
Modo autónomo de Redis
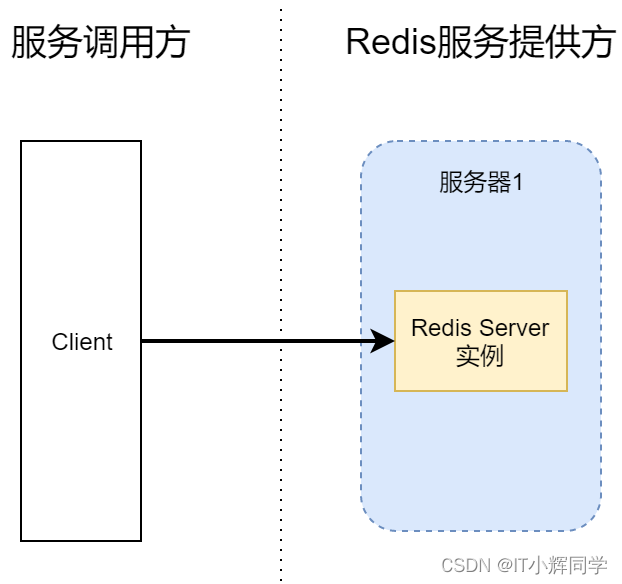
El modo autónomo de Redis hace referencia al modo en el que la base de datos de Redis se ejecuta como un proceso único e independiente en un único servidor. En este modo, Redis no implica fragmentación de datos ni configuración de clústeres, y todos los datos y operaciones se realizan en una sola instancia. La siguiente es una introducción detallada al modo independiente de Redis:
-
Instancia única: en el modo independiente de Redis, solo se ejecuta una instancia de Redis en un servidor. Esta instancia es responsable de manejar todas las solicitudes de almacenamiento y manipulación de datos.
-
Base de datos de memoria: el modo independiente de Redis sigue siendo una base de datos basada en memoria, todos los datos se almacenan en la memoria, por lo que la operación de lectura es muy rápida. Esto hace que el modo independiente de Redis sea adecuado para escenarios de aplicaciones que requieren una lectura de alta velocidad, como los sistemas de almacenamiento en caché.
-
Modelo de subproceso único: el modo independiente de Redis utiliza un modelo de subproceso único para procesar las solicitudes de los clientes. Esto se debe a que la mayoría de las operaciones de Redis son sin bloqueo, y el cuello de botella de rendimiento de Redis generalmente radica en la CPU en lugar de la concurrencia de subprocesos. Este modelo de subproceso único simplifica las operaciones y las estructuras de datos internas, mejorando el rendimiento y la estabilidad.
-
Persistencia: el modo independiente de Redis admite la persistencia de datos, es decir, guardar datos en el disco para recuperarlos después de reiniciar. Hay dos métodos principales de persistencia: RDB (Volcado de base de datos de Redis) y AOF (Archivo de solo adición). RDB guarda la instantánea de la base de datos en el disco y AOF agrega la operación de escritura al archivo para la recuperación de datos.
-
Tipo de datos: el modo independiente de Redis admite una variedad de tipos de datos, como cadenas, tablas hash, listas, conjuntos, conjuntos ordenados, etc. Estos tipos de datos permiten que Redis se use para una variedad de propósitos, como almacenamiento en caché, contadores, tablas de clasificación, análisis en tiempo real y más.
-
Publicar-suscribir: el modo independiente de Redis admite el modo publicar-suscribir, donde un cliente puede publicar mensajes, mientras que otros clientes pueden suscribirse a los canales de mensajes interesados. Esto es muy útil cuando se construyen sistemas de mensajería en tiempo real.
-
Transacción: el modo independiente de Redis admite transacciones, lo que permite que se ejecuten varios comandos en una operación atómica, ya sea que se envíen todos o se reviertan todos.
-
Escenarios de aplicaciones: el modo independiente de Redis es adecuado para aplicaciones a pequeña escala o escenarios que no requieren una disponibilidad de datos particularmente alta. Se puede utilizar como caché, contador, análisis en tiempo real, tabla de clasificación, cola de tareas, etc.
Aunque el modo independiente de Redis tiene ventajas en cuanto a simplicidad y facilidad de uso, pueden producirse cuellos de botella en el rendimiento y la disponibilidad cuando se enfrenta a datos de gran escala y alta simultaneidad.
Redis modo maestro-esclavo
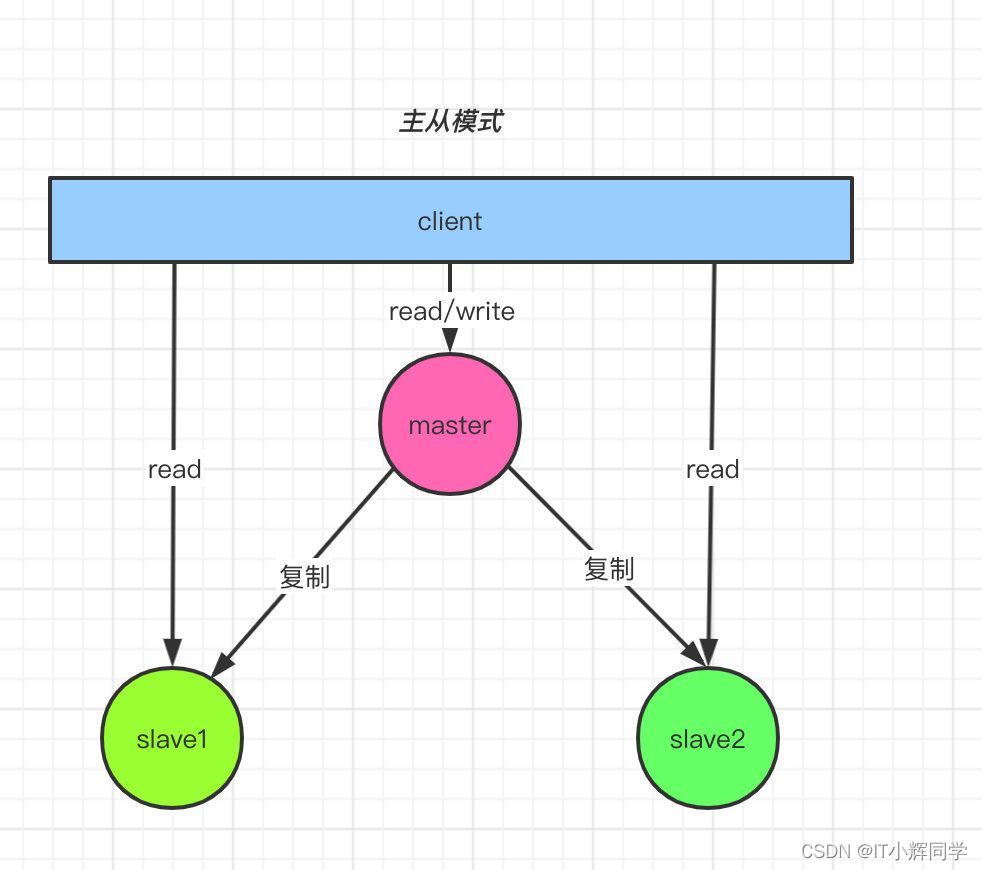
El modo maestro-esclavo de Redis es una arquitectura distribuida que se utiliza para mejorar la disponibilidad, el rendimiento y las capacidades de respaldo de datos de la base de datos de Redis. En el modo maestro-esclavo, hay un nodo maestro (maestro) y uno o más nodos esclavos (esclavos). El nodo maestro es responsable de procesar las operaciones de escritura y algunas operaciones de lectura, mientras que los nodos esclavos son responsables de replicar los datos del nodo maestro y procesar algunas operaciones de lectura.
Las siguientes son las características clave y los principios de funcionamiento del modo maestro-esclavo de Redis:
-
Replicación de datos: el nodo maestro es responsable de las operaciones de escritura y algunas operaciones de lectura, mientras que el nodo esclavo realiza la copia de seguridad de los datos y comparte la lectura mediante la replicación de los datos del nodo maestro. El nodo esclavo obtendrá periódicamente instantáneas de datos (RDB) o registros incrementales (AOF) del nodo maestro para mantener la coherencia de los datos.
-
Separación de lectura y escritura: el nodo maestro es responsable de las operaciones de escritura, mientras que los nodos esclavos son responsables de las operaciones de lectura, por lo que comparten la carga del nodo maestro. Esto mejora el rendimiento general y la capacidad de carga del sistema.
-
Copia de seguridad de datos: al copiar datos en nodos esclavos, el modo maestro-esclavo realiza una copia de seguridad redundante de datos. Cuando el nodo maestro falla, uno de los nodos esclavos se puede actualizar a un nuevo nodo maestro, lo que garantiza la disponibilidad del sistema.
-
Recuperación de fallas: cuando falla el nodo maestro, puede lograr una recuperación de fallas rápida actualizando un nodo esclavo para que sea el nuevo nodo maestro. Este proceso se llama conmutación por error (failover).
-
Fragmentación de datos: mediante el uso de múltiples nodos esclavos, el modo maestro-esclavo también puede lograr la fragmentación de datos, mejorando así la escalabilidad y el rendimiento del sistema.
-
Ajustes de configuración: en el modo maestro-esclavo, el nodo esclavo debe configurar la dirección y el puerto del nodo maestro para la replicación de datos. El nodo maestro no detecta automáticamente la presencia de nodos esclavos.
-
Retraso de datos: dado que el nodo esclavo necesita copiar datos del nodo maestro, puede haber un ligero retraso en los datos del nodo esclavo en relación con el nodo maestro.
El modo maestro-esclavo es adecuado para escenarios que necesitan mejorar la disponibilidad y el rendimiento de la base de datos de Redis, especialmente en aplicaciones que leen más y escriben menos. Sin embargo, el modelo maestro-esclavo no proporciona una garantía absoluta de alta disponibilidad, porque cuando falla el nodo maestro, la conmutación por error puede tardar un tiempo en completarse. Para requisitos distribuidos y de alta disponibilidad de nivel superior, puede considerar usar el clúster de Redis, el modo centinela u otras soluciones de bases de datos distribuidas, ¡que son los modos de los que hablaremos a continuación!
Redis modo centinela
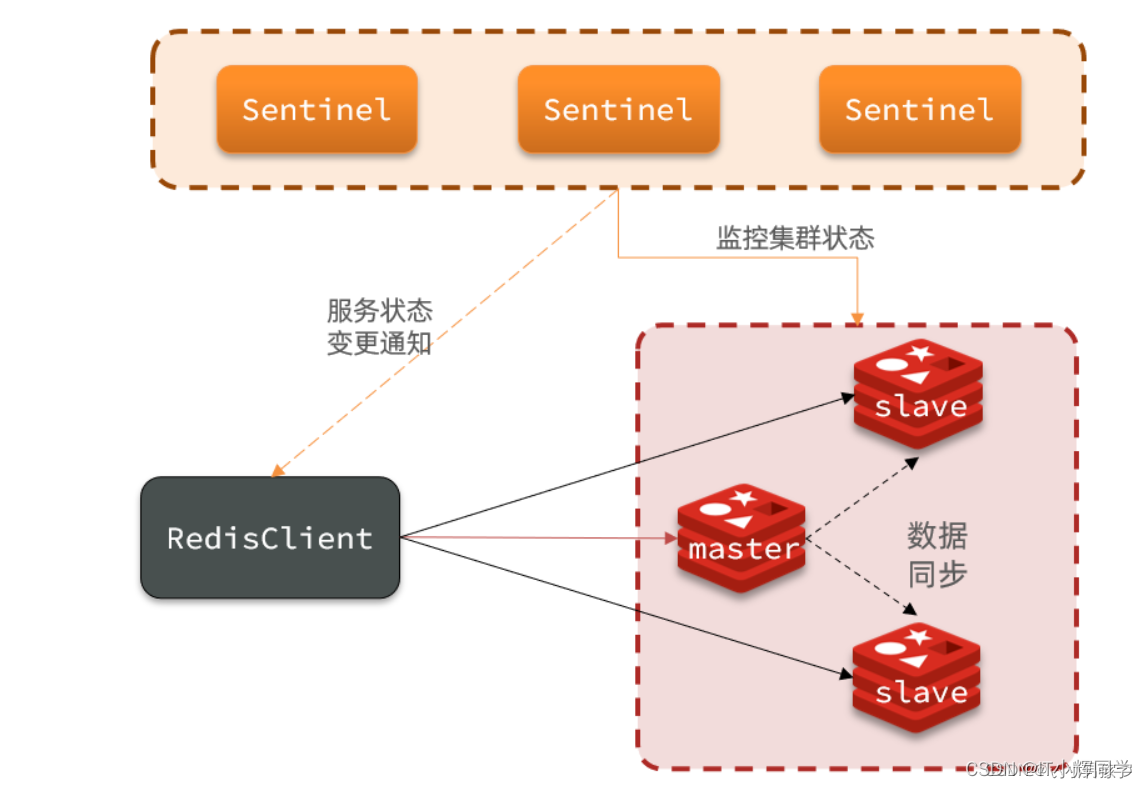
Redis Sentinel es una solución para monitorear y administrar clústeres de Redis, diseñada para proporcionar alta disponibilidad y conmutación por error automática. En el modo centinela de Redis, un grupo de procesos centinela de Redis es responsable de monitorear el estado de los nodos maestros y esclavos de Redis, y realiza la conmutación por error automáticamente cuando falla el nodo maestro.
Las siguientes son las características clave y los principios de funcionamiento del modo centinela de Redis:
-
Supervisar los nodos maestro y esclavo: el proceso centinela de Redis supervisa regularmente el estado de los nodos maestro y esclavo. Determinan el estado del nodo enviando latidos y comprobando la respuesta del servidor Redis.
-
Conmutación por error automática: Sentinel detecta automáticamente cuando falla un nodo maestro de Redis y coordina la promoción de un nodo esclavo disponible como el nuevo nodo maestro para una conmutación por error rápida. Esto reduce el tiempo de inactividad del sistema.
-
Gestión de la configuración: Sentinel de Redis puede monitorear varios nodos maestro-esclavo de Redis. Cuando cambia el estado del nodo, el centinela puede actualizar automáticamente la configuración para garantizar que el cliente se conecte al nodo correcto.
-
Proporcionar detección de servicios: los clientes pueden conectarse a uno o más procesos centinela de Redis sin conectarse directamente a nodos específicos de Redis. Sentry puede proporcionar a los clientes información sobre los nodos maestro y esclavo actualmente disponibles.
-
Modo Multi-Sentinel: se pueden configurar varios Redis Sentinel para redundancia y alta disponibilidad. Estos Centinelas cooperan entre sí para administrar conjuntamente el clúster de Redis.
-
Decisión de votación: durante el proceso de conmutación por error, si varios centinelas creen que un nodo esclavo debe promoverse al nuevo nodo maestro, votarán y llegarán a un consenso para tomar una decisión.
El modo centinela de Redis es adecuado para implementaciones de Redis que requieren alta disponibilidad, especialmente en términos de separación de lectura y escritura y conmutación por error. Puede monitorear y administrar de manera efectiva los clústeres de Redis, lo que reduce el tiempo de inactividad del sistema y mejora la estabilidad de la aplicación.
Sin embargo, debe tenerse en cuenta que el modo centinela de Redis no proporciona una alta disponibilidad absoluta, ya que puede haber breves interrupciones del servicio durante la conmutación por error. Para requisitos de rendimiento y alta disponibilidad de alto nivel, considere usar el clúster de Redis que se tratará a continuación.
Modo de clúster de Redis
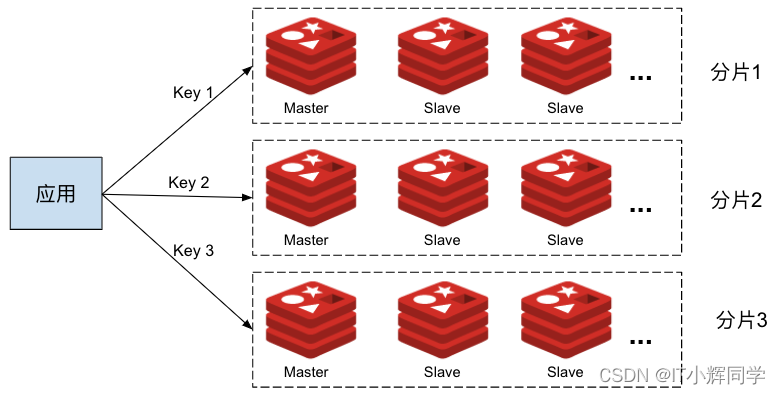
El modo de clúster de Redis es una arquitectura distribuida para combinar varios nodos de Redis en un clúster lógico para proporcionar capacidades de alta disponibilidad, escalabilidad y distribución de datos. En un clúster de Redis, los datos se distribuirán a múltiples nodos, cada nodo es responsable de administrar parte de los datos y también puede realizar automáticamente la conmutación por error y la migración de datos.
Las siguientes son las características clave y los principios de funcionamiento del modo de clúster de Redis:
-
Fragmentación de datos: el clúster de Redis dividirá los datos en múltiples fragmentos de datos, y cada fragmento de datos se almacenará en diferentes nodos. Esto puede distribuir datos de manera efectiva a múltiples nodos, mejorando la escalabilidad y el rendimiento del sistema.
-
Alta disponibilidad: el clúster de Redis está diseñado con alta disponibilidad, cada fragmento de datos tiene varias copias, lo que garantiza que, incluso si falla un nodo, los datos seguirán estando disponibles. El clúster admite la conmutación por error automática, que puede actualizar un nodo esclavo a un nuevo nodo maestro, lo que garantiza la disponibilidad del sistema.
-
Detección de fallas distribuida: el clúster de Redis utiliza varios nodos para la detección de fallas. Cuando un nodo falla, otros nodos pueden detectarlo y coordinar la conmutación por error.
-
Comunicación entre nodos: los nodos del clúster de Redis se comunican a través de un protocolo binario para lograr la sincronización de datos, la detección de fallas y el mantenimiento del estado de los nodos.
-
Migración automática de datos: al agregar o eliminar nodos, el clúster de Redis puede realizar automáticamente la migración de datos para garantizar que los datos se distribuyan uniformemente entre los diferentes nodos.
-
Coherencia de los datos: el clúster de Redis distribuye los datos mediante el uso de ranuras hash para garantizar que los datos con la misma clave se almacenen en el mismo nodo, lo que garantiza la coherencia de los datos.
-
Separación de lectura y escritura: el clúster de Redis admite la separación de lectura y escritura del lado del cliente, es decir, las operaciones de lectura pueden leer datos de cualquier nodo entre varios nodos, mientras que las operaciones de escritura se enviarán al nodo maestro.
-
Expansión de nodos: cuando sea necesario ampliar la capacidad del clúster de Redis, se puede lograr agregando nuevos nodos. El clúster de Redis migrará automáticamente parte de los datos a nuevos nodos para lograr la expansión de la capacidad.
El modo de clúster de Redis es adecuado para escenarios que requieren alta disponibilidad, alto rendimiento y capacidades distribuidas, especialmente cuando se enfrentan a datos a gran escala y muchas solicitudes simultáneas. Puede administrar y distribuir datos de manera efectiva, proporcionando un mayor nivel de disponibilidad y escalabilidad, pero también requiere un trabajo adicional de configuración y administración, especialmente la configuración del clúster, que es un lugar laborioso, cómo asignar recursos, incluso expansión y contracción, lo que implica una arquitectura elástica. , es una tecnología relativamente avanzada. Por supuesto, también hay un método de implementación de Docker, puedes probarlo, ¡es muy divertido e interesante! ! !
La diferencia entre los cuatro modos.
Presentamos el modo independiente, el modo maestro-esclavo, el modo centinela y el modo de clúster de Redis, respectivamente. A continuación, compararé brevemente estos 4 modos para comprender mejor las diferencias entre ellos.
-
Modo independiente:
- Descripción general: el modo independiente de Redis es el modo de implementación más simple, con solo una instancia de Redis ejecutándose en un solo servidor.
- Ventajas: Simple y fácil de usar, adecuado para aplicaciones o entornos de desarrollo a pequeña escala. Se puede utilizar como caché, almacenamiento temporal, etc.
- Desventajas: No tiene alta disponibilidad, y si ocurre un único punto de falla, los datos no estarán disponibles. No es adecuado para aplicaciones de alta concurrencia y a gran escala.
-
Modo maestro-esclavo:
- Descripción general: el modo maestro-esclavo de Redis consta de nodos maestros y nodos esclavos. Los nodos esclavos replican los datos del nodo maestro para mejorar la disponibilidad y la separación de lectura y escritura.
- Ventajas: Proporciona un cierto grado de alta disponibilidad y separación de lectura y escritura. Puede hacer frente a la falla del nodo maestro y realizar una conmutación por error rápida.
- Desventaja: cuando el nodo maestro falla, es necesario actualizar manualmente el nodo esclavo al nuevo nodo maestro y hay una cierta cantidad de tiempo de inactividad. No es adecuado para escenarios de distribución de datos y escritura a gran escala.
-
Modo centinela:
- Descripción general: el modo centinela de Redis supervisa el estado de los nodos maestro y esclavo a través de un grupo de procesos centinela y realiza automáticamente la conmutación por error.
- Ventajas: proporciona alta disponibilidad automatizada con detección automática de fallas en el nodo principal y conmutación por error rápida. Adecuado para escenarios que requieren alta disponibilidad.
- Desventaja: la conmutación por error puede provocar una breve interrupción del servicio. La configuración y la gestión son relativamente complejas.
-
Modo de grupo:
- Descripción general: el modo de clúster de Redis logra fragmentación de datos y alta disponibilidad al agrupar varios nodos.
- Ventajas: Proporciona alta disponibilidad, escalabilidad y capacidades de distribución de datos. Fragmentación automática de datos y conmutación por error, adecuada para escenarios a gran escala y de alta concurrencia.
- Desventajas: la configuración y la gestión son relativamente complicadas y es necesario mantener varios nodos.
En general, los diferentes modos de implementación de Redis son adecuados para diferentes necesidades y escenarios. Si necesita un almacenamiento de datos simple o un entorno de desarrollo y prueba, puede considerar el modo independiente. Si necesita cierta alta disponibilidad y separación de lectura y escritura, puede elegir el modo maestro-esclavo. El modo Sentinel se puede utilizar si se requiere un mayor nivel de alta disponibilidad automatizada y conmutación por error. Y si necesita capacidades de alta disponibilidad, escalabilidad y distribución de datos, puede elegir el modo de clúster. Al elegir un modo, haga concesiones y tome decisiones en función de las necesidades de su aplicación, los requisitos de disponibilidad y los requisitos de rendimiento.
Y en el artículo anterior, debido a que se trata de la implementación del clúster de Docker, publiqué un artículo detallado sobre la implementación del clúster de Redis. ¡Puede leerlo si está interesado!
Docker implementa nodos de clúster de Redis.
De acuerdo con mi breve experiencia en proyectos, aún no he encontrado un sistema a gran escala, por lo que no he usado el modo de clúster. Es una versión independiente, que implementa autenticación de token o datos personales del usuario. almacenamiento. No existe un requisito tan avanzado. Sin embargo, eso no significa que no lo necesite en el futuro. Todos esperan aprender más y practicar más. ¡Las oportunidades siempre están reservadas para aquellos que están preparados!
respectivos escenarios de aplicación
Los diferentes modos de implementación de Redis son adecuados para diferentes escenarios de aplicaciones. Aquí hay sugerencias para diferentes escenarios:
- Modo independiente:
- Escenarios aplicables: entornos de desarrollo y prueba, aplicaciones a pequeña escala, almacenamiento temporal de datos, datos en caché, contadores temporales, etc.
- Modo maestro-esclavo:
- Escenarios aplicables: aplicaciones con más lecturas y menos escrituras, rendimiento de lectura mejorado y copia de seguridad redundante de algunos datos.
- Modo centinela:
- Escenarios aplicables: escenarios que requieren alta disponibilidad automatizada y conmutación por error, y requieren alta disponibilidad de datos.
- Modo de grupo:
- Escenarios aplicables: aplicaciones a gran escala que requieren alta disponibilidad, alto rendimiento y distribución de datos, y escenarios de escritura y lectura a gran escala.
En conjunto, elegir el modelo de implementación de Redis correcto depende de las necesidades y prioridades de su aplicación. Si necesita almacenamiento en caché simple o almacenamiento temporal, puede elegir el modo independiente. Si necesita separación de lectura y escritura y un cierto grado de alta disponibilidad, puede elegir el modo maestro-esclavo. Si tiene requisitos elevados de alta disponibilidad y no desea administrar manualmente la conmutación por error, puede elegir el modo Sentinel. Y si necesita alta disponibilidad, escalabilidad y distribución de datos, puede elegir el modo de clúster. Independientemente del modelo que elija, debe hacer concesiones y decisiones en función de las necesidades reales.
Es el comienzo del otoño, y el verano de 2023 se ha convertido en ayer, bendícenos, bendícenos unos a otros, el cielo es fresco y otoño, ¡todo será un éxito! ¡vamos! ! !