classement de classification postgresql
fonction de fenêtre de classement
La fonction de fenêtre de classement est utilisée pour classer les données par groupes. Les fonctions courantes de la fenêtre de classement incluent :
• ROW_NUMBER , qui attribue un numéro de série à chaque ligne de données dans la partition, et le numéro de série commence à 1.
• RANK , calcule le rang de chaque ligne de données dans sa partition ; s'il y a des données avec le même rang, le classement suivant sautera
.
• DENSE_RANK , calcule le classement de chaque ligne de données dans sa partition ; même s'il y a des données avec le même classement, les
classements suivants sont des valeurs continues.
• PERCENT_RANK , qui affiche le rang de chaque ligne de données dans sa partition sous forme de pourcentage ; s'il y a
des données avec le même rang, les classements suivants sauteront.
• CUME_DIST , calcule la distribution cumulée de chaque ligne de données dans sa partition, c'est-à-dire le rapport de la ligne de données aux données précédentes
; la plage de valeurs est supérieure à 0 et inférieure ou égale à 1.
• NTILE , divisez les données de la partition en N parties égales et calculez son emplacement pour chaque ligne de données.
La fonction de fenêtre de classement ne prend pas en charge la taille de fenêtre dynamique ( frame_clause ), mais utilise la partition actuelle comme fenêtre d'analyse.
exemple
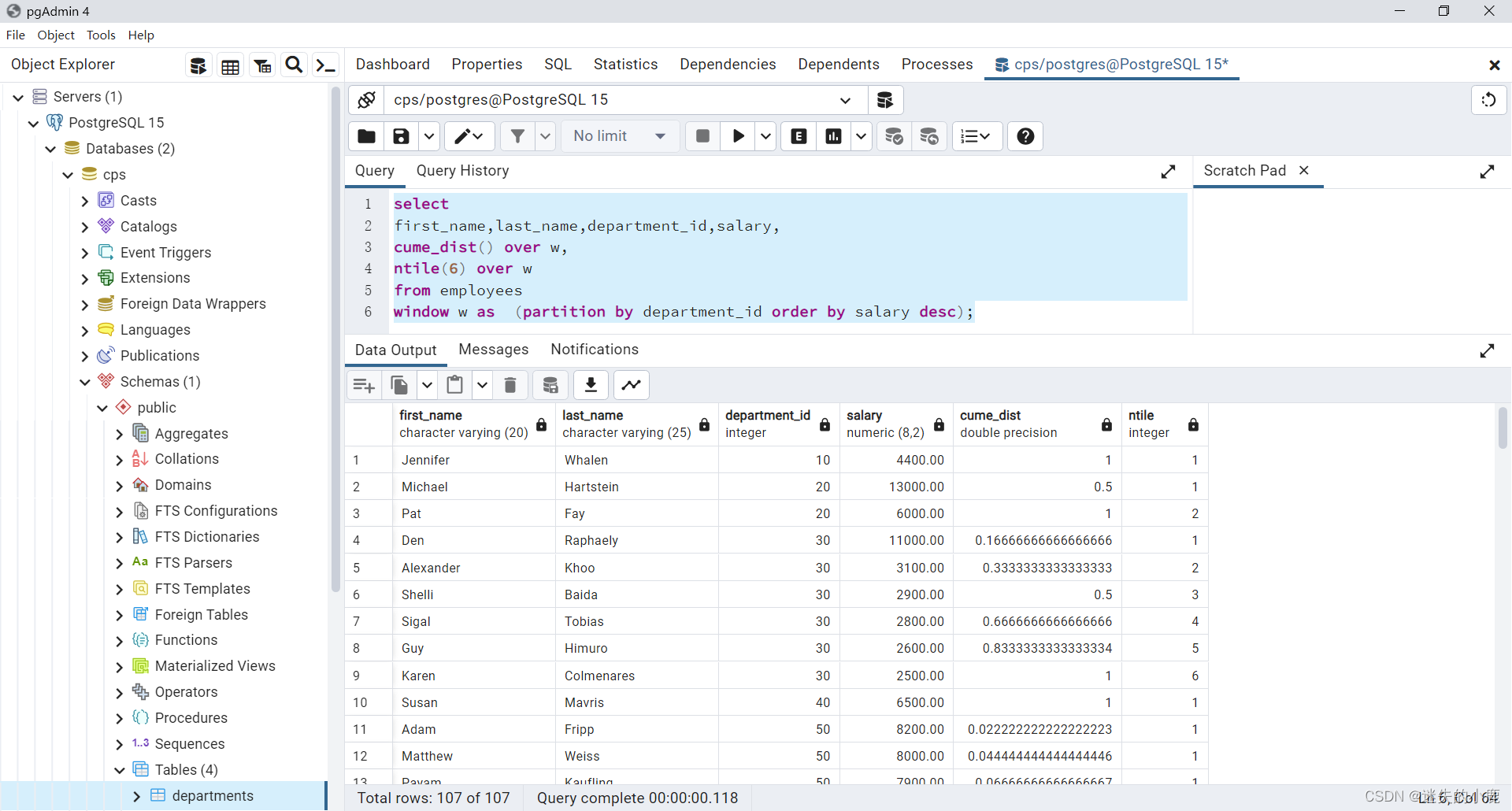
Selon le département comme unité, calculer le classement salarial mensuel des salariés :
select
first_name,last_name,department_id,salary,
row_number() over(partition by department_id order by salary desc),
rank() over(partition by department_id order by salary desc),
dense_rank() over(partition by department_id order by salary desc),
percent_rank() over(partition by department_id order by salary desc)
from employees;
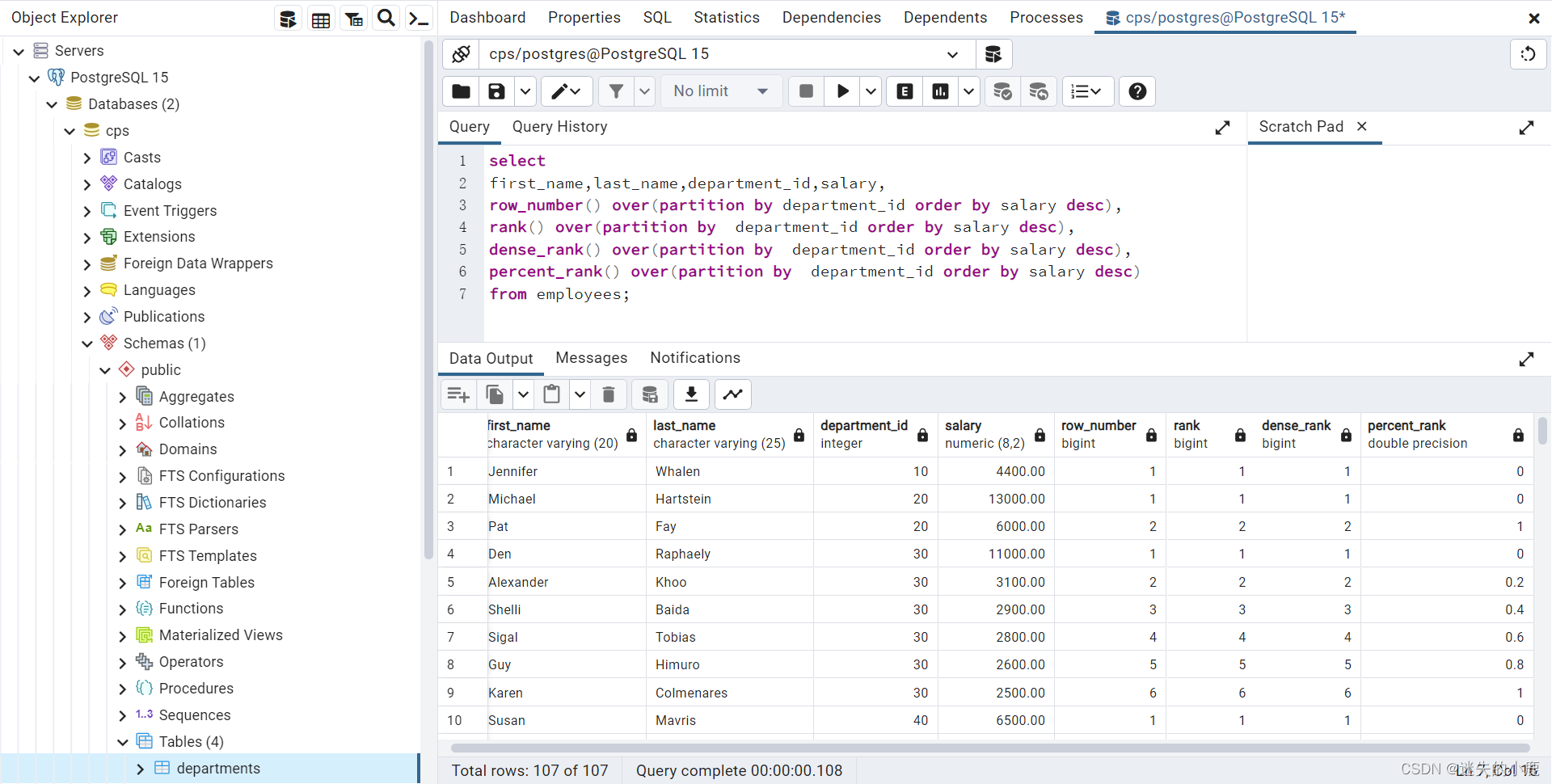
Les clauses OVER des quatre fonctions de fenêtre dans les exemples ci-dessus sont exactement les mêmes, et une méthode d'écriture plus simple peut être utilisée pour le moment :
select
first_name,last_name,department_id,salary,
row_number() over w,
rank() over w,
dense_rank() over w,
percent_rank() over w
from employees
window w as (partition by department_id order by salary desc);
CUME_DIST et NTILE
select
first_name,last_name,department_id,salary,
cume_dist() over w,
ntile(6) over w
from employees
window w as (partition by department_id order by salary desc);