Directorio de artículos
- Historia del desarrollo del marco de aprendizaje profundo.
- Historial de desarrollo del marco TensorFlow
- API principal de red neuronal
- Problemas numéricos preliminares escritos a mano
- La imagen de representación matricial es para estudiar qué valores se colocan en la matriz.
- Gráfico de cálculo, codificación one-hot one-hot preliminar
- Función relu preliminar, distancia euclidiana
- Resumir
- poca practica
Historia del desarrollo del marco de aprendizaje profundo.


la pérdida se puede llamar función objetivo y función de pérdida
TensorFlow tiene tres núcleos: tensorflow.layers (capa), tensorflow.metrics (matriz), tensorflow.losses (función objetivo)
Revisar Descenso de gradiente por tfcontrib
Historial de desarrollo del marco TensorFlow
La versión TensorFlow 1.0 de 2015 obviamente no es tan simple como PyTorch
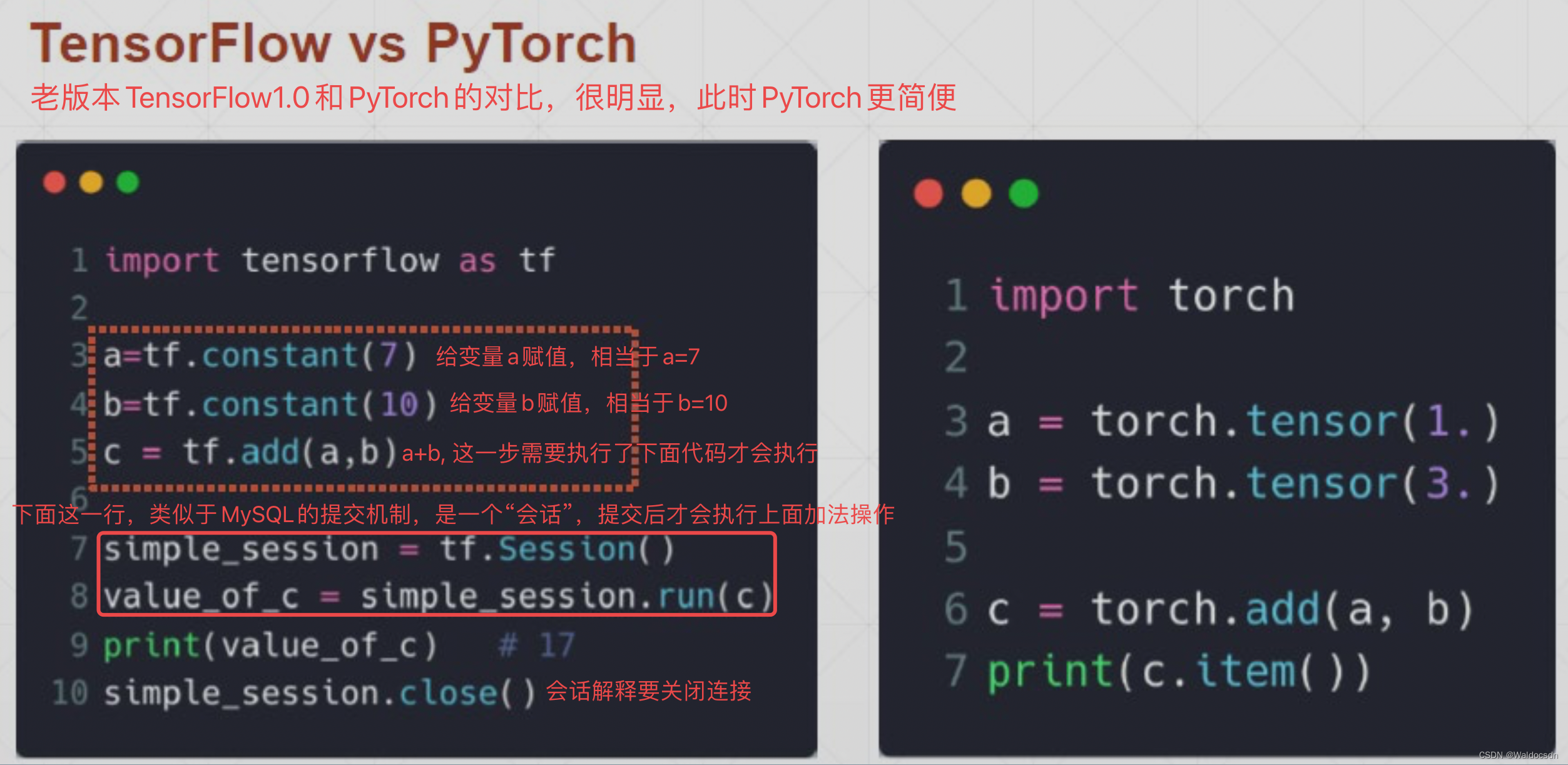
Después de que Google adquirió TensorFlow, fusionó TF + Keras y lanzó TensorFlow 2.0, lo que hace que TensorFlow sea más fácil.


API principal de red neuronal

Problemas numéricos preliminares escritos a mano
Pensamiento: ¿Qué tipo de problema es este? ¿Qué tecnología (método) se utiliza para resolver este problema? ¿Cómo implementar esta tecnología? ¿Cómo se construye la red neuronal en el pensamiento de la computadora? ¿Por qué utilizar una red neuronal de este tipo para simular el pensamiento humano?
introducción
Modelo lineal simple: y = w * x + b. Anteriormente, xay se asignaban entre un solo número y un solo número, lo que significa: y = 2x + 3, cuando x = 1, asignado a y = 5, solo implica un número.
Y cuando la entrada y la salida se vuelven variables, puede convertirse en un mapeo de matriz a matriz, como [0 1 1 2] mapeado a [3 5 5 7]; en otros modelos, la matriz también se puede mapear a un solo número.
映射就是工序,这个要牢记
También es posible adoptar algún tipo de modelo de mapeo, como mapear [arriba, izquierda, abajo, derecha] a [perro, gato, ballena, pájaro].并不是只能数字映射到数字,也可以数字映射到文字,文字映射到数字。只要找到适当的映射,任何万物都可以相连起来。
Según el pensamiento de la oración anterior, al clasificar imágenes, la entrada son imágenes y la salida son palabras en inglés. Necesitamos encontrar una manera de expresar imágenes. La siguiente es la introducción del conjunto de datos MNIST:
Se introduce el conjunto de datos ministeriales para el artículo básico 5 de NLPCV
Introducción al conjunto de datos MNIST
Size:Imágenes digitales manuscritas en escala de grises de 28 × 28,
Num:conjunto de entrenamiento 60 000 y conjunto de prueba 10 000, un total de 70 000 imágenes 0, 1, 2, 3, 4, 5,
Classes:6, 7 , 8, 9
Enlace de descarga oficial: MNIST

Lectura del conjunto de datos
Probado con el laboratorio jupyter. La ruta depende de su computadora para su modificación. No se puede leer el archivo, modifique los parámetros:
download=True.
- Archivo de conjunto de datos MNIST
train-images-idx3-ubyte.gz: Imágenes del conjunto de entrenamiento (9912422 bytes) 55000 conjuntos de entrenamiento + 5000 conjuntos de verificación;train-labels-idx1-ubyte.gz: Etiqueta del conjunto de entrenamiento (28881 bytes) La etiqueta correspondiente al conjunto de entrenamiento;t10k-images-idx3-ubyte.gz: Imágenes del conjunto de prueba (1648877 bytes) 10000 conjuntos de prueba;t10k-labels-idx1-ubyte.gz: Etiqueta del conjunto de prueba (4542 bytes) La etiqueta correspondiente al conjunto de prueba;
- Leer el conjunto de datos MNIST
Si el conjunto de datos no se descarga, modifique los parámetros:download=True
from torchvision import datasets, transforms
train_data = datasets.MNIST(root="./MNIST",
train=True,
transform=transforms.ToTensor(),
download=False)
test_data = datasets.MNIST(root="./MNIST",
train=False,
transform=transforms.ToTensor(),
download=False)
print(train_data)
print(test_data)
resultado de salida:
Dataset MNIST
Number of datapoints: 60000
Root location: ./MNIST
Split: Train
StandardTransform
Transform: ToTensor()
Dataset MNIST
Number of datapoints: 10000
Root location: ./MNIST
Split: Test
StandardTransform
Transform: ToTensor()
Código de lectura completo del conjunto de datos:
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
train_data = datasets.MNIST(root="./MNIST",
train=True,
transform=transforms.ToTensor(),
download=False)
test_data = datasets.MNIST(root="./MNIST",
train=False,
transform=transforms.ToTensor(),
download=False)
train_loader = DataLoader(dataset=train_data,
batch_size=64,
shuffle=True)
test_loader = DataLoader(dataset=test_data,
batch_size=64,
shuffle=True)
Visualización de datos
Tome el conjunto de datos como ejemplo:
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
train_data = datasets.MNIST(root="./MNIST",
train=True,
transform=transforms.ToTensor(),
download=False)
train_loader = DataLoader(dataset=train_data,
batch_size=64,
shuffle=True)
for num, (image, label) in enumerate(train_loader):
image_batch = torchvision.utils.make_grid(image, padding=2)
plt.imshow(np.transpose(image_batch.numpy(), (1, 2, 0)), vmin=0, vmax=255)
plt.show()
print(label)
producción:
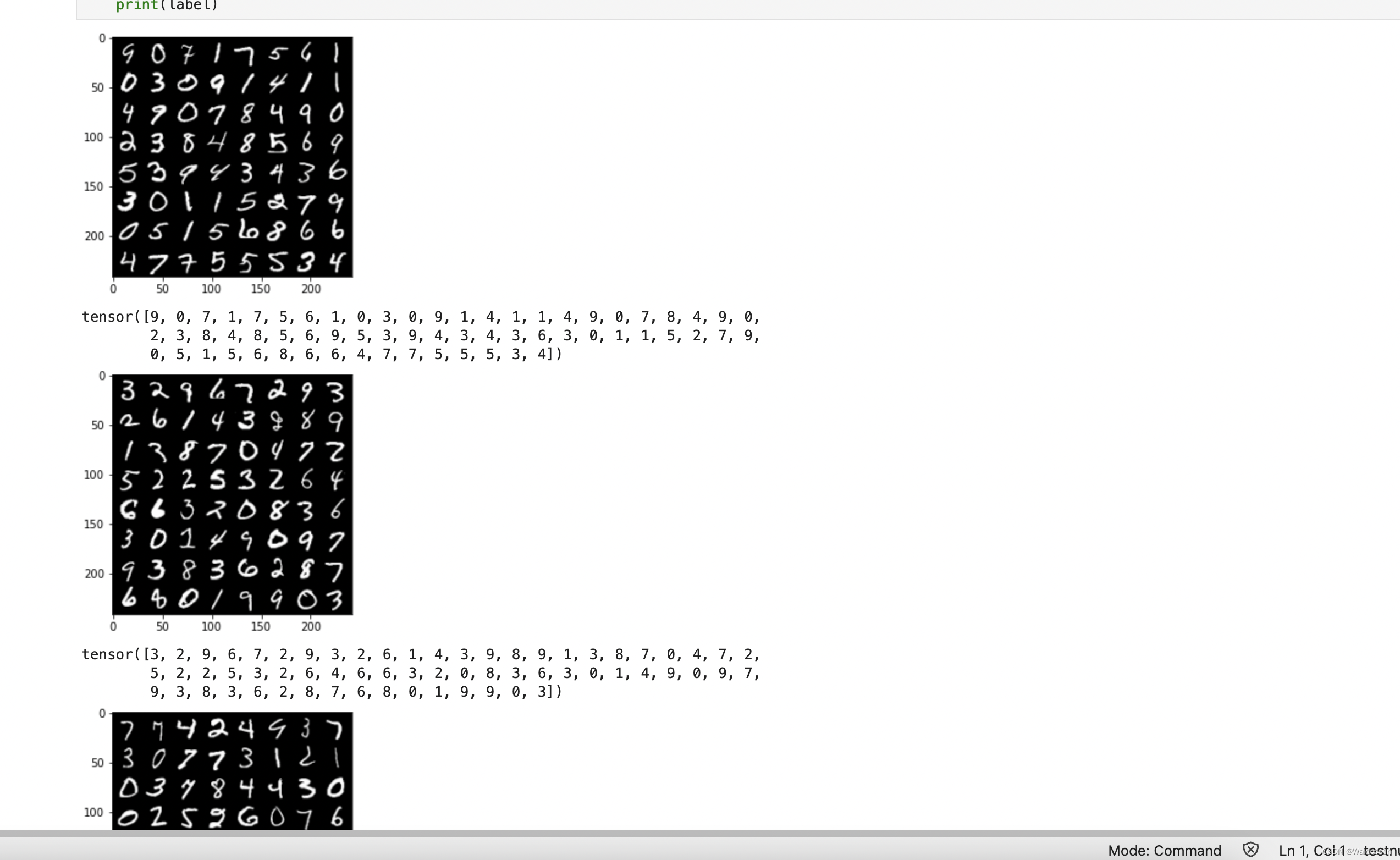
La imagen de representación matricial es para estudiar qué valores se colocan en la matriz.
La inteligencia artificial tiene una dirección llamada aprendizaje de representación, que estudia cómo expresar las cosas en la naturaleza en una forma que las computadoras puedan aceptar.
Para una imagen en formato png, jpg, etc., la computadora no comprende este formato. Las representaciones de imagen comunes son: RGB (triple), valor de gris (cuádruple).
Para la imagen "8" a continuación, utilizamos 28 * 28 * 1 píxeles, y estos píxeles forman una matriz multidimensional para representar esta imagen. En el futuro, nos centraremos en qué valores poner en esta matriz:
La imagen de representación matricial es para estudiar qué valores se colocan en la matriz.
Si existe 通用形式的输入x: [b, 784]. "b" significa "lote", que representa un conjunto de datos y el valor de b es cuántas imágenes hay. Aquí cada imagen está representada por valores "784". Incluso esta entrada x también se puede escribir como [b, 28, 28], [b, 28, 28, 1], donde la entrada [b, 28, 28] significa que cada imagen está representada por una matriz de 28 * 28. En la matriz hay 784 elementos.
Supongamos que el perro está representado por 0, el gato está representado por 1 y el pez está representado por 2;
ingrese [b, 28, 28], después de múltiples procesos (mapeo), obtenga 0 o 1 o 2 y asigne la matriz de alta dimensión. a un solo número, requiere un proceso complejo de varios pasos (mapeo):
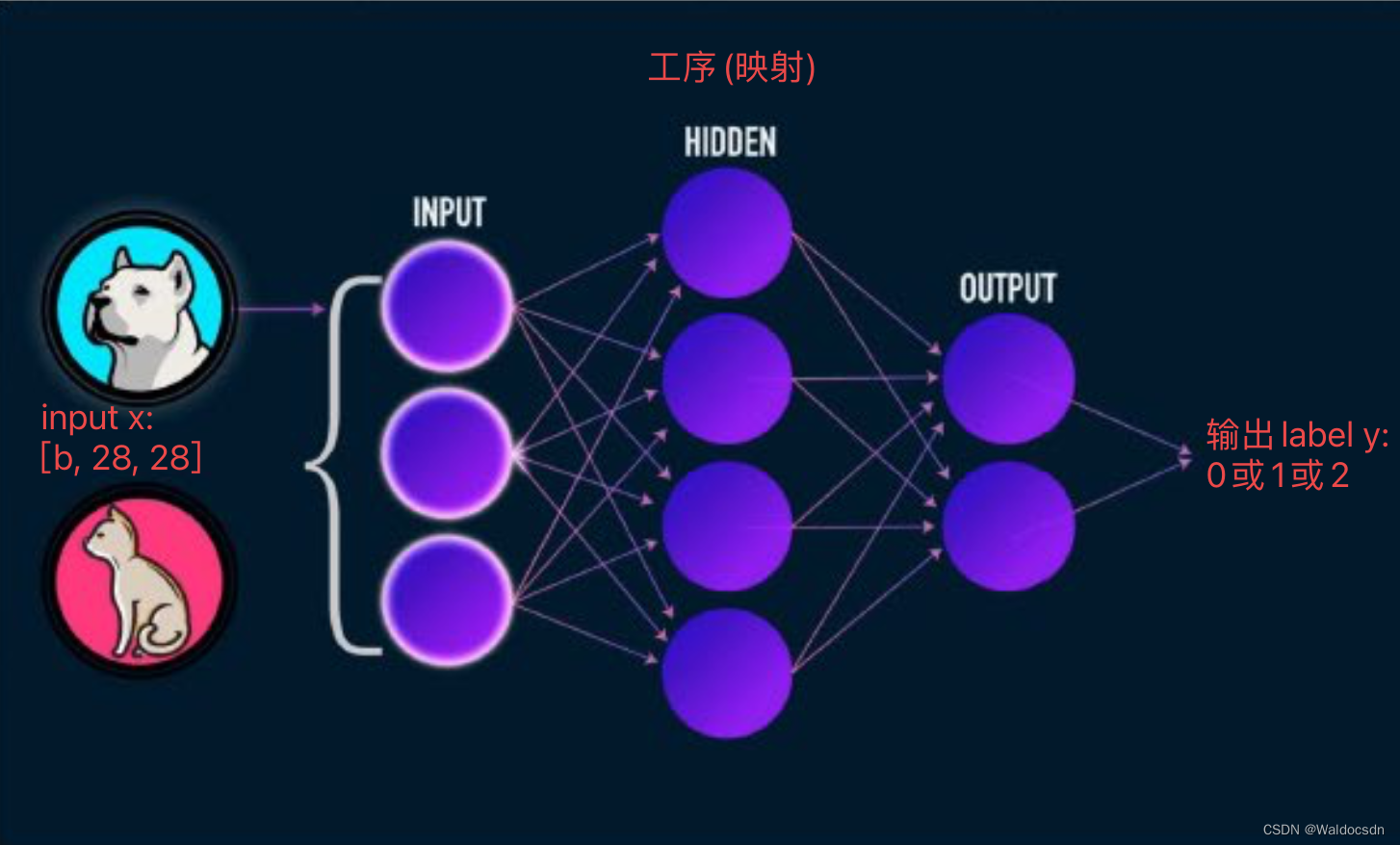
Gráfico de cálculo, codificación one-hot one-hot preliminar
Versión clara del vídeo a continuación: Enlace: https://pan.baidu.com/s/1xwzPn_e_Rcy-e7CMADMwkw?pwd=derx Código de extracción: derx
Artículo básico 5 de CVNLP Gráfico de cálculo
Función relu preliminar, distancia euclidiana
Entonces, ¿cómo conectarse con la red neuronal anterior? Si usa directamente [b, 784] * [784, 10] = [b, 10], solo se necesita un paso para obtener el resultado, que es demasiado simple y violento para abordar problemas complejos. Según la complejidad del problema, elija el modelo adecuado. Se puede dividir en varios pasos para obtener [b, 10], y es mejor usar la función relu para procesar la entrada de cada ronda. Para más detalles, vea el video debajo de la imagen:

Versión clara del vídeo a continuación: Enlace: https://pan.baidu.com/s/1ZMDVBjDBBotBhUer3oenUg?pwd=6a8t Código de extracción: 6a8t
CVNLP artículo básico 5relu función distancia euclidiana preliminar
Error cuadrático medio MSE: error cuadrático medio. Cuando es multidimensional, puede utilizar la "distancia euclidiana" para calcular el valor de pérdida entre "salida" y "etiqueta y".
Resumir

Versión clara del siguiente vídeo: Enlace: https://pan.baidu.com/s/17pdfOT03NVhsiBmuDwVQNQ?pwd=f956 Código de extracción: f956
Proceso de clasificación del artículo 5 básico del CVNLP
poca practica
Hay 100 imágenes, la entrada x es [100, 784] y la etiqueta de salida y es 20 categorías. Escriba el proceso del proceso de tres capas y escriba las dimensiones de cada w, by las dimensiones de salida de cada capa.
