序文
Python は非常に強力なデータ分析ツールであり、データを処理、分析、視覚化するためのライブラリと関数が豊富に提供されており、さまざまな分野で広く使用されています。この記事ではPythonを使ったデータ分析の方法を紹介します。以下にプロセスを簡単に説明します。
1. データの前処理
データ前処理は通常、データ分析の最初のステップであり、生データから有用な情報を抽出し、さらなる分析とモデリングのためにデータを準備するプロセスです。これらには、データ クリーニング、データ統合、データ変換、欠損値の補充、外れ値の処理などが含まれます。
【----テクノロジーの学習に役立ちます。記事の最後にある以下の学習教材はすべて無料です。----】
たとえば、pandas ライブラリを使用して CSV 形式でデータセットを読み取り、データ クリーニング操作を実行し、データセット情報を表示できます。
import pandas as pd
# 读取csv文件
data = pd.read_csv("data.csv")
# 去掉重复行
data.drop_duplicates(inplace=True)
# 更改数据类型
data['age'] = data['age'].astype('int')
# 查看数据集信息
print(data.info())
1.2. 探索的データ分析
探索的データ分析 (EDA) はデータ分析の重要な部分であり、データの統計的記述、データの視覚化などを含む、データセットのより深い構造と法則を発見することです。
たとえば、年齢と収入の間の散布図をプロットして、相関関係を観察できます。
import matplotlib.pyplot as plt
# 绘制收入和年龄散点图
plt.scatter(data.age, data.income)
plt.xlabel('Age')
plt.ylabel('Income')
plt.title('Relationship between Age and Income')
plt.show()
- 3. データモデリング
上記の探索的データ分析結果によれば、データ型、ビニング処理、標準化など、次のモデリングに向けていくつかの変数を適切に調整できます。次に、モデリングに適切なモデルを選択できます。機械学習では選択できるモデルが多数ありますが、ここでは例として線形回帰を使用します。
以下は、sklearn ライブラリを使用して単純な線形回帰モデルを構築する例です。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 标准化特征
data['age'] = (data['age'] - data['age'].mean()) / data['age'].std()
# 定义特征和目标列
X = data[['age']]
y = data['income']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
lr = LinearRegression()
# 拟合模型
lr.fit(X_train, y_train)
# 计算测试集均方误差
y_predict = lr.predict(X_test)
mse = mean_squared_error(y_test, y_predict)
print('Mean Squared Error:', mse)
- 4 モデルの評価
モデル評価は、通常、精度、再現率、f1 スコア、その他の指標を含む、トレーニングされたモデルのパフォーマンスを評価することです。ここでは、連続値予測の一般的な尺度である平均二乗誤差 (MSE) メトリクスを使用して、上で構築した線形回帰モデルを評価します。
- 5 データの視覚化
データの視覚化は Python データ分析の重要な側面であり、データとデータ間の関係をより深く理解するのに役立ちます。Python は、matplotlib や seaborn など、データ視覚化のためのさまざまなライブラリを提供します。
たとえば、モデルの決定境界を描画し、モデルの予測結果を観察できます。
import numpy as np
import seaborn as sns
# 定义边界起点和终点
x_boundaries = np.array([data['age'].min(), data['age'].max()])
y_boundaries = lr.predict(x_boundaries[:, np.newaxis])
# 绘制收入和年龄散点图
plt.scatter(data.age, data.income)
# 绘制决策边界
sns.lineplot(x_boundaries, y_boundaries, color='red')
plt.xlabel('Age')
plt.ylabel('Income')
plt.title('Relationship between Age and Income')
plt.show()
上記は Python を使用したデータ分析の基本的なプロセスですが、もちろん、特徴の選択、相互検証、ハイパーパラメーターの調整など、注意すべき詳細はまだたくさんあります。この投稿が、一部の読者がデータ分析に Python を使用してより良いスタートを切り、自分の研究に応用できるようになるのに役立つことを願っています。
Python はデータ分析によく使用されるツールの 1 つであり、その強力なデータ処理、統計、視覚化ライブラリをデータ分析に使用できます。
データ分析を実行する一般的な手順は次のとおりです。
- データの取得: 分析する必要があるデータセットを取得します。Pandas ライブラリの関数を使用して、CSV、Excel などのファイル形式からデータをインポートしたり、データベースからデータを直接取得したりできます。
- データ クリーニング: 重複値の削除、欠損値の処理、データ型の変換など、データのクリーニングと整理。このステップでは、Pandas ライブラリによって提供されるさまざまなデータ クリーニング方法を使用できます。
- データ探索的分析 (EDA): 視覚化と統計的要約を通じて、データの特性、変数の関係、データの分布、外れ値を分析します。このステップでは、Matplotlib や Seaborn などのライブラリを使用して、統計的記述やデータ モデリングのためにデータを視覚化できます。
- データ モデリング: 線形回帰、デシジョン ツリー、ランダム フォレストなどの機械学習モデルを通じてデータをモデル化し、予測します。このステップでは、Scikit-Learn などの機械学習ライブラリを使用できます。
- 結果出力:分析結果を業務担当者が理解しやすいようにグラフやレポートなどの形式で表示します。
Python には、NumPy、Pandas、Matplotlib、Seaborn、Scikit-Learn など、データ分析に関連するライブラリやツールが多数あります。これらのライブラリの使用に慣れると、データ分析を簡単に実行できるようになります。
これは私が実行したコードの一部のスクリーンショットです



Pythonのデータ分析を簡単に理解する方法も教えます
Python は、さまざまな種類のデータの処理と分析に使用できる、広く使用されているプログラミング言語です。Python には、さまざまな種類のデータ分析タスクを実行できる組み込みライブラリとサードパーティ ライブラリが豊富にあります。Python データ分析をマスターするためのいくつかの提案を次に示します。
-
基礎を学ぶ: Python データ分析を学ぶ前に、変数、ループ、条件文などの基本概念や構文を含む、Python プログラミング言語の基礎を理解する必要があります。
-
NumPy、Pandas、Matplotlib などのライブラリを学習します。これらのライブラリは、Python でのデータ分析のコア ライブラリです。NumPy は数値計算のための効率的なデータ処理ツールを提供し、Pandas はデータの読み取り、クリーンアップ、処理を簡単に実行できる強力なデータ操作および処理機能を提供し、Matplotlib はグラフィックの生成や曲線の描画などのデータ視覚化ツールを提供します。これらのライブラリの使用方法を学ぶことで、データの処理と分析を迅速に実行し、プロレベルのデータ レポートと視覚化結果を提示できるようになります。
-
実践的なプロジェクト: 本やチュートリアルを読むことは理論的な学習ですが、データ分析を真にマスターするには実践することが鍵となります。関連するデータセットをいくつか見つけて、そこからデータ情報をマイニングしてみることができます。理解が深まるだけでなく、実践に向けたスキルも養われます。
-
いくつかの優れた学習リソースをお勧めします。
(1) 「データ分析のための Python の使用」 (データ分析のための Python、第 2 版) • Wes McKinney
(2) 『Python データ サイエンス ハンドブック』 (Python データ サイエンス ハンドブック) Jake VanderPlas
(3) Coursera の優れたデータ サイエンス コース 例: ミシガン大学の Applied Data Science with Python 特別コース
Pythonと他のデータ分析の違いについてもお話します
Python と他のデータ分析ツールの間には、いくつかの顕著な違いがあります。相違点の主な点をいくつか示します。
-
機能と難易度: 従来の GUI ベースのソフトウェア (SPSS、SAS など) と比較して、Python は柔軟性と自由度が高く、プログラミングの学習と練習もより多く必要とします。しかし、この自由度により、Python は大規模で複雑で不規則なデータを処理することもできます。
-
オープン性とコミュニティ サポート: Python は、大規模なユーザー ベースと強力なコミュニティ サポートを備えたオープン ソース プログラミング言語であり、ユーザーはデータの処理と分析にさまざまな種類のプラグインや拡張機能を使用できます。
-
クロスプラットフォーム: Python は、Windows、MacOS、Linux、およびその他のオペレーティング システムで実行できる移植性の高いプログラミング言語です。
-
データベースのサポート: 他のデータ分析ツールと比較して、Python は幅広いデータベース サポートを提供します。リレーショナル データベース (MySQL、PostgreSQL など) に接続するだけでなく、非リレーショナル データベース (MongoDB など) にも接続できます。
-
学習のしきい値: 他の分析ツールと比較して、Python は、Python 言語自体の構文やいくつかの一般的なデータ構造など、特定のプログラミングの基礎を学習する必要がある場合があります。ただし、一部の GUI データ分析ツールは機能が比較的カプセル化されているため、初心者でも高度なプログラミング能力がなくても直接開始できます。
一般に、Python はプログラミング言語として、さまざまな便利なツールを開発および構築できますが、同時にデータ分析も Python の広く使用される分野の 1 つとなっています。これに比べて、他の一般的なデータ分析ツールは、特定の分野で解決する必要がある機能に重点を置いている可能性があり、Python データ分析をマスターするには、より実践的な練習が必要であり、同時に、継続的な学習で徐々に能力レベルを向上させる必要があります。練習とディスカッション。これらの提案がお役に立てば幸いです。
1. Python の概要
以下の内容は、Python の応用全般に必要な基礎知識であり、クローラ、データ分析、人工知能などをやりたい場合は、まず学習する必要があります。高いものはすべて原始的な基礎の上に建てられます。しっかりした基礎があれば、前に進む道はより安定します。すべての素材は記事の最後に無料で掲載されています!!!
含む:
コンピュータの基本
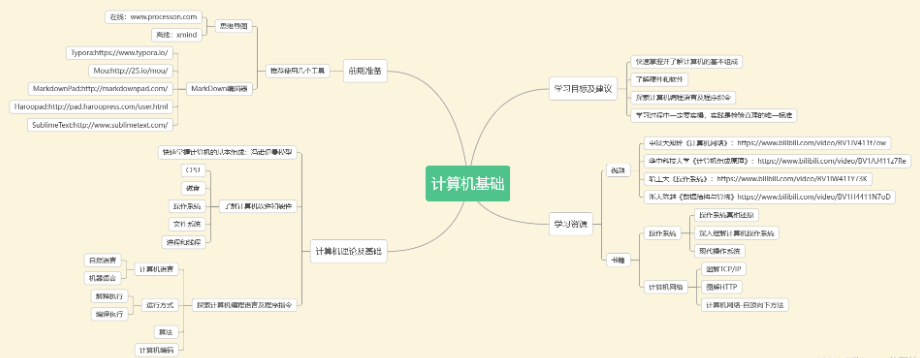
Pythonの基本

Python入門ビデオ600話:
ゼロベース学習ビデオを見るのが最も早くて効果的な学習方法で、ビデオ内の教師のアイデアに従って、基礎から詳細まで非常に簡単に始めることができます。
2. Python クローラー
人気の方向性として、爬虫類はアルバイトでも仕事効率を上げるための補助スキルとしても最適です。
クローラーテクノロジーを通じて関連コンテンツを収集し、分析、削除することで、本当に必要な情報を取得できます。
この情報収集・分析・統合作業は、生活サービス、旅行、金融投資、各種製造業の製品市場需要など、幅広い分野で応用可能であり、クローラ技術を活用することで、より正確かつ正確な情報を取得することができます。有効な情報を活用してください。

Python クローラーのビデオ素材
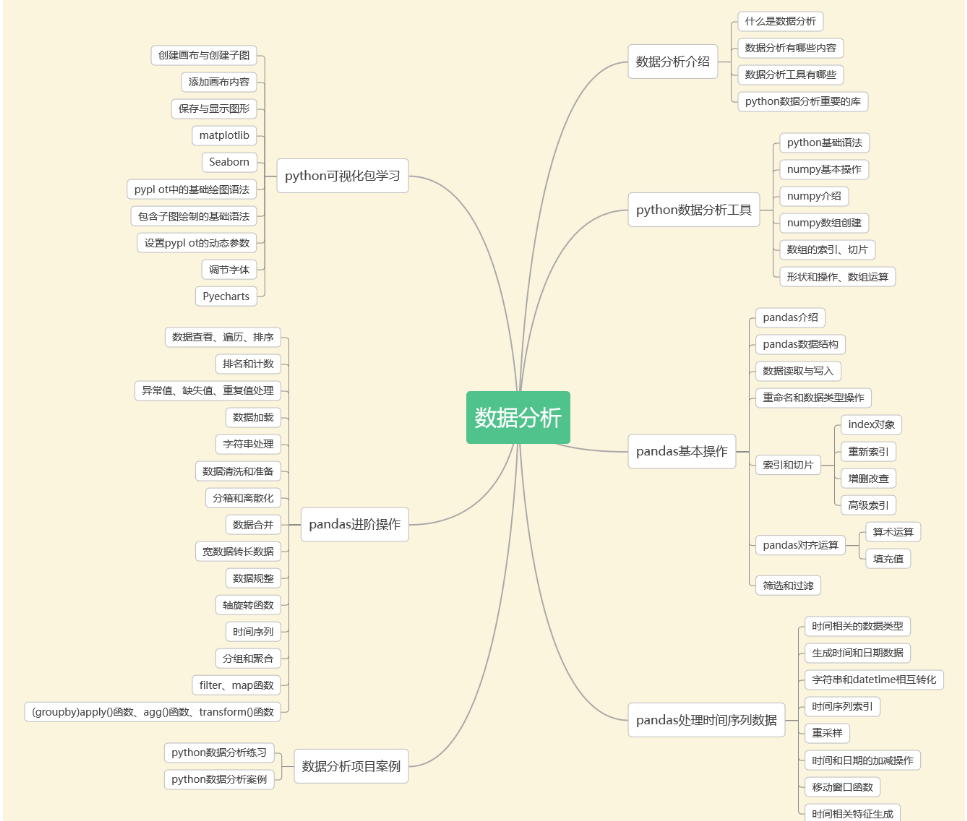
3. データ分析
清華大学経済管理学院が発表した報告書「中国経済のデジタル変革:人材と雇用」によると、データ分析人材の格差は2025年に230万人に達すると予想されている。
人材の格差がこれほど大きいと、データ分析は広大なブルーオーシャンのようなものになります。初任給10万は本当に当たり前です。
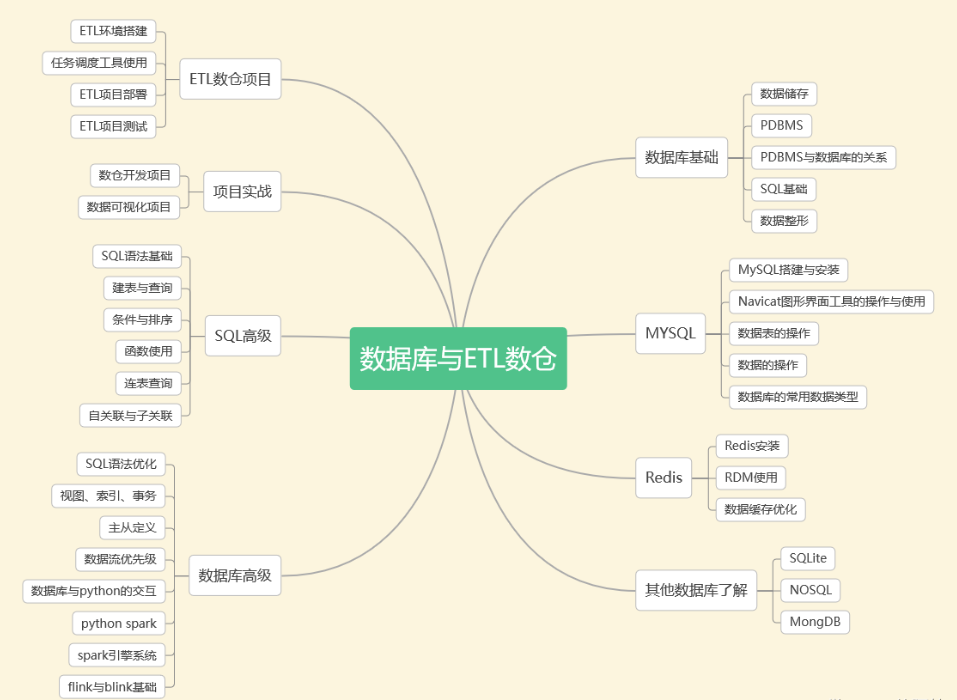
4. データベースとETLデータウェアハウス
企業は、ビジネス データベースからコールド データを定期的に転送し、履歴データの保存専用のウェアハウスに保存する必要があります。各部門は、独自のビジネス特性に基づいて統合されたデータ サービスを提供できます。このウェアハウスはデータ ウェアハウスです。
従来のデータ ウェアハウス統合処理アーキテクチャは ETL であり、ETL プラットフォームの機能を使用します。E = ソース データベースからデータを抽出、L = データ (ルールに準拠していないデータ) のクリーンアップ、変換 (さまざまなディメンションおよびさまざまな粒度)ビジネス ニーズに応じたテーブルの場合)、さまざまなビジネス ルールの計算)、T = 処理されたテーブルをデータ ウェアハウスに段階的に、完全に、異なる時点でロードします。
5. 機械学習
機械学習とは、コンピュータのデータの一部を学習し、他のデータを予測・判断することです。
機械学習の核心は、「アルゴリズムを使用してデータを解析し、そこから学習し、新しいデータに関する意思決定や予測を行うこと」です。つまり、コンピュータは、得られたデータからあるモデルを取得し、そのモデルを用いて予測を行うというもので、人間が一定の経験を積んだ後に新たな問題を予測するなど、人間の学習プロセスに似ています。

機械学習教材:
6. 高度な Python
基本的な文法内容から、プログラミング言語の設計を理解するためのより深い高度な知識まで、ここで学習すると、Python の入門から上級までのすべての知識を基本的に理解することができます。

この時点で企業の採用要件はほぼ満たせますが、面接資料や履歴書のテンプレートがどこにあるのかわからないという方のためにコピーも用意しましたので、まさに体系的な学習と言えます。乳母と .
ただし、プログラミングの学習は一夜にして達成できるものではなく、長期的な継続とトレーニングが必要です。この学習ルートを整理する中で、私自身も技術的な点を復習しながら、皆さんと一緒に進めていきたいと思っています。プログラミングの初心者であっても、高度な技術を必要とする経験豊富なプログラマーであっても、誰もがそこから何かを得ることができると私は信じています。
それは一夜にして達成できますが、長期的な忍耐力と訓練が必要です。この学習ルートを整理する中で、私自身も技術的な点を復習しながら、皆さんと一緒に進めていきたいと思っています。プログラミングの初心者であっても、高度な技術を必要とする経験豊富なプログラマーであっても、誰もがそこから何かを得ることができると私は信じています。
データ収集
Python 学習教材のフルセットのこの完全版は公式 CSDN にアップロードされています。必要な場合は、下の CSDN 公式認定 WeChat カードをクリックして無料で入手できます ↓↓↓ [100% 無料保証]

良い記事をお勧めします
Python の展望を理解する: https://blog.csdn.net/SpringJavaMyBatis/article/details/127194835
Python のパートタイムの副業について学ぶ: https://blog.csdn.net/SpringJavaMyBatis/article/details/127196603