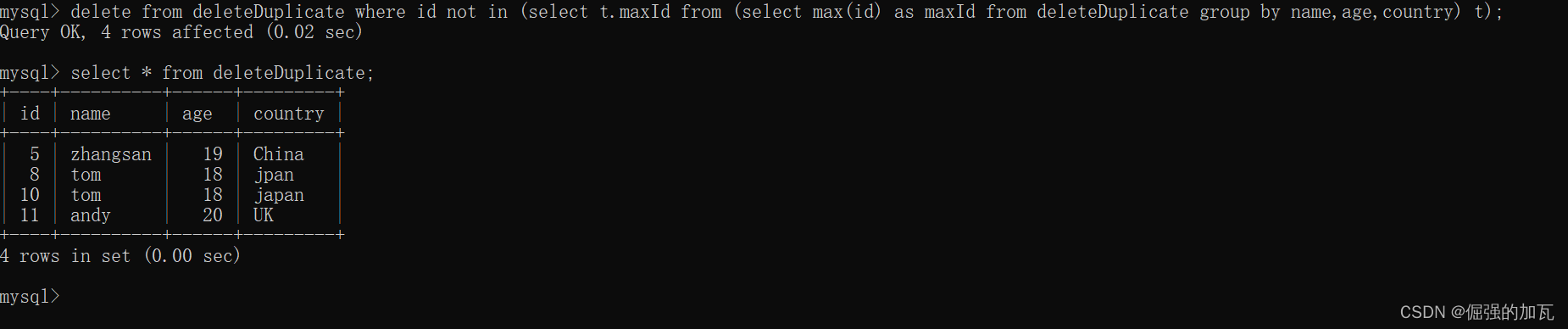
1 먼저 데모용 테이블을 만듭니다. 그림과 같이 먼저 테이블을 생성합니다.
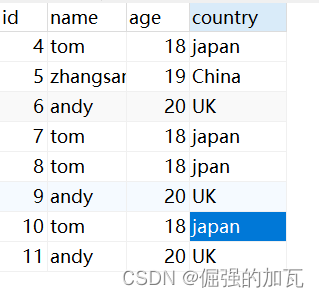
2 그런 다음 명령줄로 전환하여 데이터베이스의 테이블 내용을 확인하면 실제로 중복된 항목이 있습니다.
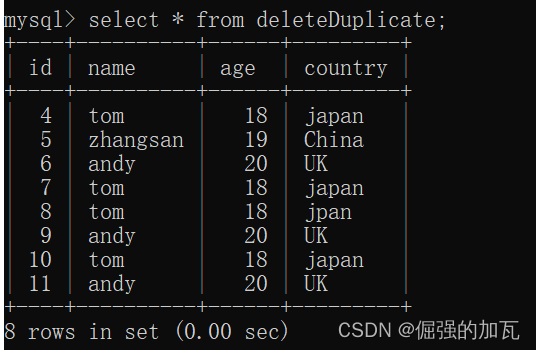
3 먼저 중복 행을 쿼리합니다.

4 이제 삭제하려는 것은 이 테이블에 나타나는 데이터이고, 각 그룹에서 가장 큰 ID를 가진 행만 유지하므로 가장 큰 행을 쿼리하려면 max 함수를 사용해야 하므로 먼저 이 ID가 무엇인지 알아보세요. 가장 큰 행에 없거나
 ID를 쿼리합니다. 이들의 최대값은
ID를 쿼리합니다. 이들의 최대값은

반복되지 않는 행에 포함되지 않으므로 삭제할 수 있습니다.
delete from deleteDuplicate where id not in (select t.maxId from (select max(id) as maxId from deleteDuplicate group by name,age,country) t);