Recientemente, encontré un problema increíble mientras trabajaba en un proyecto.
El código se muestra a continuación:
Mi mapa se convierte de List<Pair<Long, String>>:


Cuando se ejecuta el bucle for, se lanza una excepción:

¿Dime que BigInteger no se puede convertir a Long? Confundido.
Debería ser que la clave de este mapa es BigInteger. Usé Long para recibirlo y necesitaba una conversión de tipo, así que informé un error, así que cambié la redacción para confirmar y ver de qué tipo es la clave:
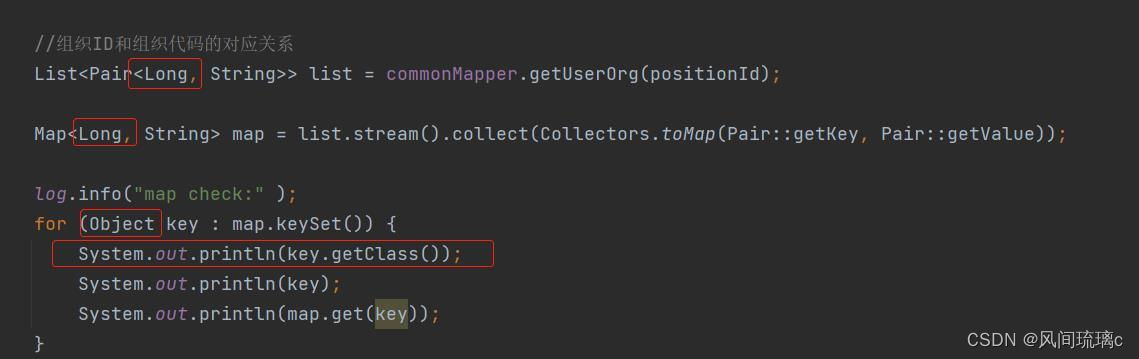

¡Realmente un gran entero!
Lo que quiero hacer aquí es obtener los dos campos en la tabla. Dado que los datos corresponden uno por uno, quiero usar Map para recibirlos directamente, pero Mybatis no admite la conversión directa al mapa que quiero. Tengo que manejarlo yo mismo. Hay alrededor de 3 métodos en Internet:
1. Escriba una anotación para implementarla usted mismo.
2. Escriba un controlador y consígalo.
3. Utilice Pair para recibir, esto parece lo más fácil, así que elegí esta solución.
Mirando la estructura de la tabla de la base de datos, es cierto que ORG_ID es BigInt y no hay ningún problema con recibir Bigint con mucho antes. ¿Por qué se convierte a BigInteger esta vez y no hay ningún error al recibirlo y no informa? un error hasta que se atraviesa?
En mapeador:
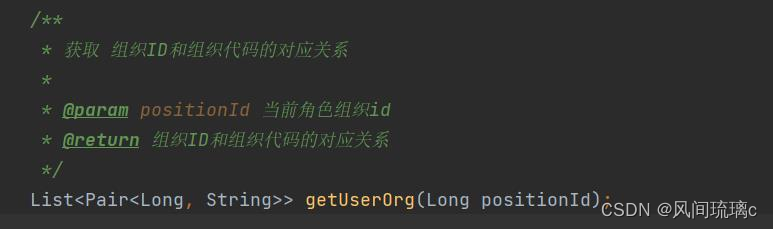
Estructura de la tabla:
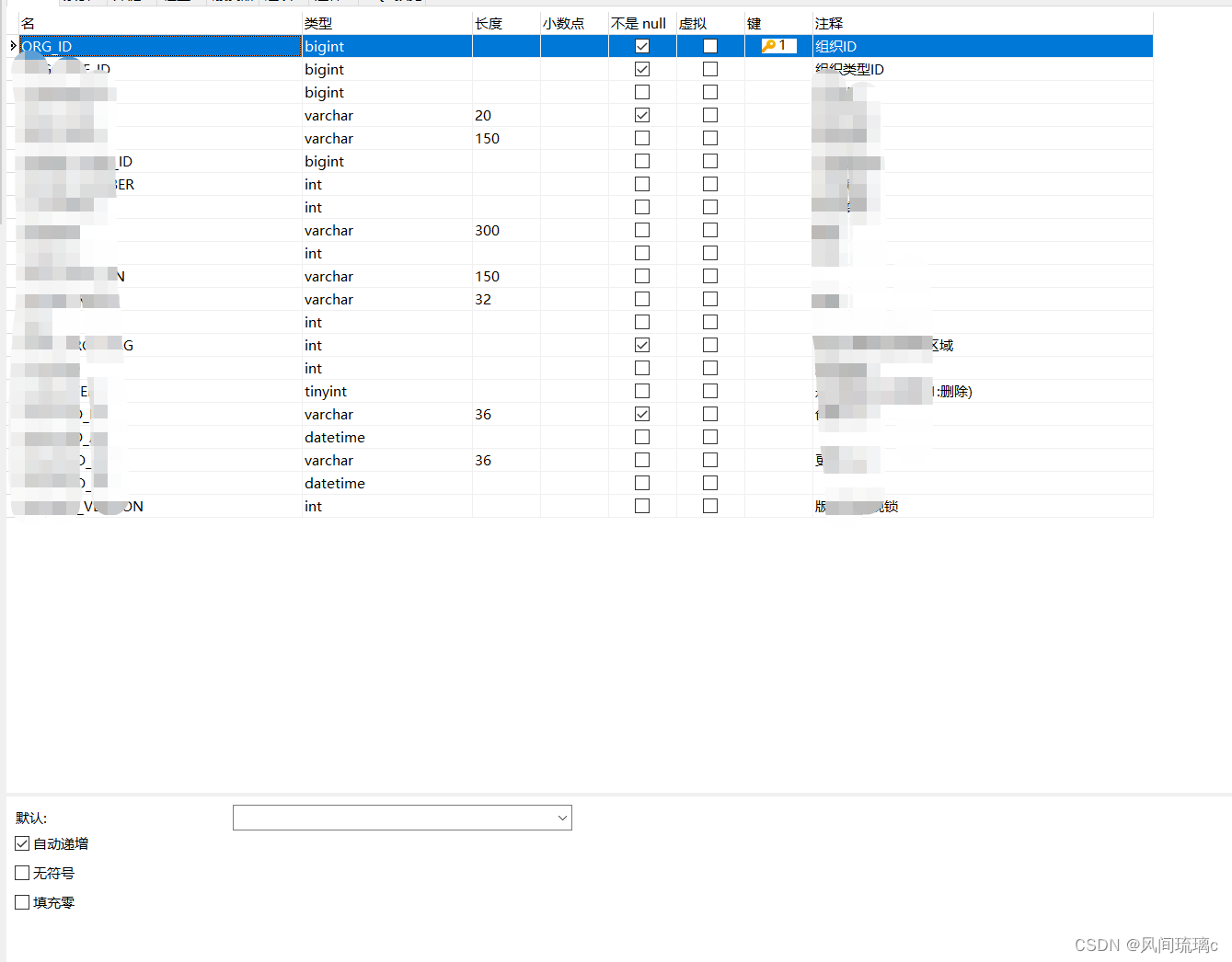
Mapeador.xml
Discutió con colegas y aprendió:

Pero este campo en mi tabla no está definido como sin firmar, ¿por qué se convierte a BigInteger por mí?
Hasta ahora tengo dos dudas muy desconcertantes:
1. ¿Por qué mybatis convierte automáticamente el campo de tipo bigint en mysql a Biginteger cuando unsigned no está definido? Según el documento oficial, bigint debe corresponder a Long, solo cuando se define como sin firmar se convertirá en BigInteger si excede el rango de Long.
2. ¿Por qué Long está definido en Pair para recibir BigInteger pero no se informa ningún error y no se informa ningún error hasta que se atraviesa?
Después de una dura investigación, obtuve el resultado:
1. En la declaración SQL, el ORG_ID de la selección proviene de la tabla O y los otros campos provienen de la tabla T. Cuando verifiqué, verifiqué el campo ORG_ID en la tabla T. Mirando la tabla O nuevamente, es cierto que el campo ORG_ID en la tabla O está definido como sin firmar, por lo que cuando lo recibe, mybatis lo convierte a Biginteger.

2. Pero todavía hay un problema, ¿por qué no hay ningún error al usar Long para recibir BigInteger y no informa un error hasta que se ejecuta en el recorrido del bucle for?
Esto se debe al mecanismo de borrado de tipos de JAVA. Aquí hay una reimpresión de la información que vi:
¿Qué es el borrado de tipos?
Esta es una "característica" exclusiva de Java. En tiempo de ejecución, Java no conserva los tipos genéricos.
Por ejemplo, puedes poner un perro en un grupo de gatos:
LinkedList<Cat> cats = new LinkedList<Cat>(); LinkedList list = cats; // 注意我在这里把范型去掉了,但是list和cats是同一个链表! list.add(new Dog()); // 完全没问题!¿Por qué puedes jugar así? Debido a que el tipo genérico de Java solo existe en el código fuente, verificará estáticamente si el tipo genérico es correcto al compilar, pero no se verificará en tiempo de ejecución. El código anterior no se diferencia del siguiente párrafo en JRE (Java Runtime Environment):
LinkedList cats = new LinkedList(); // 注意:没有范型! LinkedList list = cats; list.add(new Dog());¿Por qué escribir borrado?
Para compatibilidad con versiones anteriores.
Java 5 solo introdujo tipos genéricos, y antes de eso no había tipos genéricos. En ese momento, el tipo genérico se introdujo solo para resolver el problema de la transformación manual forzada al atravesar la colección , como un código como este:
List cats = loadCats(); // 5之前没有范型哦 for (Object obj : cats) { Cat cat = (Cat) obj; // 所以这里总是需要强转 ... }Para mantener la JVM compatible con versiones anteriores, borrar tipos es una mala idea.
Consecuencias del borrado de tipos
El borrado de tipos tiene muchas consecuencias negativas. Aquí hay tres que yo sepa (el nombre es mío, no oficial):
Debido a que no existe un tipo genérico en tiempo de ejecución, muchas implementaciones basadas en reflexión deben proporcionar información de tipo genérico adicional. Por ejemplo, Gson se confundirá al deserializar cadenas JSON a los siguientes tipos de objetos:
public class Foo { private LinkedList<Bar> bars; // 省略 get 和 set 方法 }¿Por qué? ¡Porque Gson no puede obtener el tipo de elementos en las barras mediante la reflexión en tiempo de ejecución! Entonces, en este caso, necesita un código más complicado y contrario a la intuición para resolver el problema.
tipo explosión de número
El segundo problema con el borrado de tipos es la explosión del recuento de tipos. Por ejemplo, ¿por qué la interfaz funcional incorporada de Java 8 tiene Proveedor, Función y BiFunción? Esto se debe a que Java no puede usar la cantidad de tipos genéricos para distinguir tipos, porque los tipos genéricos se borran. C# no tiene borrado de tipos, por lo que puede usarse para
Func<R>representar un tipo,Func<T, R>otro tipoFunc<T1, T2, R>y otro tipo.Discriminación de tipos de datos básicos
Una consecuencia menos obvia de este mecanismo es que se discriminan los tipos de datos básicos.
Dado que los genéricos se borran en tiempo de ejecución, el tiempo de ejecución no puede calcular el tamaño de memoria requerido por el tipo genérico. ¿Cómo hacerlo? El equipo de diseño de Java pensó en otro truco torcido: ¡ el tipo genérico solo puede ser un tipo de referencia! De todos modos, no importa qué tipo de referencia ocupe el mismo tamaño de memoria. No se permite el uso de tipos de datos básicos porque cada uno tiene su propio tamaño.
Resuelva un problema e introduzca uno nuevo: ¿Qué debo hacer si necesito incluir tipos de datos básicos en la colección? ¡Embalar! Entonces, hay clases de empaquetado para varios tipos de datos básicos (por cierto, la clase de empaquetado para long es Long, la clase de empaquetado para double es Double y la clase de empaquetado para int no es Int?), ¿qué más es el empaquetado y desempaquetado automático? • Las “propiedades” de la caja.
Por cierto, el tipo genérico de C# se conservará hasta el tiempo de ejecución, por lo que el tipo genérico de C# puede ser un tipo de valor (similar al tipo de datos básico de Java pero más potente) y no hay necesidad de operaciones de boxeo y unboxing.
Siguiendo quejándonos, la discriminación de tipos de datos básicos también agravará la explosión del número de tipos, porque él y el número de paradigmas no están en la misma dimensión, por lo que los coeficientes de explosión provocados por cada uno deben multiplicarse. Por ejemplo, el Proveedor mencionado anteriormente, si desea devolver un int, no puede usarlo
Supplier<int>(porque el tipo genérico no puede ser un tipo de datos básico), pero debe usarloIntSupplier, y debe usarlo si desea devolver un dobleDoubleSupplier. De manera similar, existenIntFunction,,,, etc., y cada combinación de parámetros y tipos de retorno debe definir una interfaz porDoubleFunctionseparadoLongFunction. Java, eres realmente un desesperado. (Más quejas, la función que devuelve booleano no se llama BooleanFunction, ¡sino Predicate! Según el diseño de orina de la interfaz funcional de Java, BiPredicate, IntPredicate, LongPredicate, DoublePredicate se derivan, realmente borrachos)ToLongFunctionIntToDoubleFunction¡ Conté
java.util.function43 interfaces funcionales en el paquete! Y este no es el final, porque no se cubren todos los tipos de datos básicos, como byte , char y short. Si necesita soporte para estos tipos, lo siento, ¡tendrá que escribir la interfaz funcional usted mismo! ¡E incluso si está escrito, la interfaz de transmisión de Java todavía no lo reconoce!conclusión
El paradigma de Java es como un hijo ilegítimo no deseado: su nacimiento fue solo un resultado rápido y desde entonces no ha sido cuidado por su padre biológico, lo que ha provocado varios problemas sociales posteriores. Se puede decir que las plantillas de C ++ son mejores, sin mencionar el verdadero paradigma de C #. Creo que para que Java pueda lograr grandes avances en las características del lenguaje , es necesario solucionar estos problemas históricos en algún momento, en lugar de insistir ciegamente en la compatibilidad con versiones anteriores sin principios, de lo contrario solo se volverá cada vez más feo.
Autor: Aetherus
Enlace: https://www.zhihu.com/question/452958728/answer/1817841881