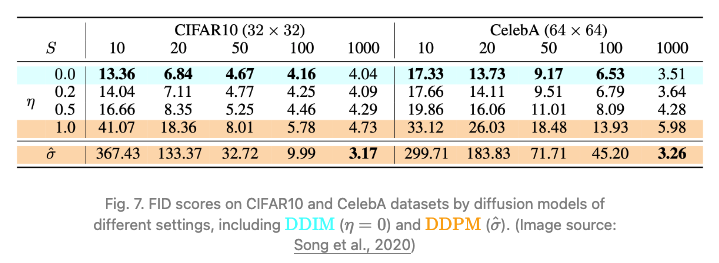
実験ではすべてのモデルが Τ=1000 拡散ステップでトレーニングされましたが、S が小さい場合は DDIM (η=0) が最高品質のサンプルを生成できるのに対し、S が小さい場合の DDPM (η=1) のパフォーマンスははるかに悪いことが観察されました。完全な逆マルコフ拡散ステップ (S=Τ=1000) を実行できる場合、DDPM はさらに優れたパフォーマンスを発揮します。
DDIM を使用すると、拡散モデルは任意の数の前方ステップにトレーニングできますが、生成プロセスのステップのサブセットからのみサンプリングされます。論文中の DDPM と DDIM の比較テスト結果を以下の図に示します。
出典: https://arxiv.org/pdf/2010.02502.pdf
DDIM と DDPM の比較は次のように要約されます。
少ないステップで高品質のサンプルを生成
生成プロセスは決定論的であるため、同じ潜在変数で条件付けされた複数のサンプルが同様の高レベルの特徴を持っていることを意味します。
DDIM は、一貫性により潜在変数間で意味のある補間を可能にします
2
LDM論文の解釈
もう 1 つの重要な論文は、潜在拡散モデル (LDM: Rombach & Blattmann et al., 2022) 論文 (以下に表示) です。これは、拡散プロセスをピクセル空間ではなく潜在空間で実行することを提案しており、これによりトレーニング コストが削減され、推論速度が向上します。 。
LDM: Rombach & Blattmann 他、2022:
https://arxiv.org/abs/2112.10752

出典: https://arxiv.org/pdf/2112.10752.pdf
この論文は、画像の大部分が知覚的に詳細に表現されている一方で、意味論的および概念的な構成は積極的な圧縮後も持続するという観察によって動機付けられています。LDM は、最初にオートエンコーダーを使用してピクセルレベルの冗長性をトリミングし、次に学習した潜在的な拡散プロセスを使用して意味概念を操作/生成することにより、生成モデリングを通じて知覚圧縮と意味圧縮を大まかに分解することを学習します。
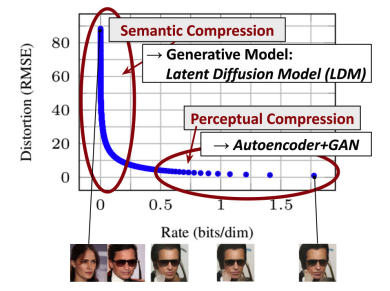
説明認識と意味圧縮
(知覚的および意味的圧縮を示す)
デジタル画像のほとんどの部分は、知覚できない細部に相当します。拡散モデルは、損失項を最小限に抑えることで、この意味的に意味のない情報を既に抑制していますが、それでもすべてのピクセルで勾配 (トレーニング中) とニューラル ネットワーク バックボーン (トレーニングと推論の両方) を評価する必要があり、これが冗長な計算と不必要なコストの増加につながります。最適化と推論。
したがって、DDIM 論文では、別個の光圧縮段階を備えた効率的な生成モデルとして潜在拡散モデル (LDM) を提案しています。
DDIM 対応の圧縮プロセスは、オートエンコーダー モデルに依存しています。エンコーダーは、入力画像 x∈R H×W×3 をより小さい 2D 潜在ベクトル z=ε(x)∈R h×w×cに圧縮するために使用されます。ここで、ダウンサンプリング レート f=H/h=W/w =2 m , m∈N の場合、デコーダ D は潜在ベクトル x ̃=D(z) から画像を再構成します。
拡散とノイズ除去のプロセスは潜在ベクトル Z 上で行われます。ノイズ除去モデルは、画像生成のための柔軟な条件情報 (カテゴリ ラベル、セマンティック マップ、画像のぼやけたバリアントなど) を処理するためのクロスアテンション メカニズムで強化された、時間的に条件付けされた U-Net です。この設計は、クロスアテンション メカニズムを介して、さまざまなモダリティの表現をモデルに融合することに相当します。各タイプのコンディショニング情報は、コンディショニング入力 y をクロスアテンション コンポーネント τ θ (y) ∈ R (M × dτ )にマッピングできる中間表現に投影するためのドメイン固有エンコーダ τθ とペアになります。
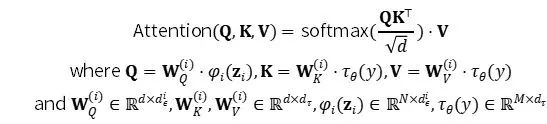

潜在拡散モデルのアーキテクチャ。(画像出典: Rombach & Blattmann, et al. 2022)
3. 拡散モデルの条件付き生成
条件付き生成
ImageNet データセットなどの情報に基づいて条件付けされた画像で生成モデルをトレーニングする場合、通常、サンプルはクラス ラベルまたは説明テキストから生成されます。
1
拡散モデルの分類子ガイダンス
分類子による誘導拡散
GLIDE 論文 (下の写真) は、拡散モデルの分類器ガイダンスの分野における最新の研究を紹介しています。

出典: https://arxiv.org/pdf/2112.10741.pdf
カテゴリ情報をモデル拡散プロセスに明示的に組み込むために、Dhariwal & Nichol (2021) はノイズのある画像 x tで 分類器 f ϕ (y|x t ,t) をトレーニングし、勾配 ∇ x logf ϕ (y |x t ) は、ノイズ予測を変更することによって、条件付き情報 y (オブジェクト クラス ラベルなど) に向けて拡散サンプリング プロセスをガイドします。結果として得られるアブレーション拡散モデル (ADM) と追加の分類子ガイダンスを備えたモデル (ADM-G) は、BigGAN などの SOTA 生成モデルよりも優れた結果を達成できます。
ダリワルとニコル (2021)
https://arxiv.org/abs/2105.05233

このアルゴリズムは、分類器からのガイダンスを使用して、DDPM および DDIM で条件付き生成を実行します。(画像出典: Dhariwal & Nichol、2021])
2
普及モデルのための授業不要のガイダンス
分類子を使用しないガイダンス
さらに、GLIDE の論文では、GLIDE からサンプルを選択するための分類子を使用しないガイダンスの使用についても説明されています。論文で提供されているサンプル画像データから、GLIDE モデルが影や反射を含むリアルな画像を生成できること、複数のコンセプトを組み合わせたり、新しいコンセプトの芸術的なレンダリングを生成したりできることがわかります。


出典: https://arxiv.org/pdf/2112.10741.pdf
GLIDE 論文では、ガイダンス戦略、CLIP ガイダンス、および未分類のガイダンスも詳細に検討されており、後者の方がより一般的であることがわかります。
4. 拡散モデルの高解像度・高画質
1
CDM ペーパー
論文「高忠実度画像生成のためのカスケード拡散モデル」では、一連の高解像度の複数拡散モデルが提案されています。パイプライン モデル間のノイズ コンディショニングの強化は、最終的な画質にとって非常に重要です。つまり、各超解像度モデル p θ
高忠実度画像生成のためのカスケード拡散モデル:
https://arxiv.org/abs/2106.15282

出典: https://arxiv.org/pdf/2106.15282.pdf
高解像度画像を生成するための拡散モデリングでは、モデル アーキテクチャとして U-Net が一般的に選択されます。この論文では、カスケード拡散モデルのパイプラインでは、各モデルが U-Net アーキテクチャを使用していると述べられています。以下に示すように:
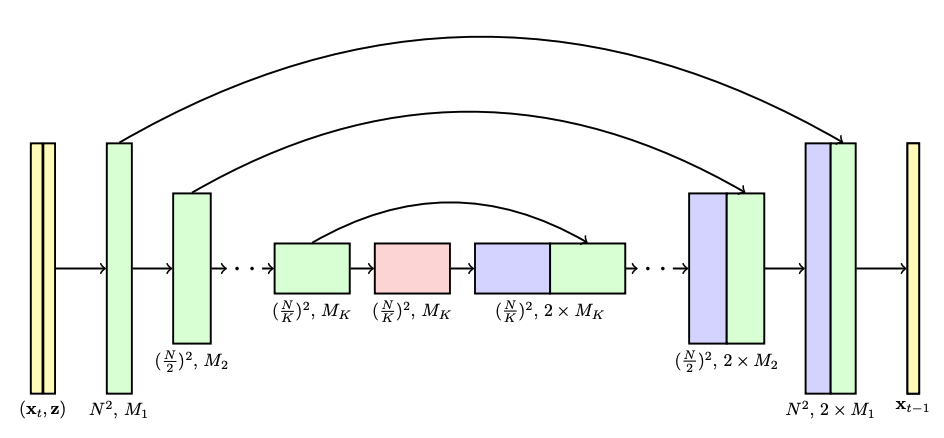
出典: https://arxiv.org/pdf/2106.15282.pdf
この論文では、最も効果的なノイズは低解像度で適用されるガウス ノイズと高解像度で適用されるガウス ブラーであることが判明したとも述べています。さらに、トレーニング手順に若干の変更を必要とする条件付き拡張の 2 つの形式を調査します。条件付きノイズはトレーニングにのみ役立ち、推論には役立ちません。
2
UnCLIP論文
2 段階拡散モデル UnCLIP (Ramesh et al. 2022) の論文では、CLIP テキスト エンコーダを利用して高品質のテキストガイド付き画像を生成することが提案されています。
ラメシュら。2022年
https://arxiv.org/abs/2204.06125

出典: https://arxiv.org/abs/2204.06125
事前トレーニング済みの CLIP モデル c と拡散モデル (x, y) のペアのトレーニング データが与えられると、x は画像、y は対応するキャプションとなり、CLIP のベクトル表現 Ct(y) と Ct(y) を計算できます。テキストと画像、それぞれ.i ( x) 。
UnCLIP は 2 つのモデルを同時に学習します。
以前のモデル p(ci | y): テキスト y を指定して、ci の CLIP イメージ ベクトル表現を出力します。
デコーダ p(x|ci , [y]) : CLIP 画像ベクトル表現 ci と (オプションで) 生のテキスト y を指定すると、画像 x を出力します。
これら 2 つのモデルは、次の理由により条件付き生成をサポートします。
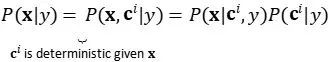
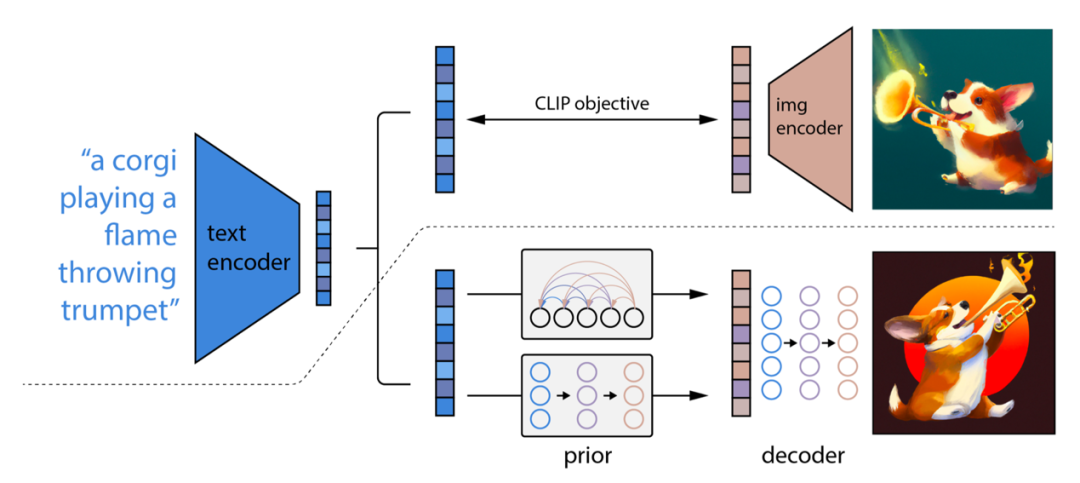
unCLIP のアーキテクチャ。(画像出典: Ramesh et al. 2022)
3
イマージェンの論文
Imagen の論文 Imagen (Saharia et al. 2022) では CLIP モデルを使用していませんが、事前にトレーニングされた大規模な LM (凍結された T5-XXL テキスト エンコーダー) を使用してテキストをエンコードし、画像を生成します。
サハリアら。2022年
https://arxiv.org/abs/2205.11487

出典: https://arxiv.org/pdf/2205.11487.pdf
一般的な傾向として、モデル サイズが大きいほど、画質とテキストと画像の位置合わせが向上します。この論文の研究チームは、T5-XXL と CLIP テキスト エンコーダが MS-COCO 上で同様のパフォーマンスを達成していることを発見しました。

出典: https://arxiv.org/pdf/2205.11487.pdf
Imagen は、U-net を効率的にするために U-net のいくつかの設計を変更しました。例えば:
低解像度の残留ロックを追加することで、高解像度モジュールから低解像度モジュールにモデル パラメーターを転送します。
スキップ接続のサイズを1/√2倍に拡張
ダウンサンプリング操作 (畳み込みの前に移動) とアップサンプリング操作 (畳み込みの後に移動) の順序を逆にして、フォワード パスの速度を向上させます。
論文チームの経験の概要には次のものが含まれます。
ノイズ調整の強化、動的なしきい値処理、効率的な U-Net は画質にとって重要です
テキスト エンコーダ サイズのスケーリングは U-Net サイズよりも重要です
まとめ
この号では、VAE、DDPM、DDIM、GLIDE、Imagen、UnCLIP、CDM、LDM、その他の主要な普及モデル分野を含む、Text-to-Image の方向での主要論文の解釈について議論を開始しました。
私たちの分析によると、普及モデルの主な利点と欠点は次のとおりです。
長所:トレーサビリティと柔軟性は、生成モデリングにおける 2 つの相反する目標です。扱いやすいモデルは分析的に評価でき、(ガウスやラプラシアンなどを介して) データを効率的に適合させることができますが、豊富なデータセットの構造を簡単に記述することはできません。柔軟なモデルはデータ内の任意の構造に適合できますが、多くの場合、これらのモデルの評価、トレーニング、またはサンプリングにはコストがかかります。拡散モデルは、分析におけるトレーサビリティと柔軟性の両方を実現できます。
短所:拡散モデルは、サンプルを生成するために長いマルコフ拡散ステップの連鎖に依存するため、時間と計算の点でコストがかかる可能性があります。プロセスを高速化する新しい方法がいくつかありますが、サンプリング速度は依然として GAN より遅いです。
「Generative AI New World | Vincent Graph フィールドの実践演習: 事前トレーニング済みモデルのデプロイメントと推論」では、実践的な演習セッションをご紹介します。Amazon Cloud Technology の Amazon SageMaker などのサービスを使用して、クラウド内の Text-to-Image 分野で大規模なモデルを構築するアプリケーションを体験できるようにご案内します。
開発者向けのテクノロジー共有やクラウド開発トレンドについて詳しく知るために、「Amazon Cloud Developer」 WeChat 公式アカウントに引き続きご注目ください。
この記事の著者

ホアン・ハオウェン
AI/ML、データサイエンスなどに重点を置く、Amazon クラウドテクノロジーのシニア開発者エバンジェリスト。電気通信、モバイル インターネット、クラウド コンピューティング業界におけるアーキテクチャ設計、テクノロジー、起業家経営における 20 年以上の豊富な経験を持ち、マイクロソフト、サン マイクロシステムズ、チャイナ テレコムなどの企業に勤務し、ゲームなどの企業クライアントへの提供に注力してきました。 eコマース、メディア、広告、AI/ML、データ分析、エンタープライズデジタルトランスフォーメーションなどのソリューションコンサルティングサービス。


聞いたので、下の 4 つのボタンをクリックしてください
バグに遭遇することはありません!
