
Los productos de modelos grandes de OpenAI no son solo un modelo, sino que están respaldados por una serie de modelos diversos que cubren texto, código, diálogo, imágenes, etc. con diferentes capacidades y opciones de precio.
1. Modelo de lenguaje grande
Para modelos de lenguaje grandes, OpenAI proporciona modelos de las series GPT3, GPT-3.5 y GPT-4 para comprender y generar código y lenguaje natural.
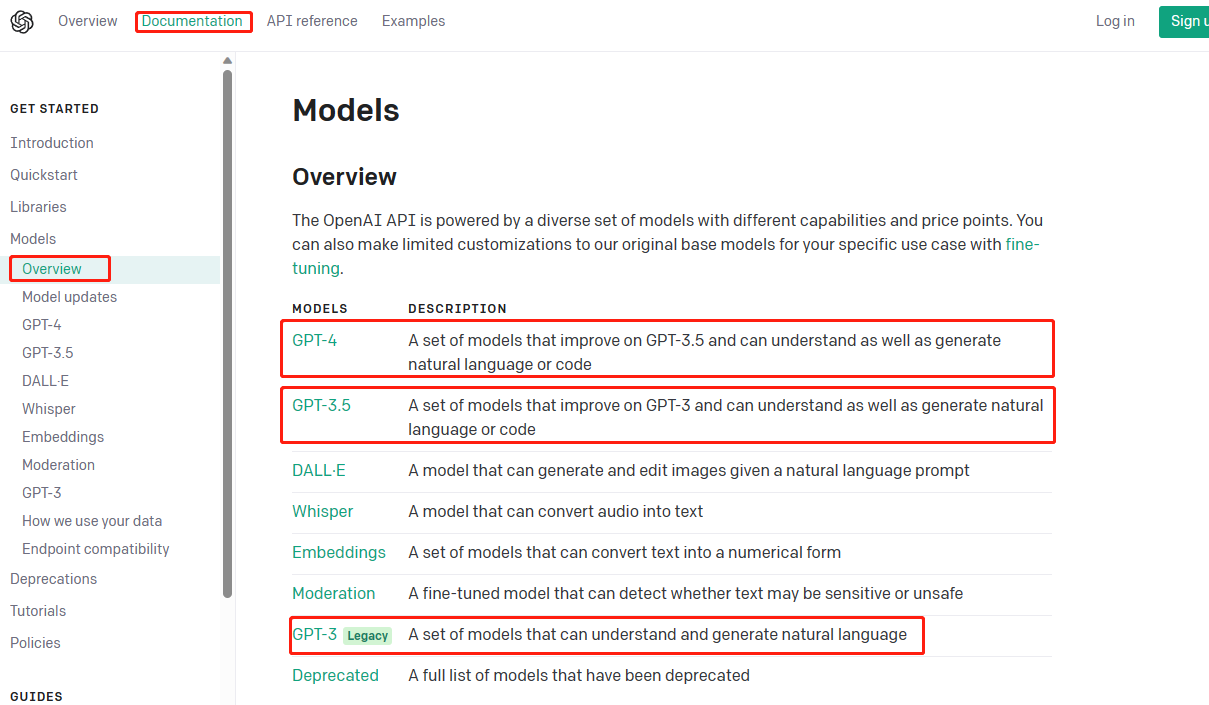
Mientras entrenaba GPT3, OpenAI también entrenó cuatro modelos base A, B, C y D. Sus parámetros y complejidad son diferentes y se pueden usar en diferentes escenarios. Los nombres completos son: ada, babbage, curie y davinci.
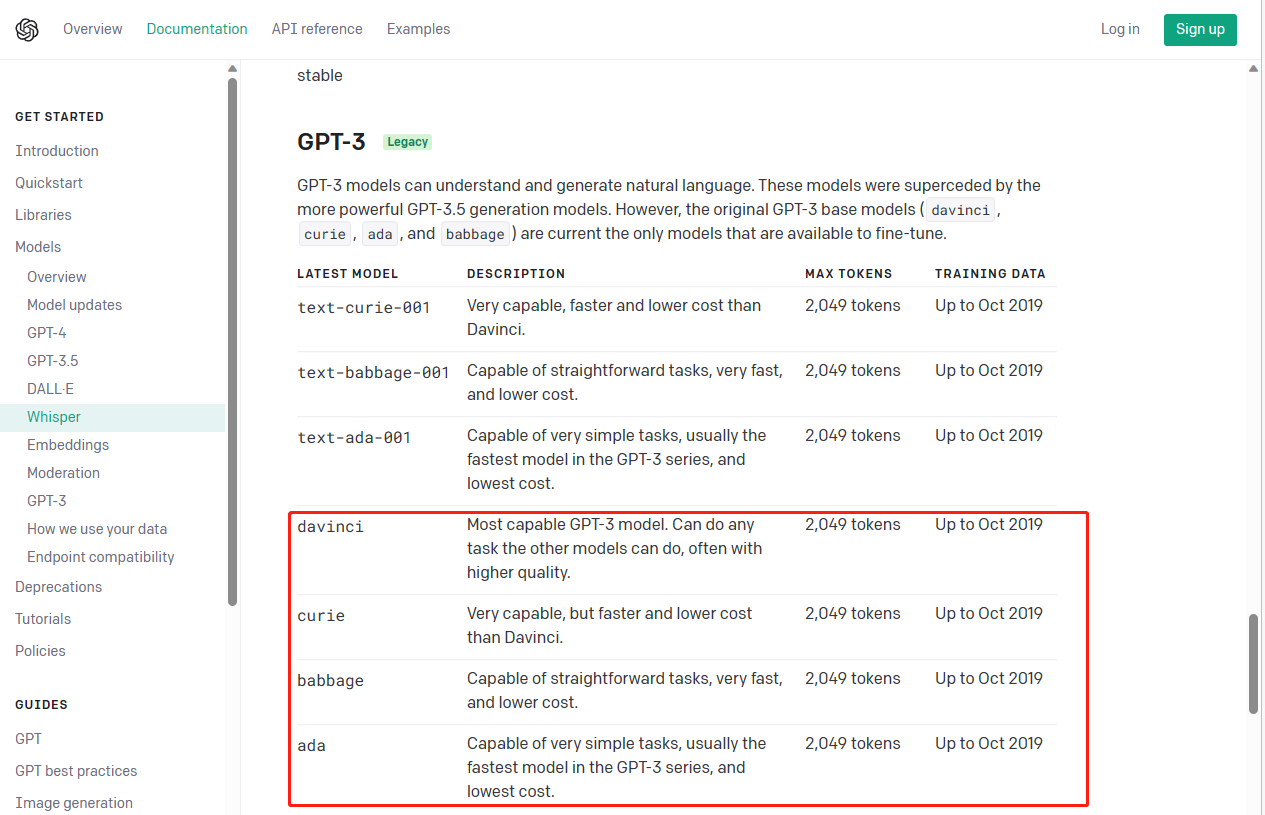
ada: Capaz de realizar tareas muy simples y, en general, el modelo más rápido y económico de la familia GPT-3. Admite 2049 tokens
babbage: Capaz de realizar tareas sencillas, muy rápidas y menos costosas. Admite 2049 tokens.
curie: muy potente, más rápido y más barato que davinci. Admite 2049 tokens.
davinci: El modelo GPT-3 más potente. Capaces de realizar cualquier tarea de la que son capaces otros modelos y, en general, de mayor calidad. Admite 2049 tokens.
Entonces, a juzgar por la introducción oficial, estos cuatro modelos no son modelos de ajuste fino de GPT-3, sino cuatro modelos entrenados de forma independiente y aumentan en orden según el tamaño y la complejidad de los parámetros.
2. Imagen de modelo grande multimodal
DALL·E es un sistema de inteligencia artificial capaz de crear imágenes realistas y obras de arte basadas en descripciones en lenguaje natural. Actualmente se admite la capacidad de crear nuevas imágenes con dimensiones específicas, editar imágenes existentes o crear variaciones de imágenes proporcionadas por el usuario según las indicaciones.
La última versión es: el modelo DALL·E es el modelo DALL·E de segunda generación, en comparación con el modelo original, puede generar imágenes más realistas y precisas, y la resolución es 4 veces mayor que el modelo original.

La capacidad de DALL E para comprender imágenes proviene del modelo de lenguaje grande y aplica esta capacidad al campo visual. El método central es: tratar las imágenes como un lenguaje, convertirlas en tokens y luego combinarlas con tokens de texto reunidos para el entrenamiento.
3. Modelo de reconocimiento de voz
Whisper es un modelo general de reconocimiento de voz. Está entrenado en un conjunto de datos de audio grande y diverso y es un modelo multitarea que puede realizar reconocimiento de voz multilingüe, traducción de voz e identificación de idioma.
La última versión es el modelo Whisper v2-large, que ha sido de código abierto por OpenAI y se puede implementar localmente o llamar a través de API como otros modelos grandes de OpenAI.

4. Modelo de vectorización de texto
Las incrustaciones son representaciones numéricas de texto y se pueden utilizar para medir la correlación entre dos fragmentos de texto. Como modelo de incrustación de texto, su capacidad es convertir texto en vectores de palabras y, mediante operaciones como el cálculo de la similitud de los vectores de palabras, puede realizar tareas como recomendación, clasificación y búsqueda en el texto real que representa.
La última versión es: text-embedding-ada-002

El proceso general es básicamente el siguiente:
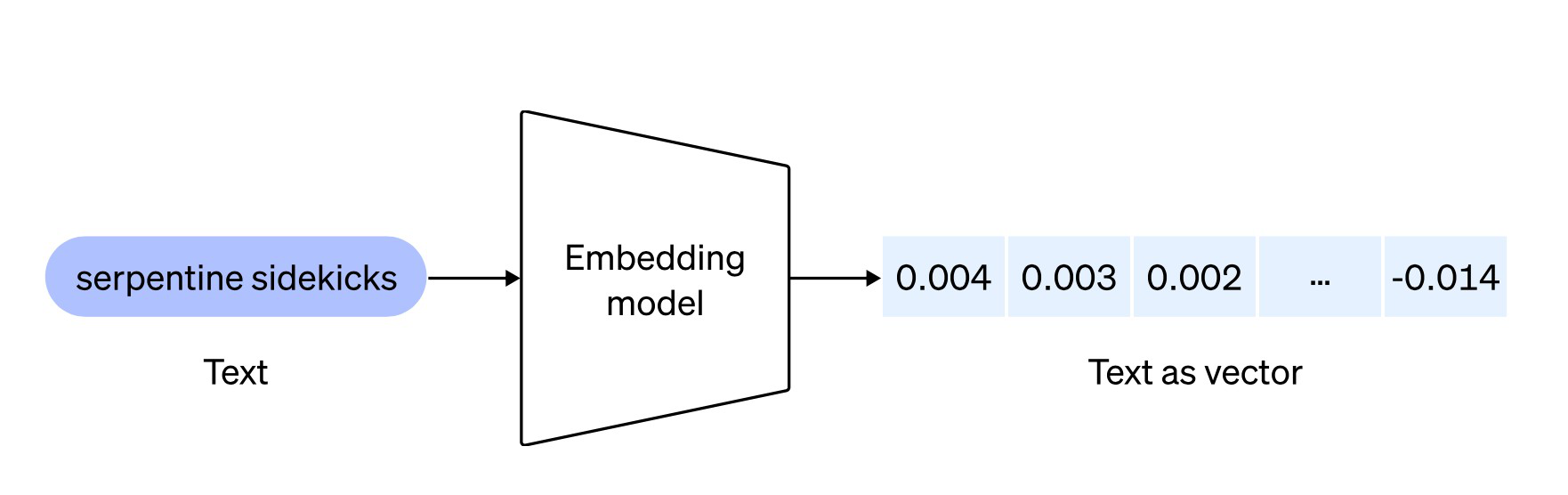
La incrustación asignará palabras, oraciones o estructuras de lenguaje de nivel superior a vectores en un espacio de alto nivel, de modo que las palabras u oraciones semánticamente similares estén más cerca en el espacio vectorial. La capa de incrustación del modelo GPT está en el proceso de entrenamiento . entrenamiento , el ajuste fino a menudo modifica la capa de incrustación.
5. Revisa el modelo
El modelo de moderación está diseñado para comprobar que el contenido cumple con las políticas de uso de OpenAI. Estos modelos proporcionan capacidades de clasificación para detectar las siguientes categorías de contenido: odio, odio/amenazas, autolesiones, contenido sexual, contenido sexual que involucra a menores, violencia y violencia/gráficos.
Política de uso de nAI. Estos modelos proporcionan capacidades de clasificación para detectar las siguientes categorías de contenido: odio, odio/amenazas, autolesiones, contenido sexual, contenido sexual que involucra a menores, violencia y violencia/gráficos.

Finalmente, ¡gracias por leer este artículo! Si sientes que has ganado algo, no olvides darle me gusta, marcarlo y seguirme, esta es la motivación para mi creación continua. Si tiene alguna pregunta o sugerencia, puede dejar un mensaje en el área de comentarios, haré todo lo posible para responder y aceptar sus comentarios. Si hay un tema en particular que le gustaría conocer, hágamelo saber y estaré encantado de escribir un artículo al respecto. ¡Gracias por su apoyo y esperamos crecer con usted!
Esperamos crecer junto con usted en futuros estudios.