经典HTML前端面试题总结
-
- 1. 1简述一下你对 HTML 语义化的理解?.
- 1.2 标签上 title 与 alt 属性的区别是什么?
- 1.3 iframe的优缺点?
- 1.4 href 与 src?
- 1.5 HTML、XHTML、XML有什么区别
- 1.6 知道img的srcset的作用是什么?
- 1.7 link和@import的区别?
- 1.8 谈谈对BFC的理解 是什么?
- 1.9 html5有哪些新特性,移除了哪些元素?如何处理HTML5新标签的浏览器谦容问题?如何区分HTML和HTML5?
- 1.10 浏览器的内核分别是什么?经常遇到的浏览器的谦容性有哪些?原因,解决方法是什么,常用hack的技巧?
- 1.11 html常见兼容性问题?
- 1.12 什么是外边距重叠?重叠的结果是什么?
- 1.13 你能描述一下渐进增强和优雅降级之间的不同吗?
- 1.14 HTML5和css3的新标签
- 1.15 DOCTYPE的作用?严格模式和混杂模式的区别?
- 1.16 说一下HTML5的离线存储?
- 1.17 说一下怎么做好seo?
- 1.18 说一下drag api?
- 1.19 说一下canvas和svg的区别?
- 1.20 行内元素有哪些?块级元素有哪些? 空(void)元素有那些?行内元素和块级元素有什么区别?
- 1.21 说说你对 SSG 的理解
- 1.22 说一下web worker?
- 1.23 说一下img的srcset作用?alt和title的区别?
- 1.24 说说你对 Dom 树的理解
- 1.25 Node 和 Element 是什么关系?
- 1.26 导致页面加载白屏时间长的原因有哪些,怎么进行优化?
- 1.27 渐进式jpg有了解过吗?
- 1.28 怎么实现“点击回到顶部”的功能?
- 1.29 Cómo lograr la optimización SEO
- 1.30 ¿Qué es el SEO?
- 1.31 ¿Qué es la preresolución de DNS? ¿Cómo lograrlo?
- 1.32 Cómo utilizar indexDB
- 1.33 ¿Qué API relacionadas con el arrastre tiene HTML5?
- 1.34 ¿Cuál es el motivo de los caracteres confusos en el navegador? ¿Cómo resolver?
- 1.35 ¿Cómo afectan js y css a la construcción del árbol DOM?
- 1.36 La diferencia entre solo lectura y deshabilitado en el formulario
- 1.37 Navegadores y kernels convencionales
- 1.38 Hable sobre su comprensión de los siguientes eventos del ciclo de vida de la página: DOMContentLoaded, cargar, antes de descargar, descargar
- 1.39 Cuando se utiliza la etiqueta de entrada para cargar imágenes, ¿cómo activar la función de cámara predeterminada?
- 1.40 ¿Cómo prohibir que la entrada muestre el historial de entrada?
- 1.41 ¿Qué es iconfont? ¿Cuáles son los pros y los contras?
- 1.42 ¿Cuáles son los indicadores PV y UV comúnmente utilizados en las estadísticas de páginas?
- 1.43 ¿El dpr de un dispositivo es variable?
- 1.44 ¿Cuáles son las reglas de carga y representación de imágenes en html y css?
- 1.45 ¿Cuál es el uso de la ventana gráfica en la etiqueta mete?
- 1.46 Cómo elegir el formato de imagen en la interfaz
1. 1 Describe brevemente tu comprensión de la semántica HTML. .
- Haga lo correcto con la etiqueta correcta.
- La semántica HTML hace que el contenido de la página sea estructurado y más claro, lo cual es conveniente para que los navegadores y motores de búsqueda lo analicen, se muestra en formato de documento incluso si no hay estilo>estilo CSS y es fácil de leer;
- Los rastreadores de motores de búsqueda también se basan en etiquetas HTML para determinar el contexto y el peso de cada palabra clave, lo cual es bueno para el SEO;
- Facilite a las personas que leen el código fuente dividir el sitio web en bloques, lo cual es fácil de leer, mantener y comprender.
1.2 ¿Cuál es la diferencia entre los atributos title y alt en las etiquetas?
alt es para que el motor de búsqueda lo identifique y el texto alternativo cuando la imagen no se puede mostrar;
el título es la información de anotación sobre el elemento, principalmente para que los usuarios la interpreten.
Cuando se coloca el mouse sobre el texto o la imagen, se mostrará el texto del título. (Porque IE no es estándar) En el navegador IE, alt desempeña el papel de título y se convierte en un mensaje de texto.
Al definir el objeto img, escriba todos los atributos alt y title para asegurarse de que se pueda usar normalmente en varios navegadores.
alt es para que el motor de búsqueda lo identifique y el texto alternativo cuando la imagen no se puede mostrar;
el título es la información de anotación sobre el elemento, principalmente para que los usuarios la interpreten.
Cuando se coloca el mouse sobre el texto o la imagen, se mostrará el texto del título. (Porque IE no es estándar) En el navegador IE, alt desempeña el papel de título y se convierte en un mensaje de texto.
Al definir el objeto img, escriba todos los atributos alt y title para asegurarse de que se pueda usar normalmente en varios navegadores.
1.3 ¿Cuáles son las ventajas y desventajas del iframe?
ventaja:
- Soluciona problemas de carga con contenido de terceros de carga lenta, como íconos y anuncios.
- Zona de seguridad de seguridad
- Cargar scripts en paralelo
defecto:
- iframe bloqueará el evento Onload de la página principal
- Incluso si el contenido está vacío, tardará en cargarse.
- sin semántica
1.4 href y src?
- href (referencia de hipertexto) especifica la ubicación de un recurso web, definiendo así un vínculo o relación entre el elemento actual o el documento actual y el ancla o recurso deseado definido por el atributo actual. (El propósito no es hacer referencia a recursos, sino establecer un vínculo para que la etiqueta actual pueda vincularse a la dirección de destino).
- src source (abreviatura), apunta a la ubicación del recurso externo, y el contenido señalado se aplicará a la ubicación de la etiqueta actual en el documento.
- La diferencia entre href y src
- 1. Los tipos de recursos solicitados son diferentes: href apunta a la ubicación del recurso de red y establece una conexión con el elemento actual (ancla) o el documento actual (enlace). Cuando se solicita el recurso src, los recursos a los que apunta se descargarán y aplicarán al documento, como scripts JavaScript e imágenes img;
- 2. Los resultados son diferentes: href se usa para establecer una conexión entre el documento actual y el recurso de referencia, src se usa para reemplazar el contenido actual;
- 3. Los métodos de análisis del navegador son diferentes: cuando el navegador analiza src, suspenderá la descarga y el procesamiento de otros recursos hasta que el recurso se cargue, compile y ejecute. Lo mismo ocurre con las imágenes y los marcos, de forma similar a aplicar el método puntiagudo. recurso al contenido actual. Es por eso que se recomienda colocar el script js en la parte inferior en lugar del encabezado.
1.5 ¿Cuál es la diferencia entre HTML, XHTML y XML?
- HTML (lenguaje de marcado de hipertexto): antes de html4.0, HTML tenía implementación y luego estándares, lo que resultaba en un HTML muy confuso y suelto.
- XML (lenguaje de marcado extensible): se utiliza principalmente para almacenar datos y estructuras, y es extensible. El conocido JSON también tiene una función similar, pero es más liviano y eficiente, por lo que el mercado XML es cada vez más pequeño.
- XHTML (Lenguaje de marcado de hipertexto extensible): basado en los dos anteriores, nació el W3C para resolver el problema de la confusión de HTML, y en base a esto nació HTML5. De ahí surgió la práctica de agregarlo al principio. Si no es así agregado, es compatible con HTML confuso.Se
<!DOCTYPE html>agregó el modo estándar.
1.6 ¿Cuál es la función de srcset de img?
Se pueden diseñar imágenes responsivas y podemos usar dos nuevos atributos srcset y tamaños para proporcionar más imágenes de recursos adicionales y sugerencias para ayudar al navegador a elegir el recurso correcto.
srcset define el conjunto de imágenes que permitimos que el navegador elija y el tamaño de cada imagen.
tamaños define un conjunto de condiciones de medios (como el ancho de la pantalla) e indica qué tamaño de imagen es la mejor opción cuando ciertas condiciones de medios son verdaderas.
Entonces, con estos atributos, el navegador:
- Ver ancho del dispositivo
- Compruebe qué condición del medio es verdadera primero en la lista de tamaños
- Ver el tamaño de espacio asignado a esta consulta de medios
- Carga la imagen a la que se hace referencia en la lista srcset más cercana al tamaño de ranura seleccionado
srcset proporciona la posibilidad de seleccionar imágenes según las condiciones de la pantalla

1.7 ¿Cuál es la diferencia entre enlace e @import?
- link pertenece a etiquetas XHTML, mientras que @import lo proporciona CSS.
- Cuando se carga la página, el enlace se cargará al mismo tiempo y el CSS al que hace referencia @import esperará hasta que se cargue la página antes de cargar.
- import sólo puede ser reconocido por IE 5 y superior, y el enlace es una etiqueta XHTML, por lo que no hay ningún problema de compatibilidad.
- El peso de estilo del método de enlace es mayor que el de @import.
- La diferencia al usar dom para controlar estilos. Cuando usa javascript para controlar el dom para cambiar el estilo, solo puede usar la etiqueta de enlace, porque @import no está controlado por el dom.
1.8 ¿Qué entiende usted por BFC?
Explicación escrita: desmantelamiento de BFC (Block Formatting Context) en inglés
- Bloque: el bloque aquí puede entenderse como cuadro a nivel de bloque, que se refiere al estándar de cuadros a nivel de bloque.
- Contexto de formato: formato de contexto a nivel de bloque, que es un área de representación en la página y tiene un conjunto de reglas de representación que determinan cómo se ubicarán sus elementos secundarios, así como la relación e interacción con otros elementos.
BFC se refiere a un área de representación independiente, solo participa el Cuadro a nivel de bloque, especifica cómo se distribuye el Cuadro a nivel de bloque interno y no tiene nada que ver con el exterior de esta área .
Su función es aislar los elementos del interior del BFC de los elementos exteriores en una zona independiente .
¿Cómo formarse?
Condiciones de activación de BFC:
- El elemento raíz, el elemento HTML.
- posición: fija/absoluta
- flotador no es ninguno
- el desbordamiento no es visible
- El valor de visualización es bloque en línea, celda de tabla, título de tabla
- ¿Cual es el rol?
- Evitar que los márgenes se superpongan
- Diseño de dos columnas, evitando el ajuste de texto, etc.
- Evitar que los elementos colapsen
1.9 ¿Cuáles son las nuevas características de html5 y qué elementos se han eliminado? ¿Cómo lidiar con el problema de modestia del navegador de la nueva pestaña HTML5? ¿Cómo distinguir HTML y HTML5?
* HTML5 ya no es un subconjunto de SGML, principalmente para agregar imágenes, ubicación, almacenamiento, multitarea y otras funciones.
* Pintura lienzo
elementos de video y audio para reproducción multimedia
Almacenamiento local fuera de línea localStorage almacena datos durante mucho tiempo y los datos no se perderán después de cerrar el navegador;
Los datos de sessionStorage se eliminan automáticamente después de cerrar el navegador.
Elementos de contenido con mejor semántica, como artículo, pie de página, encabezado, navegación, sección
Controles de formulario, calendario, fecha, hora, correo electrónico, URL, búsqueda
Webworker de nuevas tecnologías, websockt, Geolocalización.
* elemento eliminado
Elementos de expresión pura: basefont, big, center, font, s, strike, tt, u;
Elementos que afectan negativamente a la usabilidad: frame, frameset, noframes;
Admite nuevas etiquetas HTML5:
* IE8/IE7/IE6 admite etiquetas generadas por el método document.createElement,
Puede utilizar esta función para que estos navegadores admitan nuevas etiquetas HTML5,
Una vez que el navegador admita la nueva pestaña, también debe agregar el estilo predeterminado de la pestaña:
* Por supuesto, la mejor manera es utilizar un marco maduro directamente, el más utilizado es el marco html5shim.
1.10 ¿Cuáles son los núcleos de los navegadores? ¿Cuáles son las tolerancias de los navegadores que se encuentran a menudo? ¿Cuál es el motivo, cuál es la solución y cuáles son los trucos más comunes?
* Kernel Trident del navegador IE, Gecko de Mozilla, WebKit de Google, kernel Presto de Opera;
* La imagen de png24 aparece de fondo en el navegador iE6, la solución es convertirla en PNG8.
* El margen y el relleno predeterminados del navegador son diferentes. La solución es agregar un *{margin:0;padding:0;} global para unificar.
* Error de margen bilateral de IE6: después de que la etiqueta del atributo del bloque flota, hay un margen horizontal y el margen que se muestra en ie6 es mayor que la configuración.
La doble distancia generada por flotación, es decir, #box{ float:left; width:10px; margin:0 0 0 100px;}
En este caso, IE generará una distancia de 20px. La solución es agregar --_display:inline; al control de estilo de etiqueta flotante para convertirlo en un atributo en línea. (_Este símbolo sólo lo reconoce ie6)
El método de reconocimiento progresivo excluye gradualmente la parte del todo.
Primero, use inteligentemente la marca "\9" para separar el navegador IE de todos los casos.
Luego, use "+" nuevamente para separar IE8 de IE7 e IE6, de modo que IE8 se reconozca de forma independiente.
CSS
.bb{
background-color:#f1ee18;/ Todo reconocimiento /
.background-color:#00deff\9; / Reconocimiento IE6, 7, 8 /
+color de fondo:#a200ff;/ Reconocimiento IE6, 7 /
_background-color:#1e0bd1;/ reconocimiento IE6 /
}
* En IE, puede utilizar el método de obtención de atributos regulares para obtener atributos personalizados.
También puedes usar getAttribute() para obtener atributos personalizados;
En Firefox, solo puedes usar getAttribute() para obtener atributos personalizados.
Solución: obtenga atributos personalizados de manera uniforme a través de getAttribute().
* En IE, el objeto par tiene atributos x, y, pero no atributos pageX, pageY;
En Firefox, el objeto de evento tiene atributos pageX, pageY, pero no atributos x, y.
* (Comentario condicional) La desventaja es que puede aumentar el número de solicitudes HTTP adicionales en el navegador IE.
* De forma predeterminada, la interfaz china de Chrome forzará que los textos de menos de 12 px se muestren en 12 px, lo que se puede resolver agregando la propiedad CSS -webkit-text-size-adjust: none;
Después de visitar el hipervínculo, el estilo de desplazamiento no aparecerá. El estilo de hipervínculo visitado y en el que se hizo clic ya no tendrá el desplazamiento ni estará activo. La solución es cambiar el orden de las propiedades CSS:
LVHA: a:enlace {} a:visitado {} a:hover {} a:activo {}
1.11 ¿Problemas comunes de compatibilidad con HTML?
1. El uso de la pantalla causado por la distancia BUG flotante de doble cara
2.3 Problema de píxeles causado por el uso de float usando dislpay:inline -3px
3. El hipervínculo al pasar el mouse deja de ser válido después de hacer clic. Use el orden de escritura correcto del enlace visitado al pasar el mouse activo
4. Problema del índice z de IE para agregar posición: relativa al padre
5. Png usa de forma transparente el código js para cambiar
6.Altura mínima ¡Altura mínima! Importante resolver'
7. La selección está cubierta en ie6 usando anidamiento de iframe
8. ¿Por qué no hay forma de definir un contenedor con un ancho de aproximadamente 1 px (debido a la altura de línea predeterminada de IE6, use over: oculto, zoom: 0.08 altura de línea: 1 px)?
9. IE5-8 no admite opacidad, solución:
.opacidad {
opacidad: 0,4
filtro: alfa(opacidad=60); /* para IE5-7 */
-ms-filter: “progid:DXImageTransform.Microsoft.Alpha(Opacidad=60)”; /* para IE 8*/
}
\ 10. IE6 no admite fondos transparentes PNG, solución: use una imagen gif en IE6
1.12 ¿Qué es la superposición de márgenes? ¿Cuál es el resultado de la superposición?
La superposición de márgenes es un colapso de márgenes.
En CSS, los márgenes de dos cuadros adyacentes (que pueden ser hermanos o antepasados) se pueden combinar en un solo margen. Esta forma de combinar márgenes se denomina colapso y, por tanto, los márgenes combinados se denominan márgenes colapsados.
Los resultados del plegado siguen las siguientes reglas de cálculo:
Cuando dos márgenes adyacentes son positivos, el resultado colapsado es el valor mayor entre ellos.
Cuando dos márgenes adyacentes son negativos, el resultado del plegado es el valor mayor de los dos valores absolutos.
Cuando los dos márgenes son positivos y negativos, el resultado del plegado es la suma de los dos.
1.13 ¿Puedes describir la diferencia entre mejora progresiva y degradación elegante?
Mejora progresiva: cree páginas para navegadores de versión baja para garantizar las funciones más básicas y luego mejore y agregue funciones como efectos e interacciones para navegadores avanzados para lograr una mejor experiencia de usuario.
优雅降级 graceful degradation:一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。
区别:优雅降级是从复杂的现状开始,并试图减少用户体验的供给,而渐进增强则是从一个非常基础的,能够起作用的版本开始,并不断扩充,以适应未来环境的需要。降级(功能衰减)意味着往回看;而渐进增强则意味着朝前看,同时保证其根基处于安全地带。
“优雅降级”观点
“优雅降级”观点认为应该针对那些最高级、最完善的浏览器来设计网站。而将那些被认为“过时”或有功能缺失的浏览器下的测试工作安排在开发周期的最后阶段,并把测试对象限定为主流浏览器(如 IE、Mozilla 等)的前一个版本。
在这种设计范例下,旧版的浏览器被认为仅能提供“简陋却无妨 (poor, but passable)” 的浏览体验。你可以做一些小的调整来适应某个特定的浏览器。但由于它们并非我们所关注的焦点,因此除了修复较大的错误之外,其它的差异将被直接忽略。
“渐进增强”观点
“渐进增强”观点则认为应关注于内容本身。
内容是我们建立网站的诱因。有的网站展示它,有的则收集它,有的寻求,有的操作,还有的网站甚至会包含以上的种种,但相同点是它们全都涉及到内容。这使得“渐进增强”成为一种更为合理的设计范例。这也是它立即被 Yahoo! 所采纳并用以构建其“分级式浏览器支持 (Graded Browser Support)”策略的原因所在。
1.14 HTML5和css3的新标签
HTML5: nav, footer, header, section, hgroup, video, time, canvas, audio…CSS3: RGBA, opacity, text-shadow, box-shadow, border-radius, border-image, border-color, transform…;
1.15 DOCTYPE的作用?严格模式和混杂模式的区别?
! DOCTYPE le dice al navegador que analice la página de acuerdo con el estándar HTML5; si no está escrita, ingresará al modo promiscuo Modo
estricto (modo estándar): analiza el código de acuerdo con el estándar w3c
Modo promiscuo (modo extraño): el navegador analiza el HTML5
no tiene DTD, por lo que no hay diferencia entre el modo estricto y el modo mixto. HTML5 tiene un método relativamente flexible. Al implementarlo, se logró compatibilidad con versiones anteriores tanto como sea posible (HTML5 no es estricto ni promiscuo).
1.16 ¿Cuénteme sobre el almacenamiento fuera de línea de HTML5?
El almacenamiento sin conexión de HTML5 es una tecnología de almacenamiento en caché de aplicaciones web que permite guardar los recursos de las aplicaciones web (como archivos HTML, hojas de estilo CSS, códigos e imágenes JavaScript, etc.) para que funcionen. El almacenamiento sin conexión puede mejorar el rendimiento y la accesibilidad de las aplicaciones web y proporcionar una forma más estable y confiable de servir aplicaciones web.
En HTML5, la API de caché de aplicaciones se utiliza para implementar el almacenamiento fuera de línea. Al agregar un atributo de manifiesto al encabezado del archivo HTML para apuntar a un archivo de manifiesto que describe la lista de recursos que deben almacenarse en caché, se puede habilitar el almacenamiento fuera de línea. Una vez que una aplicación web se almacena en caché sin conexión, los usuarios pueden acceder a la aplicación sin una conexión de red sin descargar recursos de servidores remotos.
Aunque el almacenamiento fuera de línea puede mejorar el rendimiento y la accesibilidad de las aplicaciones web, los desarrolladores deben ser conscientes de sus inconvenientes. Dado que los datos almacenados fuera de línea se mantienen en la computadora local, si los datos se manipulan o se corrompen, la aplicación web puede verse comprometida o no funcionar correctamente. Además, los datos almacenados sin conexión también pueden ocupar grandes cantidades de espacio de almacenamiento local, lo que puede afectar el rendimiento del dispositivo del usuario.
1.17 Dime ¿cómo hacer un buen trabajo en SEO?
- Optimización de la estructura del sitio web: asegúrese de que la estructura del sitio web sea clara y concisa, y evite el uso excesivo de Flash, JavaScript y otras tecnologías que no sean amigables para los motores de búsqueda.
- Optimización de palabras clave: las palabras clave deben determinarse de acuerdo con factores como la industria a la que pertenece el sitio web, los usuarios objetivo, etc., y deben usarse de manera razonable en títulos, textos, imágenes, etc., pero al mismo tiempo, evitar su uso excesivo. de palabras clave para evitar ser reconocido por los motores de búsqueda como spam.
- Optimización de contenido: proporcione contenido valioso y de alta calidad para atraer a los usuarios a quedarse, aumentar el tiempo de permanencia de los usuarios y las visitas a la página y, al mismo tiempo, mejorar la credibilidad y la clasificación del sitio web.
- Optimización de enlaces externos: para mejorar el peso y el ranking del sitio web buscando enlaces externos relevantes y de alta calidad.
1.18 ¿Cuéntame sobre la API de arrastre?
Drag API es una API web que agrega funcionalidad de arrastrar y soltar a páginas web. Permite a los usuarios mover ciertos elementos de una ubicación a otra haciendo clic y arrastrando el mouse.
Al utilizar Drag API, los desarrolladores pueden implementar una funcionalidad personalizada de arrastrar y soltar en páginas web y ejercer un control detallado sobre ella. Por ejemplo, puede definir qué elementos se pueden arrastrar, qué elementos se pueden usar como destinos de arrastrar y soltar y cómo manejar los eventos de arrastrar y soltar.
Drag API proporciona varias interfaces y eventos principales:
- Arrastrable: marque un elemento como arrastrable estableciendo la propiedad arrastrable en verdadero.
- Evento Dragstart: se activa cuando el usuario comienza a arrastrar un elemento.
- Evento Dragenter: se activa cuando un elemento que se puede arrastrar ingresa en un área de elementos que se pueden soltar.
- Evento de arrastre: se activa cuando un elemento que se puede arrastrar se mueve dentro de un área de elementos que se pueden soltar.
- Evento de colocación: se activa cuando el usuario suelta el mouse, libera un elemento que se puede arrastrar y lo suelta en un área de elementos que se pueden soltar.
- Evento Dragend: Se activa cuando el usuario termina de arrastrar.
Al utilizar Drag API, los desarrolladores pueden crear varias aplicaciones web interesantes e interactivas, como arrastrar imágenes para cargar, arrastrar elementos para ordenar, arrastrar gráficos, etc. Puede mejorar la experiencia del usuario y aumentar el atractivo y la interactividad del sitio web.
1.19 ¿Dime la diferencia entre lienzo y svg?
Tanto Canvas como SVG son tecnologías de dibujo comunes proporcionadas por HTML5, pero sus principios de implementación y escenarios de aplicación son bastante diferentes.
- Principio de implementación Canvas es una tecnología de dibujo basada en píxeles que utiliza JavaScript para manipular píxeles en el lienzo para dibujar. Cuando usamos Canvas para dibujar, podemos obtener un espacio similar al lienzo y luego usar la matriz para operar en los píxeles y dibujar el patrón requerido. Sin embargo, SVG adopta el método de dibujo vectorial, es decir, basándose en fórmulas matemáticas, los atributos como la forma, el tamaño y la posición de varios gráficos y elementos se calculan mediante una computadora y se convierten en rutas vectoriales, que finalmente se muestran en la pantalla.
- Escenarios de aplicación Canvas es más adecuado para mostrar dinámicamente una gran cantidad de gráficos complejos o efectos de animación, como juegos, visualización de datos, diseño de carteles, etc., porque puede controlar rápidamente los píxeles y tiene mayor flexibilidad e interactividad. SVG se utiliza principalmente para dibujos gráficos estáticos o de escala fija, como iconos, logotipos, mapas vectoriales, etc. Dado que está en forma vectorial, no se distorsionará al hacer zoom ni deformarse. Además, SVG también proporciona eventos interactivos enriquecidos y soporte de estilo CSS, y es más conveniente usar SVG para elementos gráficos que deben editarse y modificarse.
- Rendimiento y mantenibilidad Dado que Canvas se basa en operaciones de píxeles e implica mucho cálculo y renderizado, tiene un rendimiento deficiente en comparación con SVG cuando se trata de dibujo de gráficos estáticos. Pero para aplicaciones y imágenes dinámicas de gran tamaño que requieren interacción en tiempo real, Canvas tiene ventajas sobre SVG. Dado que SVG construye gráficos basados en el lenguaje de marcado XML, la cantidad de código es mayor. Cuando los gráficos dibujados por SVG se vuelven más complejos, la capacidad de mantenimiento del código disminuirá.
(1) SVG: SVG Scalable Vector Graphics (gráficos vectoriales escalables) es un lenguaje basado en gráficos 2D descritos por el lenguaje de marcado extensible XML. SVG basado en XML significa que cada elemento en SVG DOM está disponible y puede usarse para un determinado elementos para adjuntar controladores de eventos Javascript. En SVG, cada forma dibujada se considera un objeto. Los navegadores pueden reproducir gráficos automáticamente si las propiedades del objeto SVG cambian.
Sus características son las siguientes:
- independiente de la resolución
- Soporte para controladores de eventos
- Lo mejor para aplicaciones con grandes áreas de renderizado (como Google Maps)
- La alta complejidad ralentiza el renderizado (cualquier aplicación que haga un uso intensivo del DOM no es rápida)
- No apto para aplicaciones de juegos.
(2) Lienzo: Canvas es un lienzo que dibuja gráficos 2D a través de Javascript y los representa píxel por píxel. Cuando su posición cambie, se volverá a dibujar.
Sus características son las siguientes:
- dependiente de la resolución
- los controladores de eventos no son compatibles
- mala representación del texto
- Posibilidad de guardar las imágenes resultantes en formato .png o .jpg
- Lo mejor para juegos con uso intensivo de gráficos donde muchos objetos se vuelven a dibujar con frecuencia
NOTA: Un diagrama vectorial, también conocido como imagen orientada a objetos o imagen de dibujo, se define matemáticamente como una serie de puntos conectados por líneas. Los elementos gráficos en archivos vectoriales se denominan objetos. Cada objeto es una entidad autónoma con atributos como color, forma, contorno, tamaño y posición en la pantalla.
En resumen, Canvas y SVG tienen sus propios escenarios de aplicación adecuados y deben seleccionarse de acuerdo con las necesidades comerciales específicas. Si necesita mostrar algunos patrones fijos simples o gráficos de estadísticas de datos, etc., es más adecuado usar SVG; y si desea realizar algunas animaciones y juegos interactivos, es más conveniente y efectivo usar Canvas.
1.20 ¿Cuáles son los elementos en línea? ¿Qué son los elementos a nivel de bloque? ¿Cuáles son los elementos vacíos (vacíos)? ¿Cuál es la diferencia entre elementos en línea y elementos a nivel de bloque?
- Los elementos en línea son:
a b span img input select strong- Los elementos a nivel de bloque son:
div ul ol li dl dt dd h1 h2 h3 h4…p- elemento vacío:
<br> <hr> <img> <input> <link> <meta>- Los elementos en línea no pueden establecer el ancho y el alto, y no ocupan una sola línea
- Los elementos a nivel de bloque pueden establecer el ancho y el alto y ocupar una sola línea
1.21 Hable sobre su comprensión de SSG
SSG (Generación de sitios estáticos) se refiere a la generación previa de páginas estáticas durante la construcción y la implementación de estas páginas en CDN u otros servicios de almacenamiento para mejorar el rendimiento y la experiencia del usuario de las aplicaciones web.
Específicamente, la implementación de SSG suele incluir los siguientes pasos:
- En la fase de desarrollo, utilice tecnologías como motores de plantillas para crear plantillas de páginas estáticas;
- Obtenga los datos que se mostrarán desde la API en segundo plano o mediante otros canales, y complételos en la plantilla de página estática para generar una página HTML completa;
- Utilice herramientas de creación (como Gatsby, Next.js, etc.) para crear páginas estáticas y generar archivos HTML, CSS y JavaScript estáticos;
- Implemente los archivos estáticos generados en el servidor o CDN para el acceso de los usuarios.
En comparación con las páginas web dinámicas tradicionales, SSG tiene las siguientes ventajas:
- Carga rápida: dado que no es necesario representar dinámicamente la página para cada solicitud, SSG puede reducir el tiempo de carga de la página, mejorando así la experiencia del usuario y la clasificación en los motores de búsqueda;
- Alta seguridad: dado que no existe código de fondo ni base de datos, SSG no es vulnerable a ataques como la inyección SQL;
- Bajo costo: SSG puede reducir los costos de operación y mantenimiento del sitio web y la carga del servidor porque no requiere servidores dinámicos ni otros equipos.
Cabe señalar que SSG no es adecuado para escenarios como contenido actualizado con frecuencia e interacción dinámica, pero es una buena opción para optimizar el rendimiento de sitios web con contenido más estable y menos actualizaciones.
1.22 ¿Cuéntame sobre los trabajadores web?
La función de Web Worker es crear un entorno de subprocesos múltiples para JavaScript, permitiendo que el subproceso principal cree subprocesos de trabajo y asigne algunas tareas a este último para que se ejecute. Una vez que el subproceso de trabajo se crea correctamente,
siempre se ejecutará y no verse afectado por la interrupción de las actividades en el hilo principal (como el clic del botón del usuario, el envío de formularios). Esto favorece la respuesta a la comunicación del hilo principal en cualquier momento. Sin embargo, esto también hace que el Trabajador consuma más recursos y no se debe abusar, y una vez usado, se debe cerrar.
Pase el resultado al hilo principal a través de postMessage, de modo que el proceso principal no se bloquee durante operaciones complejas
[artículo de Ruan Yifeng] ( Tutorial de uso de Web Worker: registro de red de Ruan Yifeng (ruanyifeng.com) )
1.23 ¿Cuéntame sobre la función srcset de img? ¿Cuál es la diferencia entre alt y título?
- Las páginas responsivas se utilizan a menudo para configurar diferentes imágenes según la densidad de la pantalla.
- En este momento, se utiliza el atributo srcset de la etiqueta img. El atributo srcset se usa para configurar diferentes densidades de pantalla, img cargará automáticamente diferentes imágenes
- alt es la dirección de la imagen de respaldo cuando la imagen falla y title es el título de la imagen
1.24 Hable sobre su comprensión del árbol Dom.
¿Qué es DOM?
El motor de renderizado no puede entender directamente el flujo de bytes del archivo HTML transmitido desde la red al motor de renderizado, por lo que debe convertirse en una estructura interna que el motor de renderizado pueda entender, esta estructura es DOM.
DOM proporciona una representación estructurada de documentos HTML.
En el motor de renderizado, DOM tiene tres niveles de funciones:
- Desde la perspectiva de la página, el DOM es la estructura de datos básica que genera la página.
- Desde la perspectiva de las secuencias de comandos JavaScript, DOM proporciona una interfaz para las operaciones de secuencias de comandos JavaScript. A través de este conjunto de interfaces, JavaScript puede acceder a la estructura DOM, cambiando así la estructura, el estilo y el contenido del documento.
- Desde una perspectiva de seguridad, DOM es una línea de seguridad y parte del contenido inseguro se rechaza durante la fase de análisis de DOM.
En resumen, DOM es la estructura de datos interna que representa HTML, conecta páginas web y scripts JavaScript y filtra contenido inseguro.
Cómo se genera el árbol DOM
Analizador HTML (HTMLParser): responsable de convertir flujos de bytes HTML en estructuras DOM.
Entonces, ¿cómo pasa el proceso de red datos al analizador HTML?
[Error en la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo de enlace antirrobo, se recomienda guardar la imagen y cargarla directamente (img-1w0cvHXF-1683893094351) (C:\Users\32063\AppData\Roaming\Typora \typora-user-images\ image-20230511155523413.png)]
A partir de la figura, podemos saber que existe un canal de datos compartido entre el proceso de red y el proceso de representación, y cuántos datos carga el proceso de red y los datos se pasan al analizador HTML para su análisis.
Después de que el analizador HTML recibe los datos (flujo de bytes), el flujo de bytes se convertirá en DOM, el proceso es el siguiente:
[Error en la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-2OHMEm6l-1683893094352) (C:\Users\32063\AppData\Roaming\Typora\ typora-user-images\ image-20230511155547442.png)]
Hay tres etapas :
1. Convierta el flujo de bytes en Token a través del tokenizador. El tokenizador primero convierte el flujo de bytes en tokens, que se dividen en token de etiqueta y token de texto.
Tenga en cuenta que el Token aquí no es el Token que entendíamos antes, aquí hay un fragmento.
2. El token se analiza en un nodo DOM.
3. Agregue nodos DOM al árbol DOM.
JavaScript afecta la generación de DOM
Sabemos que JavaScript puede modificar el DOM y también afectará la generación del DOM.
1. Script JavaScript incorporado Por ejemplo, si incrustamos un
<script>código de etiqueta, el proceso de análisis anterior es el mismo, pero cuando se analiza la etiqueta del script, el motor de renderizado juzga que es un script y el analizador HTML suspenderá el análisis DOM en Esta vez , porque el siguiente JavaScript puede modificar la estructura DOM generada actualmente.Después de pausar el análisis, el motor JavaScript interviene y ejecuta
<script>el script en la etiqueta . Una vez ejecutado el script, el analizador HTML reanuda el proceso de análisis y continúa analizando el contenido posterior hasta que se genera el DOM final.2. La introducción de archivos JavaScript es básicamente la misma que antes, la diferencia es que, para ejecutar el código JavaScript después de pausar el análisis, primero debe descargar este código JavaScript .
1.25 ¿Cuál es la relación entre Nodo y Elemento?
La relación entre Nodo y Elemento puede ser mucho más clara en términos de herencia.
Element hereda de Node, tiene los métodos de Node y, al mismo tiempo, expande muchos de sus propios métodos únicos.
En algunos métodos de Elemento, Nodo y Elemento se distinguen claramente. Por ejemplo: childNodes e hijos, parentNode y parentElement y otros métodos.
Para algunos métodos de Nodo, el valor de retorno es Nodo, como nodo de texto, nodo de comentario, etc., mientras que para algunos métodos de Elemento, el valor de retorno debe ser Elemento.
Al distinguir claramente este punto, se pueden evitar muchos problemas de bajo nivel.
ElementEn pocas palabras, Node es una clase base y todo lo que hay en el DOMText和Commenthereda de ella. En otras palabras,ElementyTextson tresCommentNodos especiales, se llamanELEMENT_NODEyTEXT_NODE.COMMENT_NODEEntonces, los elementos en html que usamos habitualmente, es decir
Element, son deELEMENT_NODEtipoNode.
1.26 ¿Cuáles son las razones del largo tiempo de carga de la página y cómo optimizarla?
1. Tiempo de pantalla blanca
Tiempo de pantalla en blanco: se refiere al tiempo desde que la pantalla está en blanco hasta que se muestra la primera pantalla después de que el usuario hace clic en un enlace o abre el navegador e ingresa la dirección URL.
2. La importancia del tiempo frente a la pantalla en blanco
Cuando el usuario hace clic en un enlace o ingresa directamente la URL en el navegador para comenzar a acceder, comienza a esperar a que se muestre la página. Cuanto más corto sea el tiempo de representación de la página, menos esperará el usuario y más rápido percibirá la página. Esto puede mejorar enormemente la experiencia del usuario, reducir el rebote del usuario y mejorar la tasa de retención de la página.
3. El proceso de pantalla blanca.
El proceso desde ingresar la URL hasta mostrar la pantalla de la página.
1. Primero, ingrese la URL en la barra de direcciones del navegador.
2. El navegador primero verifica la caché del navegador, la caché del sistema, la caché del enrutador y, si hay una en la caché, mostrará directamente el contenido de la página en la pantalla. Si no, salta al tercer paso.
3. Antes de enviar una solicitud http, se requiere resolución de nombre de dominio (resolución DNS) para obtener la dirección IP correspondiente.
4. El navegador inicia una conexión TCP con el servidor y establece un protocolo de enlace TCP de tres vías con el navegador.
5. Una vez que el protocolo de enlace es exitoso, el navegador envía una solicitud http al servidor para solicitar un paquete de datos.
6. El servidor procesa la solicitud recibida y devuelve los datos al navegador.
7. El navegador recibe la respuesta HTTP.
8. Lea el contenido de la página, representelo en el navegador y analice el código fuente html.
9. Generar árbol Dom, analizar estilo CSS, interacción js, renderizar y mostrar página
Después de que el navegador descarga el HTML, primero analiza el código del encabezado, descarga la hoja de estilo y luego continúa analizando el código HTML hacia abajo, crea un árbol DOM y descarga la hoja de estilo al mismo tiempo. Cuando se construye el árbol DOM, comience inmediatamente a construir el árbol CSSOM. Idealmente, la velocidad de descarga de la hoja de estilo es lo suficientemente rápida, y el árbol DOM y el árbol CSSOM entran en un proceso paralelo. Cuando se construyen los dos árboles, se construye el árbol de representación y luego se dibuja.
Consejos: El impacto de las políticas de análisis de seguridad del navegador en el análisis de HTML:
Cuando se encuentra código JS en línea al analizar HTML, bloqueará la construcción del árbol DOM y el código JS se ejecutará primero; cuando el archivo de estilo CSS no se descarga, el navegador analiza HTML y encuentra código JS en línea. En ese momento, el navegador pausa la ejecución del script JS y pausa el análisis HTML. Hasta que se complete la descarga del archivo CSS, se completará la construcción del árbol CSSOM y se reanudará el análisis original.
JavaScript bloqueará la generación de DOM y los archivos de estilo bloquearán la ejecución de JavaScript. Por lo tanto, en proyectos reales, debe centrarse en los archivos JavaScript y los archivos de hojas de estilo. El uso inadecuado afectará el rendimiento de la página.
4. Pantalla blanca: optimización del rendimiento
1. Optimización de la resolución DNS
Para el enlace de búsqueda de DNS, podemos optimizar la resolución de DNS de manera específica.
- Optimización de la caché de DNS
- Política de precarga de DNS
- Servidor DNS estable y confiable
2. Optimización del enlace de red TCP
gastar más dinero
3. Optimización del procesamiento del lado del servidor
La optimización del procesamiento del lado del servidor es un tema muy amplio, que involucrará el caché de Redis, la optimización del almacenamiento de la base de datos, varios middleware en el sistema y la compresión Gzip, etc.
4. Descarga del navegador, análisis y optimización de la página de renderizado.
De acuerdo con el proceso de descarga, análisis y representación de la página por parte del navegador, puede considerar las siguientes optimizaciones:
- Optimice el código y la estructura HTML tanto como sea posible
- Optimice los archivos y estructuras CSS tanto como sea posible
- Asegúrese de colocar el código JS de manera razonable, intente no utilizar código JS en línea
- Incluir el CSS crítico necesario para representar el contenido de la mitad superior de la página en el HTML hace que la descarga de CSS sea mucho más rápida. Se puede renderizar después de que se completa la descarga de HTML y se adelanta el tiempo de renderizado de la página, acortando así el tiempo de renderizado de la primera pantalla;
- Retrasar la carga de imágenes que no son necesarias para la primera pantalla y priorizar la carga de las imágenes necesarias para la primera pantalla (offsetTop<clientHeight)
document.documentElement.clientHeight//获取屏幕可视区域的高度
element.offsetTop//获取元素相对于文档顶部的高度
Debido a que JavaScript bloqueará la generación de DOM y los archivos de estilo bloquearán la ejecución de JavaScript, en el proyecto real, debemos centrarnos en los archivos JavaScript y los archivos de hojas de estilo, el uso inadecuado afectará el rendimiento de la página.
1.27 ¿Alguna vez has oído hablar del jpg progresivo?
JPEG progresivo (JPEG progresivo), o PJPEG, es uno de los tres modos de compresión populares del estándar.
El JPEG progresivo comprime fotografías y gráficos de una manera específica y, a diferencia del JPEG básico, PJPEG inicialmente da la apariencia de una imagen borrosa cuando se representa en un navegador web. Luego comienza a renderizar la imagen poco a poco hasta que muestra la imagen completamente renderizada. En realidad, el navegador interpreta la imagen línea por línea, pero proporciona una vista previa borrosa de la imagen completa en el marcador de posición. A medida que el motor de renderizado del navegador web procesa los datos, el contraste de la imagen comienza a volverse más nítido y detallado. Hasta que se complete la representación final, el usuario verá la imagen completa y clara.
PJPEG puede tener un efecto psicológico muy significativo, permitiendo a los usuarios tener algo que mirar en lugar de sentarse esperando a que una imagen grande aparezca lentamente en la pantalla.
PJPEG funciona con los navegadores más comunes, incluidos
Chrome,FirefoxyInternet Explorer 9posteriores. Las versiones anteriores de Internet Explorer tenían algunos problemas al mostrar archivos JPEG progresivos, pero esto era sólo un pequeño porcentaje de usuarios. Los navegadores que no admiten el formato JPEG progresivo cargarán la foto como JPEG normal.
1.28 ¿Cómo realizar la función de "hacer clic para volver al principio"?
1. Anclas
Usar enlaces de anclaje es una forma sencilla de volver a la parte superior de la función.
Esta implementación coloca principalmente un enlace de anclaje con un nombre específico en la parte superior de la página, y luego coloca un enlace de regreso al ancla en la parte inferior de la página, y el usuario hace clic en el enlace para regresar a la posición superior donde está el ancla. situado.
<body style="height:2000px;">
<div id="topAnchor"></div>
<a href="#topAnchor" style="position:fixed;right:0;bottom:0">回到顶部</a>
</body>
2、desplazarse hacia arriba
La propiedad scrollTop indica la cantidad de píxeles que se ocultarán sobre el área de contenido.
Cuando el elemento no se desplaza, el valor de scrollTop es 0. Si el elemento se desplaza verticalmente, el valor de scrollTop es mayor que 0 e indica el ancho de píxeles del contenido invisible sobre el elemento.
Dado que se puede escribir en scrollTop, se puede utilizar scrollTop para lograr la función de regresar a la parte superior
<body style="height:2000px;">
<button id="test" style="position:fixed;right:0;bottom:0">回到顶部</button>
<script>
test.onclick = function(){
document.body.scrollTop = document.documentElement.scrollTop = 0;
}
</script>
</body>
3、desplazarse hacia
El método scrollTo(x,y) desplaza el documento que se muestra en la ventana actual para que el punto especificado por las coordenadas xey en el documento se ubique en la esquina superior izquierda del área de visualización.
Configure scrollTo (0,0) para lograr el efecto de regresar a la cima
<body style="height:2000px;">
<button id="test" style="position:fixed;right:0;bottom:0">回到顶部</button>
<script>
test.onclick = function(){
scrollTo(0,0);
}
</script>
</body>
4、desplazarse por()
El método scrollBy(x,y) desplaza el documento que se muestra en la ventana actual, y xey especifican la cantidad relativa de desplazamiento
Siempre que se utilice la longitud de desplazamiento de la página actual como parámetro y se desplace hacia atrás, se puede lograr el efecto de volver a la parte superior.
<body style="height:2000px;">
<button id="test" style="position:fixed;right:0;bottom:0">回到顶部</button>
<script>
test.onclick = function(){
var top = document.body.scrollTop || document.documentElement.scrollTop
scrollBy(0,-top);
}
</script>
</body>
5、desplazarse hacia View()
El método Element.scrollIntoView desplaza el elemento actual al área visible del navegador
Este método puede aceptar un valor booleano como parámetro. Si es verdadero, la parte superior del elemento está alineada con la parte superior de la parte visible del área actual (si el área actual es desplazable); si es falso, la parte inferior del elemento está alineada con la cola de la parte visible del área actual. área (si el área actual es desplazable). Si no se proporciona este parámetro, el valor predeterminado es verdadero
El principio de uso de este método es similar al de usar puntos de anclaje. Establezca el elemento de destino en la parte superior de la página. Cuando la página se desplaza, el elemento de destino se desplaza fuera del área de la página. Haga clic en el botón Volver al principio para regresar. el elemento objetivo a su posición original y luego lograr el efecto esperado
<body style="height:2000px;">
<div id="target"></div>
<button id="test" style="position:fixed;right:0;bottom:0">回到顶部</button>
<script>
test.onclick = function(){
target.scrollIntoView();
}
</script>
</body>
1.29 Cómo lograr la optimización SEO
El SEO se divide principalmente en dos direcciones: interna y externa.
1. Optimización interna
- Optimización de etiquetas META: por ejemplo: optimización de TÍTULO, PALABRAS CLAVE, DESCRIPCIÓN (TDK), etc.
- Optimización de enlaces internos, incluidos enlaces relacionados (etiquetas), enlaces de texto ancla, enlaces de navegación y enlaces de imágenes.
- Actualización del contenido del sitio web: mantener el sitio actualizado todos los días (principalmente la actualización de artículos, etc.)
- Representación del lado del servidor (SSR)
2. Optimización externa
- Tipos de enlaces externos: blogs, foros, B2B, noticias, información clasificada, barras de posts, conocimiento, enciclopedias, redes de información relacionada, etc. Mantener al máximo la diversidad de enlaces
- Operación de enlaces externos: agregue una cierta cantidad de enlaces externos todos los días para que la clasificación de las palabras clave mejore constantemente.
- Selección de enlaces externos: intercambie enlaces de amistad con algunos sitios web con alta correlación con su sitio web y buena calidad general para consolidar y estabilizar el ranking de palabras clave.
1.30 ¿Qué es el SEO?
SEO (Search Engine Optimization), traducción al chino para optimización de motores de búsqueda.
La optimización de motores de búsqueda es una forma de utilizar las reglas de búsqueda de los motores de búsqueda para mejorar la clasificación natural de los sitios web actuales en los motores de búsqueda relevantes.
SEO se refiere al acto de hacer una planificación razonable desde las perspectivas de la estructura del sitio web, el plan de construcción de contenido, la comunicación de interacción del usuario y las páginas para obtener más tráfico gratuito de los motores de búsqueda, de modo que el sitio web sea más adecuado para los principios de indexación de la búsqueda. motores.
1.31 ¿Qué es la preresolución de DNS? ¿Cómo lograrlo?
optimización de DNS
Antes de la introducción dns-prefetch, primero debemos mencionar los métodos convencionales actuales para la optimización de DNS.
En términos generales, una resolución DNS tarda entre 20 y 120 ms, por lo que para optimizar el DNS, podemos considerar dos direcciones:
- Reducir el número de solicitudes de DNS
- Acortar el tiempo de resolución de DNS
dns-prefetch
¿Qué es la captación previa de DNS?
dns-prefetch( Captación previa de DNS ) es una medida de optimización del rendimiento de la red front-end. De acuerdo con las reglas definidas por el navegador, resuelve de antemano los nombres de dominio que pueden usarse, almacena en caché los resultados de la resolución en el caché del sistema , acorta el tiempo de resolución de DNS y mejora la velocidad de acceso al sitio web.
¿Por qué utilizar DNS-prefetch?
Siempre que un navegador envía una solicitud desde un servidor (de terceros), primero debe resolver el nombre de dominio entre dominios en una dirección IP a través de la resolución DNS antes de que el navegador pueda enviar la solicitud.
Si se envían varias solicitudes al mismo servidor dentro de un cierto período de tiempo, la resolución DNS se activará varias veces y repetidamente. Esto puede provocar un retraso en la carga general de la página web.
Sabemos que aunque la resolución DNS no ocupa mucho ancho de banda, provocará una alta latencia, especialmente en las redes móviles.
Por lo tanto, para reducir el retraso causado por la resolución de DNS, podemos dns-prefetchacortar efectivamente el tiempo de resolución de DNS mediante tecnología de resolución previa.
<link rel="dns-prefetch" href="https://baidu.com/">
El principio detrás de DNS-prefetch
Cuando un navegador accede a un nombre de dominio, necesita resolver el DNS una vez para obtener la dirección IP del nombre de dominio correspondiente. Durante el análisis, siga:
- caché de navegador
- caché del sistema
- caché del enrutador
- Caché DNS del ISP (operador)
- servidor de nombres raíz
- servidor de dominio de nivel superior
- servidor de nombres principal
La secuencia lee el caché paso a paso hasta obtener la dirección IP.
dns-prefetchEs para almacenar en caché la IP resuelta en el sistema .
De esta forma, dns-prefetchel tiempo de resolución de DNS se reduce efectivamente. Porque el caché de DNS se crea en el sistema operativo local, de modo que el DNS encuentra la IP correspondiente en el caché del sistema por adelantado durante el proceso de resolución.
De esta manera, no es necesario ejecutar pasos de análisis posteriores, lo que acorta el tiempo de análisis de DNS.
Si el navegador resuelve un nombre de dominio en una dirección IP por primera vez y lo almacena en caché en el sistema operativo , el siguiente tiempo de resolución DNS puede ser tan bajo como 0-1 ms .
Si el resultado no se almacena en caché en el sistema, entonces es necesario leer el caché del enrutador y el tiempo de análisis posterior es de al menos aproximadamente 15 ms .
Si el caché del enrutador no existe, necesita leer el caché DNS del ISP (operador) . Generalmente taobao.com, para baidu.comestos nombres de dominio comunes, se necesitan entre 80 y 120 ms para leer el caché DNS del ISP (operador) . Si es un nombre de dominio poco común , tarda entre 200 y 300 ms en promedio .
En términos generales, la mayoría de sitios web y operadores pueden encontrar la IP.
Es decir, dns-prefetchpuede aportar una mejora de 15 a 300 ms en el proceso de resolución de DNS, especialmente para algunos sitios web que hacen referencia a muchos otros recursos de nombres de dominio, el efecto de mejora será más obvio.
Caché DNS del navegador y captación previa de DNS
Para optimizar la resolución de DNS, los navegadores modernos también tienen una caché de DNS del navegador.
Su IP se almacena en caché cada vez que se realiza la primera resolución DNS. En cuanto a la duración del caché, cada navegador es diferente, por ejemplo, el tiempo de caducidad de Chrome es de 1 minuto y no se volverá a solicitar DNS dentro de este período.
Consejo:
Cada vez que se inicia el navegador Chrome, resolverá automática y rápidamente los primeros 10 nombres de dominio registrados la última vez que se inició el navegador. Por lo tanto, no hay retrasos en la resolución de DNS para las URL visitadas con frecuencia y la velocidad de apertura es más rápida.
Es dns-prefetchequivalente a realizar el almacenamiento en caché de DNS en el sistema operativo local después del caché del navegador. Personalmente, es para garantizar el caché del navegador e intentar permitir que DNS resuelva el local, para hacer otra capa de optimización de la resolución de DNS.
En términos generales, el tiempo de caché del DNS en el sistema es mayor que el del navegador.
Tiempo de caché DNS del navegador y del sistema
TTL (Time-To-Live), es el tiempo de retención de un registro de resolución de nombre de dominio en el servidor DNS
- El tiempo de caché DNS del navegador no tiene nada que ver con el valor TTL devuelto por el servidor DNS y su tiempo de caché depende de la configuración del propio navegador.
- La caché del sistema hará referencia al valor TTL de la respuesta del servidor DNS, pero no es exactamente igual al valor TTL .
El valor TTL de muchas plataformas nacionales e internacionales está en segundos, y el valor predeterminado de muchas es 3600, es decir, el caché predeterminado es 1 hora.
dns-prefetchdefecto
dns-prefetchEl mayor inconveniente es su uso excesivo.
Una captura previa excesiva dará lugar a una resolución DNS excesiva, lo que supone una carga para la red.
Mejores prácticas
Recuerde los siguientes tres puntos:
dns-prefetchSolo es válido para búsquedas de DNS en dominios de origen cruzado , así que evite usarlo para apuntar al mismo dominio. Esto se debe a que, cuando el navegador ve el mensaje, la IP detrás del dominio de su sitio ya se ha resuelto.- Además del enlace (y otras sugerencias de recursos), también se pueden especificar encabezados HTTP utilizando el campo de enlace HTTP :
dns-prefetch
Link: <https://fonts.gstatic.com/>; rel=dns-prefetch
- Considere la posibilidad de realizar el emparejamiento
dns-prefetchcon un mensaje depreconnect(preconexión).
Ya que dns-prefetchsólo realiza una búsqueda de DNS, al contrario preconnectno establece una conexión con el servidor.
Si el sitio se sirve a través de HTTPS, la combinación de ambos cubre la resolución de DNS, el establecimiento de una conexión TCP y la realización de un protocolo de enlace TLS. La combinación de los dos brinda la oportunidad de reducir aún más la latencia percibida de las solicitudes de origen cruzado . Como sigue:
<link rel="preconnect" href="https://fonts.gstatic.com/" crossorigin>
<link rel="dns-prefetch" href="https://fonts.gstatic.com/">
Nota : Si la página necesita establecer conexiones con muchos dominios de terceros, es contraproducente preconectarlos. preconnectEs mejor utilizar las sugerencias solo para las conexiones más críticas. Para los demás, simplemente utilice <link rel="dns-prefetch">una búsqueda de DNS para ahorrar tiempo en el primer paso.
1.32 Cómo utilizar indexDB
IndexedDB es una tecnología de base de datos local del navegador, que se diferencia de las bases de datos relacionales tradicionales o las bases de datos no relacionales. Su objetivo principal es proporcionar un mecanismo para que las aplicaciones web almacenen datos en el lado del cliente, lo que permite a los usuarios operar sin conexión o almacenar en caché grandes cantidades de datos.caso, mejor rendimiento y confiabilidad.
IndexedDB utiliza un enfoque de valor clave para el almacenamiento de datos. Cada base de datos IndexedDB consta de múltiples almacenes de objetos (Object Store), y cada almacén de objetos contiene una colección correspondiente de registros de datos. Los siguientes son los pasos de uso básicos:
- Para abrir una base de datos, puede abrir una base de datos con un nombre específico a través del objeto IndexedDB y su método de apertura, y especificar la información de configuración de la base de datos, como el número de versión, el almacén de objetos y el índice, al crear o actualizar la base de datos.
javascript复制代码// 前提条件:浏览器支持 IndexedDB
let request = indexedDB.open("myDatabase", 2);
request.onerror = function(event) {
console.log("打开数据库失败");
};
request.onupgradeneeded = function(event) {
let db = event.target.result;
let objectStore = db.createObjectStore("customers", { keyPath: "id" });
objectStore.createIndex("name", "name", { unique: false });
objectStore.createIndex("email", "email", { unique: true });
};
request.onsuccess = function(event) {
let db = event.target.result;
}
- Crear un almacén de objetos Después de abrir la base de datos IndexedDB, puede
createObjectStore()crear un almacén de objetos llamando al método. Puede especificar claves primarias e índices para manipular los datos de manera más eficiente al consultar la base de datos.
javascript复制代码let objectStore = db.createObjectStore("customers", { keyPath: "id" });
objectStore.createIndex("name", "name", { unique: false });
objectStore.createIndex("email", "email", { unique: true });
- Agregar registros de datos utiliza transacciones para agregar o actualizar registros de datos. Llamar a la función de la aplicación dentro de una transacción
add()confirma los datos que se almacenarán, especificando a qué almacén de objetos pertenece. Cabe señalar que todas las operaciones en IndexedDB son asincrónicas y están limitadas por los mecanismos de seguridad del navegador.
javascript复制代码let customerData = [
{ id: 1, name: "John Doe", email: "[email protected]" },
{ id: 2, name: "Jane Doe", email: "[email protected]" }
];
let transaction = db.transaction(["customers"], "readwrite");
let objectStore = transaction.objectStore("customers");
customerData.forEach(function(customer) {
let request = objectStore.add(customer);
request.onsuccess = function(event) {
console.log("新增数据成功");
};
});
- Leer registros de datos Leer un archivo de datos es similar a agregar un archivo de datos. También puede abrir una transacción y abrir el almacén de objetos correspondiente, y luego usar métodos como
openCursor()oget()para recorrer y obtener los registros de datos que contiene.
javascript复制代码let transaction = db.transaction(["customers"]);
let objectStore = transaction.objectStore("customers");
let request = objectStore.get(1);
request.onerror = function(event) {
console.log("读取数据失败");
};
request.onsuccess = function(event) {
if (request.result) {
console.log("读取到的数据为:" + JSON.stringify(request.result));
} else {
console.log
[Network Error]
1.33 ¿Qué API relacionadas con el arrastre tiene HTML5?
- dragstart: el cuerpo principal del evento es el elemento arrastrado y soltado, que se activa cuando el elemento arrastrado y soltado comienza a arrastrarse y soltarse.
- darg: el cuerpo del evento es el elemento arrastrado y soltado, que se activa cuando el elemento arrastrado y soltado se arrastra y suelta.
- dragenter: el cuerpo del evento es el elemento de destino, que se activa cuando el elemento arrastrado ingresa a un elemento.
- dragover: el cuerpo del evento es el elemento de destino, que se activa cuando se arrastra y se mueve dentro de un elemento.
- dragleave: el cuerpo del evento es el elemento de destino y se activa cuando el elemento arrastrado sale del elemento de destino.
- soltar: el cuerpo del evento es el elemento de destino, que se activa cuando el elemento de destino acepta completamente el elemento arrastrado y soltado.
- dragend: el cuerpo del evento es el elemento que se arrastra y suelta, que se activa cuando finaliza toda la operación de arrastrar y soltar.
1.34 ¿Cuál es el motivo de los caracteres confusos en el navegador? ¿Cómo resolver?
Causas de caracteres confusos:
- El código fuente de la página web está
gbkcodificado y los caracteres chinos en el contenido estánutf-8codificados, de modo que aparecerán caracteres confusos cuando se abra el navegadorhtmly, por el contrario, aparecerán caracteres confusos;htmlLa codificación de la página web esgbky el programa llamautf-8el contenido de la codificación desde la base de datos, lo que también provocará una codificación confusa;- El navegador no puede detectar automáticamente la codificación de la página web, lo que genera caracteres confusos en la página web.
Solución:
- Utilice software para editar contenido web HTML;
- Si la codificación de la página web está configurada en Y
gbky el formato de codificación de los datos almacenados en la base de datos es YUTF-8, en este momento, el programa necesita consultar los datos de la base de datos para mostrar los datos y hacer avanzar el programa para transcodificar;- Si hay caracteres confusos en la página web al navegar en el navegador, busque el menú del código de conversión en el navegador para realizar la conversión.
1.35 ¿Cómo afectan js y css a la construcción del árbol DOM?
CSS no bloqueará el análisis de DOM, pero afectará el funcionamiento de JAVAScript, javaSscript evitará el análisis del árbol DOM y, finalmente, css (CSSOM) afectará la representación del árbol DOM, y también se puede decir que lo hará. eventualmente afectará la generación del árbol de renderizado.
A continuación, veamos primero cómo JavaScript afecta la construcción y representación del árbol DOM, que se divide en tres tipos para explicar:
Script JavaScript en la página html
<html>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang'
</script>
<div>test</div>
</body>
</html>
Se inserta un script JavaScript entre los dos divs y el proceso de análisis de este script es un poco diferente.
Cuando se analiza la etiqueta script, el analizador HTML suspende su trabajo, el motor javascript interviene y ejecuta el script en la etiqueta script.
Debido a que este script javascript modifica el contenido del primer div en el DOM, después de ejecutar este script, el contenido del nodo div se modificó a time.geekbang. Una vez completada la ejecución del script, el analizador HTML regresa al proceso de análisis y continúa analizando el contenido posterior hasta que se genera el DOM final.
Importar archivos javaScript a páginas html
//foo.js
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang'
<html>
<body>
<div>1</div>
<script type="text/javascript" src='foo.js'></script>
<div>test</div>
</body>
</html>
La función de este fragmento de código sigue siendo la misma que la del código anterior, excepto que el script JavaScript incrustado se modifica para cargarse a través de un archivo javaScript.
Todo el proceso de ejecución sigue siendo el mismo. Cuando se ejecuta la etiqueta JAVAScript, se suspende el análisis de todo el DOM y se ejecuta el código javascript. Sin embargo, cuando se ejecuta javascript aquí, este código debe estar presente. Aquí debemos centrarnos en el entorno de descarga, porque el proceso de descarga del archivo javascript bloqueará el análisis DOM y, por lo general, la descarga lleva mucho tiempo y se verá afectada por factores como el entorno de red y el tamaño del javascript. archivo.
Mecanismo de optimización:
Google Chrome ha realizado muchas optimizaciones, una de las principales optimizaciones es la operación de análisis previo. Cuando el motor de renderizado recibe el flujo de bytes, iniciará un hilo de análisis previo para analizar los archivos JavaScript, CSS y otros archivos relacionados contenidos en el archivo HTML. Después de analizar los archivos relevantes, iniciará un hilo de análisis previo para analizar el Archivo HTML. Después de analizar javascprit, css y otros archivos relacionados contenidos en el archivo, el hilo de análisis previo descargará estos archivos con anticipación.
Volviendo al análisis de DOM, sabemos que la introducción de subprocesos de JavaScript bloqueará el DOM, pero también hay algunas estrategias relacionadas que se deben evitar, como usar CDN para acelerar la carga de archivos JavaScript y comprimir el volumen de archivos JavaScript.
Además, si no hay ningún código relacionado con DOM en el archivo JavaScript, puede configurar el script JavaScript para que se cargue de forma asincrónica y marcar el código como asíncrono o aplazar. El uso es el siguiente:
<script async type="text/javascript" src='foo.js'></script>
<script defer type="text/javascript" src='foo.js'></script>
La diferencia entre async y aplazar:
- async: el script se carga en paralelo y se ejecuta inmediatamente después de que se completa la carga. El tiempo de ejecución es incierto y el análisis HTML aún puede estar bloqueado. El tiempo de ejecución es antes de que se envíe el evento de carga.
- diferir: los scripts se cargan en paralelo, una vez completado el análisis HTML, los scripts se ejecutan en el orden de carga, antes de que se envíe el evento DOMContentLoaded.
Hay estilos CSS en la página HTML.
//theme.css
div {color:blue}
<html>
<head>
<style src='theme.css'></style>
</head>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang' // 需要 DOM
div1.style.color = 'red' // 需要 CSSOM
</script>
<div>test</div>
</body>
</html>
En este ejemplo, div1.style.color = ‘red’la declaración de aparece en el código JavaScript, que se utiliza para manipular CSSOM, por lo que antes de ejecutar JavaScript, es necesario analizar todos los estilos CSS encima de la declaración de JavaScript. Por lo tanto, si se hace referencia a un archivo CSS externo en el código, antes de ejecutar JavaScript, es necesario esperar a que se complete la descarga del archivo CSS externo y analizar y generar un objeto CSSOM antes de ejecutar el script JavaScript.
Antes de que el motor de JavaScript analice JavaScript, no sabe si JavaScript ha manipulado el CSSOM, por lo que cuando el motor de renderizado encuentra un script de JavaScript, sin importar si el script manipula el CSSOM, descargará el archivo CSS, analizará la operación y y luego ejecute el script JavaScript. Entonces el script JavaScript depende de la hoja de estilo, lo que agrega otro proceso de bloqueo.
Resumen: A través del análisis de los tres puntos anteriores, sabemos que JavaScript bloqueará la generación de DOM y los archivos de estilo bloquearán la ejecución de js.
1.36 La diferencia entre solo lectura y deshabilitado en el formulario
- Lo que tienen en común: la capacidad de evitar que los usuarios cambien el contenido del formulario.
- Diferencias:
1. solo lectura solo es válido para entrada y área de texto, pero deshabilitado es válido para todos los elementos del formulario, incluida la radio y la casilla de verificación.
2. solo lectura puede obtener el foco, pero no se puede modificar. El cuadro de texto configurado como deshabilitado no puede obtener el foco
3. Si el campo del formulario está deshabilitado, el campo no se enviará (valor del formulario) ni se serializará.
1.37 Navegadores y kernels convencionales
Google chrome: webkit/blink
safari: webkit
IE: trident
firefox: gecko
Opera: presto/webkit/blink
1.38 Hable sobre su comprensión de los siguientes eventos del ciclo de vida de la página: DOMContentLoaded, cargar, antes de descargar, descargar
El ciclo de vida de una página HTML consta de tres eventos importantes:
- DOMContentLoaded: el navegador ha cargado completamente el HTML y ha creado el árbol DOM, pero es posible que los recursos externos como estilos y hojas de estilo no hayan terminado de cargarse.
- cargar —— El navegador no solo ha cargado el HTML, sino que también ha cargado todos los recursos externos: imágenes, estilos, etc.
- beforeunload/unload: cuando el usuario abandona la página.
Cada evento es útil:
- Evento DOMContentLoaded: el DOM está listo, por lo que el controlador puede encontrar el nodo DOM e inicializar la interfaz.
- evento de carga: se han cargado recursos externos, se han aplicado estilos y se conocen los tamaños de las imágenes.
- Evento beforeunload: el usuario se va: podemos verificar si el usuario ha guardado los cambios y preguntarle si realmente quiere irse.
- evento de descarga: el usuario casi se ha ido, pero aún podemos iniciar algunas acciones, como enviar estadísticas.
DOMContentLoaded y scripts
Cuando un navegador procesa un documento HTML y encuentra
Por lo tanto, DOMContentLoaded debe ocurrir después de la ejecución de estos scripts a continuación.
Hay dos excepciones a esta regla:
- Los scripts con el atributo async no se bloquean en DOMContentLoaded, como veremos más adelante.
- Los scripts generados dinámicamente y agregados a una página usando document.createElement('script') tampoco bloquearán DOMContentLoaded.
DOMContentLoaded y estilos
Las hojas de estilo externas no afectan el DOM, por lo que DOMContentLoaded no las espera.
Pero aquí hay un problema. Si hay un script después del estilo, el script debe esperar a que termine de cargarse la hoja de estilo. La razón es que un script podría querer obtener las coordenadas del elemento y otras propiedades relacionadas con el estilo. Por lo tanto, hay que esperar a que se carguen los estilos.
Cuando DOMContentLoaded espera secuencias de comandos, ahora también espera estilos que preceden a las secuencias de comandos.
Autocompletar integrado en el navegador
Firefox, Chrome y Opera, todos los formularios de autocompletar en DOMContentLoaded.
Por ejemplo, si la página tiene un formulario con un nombre de usuario y contraseña, y el navegador recuerda estos valores, en DOMContentLoaded el navegador intentará completarlos automáticamente (si el usuario lo permite).
Entonces, si DOMContentLoaded se retrasa debido a un script que tarda mucho en cargarse, el autocompletar también esperará. Es posible que haya visto esto en algunos sitios (si utiliza el autocompletar del navegador): los campos de inicio de sesión/contraseña no se completan automáticamente de inmediato, sino que se completan de manera lenta hasta que la página se carga por completo. En realidad, esto es un retraso antes del evento DOMContentLoaded.
ventana.onload
El evento de carga en el objeto de ventana se activa cuando se ha cargado toda la página, incluidos estilos, imágenes y otros recursos. Este evento se puede obtener a través del atributo onload.
ventana.onunload
Cuando el visitante abandona la página, se activa el evento de descarga en el objeto de la ventana. Allí podremos hacer cosas que no supongan retraso, como cerrar el popup asociado.
Un caso especial notable es el envío de datos analíticos.
Supongamos que recopilamos datos sobre el uso de la página: clics del mouse, desplazamiento, áreas de la página visitadas, etc.
Naturalmente, cuando el usuario está a punto de irse, queremos guardar los datos en nuestro servidor mediante el evento de descarga.
Existe un método especial navigator.sendBeacon(url, datos) para cumplir con este requisito; consulte la especificación https://w3c.github.io/beacon/ para obtener más detalles.
Envía datos en segundo plano y no hay demora en la transición a otra página: el navegador abandona la página, pero aún ejecuta sendBeacon.
Cuando se completa la solicitud de sendBeacon, es posible que el navegador haya abandonado el documento, por lo que no hay forma de obtener la respuesta del servidor (que normalmente está vacía para los datos analíticos).
También hay un indicador de mantenimiento de actividad, que se utiliza en el método de recuperación para realizar solicitudes "después de abandonar la página" para solicitudes de red genéricas. Puede encontrar más información al respecto en el capítulo Fetch API.
Si queremos cancelar la operación de saltar a otra página, no podemos hacerlo aquí. Pero podemos usar otro evento: onbeforeunload.
ventana.onantes de descargar
Si el visitante activa la navegación fuera de la página o intenta cerrar la ventana, el controlador de descarga previa solicitará más confirmación.
Si queremos cancelar el evento, el navegador preguntará al usuario si está seguro.
Resumir
Eventos del ciclo de vida de la página:
- Cuando el DOM está listo, se activa el evento DOMContentLoaded en el documento. En esta etapa, podemos aplicar JavaScript al elemento.
- Scripts como
<script>...</script>o<script src="..."></script>bloquean en DOMContentLoaded, y el navegador espera a que terminen de ejecutarse. - Aún se pueden seguir cargando imágenes y otros recursos.
- Scripts como
- Cuando se cargan la página y todos los recursos, se activa el evento de carga en la ventana. Rara vez lo usamos porque normalmente no es necesario esperar tanto.
- Cuando el usuario quiere abandonar la página, se activa el evento beforeunload en la ventana. Si cancelamos este evento, el navegador nos preguntará si realmente queremos salir (por ejemplo, tenemos cambios sin guardar).
- Cuando el usuario finalmente se va, se activa el evento de descarga en la ventana. En los handlers solo podemos realizar acciones simples que no impliquen demoras ni preguntar al usuario. Es por esta limitación que rara vez se utiliza. Podemos usar navigator.sendBeacon para enviar solicitudes de red.
1.39 Cuando se utiliza la etiqueta de entrada para cargar imágenes, ¿cómo activar la función de cámara predeterminada?
La propiedad de captura se utiliza para especificar cómo se capturan los medios en el control de carga de archivos.
Valores opcionales:
- prefijo de usuario
- publicación ambiental
- camara camara
- cámara videocámara
- grabación de micrófono
<input type='file' accept='image/*;' capture='camera'>
Sube varias fotos para ingresar
<input type="file" name="files" multiple/>
1.40 ¿Cómo prohibir que la entrada muestre el historial de entrada?
Al ingresar la entrada, se le solicitará el contenido de la entrada original y también habrá un registro de historial desplegable. Para prohibir esta situación, simplemente agregue la entrada: autocompletar="off"
<input type="text" autocomplete="off" />
El atributo de autocompletar se utiliza para especificar si el campo de entrada está habilitado para autocompletar.
1.41 ¿Qué es iconfont? ¿Cuáles son los pros y los contras?
¿Qué es IconFont?
Como sugiere el nombre, IconFont es un ícono de fuente. En sentido estricto, un tipo de letra, sin embargo, en lugar de letras o números, contiene símbolos y glifos. Puede diseñarlo con CSS como si fuera texto normal, lo que convierte a IconFont en una opción popular para iconos cuando se desarrolla para la web.
ventaja
- Puedes aplicarles fácilmente cualquier efecto CSS.
- Al ser gráficos vectoriales, son escalables. Esto significa que podemos escalarlos sin perder calidad.
- Solo necesitamos enviar una o varias solicitudes HTTP para cargarlas, no como imágenes, que pueden requerir múltiples solicitudes HTTP.
- Se cargan rápido debido a su pequeño tamaño.
- Son compatibles con todos los navegadores (incluso hasta IE6).
insuficiente
- No se puede utilizar para mostrar imágenes complejas.
- Generalmente limitado a un color a menos que se apliquen algunos trucos de CSS.
- Los íconos de fuentes generalmente se diseñan según una cuadrícula específica, como 16x16, 32x32, 48x48, etc. Si cambia el sistema de cuadrícula a 25×25 por algún motivo, es posible que no obtenga resultados nítidos.
1.42 ¿Cuáles son los indicadores PV y UV comúnmente utilizados en las estadísticas de páginas?
PV (vistas de página)
Es decir, el número de visitas a la página o clics. Cada vez que un usuario visita cada página web del sitio web, se registra un PV.
El usuario visita la misma página varias veces y el número de visitas se acumula, lo que se utiliza para medir el número de páginas web visitadas por los usuarios del sitio web.
UV (visitante único)
Se refiere a la persona física que visita y navega por esta página web a través de Internet. Un cliente informático que accede a su sitio web es un visitante.
El mismo cliente entre las 00:00 y las 24:00 solo se cuenta una vez.
1.43 ¿El dpr de un dispositivo es variable?
devicePixelRatioEl nombre chino es la proporción de píxeles del dispositivo. Este concepto recibirá especial atención durante el desarrollo móvil, porque está relacionado con la apariencia, el diseño e incluso la claridad de toda la pantalla. En JavaScript BOM, es una propiedad bajo el objeto global de ventana y su definición es la siguiente:
dpr = píxeles del dispositivo / píxeles CSS
También hay artículos que se refieren a los píxeles del dispositivo como píxeles físicos y a los píxeles CSS como píxeles independientes (DIP), pero todos se refieren al mismo concepto:
(1) Hablemos primero de los píxeles del dispositivo. Tomando los teléfonos móviles como ejemplo, los píxeles del dispositivo son 1920 1080 píxeles o 1280 720 píxeles que se ven a menudo en los anuncios de teléfonos móviles , lo que a menudo se denomina resolución de 1080p o 720p. Se refiere a cuántas áreas mínimas en el dispositivo pueden mostrar un color específico, y este valor no cambiará en ningún dispositivo.
(2) Hablemos de píxeles CSS, que se denominan píxeles independientes en un sentido más amplio. Los píxeles CSS se crean para desarrolladores web y son una capa de abstracción utilizada en CSS y JavaScript. Las propiedades que definimos en CSS, como ancho: 100 px y tamaño de fuente: 16 px, se refieren todas a píxeles CSS. En comparación con los píxeles CSS, el concepto de píxeles del dispositivo apenas se utiliza en la interfaz (excepto para screen.width/height).
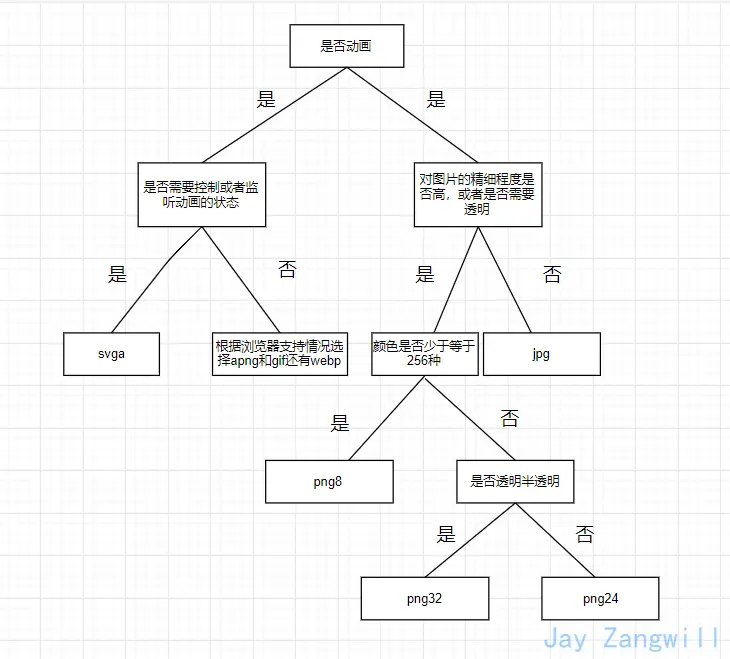
Luego, desde el punto de vista de la definición, el significado de dpr es: en un dispositivo (en cada dirección), cuántos píxeles físicos reales mostrará cada píxel CSS.
[Error en la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-1K453lNx-1683893094352) (C:\Users\32063\AppData\Roaming\Typora\ typora-user-images\ image-20230512093200340.png)]
En la imagen de arriba, un cuadrado azul representa un píxel del dispositivo y un cuadrado amarillo representa un píxel CSS. Podemos aclarar el concepto de dpr a través de esta imagen:
- Como se muestra a la izquierda, un píxel del dispositivo cubre varios píxeles CSS, dpr <1, correspondiente a la operación de alejamiento del usuario;
- Como se muestra a la derecha, un píxel CSS cubre varios píxeles del dispositivo, dpr > 1, correspondiente a la operación de acercamiento del usuario.
Dado que la operación de zoom del usuario cambia el dpr , el dpr del dispositivo se define con un zoom predeterminado del 100%.
1.44 ¿Cuáles son las reglas de carga y representación de imágenes en html y css?
El navegador web primero analiza el código HTML adquirido en un árbol DOM. Cada etiqueta en el HTML es un nodo en el árbol DOM, incluidas las etiquetas ocultas con visualización: ninguna y los elementos agregados dinámicamente por JavaScript. El navegador obtendrá todos los estilos, los analizará en reglas de estilo y eliminará los estilos que el navegador no puede reconocer durante el proceso de análisis.
El navegador combinará el árbol DOM y las reglas de estilo (los elementos DOM y las reglas de estilo coinciden) y luego construirá un árbol de renderizado (árbol de renderizado). El árbol de renderizado es similar al árbol DOM, pero todavía hay una gran diferencia entre los dos: renderizado El árbol puede identificar estilos, cada nodo (NODO) en el árbol de renderizado tiene su propio estilo y el árbol de renderizado no contiene nodos ocultos (como display:none nodos y algunos nodos dentro), porque estos nodos no utilizar Para renderizar, no afectará la representación de los nodos, por lo que no se incluirá en el árbol de representación. Una vez creado el árbol de renderizado, el navegador puede dibujar la página de acuerdo con el árbol de renderizado.
Un resumen simple es que el navegador pasará por seis procesos al representar una página web:
- Analizar HTML para formar un árbol DOM
- Analice el estilo cargado y cree un árbol de reglas de estilo
- Cargar JavaScript, ejecutar código JavaScript
- El árbol DOM y el árbol de reglas de estilo coinciden para formar un árbol de representación
- Calcular la posición del elemento para el diseño de página.
- Dibuja la página y finalmente renderízala en el navegador.
¿Crees que esto no tiene nada que ver con nuestra carga y renderizado de imágenes, pero este no es el caso, porque img, imagen o imagen de fondo son parte del árbol DOM o reglas de estilo, luego las aplicamos y el tiempo? de carga y renderizado de imágenes. Podría ser algo como esto:
- Al analizar HTML, si se encuentra una etiqueta img o de imagen, la imagen se cargará
- Analice el estilo cargado. Cuando encuentre una imagen de fondo, la imagen no se cargará, pero se creará un árbol de reglas de estilo.
- Cargue JavaScript y ejecute el código JavaScript. Si hay un elemento img creado en el código, se agregará al árbol DOM; si se agrega una regla de imagen de fondo, se agregará al árbol de reglas de estilo.
- Construya el árbol de renderizado cuando el árbol DOM coincida con la regla de estilo, y si el nodo del árbol DOM coincide con la imagen de fondo en la regla de estilo, se cargará la imagen de fondo.
- Calcular la posición del elemento (imagen) para el diseño
- Comience a renderizar la imagen y el navegador renderizará la imagen renderizada.
El mecanismo de representación de páginas del navegador se aplica arriba, pero todavía existen ciertas reglas para la carga y representación de imágenes. Porque no todos los elementos (o imágenes) de la página cargarán las imágenes y las imágenes de fondo introducidas por la imagen de fondo. Entonces surge una nueva pregunta: ¿cuándo se cargará realmente y cuáles son las reglas de carga?
Para resumir un poco:
¡No todas las imágenes de una página web se cargarán y renderizarán!
Según el mecanismo de carga y renderizado del navegador presentado anteriormente, podemos resumirlo como:
- , y cuando un elemento con imagen de fondo encuentra display:none, la imagen se cargará pero no se renderizará.
- y configurando display:none en el elemento ancestro del elemento que establece la imagen de fondo, la imagen de fondo no se representará ni se cargará, mientras que las imágenes introducidas por img y la imagen no se representarán pero se cargarán.
- y background-image importan la misma ruta y el mismo nombre de archivo de imagen, la imagen solo se cargará una vez
- Si la imagen introducida por imagen de fondo en el archivo de estilo no puede coincidir con el elemento DOM, la imagen no se cargará
- La imagen de fondo introducida por la pseudoclase, como :hover, solo se cargará cuando se active la pseudoclase.
1.45 ¿Cuál es el uso de la ventana gráfica en la etiqueta mete?
¿Qué es la ventana gráfica?
La ventana gráfica es el área visible de la página web del usuario .
La traducción de ventana gráfica al chino se puede llamar **"ventana gráfica"**.
El navegador móvil coloca la página en una "ventana" virtual (ventana gráfica), generalmente la "ventana" virtual (ventana gráfica) es más ancha que la pantalla, por lo que no es necesario comprimir cada página web en una ventana pequeña (esto romperá el diseño de páginas web que no están optimizadas para navegadores móviles), los usuarios pueden desplazarse y hacer zoom para ver diferentes partes de la página web.
Establecer ventana gráfica
Una metaetiqueta de ventana gráfica comúnmente utilizada para una página optimizada para páginas web móviles es aproximadamente la siguiente:
1<meta name="viewport" content="width=device-width, initial-scale=1.0">
- Ancho: controla el tamaño de la ventana gráfica, puedes especificar un valor, como 600, o un valor especial, como ancho del dispositivo es el ancho del dispositivo (la unidad son píxeles CSS cuando el zoom es del 100%).
- altura: correspondiente al ancho, especifique la altura.
- escala inicial: la relación de zoom inicial, es decir, la relación de zoom cuando la página se carga por primera vez.
- escala máxima: la escala máxima a la que el usuario puede hacer zoom.
- escala mínima: la escala mínima a la que el usuario puede hacer zoom.
- escalable por el usuario: si el usuario puede escalar manualmente.
1.46 Cómo elegir el formato de imagen en la interfaz
Actualmente existen dos tipos de imágenes:
- mapa de bits
- ilustración vectorial
mapa de bits
El llamado mapa de bits es una imagen formada por píxeles, también llamado mapa de bits, png, jpg y otras imágenes que utilizamos habitualmente son mapas de bits.
ilustración vectorial
Gráficos vectoriales, también conocidos como gráficos vectoriales. Los gráficos vectoriales no registran la información de cada punto en la pantalla, sino que registran el algoritmo de la forma y el color de los elementos. Cuando abre un diagrama vectorial, el software realiza cálculos sobre las funciones correspondientes a los gráficos y calcula la forma. y color de los gráficos como resultado del cálculo. Te lo muestro.
Independientemente de si la pantalla es grande o pequeña, el algoritmo correspondiente a los objetos en la pantalla no cambia, por lo que incluso si la pantalla se escala en un múltiplo considerable, no se distorsionará como un mapa de bits.
El más común es el formato svg.
tipo de compresión de imagen
- sin compresión
- compresión con pérdida
- compresión sin perdidas
sin compresión
El formato de imagen sin comprimir no comprime los datos de la imagen y puede presentar con precisión la imagen original. Por ejemplo, imágenes en formato BMP.
compresión con pérdida
Significa que en el proceso de comprimir el tamaño del archivo, parte de la información de la imagen se pierde, es decir, la calidad de la imagen se reduce (es decir, la imagen se ve borrosa), y esta pérdida es irreversible.
Un método común de compresión con pérdida es combinar píxeles adyacentes según un determinado algoritmo. El algoritmo de compresión no codifica ni comprime todos los datos de la imagen, pero elimina los detalles de la imagen que el ojo humano no puede reconocer durante la compresión. Por lo tanto, la compresión con pérdida puede reducir en gran medida el tamaño de la imagen con la misma calidad de imagen. Por ejemplo, las imágenes en formato jpg utilizan compresión con pérdida.
compresión sin perdidas
En el proceso de comprimir imágenes, no se pierde calidad de imagen. Podemos restaurar la información original a partir de imágenes comprimidas sin pérdidas en cualquier momento.
El algoritmo de compresión codifica y comprime todos los datos de la imagen, lo que puede reducir el volumen de la imagen y al mismo tiempo garantizar la calidad de la imagen. Por ejemplo, png y gif utilizan compresión sin pérdidas.
Bits de imagen
Los bits de imagen generalmente se dividen en 8, 16, 24, 32
- Cuanto mayor sea el número de bits de una imagen, más colores podrá representar y mayor será el volumen que ocupará. Por ejemplo, las imágenes de 8 bits admiten 256 colores, que es 2 elevado a la octava potencia.
- Cuanto mayor sea el número de bits de la imagen, más delicada será la transición de color y la información de color transmitida podrá ser más rica.
- La diferencia entre 32 bits y 24 bits es que hay un canal Alfa adicional para admitir la translucidez, y los demás son básicamente iguales que los de 24 bits.
formatos de imagen comunes
GIF
El nombre completo de GIF es GIF Graphics Interchange Format, que se puede traducir al formato de intercambio de gráficos, fue desarrollado por Compu Serve en 1987 para llenar el vacío en los formatos de imagen multiplataforma.
GIF utiliza el algoritmo de compresión Lempel-Zev-Welch (LZW), que admite hasta 256 colores. Debido a esta característica, GIF es más adecuado para imágenes con menos color, como formas de dibujos animados, logotipos de empresas, etc. Si encuentra ocasiones que requieren colores reales de 24 bits, entonces la expresividad del GIF es limitada.
La característica más importante de las imágenes en formato GIF es la animación de cuadros, que es más pequeña en comparación con el antiguo formato bmp y admite transparencia (no admite translucidez, porque el canal de transparencia Alpha no es compatible) y animación.
ventaja:
- pequeño volumen
- animación de apoyo
defecto:
- Debido a la compresión de 8 bits, sólo se pueden procesar hasta 256 colores
JPEG/JPG
JPEG es Joint Photographic Experts Groupla abreviatura de (Joint Photographic Experts Group) y el nombre del sufijo del archivo es ".jpg" o ".jpeg". Es un formato de archivo de imagen de uso común y está formulado por una asociación de desarrollo de software. Es una compresión con pérdida. formato La imagen se puede comprimir en un espacio de almacenamiento pequeño y se perderán datos repetidos o sin importancia en la imagen, por lo que es fácil dañar los datos de la imagen. En particular, si la relación de compresión es demasiado alta, la calidad de la imagen restaurada después de la descompresión se reducirá significativamente. Si busca imágenes de alta calidad, no debe utilizar una relación de compresión excesiva.
ventaja:
- Al utilizar compresión con pérdida, el volumen comprimido es más pequeño
- Admite color verdadero de 24 bits
- Soporte para carga progresiva
defecto:
- La compresión con pérdida puede dañar la calidad de la imagen.
- No admite transparencia/translucidez
JPEG progresivo (jpeg progresivo)
Los archivos jpg progresivos contienen múltiples escaneos que se almacenan secuencialmente en el archivo jpg. En el proceso de abrir el archivo, primero se mostrará el contorno borroso de toda la imagen y la imagen se volverá cada vez más clara a medida que aumenta el número de escaneos.
PNG
png, o Portable Network Graphics, es un formato gráfico de mapa de bits comprimido sin pérdidas diseñado para reemplazar los formatos de archivo GIF y TIFF y al mismo tiempo agrega algunas características que el formato de archivo GIF no tiene. PNG utiliza un algoritmo de compresión de datos sin pérdidas derivado de LZ77 y generalmente se usa en programas JAVA, páginas web o programas S60 debido a su alta relación de compresión y tamaño de archivo pequeño.
PNG admite 8 bits, 24 bits y 32 bits, normalmente los llamamos png8, png24 y png32.
ventaja:
- compresión sin perdidas
- Soporte transparente, translúcido
- Se admiten imágenes en color verdadero de hasta 24 bits e imágenes en escala de grises de 8 bits, eliminando así por completo los bordes irregulares.
defecto:
- PNG ofrece menos compresión que la compresión con pérdida de jpg
- No admite animación, si necesita admitir animación, debe usar apng
APNG
APNG (Animated Portable Network Graphics) es un formato de animación de mapa de bits basado en PNG (Portable Network Graphics). De hecho, es una animación compuesta por múltiples png. Abra la computadora MAC y podrá ver todas las imágenes que componen apng.
ventaja:
- Soporta todas las ventajas de png
- animación de apoyo
defecto:
- El soporte del navegador es pobre
WEBP
WebP fue lanzado originalmente por Google en 2010 con el objetivo de reducir el tamaño de los archivos. Admite compresión con y sin pérdidas.
Casi integra las ventajas de todas las imágenes anteriores y puede tener una tasa de compresión más alta, pero la tasa de compatibilidad del navegador no es lo suficientemente ideal.
SVG
SVG es un lenguaje definido en XML para describir gráficos vectoriales y vectoriales/rasterizados bidimensionales. SVG proporciona tres tipos de objetos gráficos: gráficos vectoriales (por ejemplo: trazados compuestos de líneas rectas y curvas), imágenes y texto. Los objetos gráficos también se pueden agrupar, diseñar, transformar, combinar y más. El conjunto de funciones incluye transformaciones anidadas, trazados de recorte, máscaras alfa, efectos de filtro, objetos de plantilla y otras extensiones.
Los gráficos SVG son interactivos y dinámicos, y puede incrustar elementos de animación en archivos SVG o definir animaciones mediante scripts.
La diferencia entre SVG y la imagen de arriba es que es un diagrama vectorial, no importa cómo lo acerques, no se distorsionará; al mismo tiempo, los archivos SVG suelen ser mucho más pequeños que los archivos de formato JPEG y PNG.
ventaja:
- SVG se puede leer y modificar con muchas herramientas (como el Bloc de notas)
- SVG es más pequeño y comprimible que las imágenes JPEG y GIF.
- SVG es escalable
- Las imágenes SVG se pueden imprimir con alta calidad en cualquier resolución.
- SVG se puede ampliar sin pérdida de calidad de imagen
- SVG puede ejecutarse con tecnología JavaScript
- Los archivos SVG son XML puro
defecto:
- El costo de renderizado es relativamente alto en comparación con otras imágenes de formato, lo que tiene un impacto en el rendimiento.
- Hay un costo de aprendizaje ya que SVG es un lenguaje definido en XML.
Cómo elegir el formato de la imagen.