Artikelverzeichnis
Frühling
In der ursprünglichen Implementierung der Schichtarchitektur hängt die Controller-Schicht, die für die Beantwortung von Anfragen verantwortlich ist, von der Service-Schicht für die Verarbeitung der Geschäftslogik ab, und die Service-Schicht für die Verarbeitung der Geschäftslogik hängt von der Dao-Schicht für den Datenzugriff ab. Die obere und untere Schicht hängen bei der Kopplung voneinander ab. Der Nachteil der Kopplung besteht darin, dass sie den gesamten Körper betrifft, was der späteren Aufrechterhaltung und Erweiterung nicht förderlich ist.
Für die geschichtete Entkopplung verwendet Spring die IoC-Steuerungsumkehr und die DI-Abhängigkeitsinjektion, um das Kopplungsproblem zu lösen.

IoC-Kontrollumkehr
Die Idee von IoC (Inversion of Control) ist die Umkehrung der Kontrolle: Bei der Verwendung eines Objekts wird nicht mehr aktiv ein neues Objekt generiert, sondern in ein extern bereitgestelltes Objekt umgewandelt. Dabei wird die Kontrolle über die Objekterstellung übertragen das Programm nach außen.
- Die Spring-Technologie implementiert die IoC-Idee. Spring stellt einen Container bereit,
IoCder als Container bezeichnet wird und in der IoC-Idee als Container fungiert.“外部”的概念 - Der IoC-Container ist für eine Reihe von Aufgaben wie die Objekterstellung und -initialisierung verantwortlich, und die erstellten oder verwalteten Objekte werden
IoCim Container gemeinsam als bezeichnetBean
DI-Abhängigkeitsinjektion
Die IoC-Kontrollumkehr entspricht der Übergabe des Objekts an den Container zur Verwaltung, also dem Prozess vom Objekt zum Container, während DI (Dependency Dependency Injection) der Prozess ist, bei dem das entsprechende Objekt aus dem Container entnommen wird.
Bohne
Bean-Grundkonfiguration
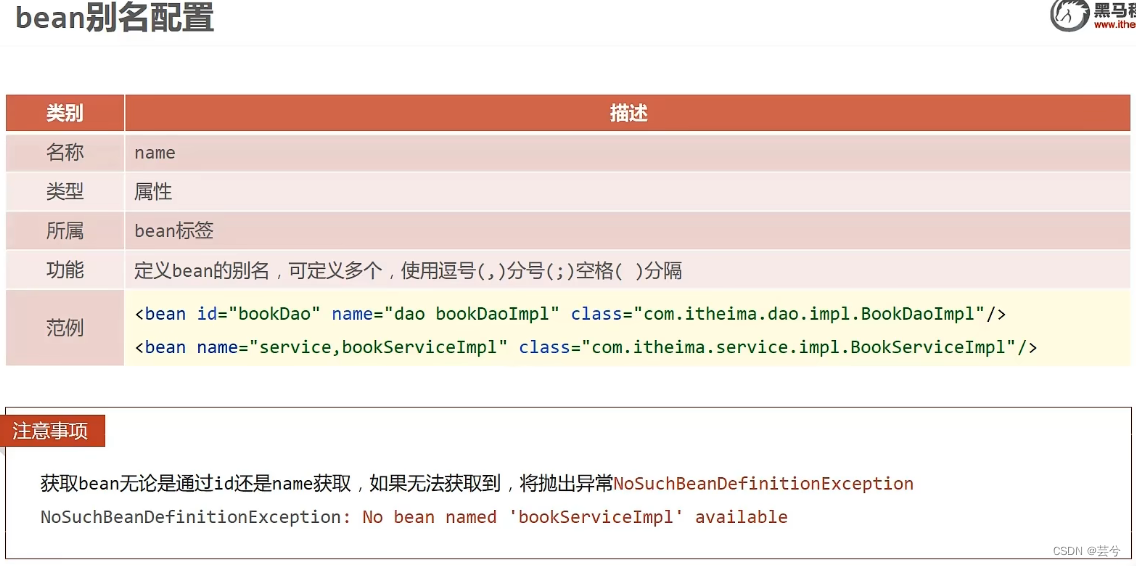
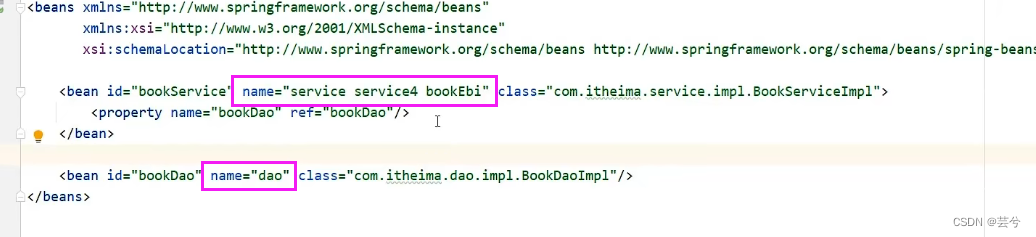
Name
Das Bean-Tag gibt den Namensattribut-Konfigurationsalias an:
Umfang
Das Bereichsattribut des Bean-Tags konfiguriert den Bereich der Bean. Der Standardwert des Bereichsattributs ist Singleton und das Bean-Objekt ist ein Singleton. Wenn Sie ein Nicht-Singleton-Objekt erstellen möchten, geben Sie den Attributwert als Prototyp an

Bean-Instanziierungsmethode
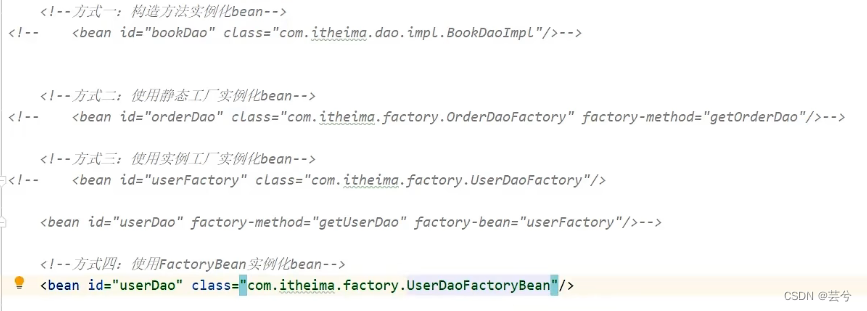
Die Essenz einer Bohne ist ein Objekt, das auf die folgenden vier Arten konstruiert werden kann:
- 1. Instanziieren Sie die Bean über die Konstruktionsmethode ohne Argumente (die Standardkonstruktionsmethode), sodass eine Klasse an den IoC-Container übergeben werden soll. Wenn die Konstruktionsmethode ohne Argumente nicht vorhanden ist, wird bei Bedarf eine Ausnahme ausgelöst um die Bohne zu konstruieren
BeanCreationException - 2. Verwenden Sie die statische Factory, um die Bean zu instanziieren, instanziieren Sie zuerst die statische Factory-Klasse und führen Sie dann die Produktionsmethode aus, deren Attributfeld der Factory-Methode die statische Factory ist.
- 3. Instanziieren Sie die Bean mithilfe der Instanzfabrik. Instanziieren Sie zuerst die Instanz-Factory-Klasse und geben Sie dann beim Instanziieren der Bean
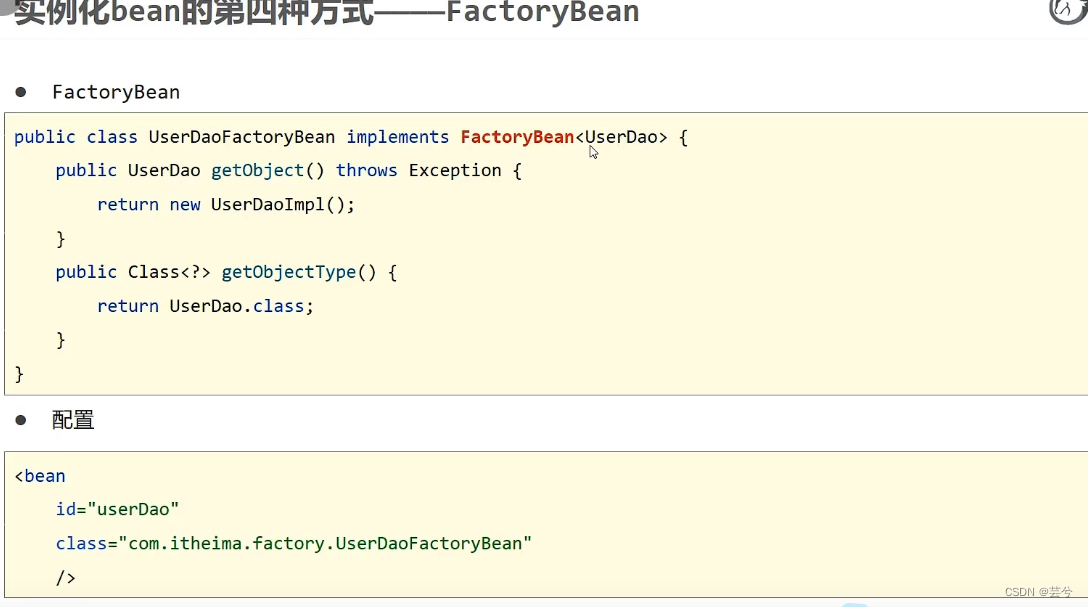
factory-methoddie Attribute und Attribute an.factory-bean - 4. Die Art und Weise, FactoryBean zu verwenden. Diese Methode ist im Wesentlichen die gleiche wie Methode 3, außer dass Spring uns Schnittstellenspezifikationen bereitstellt, um das Schreiben von Bean-Konfigurationen prägnanter zu gestalten.
Verwenden Sie zum Instanziieren die Factory-Methode, um die Erweiterung des Instanziierungsprozesses zu erleichtern
FactoryBean ist ein von Spring bereitgestellter Schnittstellenstandard.
Lebenszyklus einer Bohne
Wenn der Benutzer getBean für Prototype Bean die Instanz von Prototype Bean erhält, verwaltet der IOC-Container die aktuelle Instanz nicht mehr, sondern übergibt das Verwaltungsrecht an den Benutzer, und getBean generiert dann eine neue Instanz.
Wenn wir also den Lebenszyklus von Bean beschreiben, beziehen wir uns alle auf Singleton Bean.
Bohnenlebenszyklusprozess:
- Schritt 1: Instanziieren Sie ein Bean-Objekt und erstellen Sie es
- Schritt 2: Legen Sie zugehörige Eigenschaften und Abhängigkeiten für Bean fest; PropertiesSet
- Schritt 3, Initialisierung; init
- Schritt 4: Zerstören; zerstören
Es gibt zwei Möglichkeiten, die Lebenszyklus-Kontrollmethode der Bean festzulegen:
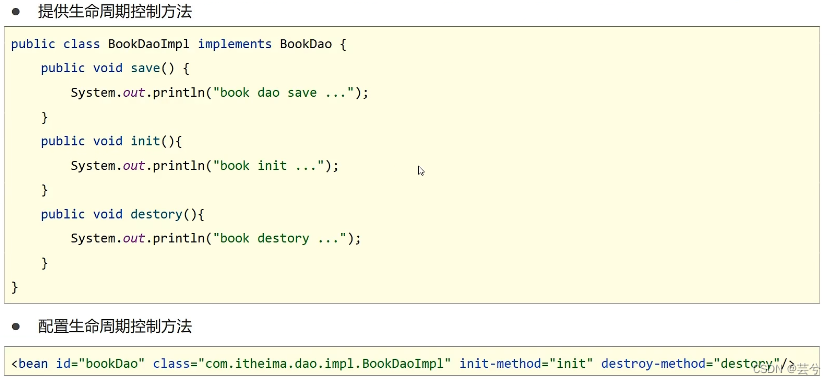
Die erste Methode: Stellen Sie zuerst die Lebenszyklus-Kontrollmethode in der Klasse bereit und geben Sie dann beim Konfigurieren der Bean die Init-Methode und die Destroy-Methode im Bean-Tag an.
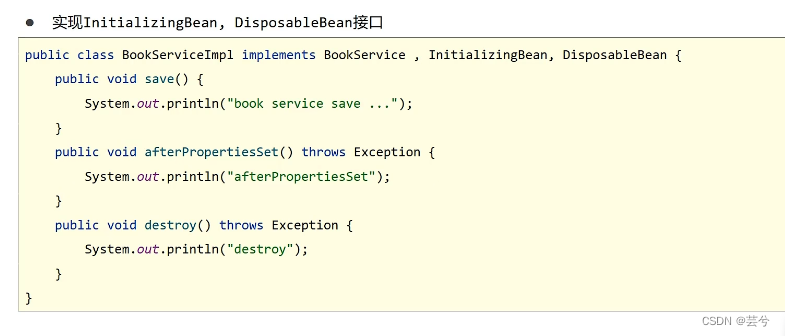
Der zweite Weg: durch Implementierung der von Spring bereitgestellten InitializingBean-Schnittstelle und DisposibleBean-Schnittstelle:
Die Reihenfolge des Lebenszyklus:
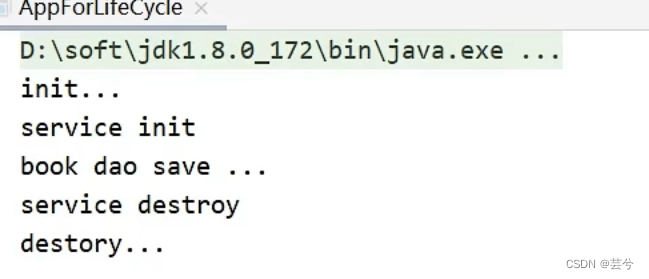
Aus dem Obigen können Sie ersehen, dass die Init-Methode und die Destroy-Methode im Bean-Tag einen größeren Umfang haben als die implementierte Schnittstellenmethode (zuerst Init, dann Destroy).
Hinweis: Um den Effekt der Zerstörung zu sehen, müssen wir den IOC-Container manuell schließen.
Der Weg zum Schließen des IOC-Containers kann über close()die Methode des Containers oder über registerShutdownHook()die Methode des Containers erfolgen.


Abhängigkeitsspritze
Stellen Sie eine set()-Methode bereit oder verwenden Sie einen Konstruktor.

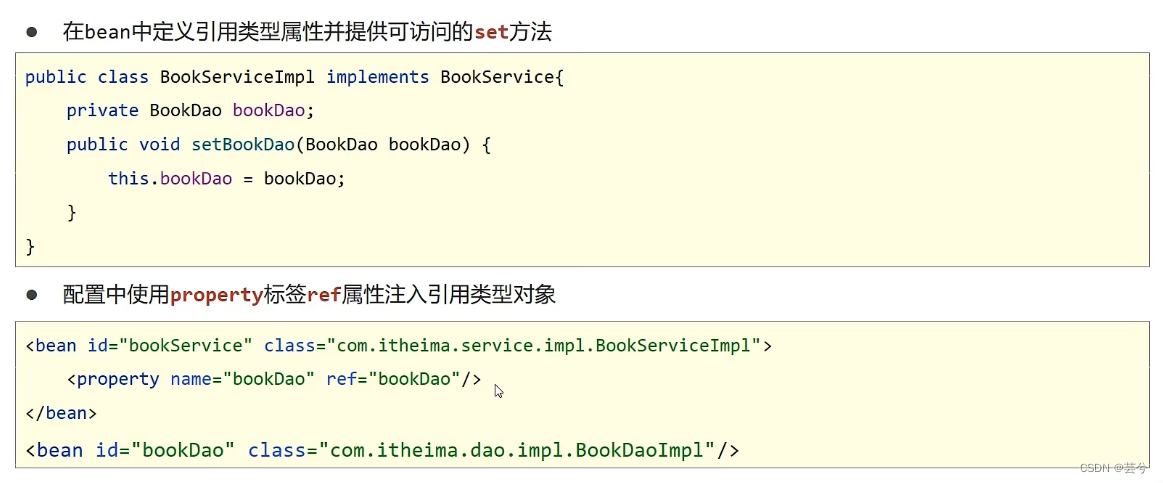
Fall 1: Verwenden Sie die Mengenabhängigkeit, um einen Referenztyp einzufügen.
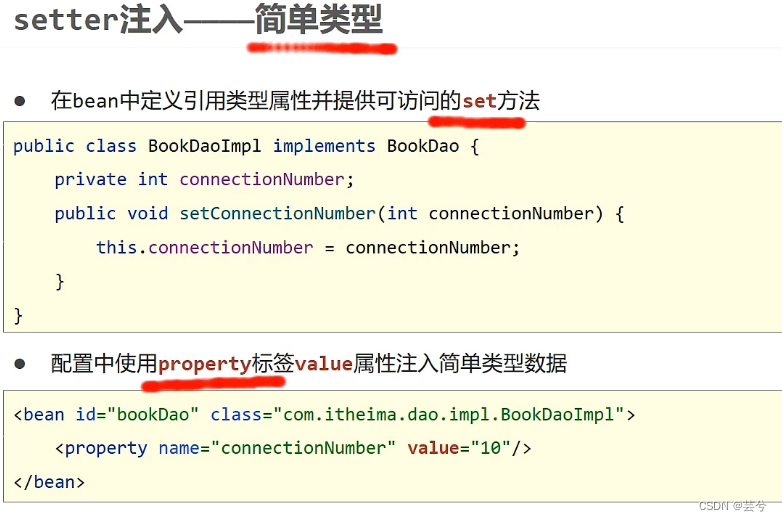
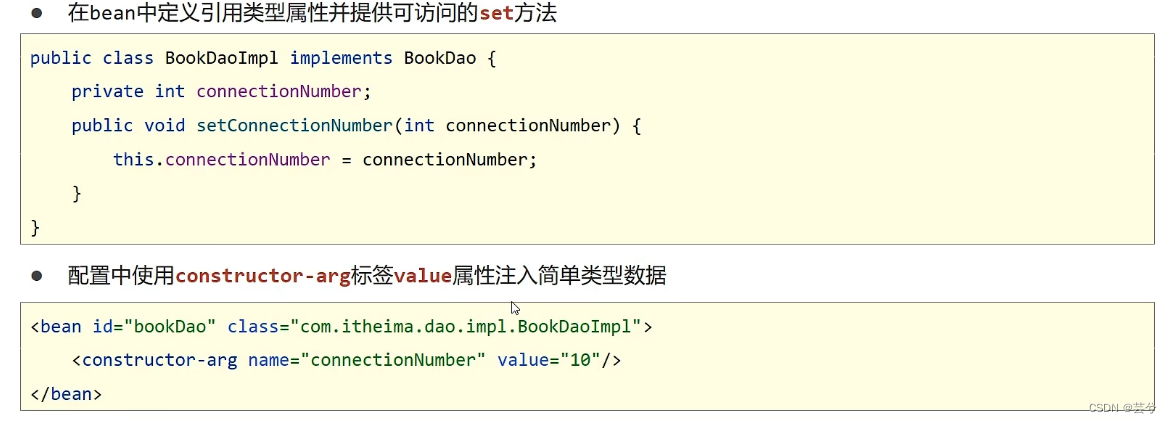
Fall 2: Set verwenden, um einfache Typen einzufügen.
Fall 3: Konstruktor verwenden, um einfache Typen einzufügen:
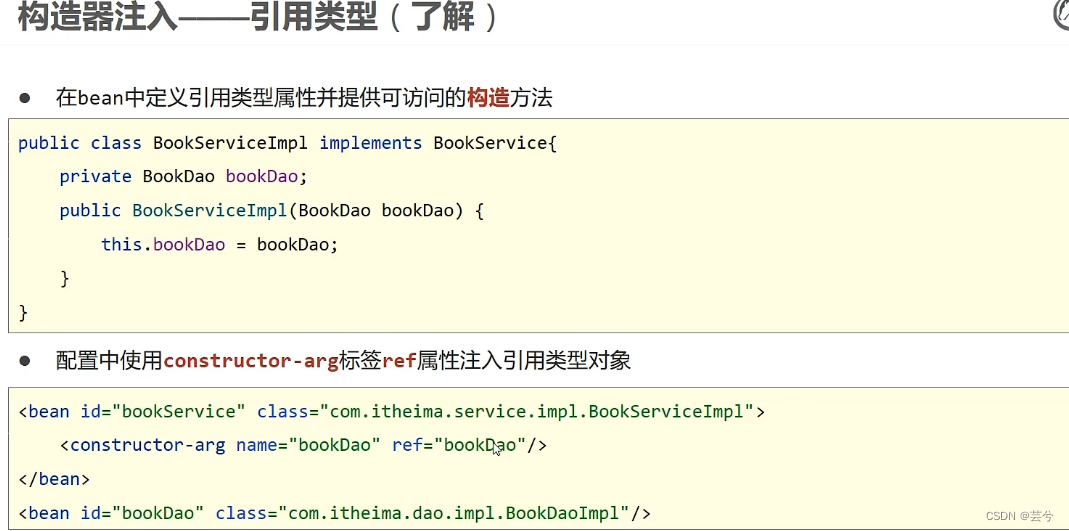
Im vierten Fall verwenden Sie den Konstruktor, um den Referenztyp einzufügen:

Automatische Abhängigkeitsverdrahtung
Das Bean-Tag wird automatisch mithilfe des Autowire-Attributs zusammengestellt, und

der Wert des Autowire-Attributs kann wie folgt ausgewählt werden:

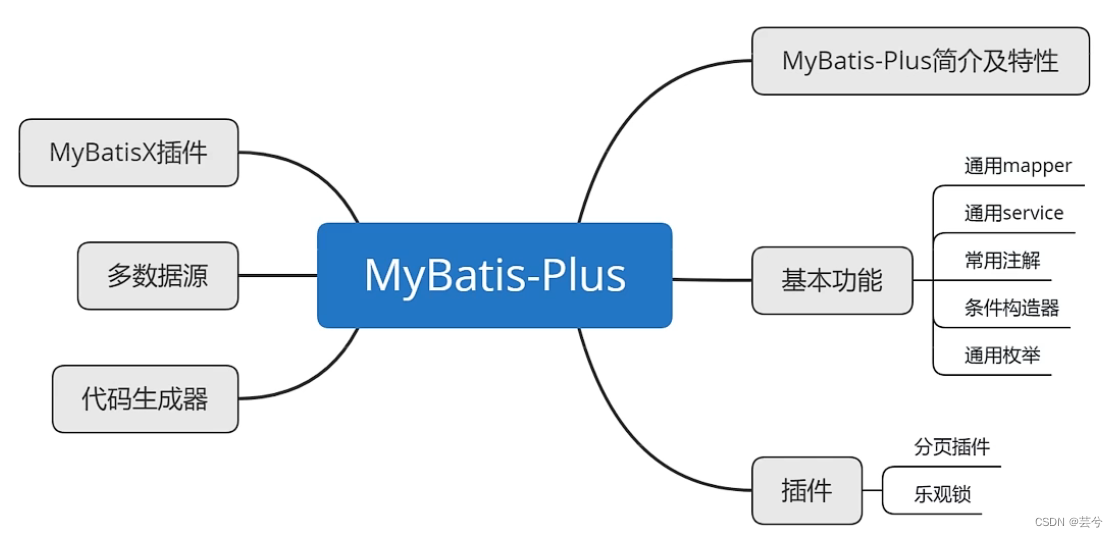
Mybatis-Plus
Mybatis-Plus ist ein Erweiterungstool für Mybatis. Basierend auf Mybatis werden nur Erweiterungen ohne Änderungen vorgenommen. Es soll die Entwicklung vereinfachen und Effizienz bieten.
Aufbau
Abhängigkeiten hinzufügen:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
Fügen Sie die Annotation @MapperScan zur Springboot-Startklasse hinzu, um das Mapper-Paket zu scannen.
@SpringBootApplication
@MapperScan("com.atguigu.mybatisplus.mapper")
public class MybatisplusApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisplusApplication.class, args);
}
}
Konfigurieren Sie die Protokollausgabe in application.yml:
# 配置MyBatis日志
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
BaseMapper
BaseMapper ist der von Mybatis-Plus bereitgestellte Vorlagen-Mapper, der grundlegende CRUD-Methoden enthält, und der generische Typ ist der Entitätstyp der Operation.
Nehmen Sie als Beispiel die Benutzerentität:
@Data //lombok注解
public class User {
private Long id;
private String name;
private Integer age;
private String email;
}
Wenn wir unseren eigenen Mapper schreiben, können wir diesen Vorlagen-Mapper erben.
public interface UserMapper extends BaseMapper<User> {
}
Zunahme:
@Test
public void testInsert(){
User user = new User(null, "张三", 23, "[email protected]");
//INSERT INTO user ( id, name, age, email ) VALUES ( ?, ?, ?, ? )
int result = userMapper.insert(user);
System.out.println("受影响行数:"+result);
//1475754982694199298
System.out.println("id自动获取:"+user.getId());
}
löschen:
@Test
public void testDeleteById(){
//通过id删除用户信息
//DELETE FROM user WHERE id=?
int result = userMapper.deleteById(1475754982694199298L);
System.out.println("受影响行数:"+result);
@Test
public void testDeleteBatchIds(){
//通过多个id批量删除
//DELETE FROM user WHERE id IN ( ? , ? , ? )
List<Long> idList = Arrays.asList(1L, 2L, 3L);
int result = userMapper.deleteBatchIds(idList);
System.out.println("受影响行数:"+result);
}
}
@Test
public void testDeleteByMap(){
//根据map集合中所设置的条件删除记录
//DELETE FROM user WHERE name = ? AND age = ?
Map<String, Object> map = new HashMap<>();
map.put("age", 23);
map.put("name", "张三");
int result = userMapper.deleteByMap(map);
System.out.println("受影响行数:"+result);
}
ändern:
@Test
public void testUpdateById(){
User user = new User(4L, "admin", 22, null);
//UPDATE user SET name=?, age=? WHERE id=?
int result = userMapper.updateById(user);
System.out.println("受影响行数:"+result);
}
überprüfen:
@Test
public void testSelectById(){
//根据id查询用户信息
//SELECT id,name,age,email FROM user WHERE id=?
User user = userMapper.selectById(4L);
System.out.println(user);
}
@Test
public void testSelectBatchIds(){
//根据多个id查询多个用户信息
//SELECT id,name,age,email FROM user WHERE id IN ( ? , ? )
List<Long> idList = Arrays.asList(4L, 5L);
List<User> list = userMapper.selectBatchIds(idList);
list.forEach(System.out::println);
}
@Test
public void testSelectByMap(){
//通过map条件查询用户信息
//SELECT id,name,age,email FROM user WHERE name = ? AND age = ?
Map<String, Object> map = new HashMap<>();
map.put("age", 22);
map.put("name", "admin");
List<User> list = userMapper.selectByMap(map);
list.forEach(System.out::println);
}
@Test
public void testSelectList(){
//查询所有用户信息
//SELECT id,name,age,email FROM user
List<User> list = userMapper.selectList(null);
list.forEach(System.out::println);
}
Üblicher Service
Beschreibung:
General Service CRUD kapselt die IService-Schnittstelle.Kapseln Sie CRUD weiter. Verwenden Sie die Benennungsmethode „Get Query Single Line“, „Remove List List“, „Set Page“, „Pagination Prefix“ und „Mapper Layer“, um Verwirrung zu vermeiden,
der generische Typ T ist ein beliebiges Entitätsobjekt.
Wenn die Möglichkeit besteht, die allgemeine Service-Methode anzupassen, wird empfohlen, einen eigenen IBaseService zu erstellen, um die
von Mybatis-Plus bereitgestellte Basisklasse zu erben. Offizielle
Website-Adresse: https://baomidou .com/pages/49cc81/#service-crud-%E6%8E%A5%E5%8F%
A3
Zu verwendende Schritte:
1. Erstellen Sie eine Serviceschnittstelle und eine Implementierungsklasse.
/**
* UserService继承IService模板提供的基础功能
*/
public interface UserService extends IService<User> {
}
/**
* ServiceImpl实现了IService,提供了IService中基础功能的实现
* 若ServiceImpl无法满足业务需求,则可以使用自定的UserService定义方法,并在实现类中实现
*/
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements
UserService {
}
Anwendungsfälle:
1. Testen Sie die Anzahl der Abfragedatensätze:
@Autowired
private UserService userService;
@Test
public void testGetCount(){
long count = userService.count();
System.out.println("总记录数:" + count);
}
2. Teststapeleinfügung:
@Test
public void testSaveBatch(){
// SQL长度有限制,海量数据插入单条SQL无法实行,
// 因此MP将批量插入放在了通用Service中实现,而不是通用Mapper
ArrayList<User> users = new ArrayList<>();
for (int i = 0; i < 5; i++) {
User user = new User();
user.setName("ybc" + i);
user.setAge(20 + i);
users.add(user);
}
//SQL:INSERT INTO t_user ( username, age ) VALUES ( ?, ? )
userService.saveBatch(users);
}
Allgemeine Hinweise
@Tabellenname
Bei der Verwendung von MyBatis-Plus zur Implementierung von grundlegendem CRUD haben wir die zu bedienende Tabelle nicht angegeben, sondern
den generischen Benutzer festgelegt, als die Mapper-Schnittstelle BaseMapper geerbt hat und die betriebene Tabelle die Benutzertabelle ist
. Daraus wird geschlossen, dass MyBatis- Außerdem wird bei der Bestimmung der zu bedienenden Tabelle der generische Typ von BaseMapper, also der Entitätstyp, bestimmt,
und der Tabellenname der Standardoperation stimmt mit dem Klassennamen des Entitätstyps überein
Welche Probleme treten auf, wenn der Klassenname des Entitätsklassentyps nicht mit dem Tabellennamen der zu bedienenden Tabelle übereinstimmt?
Benennen Sie den Tabellenbenutzer in t_user um und testen Sie die Abfragefunktion. Es tritt dann ein Fehler auf.
An dieser Stelle können wir die Annotation @TableName verwenden, um den Namen der Tabelle anzugeben, an der gearbeitet werden soll:

Sie können auch die globale Konfiguration verwenden:
Während des Entwicklungsprozesses treten häufig die oben genannten Probleme auf, dh die den Entitätsklassen entsprechenden Tabellen haben feste Präfixe wie t_ oder tbl_.
Zu diesem Zeitpunkt können Sie die von MyBatis bereitgestellte globale Konfiguration verwenden -Legen Sie außerdem das Standardpräfix für den Tabellennamen fest, der der Entitätsklasse entspricht. Dann ist es
nicht erforderlich, die der Entitätsklasse entsprechende Tabelle über @TableName für jede Entitätsklasse zu identifizieren
Dann können Sie die Konfiguration von mybatis-plus in application.yml verwenden:
mybatis-plus:
configuration:
# 配置MyBatis日志
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
# 配置MyBatis-Plus操作表的默认前缀
table-prefix: t_
@TableId
Wenn MyBatis-Plus CRUD implementiert, wird die ID standardmäßig als Primärschlüsselspalte verwendet, und beim Einfügen von Daten wird die ID standardmäßig basierend auf der Strategie des Snowflake-Algorithmus generiert.
Wenn der in der Entitätsklasse und Tabelle dargestellte Primärschlüssel nicht die ID, sondern andere Felder wie die UID ist, müssen Sie die Annotation @TableId verwenden, um den Primärschlüssel für das Attribut zu identifizieren, das durch den Primärschlüssel der Entitätsklasse dargestellt wird: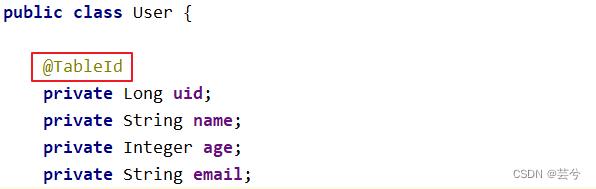
Das Wertattribut von @TableId
Wenn das Attribut, das dem Primärschlüssel in der Entitätsklasse entspricht, eine ID ist und das Feld, das den Primärschlüssel in der Tabelle darstellt, eine UID ist. Wenn zu diesem Zeitpunkt nur die Annotation @TableId zur Attribut-ID hinzugefügt wird, tritt eine Ausnahme auf. Unbekannte Spalte
' id‘ in ‚field list‘ wird geworfen, das heißt, MyBatis-Plus verwendet weiterhin
id als Primärschlüssel der Tabelle, und der Primärschlüssel in der Tabelle ist die Feld-UID.
Zu diesem Zeitpunkt müssen Sie den Wert übergeben Attribut der @TableId-Annotation zur Angabe des Primärschlüsselfelds in der Tabelle, @TableId("uid") oder
@TableId (value="uid")
Das Typattribut von @TableId
Das Typattribut wird verwendet, um die Primärschlüsselstrategie zu definieren
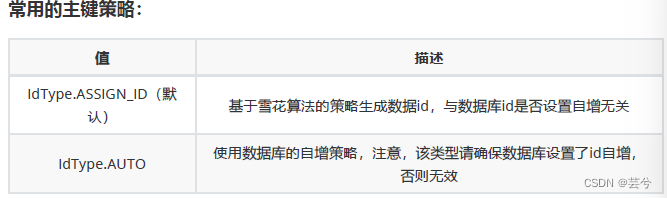
und die globale Primärschlüsselstrategie zu konfigurieren:
mybatis-plus:
configuration:
# 配置MyBatis日志
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
# 配置MyBatis-Plus操作表的默认前缀
table-prefix: t_
# 配置MyBatis-Plus的主键策略
id-type: auto
Schneeflocken-Algorithmus
Es ist notwendig, eine geeignete Methode zu wählen, um mit dem Wachstum des Datenumfangs umzugehen und den allmählich zunehmenden Zugriffsdruck und das Datenvolumen zu bewältigen. Zu den Erweiterungsmethoden der Datenbank gehören hauptsächlich: Geschäftsunterdatenbank, Master-Slave-Replikation und Datenbankuntertabelle.
- Vertikale Tabellenaufteilung
Die vertikale Tabellenaufteilung eignet sich zum Aufteilen einiger Spalten, die nicht häufig verwendet werden und viel Platz in der Tabelle beanspruchen.
Angenommen, wir sind beispielsweise eine Dating-Website für die Felder „Spitzname“ und „Beschreibung“ im vorherigen schematischen Diagramm. Wenn Benutzer andere Benutzer filtern, verwenden sie hauptsächlich die beiden Felder „Alter“
und „Geschlecht“ für die Abfrage, während die beiden Felder „Spitzname“ und „Beschreibung“ für die Abfrage verwendet werden Wird hauptsächlich zur Anzeige verwendet und
im Allgemeinen nicht für Geschäftsabfragen verwendet. Die Beschreibung selbst ist relativ lang, sodass wir diese beiden Felder in eine andere Tabelle aufteilen können
, sodass bei der Abfrage von Alter und Geschlecht eine gewisse Leistungsverbesserung erzielt werden kann. - Horizontale Tabellenunterteilung
Die horizontale Tabellenunterteilung eignet sich für Tabellen mit besonders vielen Zeilen. Einige Unternehmen verlangen eine Tabellenunterteilung, wenn die Anzahl der Zeilen in einer einzelnen Tabelle 50 Millionen überschreitet. Diese Zahl kann als Referenz verwendet werden, ist aber keine
Referenz absoluter Standard. Der Schlüssel liegt darin, die Tabellenzugriffsleistung zu betrachten. Bei einigen komplexeren Tabellen kann
die Aufteilung der Tabelle mehr als 10 Millionen betragen, und bei einigen einfachen Tabellen ist eine Aufteilung der Tabelle nicht erforderlich, selbst wenn die gespeicherten Daten 100 Millionen Zeilen überschreiten.
Im Vergleich zur vertikalen Tabellenpartitionierung führt die horizontale Tabellenpartitionierung zu mehr Komplexität, z. B. bei der Handhabung der Anforderung einer global eindeutigen Daten-ID- Automatische Inkrementierung des Primärschlüssels
Am Beispiel der häufigsten Benutzer-ID kann sie nach dem Bereich 1000000 segmentiert werden, 1 bis 999999 werden in Tabelle 1 eingetragen, 1000000 bis 1999999 werden in Tabelle 2 eingetragen und so weiter. Der Nachteil dabei ist, dass die Verteilung ungleichmäßig sein kann. Es ist möglich, dass ein Segment tatsächlich nur 1 Datenelement speichert, während ein anderes
Segment tatsächlich 10 Millionen Datenelemente speichert. - Der Modulus
nimmt auch die Benutzer-ID als Beispiel. Wenn wir von Anfang an 10 Datenbanktabellen planen, können wir einfach den Wert von user_id % 10 verwenden, um die Datenbanktabellennummer anzugeben, zu der die Daten gehören. In der Untertabelle wird die Der Benutzer mit der ID 10086 wird in die Untertabelle mit der Nummer 6 eingefügt. Der Vorteil dieser Methode besteht darin, dass die Tabellenverteilung relativ gleichmäßig ist. Der Nachteil besteht jedoch darin, dass das Erweitern der neuen Tabelle sehr mühsam ist und alle Daten neu verteilt werden müssen. - Snowflake-Algorithmus
Der Snowflake-Algorithmus ist ein von Twitter veröffentlichter verteilter Primärschlüssel-Generierungsalgorithmus, der sicherstellen kann, dass Primärschlüssel in verschiedenen Tabellen nicht dupliziert werden und die Reihenfolge derselben Tabelle gewährleistet ist.
- Automatische Inkrementierung des Primärschlüssels
Prinzip des Snowflake-Algorithmus:

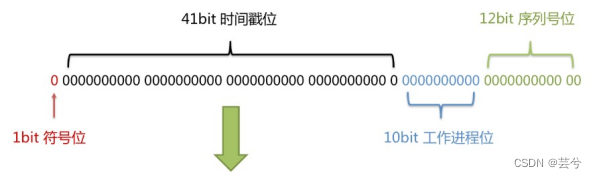
Vorteile des Snowflake-Algorithmus: Insgesamt werden sie nach Zeitinkrement sortiert, und im gesamten verteilten System kommt es zu keiner ID-Kollision, sodass die Effizienz hoch ist.
@TableField
Wenn MyBatis-Plus SQL-Anweisungen ausführt, muss sichergestellt werden, dass die Attributnamen in der Entitätsklasse
mit den Feldnamen in der Tabelle übereinstimmen.
Welche Probleme treten auf, wenn die Attributnamen in der Entitätsklasse nicht mit den Feldnamen übereinstimmen?
Fall 1:
Wenn das Attribut in der Entitätsklasse den Buckel-Benennungsstil verwendet und das Feldattribut in der Tabelle den Unterstrich-Benennungsstil verwendet, wenn beispielsweise das Entitätsklassenattribut userName das Feld user_name in der Tabelle ist, wird MyBatis-Plus dies tun Konvertieren Sie den Unterstrich-Benennungsstil automatisch in camelCase. Der Benennungsstil entspricht der Konfiguration in MyBatis.
Fall 2:
Wenn die Attribute in der Entitätsklasse und die Felder in der Tabelle Fall 1 nicht erfüllen, z. B. das Attribut der Entitätsklasse Name ist und das Feld in der Tabelle Benutzername ist, müssen Sie @ verwenden TableFile("username") setzt das Attribut auf das Attribut der Entitätsklasse. Der entsprechende Feldname.
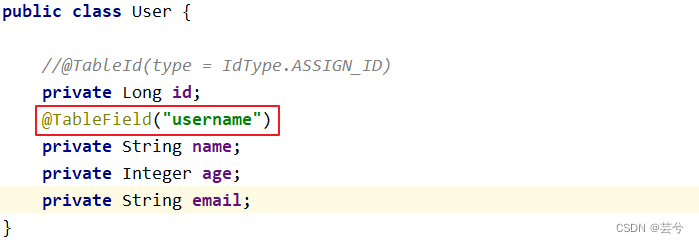
@TableLogic
- Physische Löschung: Echte Löschung, die entsprechenden Daten werden aus der Datenbank gelöscht und die gelöschten Daten können anschließend nicht mehr abgefragt werden
- Logisches Löschen: Falsches Löschen. Ändern Sie den Status des Felds, das angibt, ob es in den entsprechenden Daten gelöscht wurde, in „Status gelöscht“, und
dieser Datensatz ist dann weiterhin in der Datenbank sichtbar - Nutzungsszenario: Datenwiederherstellung ist möglich
Schritte zum Implementieren des logischen Löschens:
Schritt 1: Erstellen Sie ein logisches Löschstatusfeld in der Datenbank und legen Sie den Standardwert auf 0 fest
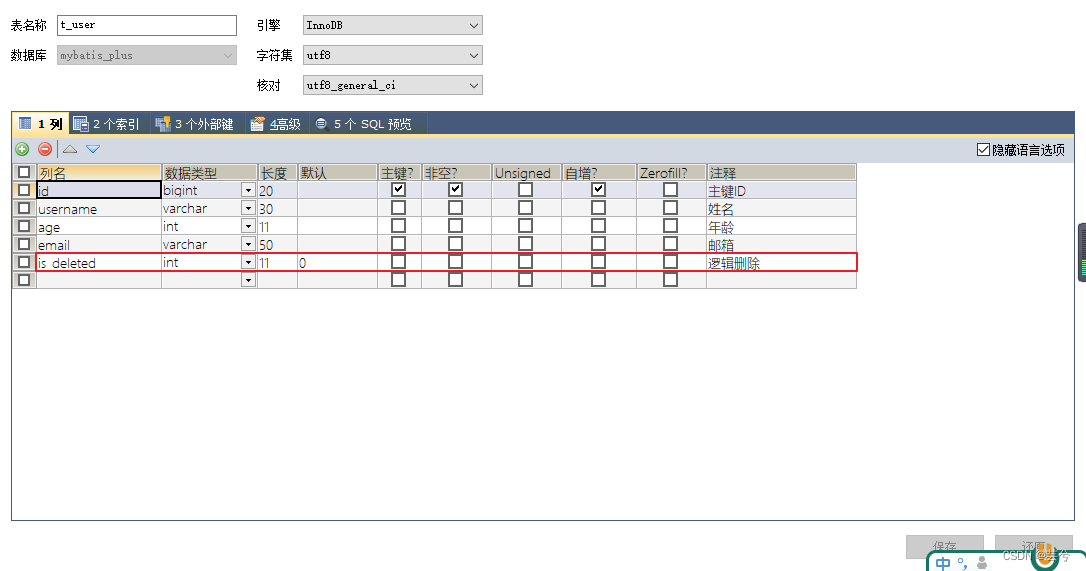
Schritt 2: Fügen Sie das logische Löschattribut zur Entitätsklasse hinzu und fügen Sie die Annotation @TableLogic hinzu
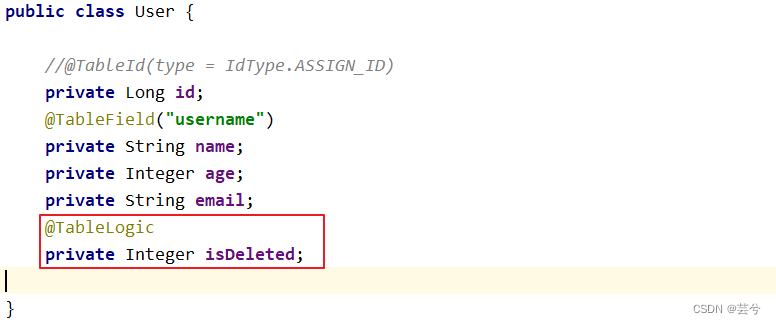
Schritt 3: Testen Um die Löschfunktion zu testen , besteht die eigentliche Ausführung darin
, UPDATE t_user SET is_deleted=1 WHERE id=? AND is_deleted=0 zu ändern
, um die Abfragefunktion zu testen. Die logisch gelöschten Daten werden standardmäßig nicht abgefragt
SELECT id, Benutzername AS Name, Alter, E-Mail, is_deleted FROM t_user WHERE is_deleted=0
Bedingte Konstruktoren und gemeinsame Schnittstellen
Wrapper: bedingt konstruierte abstrakte Klasse, die oberste übergeordnete Klasse. Helfen Sie uns, die Bedingungen für das Hinzufügen, Löschen, Ändern und Überprüfen zu schaffen.
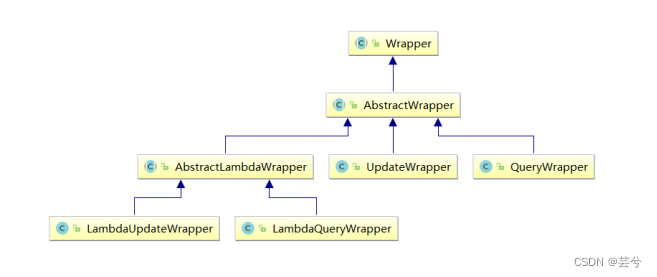
QueryWrapper
Beispiel 1: Abfragebedingungen zusammenstellen:
@Test
public void test01(){
//查询用户名包含a,年龄在20到30之间,并且邮箱不为null的用户信息
//SELECT id,username AS name,age,email,is_deleted FROM t_user WHERE
is_deleted=0 AND (username LIKE ? AND age BETWEEN ? AND ? AND email IS NOT NULL)
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.like("username", "a")
.between("age", 20, 30)
.isNotNull("email");
List<User> list = userMapper.selectList(queryWrapper);
list.forEach(System.out::println);
}
Beispiel 2: Zusammenstellen einer Sortierbedingung
UpdateWrapper
Plug-in
MyBatis Plus verfügt über ein eigenes Paging-Plug-in, das die Paging-Funktion durch einfache Konfiguration realisieren kann.
Zu verwendende Schritte:
1. Konfigurationsklasse hinzufügen
@Configuration
@MapperScan("com.atguigu.mybatisplus.mapper") //可以将主类中的注解移到此处
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new
PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
2. Testen
@Test
public void testPage(){
//设置分页参数
Page<User> page = new Page<>(1, 5);
userMapper.selectPage(page, null);
//获取分页数据
List<User> list = page.getRecords();
list.forEach(System.out::println);
System.out.println("当前页:"+page.getCurrent());
System.out.println("每页显示的条数:"+page.getSize());
System.out.println("总记录数:"+page.getTotal());
System.out.println("总页数:"+page.getPages());
System.out.println("是否有上一页:"+page.hasPrevious());
System.out.println("是否有下一页:"+page.hasNext());
}