Directorio de artículos
ilustrar
Durante la ejecución de un programa Java, la máquina virtual Java divide la memoria que gestiona en varias áreas de datos diferentes. Estas áreas tienen sus propios propósitos, así como el tiempo de creación y destrucción, algunas áreas siempre existen con el inicio del proceso de la máquina virtual, y otras áreas se crean y destruyen dependiendo del inicio y final de los hilos del usuario. Como se muestra en la figura siguiente, este artículo presenta brevemente las funciones de cada área.
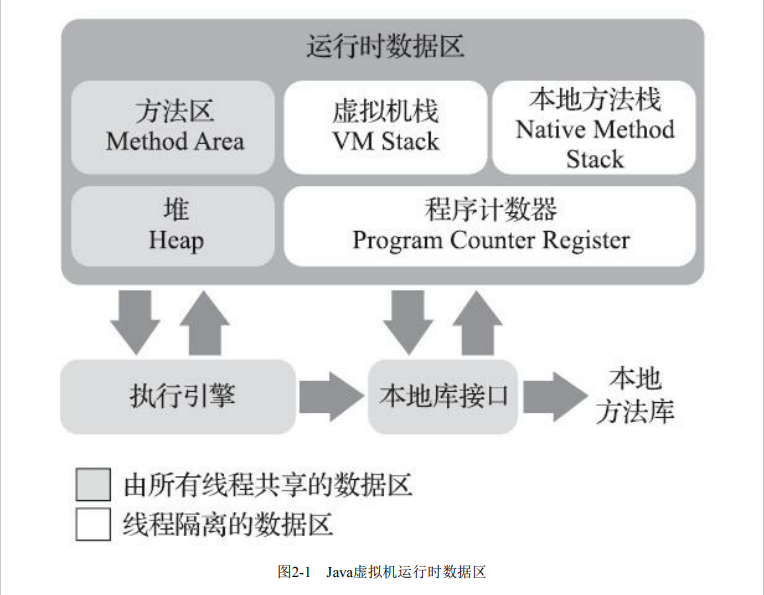
contador de programa
El contador de programa (PC para abreviar) es un área de memoria en la máquina virtual Java (JVM), es un pequeño espacio de memoria que no se ve afectado por el cambio de subprocesos. Cada subproceso tiene su propio contador de programa independiente, que se utiliza para almacenar la dirección de la instrucción de código de bytes ejecutada por el subproceso actual.
El contador de programa tiene las siguientes funciones principales en la JVM:
- Control de subprocesos : El contador del programa indica la dirección de la instrucción que ejecutará cada subproceso. La JVM puede recuperarse hasta el punto de ejecución correcto cuando se cambia el hilo.
- Intérprete de código de bytes : en Java, el código se compila en código de bytes (código de bytes). El contador de programa se utiliza para realizar un seguimiento de las instrucciones de código de bytes que se están ejecutando actualmente, de modo que el intérprete de código de bytes pueda ejecutar las instrucciones una por una.
- Manejo de excepciones : cuando un programa Java genera una excepción, la JVM determinará la ubicación del código de manejo de excepciones en función de la tabla de manejo de excepciones. El contador de programa juega un papel clave aquí, ayudando a la JVM a saber exactamente dónde está el código de procesamiento de bits.
- Thread-private : cada hilo tiene su propio contador de programa independiente. Esto permite que los subprocesos se ejecuten de forma independiente sin verse afectados por otros subprocesos.
En pocas palabras, el contador del programa es la dirección de la siguiente instrucción a ejecutar, cada hilo la tendrá y el hilo es privado.
pila de máquinas virtuales
La pila de máquina virtual (Virtual Machine Stack) es un área de memoria creada de forma privada por la máquina virtual Java (JVM) para cada subproceso y se utiliza para almacenar información como variables locales, pilas de operandos, enlaces dinámicos y salidas de métodos durante la ejecución del método. . Cada método creará un marco de pila (Stack Frame) y lo colocará en la pila cuando se ejecute. Después de ejecutar el método, el marco de pila saldrá de la pila. El marco de la pila contiene información como las variables locales del método, la pila de operandos y la dirección de retorno.
La pila de máquinas virtuales tiene las siguientes características principales:
- Subproceso privado : cada subproceso tiene su propia pila de máquina virtual independiente, lo que garantiza que el estado de ejecución de los métodos en un entorno de subprocesos múltiples no interfiera entre sí.
- Llamada al método : la pila de la máquina virtual se utiliza para guardar el estado de la llamada al método. Cada vez que se llama a un método, se crea un marco de pila en la pila de la máquina virtual, y el marco de pila contiene información como las variables locales del método y la pila de operandos.
- Pila de variables locales y operandos : el marco de la pila contiene una tabla de variables locales y una pila de operandos. La tabla de variables locales se usa para almacenar variables locales en el método, y la pila de operandos se usa para el almacenamiento temporal al ejecutar códigos de operación (instrucciones de código de bytes).
- Manejo de excepciones : la pila de máquinas virtuales también participa en el mecanismo de manejo de excepciones. Cuando ocurre una excepción dentro del método pero no se detecta, la máquina virtual busca en la pila de la máquina virtual para ubicar la ubicación donde ocurrió la excepción, para facilitar el manejo de excepciones.
Cabe señalar que el tamaño de la pila de la máquina virtual se puede configurar y puede ocurrir una excepción de desbordamiento de pila en el espacio de la pila. El desbordamiento de la pila suele deberse a llamadas recursivas demasiado profundas o a que la tabla de variables locales y la pila de operandos ocupan demasiado espacio.
En pocas palabras, cada método corresponde a un marco de pila, y la llamada y ejecución del método representan las operaciones de extracción y apilamiento del marco de pila, y parte de la información necesaria del método se almacena en el marco de pila.
pila de métodos nativos
La pila de métodos nativos (Native Method Stack) es similar a la pila de máquinas virtuales, que es un área de memoria preparada por la máquina virtual Java para ejecutar el método nativo (Native Method). Los métodos nativos se refieren a métodos escritos en lenguajes que no son Java (generalmente C, C ++, etc.), y estos métodos se pueden llamar en programas Java a través de la interfaz nativa de Java (JNI, Java Native Interface).
La pila de métodos nativos es un área de memoria que existe para admitir la interacción entre programas Java y métodos nativos que no son Java, similar a la pila de máquinas virtuales, pero que se utiliza para llamar y ejecutar métodos nativos.
montón de Java
Cuando escribimos programas Java, todas las instancias de objetos (como instancias de clases, matrices, etc.) deben almacenarse en la memoria. El montón de Java es donde se almacenan estos objetos. Es un área de memoria muy grande compartida por todos los subprocesos.
Los puntos clave son los siguientes:
-
Almacenamiento de objetos : cada vez que
newse crea un objeto utilizando la palabra clave, el objeto se asignará en el montón de Java. Ya sea una clase definida por nosotros mismos o una clase integrada en Java, la memoria se asignará en el montón. -
Recolección de basura : el recolector de basura administra el montón de Java. Cuando el programa ya no hace referencia a un objeto, es decir, cuando no hay variables que apunten a él, el recolector de basura recuperará la memoria ocupada por el objeto para asignar espacio para objetos futuros.
-
Estructura generacional : el montón de Java generalmente se divide en diferentes "generaciones", como la nueva generación y la anterior. Los objetos recién creados se asignan a la generación más joven, mientras que los objetos que han vivido más tiempo se trasladan a la generación anterior. Esta estructura generacional ayuda a mejorar la eficiencia de la recolección de basura.
-
Configuración de memoria : podemos establecer el tamaño inicial y el tamaño máximo del montón de Java a través de parámetros de línea de comando. Esto puede ayudarnos a optimizar el uso de memoria del programa.
-
Desbordamiento de memoria : si nuestro programa crea demasiados objetos y excede el espacio disponible del montón, se activará un error de desbordamiento de memoria y el programa fallará.
En resumen, el montón de Java es un área de memoria que se utiliza para almacenar objetos en un programa Java, donde el recolector de basura gestiona la asignación y liberación de objetos para mantener el programa funcionando normalmente.
área del método
El área de método (Área de método) es un área de memoria en la máquina virtual Java, que se utiliza para almacenar información de metadatos, variables estáticas, grupos constantes, códigos de métodos, etc. de la clase. Es compartido por todos los subprocesos y, al igual que el montón, también forma parte de la máquina virtual Java.
Aquí hay algunos puntos clave sobre el área del método:
-
Información de metadatos : el área de método se utiliza principalmente para almacenar la información de metadatos de la clase, incluido el nombre de la clase, modificadores de acceso, información de campo, información de método, etc. La máquina virtual Java utiliza esta información en tiempo de ejecución, como durante la carga de clases, el análisis de códigos de bytes y la invocación de métodos.
-
Variables estáticas : las variables estáticas, también llamadas variables de clase, se almacenan en el área de métodos. Estas variables se crean y asignan durante la carga de la clase y permanecen constantes durante toda la vida de la clase.
-
Grupo constante : el grupo constante es una estructura de datos almacenada en el área de método, que se utiliza para almacenar varios literales y referencias de símbolos generados en el momento de la compilación. Incluye información como constantes de cadena, nombres completos de clases e interfaces, nombres y descriptores de campos y métodos.
-
Código de método : el área de método también almacena el código de método de la clase. Estos códigos se ejecutan cuando se llama a la clase. El código de bytes del método almacenado en el área del método es ejecutado por un intérprete o un compilador justo a tiempo (como el compilador C2 de HotSpot).
-
Grupo de constantes en tiempo de ejecución : en Java 7 y versiones anteriores, el grupo de constantes también incluye algunas constantes generadas en tiempo de ejecución. Pero a partir de Java 8, el grupo de constantes de tiempo de ejecución se ha movido a una parte del montón llamado grupo de constantes de tiempo de ejecución.
-
Desbordamiento de memoria : los errores de desbordamiento de memoria del área de método a menudo se denominan "desbordamiento de generación permanente", porque en Java 7 y versiones anteriores, el área de método se implementó como una generación permanente. A medida que continúa la carga y descarga de clases, el espacio en el área del método también se agotará, lo que provocará que el programa falle.
Cabe señalar que a partir de Java 8, el área de método se reemplaza por Metaspace. Metaspace utiliza memoria local en lugar de memoria de máquina virtual, por lo que es más flexible y evita problemas como el desbordamiento de generación persistente.
En resumen, el área de método es un área de memoria que almacena información como metadatos, variables estáticas, grupos constantes y códigos de método de una clase, y es uno de los componentes importantes de la máquina virtual Java.
grupo constante de tiempo de ejecución
Cuando un archivo de clase Java se carga en la memoria, se crea un grupo de constantes de tiempo de ejecución (Runtime Constant Pool), que es una representación de tiempo de ejecución de las constantes de la clase. El grupo de constantes en tiempo de ejecución contiene parte del contenido extraído del grupo de constantes en tiempo de compilación del archivo de clase, así como las constantes generadas en tiempo de ejecución.
El grupo de constantes en tiempo de compilación se encuentra en el archivo de clase, que contiene varias constantes en la clase, como cadenas, números, nombres de clases, nombres de métodos, etc. El grupo constante de tiempo de ejecución se crea cuando se carga la clase para admitir referencias y operaciones constantes durante la ejecución del programa.
El grupo de constantes en tiempo de ejecución contiene no solo el contenido del grupo de constantes en tiempo de compilación, sino también algunas constantes generadas en tiempo de ejecución. Por ejemplo, los resultados del empalme de cadenas, las llamadas a métodos dinámicos, etc., pueden reflejarse en el grupo constante de tiempo de ejecución.
Cabe señalar que a partir de Java 8, el grupo constante se ha movido al metaespacio (Metaspace), reemplazando la generación permanente anterior. Metaspace tiene más flexibilidad y ya no está limitado por un tamaño fijo. En este caso, el grupo constante de tiempo de ejecución todavía existe, pero se administra de manera diferente al grupo constante.
En resumen, el grupo de constantes en tiempo de ejecución es una estructura de datos construida después de la carga de clases, que contiene parte del grupo de constantes en tiempo de compilación y las constantes generadas en tiempo de ejecución, y proporciona referencia constante y soporte operativo para programas Java.
memoria directa
Cuando usamos memoria en un programa Java, generalmente involucra memoria de montón, memoria de pila, etc. La memoria directa es un método de asignación de memoria diferente de los métodos tradicionales de administración de memoria y se utiliza principalmente para mejorar el rendimiento y la eficiencia de las operaciones de E/S. La memoria directa es un método de asignación de memoria que se utiliza para mejorar el rendimiento de las operaciones de E/S y se utiliza ampliamente en la biblioteca Java NIO. Si bien puede proporcionar algunos beneficios de rendimiento, requiere que los desarrolladores administren ellos mismos la asignación y desasignación para evitar riesgos potenciales.
En el método tradicional de administración de memoria de Java, la asignación y liberación de la memoria del montón de Java son administradas por el mecanismo de recolección de basura de la JVM. Pero en algunos escenarios específicos, especialmente cuando se trata de operaciones de E/S, los métodos tradicionales de administración de memoria pueden causar problemas de rendimiento. En este momento, la memoria directa se puede utilizar como medio para actuar como puente entre el programa Java y el sistema operativo para mejorar el rendimiento y la eficiencia.
La forma tradicional de asignación de memoria dinámica de Java implica los siguientes pasos:
- Copia del programa de aplicación a la memoria del montón de Java : cuando los datos se transfieren desde el programa de aplicación a la memoria del montón de Java, se requiere la copia de datos.
- Copia de la memoria del montón de Java al sistema operativo : al realizar operaciones de E/S, los datos deben copiarse desde la memoria del montón de Java al búfer del kernel del sistema operativo.
- Copiar desde el sistema operativo a la memoria del montón de Java : una vez completada la operación de E/S, los datos deben copiarse desde el búfer del kernel del sistema operativo a la memoria del montón de Java.
Y en el caso de utilizar memoria directa:
- Aplicación a copia de memoria directa : cuando los datos se transfieren desde la aplicación a la memoria directa, no se requiere copia de datos y los datos se almacenan directamente en la memoria directa.
- Copia directa de la memoria al sistema operativo : al realizar operaciones de E/S, los datos se pueden pasar directamente desde la memoria directa al búfer del kernel del sistema operativo, evitando la copia de datos.
- Copiar desde el sistema operativo a la memoria directa : una vez completada la operación de E/S, los datos se pueden pasar directamente desde el búfer del núcleo del sistema operativo a la memoria directa, lo que también evita la copia de datos.
Al realizar operaciones de E/S, los datos se pueden pasar directamente desde la memoria directa al búfer del kernel del sistema operativo, evitando la copia de datos.
3. Copiar desde el sistema operativo a la memoria directa : una vez completada la operación de E/S, los datos se pueden transferir directamente desde el búfer del núcleo del sistema operativo a la memoria directa, lo que también evita la copia de datos.
En resumen, el uso de memoria directa puede reducir la copia de datos entre memorias, mejorando así el rendimiento de las operaciones de E/S. Este método es especialmente adecuado para escenarios que requieren operaciones de E/S frecuentes a gran escala, como lectura y escritura de archivos, transmisión de red, etc. Sin embargo, cabe señalar que la gestión de la memoria directa es responsabilidad del desarrollador y, si no se gestiona correctamente, puede provocar pérdidas de memoria y otros problemas.