Tabla de contenido
- prefacio
- leer navegación
- Conocimiento previo
- Contenido del curso
- resumir
prefacio
En primavera, se puede decir que la mayoría de nuestros reproductores Java [el extraño más familiar]. Ocho palabras para describir: medio entendido,

dirás aplicación simple, todos lo sabemos, si realmente quieres expandirte y decir dos oraciones, entonces solo puedes llegar a estas dos oraciones: esta es la primera oración, seguida de la segunda oración, bueno, ya terminé.

Pero ah xdm,Se dice que Spring es un código fuente muy, muy, muy bueno. No solo tiene escenarios de aplicación de patrones de diseño ricos, sino que también el código está bellamente escrito y organizado, por lo que recomiendo a todos que lo aprendan. Además de poder simular en la vida diaria, también podrás enriquecer tus conocimientos y mejorar tu capacidad para escribir código.
leer navegación
Lectores: personas que tienen experiencia en el desarrollo de Spring.
Conocimiento previo
P1: ¿Puede describir el proceso de creación de objetos JVM?
Respuesta: Mira la imagen y habla:
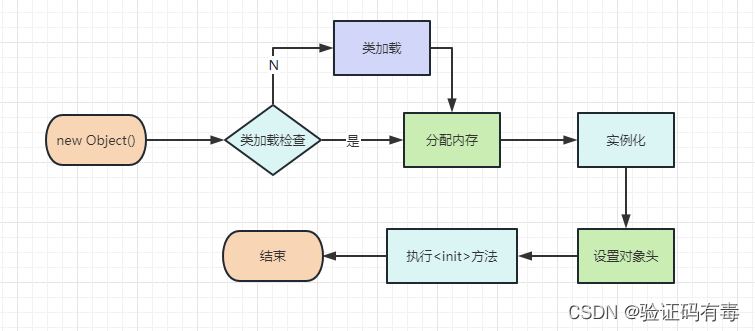
- Carga de clases: antes de usar una clase, la máquina virtual Java necesita cargar el código de bytes de la clase en la memoria. La carga de clases es el proceso central de la máquina virtual Java, que es responsable de encontrar el archivo de código de bytes de la clase y cargarlo en el área de método de la memoria. La carga de clases incluye cinco fases: carga, verificación, preparación, análisis e inicialización.
- Asignación de memoria: una vez completada la carga de la clase, la máquina virtual Java asigna espacio de memoria para el objeto. La asignación de memoria generalmente se realiza en el montón, pero en algunos casos especiales también hay objetos que pueden asignar memoria en la pila, como los objetos locales en la pila de subprocesos.
- Creación de instancias (inicialización de valor cero): después de asignar memoria, la máquina virtual Java inicializa el espacio de memoria del objeto a un valor cero. Esto incluye valores predeterminados para tipos primitivos (como 0, falso, etc.) y valores predeterminados (nulo) para tipos de referencia.
- Establecer el encabezado del objeto: el diseño del objeto Java en la memoria incluye dos partes: el encabezado del objeto y los datos de la instancia. El encabezado del objeto almacena algunos metadatos, como el código hash del objeto, el estado de bloqueo, etc. Durante la creación del objeto, la máquina virtual Java establece el valor del encabezado del objeto.
- Ejecutar el constructor: el último paso en la creación de objetos es ejecutar el constructor. El constructor se utiliza para inicializar los datos de instancia del objeto y realizar otras operaciones de inicialización necesarias. El constructor puede ser el constructor predeterminado de la clase o un constructor personalizado.
- Devolver referencia de objeto: una vez creado el objeto, la máquina virtual Java devuelve una referencia al objeto. A través de la referencia, el programa puede manipular las propiedades y métodos del objeto.
(PD: ¿Por qué haces esta pregunta? Debido a que Spring es una tecnología COI, no importa cuánto se desarrolle, debe seguir este proceso básico para crear objetos. Sin embargo, puedo decirles de antemano que Spring IOC ha agregado muchos espacios nuevos en este proceso y ha enriquecido las funciones del COI mediante el intercambio en caliente.)
P2: ¿Cuáles son las características de Spring?
Respuesta: ¡Las características de Spring son los dos conceptos de COI y AOP! Incluso se puede decir que:Spring es un contenedor IOC que implementa tecnología AOP. (contenedor, contenedor, contenedor)
P3: ¿Qué es el COI y qué es el AOP?
Respuesta: La siguiente respuesta proviene de Baidu [Wen Xin Yi Yan]:
- IOC (Inversión de Control) es un patrón de diseño (pensamiento) que permite que la creación y gestión de objetos sean manejados por el contenedor Spring en lugar de crear objetos directamente en el código . Al utilizar IOC, las dependencias de objetos se pueden desacoplar del código, lo que hace que el código sea más flexible, mantenible y comprobable.
- AOP (Programación orientada a aspectos) también es un patrón de diseño (pensamiento), que utiliza precompilación y proxy dinámico en tiempo de ejecución para agregar dinámicamente funciones a los programas sin modificar el código fuente . AOP resuelve problemas que no se pueden resolver en la programación orientada a objetos, como gestión de transacciones, seguridad, registro, etc.
El marco Spring hace que el programa sea más modular, flexible y fácil de mantener mediante la implementación de IOC y AOP. Al mismo tiempo, Spring también proporciona muchos otros módulos y funciones, como DAO, ORM, WebMVC, etc., lo que lo convierte en un potente marco de desarrollo de Java.
Resumen de conocimientos previos
De la pregunta anterior, mencionamos algo muy importante, a saber:Spring es un contenedor IOC que implementa tecnología AOP. Además, también describe de forma general los conceptos de COI y AOP. Ahora que también sabemos que IOC en realidad gestiona la creación de objetos, cuando se trata de creación de objetos, debe ser inseparable del proceso de creación de objetos que mencionamos en la pregunta 1. Además, no importa cómo se crea el objeto o quién lo crea, no hay forma de abandonar el proceso anterior.
De hecho, lo que puedo decirles de antemano es que el proceso de creación de objetos en IOC no es más que enriquecer algunos detalles y agregar algunos puntos de extensión en el proceso de creación de objetos anterior para brindar soporte para la realización de la función Spring.
Contenido del curso
Para llevar a cabo la investigación sobre el código fuente de Spring, aquí hablaremos brevemente sobre algunos puntos de conocimiento centrales de Spring, para que todos puedan tener una comprensión clara de alguna lógica básica en la base de Spring.
1. Iniciar el contenedor Spring
Creo que los amigos que han experimentado la era SSM/SSH estarán familiarizados con el siguiente código:
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("spring.xml");
UserService userService = (UserService) context.getBean("userService");
userService.test();
System.out.println(userService);
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd">
<!-- <import resource="引入其他bean xml配置文件" />-->
<bean id="userService" class="org.example.spring.bean.UserService"/>
</beans>
No importa si realmente no está familiarizado, el siguiente puede resultarle relativamente familiar: ( También explicaré la primavera de este método de inicio más adelante. Además de los más convencionales a continuación, también se debe a que el siguiente método es más puntos ampliamente utilizados, actualizados y con contenido relativamente ricos! )
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
UserService userService = (UserService) context.getBean("userService");
userService.test();
System.out.println(userService);
@Component
public class UserService {
public void test() {
System.out.println("这是一个测试方法");
}
}
Jaja, supongo que es posible que muchos amigos que han entrado directamente en la era de Java [SpringBoot] ni siquiera hayan visto lo anterior.
¿Qué hace el código anterior? Muy simple, simplemente inicie un contenedor Spring. Los dos métodos de inicio diferentes anteriores son solo métodos diferentes de registro de beans. Por ejemplo, el primero se define leyendo las etiquetas xmldentro <bean>y el segundo es la anotación de lectura Bean.
En este punto me gustaría hacerte una pregunta, es decir, a través del código del segundo método anterior, ¿qué encontraste? Mi descubrimiento es: simplemente llamo a una línea de código y puedo comenzar a usar el Bean definido por Spring. No me importa la inyección de dependencia, AOP, etc., solo hágalo directamente. ¿Qué prueba esto? De hecho, es superficial y un poco absurdo, y esa es la prueba:A través de esta línea de código, me ayuda a completar todas las capacidades básicas de Spring que usamos habitualmente.。
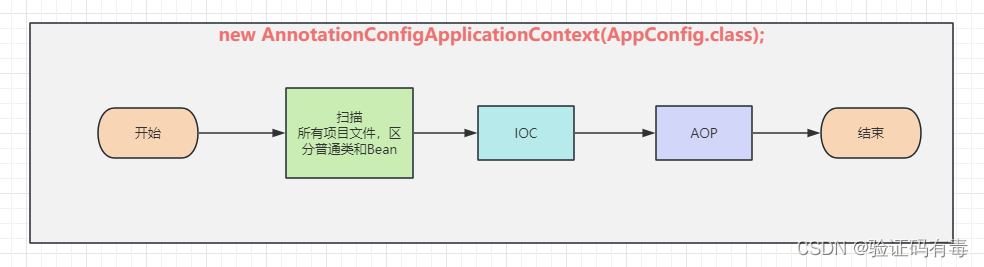
2. Especulación general del proceso
De acuerdo con las operaciones relacionadas con Spring que hemos aprendido antes, podemos simplemente especular sobre lo que se hace en esta línea de código.
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
2.1 Escaneo
El primero es el primer punto [escaneo]. Hemos escrito tantos beans en el proyecto, o en otras palabras, hay tantas clases en mi proyecto, cuáles son beans y cuáles son clases ordinarias, ¿cómo lo reconoce Spring? De hecho, la razón es muy simple: Spring no es tan inteligente, si desea obtener la información de esta clase, Spring debe echarle un vistazo [en persona] para conocer la información específica de esta clase. ¿Cuántos archivos tienes? ¿Cuántas clases escaneará? El código clave es el siguiente:
// 定义需要扫描的基础包名
@ComponentScan("org.tuling.spring")
public class AppConfig {
}
2.2 COI
Después de escanear todos los archivos, Spring básicamente puede determinar cuáles son Beans y cuáles son clases ordinarias. A continuación, puede comenzar a crear beans, aquí está el llamado proceso IOC
2.3 POA
AOP debe haber sucedido después de la COI. Si comprende el [patrón de proxy] en el patrón de diseño, no es difícil entenderlo. Después de todo, si el objeto de destino no es completamente funcional, la funcionalidad del objeto proxy también se verá afectada.
2.4 Resumen
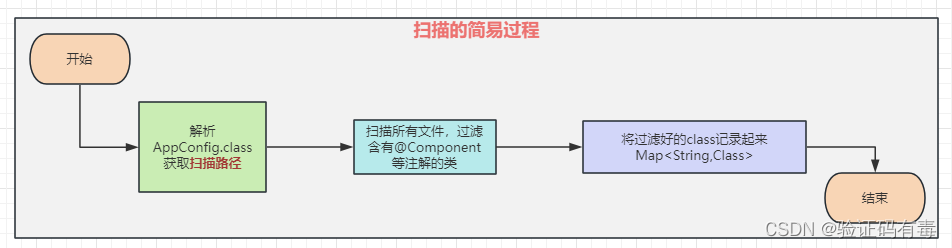
3. [Escaneo] El proceso es simple de especular.
También dijimos antes que el escaneo requiere que Spring verifique en persona cuáles deben crearse y cuáles no. Tome nuestro ejemplo new AnnotationConfigApplicationContext(AppConfig.class), los pasos generales son los siguientes: (simple especulación, desconocida)
- Primero debe mirar
AppConfig.classy leer la ruta base del paquete escaneado. - De acuerdo con la ruta básica leída en el paso anterior, recorra todos los archivos bajo el paquete, si hay anotaciones como
@Component,@Serviceetc. en la clase, se confirma como un Bean. - Después del filtrado, registre la información leída del Bean, por ejemplo, guárdela en un mapa para su posterior recorrido.
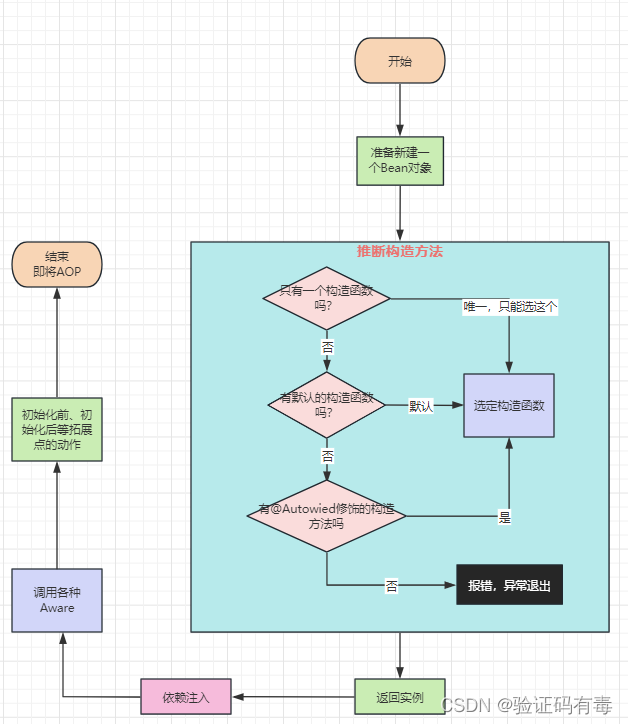
4. 【IOC】Proceso de adivinanza simple
El proceso del COI, de hecho, tiene un término más profesional en Spring, llamado: ciclo de vida del frijol. Unas pocas palabras simples contienen mucho contenido. Antes de eso, echemos un vistazo al [proceso de creación de objetos JVM] en [Conocimiento previo] para profundizar su impresión.
Incluido:
- Utilice el método de construcción de esta clase para crear una instancia de un objeto (pero si hay varios métodos de construcción en una clase, Spring elegirá, esto se llama método de construcción inferido)
- Después de obtener un objeto, Spring juzgará si hay atributos anotados por @Autowired en el objeto, descubrirá estos atributos y asignará valores a través de Spring (inyección de dependencia).
- Después de la inyección de dependencia, Spring juzgará si el objeto implementa la interfaz BeanNameAware, la interfaz BeanClassLoaderAware y la interfaz BeanFactoryAware. Si está implementado, significa que el objeto actual debe implementar los métodos setBeanName (), setBeanClassLoader () y setBeanFactory () definidos. en la interfaz Luego Spring llamará a estos métodos y pasará los parámetros correspondientes (devolución de llamada consciente)
- Después de la devolución de llamada de Aware, Spring juzgará si hay un método anotado por @PostConstruct en el objeto. Si existe, Spring llamará a este método del objeto actual (antes de la inicialización)
- Inmediatamente después, Spring juzgará si el objeto implementa la interfaz InitializingBean. Si está implementada, significa que el objeto actual debe implementar el método afterPropertiesSet () en la interfaz, y luego Spring llamará al método afterPropertiesSet () en el objeto actual. (inicialización)
- Finalmente, Spring juzgará si el objeto actual necesita realizar AOP. De lo contrario, se creará el Bean. Si se requiere AOP, realizará un proxy dinámico y generará un objeto proxy como un Bean (después de la inicialización).
Otra cosa a tener en cuenta es que después de crear el objeto Bean:
- Si el Bean actual es un Bean singleton, el objeto Bean se almacenará en un Mapa <Cadena, Objeto>, la clave del Mapa es el nombre del frijol y el valor es el objeto Bean. De esta manera, la próxima vez que obtenga Bean, podrá obtener directamente el objeto Bean correspondiente del Mapa (de hecho, en el código fuente de Spring, este Mapa es un grupo singleton);
- Si el bean actual es un bean prototipo, no habrá otras acciones en el futuro y no se almacenará ningún mapa. La próxima vez que obtenga el Bean, el proceso de creación anterior se ejecutará nuevamente y se obtendrá un nuevo objeto Bean.
4.1 Descripción detallada del proceso de inferencia del método de construcción.
En el proceso de generar beans basados en una determinada clase, Spring necesita usar el método de construcción de la clase para crear una instancia de un objeto, pero si una clase tiene múltiples métodos de construcción, ¿cuál usará Spring?
La lógica de juicio de Spring es la siguiente:
- Si una clase tiene solo un constructor, independientemente de si el constructor tiene parámetros o no, Spring usará este constructor para crear objetos porque no hay otra opción;
- Si esta clase tiene varios constructores:
- Si existe un constructor sin argumentos, utilice el constructor sin argumentos. Porque en Java, el constructor sin argumentos en sí tiene un significado predeterminado;
- Si no hay un constructor sin argumentos, mire varios constructores sin argumentos, cuál tiene
@Autowiredmodificación y selecciónelo; si no hay ninguno, solo puede informar un error
Todavía tengo una pregunta. Si Spring elige un método de construcción con parámetros, Spring necesita pasar parámetros cuando llama a este método de construcción con parámetros, entonces, ¿de dónde proviene este parámetro? La respuesta es: Spring encontrará el objeto Bean en Spring según el tipo y nombre del parámetro de entrada.
3. Primero busque según el tipo de parámetro de entrada, si solo se encuentra uno, luego utilícelo directamente como parámetro de entrada;
4. Si se encuentra más de uno según el tipo, determine cuál es el único según el nombre del parámetro de entrada 5.
Finalmente, si no se encuentra, se informará un error y no se podrá crear el objeto Bean actual.
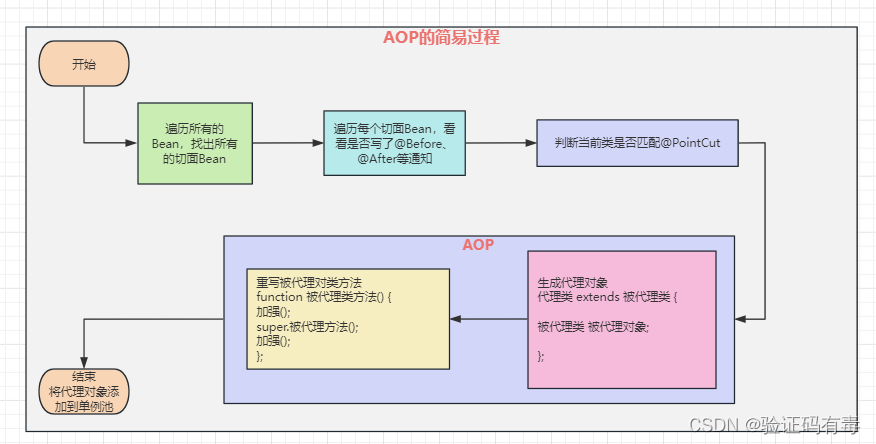
5. [AOP] proceso de adivinación simple
AOP es un proxy dinámico. En el proceso de creación de un Bean, Spring está en el último paso (Antes de ingresar al grupo singleton) juzgará si el Bean que se está creando actualmente necesita realizar AOP y, si es necesario, realizará un proxy dinámico.
Entonces, ¿cómo juzgar si AOP debe representar un Bean? Proceder de la siguiente:
- Encuentre todos los frijoles facetados (las facetas también son de frijoles, o se llaman: frijoles especiales)
- Recorra cada método en el aspecto para ver si @Before, @After y otras anotaciones (notificaciones) están escritas
- Si está escrito, juzgue si el Pointcut correspondiente coincide con la clase del objeto Bean actual
- Si coincide, significa que el objeto Bean actual tiene un Pointcut coincidente, lo que significa que se requiere AOP
El proceso general de AOP usando cglib: (consulte el paradigma de proxy anterior)
- Agregue una clase de proxy XxxProxy, que hereda del objeto proxy XxxTarget y contiene una variable miembro de XxxTarget (esta variable miembro debe pasar por un ciclo de declaración de Bean, es decir, completar IOC, etc.)
- Anular el método de la clase principal en la clase proxy
- Al ejecutar el método de la clase proxy, se llama al método de la clase proxy, pero al mismo tiempo es necesario ejecutar la lógica del aspecto.
Entonces aquí hay un paradigma para [modo proxy]:
// 被代理对象
public class ProxyTarget {
public void run() {
System.out.println("这是普通对象的run");
}
}
// 代理对象
public class ProxyModel extends ProxyTarget {
private ProxyTarget proxyTarget;
public void setProxyTarget(ProxyTarget proxyTarget) {
this.proxyTarget = proxyTarget;
}
@Override
public void run() {
System.out.println("我代理对象可以在这里做加强---1");
super.run();
System.out.println("我代理对象也可以在这里做加强---2");
}
}
Seis, asuntos de primavera
Cuando agregamos la anotación @Transactional a un método, significa que el método iniciará una transacción Spring cuando se llame, y el objeto Bean correspondiente a la clase donde se encuentra el método será el objeto proxy de la clase.
Los pasos cuando el objeto proxy de la transacción Spring ejecuta un determinado método:
- Determinar si el método que se está ejecutando actualmente tiene la anotación @Transactional
- Si existe, utilice el administrador de transacciones (TransactionManager) para crear una nueva conexión a la base de datos.
- Modifique la confirmación automática de la conexión de la base de datos a falso
- Ejecute target.test (), ejecute el código de lógica empresarial escrito por el programador, es decir, ejecute sql
- Después de la ejecución, si no hay excepción, envíe; de lo contrario, retroceda
Criterios para juzgar si una transacción Spring fallará: cuando se llama a un método anotado con @Transactional, es necesario juzgar si es llamado directamente por el objeto proxy. Si es así, la transacción tendrá efecto, y si no, fallar.(PD: este punto es fácil de pasar por alto)
Además, hay otro ejemplo clásico, es decir , el resultado es diferente cuando @Beanhay o no , de la siguiente manera:@Configuration
La forma de declarar el frijol:
@ComponentScan("org.tuling.spring")
@Configuration
public class AppConfig {
@Bean
public UserService userService() {
return new UserService(walletService());
}
@Bean
public UserService userService1() {
return new UserService(walletService());
}
@Bean
public WalletService walletService() {
return new WalletService();
}
}
// UserService声明
public class UserService {
private WalletService walletService;
public UserService() {
}
public UserService(WalletService walletService) {
this.walletService = walletService;
}
public WalletService getWalletService() {
return walletService;
}
/**
* 自我介绍
*/
public void selfIntroduction() {
System.out.println("你好,我是阿通,我有好多钱");
walletService.showMyBalance();
}
}
Mire el método de declaración de Bean anterior: según el supuesto, WalletServicedebe ser un singleton, por lo que debe ser el mismo userServiceque el objeto userService1retenido .walletService
Método de llamada:
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
UserService userService = (UserService)context.getBean("userService");
System.out.println(userService);
System.out.println(userService.getWalletService());
System.out.println("--------------------------------");
UserService userService1 = (UserService)context.getBean("userService1");
System.out.println(userService1);
System.out.println(userService1.getWalletService());
El resultado resultante es el siguiente:
org.tuling.spring.bean.UserService@2c34f934
org.tuling.spring.bean.WalletService@12d3a4e9
--------------------------------
org.tuling.spring.bean.UserService@240237d2
org.tuling.spring.bean.WalletService@12d3a4e9
Al observar los resultados, no hay ningún problema y el resultado es según lo programado. Pero si eliminamos el método que declara el Bean @Configuration, el resultado quedará así:
@ComponentScan("org.tuling.spring")
//@Configuration
public class AppConfig {
@Bean
public UserService userService() {
return new UserService(walletService());
}
@Bean
public UserService userService1() {
return new UserService(walletService());
}
@Bean
public WalletService walletService() {
return new WalletService();
}
}
org.tuling.spring.bean.UserService@710726a3
org.tuling.spring.bean.WalletService@646007f4
--------------------------------
org.tuling.spring.bean.UserService@481a15ff
org.tuling.spring.bean.WalletService@78186a70
¿Por qué simplemente anotar un @Configurationresultado es diferente? analiza de la siguiente manera:
@BeanLa anotación puede registrar el objeto devuelto por el método como un Bean, y el contenedor Spring administrará el Bean. nada mas- Por lo tanto, cuando
userService()se vuelve a llamar al métodowalletService(), en realidad es solo una llamada Java ordinaria y definitivamente se volverá a llamar.new WalletService() - Después de ser
@Configurationanotados, todos los métodos serán proxy (aún no se ha encontrado la evidencia del código fuente y la adjuntaré más tarde cuando la entienda)
resumir
- Acabo de aprender el proceso de inicio de Spring.
- A través de una serie de algunas operaciones comunes de Spring, tengo una comprensión general del proceso general de COI y AOP.