Tabla de contenido
Conceptos y operaciones básicos:
Método y principio de implementación.
Escenarios de aplicación y precauciones de uso
Análisis de algoritmos y complejidad:
Comparación con otras estructuras de datos:
PD: Si hay algún error u omisión, corríjame.
Conceptos y operaciones básicos:
La tabla de secuencia es una estructura de datos lineal común, que generalmente consta de unidades de almacenamiento continuas y se puede acceder a cualquier elemento de ella de forma aleatoria. Una tabla secuencial es una estructura de datos implementada por una matriz, en la que los elementos se almacenan consecutivamente en la memoria y cada elemento ocupa un espacio de tamaño fijo. La tabla secuencial tiene la ventaja del acceso aleatorio y puede atravesar, buscar, modificar y otras operaciones de manera más eficiente. Sin embargo, las operaciones de inserción y eliminación consumen mucho tiempo y necesitan mover los siguientes elementos, lo que puede no ser adecuado para escenarios de inserción y eliminación frecuentes.
Las siguientes son operaciones de uso común en tablas de secuencia:
-
Inicializar la tabla de secuencia: Inicializar la tabla de secuencia es crear una tabla de secuencia vacía para almacenar la tabla lineal, el proceso de creación es el siguiente:
| paso | funcionar |
|---|---|
| 1 | Inicializar maxsize al valor real |
| 2 | Solicite un espacio de almacenamiento que pueda almacenar elementos de datos de tamaño máximo para una matriz, y el tipo de elementos de datos depende de la aplicación real |
| 3 | Inicializar longitud a 0 |
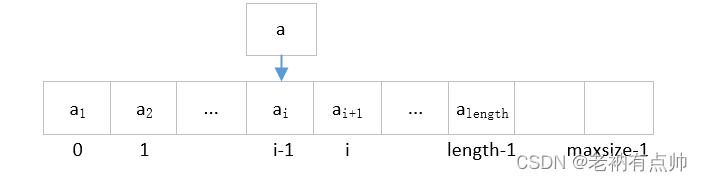
2. Operación de inserción: insertar elementos de datos (aquí solo hablamos de inserción directa) significa asumir que ya hay elementos de datos de longitud (0≤length≤maxsize-1) en la tabla de secuencia, i (1≤i ≤length+1) Inserte un nuevo elemento de datos en la posición del elemento de datos. El proceso de creación se muestra en la siguiente tabla:
| paso | funcionar |
|---|---|
| 1 | Si no se especifica la posición de inserción, el elemento de datos se insertará en la última posición de la tabla de secuencia; si se especifica la posición de inserción i, si la posición de inserción i <1 o pos> longitud +1, no se puede insertar, de lo contrario, se transferirá al paso 2.
|
| 2 | Mueva los elementos de datos de longitud-i+1 desde la posición de almacenamiento de longitud-ésima a la i-ésima en secuencia y coloque el nuevo elemento de datos en la posición i |
| 3 | Suma 1 a la longitud de la tabla de secuencia
|


3. Eliminar operación
Suponiendo que ya hay elementos de datos de longitud (1≤longitud≤maxsize) en la tabla de secuencia, elimine el elemento de datos en la posición especificada. El algoritmo específico es el siguiente:
| paso | funcionar |
|---|---|
| 1 | Si la lista está vacía o no cumple con 1≤i≤length, solicite que se elimine el elemento; de lo contrario, vaya al paso 2
|
| 2 | Mueva los elementos de datos i+1 a longitud (longitud total-i) hacia adelante secuencialmente
|
| 3 | Disminuya la longitud de la tabla de secuencia en 1
|



Otras operaciones relacionadas con la tabla lineal, como buscar elementos de la tabla, ubicar elementos, encontrar la longitud de la tabla y juzgar que está vacía, son relativamente simples de implementar en Shun. Para obtener más detalles, consulte el siguiente código C#:
/// <summary>
/// 顺序表
/// </summary>
/// <typeparam name="T"></typeparam>
public class SeqList<T> : ILinarList<T>
{
private int maxsize;//顺序表的最大容量
private T[] data;///数组,用于存储顺序表中的数据元素
private int length;//顺序表的实际长度
/// <summary>
/// 实际长度属性
/// </summary>
public int Length
{
get
{
return length;
}
}
/// <summary>
/// 最大容量属性
/// </summary>
public int Maxsize
{
get
{
return maxsize;
}
set
{
maxsize = value;
}
}
/// <summary>
/// 初始化线性表
/// </summary>
/// <param name="size">设置的顺序表的最大容量</param>
public SeqList(int size)
{
maxsize = size;
data = new T[maxsize];
length = 0;
}
/// <summary>
/// 在顺序表的末尾追加数据元素
/// </summary>
/// <param name="value"></param>
public void InsertNode(T value)
{
if (IsFull())
{
Console.WriteLine("List is tull");
return;
}
data[length] = value;
length++;
}
/// <summary>
/// 在顺序表的第i个数据元素的位置插入一个数据元素
/// </summary>
/// <param name="value"></param>
/// <param name="i"></param>
public void InsertNode(T value, int i)
{
if (IsFull())
{
Console.WriteLine("List is full");
return;
}
if(i<1 || i>length + 1)
{
Console.WriteLine("Position is error!");
return;
}
for (int j = length-1; j >= i-1; j--)
{
data[j + 1] = data[j];
}
data[i - 1] = value;
length++;
}
/// <summary>
/// 删除顺序表的第i个数据元素
/// </summary>
/// <param name="i"></param>
public void DeleteNode(int i)
{
if (IsEmpty())
{
Console.WriteLine("List is empty");
return;
}
if(i<1 || i > length)
{
Console.WriteLine("Position is error!");
return;
}
for (int j = i; j < length; j++)
{
data[j - 1] = data[j];
}
length--;
}
/// <summary>
/// 获取顺序表第i个数据元素
/// </summary>
/// <param name="i"></param>
/// <returns></returns>
public T SearchNode(int i)
{
if(IsEmpty() || i<1 || i > length)
{
Console.WriteLine("List is empty or position is error");
return default(T);
}
return data[i-1];
}
/// <summary>
/// 在顺序表中查找值为value的数据元素
/// </summary>
/// <param name="value">要查找的数据元素</param>
/// <returns></returns>
public T SearchNode(T value)
{
if (IsEmpty())
{
Console.WriteLine("List is empty");
return default(T);
}
for (int i = 0; i < length; i++)
{
if(data[i].Equals(value))
{
return data[i];
}
}
return default(T);
}
/// <summary>
/// 求顺序表的长度
/// </summary>
/// <returns></returns>
public int GetLength()
{
return length;
}
/// <summary>
/// 清空顺序表
/// </summary>
public void Clear()
{
length = 0;
}
/// <summary>
/// 判断顺序表是否为空
/// </summary>
/// <returns></returns>
public bool IsEmpty()
{
if(length == 0)
{
return true;
}
return false;
}
/// <summary>
/// 反转顺序表
/// </summary>
public void ReverseList()
{
if (IsEmpty())
{
Console.WriteLine("List is empty");
return;
}
int left = 0;
int right =length - 1;
while (left < right)
{
T temp = data[left];
data[left] = data[right];
data[right] = temp;
left++;
right--;
}
}
/// <summary>
/// 判断顺序表是否已满
/// </summary>
/// <returns></returns>
public bool IsFull()
{
if(length == maxsize)
{
return true;
}
return false;
}
}Método y principio de implementación.
Una tabla secuencial se compone de un espacio de memoria contiguo en el que cada elemento ocupa el mismo tamaño de espacio. En el uso real, las matrices se pueden utilizar para implementar tablas secuenciales.
Específicamente, en el lenguaje C#, List<T>se puede usar una clase o una matriz ordinaria para implementar la tabla de secuencia. Se introducen los siguientes dos métodos de implementación respectivamente:
-
Clase de uso
List<T>:List<T>una clase es una de las estructuras de datos más utilizadas en C#, encapsula una matriz dinámica y puede realizar operaciones de adición y eliminación de manera eficiente.List<T>La clase proporciona muchos métodos, como Agregar, Insertar, Eliminar, Borrar, etc., que son convenientes para agregar, eliminar, modificar y verificar la lista. En el uso real, puedeList<T>crear una lista vacía llamando al constructor de la clase y agregarle elementos en cualquier momento. -
Utilice matrices ordinarias: una matriz ordinaria es una estructura de datos básica que permite un acceso aleatorio eficiente a cualquier elemento que contenga. En el uso real, puede implementar una tabla secuencial definiendo una matriz estática y luego usar el descriptor de acceso de subíndice ([]) para acceder y modificar elementos. Para admitir la adición y eliminación dinámica de elementos, es necesario expandir la matriz cuando esté llena y, al mismo tiempo, utilizar técnicas de inserción y eliminación para garantizar la continuidad y el orden de los elementos.
En resumen, una tabla de secuencia es una estructura de datos común que puede List<T>implementarse mediante una matriz o una clase. Al utilizar la tabla de secuencia, es necesario elegir de acuerdo con los escenarios y requisitos de aplicación específicos, y utilizar las habilidades operativas adecuadas para garantizar la continuidad y el orden de los elementos.
Escenarios de aplicación y precauciones de uso
La tabla de secuencia es una estructura de datos común, que es adecuada para escenarios que requieren acceso aleatorio a elementos y operaciones frecuentes de búsqueda y modificación. Los siguientes son algunos escenarios de aplicación comunes para tablas de secuencia:
-
Matriz: Array es la tabla de secuencia más básica, adecuada para escenarios que requieren acceso aleatorio eficiente a elementos de matriz, como matrices multidimensionales, procesamiento de imágenes, etc.
-
Almacenamiento de base de datos: en una base de datos relacional, los datos de la tabla se pueden almacenar en forma de tabla secuencial, cada fila de datos corresponde a un elemento y se puede acceder a cualquier fila de datos de forma rápida y aleatoria a través de accesores de subíndice. Por ejemplo, en MySQL, cada tabla corresponde a un archivo físico, en el que los datos se almacenan y gestionan en forma de tablas secuenciales.
-
Desarrollo de interfaz gráfica: en el desarrollo de interfaz gráfica, los controles de UI generalmente se almacenan y representan en forma de tablas secuenciales, como el control ListBox en Windows Forms o el control ItemsControl en WPF.
Al utilizar tablas de secuencia, debe prestar atención a los siguientes puntos:
-
La longitud de la tabla de secuencia es fija: dado que el espacio de memoria de la tabla de secuencia es continuo, su longitud es fija. Si la cantidad de elementos a almacenar excede la capacidad de la tabla de secuencia, se requiere una operación de expansión.
-
La inserción y eliminación de elementos lleva relativamente tiempo: en una tabla secuencial, insertar y eliminar elementos generalmente requiere mover elementos posteriores, por lo que lleva relativamente tiempo. Si se requieren operaciones frecuentes de inserción y eliminación, se recomienda utilizar una estructura de datos como una lista vinculada.
-
Problema de matriz fuera de límites: cuando se utiliza una matriz para implementar una tabla de secuencia, puede ocurrir un problema de matriz fuera de límites y se debe prestar atención para evitar esta situación.
En conclusión, la tabla secuencial es una estructura de datos común con excelente rendimiento en escenarios que requieren acceso aleatorio y modificación de elementos. En el uso real, es necesario seleccionar una estructura de datos adecuada de acuerdo con las necesidades y escenarios específicos, y prestar atención a sus características y precauciones de uso.
Análisis de algoritmos y complejidad:
Los algoritmos comunes para tablas de secuencia son los siguientes:
-
Insertar un elemento en una posición especificada: mueva todos los elementos en esa posición y después de ella un bit hacia atrás y luego inserte un nuevo elemento en esa posición. La complejidad del tiempo es O (n).
-
Eliminar un elemento en una posición específica: mueva todos los elementos después de la posición hacia adelante uno y luego elimine el último elemento. La complejidad del tiempo es O (n).
-
Buscar elemento: puede encontrar el elemento especificado mediante recorrido secuencial o búsqueda binaria. En una tabla de secuencia desordenada, la complejidad temporal del recorrido secuencial es O (n), mientras que la complejidad temporal de la búsqueda binaria es O (log n); en una tabla de secuencia ordenada, la complejidad temporal del uso de la búsqueda binaria es O (log n ).
-
Clasificación de la lista de secuencias: se pueden utilizar varios algoritmos de clasificación, como clasificación por burbujas, clasificación rápida, clasificación por combinación, etc. Entre ellos, la complejidad temporal promedio de la clasificación rápida y la clasificación por combinación es O (n log n), mientras que la complejidad temporal de la clasificación por burbujas es O (n ^ 2).
La complejidad espacial de la tabla secuencial es O (n), es decir, se requiere espacio para almacenar n elementos. En aplicaciones prácticas, debido a la longitud fija de la matriz subyacente de la tabla de secuencia, pueden ocurrir problemas de desbordamiento y se requieren operaciones de expansión, lo que resulta en una mayor complejidad espacial.
En conclusión, la tabla secuencial es una estructura de datos común con una excelente eficiencia de acceso aleatorio. La complejidad temporal de su operación depende principalmente de operaciones como la inserción, eliminación y búsqueda de elementos. En aplicaciones prácticas, es necesario seleccionar un algoritmo y una estructura de datos adecuados de acuerdo con la situación específica, y hacer concesiones y compromisos.
Comparación con otras estructuras de datos:
Una tabla de secuencia es una estructura de datos común que tiene las siguientes ventajas y desventajas en comparación con otras estructuras de datos:
-
En comparación con la lista vinculada, la lista secuencial tiene una mayor eficiencia de acceso aleatorio y puede acceder a cualquier elemento en tiempo O (1). Sin embargo, los elementos posteriores deben moverse al insertar y eliminar elementos, por lo que es menos eficiente (O (n)).
-
En comparación con las pilas y las colas, las tablas secuenciales pueden almacenar más elementos y admitir métodos de acceso más flexibles. Sin embargo, sus operaciones de inserción y eliminación son relativamente ineficientes (O (n)), lo que las hace inadecuadas para operaciones frecuentes.
-
En comparación con estructuras de datos complejas, como árboles y gráficos, las tablas secuenciales son sencillas de implementar, fáciles de entender y mantener. Sin embargo, es ineficiente cuando se buscan y atraviesan grandes cantidades de datos y no es adecuado para tales escenarios de aplicación.
-
En comparación con la tabla hash, la eficiencia de búsqueda de la tabla secuencial es menor (O (n)) y no admite operaciones rápidas de inserción y eliminación. Sin embargo, es sencillo de implementar y no necesita lidiar con problemas como colisiones de hash.
En resumen, la tabla secuencial es una estructura de datos común con una excelente eficiencia de acceso aleatorio, pero es ineficiente en operaciones como inserción, eliminación y búsqueda, y debe seleccionarse de acuerdo con las necesidades específicas y los escenarios de aplicación al usarla. Cabe señalar que en aplicaciones prácticas, puede haber compensaciones y compromisos entre diferentes estructuras de datos, y la elección debe realizarse de acuerdo con la situación real.