Inhaltsverzeichnis
Code-Implementierung der Hauptfunktion
Holen Sie sich den Quellcode der Webseite
Erhalten Sie Links zu einzelnen Artikeln
Holen Sie sich den Titel des Artikels
Holen Sie sich den Quellcode des Artikels
Extrahieren Sie Links zu einzelnen Artikeln eines Artikelverzeichnisses
Blog zum vorherigen Kapitel
Vorwort
Im vorherigen Kapitel des Blogs haben wir darüber gesprochen, wie man über PyQt5 eine grafische Oberfläche erstellt und einige Grundeinstellungen vornimmt
In den nächsten beiden Kapiteln sprechen wir hauptsächlich über die Implementierung des Kern-Crawler-Codes

Code-Implementierung der Hauptfunktion
Code aus dem vorherigen Kapitel
self.Button_run.clicked.connect(self.F_run)Stellt das Klicken auf die Schaltfläche dar, um die F_run-Funktion auszuführen (beachten Sie, dass hier keine Klammern vorhanden sind).
Dann müssen wir diese Funktion definieren
Die Idee ist wahrscheinlich so
def F_run(self):
link_1=self.line_link.text()
title_1=F_gettitle(link_1)
self.text_result.setText(f"标题获取成功——{title_1}")
# file_1=open(f'{title_1}.txt',mode='w',encoding='utf-8 ')
test_1=F_getyuan(link_1)
self.text_result.setText("提取源代码成功")
time.sleep(1)
search_1=F_searchlink(test_1)
self.text_result.append("提取文章链接成功")
pachong(search_1,title_1)Zeile für Zeile Code-Analyse
Link bekommen
erster Pass
self.line_link.text()Befehl, um den Link in das Eingabefeld einzugeben
Und weisen Sie es link_1 zu
Titel bekommen
Gleichzeitig extrahiere ich die Schlüsselwörter, indem ich den Quellcode des Webseiten-Links crawle, um den Titel des Artikels zu erhalten
so heißt der Roman
title_1=F_gettitle(link_1)Holen Sie sich den Quellcode der Webseite
Crawlen Sie den Quellcode der Katalogseite des Romanartikels und weisen Sie ihn als test_1 zu (zur späteren Extraktion von Links zu jedem Artikel).
test_1=F_getyuan(link_1)Erhalten Sie Links zu einzelnen Artikeln
search_1=F_searchlink(test_1)Extrahieren und filtern Sie den erhaltenen Quellcode, um die Links zu jedem Artikel zu erhalten
Darunter werden self.text_result.setText und self.text_result.append im roten Kreis unten angezeigt
(Aus ästhetischen Gründen können Sie es nicht hinzufügen)
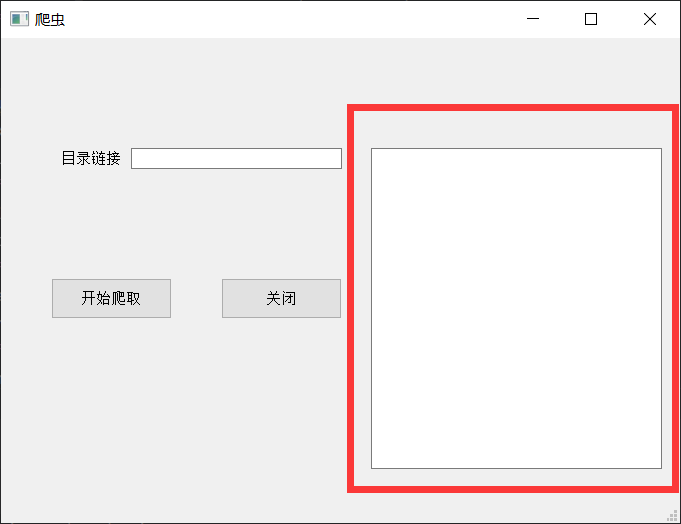
Funktionscode
Um den Code hier nicht zu lang zu machen, habe ich zwei separate Python-Dateien zum Speichern von Python-Funktionen erstellt
Bibliotheksdatei importieren
import requests
import re
import numpy as np
from lxml import etreerequest wird für Netzwerkanfragen verwendet
re und lxml werden zum Filtern von Quellcodeinformationen verwendet
während Numpy zum Speichern der Elemente verwendet wird
Holen Sie sich den Titel des Artikels
def F_gettitle(link_0):
head_qb={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'
}
test_1=requests.get(url=link_0,headers=head_qb)
test_yuan=test_1.text
dom=etree.HTML(test_yuan)
test_2=dom.xpath('/html/body/article[1]/div[2]/div[2]/h1/text()')
return test_2[0]Sehr einfacher Aufbau eines
Erhalten Sie den Quellcode auf Anfrage
Verwenden Sie dann den Baum in lxml, um den Quellcode zu filtern
(Wenn Sie den XPath-Pfad verwenden, fügen Sie am Ende text() hinzu, um die Textform auszugeben, andernfalls wird der Quellcode nicht angezeigt.)
Der XPath-Pfad kann durch Drücken der F12-Konsole extrahiert werden
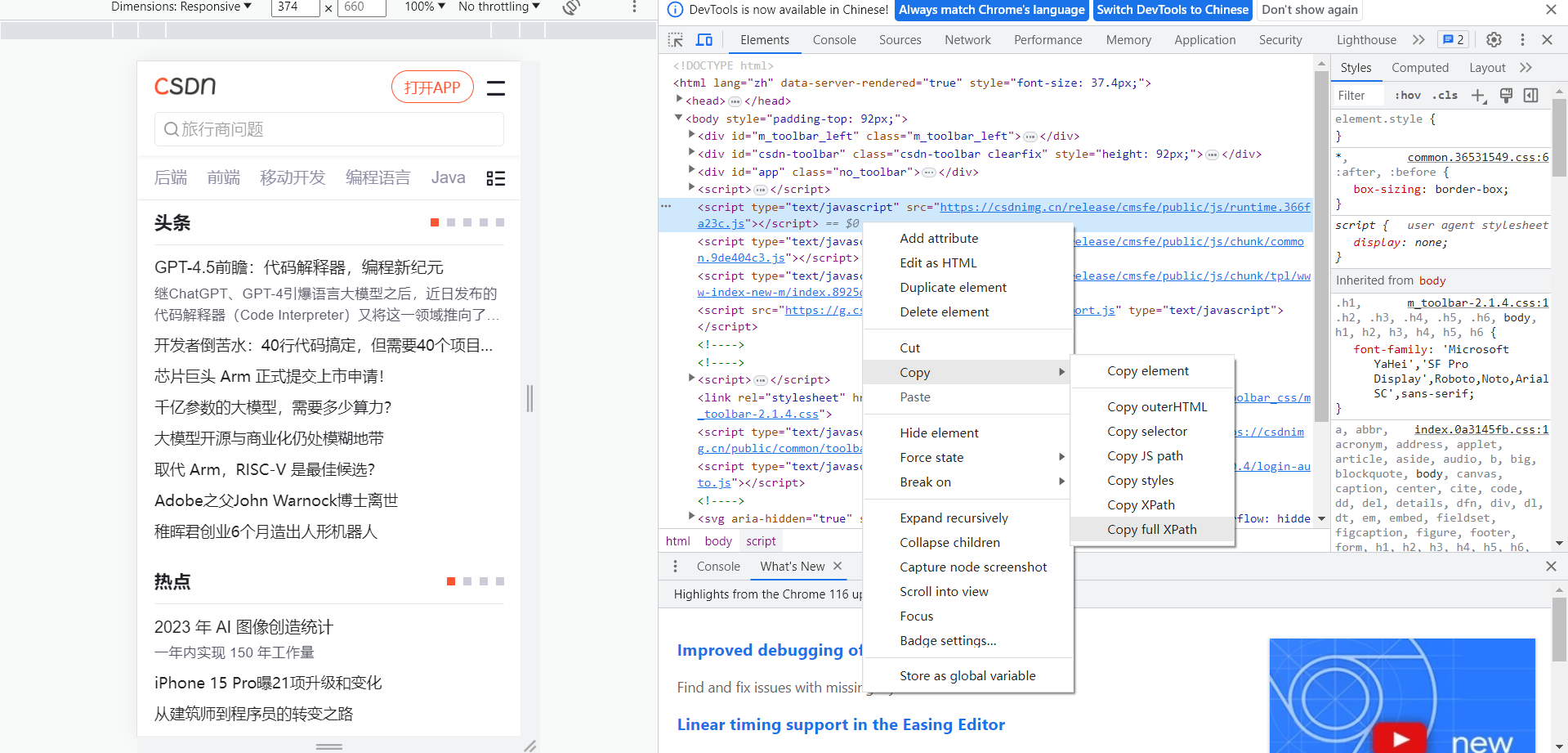
Holen Sie sich den Quellcode des Artikels
Es sollte leicht zu verstehen sein. Schreiben Sie einfach den Code direkt
def F_getyuan(link_1):
head_qb={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'
}
test_1=requests.get(url=link_1,headers=head_qb)
test_yuan=test_1.text
test_yuan=str(test_yuan)
return test_yuanExtrahieren Sie Links zu einzelnen Artikeln eines Artikelverzeichnisses
def F_searchlink(link_2):
re_1='<a id="haitung" href="(.*?)" rel="chapter">'
re_1=re.compile(re_1)
link_3=re.findall(re_1,link_2)
link_max=np.array([])
for link_1 in link_3:
link_4=f'http://www.biquge66.net{link_1}'
link_max=np.append(link_max,link_4)
return link_maxHier verwende ich direkt die Regelmäßigkeit der Re-Bibliothek, um den passenden Link abzugleichen
Beachten Sie, dass es sich bei dem passenden Link nicht um einen vollständigen Link handelt
Es muss also gespleißt werden
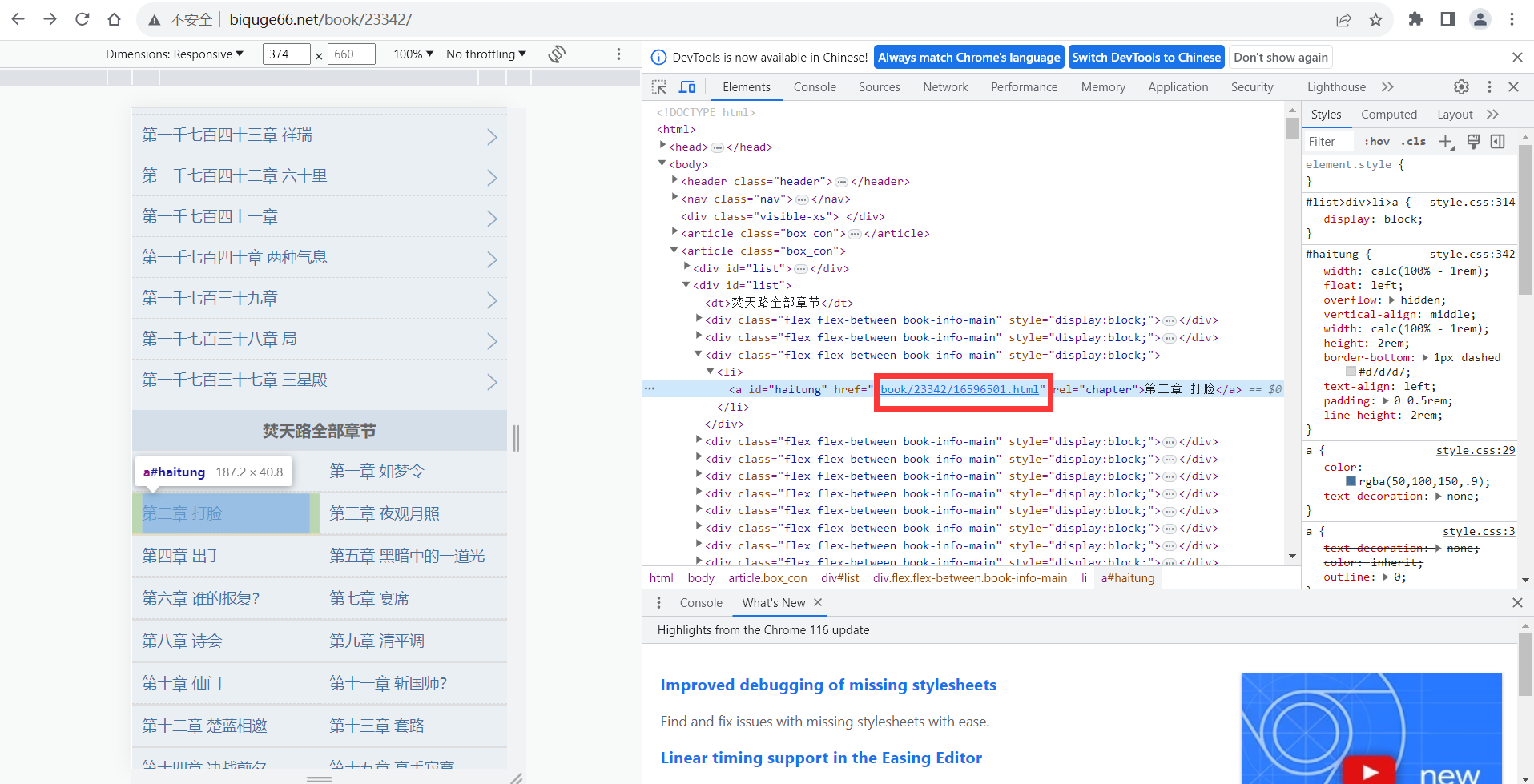
Nachdem das Spleißen abgeschlossen ist, kann es direkt geöffnet werden
Hier speichere ich es der Einfachheit halber in einem Array und crawle dann den Quellcode jedes Artikels
und dann zurück
Gesamtcode
main.py
import sys
# PyQt5中使用的基本控件都在PyQt5.QtWidgets模块中
from PyQt5.QtWidgets import QApplication, QMainWindow
# 导入designer工具生成的login模块
from win import Ui_MainWindow
from test_1 import *
import time
class MyMainForm(QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(MyMainForm, self).__init__(parent)
self.setupUi(self)
self.Button_close.clicked.connect(self.close)
self.Button_run.clicked.connect(self.F_run)
def F_run(self):
link_1=self.line_link.text()
title_1=F_gettitle(link_1)
self.text_result.setText(f"标题获取成功——{title_1}")
# file_1=open(f'{title_1}.txt',mode='w',encoding='utf-8 ')
test_1=F_getyuan(link_1)
self.text_result.append("提取源代码成功")
time.sleep(1)
search_1=F_searchlink(test_1)
self.text_result.append("提取文章链接成功")
pachong(search_1,title_1)
if __name__ == "__main__":
# 固定的,PyQt5程序都需要QApplication对象。sys.argv是命令行参数列表,确保程序可以双击运行
app = QApplication(sys.argv)
# 初始化
myWin = MyMainForm()
# 将窗口控件显示在屏幕上
myWin.show()
# 程序运行,sys.exit方法确保程序完整退出。
sys.exit(app.exec_())
test_1.py
import requests
import re
import numpy as np
from lxml import etree
#获取文章标题
def F_gettitle(link_0):
head_qb={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'
}
test_1=requests.get(url=link_0,headers=head_qb)
test_yuan=test_1.text
dom=etree.HTML(test_yuan)
test_2=dom.xpath('/html/body/article[1]/div[2]/div[2]/h1/text()')
return test_2[0]
#提取源代码
def F_getyuan(link_1):
head_qb={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'
}
test_1=requests.get(url=link_1,headers=head_qb)
test_yuan=test_1.text
test_yuan=str(test_yuan)
return test_yuan
#查询所有小说章节链接
def F_searchlink(link_2):
re_1='<a id="haitung" href="(.*?)" rel="chapter">'
re_1=re.compile(re_1)
link_3=re.findall(re_1,link_2)
link_max=np.array([])
for link_1 in link_3:
link_4=f'http://www.biquge66.net{link_1}'
link_max=np.append(link_max,link_4)
return link_max
# #输出文章内容
# def F_edittxt(link_3):
# head_qb={
# 'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'
# }
# trytimes = 3
# for i in range(trytimes):
# try:
# proxies = None
# test_1=requests.get(url=link_3,headers=head_qb, verify=False, proxies=None, timeout=3)
# if test_1.status_code == 200:
# break
# except:
# print(f'requests failed {i} time')
# #提取文章链接
# re_2='<p>(.*?)</p>'
# re_2=re.compile(re_2)
# #提取文章标题
# re_3='<h1 class="bookname">(.*?)</h1>'
# re.compile(re_3)
# test_2=np.array([])
# test_3=np.array([])
# test_2=re.findall(re_2,test_1.text)
# test_3 = re.findall(re_3, test_1.text)
# #放在数组的最后一个
# test_2=np.append(test_3,test_2)
# return test_2
Inhalt des nächsten Kapitels
Schließlich werden alle Kapitellinks abgerufen und der nächste Schritt besteht darin, den Artikel zu crawlen
Es hätte zusammen geschrieben werden können (Sie können den auskommentierten Teil in meiner test_1.py sehen), aber später fanden sich einige Probleme
Nur das nächste Kapitel
wird im nächsten Kapitel ausführlich erläutert