
Directorio de artículos
- 1. Protocolo UDP
- Dos, protocolo TCP
-
- 1. Comprender el encabezado TCP + algunas estrategias TCP
-
- 1.1 Campo de encabezado TCP (problema de paquete adhesivo TCP)
- 1.2 La conexión entre la pila de protocolos de red y el sistema Linux (una tabla hash abierta con el puerto como valor clave, y el cubo hash almacena la dirección de la PCB correspondiente al puerto)
- 1.3 Comprender el encabezado TCP (datos de estructura) desde el nivel de código
- 1.4 Mecanismo de respuesta de acuse de recibo (número de secuencia y número de secuencia de acuse de recibo, características orientadas a bytes de TCP)
- 1.5 Control de flujo (tamaño de ventana de 16 bits)
- 1.6 El tipo de segmento TCP (6 bits de bandera: explique URG y RST en detalle)
- 1.7 Mecanismo de retransmisión de tiempo de espera (si el paquete de datos no recibe una respuesta dentro de la ventana de tiempo de espera, se considerará como pérdida de paquete y se retransmitirá)
- 2. Mecanismo de gestión de conexiones
-
- 2.1 ¿Por qué hay un apretón de manos de tres vías? (Verificación de costo mínimo de comunicación full-duplex + prevención de un ataque de inundación SYN de host único en el servidor)
- 2.2 Cuando las dos partes agitan sus manos cuatro veces, el estado cambia (comprende el estado CLOSE_WAIT, TIME_WAIT)
-
- 2.2.1 El proceso detallado de ondulado cuatro veces
- 2.2.2 Prueba de estado TIME_WAIT
- 2.2.3 ¿Por qué la parte que se desconecta activamente mantiene el estado TIME_WAIT para 2MSL?
- 2.2.4 Resuelva el problema de que el servidor no puede vincular el número de puerto original después de reiniciar inmediatamente
- 3. La eficiencia de TCP
-
- 3.1 Ventana deslizante (enviar segmentos de datos en lotes + mecanismo de retransmisión de tiempo de espera de soporte)
- 3.2 Control de Congestión
-
- 3.2.1 Control de congestión y mecanismo de retransmisión por tiempo de espera (pérdida de paquetes en áreas grandes: control de congestión, pérdida de paquetes en áreas pequeñas: retransmisión por tiempo de espera)
- 3.2.2 Introducción de ventana de congestión, MSS y SMSS
- 3.2.3 Algoritmo de inicio lento + algoritmo para evitar la congestión (crecimiento exponencial antes del umbral, crecimiento lineal después del umbral)
- 3.3 Acuse de recibo retrasado y acuse de recibo superpuesto
- 4. Problemas relacionados con TCP y experimentos relacionados
1. Protocolo UDP
1. Número de puerto
1.
En la comunicación de red, la esencia de la comunicación es que los procesos en dos hosts se comunican en el entorno de red, es decir, la transmisión de datos, y siempre hablamos de la pila de protocolos TCP/IP. Estos dos protocolos resuelven respectivamente dos La cuestión importante es cómo un host certifica su unicidad en el entorno de red y cómo un proceso en un host certifica su unicidad dentro del host. De hecho, es a través de la dirección IP del protocolo de la capa de red y el puerto de la capa de transporte. protocolo No. puerto para resolver estos dos problemas.
2.
Los números de puerto generalmente se pueden dividir en números de puerto conocidos y números de puerto asignados dinámicamente por el sistema operativo. El rango de números de puerto conocidos es de 0 a 1023. Por ejemplo, los números de puerto del proceso se vinculan mediante HTTP, HTTPS , SSH, FTP y otros protocolos de capa de aplicación son Es un número de puerto bien conocido, y sus números de puerto son todos fijos. 1024-65535 es un número de puerto asignado dinámicamente por el sistema operativo. Cuando escribimos el servidor, debemos evitar vincular el número de puerto conocido, porque estos números de puerto han sido utilizados durante mucho tiempo por protocolos maduros de capa de aplicación.
Entonces, cuando escribimos programación de socket antes, ya sea un servidor UDP o un servidor TCP, el número de puerto de enlace es un puerto en el rango de 1024-65535, que no ocupará un número de puerto conocido.
3.
¿Puede un proceso vincular varios números de puerto? Sí, un proceso puede proporcionar múltiples servicios de red de capa de aplicación al mismo tiempo. Por ejemplo, se pueden crear múltiples subprocesos dentro de un proceso, y cada subproceso puede llamar a la interfaz de socket para crear una estructura struct sockaddr_in y luego vincular sockfd y la estructura , de modo que se puedan vincular múltiples números de puerto dentro de un proceso, de modo que un proceso pueda proporcionar múltiples servicios de red de capa de aplicación.
¿Puede un número de puerto estar vinculado por múltiples procesos? Un número de puerto no debe estar vinculado por múltiples procesos, porque el número de puerto debe identificar la unicidad del proceso. Si varios procesos vinculan el mismo número de puerto, cuando el paquete de datos se entrega hacia arriba desde la capa de transporte, el paquete de datos debe ser entregado ¿Para qué proceso? Sabemos que los paquetes de datos se entregan hacia arriba a un proceso específico a través del número de puerto, por lo que un número de puerto no puede estar vinculado a múltiples procesos y el número de puerto debe ser único para el proceso.
4.
A continuación, se presentan dos herramientas, una es la herramienta de línea de comandos netstat para ver el estado de la conexión en la red y la otra es la herramienta de línea de comandos pidof para ver rápidamente la identificación del proceso del servidor.

2. Comprender el encabezado UDP
1.
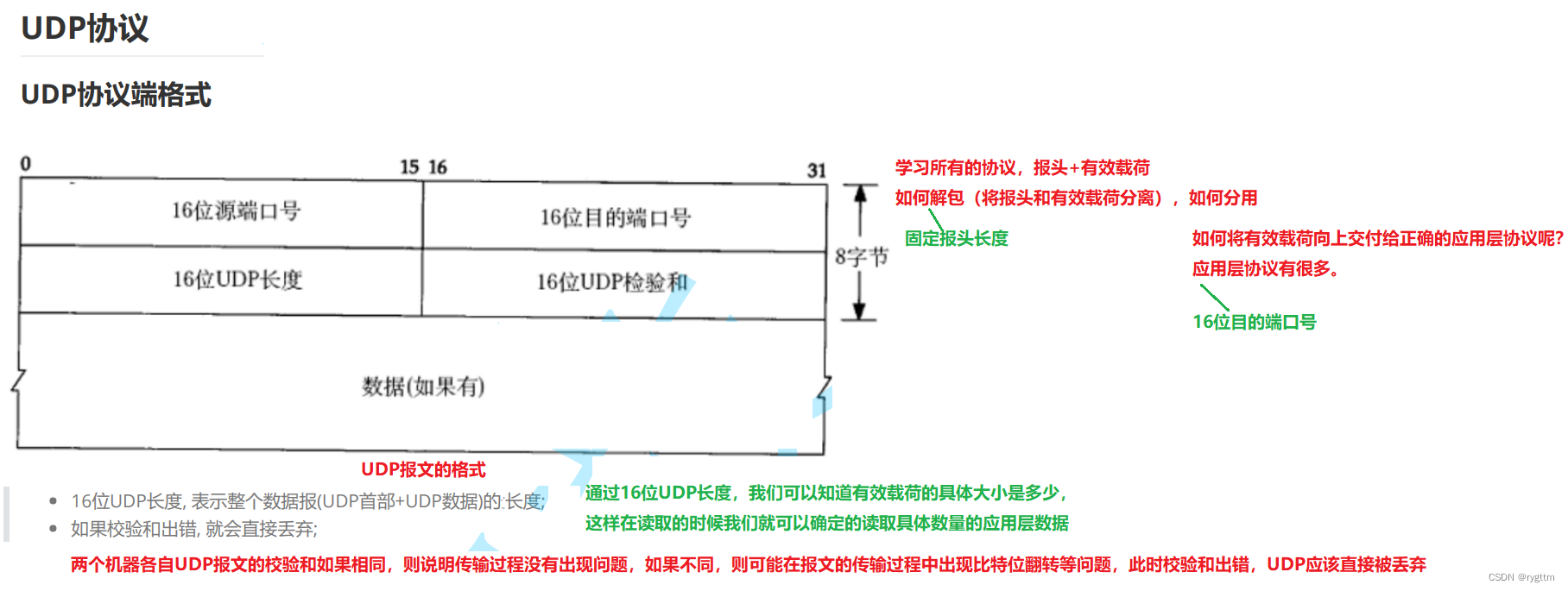
El formato del encabezado del protocolo UDP es el siguiente: debido a que UDP no necesita garantizar la confiabilidad, el contenido del campo del encabezado UDP será relativamente pequeño, por lo que la comunicación UDP es relativamente simple. Independientemente del protocolo que esté aprendiendo, debe poder desempaquetarlo y dividirlo. Como cuando creamos el protocolo de la capa de aplicación nosotros mismos, cuando separamos el encabezado de la capa de aplicación y la carga útil, usamos el delimitador especial \r\n. Encabezado separado y carga útil. En UDP, la carga útil y el encabezado en realidad se separan fijando la longitud del encabezado. Al demultiplexar, los datos pueden enviarse hacia arriba a un proceso de capa de aplicación específico solo a través del número de puerto de destino de 16 bits.
También hay un campo de longitud UDP de 16 bits, que se utiliza para indicar el tamaño total del mensaje. Por lo general, no nos preocupamos por la suma de verificación. Si la suma de verificación es correcta, prueba que el mensaje no se dañó durante la transmisión y el par puede recibir el mensaje normalmente. Si la suma de verificación es incorrecta, como cambios de bit, etc. , Luego, el extremo opuesto descarta directamente el paquete y el paquete se considera un paquete no válido.
2.
No es absolutamente suficiente entender el encabezado UDP en el nivel anterior. Lo anterior es solo desde el nivel lógico. Necesitamos entender el encabezado UDP en el nivel del código para comprender mejor el encabezado UDP.
Tanto la capa de transporte como la capa de red se implementan en el kernel de Linux, y el kernel de Linux se implementa en lenguaje C, por lo que el encabezado UDP es en realidad una estructura y las variables miembro de la estructura son en realidad los valores de los campos. en el encabezado UDP Al usarlo, solo necesita dejar que el puntero apunte a los primeros 8 bytes del paquete de datos, luego fuerce el tipo de puntero en un tipo de estructura y luego lea el valor de la variable miembro dentro para lograr compartir .
En lenguaje C, incluso los datos de estructura son en realidad un flujo de bytes binario. Si queremos unir el encabezado y la carga útil, podemos abrir una gran matriz de caracteres y luego convertir los datos de estructura en un flujo de bytes. El método se copia en el carácter. matriz, y luego la carga útil se copia en él.Cuando desee leer el encabezado UDP para compartir, puede convertir directamente el puntero en un tipo de estructura y luego realizar la selección de miembros para leer el contenido del encabezado UDP.

3. Las características de UDP (orientado a datagramas, dúplex completo)
1.
La característica más típica de UDP está orientada a datagramas. Al crear un socket, el núcleo creará dos búfer de núcleo en la capa de transporte, uno es el búfer de envío y el otro es el búfer de recepción. Cuando UDP envía datos, puede debe entenderse como no usar el búfer de envío, sino entregar directamente el paquete de datos hacia abajo, esto es muy diferente del TCP orientado al flujo de bytes, que usa el búfer de envío para mejorar la eficiencia de envío, como el uso de estrategias como ventanas deslizantes.
Hay límites claros entre los datagramas, por lo que cuando la capa de aplicación lee los datos en el búfer de la capa de transporte UDP, solo es posible leer un mensaje completo o no leer el mensaje en absoluto (el mensaje se pierde). de más de un mensaje, o la mitad de un mensaje, que es diferente del flujo de bytes. En TCP, el búfer de recepción contendrá la carga útil de múltiples paquetes de datos. Estas cargas útiles son leídas por la capa de aplicación en forma de flujo de bytes, por lo tanto, la capa de aplicación puede leer el contenido de más de un mensaje, o leer el contenido de la mitad de un mensaje, porque es un flujo de bytes y el mensaje no tiene un límite claro entre el texto y el mensaje.
Para decirlo de otra manera, la comunicación UDP es como enviar una carta. El remitente envía sobres uno por uno al par. Cuando el par los recibe, recibirá los sobres uno por uno y luego abrirá los sobres para ver el contenido dentro. La comunicación TCP es como escribir todo el contenido de la carta en un papel A4 grande y luego enviar directamente el papel A4 al par. Cuando el par lo recibe, necesita juzgar el contenido en el papel A4 por sí mismo, y dónde es una carta El contenido de la carta, de donde a donde es el contenido de la siguiente carta.

2.
Y a partir de la diferencia entre la API de programación de socket utilizada cuando UDP y TCP se comunican, también podemos ver la diferencia entre los datagramas orientados a UDP y los flujos de bytes orientados a TCP. UDP no tiene conexión, por lo que UDP siempre que envíe datos, necesita para especificar la dirección de socket del par. De manera similar, cada vez que recibe datos, también debe especificar la dirección de socket del remitente para asegurarse de que cada vez que envíe, enviará un datagrama completo a la otra parte. Cuando el otro parte lo recibe, también recibe directamente un datagrama completo, por lo que se llama a sendto varias veces, y recvfrom se llamará varias veces en consecuencia.
Y TCP está conectado. Cuando TCP envía datos, el primer envío copiará los datos de la capa de aplicación en el búfer de envío del socket. Cuando realmente envía, TCP tiene su propia estrategia de envío, porque TCP se llama protocolo de control de transmisión, como política de ventana deslizante, congestión control, etc., por lo que es posible que un datagrama completo no se envíe completamente al par en el búfer de envío del socket, pero se dividirá o ensamblará con otros mensajes antes de enviarse al par, porque esto puede mejorar la eficiencia de la transmisión de datos TCP, que también es una característica de los flujos de bytes. Así que se llama a enviar varias veces y a recv varias veces. No hay una conexión necesaria entre ellos. Puede llamar a enviar 100 veces para enviar 100 bytes de datos, y el par puede llamar a recv para leer 100 bytes de datos a la vez. Este es un flujo de bytes.

3.
Independientemente de si es UDP o TCP, al crear un socket, el kernel creará un búfer de envío y recepción correspondiente, y el búfer es en realidad un poco como la cola circular en el modelo de producción y consumo, que puede desacoplar los dos partes en la comunicación. La capa de aplicación solo necesita Después de copiar los datos en el búfer del socket del kernel, la capa de aplicación puede hacer otras cosas. En cuanto a cuando los datos se envían a través de la pila de protocolos de red, ¿qué debo hacer si los datos se pierden? durante el proceso de envío? Estos problemas los resuelve la capa de transporte, ¡y a la capa de aplicación no le importa en absoluto!
Entonces decimos que el búfer puede realizar el desacoplamiento de las partes de la comunicación. Al mismo tiempo, para TCP, el búfer de envío también puede mejorar la eficiencia de la transmisión de datos TCP. Para UDP, UDP no tiene un búfer de envío real. Pero en De hecho, existe, pero este búfer es inútil.Después de que el kernel recibe los datos, encapsulará directamente el encabezado y entregará los datos a la capa de red para su procesamiento posterior.

4.
Ya sea UDP o TCP, todos son full-duplex, porque ambas partes tienen un conjunto de búferes de envío y recepción, lo que hace posible que el cliente envíe datos al servidor y que el servidor envíe datos al servidor. cliente en un momento dado, lo que mejora en gran medida la eficiencia de la comunicación en la red. El búfer es como un supermercado, la capa de aplicación del cliente es como un productor y la capa de aplicación del servidor es como un consumidor. Este es un modelo típico de producción y consumo, que soporta el ajetreo desigual y desacopla las partes de comunicación.
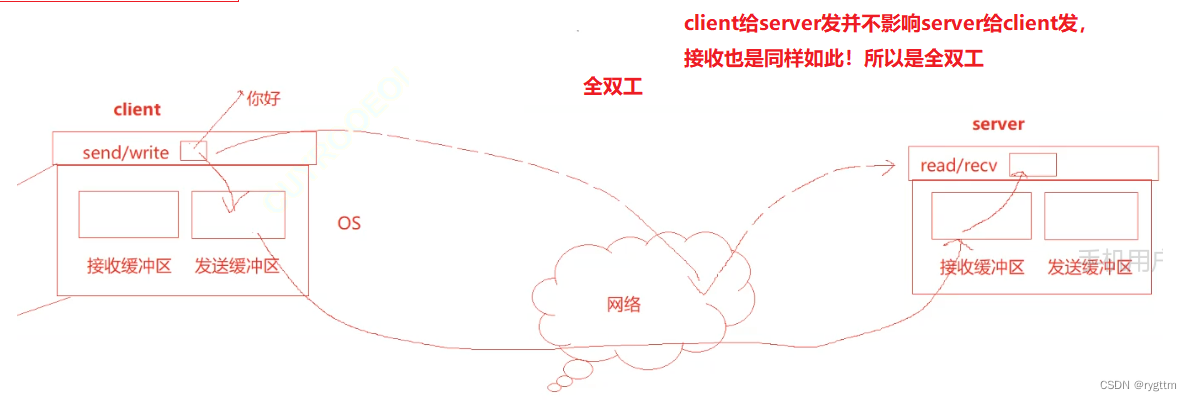
5.
Otro punto que debe explicarse es que todas las interfaces de llamada al sistema a nivel de red que hemos aprendido no son interfaces para enviar y recibir datos de red, ¡sino interfaces de copia! Por ejemplo, cuando llama a enviar enviar a escribir, en realidad copia los datos del búfer que definió en la capa de la aplicación al búfer de recepción en el kernel. Los datos en el búfer se extraen y luego se agrega el encabezado y se envía al capa de red. De manera similar, cuando llama a recv recvfrom read, los datos en realidad se copian del búfer del núcleo al búfer de la capa de aplicación. La capa de aplicación El búfer es en realidad el búfer de caracteres que definimos, por lo que decimos que la interfaz de E/S de red es en realidad la interfaz de copia de red.
Vale la pena señalar que lo que se almacena en el búfer del socket del kernel es la carga útil de la capa de transporte, que no contiene el encabezado UDP ni el encabezado TCP.
6.
Hay un valor de campo de longitud UDP de 16 bits en el encabezado UDP, por lo que la longitud máxima de un mensaje UDP es 2^16, que es de 65536 bytes. Si la longitud del mensaje de la capa de aplicación excede 65536-20, la aplicación La capa necesita dividir manualmente los paquetes en varios paquetes para la transmisión de datos de red, y el extremo receptor debe ensamblar manualmente los datos después de recibirlos.
En realidad, el método es muy simple, porque UDP está orientado a datagramas y el tamaño en bytes de la carga útil se puede obtener fácilmente en la capa de transporte a través del valor de campo de la longitud UDP de 16 bits, por lo que la capa de aplicación en el extremo de envío puede estar en el mensaje dividido Agregue un número de serie, por ejemplo, agregue un número de serie al primer byte de la carga útil de la capa de aplicación, y luego entregue los paquetes divididos hacia abajo.Al recibir, el extremo receptor obtendrá la carga útil del transporte capa En la capa de aplicación, después de leer el encabezado de la capa de aplicación, al leer la carga útil, determine el número de serie del mensaje y vuelva a ensamblarlo de acuerdo con el número de serie.
(En realidad, lo que dije todavía es un poco problemático. Podemos poner el número de secuencia del mensaje de la capa de aplicación directamente en el encabezado de la capa de aplicación. Cuando el compañero lee, siempre que se lea el encabezado de la capa de aplicación, puede saber la secuencia número del mensaje actual. Sí.)
A partir de la longitud UDP de 16 bits en el encabezado UDP, podemos obtener el tamaño de la carga útil, y también podemos encontrar las pistas de que UDP está orientado a datagramas. problema en UDP? Debido a que el receptor está en su propia capa de transporte, el tamaño de la carga útil se puede obtener a través del encabezado UDP y se puede determinar el tamaño de la carga útil de cada mensaje, por lo que el receptor puede leer con precisión solo uno al leer. no hay problema con los paquetes pegajosos (los mensajes de la capa de aplicación múltiple están en el búfer del kernel y no hay límite entre ellos. Cuando la capa de referencia lee, no sabe si los datos leídos actualmente son un paquete de datos o varios paquetes de datos. pegado juntos).

Dos, protocolo TCP
1. Comprender el encabezado TCP + algunas estrategias TCP
1.1 Campo de encabezado TCP (problema de paquete adhesivo TCP)
1.
El nombre completo de TCP es protocolo de control de transmisión.Protocolo de control de transmisión, como su nombre indica, TCP tiene un control detallado sobre la transmisión de datos.No solo puede garantizar su deslumbrante confiabilidad a través de varias estrategias, sino también garantizar su alta eficiencia a través de otras estrategias. sexo
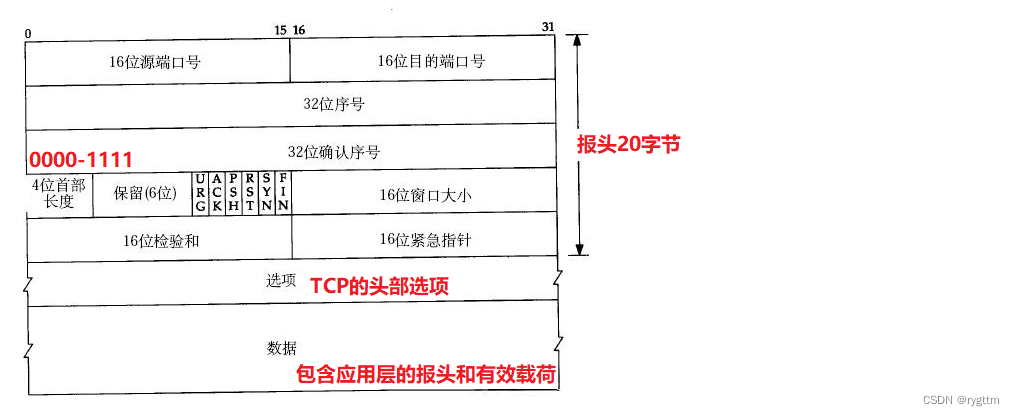
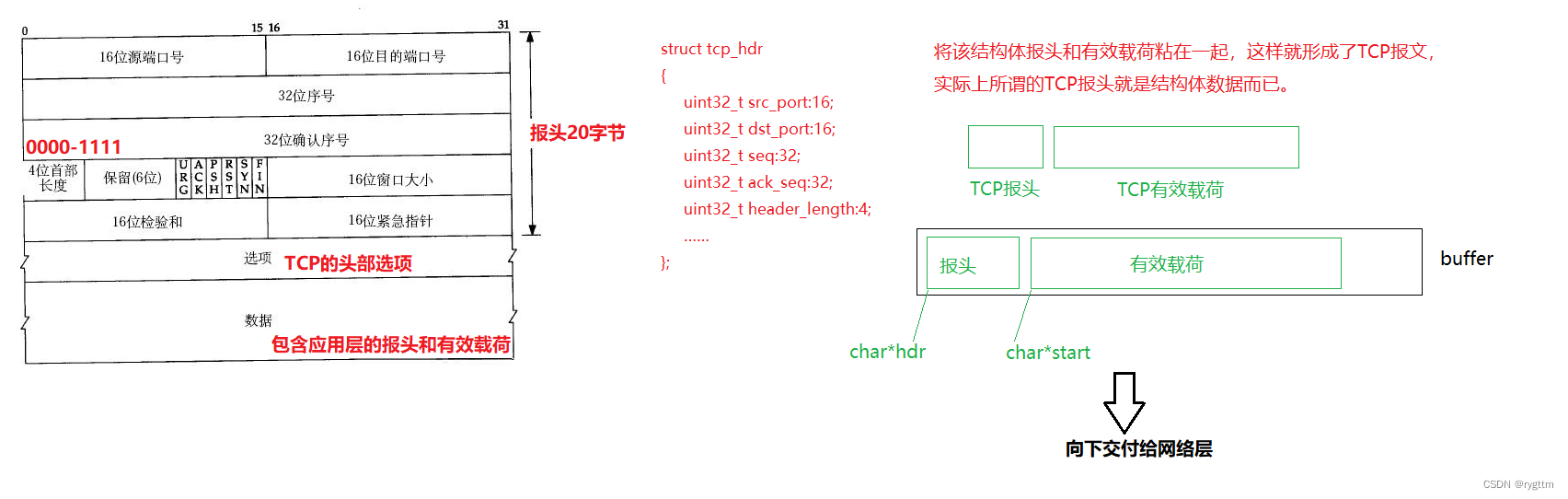
Para aprender cualquier protocolo, debemos considerar cómo separa el protocolo el encabezado de la carga útil y cómo entregar la carga útil separada a la capa superior. El encabezado del protocolo TCP tiene su propia longitud estándar de 20 bytes. Si el encabezado lleva otro El Opción de encabezado TCP, el encabezado tiene más de 20 bytes y la longitud del encabezado de 4 dígitos representa el tamaño del encabezado TCP. El valor de la longitud del encabezado de 4 dígitos × unidad de 5 bytes es igual a la longitud del encabezado TCP, por lo que la longitud del encabezado TCP es de 20 bytes, con un rango de -60 bytes.
Al dividir un mensaje TCP, solo necesita leer primero el contenido de la longitud del encabezado estándar de 20 bytes, leer el valor del campo de la longitud del encabezado de 4 dígitos y luego × 5, para que pueda obtener la longitud completa del El mensaje TCP, y la parte restante es la carga útil, y la entrega ascendente también es muy simple.Hay un número de puerto de destino de 16 bits en el encabezado estándar, y la carga útil se puede entregar con precisión a un protocolo de capa de aplicación específico ( proceso utilizando el protocolo) a través del número de puerto.
2.
Ahora hay un problema. Solo hay campos en el encabezado TCP que representan la longitud del encabezado TCP, pero no hay ningún campo que represente el tamaño de la carga útil. ¿Cómo puede el receptor determinar la carga útil de lectura cuando la capa de aplicación lee la carga útil en el búfer TCP?¿Es la carga útil en un mensaje? Para lograr la situación de no más lectura o menos lectura.
De hecho, esta es también la característica de TCP para flujos de bytes, que es completamente diferente de UDP para datagramas. TCP no tiene por qué resolver el problema de si su capa de aplicación puede leer un mensaje completo. TCP no tiene esta responsabilidad y obligación. , porque TCP está orientado a bytes, y los datos en el búfer de TCP se almacenan byte a byte. No está orientado a datagramas como UDP, por lo que existe un límite claro entre las cargas útiles (capa de transporte), que son exactamente características de los flujos de bytes .
Entonces, ¿quién resolverá este problema (en realidad, el problema del paquete pegajoso)? Por supuesto, es la capa de aplicación la que resuelve el problema. La capa de aplicación necesita establecer un protocolo para que el receptor pueda leer un mensaje completamente al leer el mensaje. De hecho, resolvimos este problema cuando escribimos la versión de red del calculadora. Utilizamos \r\n como delimitador de carácter especial para aclarar el límite entre dos paquetes. Hay un delimitador especial entre el encabezado de la capa de aplicación y el mensaje, y también hay un delimitador de carácter especial al final del mensaje.

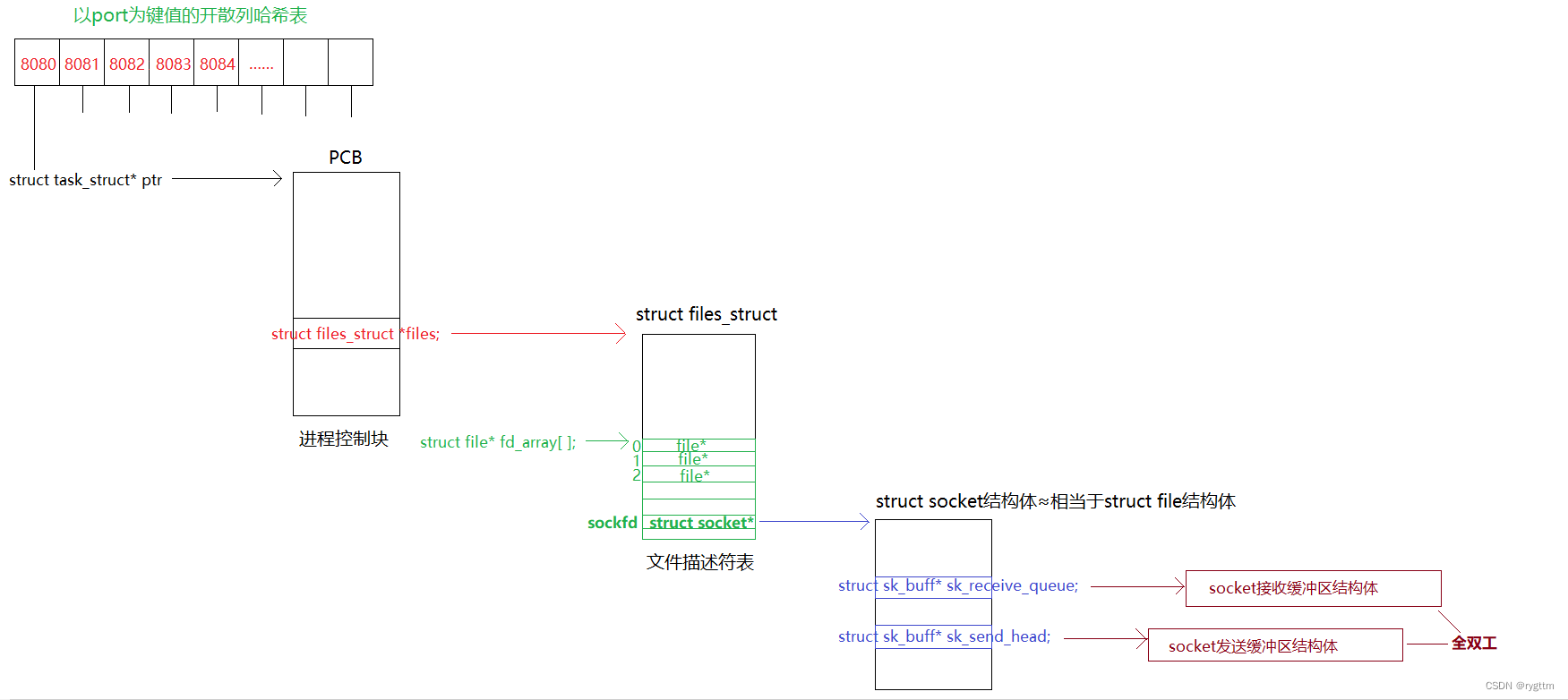
1.2 La conexión entre la pila de protocolos de red y el sistema Linux (una tabla hash abierta con el puerto como valor clave, y el cubo hash almacena la dirección de la PCB correspondiente al puerto)
1.
Cuando hablamos sobre el número de puerto en la etapa inicial, dijimos que la capa de transporte entregó datos a un proceso específico usando el protocolo de la capa de aplicación a través del número de puerto de destino de 16 bits en el encabezado del protocolo. entender de esta manera, pero se entiende hasta este punto Aún no lo suficientemente profundo, necesitamos refinar este proceso y vincular la pila de protocolos de red con el sistema de archivos de Linux, para comprender mejor el proceso de entrega de la carga útil hacia arriba desde el capa de transporte.
De hecho, el núcleo mantendrá una tabla hash abierta con el número de puerto como valor clave. El puntero a la estructura de la PCB se almacenará en el contenedor hash. Cuando la capa de transporte entrega la carga útil a un proceso específico a través del puerto, el La estructura de proceso específica se puede encontrar rápidamente a través de la tabla hash, por lo que la entrega ascendente no es una charla vacía, sino que debe completarse a través de una estructura de datos específica.
Además, el sockfd devuelto al llamar a la interfaz de socket es en realidad un descriptor de archivo. El descriptor de archivo es en realidad el subíndice de la matriz fd_array. El puntero a la estructura del archivo se almacenará en la ubicación correspondiente al subíndice, y la estructura del archivo se mantendrá internamente. Al crear sockfd, el kernel crea punteros al búfer de recepción y al búfer de envío al mismo tiempo. El puntero se denomina struct sk_buff * sk_receive_queue/sk_send_head, por lo que el búfer de envío y recepción no es simplemente una matriz, sino un estructura.
Cuando la red recibe datos, el host del mismo nivel primero colocará los datos en el búfer de recepción dentro de la estructura de archivo correspondiente al sockfd utilizado para la comunicación, de modo que la capa de aplicación pueda leer los datos de la red en forma de un descriptor de archivo. la capa superior llama a recv recvfrom read y otras interfaces de red IO, en realidad copia los datos en el búfer de recepción dentro de la estructura de archivos correspondiente a sockfd al búfer de la capa de aplicación
1.3 Comprender el encabezado TCP (datos de estructura) desde el nivel de código
1.
Comprenda que el encabezado TCP es el mismo que el encabezado UDP. En realidad, son estructuras en el kernel de Linux. Al enviar un mensaje a la capa de red, TCP unirá los datos en el búfer de envío y el encabezado TCP, y luego enviarlos a la próxima entrega.
Cuando entiendo el proceso de entrega descendente unificada de mensajes TCP desde el nivel de código, el núcleo copia el encabezado TCP de datos de estructura en un gran búfer de caracteres y luego copia la carga útil de TCP en este gran búfer. En realidad, es muy fácil de hacer. La siguiente captura de pantalla muestra cómo copiar los datos de la estructura en la matriz de caracteres y luego explicar completamente el valor de las variables de los miembros de la estructura al leer el contenido de la matriz. De hecho, es suficiente para convertir el tipo de puntero.
Por supuesto, no sé si el kernel hace esto. No puedo entender el código fuente del kernel en este nivel. Solo se puede entender de esta manera desde el nivel lógico, y también puedo revisar los punteros y las estructuras de por cierto, el lenguaje C. cuerpo de conocimiento en este sentido.
2.
Solo necesitamos tratar los datos de la estructura como un flujo binario, que en realidad es un flujo de bytes, y luego podemos llamar a memcpy para copiar los datos de la estructura en la matriz de caracteres. Cabe señalar que el mensaje se recibe en el receptor. end Al leer el encabezado, debe forzar el puntero a un tipo de estructura para interpretar los datos en la primera parte de la matriz de caracteres, obtener la semántica de flujo binario original y leer cada campo en el encabezado.
1.4 Mecanismo de respuesta de acuse de recibo (número de secuencia y número de secuencia de acuse de recibo, características orientadas a bytes de TCP)
1.
A continuación, analicemos uno de los mecanismos para garantizar la confiabilidad de TCP: el mecanismo de respuesta de confirmación.
De hecho, ¿por qué hay problemas poco fiables en la transmisión de red? La razón esencial es que la distancia de transmisión es demasiado larga .
Por ejemplo, cuando envío un mensaje a un internauta en Guangdong, en Mongolia Interior, el paquete de datos en realidad necesita pasar a través de muchos nodos de enrutador para el reenvío de paquetes de datos, pasar a través de muchas LAN y pasar a través de cables de par trenzado (el medio físico comúnmente utilizado). en tecnología Ethernet) dentro de la LAN. La transmisión también debe pasar por la estación base del operador. Es probable que el paquete de datos se pierda en una distancia de transmisión tan larga, los bits en los datos se inviertan o los bytes en el paquete de datos están fuera de secuencia, o el paquete de datos se envió repetidamente a mis internautas de Guangdong (el remitente puede pensar que el paquete de datos se perdió).
¿Cómo debería TCP resolver el problema poco fiable de la transmisión de red? Se requiere acuse de recibo.
Aunque el paquete de datos viaja demasiado lejos en la red, siempre que el mensaje que envié a mi internauta tenga una respuesta y una respuesta, entonces puedo juzgar que los datos que envié deben haber llegado al host de mi internauta. Por ejemplo, les pregunté a mis internautas, ¿cómo están aprendiendo TCP/IP recientemente? ¡Mi internauta me respondió que estoy aprendiendo el mecanismo de respuesta de confirmación de TCP recientemente! Entonces puedo estar seguro inmediatamente de que después de que los datos que envío se transmitan a través de la red, mi internauta debe haberlos recibido, porque el internauta respondió al mensaje que envié. Del mismo modo, si no respondí a mi internauta, entonces el internauta no está seguro de lo que dijo, debo haberlo recibido, ¡porque no he respondido al mensaje que envió! ¡Y este es un mecanismo típico de respuesta de confirmación!
Pero, de hecho, puede encontrar que cuando mis internautas y yo enviamos mensajes, siempre habrá un último mensaje que no se haya confirmado, sin importar si el último mensaje lo enviamos él o yo, por lo que podemos concluir que TCP no es ¡Confiabilidad absoluta, solo confiabilidad relativa!
Por lo tanto, la confiabilidad de TCP nunca habla de las últimas noticias, solo de noticias históricas, porque debe haber un último mensaje que no ha sido respondido.
2.
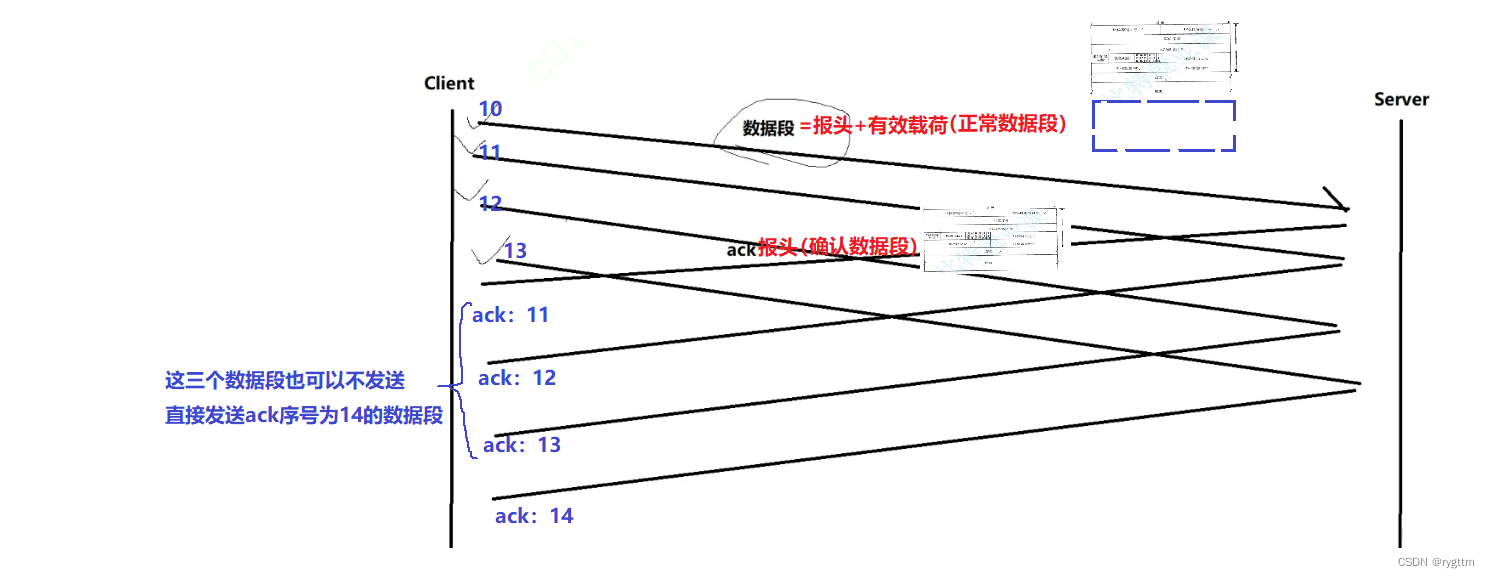
Cuando estamos aprendiendo TCP, la imagen más común es la de la izquierda, pero el modo de trabajo real de TCP está a la derecha. Al enviar un mensaje, enviará un lote de segmentos de datos a la vez, y cuando Al confirmar la respuesta, también enviará un lote de segmentos de datos a la vez. Confirmar segmento de datos. Si un segmento de datos no contiene ninguna carga útil y solo el indicador ACK se establece en 1, llamamos a este segmento un segmento de datos de reconocimiento simple y no contiene ningún mensaje.

3.
Hablar sobre el mecanismo de respuesta de confirmación es absolutamente inseparable del número de serie y el número de serie de confirmación en el encabezado TCP. En TCP, cada segmento de datos enviado tiene su propio número de serie o número de serie de confirmación, y el valor del número de serie y confirmación el número de serie está realmente en En el encabezado de TCP, solo es necesario completar el valor del número de serie correspondiente o el número de serie de confirmación en el encabezado del segmento de datos al enviar.
El número de serie es más fácil de entender, lo que significa que cada segmento de datos tiene un número para identificarse de forma única, pero la definición del número de serie de confirmación es así: el valor del número de serie de confirmación indica que el receptor ha recibido todos los mensajes. antes del número de serie del acuse de recibo y son consecutivos. Por ejemplo, si el valor del número de secuencia de la confirmación del acuse de recibo es 11, significa que el receptor ha recibido todos los paquetes con números de secuencia hasta el 10 inclusive, y el remitente puede comenzar enviar paquetes desde el número de secuencia 11 la próxima vez, por lo que el número de secuencia de confirmación El valor se entiende desde la perspectiva del remitente, que puede entenderse como el valor del número de secuencia del mensaje cuando el remitente envía el mensaje la próxima vez.
Si el servidor recibe un mensaje con un número de secuencia de 10 12 13, cuando el servidor envía un segmento de datos de confirmación al cliente, el número de secuencia de confirmación solo puede ser 11, porque el servidor no ha recibido el mensaje de 11, incluso si recibe 12 13, no puede acusar recibo 14, porque debe asegurarse de que todos los paquetes con números de secuencia antes del número de secuencia de confirmación de acuse de recibo sean recibidos.
4. ¿
Por qué el número de serie de confirmación se define de esta manera ?
De hecho, hay una razón para esta definición, cuando hablemos de la ventana deslizante más adelante, conoceremos la sutileza del número de secuencia de confirmación, que puede mejorar la eficiencia de la transmisión de datos de red en algunos casos.
Cuando el cliente envía segmentos de datos en lotes, ¿el orden en que los segmentos de datos llegan al servidor debe ser el mismo en el que se enviaron ?
Esto no es seguro, pero después de que los datos llegan al servidor, el desorden de los segmentos de datos es en realidad una manifestación de una transmisión de red de larga distancia poco confiable. Por lo tanto, después de recibir un lote de segmentos de datos, TCP primero los clasificará de acuerdo con el Números de secuencia de los segmentos de datos Para garantizar el orden del segmento de datos cuando llega, ¿
por qué debería haber dos números de serie y un número de serie no es posible ?
Debido a que TCP es full-duplex, necesita dos números de serie. Un segmento de mensaje puede tener identidades duales. Puede tener tanto un número de serie de confirmación como un número de serie, que tiene las funciones de confirmar la respuesta y enviar datos de red. Por ejemplo, el cliente envía el segmento de mensaje No. 10, el contenido es servidor, ¿terminaste de aprender TCP? El servidor envía el segmento de mensaje No. 20 y confirma que el número de secuencia es 11 (el número de secuencia del segmento de mensaje enviado por ambas partes de la comunicación es globalmente único, y el número de secuencia y el número de secuencia de confirmación se pueden negociar al mismo tiempo, y no habrá conflicto). El contenido es que he terminado de aprender TCP. En este momento, el segmento de mensaje enviado por el servidor tiene una función de dúplex completo, que no es solo una respuesta de confirmación para enviar el segmento de mensaje al cliente, sino también un segmento de mensaje que contiene datos de red para enviar al cliente. Esta es una comunicación full-duplex.
5.
De hecho, siempre que los datos del búfer de la capa de aplicación se copien en el búfer de la capa de transporte, cada byte de datos tiene naturalmente su propio número de serie, que es la característica del flujo de bytes. No hay datos entre cargas útiles. Límites claros.
Al enviar un segmento de mensaje, el número de secuencia del segmento de mensaje es el número de secuencia del primer byte de la carga útil en el búfer.
El número de secuencia de reconocimiento le dice al remitente dónde enviará los datos la próxima vez y qué datos ha recibido el receptor.

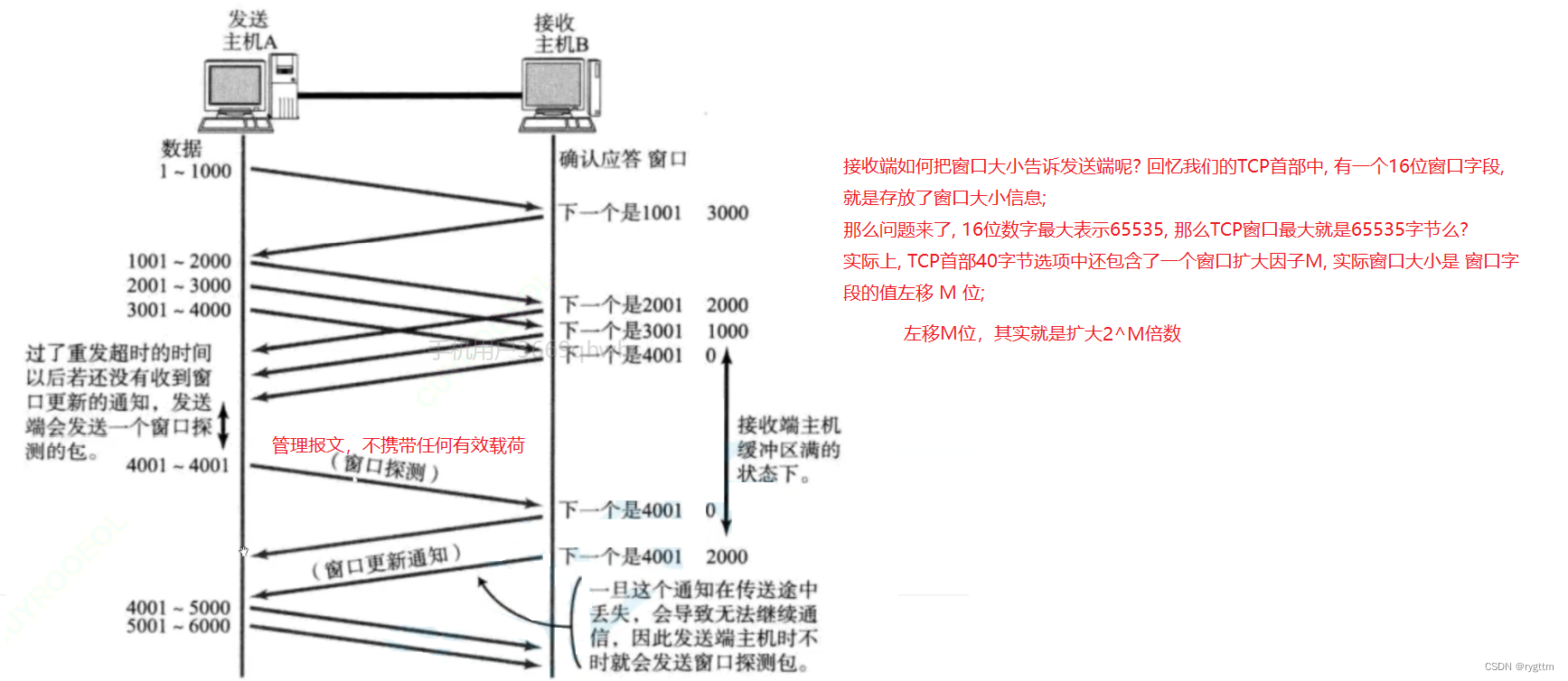
1.5 Control de flujo (tamaño de ventana de 16 bits)
1.
Se puede decir que el control de flujo no solo garantiza la confiabilidad de TCP, sino que también garantiza la eficiencia de TCP Hablar de control de flujo también debe ser inseparable del campo de tamaño de ventana de 16 bits en el encabezado de TCP.
Si los datos se envían demasiado rápido, el extremo del par puede descartar algunos segmentos de datos porque el búfer de recepción está lleno de inmediato. Si los datos se envían con demasiada lentitud, cuando la capa de aplicación del extremo opuesto llama a recv para leer los datos en el búfer de recepción de manera bloqueada, puede afectar el procesamiento comercial de la capa superior del extremo opuesto, porque recv es un bloqueo de lectura por defecto. Entonces, en TCP, no es aceptable enviar datos demasiado rápido o demasiado lento, la velocidad debe ser adecuada.
Por lo tanto, cuando las dos partes envían datos, deben conocer la capacidad de recepción de datos de la otra parte, para controlar la velocidad al enviar datos a la otra parte, y el tamaño de la ventana de 16 bits indica el tamaño de la restante espacio en el búfer de recepción.La propia capacidad de la otra parte para recibir datos, por lo que cuando las dos partes se comunican, cada vez que envían un mensaje, llevarán su propio tamaño de ventana de 16 bits para intercambiar su propia capacidad de recibir datos, de modo que para lograr el propósito del control de flujo.
2.
Ahora hay una pregunta, ¿cómo sabe el remitente la capacidad de recepción de la otra parte cuando envía datos por primera vez?
De hecho, ya en la etapa del protocolo de enlace de tres vías, las dos partes han intercambiado sus respectivas capacidades de recepción.Durante el protocolo de enlace, pueden conocer el valor del tamaño de la ventana de 16 bits en el encabezado de la otra parte, por lo que como para controlar la velocidad a la que envían los datos. Cuanto mayor sea el campo de tamaño de la ventana, mayor será el rendimiento de la red para los datos.
Si el búfer del receptor está lleno y el valor del tamaño de la ventana de 16 bits es 0, el remitente dejará de enviar mensajes después de saber que el búfer de la otra parte no tiene espacio restante, pero enviará un mensaje de detección de ventana de vez en cuando. devolverá una notificación de actualización de ventana, y cuando el búfer del receptor tenga espacio restante, las dos partes continuarán completando la comunicación.
Además, si desea expandir el tamaño de la ventana de 16 bits, hay una opción de factor de expansión de ventana en la opción de encabezado de bytes TCP40, el factor de expansión es M y el rango de M es 0-14.Después de la modificación , el tamaño real de la ventana se expandirá 2^M veces. Vale la pena señalar que la opción de factor de expansión de la ventana solo puede aparecer en el segmento de sincronización. Si aparece en otros segmentos de comunicación, esta opción se ignorará. Cuando se establezca la conexión, se fijará el factor de expansión de la ventana. Esta opción es suficiente para entender, no se usa mucho.
1.6 El tipo de segmento TCP (6 bits de bandera: explique URG y RST en detalle)
1.
Hay 6 banderas en el encabezado TCP. Diferentes banderas representan diferentes tipos de segmentos de mensajes. El servidor recibirá segmentos de mensajes de una gran cantidad de clientes diferentes, y cada segmento de mensaje tendrá su propio tipo. .
SYN: segmento de mensaje síncrono, utilizado para la solicitud de conexión cuando el protocolo de enlace de tres vías TCP establece la conexión
ACK: Confirma el segmento del mensaje, confirma la respuesta al segmento del mensaje histórico
URG: indica si el puntero urgente es
válido Abra la conexión y realice la onda TCP cuatro veces
RST : restablece el restablecimiento del segmento de mensaje, lo que indica que se restableció la conexión.
PSH: insta a la capa de aplicación del receptor a tomar los datos del búfer de recepción de la capa de transporte lo antes posible para hacer espacio para los datos posteriores.
2.
El puntero urgente de 16 bits indica el desplazamiento de los datos urgentes en la carga útil. TCP estipula que los datos urgentes solo pueden tener 1 byte. Cuando el indicador URG se establece como válido, el puntero urgente será útil. Recibir Después de leer el encabezado TCP, la parte primero leerá 1 byte de datos urgentes desde el desplazamiento indicado por el puntero urgente, y luego leerá los datos restantes desde la posición inicial de la carga útil nuevamente. Los datos urgentes generalmente se denominan fuera de banda datos.
De hecho, no usamos el puntero urgente y la bandera URG en el 99.99% de los casos.Si realmente usamos datos fuera de banda, es posible que algún personal de operación y mantenimiento los use.Por ejemplo, el servidor está bajo gran presión ahora y puede enviar 1 byte. Los datos fuera de banda se utilizan para consultar el estado del servidor actual y si ha vuelto a un estado saludable. El servidor puede devolver 1 byte de datos fuera de banda , y usa 1 byte de datos para corresponder al código de estado. ¿Cuál es el motivo para regresar al servidor? Provoca sobrecarga, porque los datos fuera de banda se pueden leer directamente en la capa de la aplicación sin pasar por largos flujos de datos.
Por lo tanto, los datos fuera de banda no están realmente en el flujo de datos normal, y los protocolos UDP y TCP generalmente se usan para datos fuera de banda. Si desea leer datos fuera de banda, puede bit a bit o agregar MSG_OOB a las banderas de recv, para que pueda leer datos fuera de banda.

3.
El apretón de manos de tres vías para establecer una conexión no necesariamente establece una conexión exitosa. Nadie dice que el apretón de manos de tres vías debe ser exitoso. Lo mismo es cierto para cuatro apretones de manos. Incluso si la conexión se establece con éxito, puede ser desconectado, como unilateralmente. Si la alimentación del host está desconectada, ¿no se desconectará automáticamente la conexión? Cuando el servidor se reinicia, el servidor no cree que la conexión se haya establecido con éxito, pero el cliente aún cree que la conexión existe, por lo que el cliente seguirá enviando mensajes al servidor y el servidor se sentirá muy extraño de que la conexión ya no esté. existe ¿Por qué todavía tiene que comunicarse con ¿Qué pasa con mi correspondencia? Entonces, en este momento, el servidor enviará un segmento de mensaje de reinicio al cliente, con el indicador RST en el encabezado establecido en 1, diciéndole al cliente, no me envíe más mensajes, la conexión se desconectó de manera anormal y usted Vuelva a iniciar el apretón de manos de tres vías y restablezca una conexión conmigo.
Por lo tanto, el indicador de restablecimiento se usa para ambas partes de la comunicación. Cuando cualquier parte piensa que la conexión es inconsistente, la parte que piensa que la conexión es anormal enviará un segmento de mensaje de reinicio para informar a la otra parte que necesitamos restablecer la conexión. .
Mucha gente debería haberse encontrado con el siguiente escenario. De hecho, se debe a que el servidor está bajo demasiada presión y no puede realizar más conexiones, lo que provoca que la conexión se restablezca y se produzca una conexión anormal. El segmento de mensaje enviado por el servidor a nuestro navegador se restablece. segmento, lo que permite al cliente restablecer una conexión con el servidor.
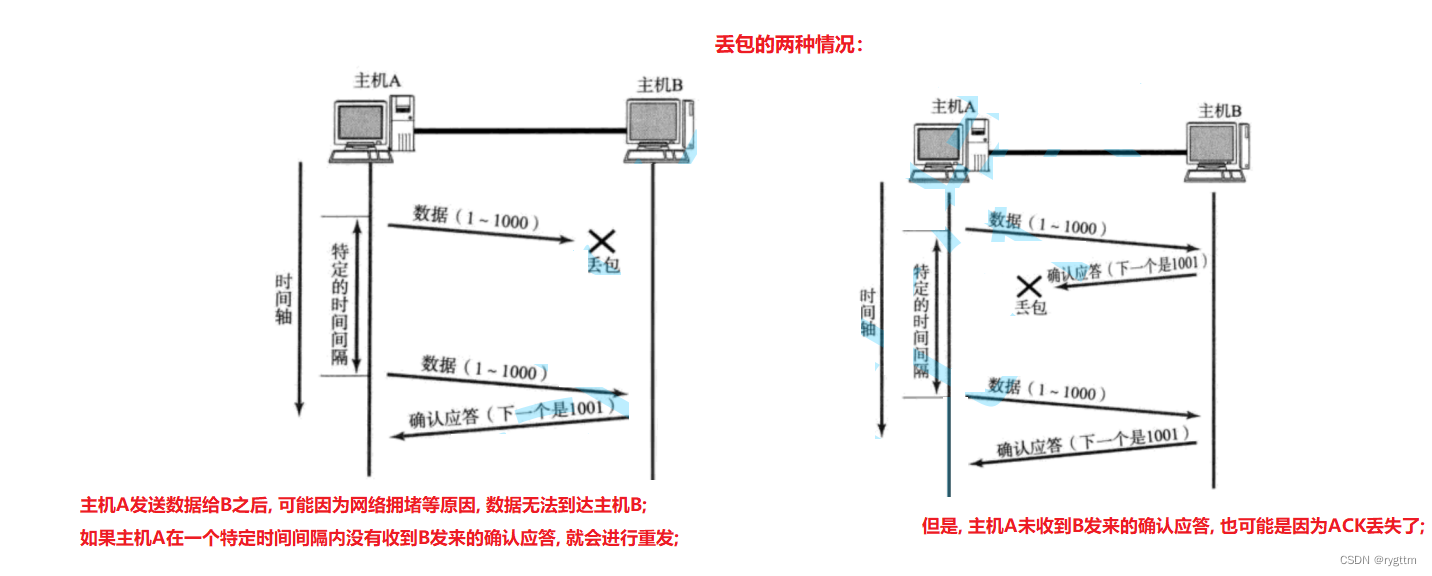
1.7 Mecanismo de retransmisión de tiempo de espera (si el paquete de datos no recibe una respuesta dentro de la ventana de tiempo de espera, se considerará como pérdida de paquete y se retransmitirá)
1.
Hemos hablado antes de uno de los problemas poco confiables en la transmisión de red: la pérdida de paquetes, la retransmisión después del tiempo de espera es para resolver el problema de la pérdida de paquetes.
La pérdida de paquetes se divide en dos casos, uno es que el segmento de datos realmente se pierde, y el otro es que el segmento de datos se ha enviado, pero el segmento del mensaje ACK se ha perdido. De hecho, el remitente no puede distinguir estos dos casos. la parte solo puede estipular que dentro de un cierto período de tiempo, si el mensaje enviado no recibe una respuesta de confirmación, el mensaje se considerará como una pérdida de paquete, al igual que no se puede encontrar al hijo de algunos padres, el niño puede simplemente salir Perdido , puede perder la vida o puede ser secuestrado por traficantes de personas. Los padres realmente no pueden determinar adónde ha ido el niño. Solo pueden juzgar desde la dimensión del tiempo. Si el niño no regresa durante un año o más, entonces los padres Pensé que el niño estaba perdido.
2.
Si es la segunda situación de pérdida de paquetes, el receptor recibirá dos mensajes idénticos. En este momento, el receptor ordenará los mensajes de acuerdo con el número de serie + deduplicación para garantizar que los mensajes recibidos sean confiables, porque los paquetes repetidos también son una especie de rendimiento poco fiable.
3.
Sabemos que es posible que el segmento de datos enviado no reciba ACK, por lo que los datos enviados no deben eliminarse inmediatamente (la eliminación en la computadora es en realidad sobrescribir datos), debe guardarse durante un período de tiempo, si los datos enviados Si el el paquete se pierde, los datos guardados se pueden volver a enviar y los datos que se enviaron pero no recibieron el ACK se almacenan en la ventana deslizante.Esto se discutirá más adelante, pero permítanme mencionarlo primero.
4.
¿Cómo configurar el tiempo extra? De hecho, este tiempo debería cambiar dinámicamente con la situación de la red. Si la situación de la red es buena, el tiempo de espera se establece muy largo, lo que en realidad afectará la eficiencia de la transmisión de la red, porque el paquete de datos se envía muy rápido y los datos el paquete puede ir y venir una vez. Toma 50 ms en total, pero si establece el período de tiempo de espera en 500 ms, el tiempo de 450 ms en el medio se desperdiciará sin motivo. En el proceso de transmisión, se considera como pérdida de paquete, lo que también afectará la eficiencia de la transmisión de datos.
Por lo tanto, la situación ideal es encontrar el tiempo más corto para garantizar que, en la mayoría de las condiciones de la red, los paquetes de datos se puedan enviar dentro de este período de tiempo más corto y los mensajes ACK se puedan enviar de vuelta al mismo tiempo.
5.
En linux (lo mismo es cierto para unix y windows), el tiempo de espera en realidad se controla con 500 ms como unidad básica. Si no se ha confirmado después de la primera retransmisión, será el exponente de potencia de 2 × 500 ms para gradualmente aumente la ventana de tiempo de espera, y cuando el número acumulado de retransmisiones alcance un cierto número, TCP cerrará por la fuerza la conexión establecida por ambas partes.

2. Mecanismo de gestión de conexiones
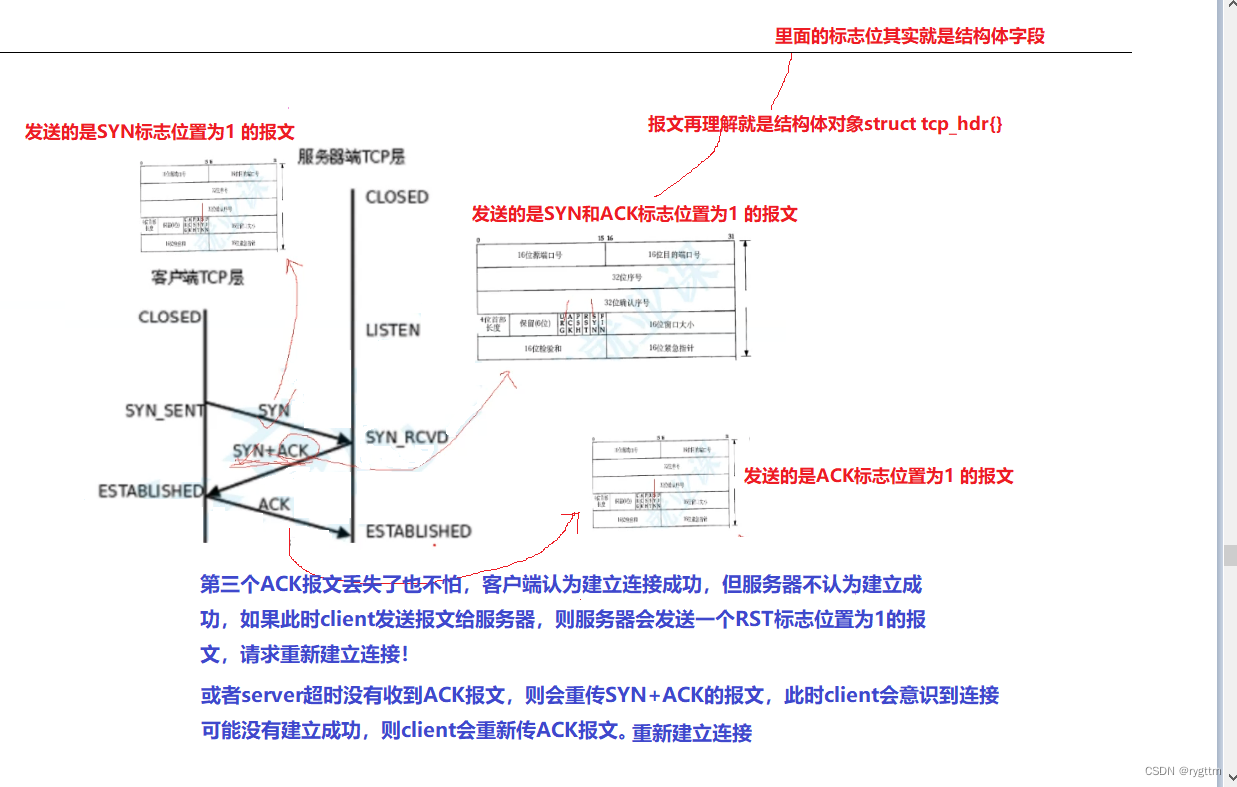
2.1 ¿Por qué hay un apretón de manos de tres vías? (Verificación de costo mínimo de comunicación full-duplex + prevención de un ataque de inundación SYN de host único en el servidor)
1.
El protocolo de enlace de tres vías es el proceso de establecer una conexión TCP. El cliente primero envía un segmento de mensaje SYN al servidor, indicando que el cliente desea establecer una conexión con el servidor, y luego el servidor confirma y responde a la solicitud de conexión del cliente, y el servidor también quiere establecer una conexión con el cliente.Solicitud, por lo que el servidor enviará un segmento de mensaje con una respuesta superpuesta.El segmento de mensaje no es solo el segmento SYN con el que el servidor desea establecer una conexión el cliente, pero también tiene la función de confirmar la respuesta. Cuando el cliente recibe el mensaje del servidor para sí mismo. Después de la respuesta de confirmación del segmento SYN del servidor, el cliente pensará que la conexión se ha establecido con éxito. Después de la cliente recibe el segmento SYN del servidor, el cliente también enviará un segmento de confirmación ACK al servidor. Cuando el servidor Después de recibir el segmento ACK, el servidor también pensará que la conexión se ha establecido con éxito. Cuando ambas partes piensan que la conexión se establece con éxito, entonces las dos partes pueden completar la comunicación.Este es todo el proceso del apretón de manos de tres vías.
2.
Hemos discutido antes que TCP solo puede garantizar la confiabilidad de los mensajes históricos, y nunca hablar sobre la confiabilidad del último mensaje. Esta oración no es un problema, como el último apretón de manos de tres apretones de manos. Este mensaje es de hecho poco confiable, porque el cliente ¡El cliente no sabe si el servidor recibe el segmento ACK enviado por el cliente! Pero no importa, incluso si se pierde el segmento del mensaje ACK, el servidor no pensará que la conexión se ha establecido correctamente. En este momento, si el cliente envía un mensaje al servidor, el servidor se sentirá muy extraño. Ya que la conexión no se ha establecido correctamente, todavía me envía un mensaje, significa que ambos pensamos que el establecimiento de la conexión es inconsistente, luego el servidor enviará un segmento de mensaje de reinicio al cliente, solicitando volver a estrechar la mano tres veces , y restablecer la conexión, porque nuestro establecimiento de conexión actual es inconsistente, el cliente piensa que la conexión se estableció con éxito, pero el servidor no la considera exitosa. O hay otra situación, si el segmento SYN enviado por el servidor no tiene una respuesta de confirmación después de un tiempo de espera, el servidor lo retransmitirá después de un tiempo de espera. El segmento del mensaje de respuesta de confirmación enviado puede perderse y el cliente volverá a enviar el ACK. segmento de mensaje en este momento.
Por lo tanto, no importa qué tipo de comportamiento no confiable ocurra en el último segmento del protocolo de enlace de tres vías, no tenemos que preocuparnos por eso. TCP tendrá estrategias correspondientes para resolver problemas no confiables, como la retransmisión de tiempo de espera. La parte existente puede envíe un segmento de mensaje de reinicio para restablecer la conexión.
También es necesario explicar que el apretón de manos de tres vías para establecer una conexión se basa en las perspectivas de ambas partes, no desde la perspectiva de Dios. Si la conexión se establece con éxito, será un éxito . Por ejemplo, siempre que el cliente reciba el segmento ACK del servidor, el cliente pensará que la conexión se ha establecido correctamente, es decir, después de que se complete el segundo protocolo de enlace de tres vías, el cliente ya pensará que la conexión se ha establecido con éxito, por lo tanto, siempre que ambas partes piensen que la conexión es exitosa. Si el establecimiento es exitoso, entonces la conexión se establece con éxito.
3.
Entonces, nadie dice que el protocolo de enlace de tres vías será exitoso, pero de hecho, en un buen entorno de red, el 99.99% del protocolo de enlace de tres vías será exitoso. Solo se puede decir que el protocolo de enlace de tres vías será exitoso. éxito con una alta probabilidad Lo que más nos preocupa es el tercer apretón de manos El segmento de mensaje se pierde, porque es la última noticia, no es confiable, pero TCP tiene una solución para noticias tan poco confiables, por lo que no hay necesidad de preocuparse demasiado.
Además, el servidor recibirá solicitudes de conexión de una gran cantidad de clientes diferentes, por lo que el servidor necesita administrar esta gran cantidad de conexiones, porque sabemos que la capa de transporte se implementa dentro del sistema operativo del host del servidor y el sistema operativo. necesita administrar la conexión, el método utilizado debe describirse primero y luego organizarse, por lo que la llamada conexión en el sistema operativo debe describirse mediante una estructura relacionada, y luego debe describirse una gran cantidad de objetos de conexión (estructura de conexión) a través de determinada estructura de datos), se puede concluir que mantener una conexión tiene un costo (costo espacio-temporal).
4.
Después de hablar sobre el proceso detallado del apretón de manos de tres vías, hablemos de por qué debe ser un apretón de manos de tres vías.
El primer protocolo de enlace definitivamente no es suficiente, porque un solo host cliente envía un montón de mensajes SYN al servidor, luego el servidor necesita mantener la conexión establecida, y sabemos que establecer una conexión es costoso, por lo que el servidor sufrirá en el caso de un solo host Un ataque de inundación SYN hace que el servidor se cuelgue.
Dos apretones de manos no son suficientes, el servidor seguirá siendo atacado por una inundación SYN, el cliente envía un segmento de mensaje SYN al servidor, el servidor necesita mantener la conexión y el servidor también enviará un SYN + ACK al cliente, pero el cliente puede ignorar esta sección del mensaje, descartarlo directamente, entonces el cliente no necesita mantener la conexión, por lo que tampoco se permiten los dos apretones de manos. Porque en el caso de un ataque de host de un solo cliente, el servidor no puede soportarlo, y mucho menos una gran cantidad de hosts de clientes.
¿ Por qué es posible el apretón de manos de tres vías ?
a. El protocolo de enlace de tres vías puede verificar la comunicación full-duplex con un costo mínimo . La comunicación full-duplex significa que tanto el servidor como el cliente pueden recibir y enviar datos, y el envío y la recepción están desacoplados.El cliente puede enviar segmentos SYN y recibir segmentos ACK del servidor, y el servidor puede enviar El segmento de mensaje SYN puede también recibir el segmento de mensaje ACK del cliente Habiendo dicho eso, ¿puede el protocolo de enlace de cuatro vías verificar la comunicación full-duplex? Por supuesto, también es posible, pero dado que el apretón de manos de tres vías está bien, ¿por qué necesitamos darnos la mano cuatro veces? ¿El cuarto apretón de manos no está consumiendo recursos de red sin razón? Entonces, el apretón de manos de tres vías es para verificar la comunicación full-duplex al costo mínimo.
b. El protocolo de enlace de tres vías puede prevenir la vulnerabilidad de un ataque de inundación SYN de un solo host en el servidor. De hecho, el servidor ha sido atacado, lo que en sí no debería ser resuelto por TCP. Este es un tema de seguridad de la red. Mi TCP solo es responsable del control de la transmisión de datos, pero si su mecanismo de establecimiento de conexión TCP es obviamente atacado Vulnerabilidades, entonces este es su problema de TCP. Sabemos que tanto el protocolo de enlace único como el protocolo de enlace doble tienen vulnerabilidades obvias para ser atacados por inundaciones SYN. ¿No existe el protocolo de enlace de tres vías? La respuesta es no.
En el protocolo de enlace de tres vías, la premisa para que el servidor establezca una conexión es que el cliente ya ha establecido la conexión, por lo que el cliente y el servidor consumen el mismo costo.Si desea que el servidor establezca una conexión, primero debe establece la conexión tú mismo como cliente, y en la mayoría de los casos la configuración del servidor es muy superior a la del cliente, por lo que si ambas partes continúan consumiendo al mismo costo, debe ser el cliente el que no puede manejarlo primero, no el servidor, por lo que en el caso de un solo host, el cliente desea que SYN inunde el servidor, ¡lo cual no es realista! (Esto es un poco como, tu amigo te dio un refrigerio muy ácido o picante para molestarte, pero dijiste que debo comerlo primero antes de comerlo. Este es el consumo de costos iguales para ambas partes) Cuatro apretones de manos,
cinco ¿Está bien darse la mano por primera vez ?
Anteriormente dijimos que el apretón de manos de tres vías puede verificar la comunicación full-duplex al costo mínimo, y los apretones de manos de cuatro y cinco vías son definitivamente posibles. Sin embargo, el protocolo de enlace de cuatro vías también tiene la vulnerabilidad del ataque de inundación SYN. El servidor envía el último protocolo de enlace al cliente, lo que le permite al cliente establecer una conexión, pero el cliente puede ignorar este segmento y solo dejar que el servidor establezca una conexión por sí mismo, y mantener el costo de conexión requerido. Al mismo tiempo, dado que el cliente envía el último protocolo de enlace de cinco vías al servidor, el cliente también establecerá una conexión antes de que el servidor establezca una conexión. Ambas partes consumen el mismo costo, y el ataque de inundación SYN de un solo El anfitrión puede ser evitado. Por lo tanto, para otros protocolos de enlace después del protocolo de enlace de tres vías, los ataques de inundación SYN aún existen en tiempos pares y los ataques de inundación SYN no existen en tiempos impares, pero no son el costo mínimo para verificar el canal de comunicación full-duplex, por lo que el ¡Se usa un apretón de manos de tres vías en lugar de otros apretones de manos!
5.
De hecho, si realmente quiere deshacerse del servidor, es muy simple, es decir, deje que varios bots se conecten a un servidor al mismo tiempo. Los llamados bots son en realidad solo un término de red, y bots son clientes Siempre que el servidor reciba conexiones de una gran cantidad de clientes, el servidor asumirá muchos costos por esto, y el resultado final es que el servidor está seriamente sobrecargado y no puede recibir solicitudes de conexión de otros clientes normales. Los ataques se denominan ataques ddos, es decir, ataques de denegación de servicio. De hecho, mientras haya suficientes broilers, cualquier servidor puede ser atacado. Los ataques más avanzados a menudo usan el método más simple. En 2001, cuando nuestro país y los piratas informáticos extranjeros se involucraron en una guerra de ataque y defensa de la red, los piratas informáticos de nuestro país tomaron el servidor de la Casa Blanca, el método utilizado fue en realidad un ataque de inundación SYN. En ese momento, debido a los diversos comportamientos opresivos de los Estados Unidos contra nuestro país, los piratas informáticos chinos visitaron el sitio web oficial de la Casa Blanca en hosts de 8w al mismo tiempo. tiempo el 4 de mayo, el Día de la Juventud, y publicado en la página de inicio Cuelgue la bandera roja de cinco estrellas, y las palabras indignadas de dejar que los barcos estadounidenses regresen.
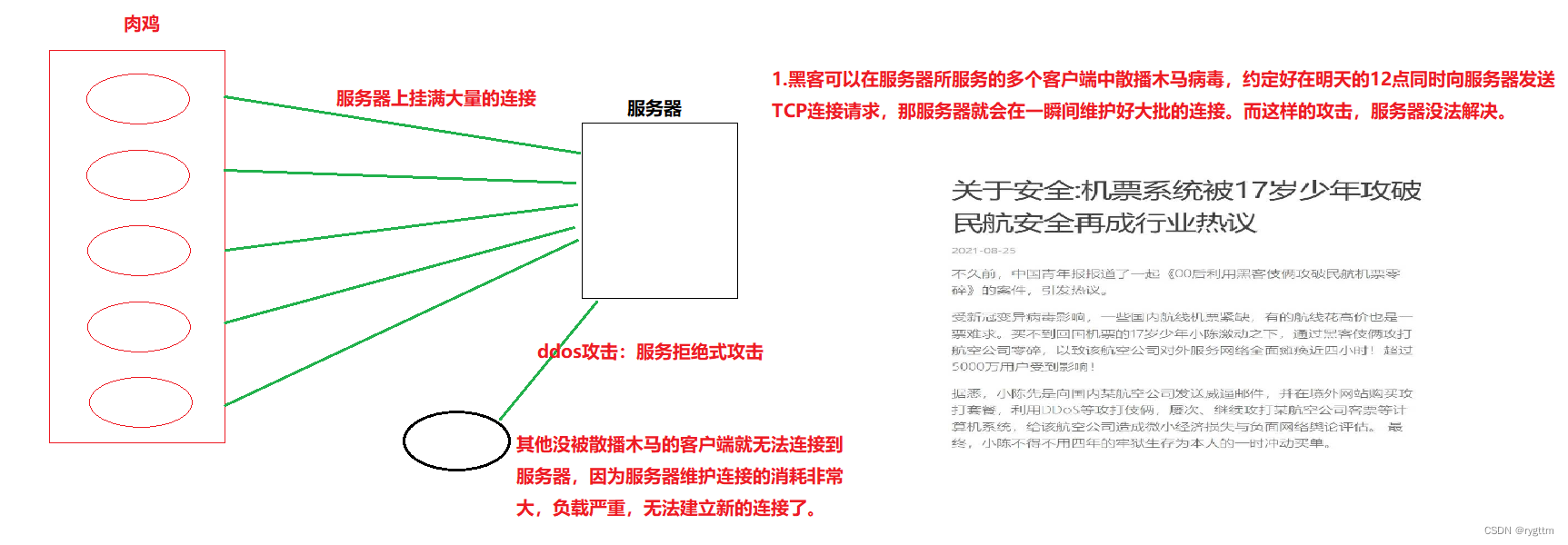
6.
Ahora, para los ataques de inundación SYN, existen más mecanismos de seguridad, como la lista negra, la lista blanca, el cortafuegos, el mecanismo de cookies SYN y otras estrategias de seguridad, que pueden aliviar los ataques de inundación SYN.
En el pasado, debido a la gran cantidad de usuarios de 12306, especialmente durante las vacaciones, la presión del servidor era muy alta y el servidor se colgaba fácilmente. No fue hasta la aparición de servidores de nube elástica que el problema de carga grave de 12306 fue resuelto.
2.2 Cuando las dos partes agitan sus manos cuatro veces, el estado cambia (comprende el estado CLOSE_WAIT, TIME_WAIT)
2.2.1 El proceso detallado de ondulado cuatro veces
1.
El establecimiento de una conexión es iniciado por una parte, la mayoría de las cuales son iniciadas por el cliente para iniciar una solicitud de conexión al servidor, pero la desconexión puede ser iniciada por cualquier parte. llame a close () para cerrar el archivo de socket Descriptor sockfd, cuando el cliente termina de enviar el mensaje, puede enviar un segmento de mensaje final FIN, y el servidor envía una respuesta ACK para confirmar la solicitud de desconexión del cliente. De manera similar, el servidor no necesita para enviar un mensaje al cliente, y él también puede enviar un mensaje final. El segmento del mensaje es FIN, y el cliente envía una respuesta ACK para confirmar la solicitud del servidor para desconectarse.
El mensaje de no envío que mencionamos aquí significa que los datos de la capa de aplicación no se envían, y no significa que la capa de transporte en sí misma no pueda enviar el segmento de administración de esta capa, como FIN, ACK y otros segmentos.
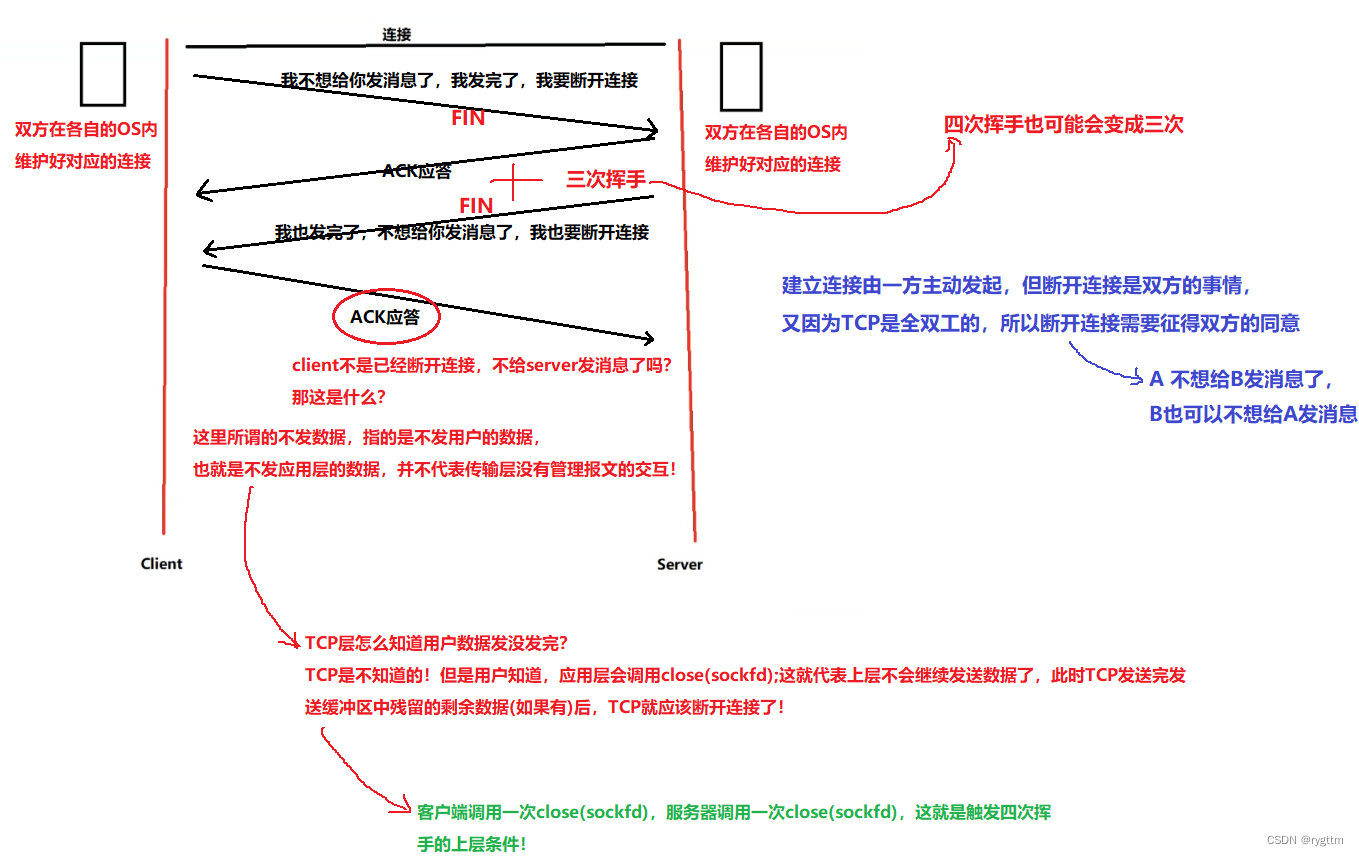
2.
Hay una pregunta, ¿por qué está conectado TCP? Es porque TCP necesita garantizar la confiabilidad, pero ¿por qué la conexión TCP puede garantizar la confiabilidad? De hecho, la conexión no garantiza directamente la fiabilidad, pero indirectamente puede garantizar la fiabilidad.
Cuando se establece la conexión, el kernel creará una estructura de conexión para administrar la conexión, y es el establecimiento de la estructura de conexión lo que puede completar mejor varias estrategias de TCP para garantizar la confiabilidad, como la retransmisión de tiempo de espera (mantenimiento interno de la estructura) Temporizador), respuesta de confirmación (campos de número de secuencia y número de secuencia de reconocimiento dentro de la estructura), control de flujo (tamaño de ventana de 16 bits dentro de la estructura), por lo que la estructura de conexión TCP es la base de la estructura de datos para que TCP garantice la confiabilidad.
3.
Puede ver que la siguiente conexión tiene muchos estados cuando se agita cuatro veces: FIN_WAIT_1, FIN_WAIT_2, TIME_WAIT, CLOSED, LAST_ACK, CLOSE_WAIT, estos estados son en realidad un campo de atributo dentro de la estructura de la conexión, al igual que el estado int. Los estados ingleses son en realidad macros, y diferentes macros representan diferentes estados de conexión. El más importante de tantos estados son los estados CLOSE_WAIT y TIME_WAIT, que deben entenderse bien.
Si el cliente primero llama a close(sockfd) para desconectarse activamente y enviar un segmento de mensaje FIN al servidor, el cliente ingresa al estado FIN_WAIT_1 Después de recibir el segmento de mensaje, el servidor devuelve un segmento de mensaje ACK y el servidor ingresa al estado CLOSE_WAIT , cuando el servidor llama a close(sockfd) para desconectarse, envía un segmento FIN al cliente y el servidor ingresa al estado LAST_ACK. Después de recibir el segmento FIN, el cliente devuelve un segmento ACK al servidor y el cliente ingresa TIME_WAIT estado, cuando el servidor recibe el segmento ACK, el servidor ingresa al estado CERRADO, y cuando el cliente ingresa al estado TIME_WAIT, debe esperar 2MSL (tiempo máximo de supervivencia del mensaje de vida máxima del segmento) antes de ingresar al estado CERRADO.

4.
Por lo tanto, el estado final de la parte que se desconecta activamente es el estado TIME_WAIT, y la parte que se desconecta pasivamente, después de completar las dos primeras oleadas, el estado cambia al estado CLOSE_WAIT.
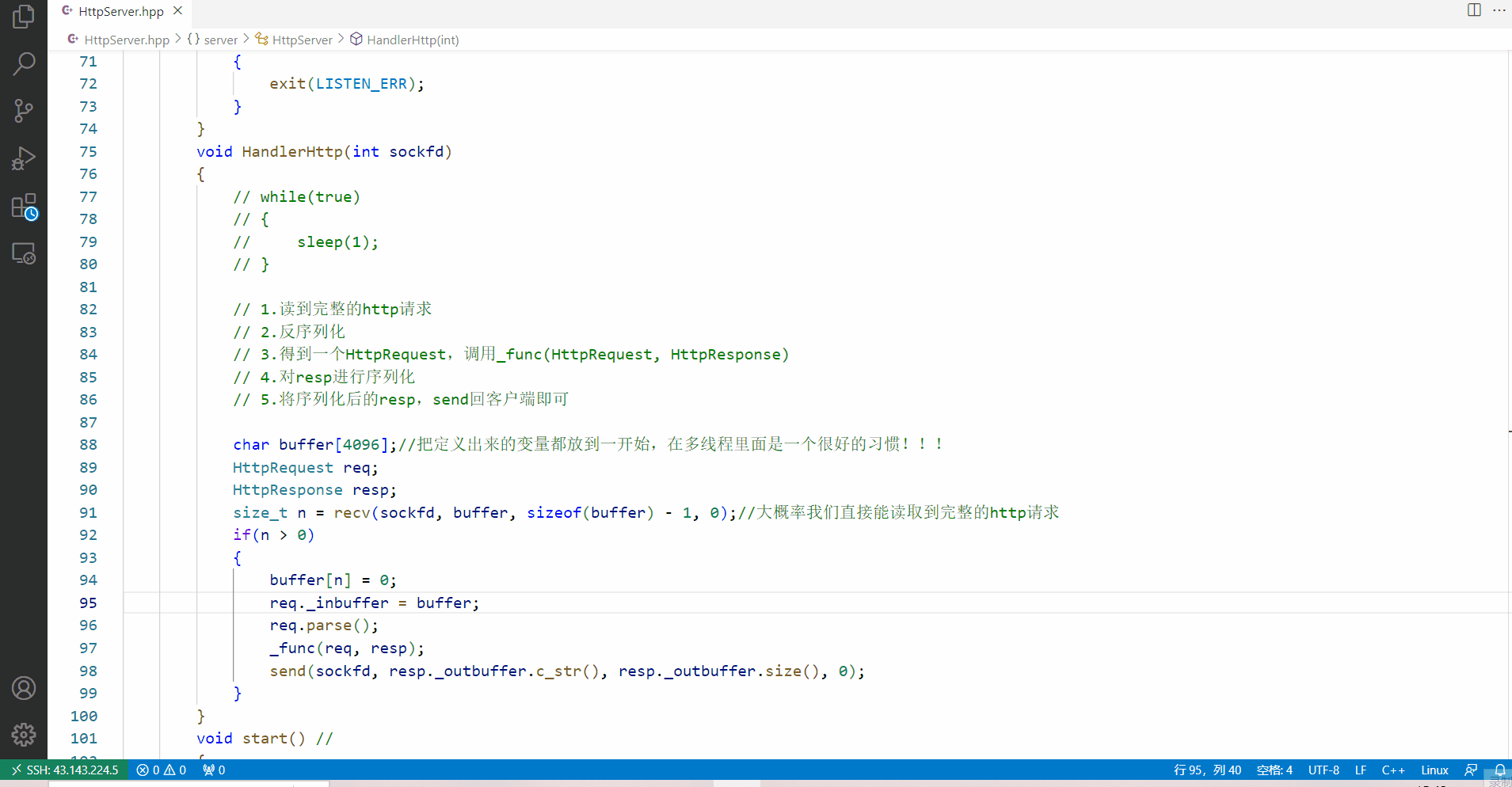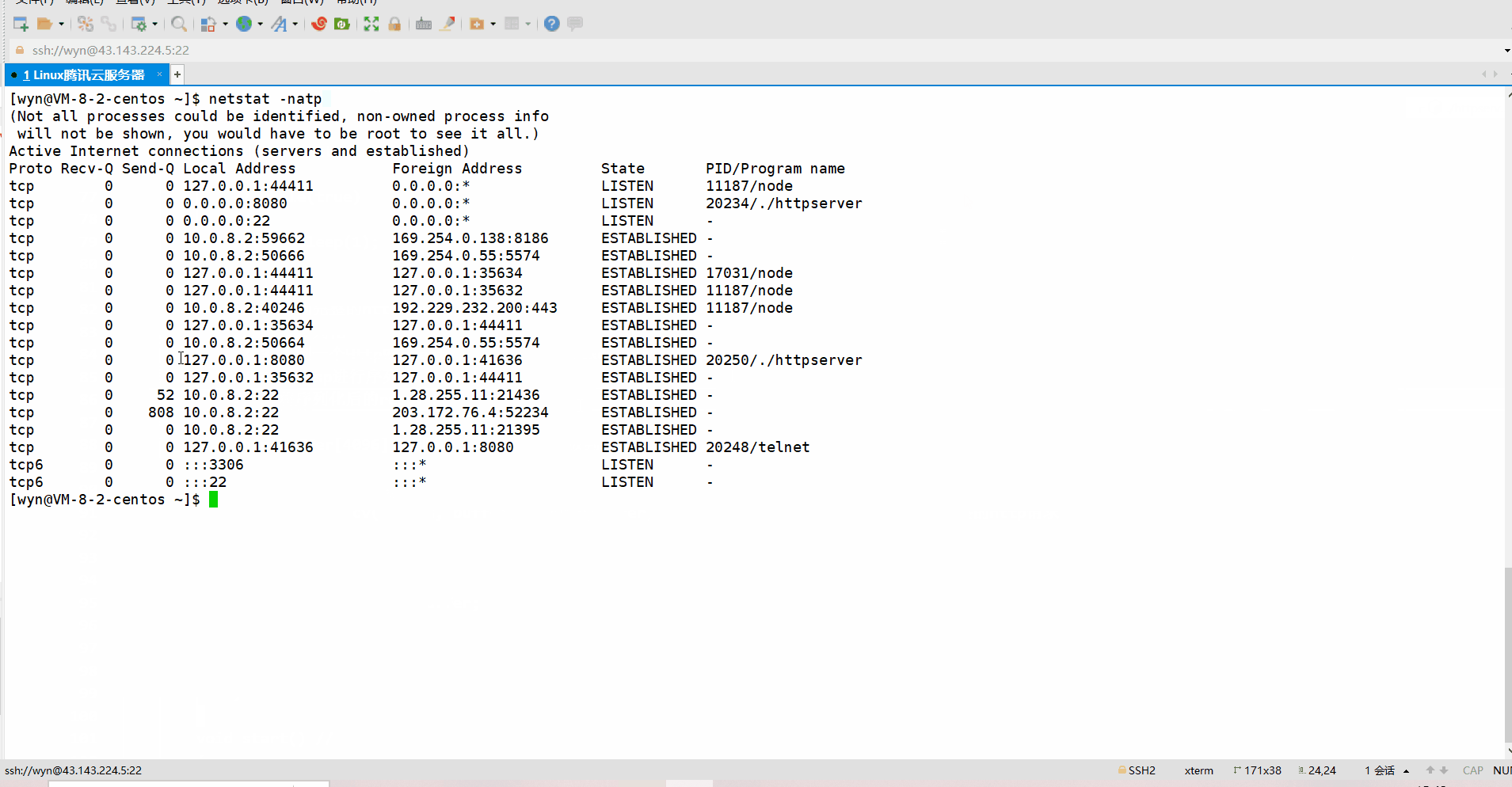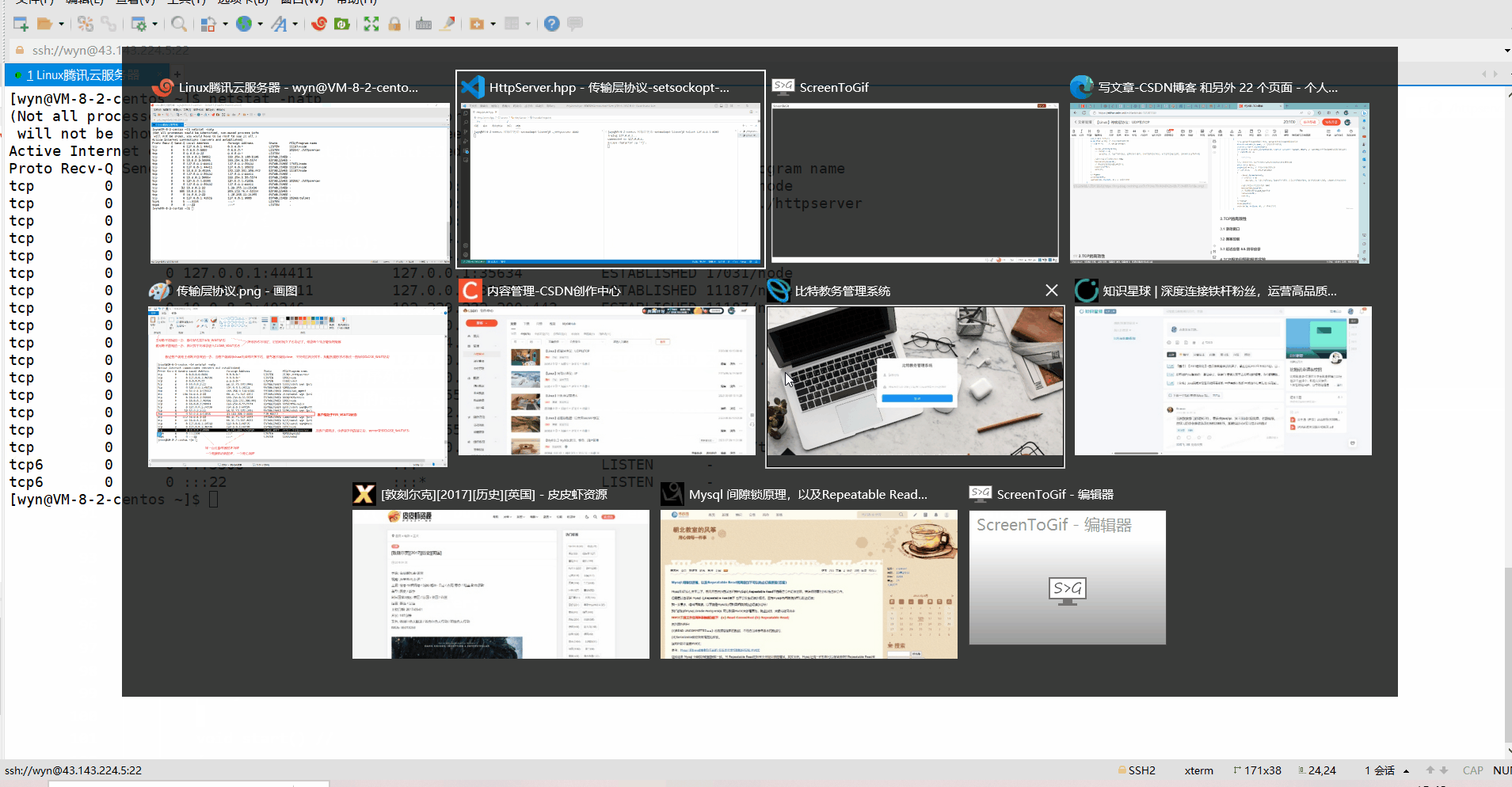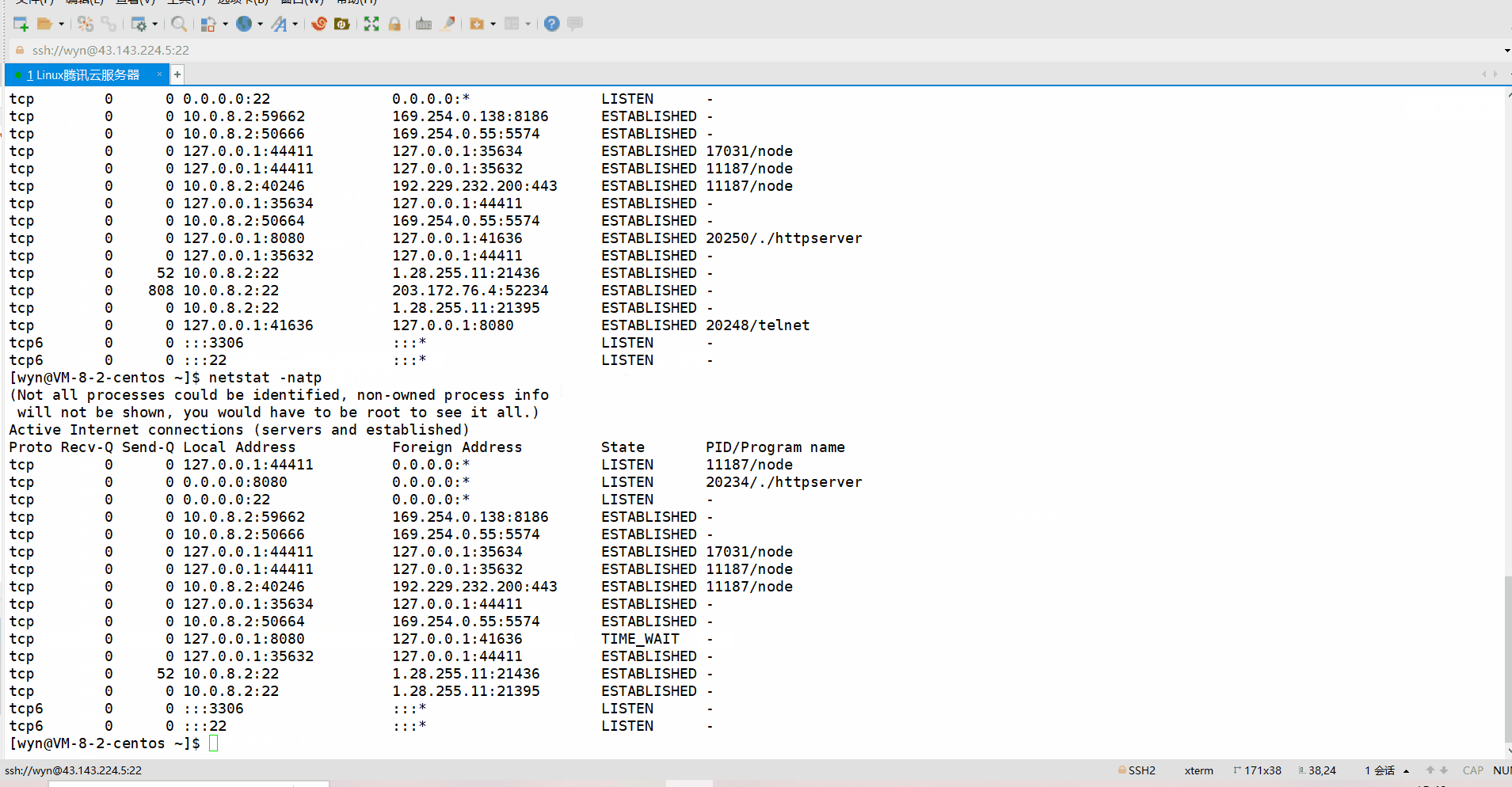
Este experimento es fácil de hacer, solo necesitamos dejar que el cliente que ha establecido una conexión finalice el proceso primero, desconecte la conexión y luego podemos ver el estado de la conexión del servidor a través de netstat.La conexión TCP del servidor está en el estado CLOSE_WAIT, y la conexión TCP del cliente está en el estado FIN_WAIT2. Dado que el cliente y el servidor se prueban en un servidor en la nube, al ver el estado de la red, podemos ver el estado de conexión del cliente y el servidor respectivamente.
Si nuestro servidor tiene una gran cantidad de estados CLOSE_WAIT, generalmente hay dos situaciones: una es que hay un error en el servidor y no hay cierre (sockfd) en el código del servidor, lo que hará que el servidor no se complete. las dos últimas olas. Otra situación es que el servidor puede estar bajo mucha presión ahora, como estar ocupado enviando mensajes al cliente, por lo que es demasiado tarde para ejecutar close (sockfd), pero esta situación es solo temporal. Después de que el servidor se recupere, puede ser completado y agitado dos veces.
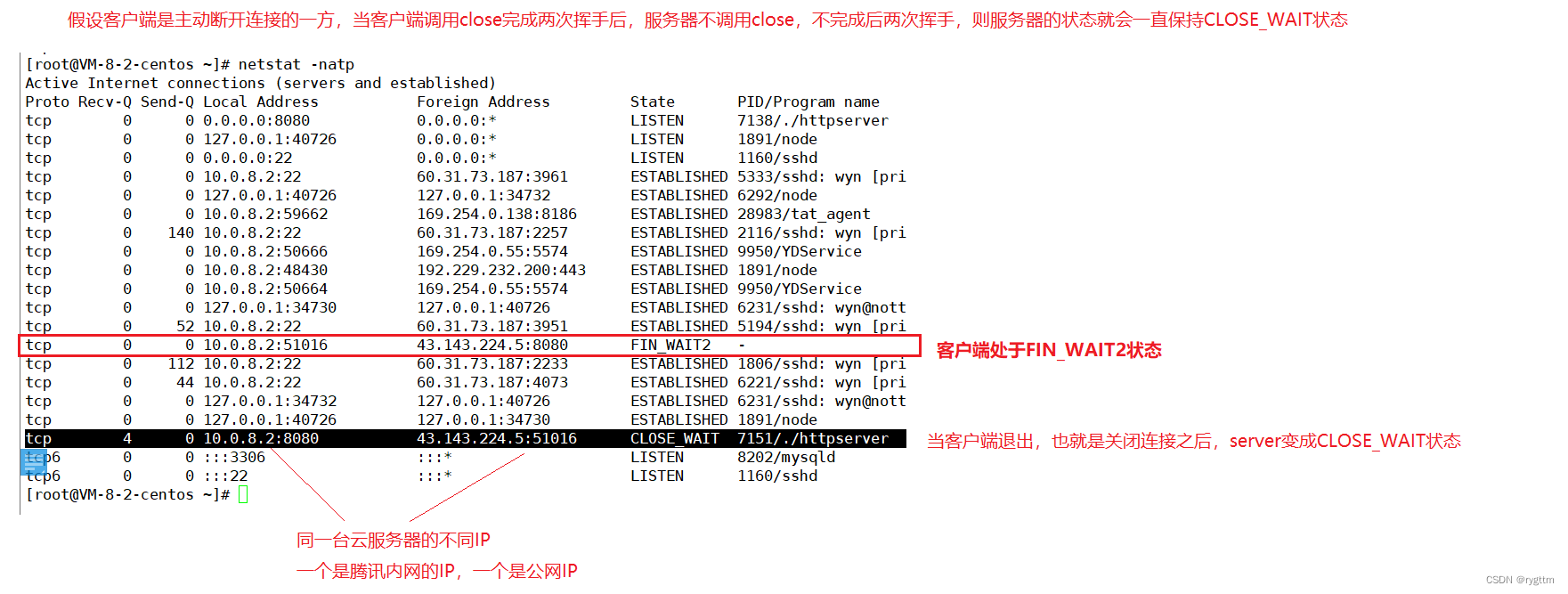
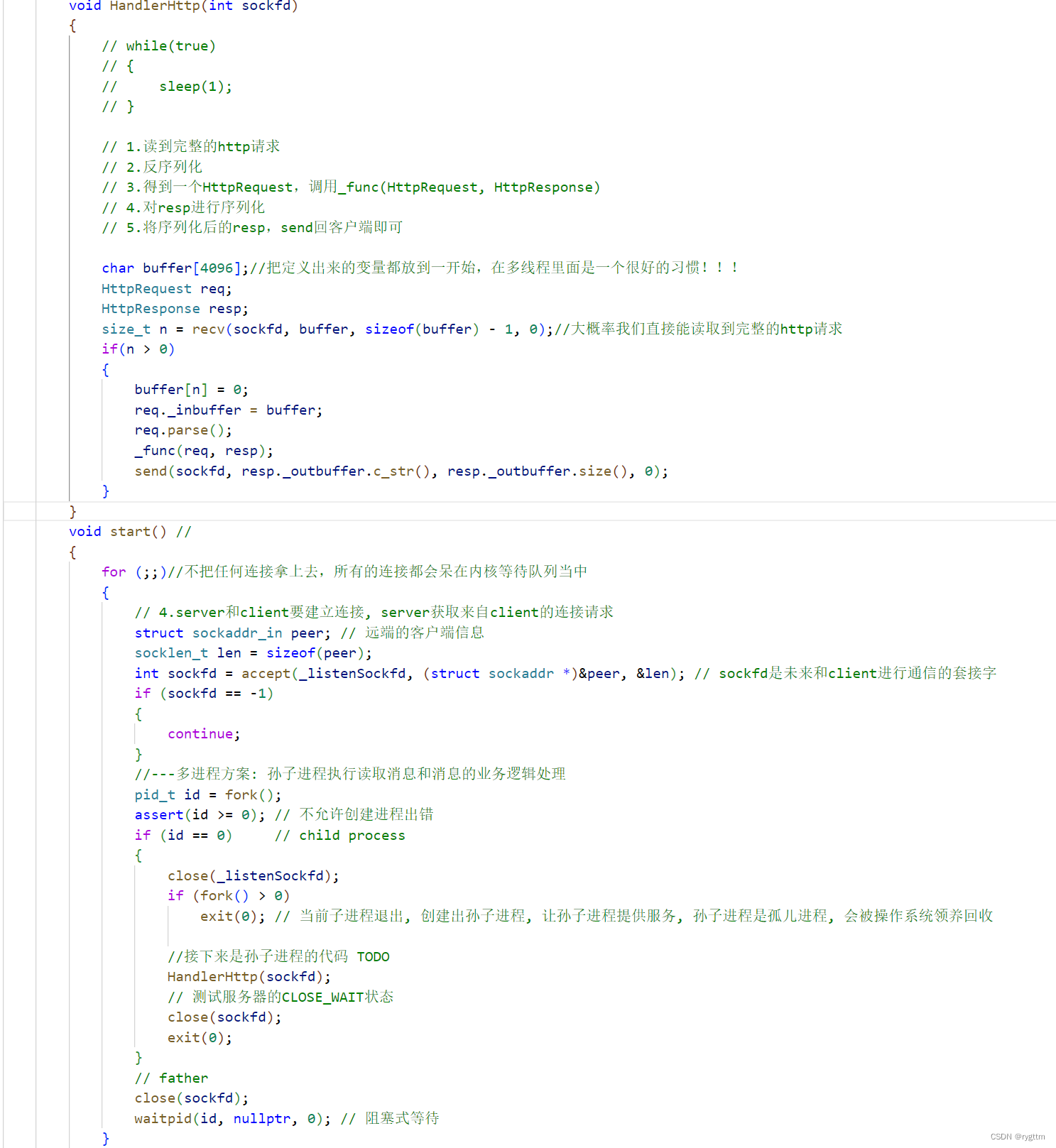
Si desea probar el estado CLOSE_WAIT, puede bloquear el código de cierre debajo de HandlerHttp(sockfd); de modo que cuando el cliente se desconecte, el servidor no llamará a close(sockfd), es decir, no se agitará dos veces después de la finalización. el estado del servidor permanecerá en el estado CLOSE_WAIT.
Si desea probar el estado TIME_WAIT, como se muestra en la segunda imagen a continuación, un servidor normal saldrá después de que el cliente salga y saludará dos veces después de llamar a close(sockfd), para que la conexión se desconecte por completo. Cuando el servidor sale solo, en realidad lee 0, lo que significa que el cliente ha salido y el servidor también debería salir en este momento.
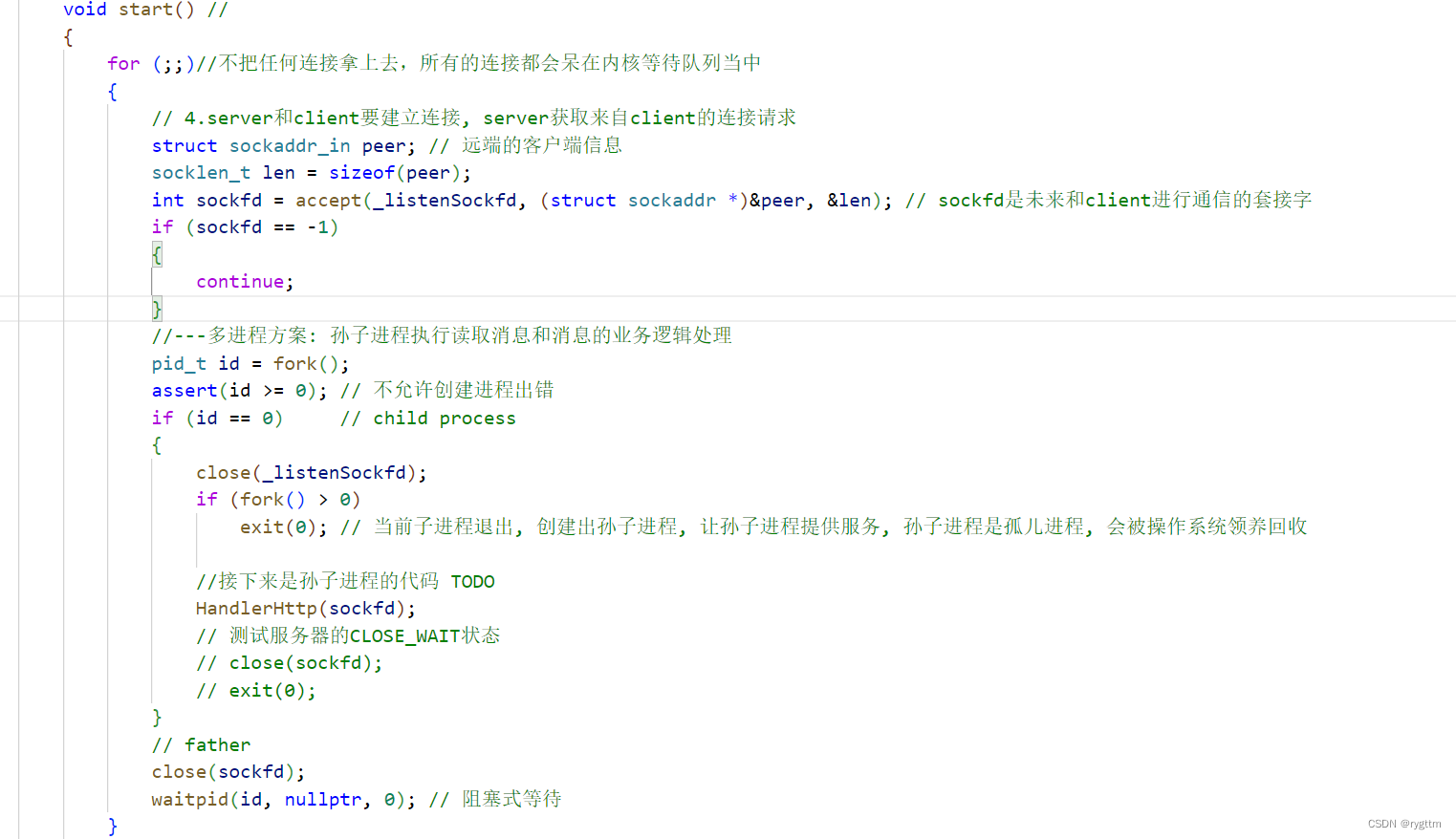
2.2.2 Prueba de estado TIME_WAIT
El siguiente es el proceso de prueba del estado TIME_WAIT, se puede ver que en el código del servidor luego de establecida una conexión se comunicará con el cliente una vez, es decir ejecutará el método HandlerHttp, pero mientras el servidor termine de ejecutarse este método, el servidor ejecutará close(sockfd), por lo que siempre que el servidor sea el que se desconecte pasivamente y las cuatro ondas se completen, el estado final del servidor será TIME_WAIT. la animación, el cliente es el que se desconecta activamente, y el servidor es el Desconectar pasivo.
2.2.3 ¿Por qué la parte que se desconecta activamente mantiene el estado TIME_WAIT para 2MSL?
¿Por qué la parte que se desconecta activamente mantiene el estado TIME_WAIT durante un período de tiempo después de que terminan las cuatro oleadas? Y esta vez es 2MSL (vida máxima del segmento)
Razón 1: para garantizar que la parte que se desconecta activamente, el mensaje ACK enviado por la última ola sea recibido por la otra parte tanto como sea posible, porque la parte que se desconecta activamente también puede volver a enviar el último Un mensaje ACK . (El concepto en el libro: terminación confiable de la conexión TCP)
MSL se refiere al tiempo máximo de supervivencia de un segmento de mensaje de izquierda a derecha o de derecha a izquierda. Tenga en cuenta que es el tiempo máximo de supervivencia. Tal tiempo máximo de producción, incluso si la condición de la red es muy mala, dentro de un MSL, el segmento de mensaje puede llegar al host de la otra parte.Si la condición de la red es buena, puede llegar al host de la otra parte sin un tiempo de MSL.
Si se pierde el último mensaje ACK, el servidor no recibirá el mensaje ACK al principio, y luego el servidor volverá a enviar el segmento del mensaje FIN.Cuando el cliente recibe el segmento del mensaje FIN nuevamente, el cliente se dará cuenta de que el último mensaje ACK El el segmento puede perderse, el cliente reenviará el último segmento ACK, y el servidor juzga que el segmento ACK se ha perdido + reenvía el segmento FIN por sí mismo. El máximo de estas dos veces es 2MSL, por lo que 2MSL continuo puede ser efectivo Está garantizado que incluso si se pierde el último mensaje ACK, la parte que se desconecta activamente aún puede tener la capacidad de reenviar el último segmento del mensaje ACK nuevamente.
Motivo 2: cuando las dos partes están desconectadas, es posible que aún queden paquetes persistentes en la red para garantizar que los paquetes persistentes se disipen . (El concepto en el libro: para garantizar que el último segmento TCP tenga tiempo suficiente para ser reconocido y descartado)
Puede haber una situación en la que, después de que el servidor envíe el segmento FIN, haya un segmento que lleve información (como el Segmento No. 6) se envía al cliente más tarde que el segmento FIN. Si el cliente está en el estado TIME_WAIT, puede tener tiempo suficiente para identificar el segmento No. 6 y descartarlo, lo que significa que puede haber Los mensajes persistentes se disipan por completo .
Y la duración de 2MSL puede disipar los segmentos de mensajes tardíos que no se han recibido en las dos direcciones de transmisión. Por ejemplo, el lado izquierdo envía un segmento de mensaje tardío al lado derecho, y el lado derecho también devolverá un segmento de mensaje después de recibir El segmento tardío, y el tiempo de ida y vuelta es como máximo 2MSL
El tiempo de MSL se puede encontrar en la siguiente ruta, el valor predeterminado es 60 s

2.2.4 Resuelva el problema de que el servidor no puede vincular el número de puerto original después de reiniciar inmediatamente
1.
En el pasado, cuando programamos sockets, nos encontramos con que a veces el servidor se reiniciaba inmediatamente y no podía vincular el número de puerto original, pero a veces sí podía vincular el número de puerto original. De hecho, era debido al estado TIME_WAIT.
Si cierra el cliente primero y luego cierra el servidor, el estado final del servidor es CERRADO. En este momento, reinicia inmediatamente el servidor para vincular el número de puerto original, y no habrá ningún problema de error de vinculación, porque el puerto número no está ocupado.
Si apaga el servidor primero, el estado final del servidor es TIME_WAIT. En este momento, reinicia inmediatamente el servidor para enlazar el número de puerto original. Debe ser un enlace fallido, porque el proceso del servidor original todavía ocupa el puerto 8080 ( tome 8080 como ejemplo), reinicia el servidor ahora y vincula el puerto 8080 nuevamente, por supuesto, se informará un error de vinculación. Debido a que un número de puerto solo puede vincularse a un proceso, un proceso puede vincular múltiples números de puerto, ya que un proceso puede abrir múltiples descriptores de archivo sockfd.
2.
Es un problema muy grave que el servidor se reinicie inmediatamente y no pueda vincular el número de puerto original. Por ejemplo, durante JD 618, el servidor está lleno de conexiones. Si el servidor cuelga accidentalmente debido al aumento del número de conexiones, el el servidor debe reiniciarse de inmediato, si el servidor no puede vincular el número de puerto original en este momento y se ve obligado a esperar 2MSL, es decir, 120 s, entonces todos los usuarios no podrán comprar en este momento, y JD.com no puede proporcionar servicios Durante el período 618, 1s es cientos de La facturación de 10,000, si espera 120s, cuánto perderá la empresa, por lo que el servidor debe poder reiniciarse inmediatamente y poder vincular el número de puerto original. Los servidores de grandes empresas básicamente vinculan números de puerto bien conocidos. Una vez que un servidor de la empresa vincula Si configura un número de puerto, no cambiará el número de puerto fácilmente.
3.
La solución no es difícil, solo necesita configurar la opción sockfd para reutilizar la dirección local SO_REUSEADDR, incluso si la estructura de conexión correspondiente al sockfd del servidor (activamente desconectado) está en el estado TIME_WAIT, la dirección del socket vinculada a sockfd (struct sockaddr_in local) también se puede reutilizar de inmediato, de modo que el servidor se pueda reiniciar de inmediato y aún pueda vincular el número de puerto original.
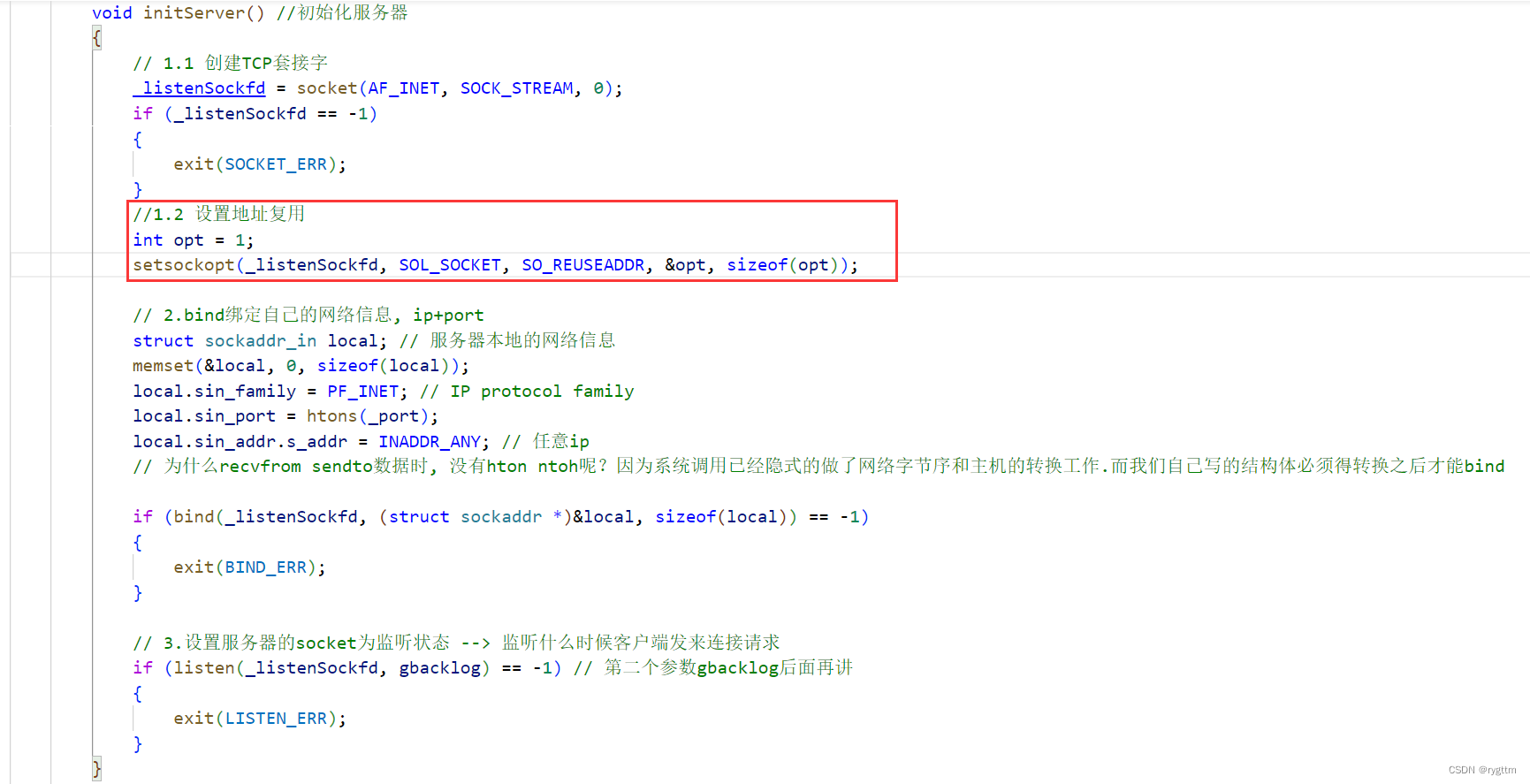
4.
Además de configurar la opción SO_REUSEADDR, también puede modificar el parámetro del kernel /proc/sys/net/ipv4/tcp_tw_recycle para reciclar rápidamente el sockfd cerrado y reciclar todos los recursos relacionados, como la estructura de conexión, la dirección del socket, etc. de modo que la parte que cierra activamente la conexión TCP no ingrese al estado TIME_WAIT en absoluto, lo que permite que el proceso del servidor reutilice inmediatamente la dirección del socket local. Extracto de: "Programación de servidor de alto rendimiento Linux"
3. La eficiencia de TCP
3.1 Ventana deslizante (enviar segmentos de datos en lotes + mecanismo de retransmisión de tiempo de espera de soporte)
1.
Cuando hablábamos antes del reconocimiento, para cada segmento de datos enviado, debe haber una respuesta de confirmación ACK. Después de recibir el ACK, se envía el siguiente segmento de datos. Este tipo de eficiencia de trabajo es muy baja. En la práctica, es para enviar un lote de mensajes en lotes. Al confirmar la respuesta, solo se puede devolver un segmento de mensaje ACK, y la realización del envío por lotes en realidad depende de la ventana deslizante en el búfer de recepción. Los segmentos de datos por lotes se pueden enviar en un punto En el tiempo Envíe directamente en Internet, mejorando en gran medida la eficiencia de transmisión de TCP.
Además de mejorar la eficiencia, la ventana deslizante en realidad admite un mecanismo de retransmisión de tiempo de espera. Sabemos que cuando se envía el segmento de datos, puede haber problemas de pérdida de paquetes, y para resolver la pérdida de paquetes, el segmento de datos debe retransmitirse, por lo que el No se recibe ACK. El segmento de datos no debe eliminarse inmediatamente, sino que debe almacenarse temporalmente durante un período de tiempo, y el segmento de mensaje que no recibió el ACK pero que se envió se almacena temporalmente en la ventana deslizante.

2.
De hecho, podemos dividir lógicamente el búfer de envío en 4 partes, de izquierda a derecha: datos que han sido enviados y ACKed al mismo tiempo (esta parte de datos puede ser sobreescrita por nuevos datos), datos que han sido enviados pero no ACKed (esta parte de los datos no se puede sobrescribir con datos nuevos), los datos que no se han enviado (los datos que se acaban de copiar del búfer de la capa de aplicación) y el espacio restante sin datos (de hecho, cuando el espacio se abre, hay datos inicializados)
. A medida que la ventana deslizante se mueve hacia la derecha, los datos de la derecha se enviarán gradualmente y los datos de la izquierda serán respondidos. Si es necesario retransmitir el segmento de datos, el se retransmitirá el segmento de datos de la ventana deslizante.

3.
Podemos considerar el búfer como un gran búfer. De hecho, la llamada ventana deslizante es en realidad el espacio formado entre los subíndices de las matrices win_start y win_end en el búfer. La ventana deslizante se mueve, de hecho, es win_start++ y win_end++ Cuando los datos en la ventana deslizante son confirmados por ACK, la ventana deslizante se moverá hacia la derecha.
Pero, ¿nuestra comprensión de las ventanas corredizas se detiene ahí? ¡Por supuesto que no! ¡Este es solo el comienzo!
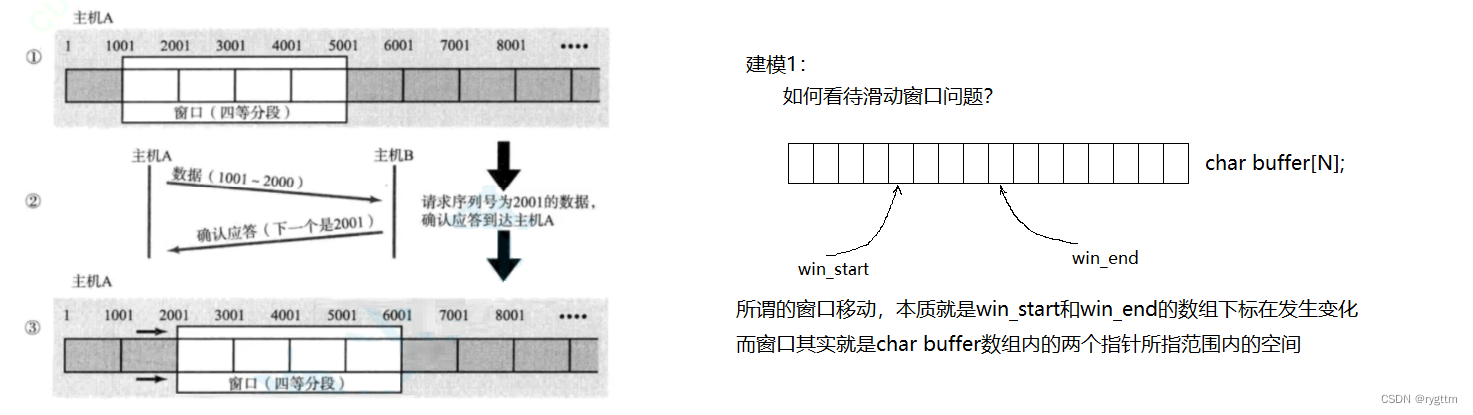
4.
A continuación, haremos muchas preguntas y profundizaremos nuestra comprensión de las ventanas corredizas respondiendo estas preguntas.
(1) ¿Cómo se establece el tamaño de la ventana corredera? ¿Cómo cambiará el tamaño en el futuro?
El tamaño de la ventana deslizante siempre debe estar vinculado a la capacidad de recepción de la otra parte, porque el tamaño de la ventana deslizante = el número de segmentos de datos enviados en lotes al mismo tiempo. Sabemos que TCP tiene control de flujo y el número de segmentos de datos enviados en lotes a la vez en realidad lo determina la otra parte. El tamaño de la ventana de 16 bits y la congestión de la red (se discutirá el siguiente control de congestión, permítanme mencionarlo primero), por lo que el tamaño de la ventana deslizante = min (tamaño de la ventana de 16 bits, tamaño de la ventana de congestión), si con Cuando la situación de la red mejora y la capacidad de recepción de la otra parte mejora, la ventana deslizante se hará más grande de forma natural. capacidad de recepción de la otra parte, siempre que haya una disminución, la ventana deslizante naturalmente se volverá más pequeña, porque el tamaño de la ventana deslizante es el mínimo de los dos.
Al principio, win_start=0, win_end=win_start+tcp_win (capacidad de recepción de la otra parte), en realidad es un error pensar así, porque también se debe considerar la congestión de la red, pero es posible entenderlo de esta manera por el momento, en la mayoría de los casos la red es Buena
(2) ¿la ventana necesariamente se desliza hacia la derecha? ¿Puedes deslizar hacia la izquierda?
La ventana deslizante no necesariamente se desliza hacia la derecha y puede permanecer estacionaria. Por ejemplo, si se pierden todos los paquetes enviados por el remitente, o se pierde el paquete ACK del mensaje enviado, la ventana deslizante permanecerá estacionaria en ambos casos. . Por supuesto, en circunstancias normales, la ventana deslizante se moverá hacia la derecha. Por ejemplo, si el segmento más a la izquierda recibe un ACK, la ventana deslizante se moverá hacia la derecha.
Pero la ventana deslizante no debe deslizarse hacia la izquierda. Los datos de la izquierda han sido ACKed, y los datos de la ventana deslizante no han sido ACKed. ¡No es razonable deslizarse hacia la izquierda!
(3) ¿Se mantendrá constante el tamaño de la ventana deslizante? ¿Se hará más grande? ¿Se hará más pequeño? ¿Cuál es la base del cambio?
El tamaño de la ventana deslizante permanecerá sin cambios. Por ejemplo, en los dos casos de pérdida de paquetes que mencionamos anteriormente, el tamaño y la posición de la ventana deslizante permanecerán sin cambios.
La ventana deslizante se hará más grande. Por ejemplo, si la capa de aplicación de la otra parte elimina todos los datos en el búfer del socket, el espacio restante en el búfer aumentará de inmediato y la situación de la red siempre será buena. Entonces, el La ventana deslizante se puede ampliar para enviar datos. En este momento, se pueden enviar más datos en lotes a la vez.
La ventana deslizante también se hará más pequeña. Por ejemplo, si la capa de aplicación de la otra parte no elimina los datos de la capa de transporte, ya que el búfer de recepción de la otra parte continúa recibiendo segmentos de datos, la capacidad de recepción de la otra parte el partido disminuirá, y en este momento la ventana deslizante también seguirá hacia abajo.
(4) ¿Qué debo hacer si el mensaje ACK recibido no es el mensaje del lado izquierdo de la ventana, sino el del medio o el del lado derecho? ¿La ventana todavía se desliza?
El mensaje ACK recibido está en el medio (lo mismo es cierto para el lado derecho). Generalmente, hay dos situaciones, una es que el segmento del mensaje izquierdo se pierde y el otro es que el segmento del mensaje izquierdo no se pierde, pero el ACK correspondiente El segmento se pierde.
Para el primer caso, en la ventana deslizante, suponiendo que el número de serie del segmento perdido es 1000 y el número de serie del segmento enviado con éxito es 2000, los datos perdidos son en realidad los datos de 1000 bytes del número de serie 1000- 1999, y Todos los segmentos de mensajes enviados más tarde obtienen ACK, pero vale la pena señalar que ¿cuáles son los números de secuencia de confirmación de estos segmentos de mensajes ACK? Cuando aprendimos el mecanismo de respuesta de reconocimiento antes, sabíamos que el número de secuencia de reconocimiento indicaba que se habían recibido todos los datos antes del número de secuencia de reconocimiento, por lo que los números de secuencia de reconocimiento de estos segmentos ACK devueltos eran todos 1000, y el remitente sabía 1000 en esta vez ¡El segmento numérico se perdió durante la transmisión! Eso activará el mecanismo de retransmisión de tiempo de espera.
Para el segundo caso, si solo se pierde el segmento ACK, entonces el número de secuencia de confirmación del segmento ACK devuelto correspondiente al segmento enviado con éxito será normal, y esta situación no causará ningún problema, la ventana deslizante se puede mover a la derecho normalmente.
(5) ¿La ventana deslizante se convertirá en 0?
Sí, si la capacidad de recepción de la otra parte es 0, la ventana deslizante también será 0. Por ejemplo, el búfer de la otra parte está lleno y la capa superior no ha tomado los datos en el búfer, entonces la capacidad de recepción en este momento es el tamaño de la ventana de 16 bits, el valor será 0
(6) ¿La ventana deslizante sigue deslizándose hacia la derecha? ¿Qué debo hacer si el espacio restante no es suficiente?
De hecho, el kernel mantiene el búfer de envío como una estructura de anillo, por lo que la ventana deslizante se deslizará hacia la derecha todo el tiempo, y la llamada estructura de anillo se realiza realmente mediante la operación de módulo. cambios de ventana, win_start y win_end Aumentará o permanecerá sin cambios en consecuencia. Después del cambio, puede hacer win_start y win_end% = el tamaño del búfer para evitar que el subíndice cruce el límite. De esta manera, se mantiene una cola de anillo .

3.2 Control de Congestión
3.2.1 Control de congestión y mecanismo de retransmisión por tiempo de espera (pérdida de paquetes en áreas grandes: control de congestión, pérdida de paquetes en áreas pequeñas: retransmisión por tiempo de espera)
1.
Todas las estrategias y mecanismos de TCP de los que hablamos antes en realidad se refieren a los dos extremos de la comunicación, no al enlace de transmisión de datos en la red intermedia. Además de los problemas de ambas partes, la pérdida de paquetes también puede ser causada por problemas en la red de enlaces intermedios La pérdida de paquetes debido a anomalías en la red o presión excesiva requiere que TCP realice el control de congestión. Por lo tanto, el tamaño de la ventana deslizante no solo debe considerar la capacidad de recepción de la otra parte, sino que también considera la situación de la red de enlace intermedio.
TCP presenta muchos mecanismos para garantizar la confiabilidad de la transmisión de datos de la red, como control de flujo, retransmisión de tiempo de espera, respuesta de confirmación, administración de conexión, y también presenta mecanismos como ventana deslizante y control de congestión para garantizar la eficiencia de transmisión de datos de red. la confiabilidad de TCP es demasiado deslumbrante, lo que hace que muchas personas ignoren la eficiencia de TCP, pero de hecho, TCP también es muy eficiente.
Entonces, ¿te atreves a decir que UDP debe ser más eficiente que TCP? Aunque mucha gente en Internet lo diga, yo no me atrevo a decirlo.

2.
Si el cliente envía un lote de segmentos de datos al servidor y solo se pierden unos pocos segmentos de datos, el cliente no sentirá nada, simplemente retransmitirá directamente después de un tiempo de espera, pero si se pierden muchos segmentos de datos, el cliente pensará que en este momento hay un problema con la red, porque bajo la gestión del mecanismo de control de flujo, un lote de segmentos de datos enviados debe cumplir con la capacidad de recepción de la otra parte.Si hay una gran área de pérdida de paquetes en este momento, debe haber un problema con el entorno de la red.Y si hay un problema con la red, se necesita el control de congestión de TCP para aliviar la presión de la red.
Por lo tanto, la confiabilidad de TCP no solo considera los problemas que pueden ocurrir entre las dos partes en la comunicación, sino que también considera los problemas que pueden ocurrir en la red de enlace intermedio.

3.
Si se produce una gran pérdida de paquetes de red en este momento, ¿puede TCP seguir adoptando la estrategia de retransmisión por tiempo de espera?
Lo que necesita saber es que no solo usted y el servidor se están comunicando en la red, sino que otros hosts también se están comunicando. Si TCP adopta una estrategia de retransmisión de tiempo de espera, entonces todos los hosts adoptarán una estrategia de retransmisión de tiempo de espera. Originalmente, la presión sobre el La red ya es lo suficientemente grande, pero como resultado, todos los hosts siguen metiendo paquetes en la red como locos, y el resultado es otra gran área de pérdida de paquetes, porque el entorno de la red tiene problemas en este momento, como demasiado mucho ancho de banda Congestión de datos de red estrecha. Por lo tanto, las retransmisiones solo exacerbarán el problema de la falla de la red.
El enfoque correcto debería ser permitir que todos los hosts cumplan con el mecanismo de detención. La red tiene la capacidad de recuperarse. Mientras todos los hosts no envíen mensajes temporalmente, o solo envíen una pequeña cantidad de mensajes, espere a que la red se recupere. Continúe comunicándose, esta es la respuesta correcta. Y cuando hay una gran área de pérdida de paquetes en la red, todos los hosts se detienen (solo una declaración visual, de hecho, el host solo envía una pequeña cantidad de paquetes de detección), y el mecanismo de espera para la recuperación de la red es en realidad control de congestión
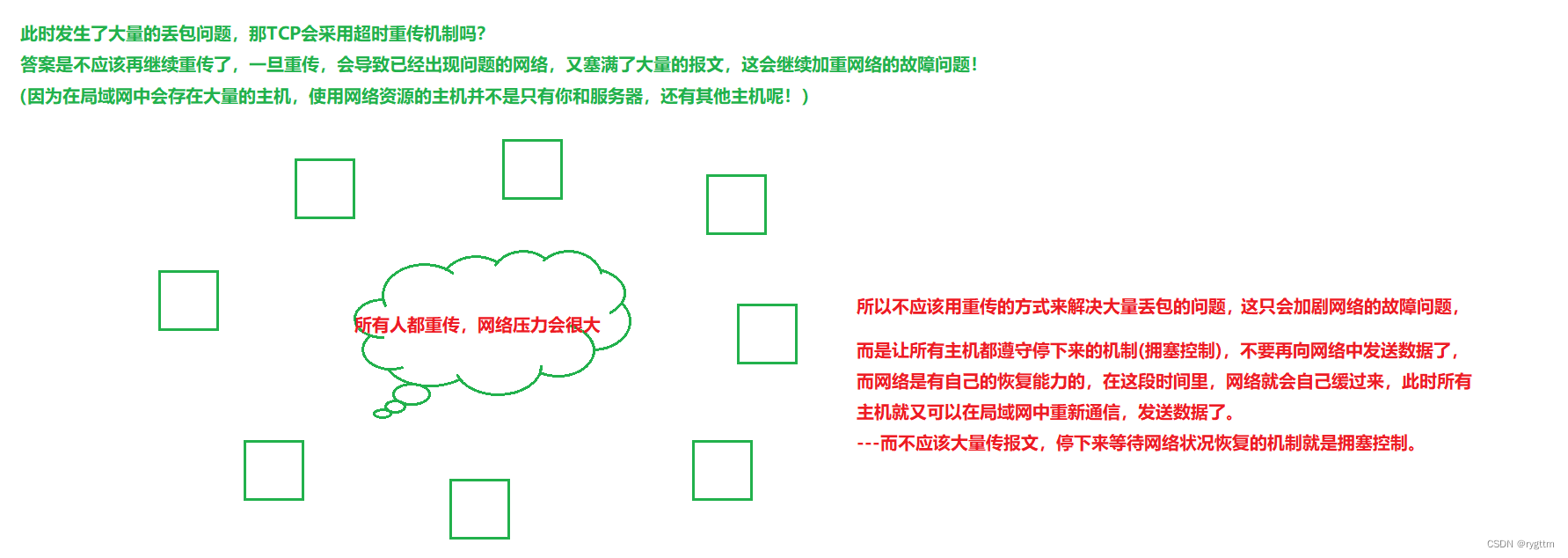
3.2.2 Introducción de ventana de congestión, MSS y SMSS
1.
Cuando la red esté congestionada, el remitente enviará un segmento de detección con el tamaño de la ventana de congestión para detectar el estado de la red.
La unidad del tamaño de la ventana de congestión es en realidad SMSS (tamaño máximo del segmento de segmento de vida máxima del segmento), SMSS es el tamaño del segmento de datos más grande que el remitente puede enviar en una conexión TCP. El valor de SMSS es un valor estimado basado en la consideración de las condiciones de la red y la capacidad de recepción de la otra parte. SMSS se utiliza para optimizar la transmisión de datos y el control de la congestión. Incluso en condiciones de red muy malas, los SMSS se pueden enviar al host del mismo nivel. con una alta probabilidad.
SMSS no se negocia ni se decide a través del campo de opción durante la fase de protocolo de enlace de tres vías de TCP, pero después de que se establece la conexión, cuando se comunica realmente, el remitente lo ajusta dinámicamente de acuerdo con los comentarios de la red y el receptor, por lo que el tamaño de la unidad de la ventana de congestión es SMSS. Por ejemplo, cuando se produce una congestión en la red, el host enviará una cantidad específica de mensajes SMSS de acuerdo con la potencia de 2.

2.
MSS (Tamaño máximo de segmento) es la fase de protocolo de enlace de tres vías de TCP. Se negocia a través de la opción de longitud máxima de segmento de tipo = 2. MSS se refiere a la longitud máxima de segmento admitida por el módulo TCP al enviar un mensaje. Por lo general, este valor es MTU-40, debido a que MTU (Unidad máxima de transmisión) es la unidad de transmisión más grande de la capa de enlace de datos, los 40 bytes restados incluyen 20 bytes del encabezado TCP y 20 bytes del encabezado IP, suponiendo que ninguno el encabezado TCP ni el encabezado IP contiene campos de opción, y este también es el caso general.
Por lo tanto, controlar el segmento TCP máximo a MTU-40 puede evitar efectivamente la fragmentación de la capa IP, porque la fragmentación y el ensamblaje de IP aumentarán mucho el consumo de red sin ningún motivo. Si podemos evitar la fragmentación, entonces debemos hacer todo lo posible para hacerlo. él.
3.
En resumen, MSS es el tamaño máximo de segmento de la capa TCP negociado durante la fase de negociación de tres vías.Si el tamaño de MSS se establece en la opción de encabezado TCP, entonces en la comunicación real, sin importar qué segmento envíe, no puede exceder este tamaño.
En SMSS, después de que el protocolo de enlace de tres vías sea exitoso, el remitente ajusta dinámicamente el tamaño del segmento del mensaje de acuerdo con los comentarios de la red y la capacidad de recepción de la otra parte durante la comunicación real, que en realidad es el tamaño de la unidad de la ventana de congestión.
3.2.3 Algoritmo de inicio lento + algoritmo para evitar la congestión (crecimiento exponencial antes del umbral, crecimiento lineal después del umbral)
1.
El inicio lento es una muy buena estrategia para el control de la congestión. Cuando la red está congestionada, TCP realizará un inicio lento y enviará segmentos del tamaño de SMSS en una potencia exponencial de incremento de 2. Sabemos que el crecimiento exponencial es en realidad un crecimiento explosivo que puede crecer lentamente en la etapa inicial, pero a medida que crezca, crecerá más y más rápido más adelante.
Y esto solo es adecuado para el control de congestión.Si la condición de la red no es buena en la etapa inicial, puede comenzar lentamente y enviar una pequeña cantidad de segmentos del tamaño de SMSS, lo que puede hacer que la condición de la red se recupere rápidamente.Después de la red la condición se recupera más tarde, la ventana de congestión también aumenta a Es muy grande, lo suficiente como para admitir la transmisión de una gran cantidad de segmentos de datos, de modo que la eficiencia de la transmisión de datos de la red se pueda mejorar rápidamente.

2.
La ventana de congestión en realidad tiene un umbral ajustado dinámicamente ssthresh (umbral de inicio lento).Cuando la ventana de congestión aumenta continuamente en forma de una potencia exponencial de 2 en la etapa inicial, una vez que se supera este umbral, la ventana de congestión aumentará linealmente (cada vez +1), cuando la red se vuelve a congestionar, la ventana de congestión se establece nuevamente en 1 y el umbral se reajusta a la mitad del tamaño de la ventana de congestión cuando se produce la congestión de la red. El valor inicial del umbral es 65535 bytes , el valor máximo de la ventana. La ventana muestra CWND en unidades de SMSS, pero en realidad está en bytes, y la abscisa está en unidades de RTT (retraso de ida y vuelta de tiempo de ida y vuelta). El tamaño inicial de ssthresh dibujado en la cifra es de 16 SMSS, pero en realidad es de 65535 bytes.
3.
La ventana de congestión no solo garantiza la confiabilidad, sino que también realiza un inicio lento para esperar la recuperación de las condiciones de la red cuando se produce una gran cantidad de pérdida de paquetes, y también garantiza una alta eficiencia.La ventana de congestión cambia constantemente, lo que también puede ajustar la tamaño de la ventana deslizante al mismo tiempo para garantizar la transmisión de datos.Eficiencia, es decir, cuidar las condiciones de la red y al mismo tiempo mejorar la eficiencia de la transmisión de datos.
3.3 Acuse de recibo retrasado y acuse de recibo superpuesto
1.
La respuesta retrasada es un medio para mejorar la eficiencia de la transmisión de datos.Si el receptor devuelve una respuesta ACK inmediatamente, la ventana de retorno puede ser relativamente pequeña, pero si se retrasa por un período de tiempo, durante este tiempo, la capa superior de la el receptor puede quitar el búfer Los datos en el área, en este momento, devuelven la respuesta ACK, el tamaño de la ventana en la respuesta ACK será relativamente grande y el remitente puede enviar más datos la próxima vez, lo que puede mejorar la eficiencia de los datos transmisión.
Vale la pena señalar que mientras haya un retraso, la capa superior definitivamente tomará los datos en el búfer dentro de este período. Este es un evento probabilístico. Solo significa que hay una alta probabilidad de que la capa superior tome Puede mejorar la eficiencia. Si no lo quita, entonces no puede quitarlo. No hay nada absoluto en este mundo. Todo es probabilístico, pero se divide en alta probabilidad y pequeña probabilidad. Lo mismo es cierto para las respuestas tardías, pero es un evento de probabilidad relativamente alta.
2.
Debe recordarse que cuanto mayor sea la ventana, mayor será el rendimiento de la red y mayor será la eficiencia de transmisión (se transmiten más datos a la vez).El mecanismo de TCP para mejorar la eficiencia es garantizar que la red no esté congestionada. Mejorar la eficiencia de transmisión tanto como sea posible.
¿Se puede retrasar el reconocimiento de todos los paquetes? De hecho, hay un límite.
Límite de cantidad: responda una vez cada N paquetes, generalmente N es 2 (el sistema operativo de diferentes versiones puede ser diferente) Límite de
tiempo: responda una vez cuando se exceda el tiempo máximo de demora, generalmente el tiempo máximo de demora es de 200 ms (el sistema operativo de diferentes versiones puede ser diferente) ) Diferencias)
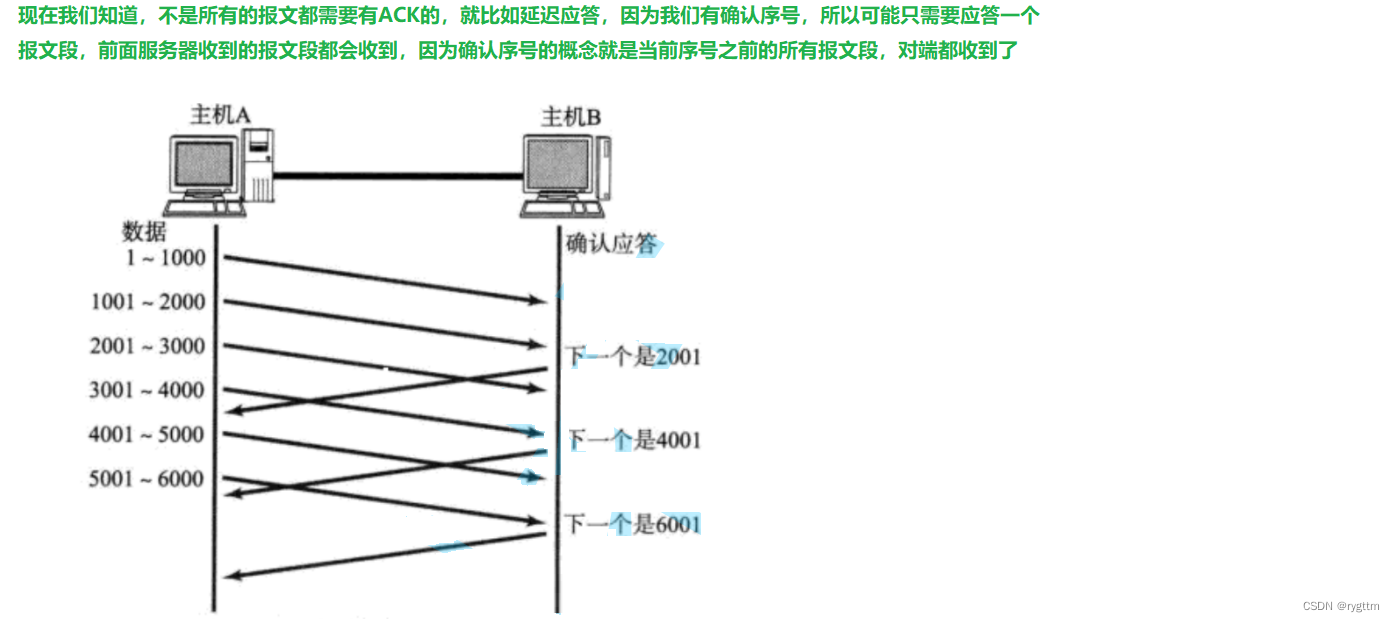
3.
Piggybacking también es un medio para que TCP mejore la eficiencia de la transmisión de datos. Hemos visto esto hace mucho tiempo. Por ejemplo, en la segunda fase de negociación de la negociación de tres vías, el servidor también quiere establecer una conexión con el cliente. , y el servidor enviará un mensaje al cliente. Un segmento de mensaje SYN, y este segmento de mensaje SYN se puede complementar con ACK para responder al segmento de mensaje SYN enviado por el cliente anterior al servidor, por lo que aprovechar la respuesta es muy simple , siempre que los indicadores ACK y SYN de este segmento de mensaje estén configurados como válidos.
4. Problemas relacionados con TCP y experimentos relacionados
4.1 Excepciones de TCP
1.
Si el proceso del cliente o servidor cuelga, ¿qué pasa con la conexión establecida por TCP antes? ¿Qué pasa si la computadora está apagada?
Cuando finaliza el proceso, el sistema operativo liberará todos los recursos relacionados con el proceso, incluidos los descriptores de archivos de socket, liberará sockfd y aún enviará segmentos FIN, lo que activará cuatro manos agitadas, por lo que no es diferente del apagado normal. Cuando probamos el estado TIME_WAIT anteriormente, en realidad vimos este fenómeno. El proceso del cliente finalizó y la conexión se desconectó normalmente. Por lo tanto, no hay diferencia en términos del efecto de la finalización del proceso y llamar a close(sockfd) directamente.
Lo mismo es cierto para el apagado de la computadora. Cuando generalmente apagamos la computadora, si hay procesos no cerrados, la computadora debe tener un aviso y le dirá que algunas aplicaciones no están cerradas. ¿Desea elegir forzar el apagado? Si forzamos el apagado, en realidad es el sistema operativo el que elimina manualmente el proceso en ejecución, y el efecto es en realidad el mismo que la finalización del proceso.
Desconecte la corriente o desconecte el cable de red, ¿qué debo hacer con la conexión anterior?
Desconecte la fuente de alimentación o desconecte el cable de red, el aislamiento físico es en realidad el más mortal, incluso el cable de red se ha ido, ¿cómo envía el segmento FIN? Pero no se preocupe, el servidor todavía piensa que la conexión es normal después de que el cliente se desconecta o el cable de red es anormal, y el servidor tendrá su propia estrategia de conexión, que periódicamente enviará segmentos de detección para preguntar si el cliente está en línea Cuando el envío llega a un cierto número de veces, el servidor se desconectará automáticamente.
4.2 Realice una transmisión confiable con UDP
1.
De hecho, existe una solución correspondiente para usar UDP para lograr una transmisión confiable, porque el TCP que tenemos ante nosotros es el mejor protocolo de transmisión confiable del mundo, y UDP también quiere realizarlo, de hecho, está imitando el kernel en el mecanismo de capa de capa de aplicación TCP para lograr.
Por ejemplo, los números de serie se introducen en la capa de aplicación para garantizar el orden de los datos. Introduzca una respuesta de confirmación para garantizar que el extremo del mismo nivel reciba los datos. Introduzca la retransmisión de tiempo de espera, cuando se produce la pérdida de paquetes, el paquete de datos se puede reenviar.
4.3 Comprender el segundo parámetro atraso de escucha (longitud de conexión completa = atraso + 1)
1.
En el pasado, cuando escribimos la programación del socket tcp, escuchamos el segundo retraso de parámetros de la escucha de la interfaz entrante. En ese momento, lo configuramos directamente en un tamaño de 5, pero de hecho había una razón para ello, y en realidad representaba la cola de escucha del núcleo, la longitud máxima de .
2.
En la vida normal, cuando comemos Haidilao, siempre vemos algunas líneas de espera fuera de Haidilao. ¿Por qué Haidilao tiene tal mecanismo de cola? De hecho, es para mejorar la tasa de utilización de los recursos, a fin de lograr el propósito de ganar dinero. Los lugares para comer en Haidilao son limitados, y a menudo sucede que todos los asientos están llenos y habrá un grupo de personas esperando afuera. De hecho, cuando algunos asientos quedan vacantes, estos asientos vacantes se pueden volver a llenar de inmediato. uso, asegurándose de que los asientos se utilicen la mayor parte del tiempo, entonces la facturación del restaurante Haidilao aumentará aún más, por lo que la esencia de hacer cola es dejar que nuestros recursos se utilicen inmediatamente cuando estén libres, para mejorar la utilización tasa de recursos Para Haidilao, este recurso es en realidad un asiento de comedor, y para una computadora, en realidad es tiempo y espacio de memoria. ¿Cómo debe determinarse la longitud de esta cola? Si hay 50 personas haciendo fila afuera de Haidilao, ¿todavía comeré hoy? Tal vez aún no es hora de comer, así que lo explico aquí, si la cola es más corta, podría intentar hacer cola de nuevo, si es muy larga, no haré cola.
En el kernel, el sistema operativo en realidad mantiene una cola de monitoreo del kernel para TCP. Las conexiones en esta cola están todas completamente conectadas, lo que indica que han completado el protocolo de enlace de tres vías. Siempre que accept tome estas conexiones, estas conexiones se pueden poner en uso inmediatamente Comunicación TCP, es posible que el proceso del servidor esté ocupado haciendo otras cosas y no llame a la interfaz de aceptación, pero en este momento el servidor ha escuchado muchas solicitudes de conexión TCP, en este momento el servidor pondrá estas conexiones en la cola de espera del kernel, cuando el servidor ejecuta Al aceptar el código, el servidor tomará una conexión completa de la cola de espera del kernel y luego usará el sockfd devuelto por accept para la comunicación TCP para la transmisión de datos posterior.

3.
Por lo tanto, accept no participa en el protocolo de enlace de tres vías TCP. Accept solo es responsable de obtener la conexión completa de la cola de espera del kernel y luego iniciar el trabajo de comunicación de red posterior. El protocolo de enlace de tres vías TCP real se inicia y se completa con las llamadas al sistema de conexión y escucha.
Cuando se llama a connect, el cliente enviará un segmento de mensaje SYN al servidor, y al mismo tiempo el cliente ingresa al estado SYN_SENT, y el servidor ya ha ingresado al estado LISTEN debido a la llamada a escuchar.Cuando el servidor recibe el mensaje SYN segmento, el servidor devolverá un segmento de mensaje El SYN+ACK, y luego el servidor entra en el estado SYN_RCVD. Cuando el cliente recibe el ACK, el cliente ya piensa que la conexión se ha establecido con éxito, y por lo tanto entra en el estado ESTABLECIDO. Cuando el El cliente ve el segmento de mensaje SYN, también devolverá un segmento de mensaje ACK al servidor, y el servidor ingresará al estado ESTABLECIDO después de recibirlo.Durante todo el proceso de negociación de tres vías, no se acepta la participación.
4.
Configuré la acumulación en 2. Al mismo tiempo, después de inicializar el servidor, no llamará a aceptar para sacar ninguna conexión completa de la cola de espera del núcleo al inicio, de modo que todas las conexiones con el servidor que completan los tres -way handshake y establecer una conexión exitosa permanecerán dentro de la cola de espera del núcleo.
Del siguiente código, también podemos ver que si desea implementar un servidor de subprocesos múltiples, solo necesita asegurarse de que un subproceso siempre pueda obtener la conexión de la cola de conexión completa, y luego otros subprocesos brindan servicios de comunicación para la conexión. que se obtiene Es un servidor multiproceso. En cuanto a la interfaz de escucha, se ha llamado tan pronto como se inicializó el servidor. Cuando se inicia el servidor, no hay necesidad de preocuparse por la interfaz de escucha, solo llame a aceptar.
A partir de los resultados experimentales se puede ver que cuando cuatro clientes se conectan al servidor, la situación de conexión del cuarto cliente es ligeramente diferente. El servidor no cree que la conexión se haya establecido correctamente y el estado es SYN_RECV, mientras que el cliente piensa que la conexión se ha establecido con éxito. El estado es ESTABLECIDO, pero después de un período de tiempo, el servidor cerrará la conexión, por lo que netstat no puede encontrarlo. Cuando llega la solicitud de conexión del cuarto cliente, el servidor no aceptará el segmento ACK del último protocolo de enlace enviado por el cliente, y no permitirá que el protocolo de enlace de tres vías se establezca con éxito, y solo está en un estado semi-conectado.
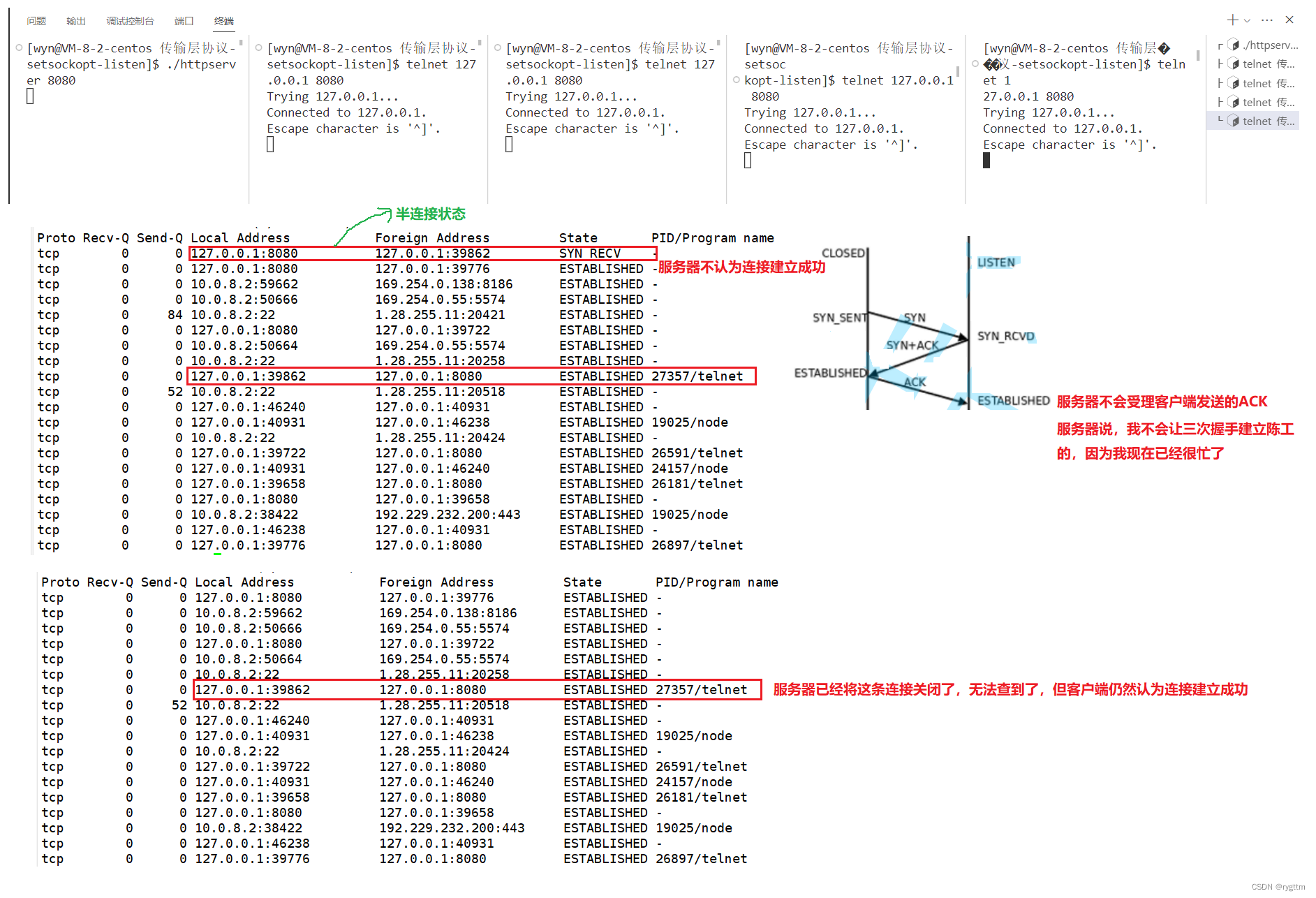
5.
A partir de los resultados experimentales, se puede ver que la cola de espera del kernel TCP solo puede permitir backlog+1 conexiones completas como máximo, y las conexiones posteriores solo pueden ser medias conexiones. Si el protocolo de enlace no se puede completar lo antes posible, el El servidor cerrará automáticamente la media conexión.
Vale la pena señalar que la longitud de la cola de conexión completa no tiene nada que ver con la cantidad de conexiones que el servidor puede establecer, solo significa que cuando el servidor no llame, acepte obtener la conexión, si la conexión llega, entonces ponga temporalmente el conexión en la cola de espera primero. , y esta cola de espera solo puede acomodar conexiones atrasadas + 1 como máximo, y cuando el servidor se ejecuta en la interfaz de aceptación, la conexión se toma de la cola.
6.
La pila de protocolos del kernel de Linux en realidad usa dos colas para administrar una conexión TCP, una es una cola de conexión parcial y la otra es una cola de conexión completa. Cuando la cola de conexión completa está llena, el servidor no puede continuar aceptando nuevas conexiones entrantes. La semiconexión sólo se mantendrá por un corto período de tiempo.
