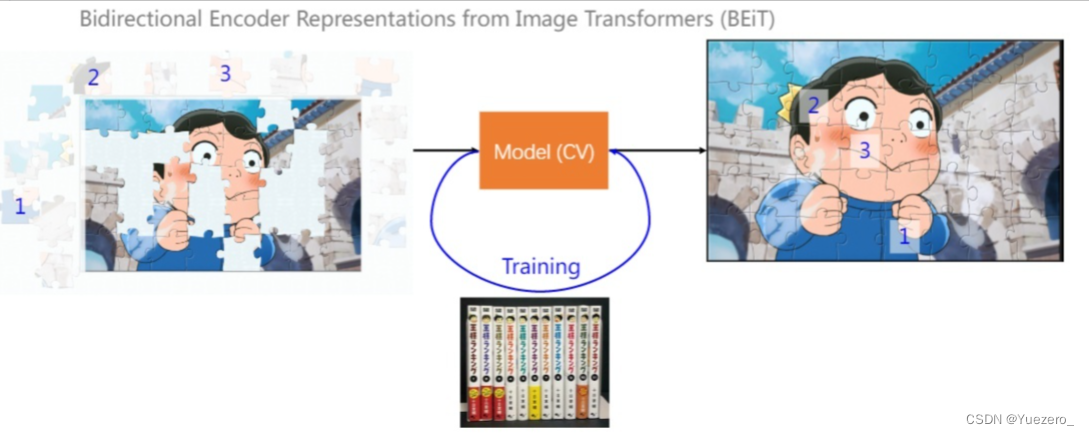
BEiT ist das erste Unternehmen, das das BERT-Modell erfolgreich im Bildbereich einsetzt. Es ist auch eine Form des selbstüberwachten Trainings und wird daher als BERT-Vortrainingsmodell von Visual Transformer bezeichnet. Diese Arbeit nutzt eine clevere Methode, um die Trainingsideen von BERT erfolgreich in der Bildaufgabe zu nutzen.
BERT : Bidiraktionale (双向) Encoder-Darstellungen von Transformers
SSL Selbstüberwachtes Lernen : Maschinelles Lernen ist in überwachtes Lernen, unüberwachtes Lernen und Verstärkungslernen, selbstüberwachtes Lernen und selbstüberwachtes Lernen unterteilt, das möglicherweise nicht direkt einer bestimmten Aufgabe gegenübersteht, unbeaufsichtigtes Vortraining und überwachte Feinabstimmung Es ist allgemeiner Natur und muss zur Bewältigung nachgelagerter Aufgaben (Downstream Tasks) geleitet werden.
1. BERT
BERT hat zwei Ziele: Das eine besteht darin, den fehlenden Teil vorherzusagen, und das andere darin, die Kontextsemantik vorherzusagen.
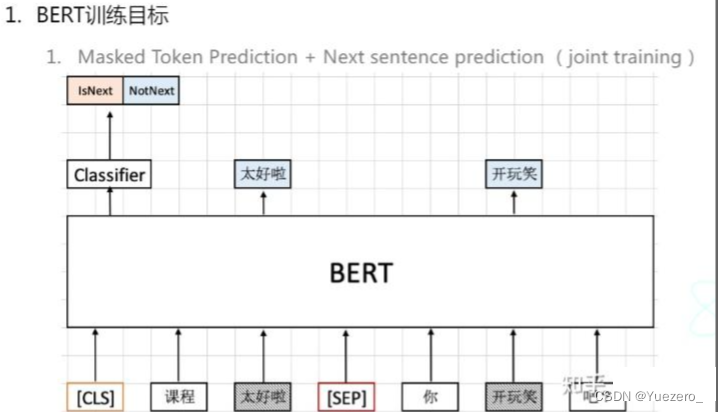
Selbstüberwachtes Lernen : Stellen Sie sich vor, einen Teil der Eingabe nicht zu sehen, und lernen Sie, ihn vorherzusagen. Vortäuschen bedeutet hier, diesen Teil (den gelöschten Teil) als Etikett zur Überwachung des Modells zu verwenden. Wenn Sie ein Bild verwenden, um es zu zeigen, ist es das Beispiel in der folgenden Abbildung. „Großartig“ wird gelöscht. Ich hoffe, dass das BERT-Modell lernen wird, die fehlenden Teile vorherzusagen. Es kann mehr als einen unsichtbaren Teil geben.

2. BeiT (BERT->CV)
Wie führt man SSL für ein Bild durch?
Die Eingabe wird zu einem Bild, von dem ein Teil sichtbar und ein Teil unsichtbar ist.