머리말
데이터 레이크는 현재 뜨거운 개념이며, 많은 기업이 자체 데이터 레이크를 구축하거나 구축을 계획하고 있습니다.
데이터 레이크는 모든 규모의 정형 및 비정형 데이터를 저장할 수 있는 중앙 집중식 저장소입니다. 먼저 구조화하지 않고 데이터를 있는 그대로 저장하고 대시보드 및 시각화부터 빅 데이터 처리, 실시간 분석 및 기계 학습에 이르기까지 다양한 유형의 분석을 실행하여 더 나은 의사 결정을 내릴 수 있습니다.
데이터 웨어하우스에서 데이터 레이크를 살펴보면
AWS 데이터 웨어하우스와 데이터 레이크의 공식 비교를 참조하세요.
- 데이터 웨어하우스는 트랜잭션 시스템 및 LOB(기간 업무) 애플리케이션 시스템의 관계형 데이터를 분석하는 데 최적화된 데이터베이스입니다. 빠른 SQL 쿼리를 제공하기 위해 데이터 구조와 Schema를 미리 정의합니다. 원시 데이터는 사용자에게 신뢰할 수 있는 "단일 데이터 결과"를 제공하기 위해 일련의 ETL 변환을 거칩니다.
- 데이터 레이크는 LOB(기간 업무) 애플리케이션의 관계형 데이터뿐만 아니라 모바일 앱, IoT 장치, 소셜 미디어의 비관계형 데이터도 저장한다는 점에서 다릅니다. 데이터를 캡처할 때 데이터 구조나 스키마를 미리 정의할 필요가 없습니다. 이는 데이터 레이크가 정교한 데이터 구조 없이 모든 유형의 데이터를 저장할 수 있음을 의미합니다. 다양한 유형의 분석(예: SQL 쿼리, 빅 데이터 분석, 전체 텍스트 검색, 실시간 분석, 기계 학습)을 데이터에 사용할 수 있습니다.
요약: 데이터 레이크는 데이터를 더 많이 포함하고 데이터 처리 방법이 더 다양합니다. 오히려 데이터 레이크의 데이터는 더 혼란스럽다.
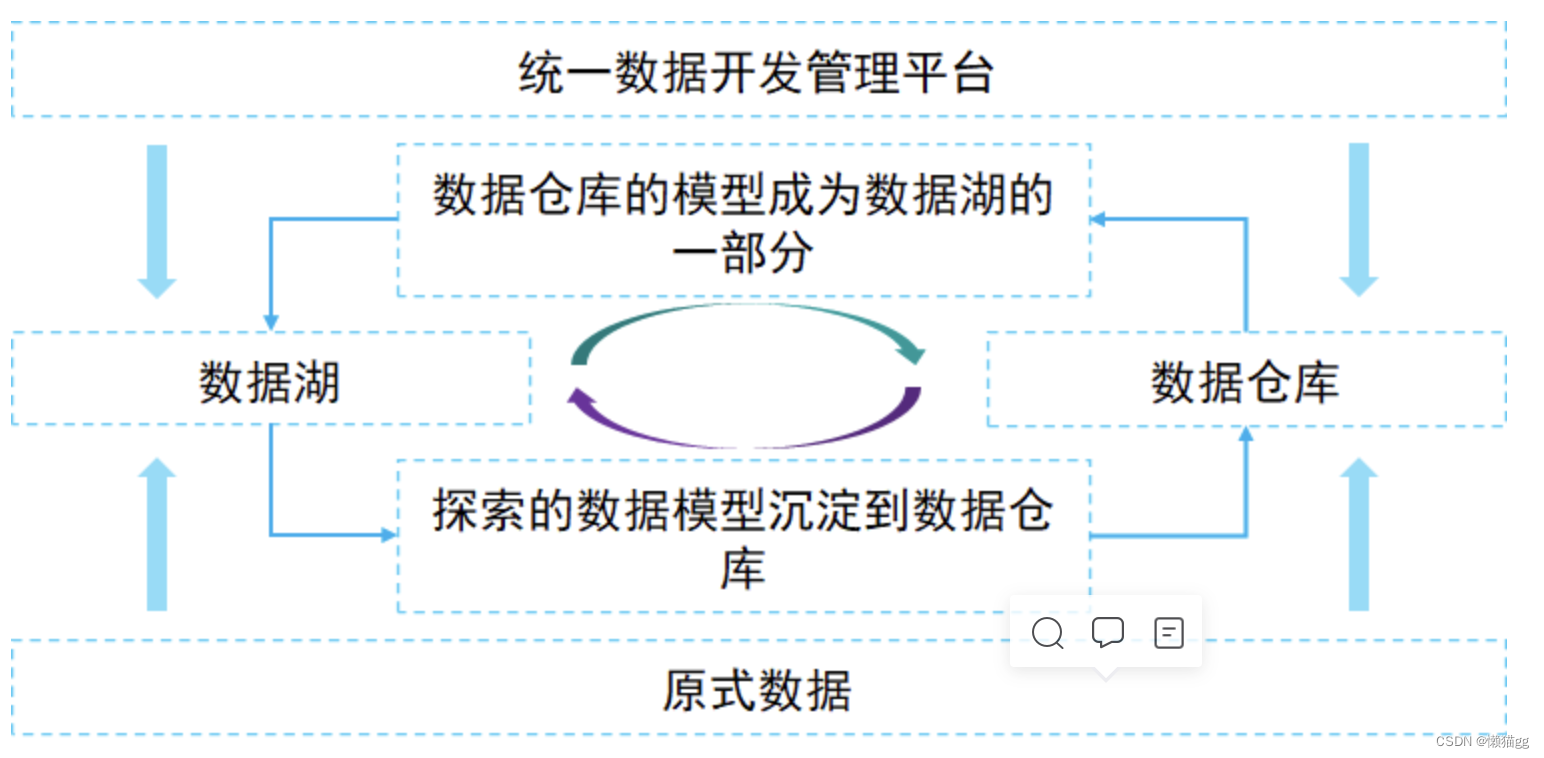
- 레이크와 웨어하우스의 메타데이터는 완벽하게 연결되어 서로 보완되며, 데이터 웨어하우스의 모델은 데이터 레이크로 피드백되어(원본 데이터의 일부가 됨) 레이크의 구조화된 애플리케이션이 데이터에 저장됩니다. 창고.
- 호수와 창고의 통합 개발, 서로 다른 시스템에 저장된 데이터를 플랫폼을 통해 통일적으로 관리할 수 있습니다.
- 데이터 레이크와 데이터 웨어하우스의 데이터에 대해서는 비즈니스 개발 요구에 따라 어떤 데이터가 데이터 웨어하우스에 저장되고 어떤 데이터가 데이터 레이크에 저장되는지 결정하여 레이크와 데이터 웨어하우스의 통합을 형성합니다. 창고.
- 데이터는 호수에 있고 모델은 창고에 있으며 변환이 반복됩니다.
후디란 무엇인가?
Hudi는 Uber의 오픈소스 데이터 레이크 아키텍처로, 새로운 기술 아키텍처인 데이터베이스 코어를 중심으로 구축된 스트리밍 데이터 레이크입니다.
스트리밍 요구 사항에 따라 그는 "COW 대 MOR"의 두 가지 데이터 모델을 구현하기 위해 파일 저장 및 관리를 설계했습니다.
이 Hudi 데이터 모델에 적응하고 현재 빅 데이터 환경에 통합하기 위해 그는 모든 구성 요소에 대한 Huid 플러그인을 작성했습니다.
데이터 레이크 솔루션인 Hudi 자체는 비즈니스 데이터를 생성하지 않으며 별도로 배포할 필요도 없습니다. 다른 빅데이터 구성요소에 완전히 의존함
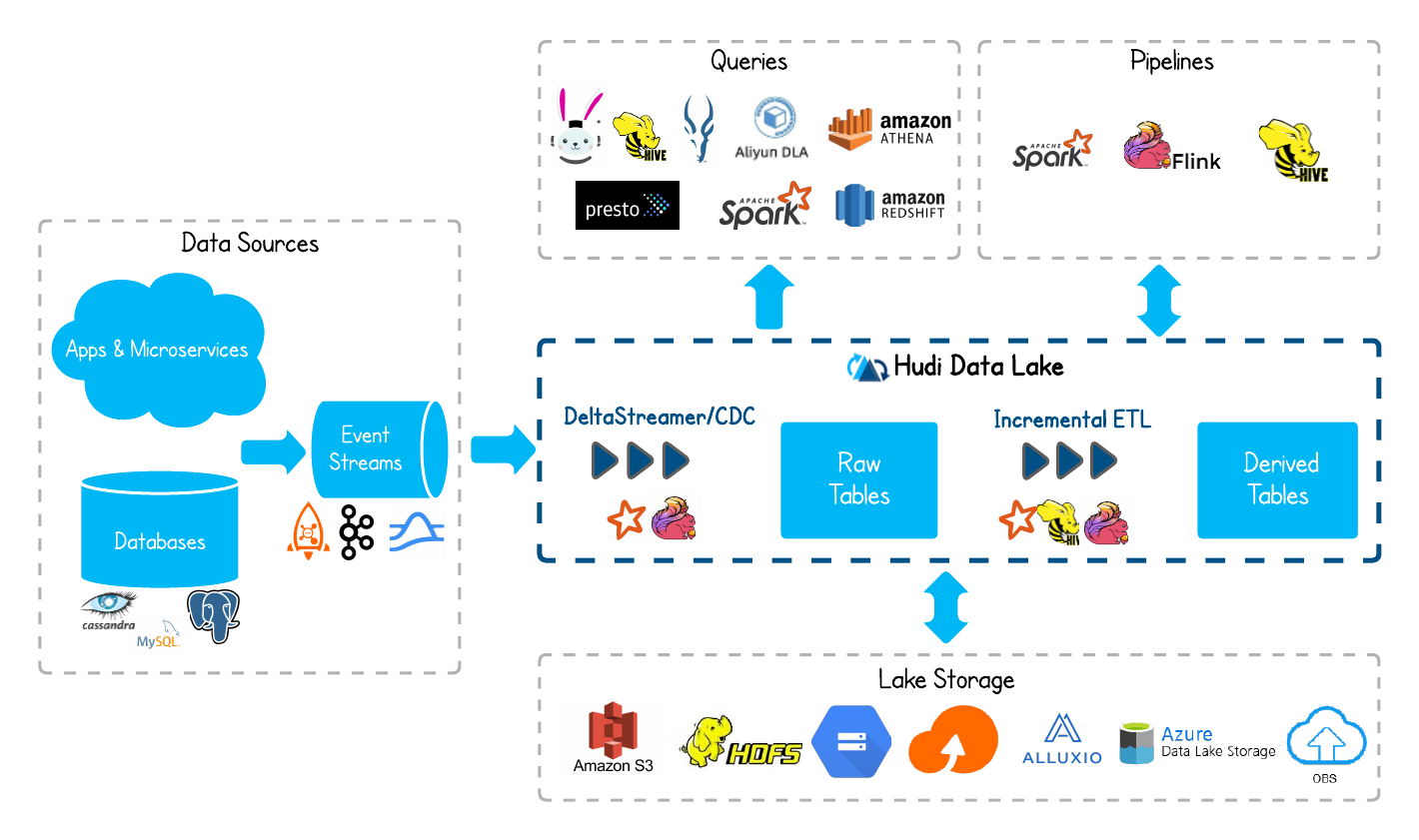
- hudi의 기본 데이터는 hdfs, s3, azure, alluxio 등에 저장할 수 있습니다.
- Hudi는 Spark/Flink 컴퓨팅 엔진을 사용하여 kafka 및 pulsar와 같은 메시지 대기열의 데이터를 사용할 수 있으며 이러한 데이터는 앱이나 마이크로 서비스의 비즈니스 데이터 및 로그 데이터 또는 mysql과 같은 데이터베이스의 binlog 로그 데이터에서 나올 수 있습니다.
- Spark/hudi는 먼저 이러한 데이터를 hudi 형식의 행 테이블(원본 테이블)로 처리한 다음 증분 ETL(증분 처리)을 통해 이 원본 테이블을 생성하여 hudi 형식의 파생 테이블 파생 테이블을 생성할 수 있습니다.
- hudi가 지원하는 쿼리 엔진에는 trino, hive, impala, Spark, presto 등이 포함됩니다.
hudi 데이터를 계속 처리하기 위해 Spark, flink 및 map-reduce와 같은 컴퓨팅 엔진이 지원됩니다.
데이터 조직 구조
Hudi 테이블의 데이터 파일은 운영 체제의 파일 시스템을 사용하여 저장할 수도 있고, HDFS와 같은 분산 파일 시스템을 사용하여 저장할 수도 있습니다. 후속 분석 성능 및 데이터 신뢰성을 위해 일반적으로 저장 장치로 HDFS가 사용됩니다. HDFS 스토리지 관점에서 Hudi 테이블의 스토리지 파일은 두 가지 범주로 나뉩니다.
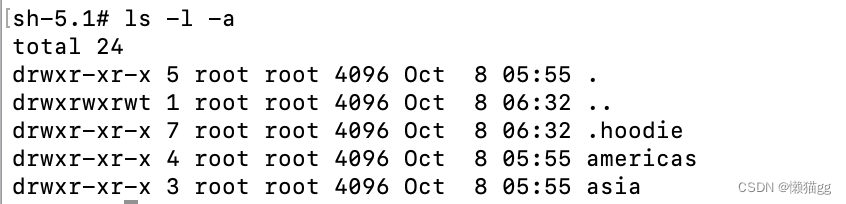
- .hoodie 파일: CRUD의 조각난 특성으로 인해 각 작업마다 파일이 생성됩니다. 이러한 작은 파일이 증가하면 HDFS 성능에 심각한 영향을 미칩니다. Hudi는 파일 병합 메커니즘을 설계했습니다. .hoodie 폴더에는 해당 파일 병합 작업과 관련된 로그 파일이 저장됩니다.
- amricas 및 asia 관련 경로는 실제 데이터 파일로 파티션별로 저장되며, 파티션의 경로 키를 지정할 수 있습니다.
까마귀 파일
Hudi는 타임라인에 따라 시간이 지남에 따라 테이블에 대한 일련의 CRUD 작업을 호출하며, 타임라인에서의 작업을 Instant라고 합니다.
- 즉각적인 조치, 이 작업이 데이터 제출(COMMITS)인지, 파일 병합(COMPACTION) 또는 파일 정리(CLEANS)인지 기록합니다.
- 인스턴트 타임(Instant Time), 이 작업이 발생한 시간입니다.
- 상태, 작업 상태(시작됨(REQUESTED)), 진행 중(INFLIGHT) 또는 완료됨(COMPLETED)

해당 작업의 상태 기록은 Hoodie 폴더에 저장됩니다.
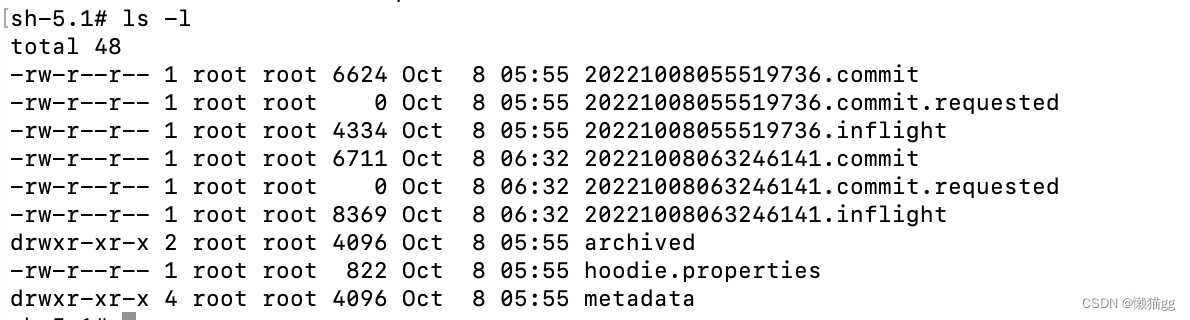
지연으로 인한 데이터 타이밍 문제를 해결하기 위한 타임라인
데이터 파일
Hudi의 실제 데이터 파일에는 메타데이터 메타데이터 파일(레코드 파티션)과 데이터 파일 마루 기둥형 저장소가 포함되어 있습니다.

데이터의 CRUD를 실현하려면 레코드를 고유하게 식별할 수 있어야 하며, Hudi는 데이터 세트의 고유 필드(레코드 키) + 데이터 파티션(partitionPath)을 데이터의 고유 키로 결합합니다.
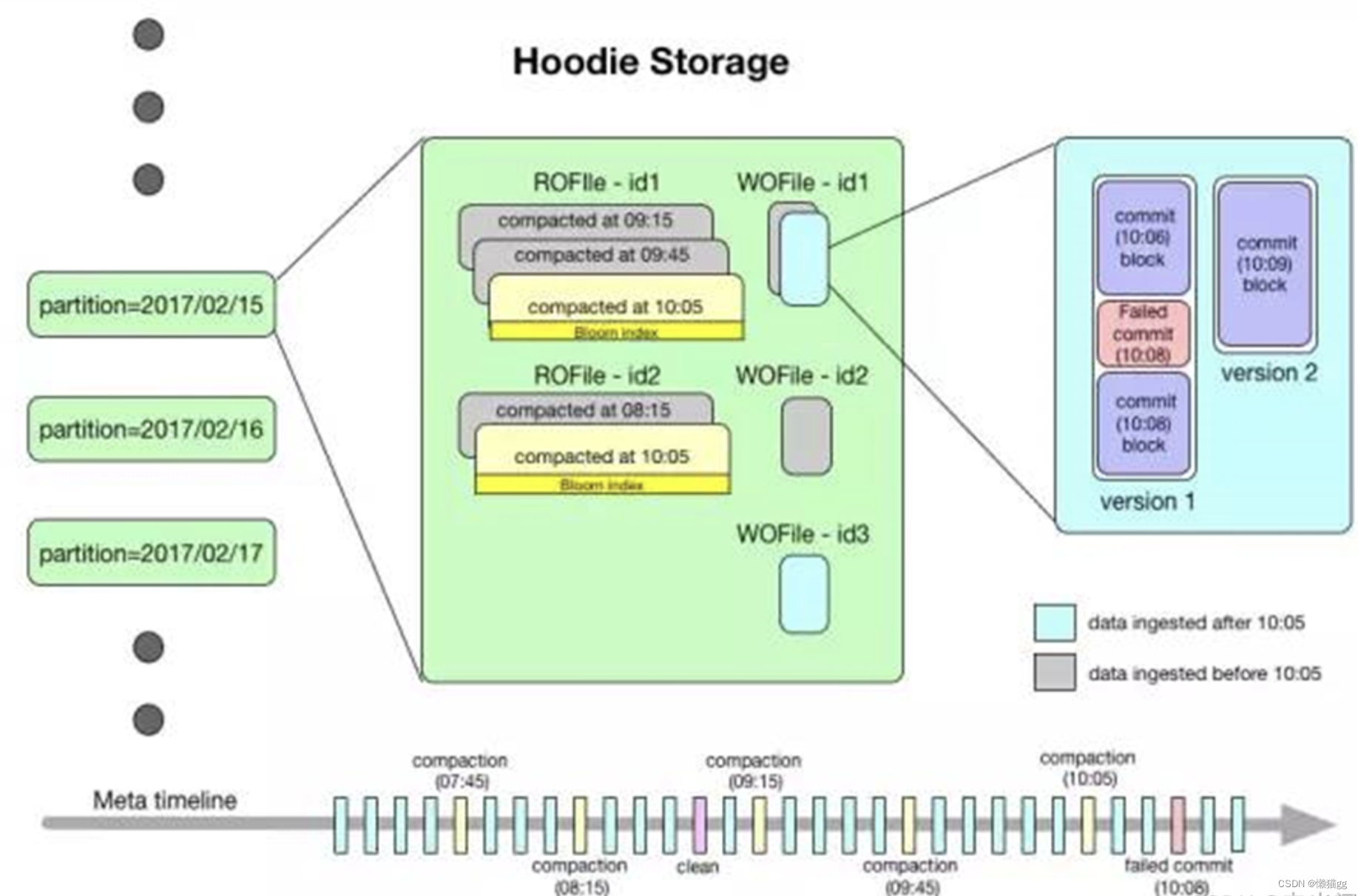
- Hudi 데이터세트의 조직 디렉터리 구조는 Hive의 조직 디렉터리 구조와 매우 유사하며 데이터세트는 이 루트 디렉터리에 해당합니다. 데이터 세트는 여러 개의 파티션으로 나누어져 있으며, 파티션 필드는 파티션의 모든 파일을 포함하는 폴더 형태로 존재합니다.
- 루트 디렉터리 아래에는 각 파티션마다 고유한 파티션 경로가 있으며 각 파티션 데이터는 여러 파일에 저장됩니다.
- 각 파일은 고유한 fileId와 파일을 생성한 커밋으로 식별됩니다. 업데이트 작업이 발생하면 여러 파일이 동일한 fileId를 공유하지만 커밋은 다릅니다.
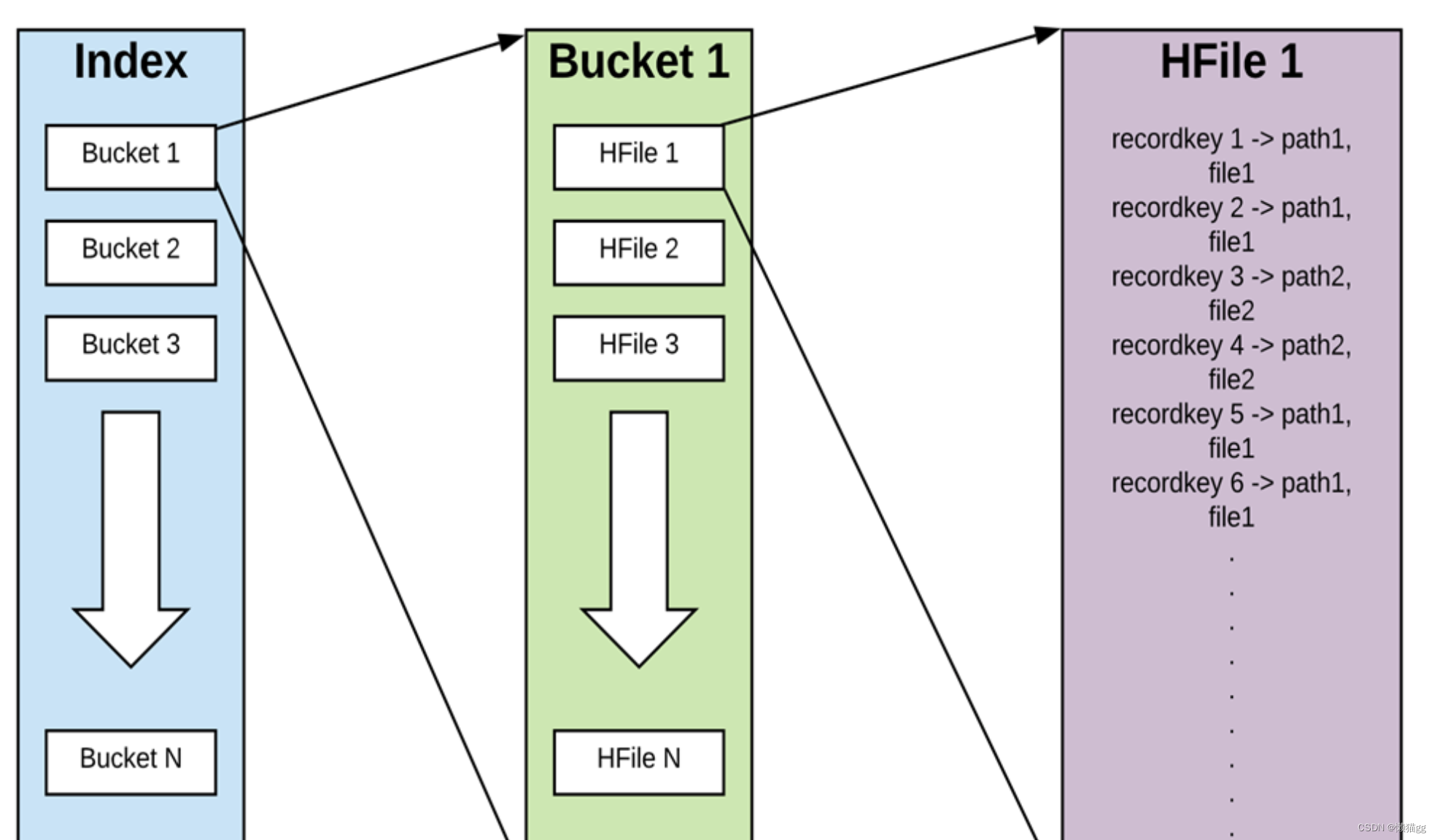
지수 지수
Hudi는 레코드 키가 존재할 때 새 레코드의 키를 해당 fileId에 빠르게 매핑할 수 있도록 지원하기 위해 인덱스를 유지 관리합니다.
- 블룸 필터: 데이터 파일의 바닥글에 저장됩니다. 기본 옵션은 외부 시스템 구현에 의존하지 않습니다. 데이터와 인덱스는 항상 일관됩니다.
- Apache HBase: 소규모 키 배치를 효율적으로 찾을 수 있습니다. 이 옵션은 인덱스 표시 중에 몇 초 더 빨라질 수 있습니다.
Hudi의 표 형식
Hudi는 COW(Copy on Write) 테이블과 MOR(Merge On Read) 테이블이라는 두 가지 유형의 테이블을 제공합니다.
- Copy-On-Write 테이블의 경우 사용자 업데이트가 데이터가 있는 파일을 다시 쓰기 때문에 쓰기 증폭이 매우 높지만 읽기 증폭은 0이므로 적게 쓰고 많이 읽는 시나리오에 적합합니다.
- Merge-On-Read Table의 경우 전체 구조가 LSM-Tree와 약간 유사하며 사용자가 쓴 내용이 먼저 델타 데이터에 기록됩니다. 이 부분의 데이터는 행 저장소를 사용합니다. 이 부분의 델타 데이터는 수동으로 병합할 수 있습니다. 스톡 파일에 저장하고 쪽모이 세공 마루의 기둥 저장 구조로 구성합니다.
쓰기 시 복사
COW로 줄여서 이름에서 알 수 있듯이 데이터를 쓸 때 원본을 복사하고 그 위에 새로운 데이터를 추가하는 기술입니다. 데이터 읽기 요청은 최신의 완전한 복사본을 읽는 것으로, 이는 MySQL의 MVCC의 개념과 유사하다.
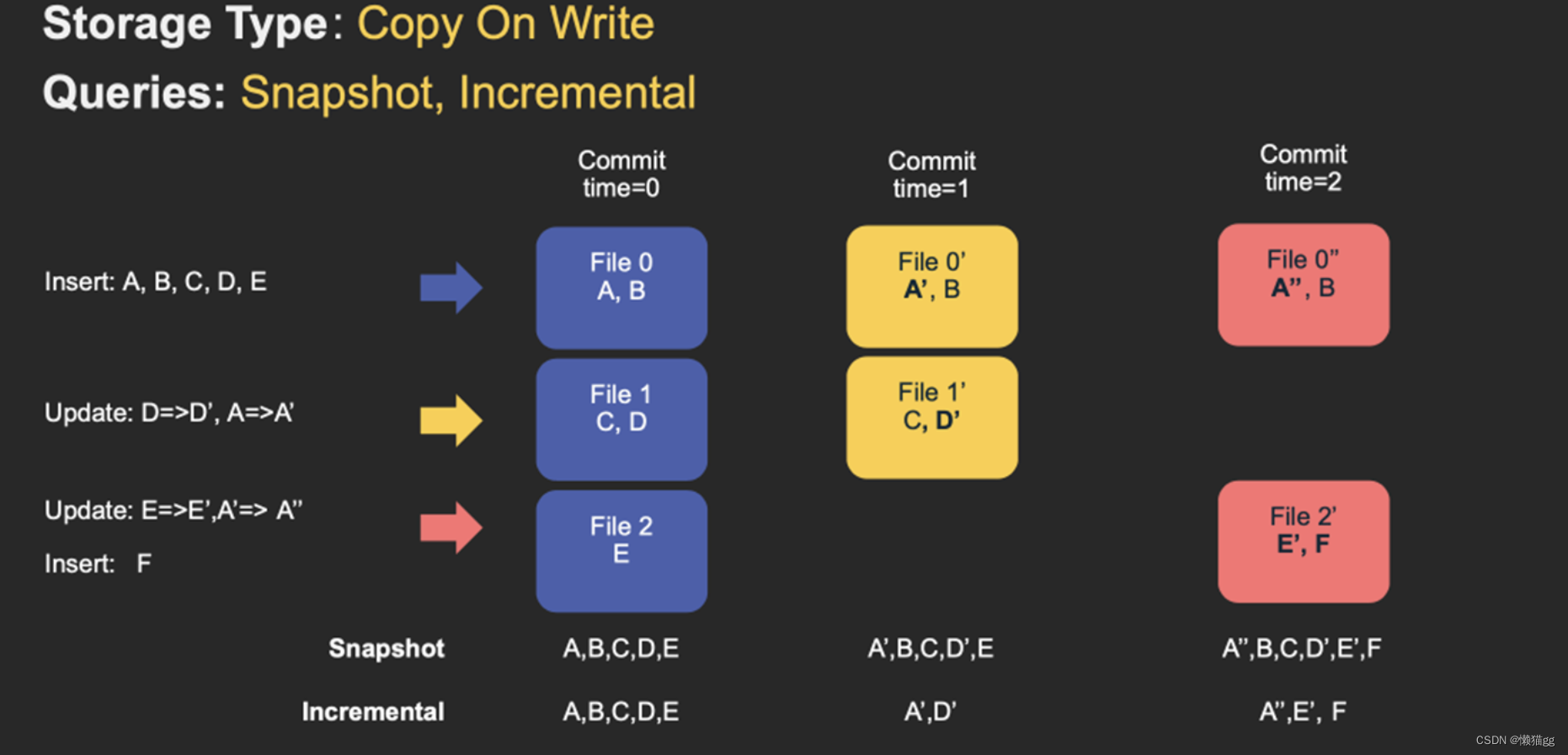
COW 테이블은 데이터를 저장하기 위해 주로 컬럼형 파일 형식(Parquet)을 사용하며, 데이터를 쓰는 과정에서 RDBMS의 B-Tree 업데이트와 유사하게 동기 병합을 수행하고 데이터 버전을 업데이트하며 데이터 파일을 다시 작성합니다.
- 업데이트 업데이트: 기록을 업데이트할 때 Hudi는 먼저 업데이트된 데이터가 포함된 파일을 찾은 다음 업데이트된 값(최신 데이터)으로 파일을 다시 작성하고 다른 기록이 포함된 파일은 변경되지 않은 상태로 유지됩니다. 갑자기 많은 수의 쓰기 작업이 발생하면 많은 수의 파일을 다시 작성하게 되어 엄청난 I/O 오버헤드가 발생합니다.
- 읽기 읽기: 데이터를 읽을 때 최신 데이터 파일을 읽어 최신 업데이트를 받습니다. 이 저장 유형은 적은 양의 쓰기와 많은 읽기 시나리오에 적합합니다.
읽기 시 병합
MOR이라고 하며 새로 삽입된 데이터는 델타 로그에 저장되고, 델타 로그는 주기적으로 Parquet 데이터 파일에 병합됩니다.
데이터를 읽을 때 델타 로그는 이전 데이터 파일과 병합되고 전체 데이터가 반환됩니다. 아래 그림은 MOR의 두 가지 데이터 읽기 및 쓰기 방법을 보여줍니다.
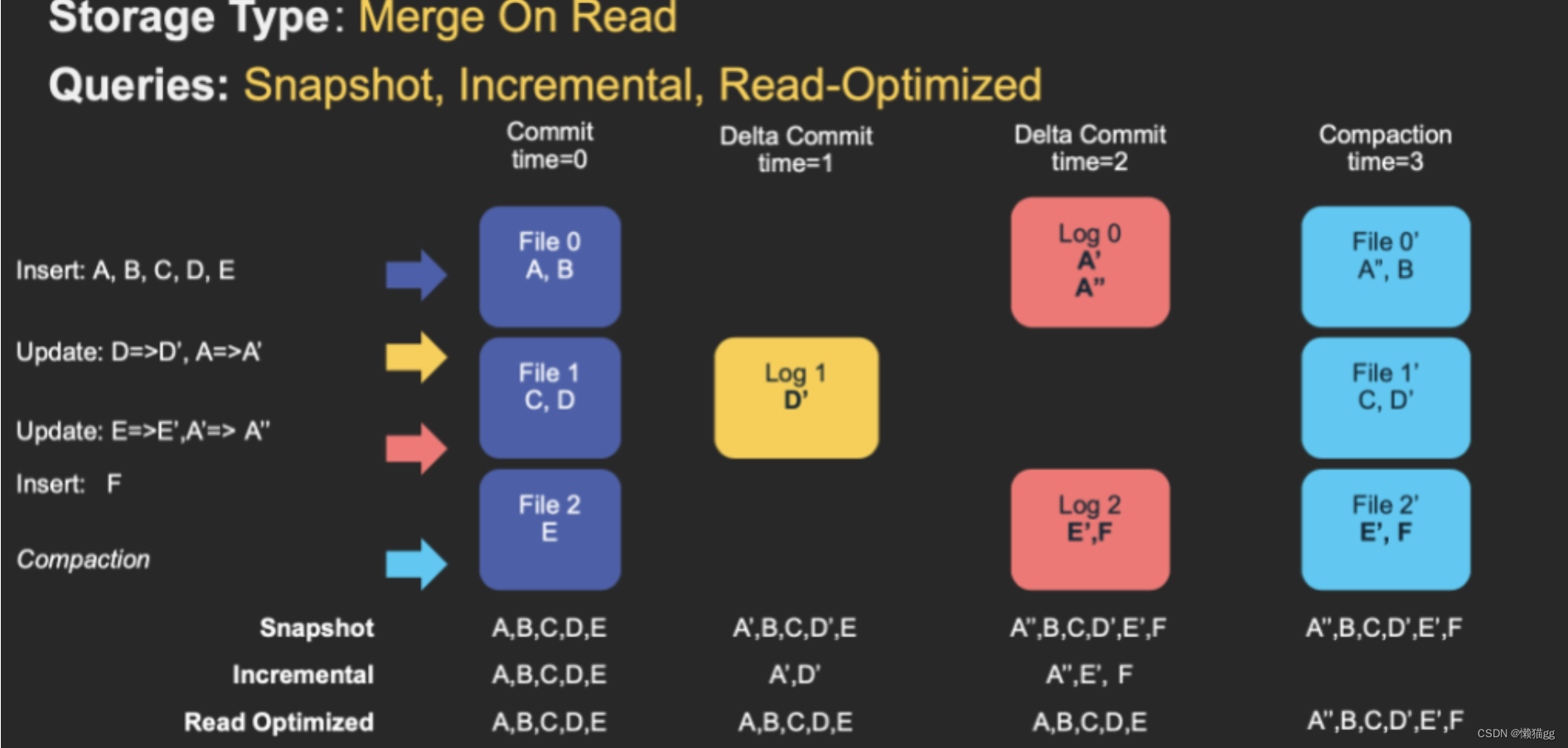
MOR 테이블은 COW 테이블의 업그레이드 버전으로, 열 형식(parquet) 파일과 행(avro) 파일을 혼합하여 데이터를 저장합니다. 레코드를 업데이트할 때 NoSQL의 LSM-Tree 업데이트와 유사합니다.
- 업데이트: 레코드를 업데이트할 때 증분 파일(Avro)만 업데이트한 다음 비동기(또는 동기) 압축을 수행하고 마지막으로 열 형식 파일(parquet)의 새 버전을 생성합니다. 이 스토리지 유형은 새 레코드가 추가 모드에서 증분 파일에 기록되므로 쓰기가 자주 발생하는 워크로드에 적합합니다.
- 읽기: 데이터 세트를 읽을 때 먼저 증분 파일을 이전 파일과 병합한 다음 컬럼 파일이 성공적으로 생성된 후 쿼리해야 합니다.
READ OPTIMIZED 모드에서는 가장 최근의 압축된 커밋만 읽습니다.
문의
Hudi는 테이블을 쿼리하는 세 가지 방법을 지원합니다.
- 스냅샷 쿼리(스냅샷 쿼리):
최신 기본 파일(parquet)과 증분 파일(Avro)을 동적으로 병합하여 거의 실시간 데이터 세트 제공- Copy On Write 테이블은 쪽모이 세공 파일을 읽습니다.
- 읽기 시 병합은 쪽모이 세공 + 로그 파일을 읽습니다.
- 증분 쿼리(incremental query)는
데이터 세트에 새로 작성된 파일만 쿼리하며, 이 조건 이후에 새 데이터를 쿼리하려면 Commit/Compaction 순간 시간(타임라인의 순간)을 조건으로 지정해야 합니다. - 최적화된 쿼리 읽기는
실제로 열 형식 파일(Parquet)인 기본 파일(데이터세트의 최신 스냅샷)을 직접 쿼리합니다.
주요 참고자료
" 데이터 레이크 기술 아키텍처 진화 "
" 데이터 레이크 시리즈 기사 "
" Hudi 공식 문서 "