Directorio de artículos
1. Comprender la biblioteca de subprocesos nativa
La biblioteca de subprocesos existe en la memoria física y también está asignada al área compartida del espacio de direcciones, por lo que cada subproceso puede implementar fácilmente su propio código, y la biblioteca también incluye códigos como cambio y administración de subprocesos. La gestión de subprocesos de la biblioteca también se describe primero y luego se organiza. Creará un TCB similar al proceso de gestión. El TCB gestiona el LWP, es decir, el proceso ligero. El usuario envía el código al TCB y el LWP También proporcionará algunas cosas utilizables a la TCB.
La biblioteca de subprocesos contiene una parte de la biblioteca dinámica, así como el TCB de cada subproceso, que contiene el almacenamiento local del subproceso, la pila de subprocesos y otros atributos. Para encontrar un TCB, solo necesita encontrar su dirección inicial, y esta dirección es el ID del hilo, que es un dato de dirección, por lo que estos datos son relativamente grandes.
Este ID de hilo es un ID de hilo a nivel de usuario, que es una dirección virtual.
Cada subproceso debe tener su propia estructura de pila independiente y la pila de subprocesos está en el TCB. El hilo principal usa la pila del sistema de proceso y el nuevo hilo usa la pila proporcionada en la biblioteca.
Cuando el usuario usa pthread_create para crear un proceso, se creará una estructura relacionada que describe el hilo en la biblioteca, se creará un proceso liviano y se creará un TCB, que contiene varias cosas definidas por el hilo en el espacio del usuario. como el proceso ligero, la dirección y la solicitud del usuario. El método de ejecución del proceso ligero se pasa al sistema, y el sistema programará el proceso ligero y luego lo ejecutará.
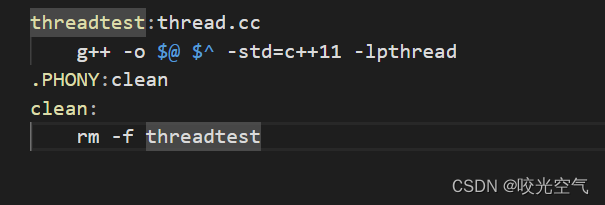
C ++ también tiene múltiples subprocesos, y la interfaz de implementación de subprocesos en C ++ también encapsula la biblioteca de subprocesos del sistema, por lo que el archivo MAKE que ejecuta el archivo C ++ debe escribirse así
#include <iostream>
#include <thread>
#include <unistd.h>
using namespace std;
void run1()
{
while(true)
{
cout << "thread 1" << endl;
sleep(1);
}
}
void run2()
{
while(true)
{
cout << "thread 2" << endl;
sleep(1);
}
}
int main()
{
thread th1(run1);
thread th2(run2);
th1.join();
th2.join();
return 0;
}
almacenamiento local de subprocesos
Varios subprocesos ejecutan el mismo método, por lo que solo hay una variable local en él y varios subprocesos operan en él a la vez, ¿o hay una variable única para cada llamada a método? De hecho, es independiente: cada hilo tiene una variable local, lo que significa que estas variables locales están en la pila de hilos y las direcciones de estas variables también son diferentes. Entonces, ¿cómo se deben tratar los nombres y direcciones de las variables?
La función se compilará antes de llamarla y el código para declarar variables se convertirá en código ensamblador. Dentro de la computadora, la pila de un proceso almacenará la parte superior de la pila (esp) y la parte inferior de la pila (ebp). Al abrir espacio, Permitirá que ebp reste los bytes ocupados por un tipo de variable y la dirección después de la resta es la dirección de la variable. Esto es para abrir espacio en tiempo de ejecución y reemplazarlo con código específico para crear variables. ebp y esp son registros dentro de la CPU, siempre que se cambien ebp y esp, se cambiará la pila del subproceso. Por lo tanto, las direcciones de las variables abiertas por diferentes subprocesos también son diferentes: una vez que se intercambian ebp y esp, van a otra pila y luego abren espacio. La creación de una variable también puede considerarse como determinar cómo crearla mediante un desplazamiento.
Al tomar la dirección, se toma la dirección más baja, porque ebp resta un número para abrir espacio, por lo que la dirección baja más el desplazamiento es la dirección inferior de la pila.
¿Qué pasa con las variables globales?
Variables globales compartidas por múltiples subprocesos, abre el segmento de datos inicializados en el espacio de direcciones. Si no desea que todos los subprocesos la compartan, agregue __thread al frente, luego la variable se almacenará en el almacenamiento local del subproceso y se copiará desde el segmento de datos inicializados al almacenamiento local. Cuando lo imprima, encontrará que la dirección se ha hecho más grande, porque la biblioteca del subproceso está entre las pilas y la dirección del segmento de datos inicializado es menor que la dirección del montón.
2. Exclusión mutua
La mayoría de los recursos en subprocesos múltiples se compartirán, por lo que debe haber acceso concurrente, es decir, varios subprocesos acceden al mismo recurso. Entonces, para resolver este problema, un subproceso accede a un recurso y otros subprocesos no pueden acceder a él nuevamente. Esto es acceso en serie, es decir, exclusión mutua. Estos recursos son recursos críticos y el código que accede a los recursos críticos es una sección crítica.
Eche un vistazo al escenario de acceso concurrente. Dos subprocesos AB acceden a la misma variable gval, que es un recurso compartido. Los datos están en la memoria, pero el cálculo está en la CPU, por lo que el flujo de ejecución debe cargar los datos en el registro, luego realizar la operación de cálculo y luego escribir los datos modificados en la memoria, que son 3 pasos. Supongamos que gval == 100, el subproceso A coloca la variable en el registro, -, después de que gval se convierte en 99, en este momento el intervalo de tiempo de A ha finalizado, entonces el sistema lo detendrá y A traerá su propio contexto y la variable de operaciones completadas se colgará. .
Luego B ejecuta nuevamente, B también hace la misma acción, pero B piensa que gval todavía es 100, porque la acción de retorno de A no se ha realizado, y luego B lo calcula y luego lo vuelve a escribir en la memoria, suponiendo que AB está en el bucle while –, luego B regresa y repite la acción anterior nuevamente, coloca el gval con un valor de 99 en el registro y luego calcula; continúa el bucle, suponiendo que gval se reduce a 10 y luego se reduce a 9, antes de regresar , no se ha reescrito como si A se hubiera visto obligado a detenerse.
Una vez que B haya terminado, será el turno de A nuevamente y A continuará escribiendo, por lo que los datos que originalmente eran 10 se cambiarán a 99. Si el acceso a las variables globales no está protegido, habrá un problema de acceso concurrente, lo que provocará inconsistencia en los datos.
Si los recursos compartidos están protegidos, se denominan recursos críticos. Cualquier subproceso tiene código para acceder a recursos críticos, y esta parte del código se denomina sección crítica. Por supuesto, algunos subprocesos no acceden a recursos críticos y estas partes son secciones no críticas. Si desea que varios subprocesos accedan de forma segura a recursos críticos, existen formas como el acceso de exclusión mutua y el bloqueo.
1. Código concurrente (obtener boletos)
int tickets = 10000;
void* threadRoutine(void* name)
{
string tname = static_cast<const char*>(name);
while(true)
{
if(tickets > 0)
{
usleep(2000);//模拟抢票花费的时间, usleep的参数是微秒级别
cout << tname << "get a ticket: " << tickets-- << endl;
}
else break;
}
return nullptr;
}
int main()
{
pthread_t t[4];
int n = sizeof(t) / sizeof(t[0]);
for(int i = 0; i < n; ++i)
{
char* data = new char[64];
snprintf(data, 64, "thread-%d", i + 1);
pthread_create(t + i, nullptr, threadRoutine, data);
}
for(int i = 0; i < n; ++i)
{
pthread_join(t[i], nullptr);
}
return 0;
}
Este terminará siendo un número negativo. Cuando el número de tickets es 1, pueden ingresar varios subprocesos. Si el subproceso ingresado no ha comenzado a funcionar, continuará ingresando al subproceso. El subproceso ingresado también puede tener un intervalo de tiempo. En los tickets, aquí hay varios subprocesos. Si , eventualmente habrá un número negativo, por lo que los boletos > 0 y los boletos son áreas críticas.
2. bloquear
Para bloquear, es necesario introducir el archivo de encabezado pthread.h
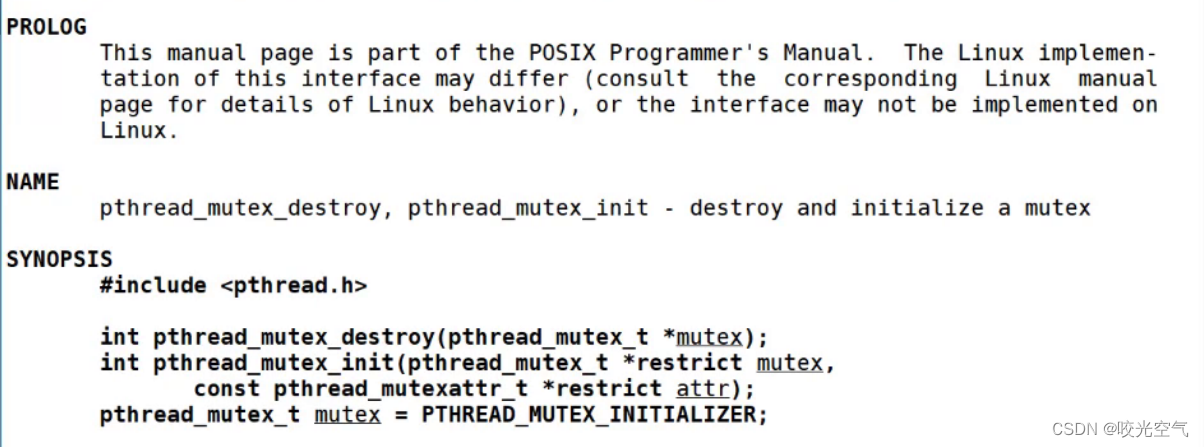
Hay dos formas de inicializar: siempre que el bloqueo sea global o estático, puede seguir la última línea, pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER, y luego no es necesario destruirlo; el otro es un bloqueo local, que debe ser inicializado + destruido. pthread_mutex_t es el tipo de bloqueo de exclusión mutua. El bloqueo debe inicializarse antes de poder usarse y debe destruirse cuando se agote.
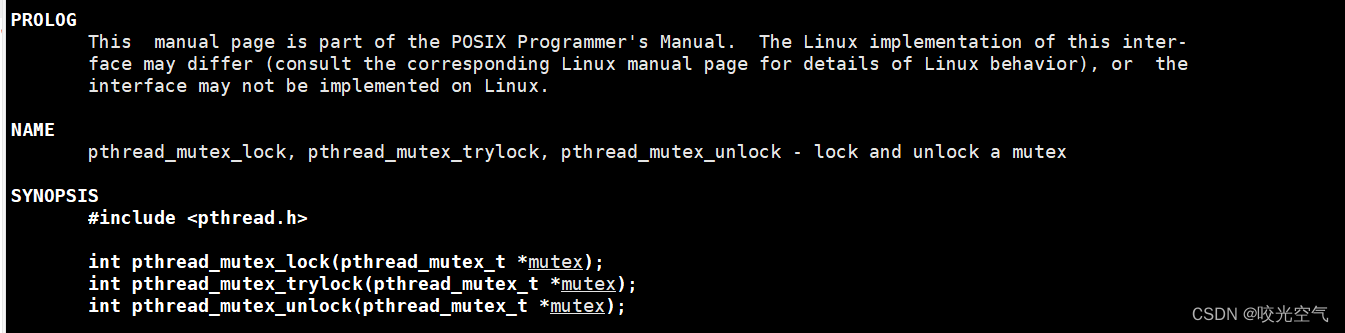
Agregar interfaz de desbloqueo. Si no se agrega, bloquee y espere hasta que se agregue.
int tickets = 10000;
pthread_mutex_t mutex;//必须先申请一把锁<F7>
void* threadRoutine(void* name)
{
string tname = static_cast<const char*>(name);
while(true)
{
pthread_mutex_lock(&mutex);//所有线程都得遵守这个规则
if(tickets > 0)
{
usleep(2000);//模拟抢票花费的时间, usleep的参数是微秒级别
cout << tname << "get a ticket: " << tickets-- << endl;
pthread_mutex_unlock(&mutex);
}
else
{
pthread_mutex_unlock(&mutex);
break;
}
}
return nullptr;
}
int main()
{
pthread_mutex_init(&mutex, nullptr);
pthread_t t[4];
int n = sizeof(t) / sizeof(t[0]);
for(int i = 0; i < n; ++i)
{
char* data = new char[64];
snprintf(data, 64, "thread-%d", i + 1);
pthread_create(t + i, nullptr, threadRoutine, data);
}
for(int i = 0; i < n; ++i)
{
pthread_join(t[i], nullptr);
}
pthread_mutex_destroy(&mutex);
return 0;
}
Después de este cambio, la velocidad será más lenta debido al proceso de bloqueo. Pero descubrirás que todos son un solo hilo para conseguir billetes. Debido a que un subproceso se está bloqueando, varios otros subprocesos están esperando, y el intervalo de tiempo del subproceso que toma el bloqueo no ha llegado, y otros subprocesos han estado esperando, por lo que solo habrá un subproceso que toma tickets.
codificar con clase
#include <iostream>
#include <unistd.h>
#include <string>
#include <cstdio>
#include <cstring>
#include <phread.h>
#include <thread>
#include <ctime>
using namespace std;
int tickets = 10000;
//pthread_mutex_t mutex;//必须先申请一把锁
class TData
{
public:
TData(const string& name, pthread_mutex_t* mutex):_name(name), _pmutex(mutex)
{
}
~TData()
{
}
public:
string _name;
pthread_mutex_t* _pmutex;
}
void* threadRoutine(void* args)
{
TData* td = static_cast<TData*>(args);
//string tname = static_cast<const char*>(name);
while(true)
{
pthread_mutex_lock(td->_pmutex);//所有线程都得遵守这个规则
if(tickets > 0)
{
usleep(2000);//模拟抢票花费的时间, usleep的参数是微秒级别
cout << td->_name << "get a ticket: " << tickets-- << endl;
pthread_mutex_unlock(td->_pmutex);
}
else
{
pthread_mutex_unlock(td->_pmutex);
break;
}
}
return nullptr;
}
int main()
{
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr);
pthread_t tids[4];
int n = sizeof(t) / sizeof(t[0]);
for(int i = 0; i < n; ++i)
{
char name[64];
snprintf(name, 64, "thread-%d", i + 1);
TData* td = new TData(name, &mutex);
pthread_create(tids + i, nullptr, threadRoutine, td);
}
for(int i = 0; i < n; ++i)
{
pthread_join(tids[i], nullptr);
}
pthread_mutex_destroy(&mutex);
return 0;
}
A través de lo anterior se puede encontrar
Todos los subprocesos que acceden al mismo recurso crítico deben estar protegidos por bloqueos y se debe agregar el mismo bloqueo, esta es una regla que no se puede violar.
Antes de que cada subproceso acceda al área crítica, debe bloquearse. La esencia del bloqueo es bloquear el área crítica. Después del bloqueo, el código realiza un acceso en serie. La granularidad de bloqueo debe ser lo más fina posible. No tenga código redundante cerca del área, o tomará más tiempo para ejecutar
Antes de bloquear, todos los subprocesos deben ver primero el mismo bloqueo, por lo que el bloqueo en sí es un recurso público y el bloqueo y desbloqueo son atómicos, por lo que el bloqueo puede garantizar su propia seguridad.
Una sección crítica puede ser una línea de código o un lote de código, por lo que es probable que el hilo se cambie antes de desbloquearse y también se puede cambiar al bloquear. Pero no tiene ningún efecto. Si se apaga después de haber sido bloqueado en la sección crítica, otros procesos no pueden solicitar el bloqueo nuevamente e ingresar a la sección crítica. Solo pueden esperar a que el hilo termine de ejecutarse antes de solicitar el bloqueo. es la serialización provocada por la exclusión mutua y el rendimiento de la optimización también es la razón por la que se ralentizará después del bloqueo. Desde la perspectiva de otros subprocesos, el estado significativo para ellos es que el bloqueo se aplica y se libera, por lo que la atomicidad del bloqueo se refleja aquí y el desbloqueo también es atómico.
Linux llama a este bloqueo mutex o mutex.
3. El principio de realización del bloqueo de exclusión mutua.
Para realizar la operación de bloqueo de exclusión mutua, la mayoría de las arquitecturas proporcionan instrucciones de intercambio o intercambio, la función de esta instrucción es intercambiar los datos del registro y la unidad de memoria, ya que solo hay una instrucción, la atomicidad está garantizada, incluso para plataformas multiprocesador. , Los ciclos de bus para acceder a la memoria también están secuenciados. Cuando se ejecuta la instrucción de intercambio en un procesador, la instrucción de intercambio de otro procesador solo puede esperar el ciclo de bus. Eche un vistazo al pseudocódigo de agregar/desbloquear.

El hilo que llama ejecutará el bloqueo y el desbloqueo. Asigne espacio para mutex en la memoria y el valor de la variable predeterminado es 1. Cuando un hilo comienza a bloquearse, primero pasará 0 al registro %al, que en realidad es para inicializarlo a 0. Solo hay un conjunto de hardware de registro, pero los datos dentro del registro, es decir, el contexto del flujo de ejecución, pertenecen al hilo mismo. Equivale a poner objetos personales en zonas públicas. Entonces, el significado de la primera oración de bloqueo es llamar al hilo, escribir 0 en su propio contexto y luego quitar este 0 al cambiar.
La segunda oración es la instrucción de intercambio, el registro y el espacio de bloqueo intercambian datos, la esencia es intercambiar los datos compartidos en su propio contexto privado, es decir, intercambiar las posiciones de 1 y 0 en el registro, esta operación es bloquear, esta declaración de ensamblaje corresponde a la atomicidad del bloqueo. Si no se ha realizado el siguiente paso en este momento y el hilo se cambia, el hilo eliminará el contenido del registro en este momento, registrará el código ejecutado por el hilo y continuará con esta línea de código después de volver a cambiar. . Pero en este momento el candado es 0, el siguiente hilo aún ejecuta el código del candado, el registro se inicializa a 0 y luego se intercambia con el candado, ingresa el juicio y descubre que el registro es 0, por lo que cuelga. y espera, por lo que la solicitud del bloqueo falla, este hilo Esperó con el contexto, esperó hasta que el hilo que solicitó el bloqueo con éxito regresó, puso 1 en el registro y luego juzgó, devolvió 0, el bloqueo fue exitoso. Así que sólo fluiré.
Entonces podrás verlo desbloqueado.
3. Encapsulación de hilos
1. Ontología de hilos
Pasa el código directamente aquí
#include <iostream>
#include <pthread.h>
#include <string>
#include <cstdlib>
using namespace std;
typedef void (*func_t)();
class Thread
{
public:
typdef enum
{
New = 0,
RUNNING,
EIXTED
}ThreadStatus;
typedef void (*func_t)(void*);
public:
Thread(int num, func_t func, void* args):_tid(0), _status(NEW), _func(func), _args(args)//num是线程编号
{
char name[128];
snprintf(name, sizeof(name), "thread-%d", num);
_name = name;
}
int status() {
return _status;}
string threadname() {
return _name;}
pthread_t threadid()
{
if(_status == RUNNING) return _tid;
else
{
return 0;
}
}
//runHelper是成员函数,类的成员函数具有默认参数this,也就是括号有一个Thread* this,pthread_create的参数应当是void*类型,就不符合,所以加上static,放在静态区,就没有this,但是又有新问题了
//static成员函数无法直接访问类内属性和其他成员函数,所以create那里要传this指针,this就是当前线程对象,传进来才能访问类内的东西
static void* runHelper(void* args)//args就是执行方法的参数
{
Thread* ts = (Thread*)args;//就拿到了当前对象
//函数里可以直接调用func这个传过来的方法,参数就是_args
(*ts)();//调用了func函数
return nullptr;
}
void operator()()//仿函数
{
if(_func != nullptr) _func(_args);
}
void run()//run函数这里传方法
{
int n = pthread_create(&_tid, nullptr, runHelper, this);//为什么传this?
if(n != 0) exit(1);
_status = RUNNING;
}
void join()
{
int n = pthread_join(_tid, nullptr);
if(n != 0)
{
cerr << "main thread join thread" << _name << "error" << endl;
return ;
}
_status = EXITED;
}
~Thread()
{
}
private:
pthread_t _tid;
string _name;
func_t func;//线程未来要执行的函数方法
void* _args;//也可以不写这个,那么typedef的函数指针就没有参数。当然,参数也可用模板来写
ThreadStatus _status;
}
Entonces el código del hilo original se puede escribir así
void threadRun(void* args)
{
string message = static_cast<const char*>(args);
while(true)
{
cout << "我是一个线程, " << message << endl;
sleep(1);
}
}
int main()
{
//弄两个线程
Thread t1(1, threadRun, (void*)"hellobit1");
Thread t2(2, threadRun, (void*)"hellobit2");
cout << "thread name: " << t1.threadname() << "thread id: " << t1.threadid() << ",thread status: " <<t1.status() << endl;
cout << "thread name: " << t1.threadname() << "thread id: " << t1.threadid() << ",thread status: " <<t1.status() << endl;
t1.run();
t2.run();
cout << "thread name: " << t1.threadname() << "thread id: " << t1.threadid() << ",thread status: " <<t1.status() << endl;
cout << "thread name: " << t1.threadname() << "thread id: " << t1.threadid() << ",thread status: " <<t1.status() << endl;
t1.join();
t2.join();
cout << "thread name: " << t1.threadname() << "thread id: " << t1.threadid() << ",thread status: " <<t1.status() << endl;
cout << "thread name: " << t1.threadname() << "thread id: " << t1.threadid() << ",thread status: " <<t1.status() << endl;
return 0;
}
2. Bloqueo de encapsulación
#pragma once
#include <iostream>
#include <pthread.h>
class Mutex//自己不维护锁,由外部传入
{
public:
Mutex(pthread_mutex_t *mutex):_pmutex(mutex)
{
}
void lock()
{
pthread_mutex_lock(_pmutex);
}
void unlock()
{
pthread_mutex_unlock(_pmutex);
}
~Mutex()
{
}
private:
pthread_mutex_t *_pmutex;
}
class LockGuard//自己不维护锁,由外部传入
{
public:
LockGuard(pthread_mutex_t *mutex):_mutex(mutex)
{
_mutex.lock();
}
~LockGuard()
{
_mutex.unlock();
}
private:
Mutex _mutex;
}
bloqueo de código
int tickets = 1000;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;//全局初始化
void threadRoutine(void* args)
{
string *message = static_cast<const char*>(args);
while(true)
{
LockGuard lockguard(&mutex);//交给类去自动创建,析构锁//RAII风格加锁
if(tickets > 0)
{
usleep(2000);
cout << message << "get a ticket: " << tickets-- << endl;
}
else
{
break;
}
}
}
int main()
{
Thread t1(1, threadRoutine, (void*)"hellobit1");
Thread t2(2, threadRoutine, (void*)"hellobit2");
Thread t3(3, threadRoutine, (void*)"hellobit3");
Thread t4(4, threadRoutine, (void*)"hellobit4");
t1.run();
t2.run();
t3.run();
t4.run();
t1.join();
t2.join();
t3.join();
t4.join();
return 0;
}
4. Seguridad del hilo
Situaciones inseguras comunes:
Funciones que no protegen variables compartidas
Funciones cuyo estado cambia cuando se llaman Funciones
que devuelven punteros a variables estáticas Funciones
que llaman a funciones no seguras para subprocesos
Situación de seguridad de subprocesos comunes:
cada subproceso solo tiene permiso de lectura para variables globales o variables estáticas, pero no permiso de escritura. En términos generales, estos subprocesos son seguros. Las
clases o interfaces parciales son operaciones atómicas para subprocesos.
Múltiples subprocesos El cambio entre ellos no causará ambigüedad en el resultado de la ejecución de esta interfaz
Situaciones comunes no reentrantes:
llamar a la función malloc/free, porque la función malloc usa una lista enlazada global para administrar el montón,
llamar a la función de biblioteca de E/S estándar y muchas implementaciones de la biblioteca de E/S estándar se utilizan en un manera no reentrante Estructuras de datos globales
Las estructuras de datos estáticas se utilizan en cuerpos de funciones no reentrantes
Situaciones reentrantes comunes:
no use variables globales o variables estáticas,
no use el espacio creado por malloc o new,
no llame a funciones no reentrantes,
no devuelva datos estáticos o globales, todos los datos son proporcionados por la persona que llama a la función
utilizar datos locales, o proteger datos globales haciendo una copia local de los datos globales
La reentrada
está relacionada con la seguridad de los subprocesos: las funciones son reentrantes, es decir, las
funciones seguras para los subprocesos no son reentrantes, por lo que no pueden ser utilizadas por varios subprocesos, lo que puede causar problemas de seguridad de los subprocesos, que pueden resolverse mediante bloqueos y otros métodos Controlar si
un La función tiene variables globales, entonces la función no es segura para subprocesos ni es reentrante.
La diferencia entre reentrante y seguridad para subprocesos:
una función reentrante es un tipo de
seguridad para subprocesos que describe el estado de una función que no es necesariamente reentrante, y una función reentrante debe ser segura para subprocesos (solo segura durante la llamada, si no es necesario llamar a variables globales antes y después de esto)
Si el acceso a recursos críticos está bloqueado, esta función es segura para subprocesos, pero si la función reentrante no se ha liberado, se
producirá un punto muerto. Por lo tanto, no es reentrante.
5. Punto muerto
El punto muerto, un recurso crítico, necesita tener dos bloqueos al mismo tiempo para poder acceder. Dos subprocesos mantienen cada uno un bloqueo y solicitan otro bloqueo entre sí, lo que provoca que ambos subprocesos se suspendan, lo que también provoca un punto muerto.
Cuatro condiciones necesarias para el punto muerto:
1. Condición de exclusión mutua: un recurso solo puede ser utilizado por un flujo de ejecución a la vez
2. Condición de solicitud y retención: cuando un flujo de ejecución se bloquea debido a la solicitud de recursos, conserve los recursos obtenidos
3. No -condición de privación: el recurso obtenido por un flujo de ejecución no se puede privar por la fuerza antes de que se agote
4. Condición de bucle (bucle y espera): varios flujos de ejecución forman un ciclo de cabeza a cola para esperar recursos Relación
Es decir, mientras se produzca un punto muerto, se deben cumplir estas cuatro condiciones.
La forma de evitar el punto muerto es romper el punto muerto, rompiendo cualquiera de estas cuatro condiciones.
Libere activamente el bloqueo sin bloquear
(la función trylock es un bloqueo de aplicación sin bloqueo y el bloqueo no se agregará si la aplicación falla. Generalmente se usa cuando se ha aplicado el primer bloqueo para usar la interfaz de bloqueo y el segundo el bloqueo es trylocked. Hágalo usted mismo, como liberar el primer bloqueo)
El orden en que varios subprocesos solicitan bloqueos es consistente
. ¿Puede el hilo A solicitar bloqueos y el hilo B puede liberar el bloqueo de A? Agregar y desbloquear se puede hacer en diferentes hilos. Es posible controlar los hilos para liberar los bloqueos de manera uniforme. Para este punto, puede mirar el pseudocódigo del proceso de bloqueo anterior. Al final está mov, pero el código es como intercambio. ¿Qué significa? El hilo no necesita devolver el bloqueo y el sistema, naturalmente, tiene una forma. para reclamar el candado.
6. Sincronización de hilos
Los subprocesos pueden cambiar libremente en la sección crítica y el sistema la protege para que no se vea afectada. Cuando un hilo sale de la sección crítica, después de que se libera el bloqueo, otros hilos pueden solicitar el bloqueo. No se puede aplicar, solo se puede esperar. Si el hilo continúa aplicando y liberando el bloqueo en un ciclo, entonces este es un hilo ineficiente. Para resolver este problema, el sistema formula reglas, el hilo que acaba de liberar el bloqueo no puede volver a aplicarse inmediatamente Bloqueo, los hilos en espera deben organizarse en orden y el hilo que sale debe ponerse en cola hasta el final del cola. De esta manera, según las reglas de seguridad, el acceso de subprocesos múltiples a los recursos tiene un orden determinado, que es la sincronización de subprocesos. Esta es una forma de que varios subprocesos trabajen juntos.
1. Variable de condición
Utilizado para lograr la sincronización de subprocesos múltiples, un subproceso puede notificar a otro subproceso de la operación que se realizará a través de la variable de condición. En la captura de boletos anterior, primero ciérrelo y luego juzgue si el número de votos es menor que 0. Este juicio es un recurso crítico, por lo que se juzga en el área crítica. Si el número de votos es menor que 0, se romperá y saldrá. Si lo cambia, se convierte en Si el número de votos es menor que 0, libere el bloqueo y luego repita la acción anterior, solicite el bloqueo, juzgue y el sistema liberará automáticamente el boleto, por lo que este programa necesita juzgar continuamente, lo que conduce a un programa ineficiente. Mientras estas acciones están en progreso, otros subprocesos no pueden realizar otras operaciones. Por lo tanto, se necesitan variables de condición para controlar toda la ejecución secuencial de bloqueo y desbloqueo y acceso a recursos críticos.
1. Interfaz
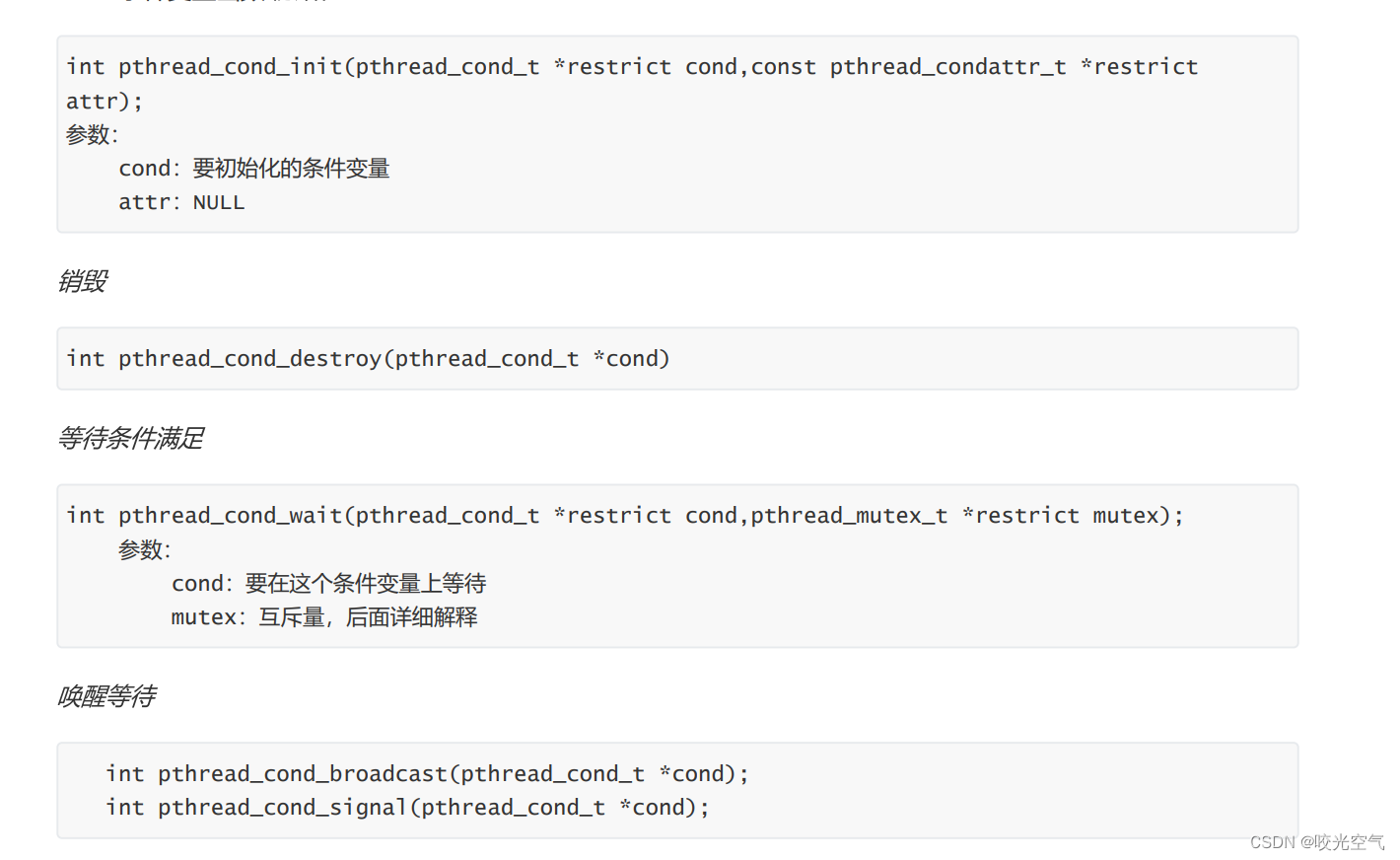
El tipo de variable de condición es en realidad una estructura. La función de espera, mutex es un bloqueo de exclusión mutua, y el juicio de condición debe ser después del bloqueo. Si no se cumple la condición, llame a esta interfaz, liberará el bloqueo propiedad del hilo y luego dejará que el hilo espere, que es ¿Por qué la interfaz de espera tiene un parámetro de bloqueo? La señal puede activar un hilo en espera y la transmisión puede activar todos los hilos en espera. La transmisión es transmisión, lo cual es familiar en Python.
2. código de demostración
La creación de variables de condición y bloqueos, etc. son similares.

const int num = 5;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
pthread_mutex_t mutex = PTHREAD_COND_INITIALIZER;
void* active(coid* args)
{
string name = static_cast<const char*>(args);
while(true)
{
pthread_mutex_lock(&mutex);
pthread_cond_wait(&cond, &mutex);//先默认一进入循环就已经是不符合判断了
cout << name << "活动" << endl;
pthread_mutex_unlock(&mutex);
}
}
int main()
{
pthread_t tids[num];
for(int i = 0; i < num; i++)
{
char* name = new char[32];
snprintf(name, 32, "thread-%d", i + 1);
pthread_create(tids + i, nullptr, active, name);
}
sleep(3);//经过上面的代码,所有线程都处于等待状态了,接下来全部唤醒
while(true)
{
//唤醒会从队列的第一个线程开始,唤醒后这个线程就会从被wait处开始,继续执行之后的代码,所以会打印活动
cout << "main thread wake up..." << endl;
pthread_cond_signal(&cond);
//pthread_cond_broadcast(&cond);会一次性打印5个线程,打印的顺序就是队列中的顺序,并且之后都会以这个顺序打印
sleep(1);//每隔一秒唤醒一个
}
for(int i = 0; i < num ; i++)
{
pthread_join(tids[i], nullptr);
}
}
Abra otra ventana y use while :; do ps -aL | head -1&&ps -aL | grep threadtest; sleep 1; done para verificar la situación. threadtest es el nombre del programa ejecutable nombrado por el propio programador.
Las variables de condición permiten que varios subprocesos se pongan en cola y esperen en cond.
Finalizar.