Directorio de artículos
El uso y principio de Timer en JDK
Uso del temporizador
Programar tareas puntuales
Ejecutar después de un retraso específico
@Test
public void givenUsingTimer_whenSchedulingTaskOnce_thenCorrect() {
TimerTask task = new TimerTask() {
public void run() {
System.out.println("Task performed on: " + new Date() + "n" +
"Thread's name: " + Thread.currentThread().getName());
}
};
Timer timer = new Timer("Timer");
long delay = 1000L;
timer.schedule(task, delay);
}
Ejecutar a la hora especificada
Cuando el segundo parámetro es Datos, significa ejecutar en la fecha especificada.

Digamos que tenemos una base de datos heredada antigua y queremos migrar sus datos a una nueva base de datos con un esquema mejor. Podemos crear una clase DatabaseMigrationTask para manejar esa migración:
public class DatabaseMigrationTask extends TimerTask {
private List<String> oldDatabase;
private List<String> newDatabase;
public DatabaseMigrationTask(List<String> oldDatabase, List<String> newDatabase) {
this.oldDatabase = oldDatabase;
this.newDatabase = newDatabase;
}
@Override
public void run() {
newDatabase.addAll(oldDatabase);
}
}
Para simplificar, representamos ambas bases de datos como listas de cadenas. En pocas palabras, nuestra migración consiste en colocar los datos de la primera lista en la segunda lista. Para ejecutar esta migración en el momento deseado, tenemos que usar la versión sobrecargada del método Schedule():
List<String> oldDatabase = Arrays.asList("Harrison Ford", "Carrie Fisher", "Mark Hamill");
List<String> newDatabase = new ArrayList<>();
LocalDateTime twoSecondsLater = LocalDateTime.now().plusSeconds(2);
Date twoSecondsLaterAsDate = Date.from(twoSecondsLater.atZone(ZoneId.systemDefault()).toInstant());
new Timer().schedule(new DatabaseMigrationTask(oldDatabase, newDatabase), twoSecondsLaterAsDate);
Le damos la tarea de migración y la fecha de ejecución al método Schedule(). Luego, ejecuta la migración en el momento indicado por twoSecondsLater:
while (LocalDateTime.now().isBefore(twoSecondsLater)) {
assertThat(newDatabase).isEmpty();
Thread.sleep(500);
}
assertThat(newDatabase).containsExactlyElementsOf(oldDatabase);
Programar tareas repetibles
La clase Timer ofrece varias posibilidades: podemos configurar la repetición para que observe un retraso fijo o una frecuencia fija.
- Retraso fijo: significa que la ejecución comenzará algún tiempo después de que comenzó la última ejecución, incluso si se retrasa (y, por lo tanto, se retrasa). Digamos que queremos programar una tarea cada dos segundos, la primera ejecución demora un segundo y la segunda ejecución demora dos segundos, pero con un retraso de un segundo. Luego, la tercera ejecución comenzará a partir del quinto segundo.
Programemos un boletín informativo segundo a segundo:
public class NewsletterTask extends TimerTask {
@Override
public void run() {
System.out.println("Email sent at: "
+ LocalDateTime.ofInstant(Instant.ofEpochMilli(scheduledExecutionTime()),
ZoneId.systemDefault()));
}
}
Cada vez que se ejecuta, la tarea imprime su hora programada, que recopilamos utilizando el método TimerTask#scheduledExecutionTime(). Entonces, ¿qué pasa si queremos programar esta tarea cada segundo en modo de retraso fijo? Tenemos que usar la versión sobrecargada de Schedule() mencionada anteriormente:
new Timer().schedule(new NewsletterTask(), 0, 1000);
for (int i = 0; i < 3; i++) {
Thread.sleep(1000);
}
Por supuesto, sólo probamos en algunos casos:
Correo electrónico enviado a: 2020-01-01T10:50:30.860
Correo electrónico enviado a: 2020-01-01T10:50:31.860
Correo electrónico enviado a: 2020-01-01T10:50:32.861
Correo electrónico enviado a: 2020-01-01T10:50 :33.861
Hay al menos un segundo entre cada ejecución, pero a veces hay un retraso de milisegundos. Este comportamiento se debe a nuestra decisión de repetir con un retraso fijo.
- Frecuencia fija: significa que cada ejecución se ajustará al cronograma inicial, independientemente de si las ejecuciones anteriores se retrasaron. Reutilicemos el ejemplo anterior, con una frecuencia fija, la segunda tarea comenzará después de 3 segundos (debido al retraso). Sin embargo, la tercera ejecución después de cuatro segundos (con respecto al cronograma inicial de ejecución cada dos segundos).
Para programar una tarea diaria:
@Test
public void givenUsingTimer_whenSchedulingDailyTask_thenCorrect() {
TimerTask repeatedTask = new TimerTask() {
public void run() {
System.out.println("Task performed on " + new Date());
}
};
Timer timer = new Timer("Timer");
long delay = 1000L;
long period = 1000L * 60L * 60L * 24L;
timer.scheduleAtFixedRate(repeatedTask, delay, period);
}
Cancelar agenda y tareas
Llame al método TimerTask.cancel() en la implementación del método run() del propio TimerTask
@Test
public void givenUsingTimer_whenCancelingTimerTask_thenCorrect()
throws InterruptedException {
TimerTask task = new TimerTask() {
public void run() {
System.out.println("Task performed on " + new Date());
cancel();
}
};
Timer timer = new Timer("Timer");
timer.scheduleAtFixedRate(task, 1000L, 1000L);
Thread.sleep(1000L * 2);
}
Cancelar el temporizador:
llame a Timer.cancel()
@Test
public void givenUsingTimer_whenCancelingTimer_thenCorrect()
throws InterruptedException {
TimerTask task = new TimerTask() {
public void run() {
System.out.println("Task performed on " + new Date());
}
};
Timer timer = new Timer("Timer");
timer.scheduleAtFixedRate(task, 1000L, 1000L);
Thread.sleep(1000L * 2);
timer.cancel();
}
Grupo de subprocesos de tareas de sincronización
Estructura de cuarzo
Quartz es un marco de programación de tareas liviano que solo necesita definir Trabajo (tarea), Activador (activador) y Programador (programador) para realizar una capacidad de programación programada. Admite el modo de clúster basado en bases de datos, que puede lograr una ejecución idempotente de tareas.
Descripción de la clase principal
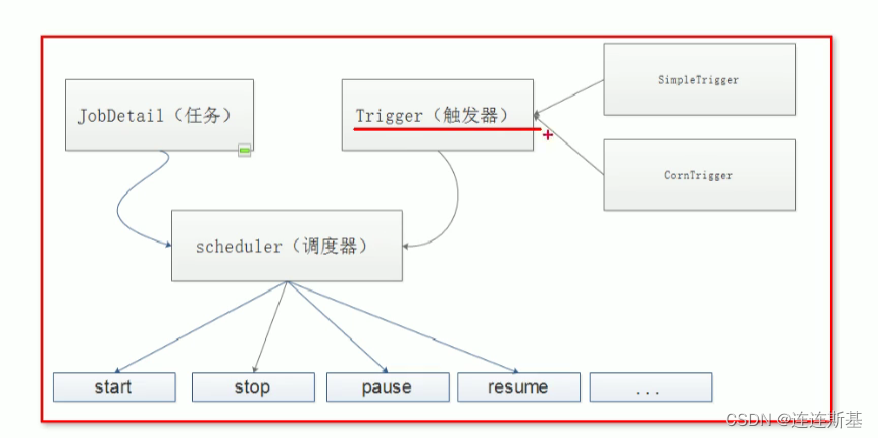
- Programador: Programador. Toda la programación está controlada por él, es el cerebro de Quartz y todas las tareas las gestiona él.
- Trabajo: tareas, cosas que desea ejecutar con regularidad (definir la lógica empresarial)
- JobDetail: basado en el trabajo, empaquetado adicional que asocia un trabajo y especifica atributos más detallados para el trabajo, como identificación, etc.
- Gatillo: Gatillo. Se puede asignar a una tarea, especificar el mecanismo de activación de la tarea
gatillo gatillo
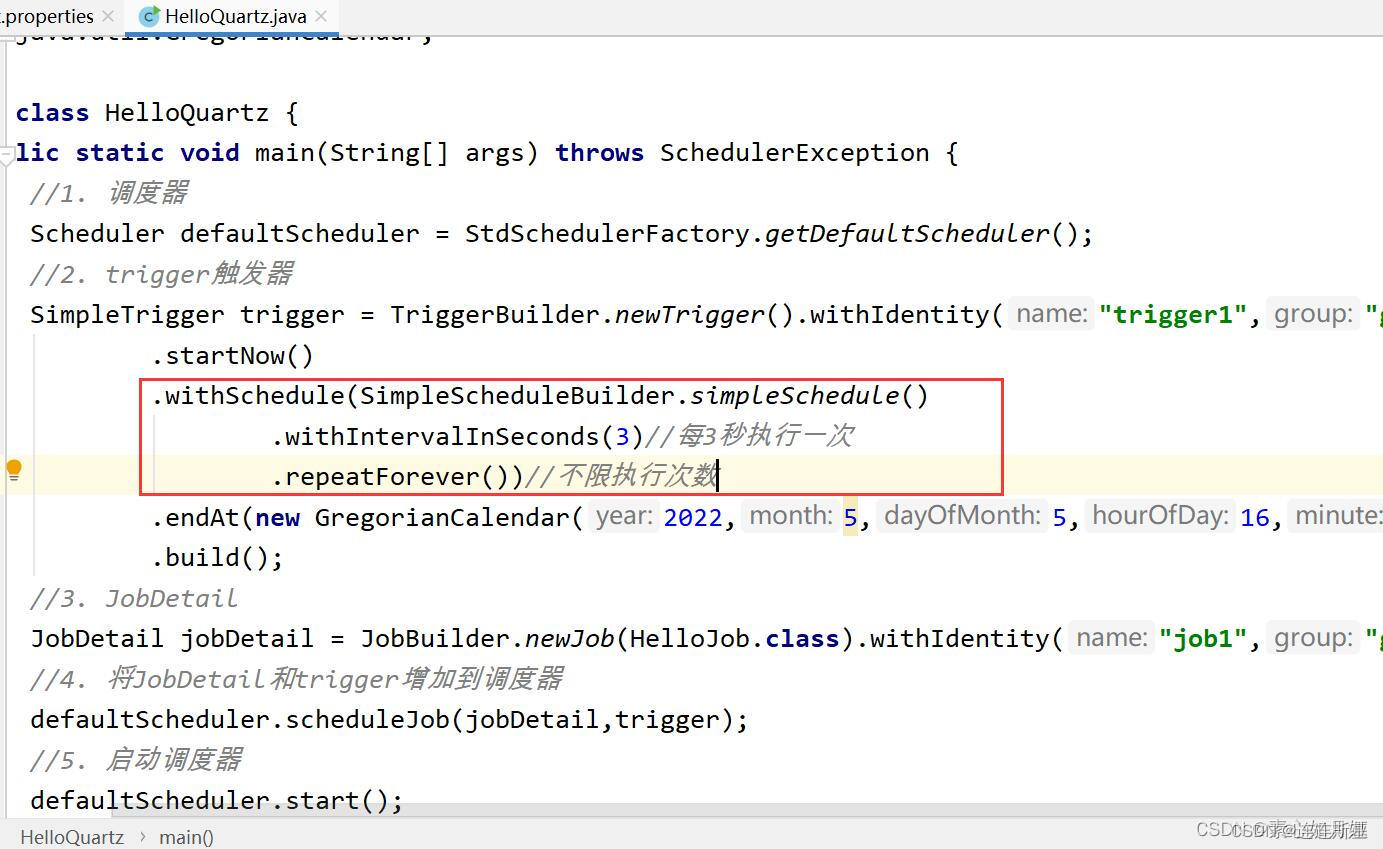
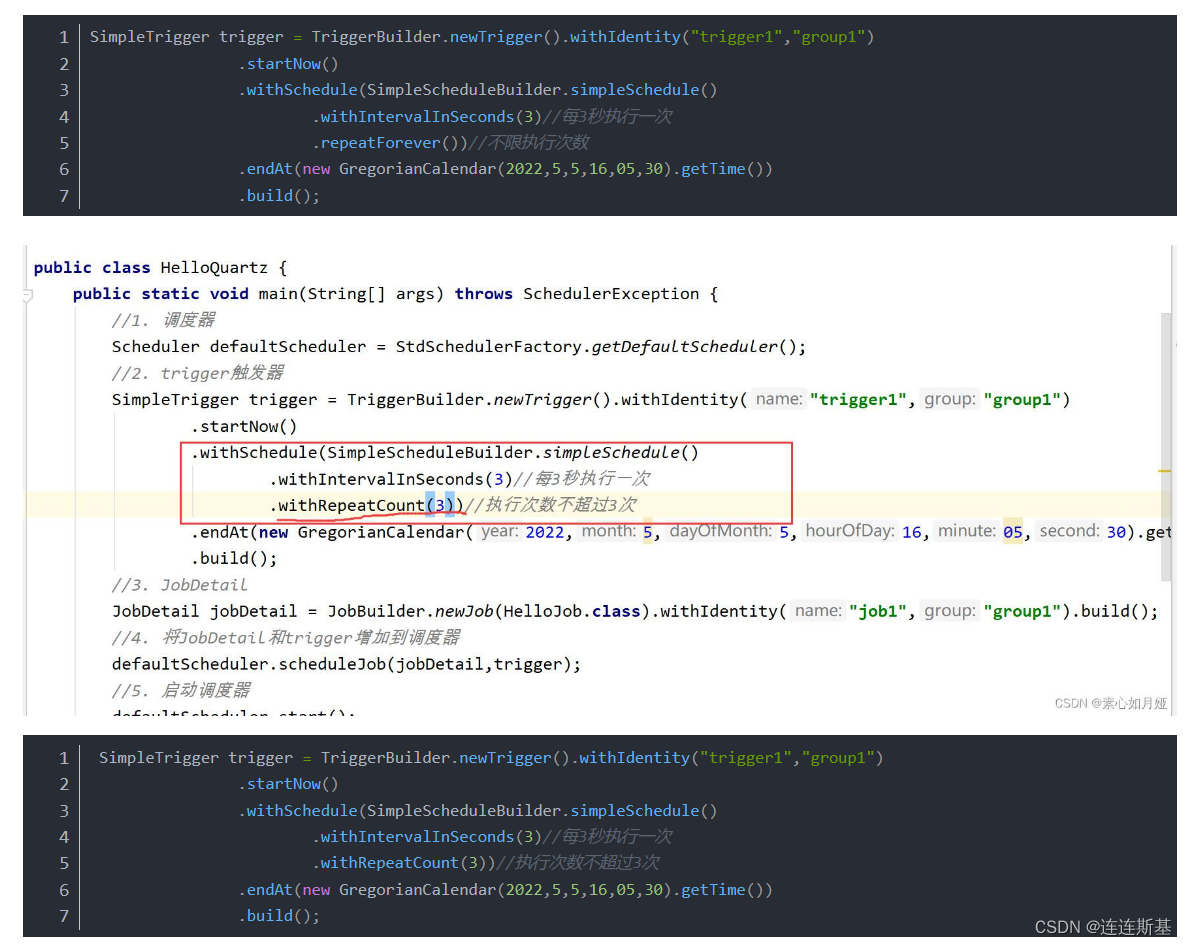
Disparador simple
Tareas ejecutadas en determinados intervalos de tiempo (en milisegundos)
- Especificar horas de inicio y finalización (el tiempo finaliza)
- Especificar intervalo de tiempo, número de ejecuciones.
CronTrigger (énfasis)
Las expresiones cron se utilizan principalmente para cronometrar el sistema de trabajos (tarea cronometrada) para definir la expresión del tiempo de ejecución o la frecuencia de ejecución. Puede usar la expresión Cron para configurar la tarea cronometrada para que se ejecute todos los días o todos los meses, etc.
formato de expresión cron:
{segundos} {minutos} {horas} {fecha} {mes} {semana} {año (puede estar vacío)}
El CronTrigger construido en base a la expresión Cron ya no usa startNow (), endAt (), etc. de SimpleTrigger, solo withSchedule (CronScheduleBuilder.cronSchedule ("30 01 17 11 5?"))
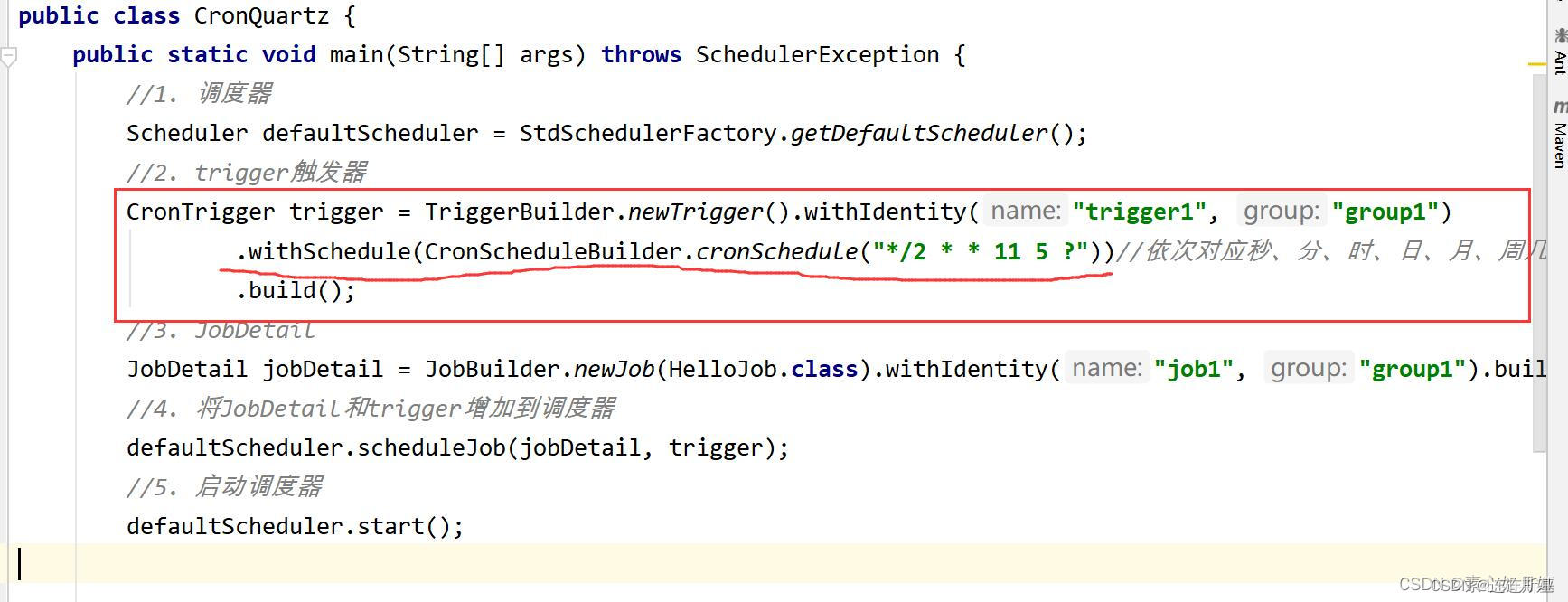
Significa que cada minuto y cada segundo de cada hora del 11 de mayo se ejecutarán una vez.
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","group1")
.withSchedule(CronScheduleBuilder.cronSchedule( "* * * 11 5 ?"))
.build();
Ejecutado cada minuto y cada 2 segundos de la hora del 11 de mayo.
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","group1")
.withSchedule(CronScheduleBuilder.cronSchedule( "*/2 * * 11 5 ?"))
.build();
Spring integra Quartz (énfasis)
Almacenamiento SQL de información de tareas
Hay dos formas de almacenar información de tareas en Quartz, usando memoria o usando una base de datos. Aquí usamos el método de almacenamiento de base de datos MySQL. Primero, necesitamos crear una nueva tabla relacionada con Quartz. La dirección de descarga del script SQL: http://www .quartz-scheduler.org /downloads/, el nombre es table_mysql.sql, después de que la creación sea exitosa, hay 11 tablas más en la base de datos
Maven depende principalmente de
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<!-- 5.1.* 版本适用于MySQL Server的5.6.*、5.7.*和8.0.* -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<!--pagehelper分页-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.3.0</version>
</dependency>
Aquí, druid se usa como grupo de conexiones de base de datos y Quartz usa c3p0 de forma predeterminada.
archivo de configuración
1. quartz.properties
De forma predeterminada, Quartz cargará quartz.properties en el classpath como un archivo de configuración. Si no se encuentra, se utilizará el archivo quartz.properties en org/quartz en el paquete jar del marco de cuarzo.
#主要分为scheduler、threadPool、jobStore、dataSource等部分
org.quartz.scheduler.instanceId=AUTO
org.quartz.scheduler.instanceName=DefaultQuartzScheduler
#如果您希望Quartz Scheduler通过RMI作为服务器导出本身,则将“rmi.export”标志设置为true
#在同一个配置文件中为'org.quartz.scheduler.rmi.export'和'org.quartz.scheduler.rmi.proxy'指定一个'true'值是没有意义的,如果你这样做'export'选项将被忽略
org.quartz.scheduler.rmi.export=false
#如果要连接(使用)远程服务的调度程序,则将“org.quartz.scheduler.rmi.proxy”标志设置为true。您还必须指定RMI注册表进程的主机和端口 - 通常是“localhost”端口1099
org.quartz.scheduler.rmi.proxy=false
org.quartz.scheduler.wrapJobExecutionInUserTransaction=false
#实例化ThreadPool时,使用的线程类为SimpleThreadPool
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
#threadCount和threadPriority将以setter的形式注入ThreadPool实例
#并发个数 如果你只有几个工作每天触发几次 那么1个线程就可以,如果你有成千上万的工作,每分钟都有很多工作 那么久需要50-100之间.
#只有1到100之间的数字是非常实用的
org.quartz.threadPool.threadCount=5
#优先级 默认值为5
org.quartz.threadPool.threadPriority=5
#可以是“true”或“false”,默认为false
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread=true
#在被认为“misfired”(失火)之前,调度程序将“tolerate(容忍)”一个Triggers(触发器)将其下一个启动时间通过的毫秒数。默认值(如果您在配置中未输入此属性)为60000(60秒)
org.quartz.jobStore.misfireThreshold=5000
# 默认存储在内存中,RAMJobStore快速轻便,但是当进程终止时,所有调度信息都会丢失
#org.quartz.jobStore.class=org.quartz.simpl.RAMJobStore
#持久化方式,默认存储在内存中,此处使用数据库方式
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
#您需要为JobStore选择一个DriverDelegate才能使用。DriverDelegate负责执行特定数据库可能需要的任何JDBC工作
# StdJDBCDelegate是一个使用“vanilla”JDBC代码(和SQL语句)来执行其工作的委托,用于完全符合JDBC的驱动程序
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#可以将“org.quartz.jobStore.useProperties”配置参数设置为“true”(默认为false),以指示JDBCJobStore将JobDataMaps中的所有值都作为字符串,
#因此可以作为名称 - 值对存储而不是在BLOB列中以其序列化形式存储更多复杂的对象。从长远来看,这是更安全的,因为您避免了将非String类序列化为BLOB的类版本问题
org.quartz.jobStore.useProperties=true
#表前缀
org.quartz.jobStore.tablePrefix=QRTZ_
#数据源别名,自定义
org.quartz.jobStore.dataSource=qzDS
#使用阿里的druid作为数据库连接池
org.quartz.dataSource.qzDS.connectionProvider.class=org.example.config.DruidPoolingconnectionProvider
org.quartz.dataSource.qzDS.URL=jdbc:mysql://127.0.0.1:3306/test_quartz?characterEncoding=utf8&useSSL=false&autoReconnect=true&serverTimezone=UTC
org.quartz.dataSource.qzDS.user=root
org.quartz.dataSource.qzDS.password=123456
org.quartz.dataSource.qzDS.driver=com.mysql.jdbc.Driver
org.quartz.dataSource.qzDS.maxConnections=10
#设置为“true”以打开群集功能。如果您有多个Quartz实例使用同一组数据库表,则此属性必须设置为“true”,否则您将遇到破坏
#org.quartz.jobStore.isClustered=false
Explicación detallada sobre la configuración: https://blog.csdn.net/zixiao217/article/details/53091812
También puede consultar el sitio web oficial: http://www.quartz-scheduler.org/documentation/2.3.1-SNAPSHOT/
2、propiedades de la aplicación
server.port=8080
#JDBC 配置:MySQL Server 版本为 5.7.35
spring.datasource.druid.url=jdbc:mysql://127.0.0.1:3306/test_quartz?characterEncoding=utf8&useSSL=false&autoReconnect=true&serverTimezone=UTC
spring.datasource.druid.username=root
spring.datasource.druid.password=123456
spring.datasource.druid.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
#druid 连接池配置
spring.datasource.druid.initial-size=3
spring.datasource.druid.min-idle=3
spring.datasource.druid.max-active=10
spring.datasource.druid.max-wait=60000
#指定 mapper 文件路径
mybatis.mapper-locations=classpath:org/example/mapper/*.xml
mybatis.configuration.cache-enabled=true
#开启驼峰命名
mybatis.configuration.map-underscore-to-camel-case=true
#打印 SQL 语句
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
Clase de configuración de cuarzo
@Configuration
public class QuartzConfig implements SchedulerFactoryBeanCustomizer {
@Bean
public Properties properties() throws IOException {
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
// 对quartz.properties文件进行读取
propertiesFactoryBean.setLocation(new ClassPathResource("/quartz.properties"));
// 在quartz.properties中的属性被读取并注入后再初始化对象
propertiesFactoryBean.afterPropertiesSet();
return propertiesFactoryBean.getObject();
}
@Bean
public SchedulerFactoryBean schedulerFactoryBean() throws IOException {
SchedulerFactoryBean schedulerFactoryBean = new SchedulerFactoryBean();
schedulerFactoryBean.setQuartzProperties(properties());
return schedulerFactoryBean;
}
/*
* quartz初始化监听器
*/
@Bean
public QuartzInitializerListener executorListener() {
return new QuartzInitializerListener();
}
/*
* 通过SchedulerFactoryBean获取Scheduler的实例
*/
@Bean
public Scheduler scheduler() throws IOException {
return schedulerFactoryBean().getScheduler();
}
/**
* 使用阿里的druid作为数据库连接池
*/
@Override
public void customize(@NotNull SchedulerFactoryBean schedulerFactoryBean) {
schedulerFactoryBean.setStartupDelay(2);
schedulerFactoryBean.setAutoStartup(true);
schedulerFactoryBean.setOverwriteExistingJobs(true);
}
}
uso para negocios
Paso 1: cree una clase de tarea:
@Slf4j
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) {
QuartzService quartzService = (QuartzService) SpringUtil.getBean("quartzServiceImpl");
PageInfo<JobAndTriggerDto> jobAndTriggerDetails = quartzService.getJobAndTriggerDetails(1, 10);
log.info("任务列表总数为:" + jobAndTriggerDetails.getTotal());
log.info("Hello Job执行时间: " + DateUtil.now());
}
}